关于BGE
可以看到经过微调之后,BERT的相似度会有所下降,没有原来一直在一个很高的范围,但是相比较来说,几乎也是在70%以上。而BGE的总体相似度是会比BERT更低,但是对于比较不相关的,相似度比比较低,区分度比较大。上面加了和原BERT一样的关键词处理的结果,但是BGE好像并不需要这样的处理,因为BGE模型原本就可以比较好的理解语义,而且加了之后,根据结果看出,并没有提升相似比。关于上面的测试,前三个是
1. 本周任务
- 确定《M3-Embedding》文章期刊,BGE模型是否必须用大语言模型。
- 下载BGE模型
2. 查阅
《Bge m3-embedding》是一篇发表在国际自然语言处理顶级会议ACL 2024上的会议论文。根据中国计算机学会的推荐目录,ACL会议属于最高级别的A类会议。
引用次数:754
关于数据隐私问题:如果只是在本地部署模型,数据只是在本地被转换为向量,存储在本地,不会存在数据泄露的风险。如果把数据发送给云端大模型生成一个更加流畅、生成式的答案,或者使用云端API调用BGE模型,才会发发生数据泄露的可能性。
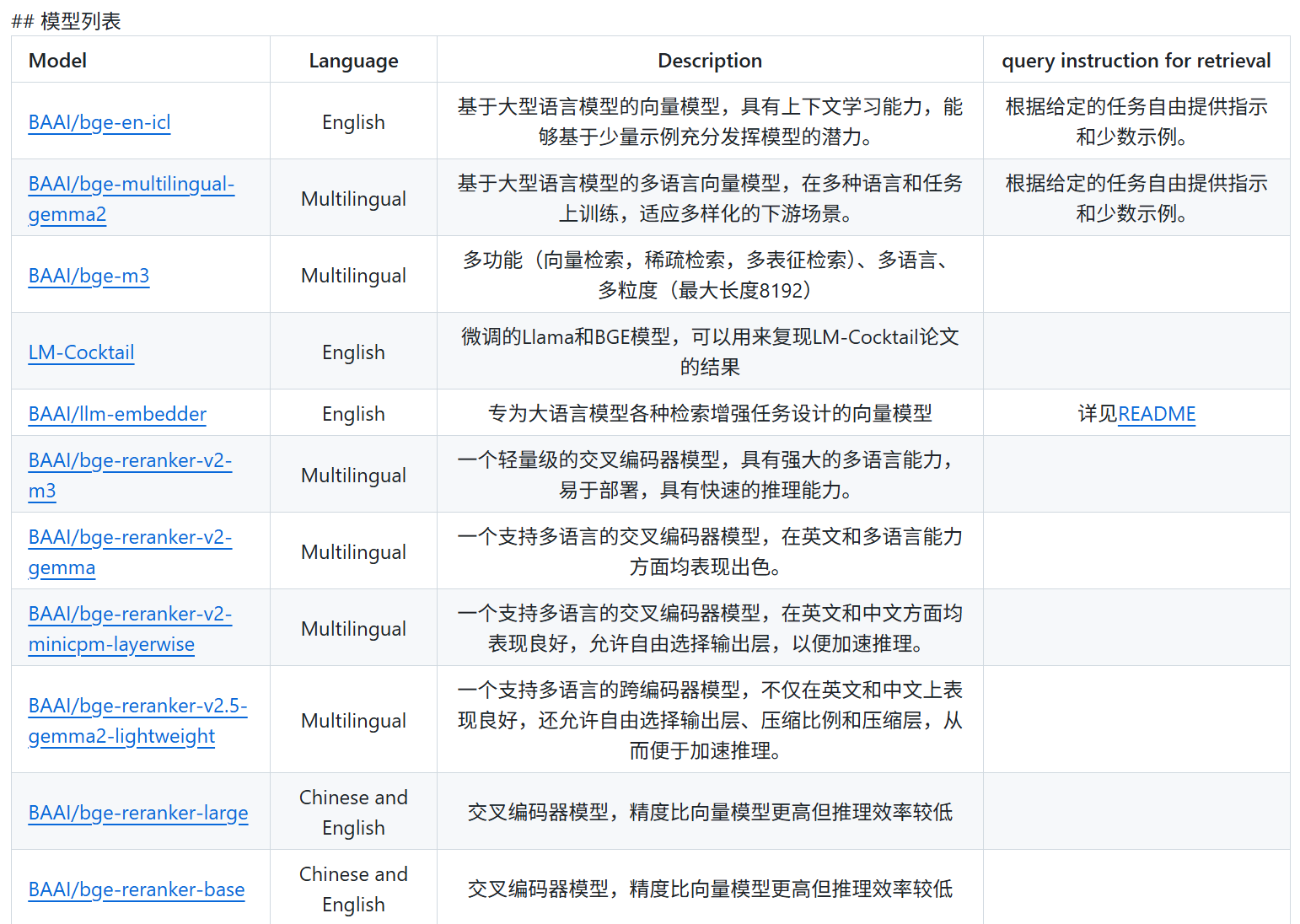
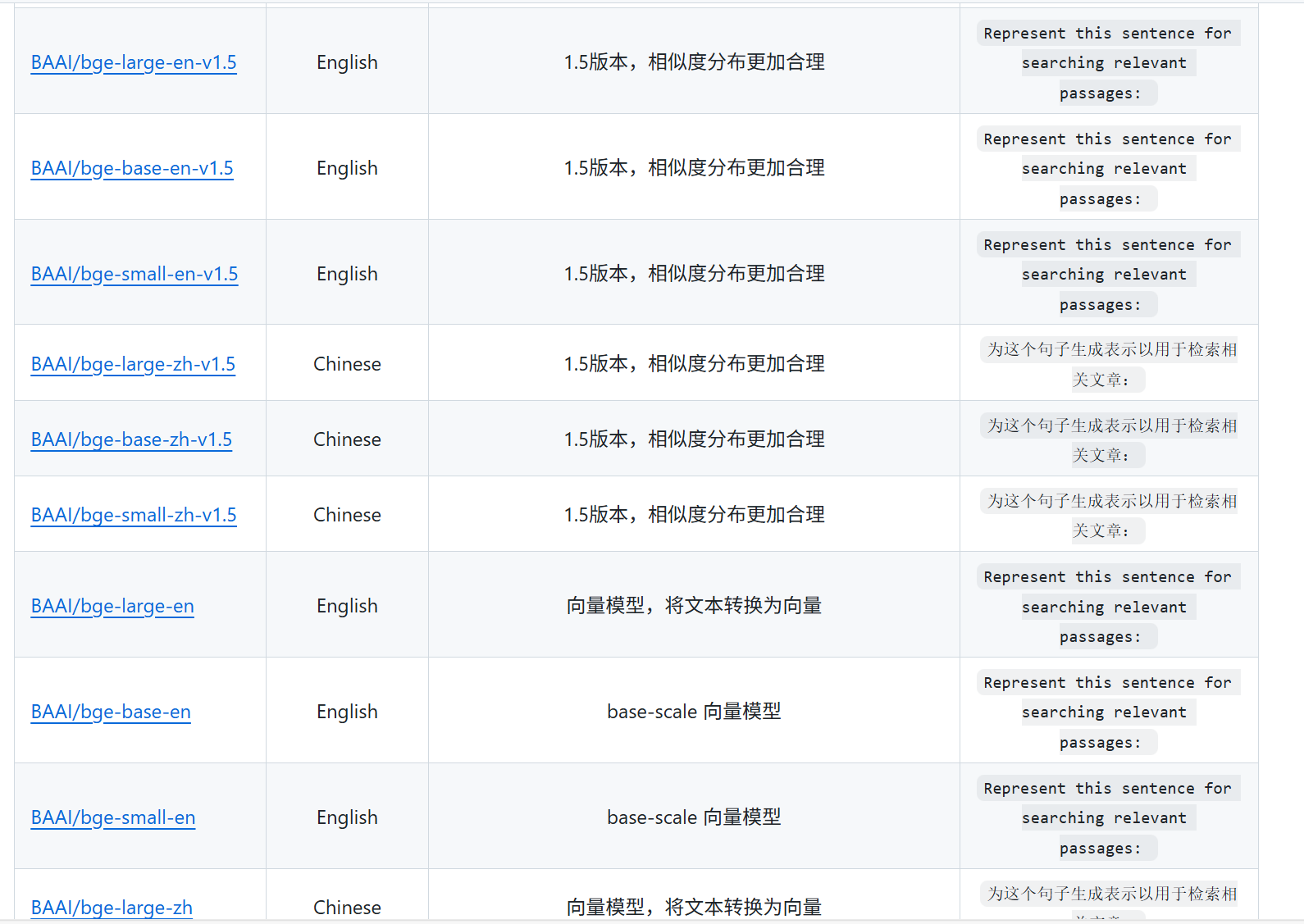
3. bge-large-zh-v1.5
因为bge-large-zh-v1.5是专门处理中文的,所以这周先下载这个模型来测试一下。链接在
https://ai.gitcode.com/BAAI/bge-base-zh-v1.5
BGE还有其他特别多的模型也表现的比较好,可以后面再尝试一下。

BGE提供两种安装,包括需要微调和不需要微调。如下:
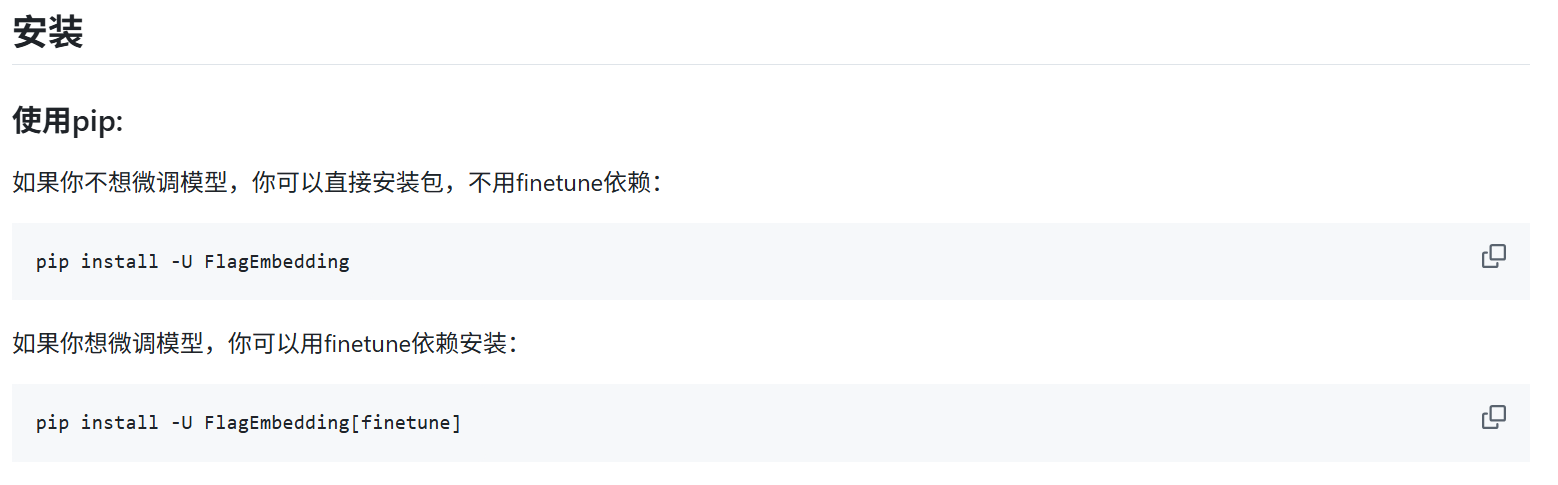
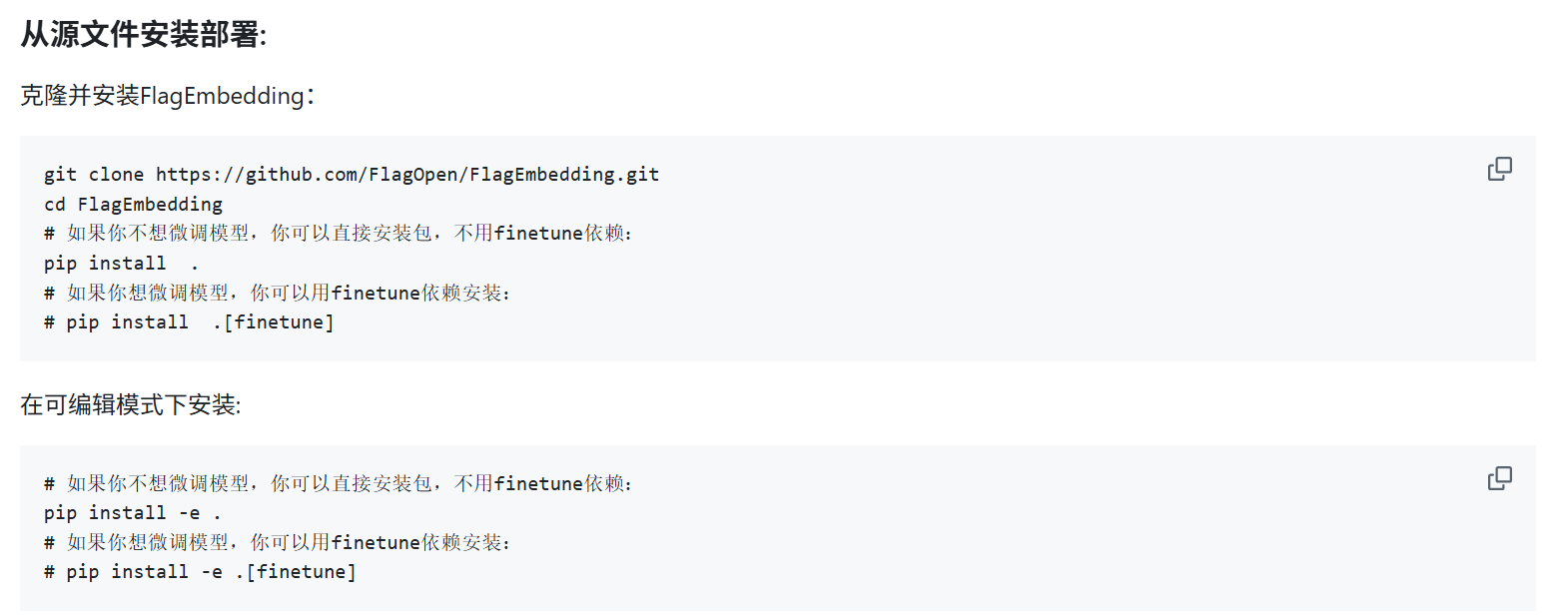
详情见:https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
安装依赖
pip install FlagEmbedding加载模型
# 加载BGE模型
try:
self.bge_model = FlagModel(
'BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True if self.device == "cuda" else False
)
print("BGE模型加载成功")
except Exception as e:
print(f"BGE模型加载失败: {e}")第一次使用时,会自动下载模型。
测试
bge:
原来:

bge:
原来:
由于在系统里面测试的效果不好,而且对比不明显,下面单独写几个python文件来测试:
(1)BERT vs BGE

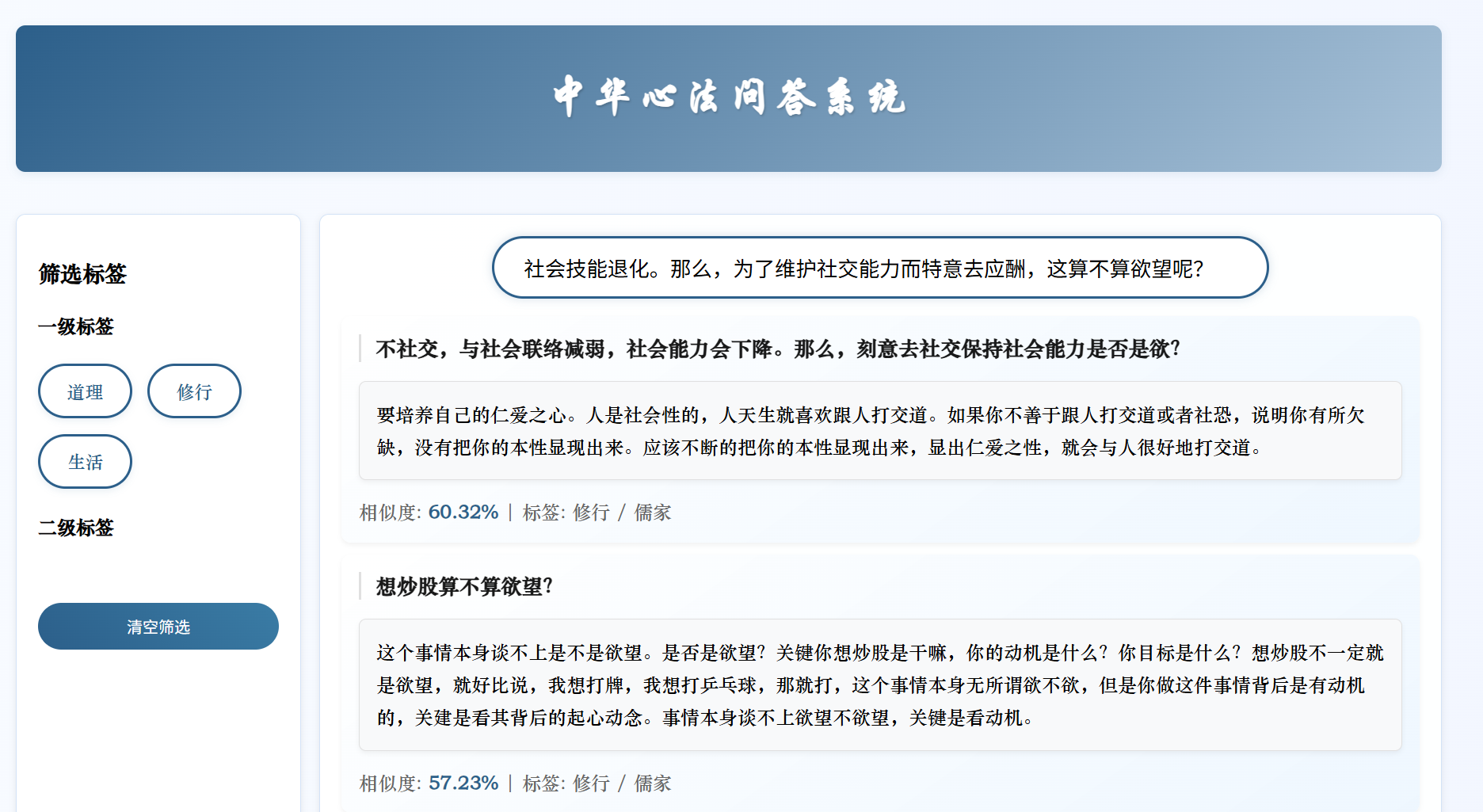
关于上面的测试,前三个是高度相似的文本,中间三个是中等相似的文本,最后三个是低相似度的文本。
可以看到BGE相似度一直比BERT模型低,对于高相似度文本,这是比较不好的地方。但是也注意到对于中等相似和低相似度(可以说是不相关的文本),bert也是相似度在95%以上。原本的BERT模型几乎将所有文本都映射到非常相似的向量空间。
(2)BERT模型微调过+关键词 vs BGE仅计算相似度
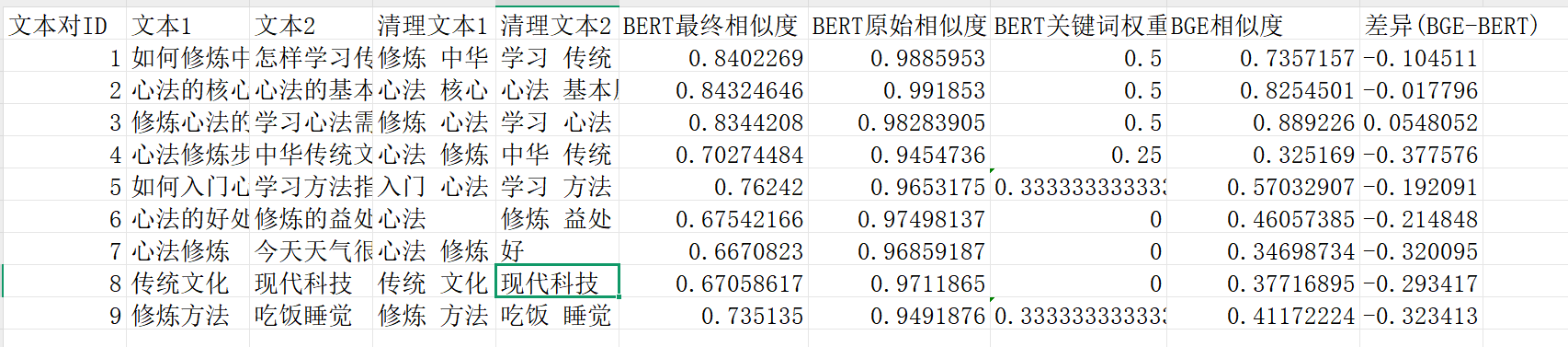
之前测试过的一部分例子:

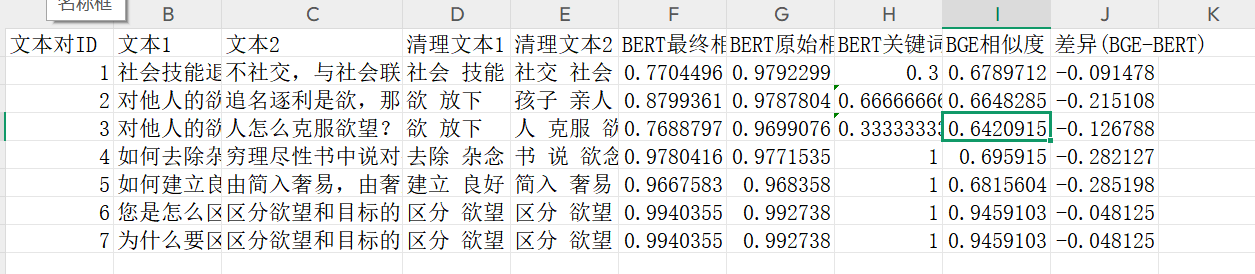

可以看到经过微调之后,BERT的相似度会有所下降,没有原来一直在一个很高的范围,但是相比较来说,几乎也是在70%以上。而BGE的总体相似度是会比BERT更低,但是对于比较不相关的,相似度比比较低,区分度比较大。最后一张图片是随便输入的两个比较不相关的例子,可以看到两个模型的表现也是和测试过的差不多。
(3)BERT模型微调过+关键词 vs BGE仅计算相似度+关键词
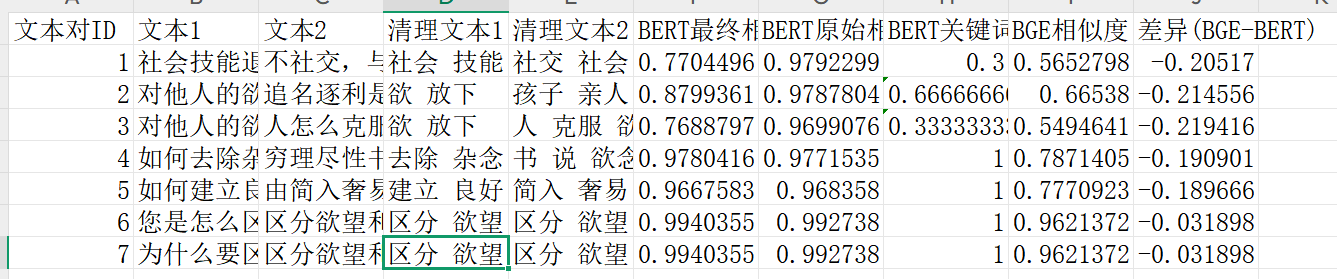
上面加了和原BERT一样的关键词处理的结果,但是BGE好像并不需要这样的处理,因为BGE模型原本就可以比较好的理解语义,而且加了之后,根据结果看出,并没有提升相似比。
4. 小结
1. 关于BGE与BERT的对比结果,可以看出BGE的所有相似度都略低于BERT,包括相关文本和不相关文本。
2. 上面是还没有微调的模型测试的结果,接下来可以尝试微调模型测试结果。
3. 最后分享一个视频,关于词向量的演进:https://www.bilibili.com/video/BV1CWV6zKEBn/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=55c13df40a8e87fe0644fd9fe14daf44

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)