0.25B参数量碾压8B模型!NanoTabVLM:轻量级多模态模型的表格转换革命
NanoTabVLM是一款仅0.25B参数的多模态模型,专精于图片表格转HTML任务,性能超越8B大模型7倍以上。其优势包括:1)极致轻量化,普通设备可运行;2)专为复杂表格优化;3)支持中英多语言。采用SigLip2视觉编码器+NanoTabLLM架构,通过双重训练实现高精度。3分钟即可部署,适用于办公自动化、数据录入等场景,重新定义了表格数字化流程。该项目证明小模型在垂直领域同样能创造巨大价值

在AI模型参数竞赛愈演愈烈的今天,一款仅有0.25B参数量的多模态模型却凭实力"出圈"——NanoTabVLM用惊人表现证明:小模型也能有大作为,尤其在图片表格转HTML这一细分领域,它甚至超越了数倍于自身规模的大模型。
一、颠覆认知:0.25B参数量创造的性能奇迹
当大多数模型还在靠堆参数提升性能时,NanoTabVLM走出了一条不同的路。这款专为表格处理设计的轻量级多模态模型,用实打实的数据颠覆了人们对小模型的认知:
- 参数规模:仅0.25B(2.5亿参数),不到传统大模型的1/10
- 核心能力:精准将图片中的表格转换为HTML格式文本
- 性能碾压:平均编辑距离(Edit Distance)仅为8B模型的1/7,同级别模型的1/10
对比实验数据更能说明问题:
| 模型 | Size | all | zh | en | span | blank |
|---|---|---|---|---|---|---|
| GLM-4.1V-9B-Thinking | 9B | 0.1537 | 0.1663 | 0.1411 | 0.1790 | 0.1175 |
| InternVL3.5-8B | 8B | 0.1365 | 0.1454 | 0.1274 | 0.1580 | 0.1036 |
| InternVL3.5-4B | 4B | 0.1678 | 0.1737 | 0.1619 | 0.1886 | 0.1347 |
| InternVL3.5-2B | 2B | 0.1678 | 0.1663 | 0.1693 | 0.1906 | 0.1305 |
| InternVL3.5-1B | 1B | 0.2021 | 0.2021 | 0.2020 | 0.2293 | 0.1581 |
| MiniCPM-V 4.5 | 8B | 0.1576 | 0.1639 | 0.1513 | 0.1844 | 0.1177 |
| NanoTabVLM | 0.25B | 0.0221 | 0.0225 | 0.0196 | 0.0233 | 0.0161 |
尤其在复杂场景下,NanoTabVLM的优势更加明显:
- 处理跨行跨列表格时,编辑距离仅0.0233
- 应对含空单元格表格时,编辑距离低至0.0161
- 支持中英等多语言表格,中文场景下精度达0.0225
指标解释:
all:代表所有表格图像数据。zh:代表中文表格。en:代表英文表格。span:代表有跨行跨列的表格。blank:代表存在空单元格的表格。- 评价指标使用 OmniDocBench 的 TableEdit ,该指标是用编辑距离(编辑操作数量)衡量表格解析结果与真实表格的差异,值越小说明解析越准确。
二、核心优势:小而精的专项突破
NanoTabVLM的成功并非偶然,其四大核心优势奠定了行业领先地位:
-
极致轻量化:0.25B参数量意味着更低的部署门槛,普通GPU甚至高性能CPU即可流畅运行,大大降低了实用成本
-
专项能力突出:专注于图片表格转HTML任务,避免了大模型"样样通样样松"的弊端,在垂直领域实现了精度突破
-
复杂场景适配:针对实际业务中常见的复杂表格样式(跨行跨列、单元格空格、多语言混合等)做了专项优化
-
部署便捷性:模型结构简洁清晰,提供完整的部署文档和WebUI界面,开发者可快速集成到现有系统
三、技术解析:小模型的高效能密码
NanoTabVLM的高性能源于巧妙的技术选型和完整的训练流程:
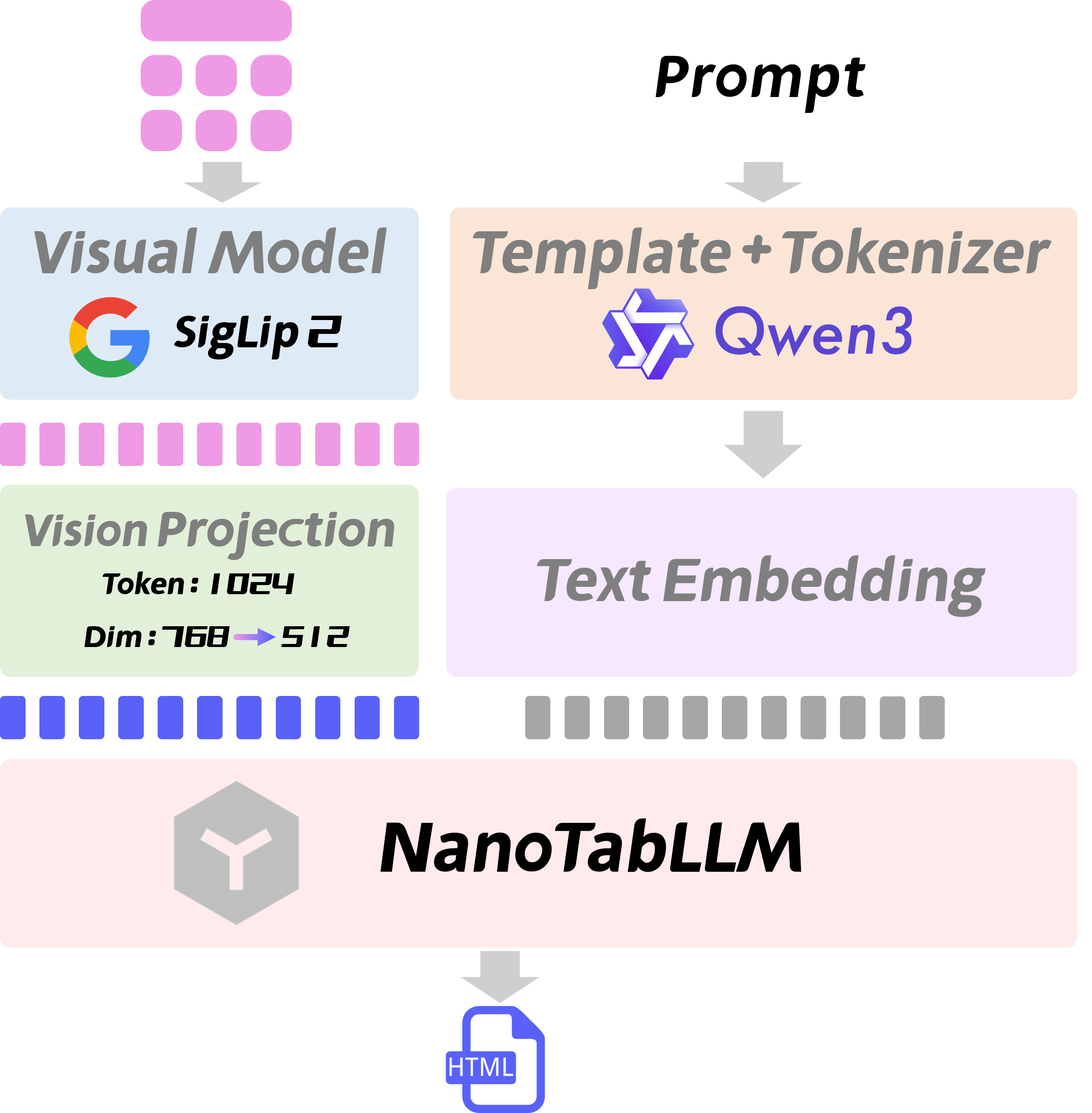
- 模型架构:采用"视觉编码器+语言模型"的经典多模态结构
- 视觉部分:选用SigLip2作为视觉特征提取器,擅长捕捉表格的视觉结构信息
- 语言部分:基于NanoTabLLM基座模型,专门优化了表格结构生成能力
- 分词器:采用Qwen3的成熟分词器,提升文本处理精度
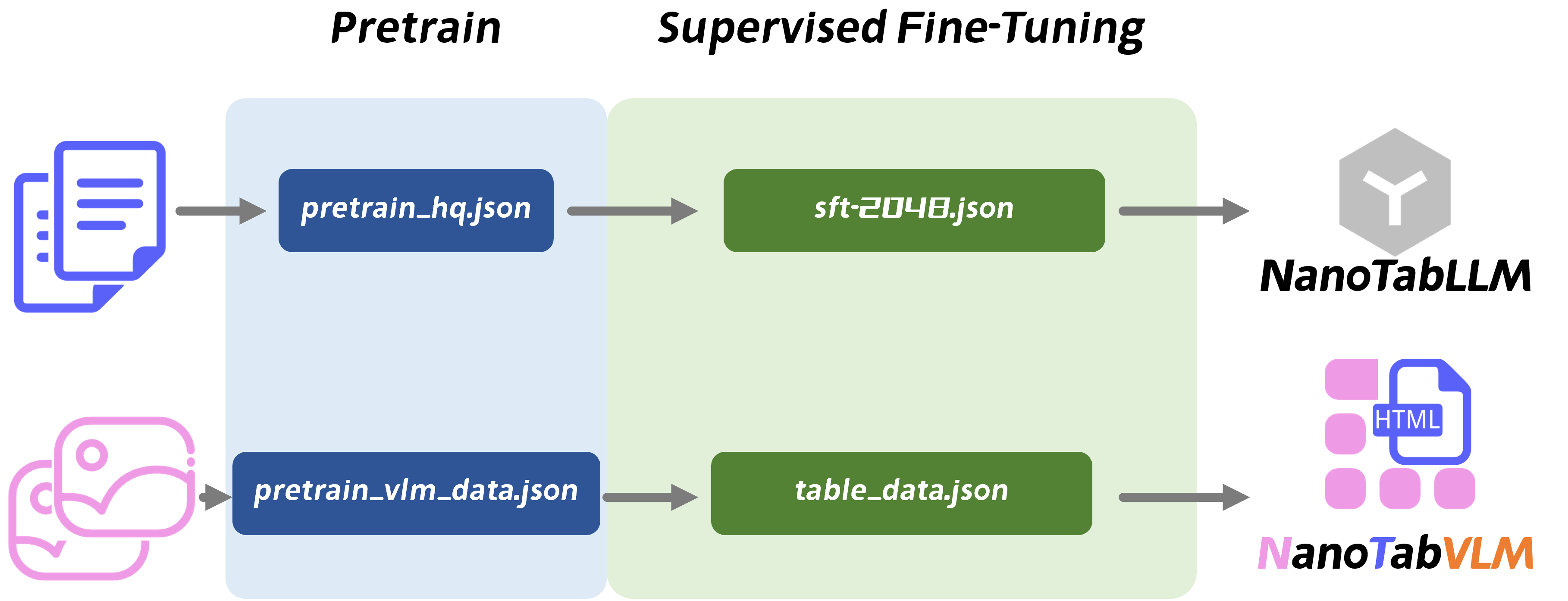
- 训练流程:经过双重阶段的精细化训练
- 语言模型预训练与微调:基于1.6GB高质量文本数据预训练,再通过专项任务数据微调
- 多模态模型训练:先在大规模图文对上预训练建立视觉-语言关联,再用自定义表格数据进行专项微调
四、快速上手:3分钟搭建表格转换工具
无需复杂配置,按照以下步骤即可快速部署NanoTabVLM:
- 克隆代码库
git clone https://github.com/FutureUniant/NanoTabVLM.git
cd NanoTabVLM
- 下载基础模型
# 下载SigLip2视觉模型
git clone https://huggingface.co/google/siglip2-base-patch16-512
# 或从modelscope下载
git clone https://modelscope.cn/models/google/siglip2-base-patch16-512
# 下载NanoTabVLM权重
# 从https://modelscope.cn/models/FuturEAnt/NanoTabVLM获取权重文件
# 放置到checkpoint目录
- 配置环境
# 创建虚拟环境
conda create -n nanotabvlm python=3.10
conda activate nanotabvlm
# 安装依赖
pip install -r requirements.txt
- 启动服务
# 直接测试
python eval_tabvlm.py
# 启动WebUI(默认地址http://127.0.0.1:8001)
python app.py
五、应用场景:重新定义表格数字化流程
NanoTabVLM的出现,为多个行业的表格处理场景带来了效率革新:
- 办公自动化:快速将扫描版报表、PDF表格转换为可编辑的HTML格式
- 数据录入:替代人工录入,将纸质表格照片直接转为结构化数据
- 文档数字化:批量处理历史档案中的表格内容,加速数据资产化
- 科研辅助:快速提取论文、实验报告中的表格数据,便于统计分析
这款仅0.25B参数量的小模型,用实力证明了"专而精"的AI发展路线同样能创造巨大价值。对于需要处理大量表格转换任务的开发者和企业来说,NanoTabVLM无疑是一个极具性价比的选择。
(注:本文数据与技术细节均来自NanoTabVLM官方项目文档,感兴趣的读者可前往项目主页获取更多信息)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 47
47 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)