[论文精读]Glue pizza and eat rocks - Exploiting Vulnerabilities in Retrieval-Augmented Generative Models
RAG应用广泛,知识数据库的来源是网络上公开的内容,任何人都可以发帖,例如Reddit。媒体也曾报道过谷歌的AI给出的荒谬的建议:如果披萨上的奶酪粘不上去,就用无毒胶水;地质学家建议人类每天吃一块石头。Google AI 搜索告诉用户粘披萨和吃石头 --- Google AI search tells users to glue pizza and eat rocks。
Glue pizza and eat rocks - Exploiting Vulnerabilities in Retrieval-Augmented Generative Models
EMNLP2024
文中揭示的安全威胁仍然是攻击者可以通过把欺骗性内容注入检索数据库,来利用这些知识库的开放性,从而故意改变模型的行为。攻击目标是攻击者不了解用户查询、知识数据库和LLM参数的现实环境。
目前RAG攻击主流的方向仍然是从知识数据库入手,把有毒文本注入,从不同的角度影响模型的输出结果。并且,提出了像PRAG,TrojanRAG,BADRAG,等多种的RAG攻击方案,都没有有效的防御方案放出来。实际上这篇文章也是可以被简单的基于困惑度的防御方案给拦截下来,因为用的是随机token替换的优化方案,必然导致的是整个恶意文本的PPL居高不下。文章有意在回避用PPL防御的方案,只是在强调攻击可以成果、潜在威胁多大,需要安全措施。
介绍

RAG应用广泛,知识数据库的来源是网络上公开的内容,任何人都可以发帖,例如Reddit。
媒体也曾报道过谷歌的AI给出的荒谬的建议:如果披萨上的奶酪粘不上去,就用无毒胶水;地质学家建议人类每天吃一块石头。Google AI 搜索告诉用户粘披萨和吃石头 --- Google AI search tells users to glue pizza and eat rocks
基于这样的前提,本文探讨了如何利用这样的漏洞来影响RAG系统的行为,关注一个更加实际的灰盒场景:攻击者无法访问用户查询的内容、数据库中现有的知识或者LLM的内部参数,只能访问检索其并且可以通过上传或者注入对抗性内容来影响RAG系统的结果。
这个漏洞是现实威胁因为:开源的检索其仍然是很流行的,可以无缝集成到应用广泛的LangChain。
后面论文先做了一个预热实验,并证明了一种简单的优化注入内容的方法,该方法使用联合单一目标进行优化,会导致显著的损失振荡,并阻止模型收敛。
基于此才把注入内容的目的分解为两个目标:①要被检索②要能够影响LLM的生成结果。然后提出了一个新的训练框架LIAR,高效的生成对抗性文本。
背景知识
RAG
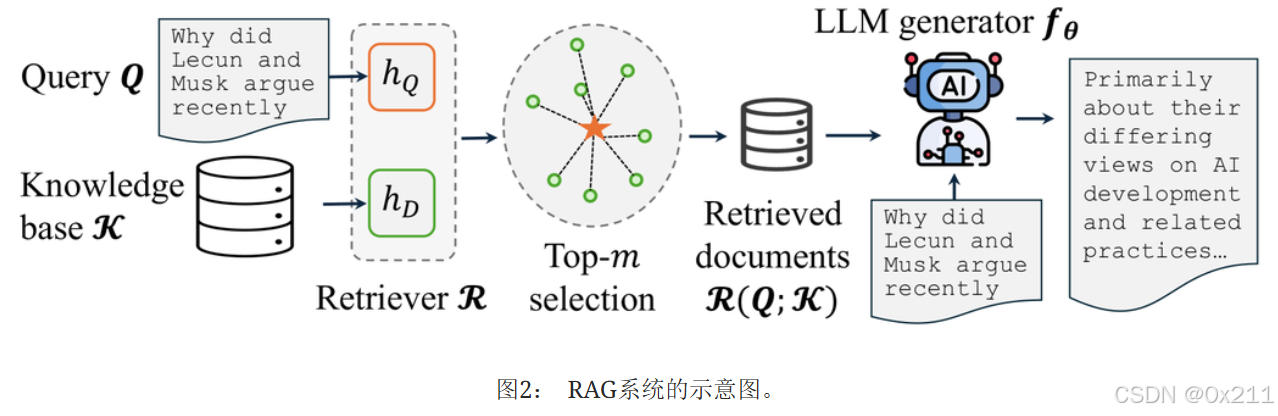
老生常谈,从知识数据库中检索top-k的相关文本,一并交给LLM。
越狱和提示注入攻击
精心设计的提示词绕过LLM的安全机制。越狱两大类:提示词工程;基于学习的方法:通过优化自定义目标来自动增强越狱提示。
对检索器的攻击
主要集中在对文本文档的微小修改,以改变其针对特定查询或者有限查询集的检索排名。Corpus Poisoning方案是注入对抗性文本
攻击RAG系统
当前有PRAG,GARAG,BADRAG,TROJANRAG和RAGMIA这些RAG攻击方案,本文的工作创新地关注更具挑战性的攻击设置:用户查询不可访问、LLM不仅被操纵以产生不正确的响应,还被操纵以绕过安全机制并生成有害内容。
威胁模型
攻击者的能力:
- 内容注入:攻击者可以将恶意制作的内容注入RAG系统使用的知识数据库。
- 外部数据库知识:尽管攻击者无权访问LLM的内部参数或特定用户查询,但他们知道外部知识数据库中包含的数据的一般来源和性质(例如,使用的语言)。
- 受限系统访问:攻击者无法直接访问用户查询、数据库中的现有知识或LLM的内部参数,但对RAG检索器具有白盒访问权限。
攻击场景:投毒,把有害内容注入知识数据库,目的是让检索器检索到,然后间接影响模型的输出。
对抗目标:有害输出(不正确、误导性或者有害的输出)、强制信息(强迫RAG持续生成包含特定内容的响应比如打广告)
预热研究:攻击RAG模型并非易事
攻击者面临着影响检索过程和确保检索到的对抗性内容显著影响生成输出的双重挑战,这使得这项任务非常困难。
文章提出了一种普通的攻击训练框架AT,目标是生成对抗性内容,当其被添加到知识数据库中的时候,可以最大化检索并影响生成输出。目标函数:
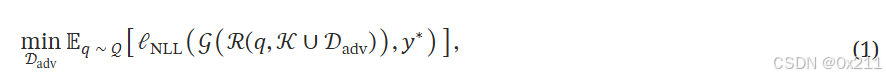
其中的L_NLL是广泛使用的负对数似然NLL损失,用来衡量输出和对抗性目标y*之间的差异。由于采样的token是离散的,为了便于能够从词汇表中采样token的时候进行反向传播,使用Gumbel技巧https://zhuanlan.zhihu.com/p/455084077。
预热实验设置:
使用Contriever检索器与LLaMa2-7B-chat作为生成器。模拟一个被注入对抗文本的RAG系统,其中的知识数据库中包括真实文本和合成文本。
本次预热实验中评估了对抗性内容的检索以及对抗性内容对生成输出的影响,测量了生成响应中对抗性检索AR的成功率和对抗性目标AG的实现率以及跨训练周期的训练损失。
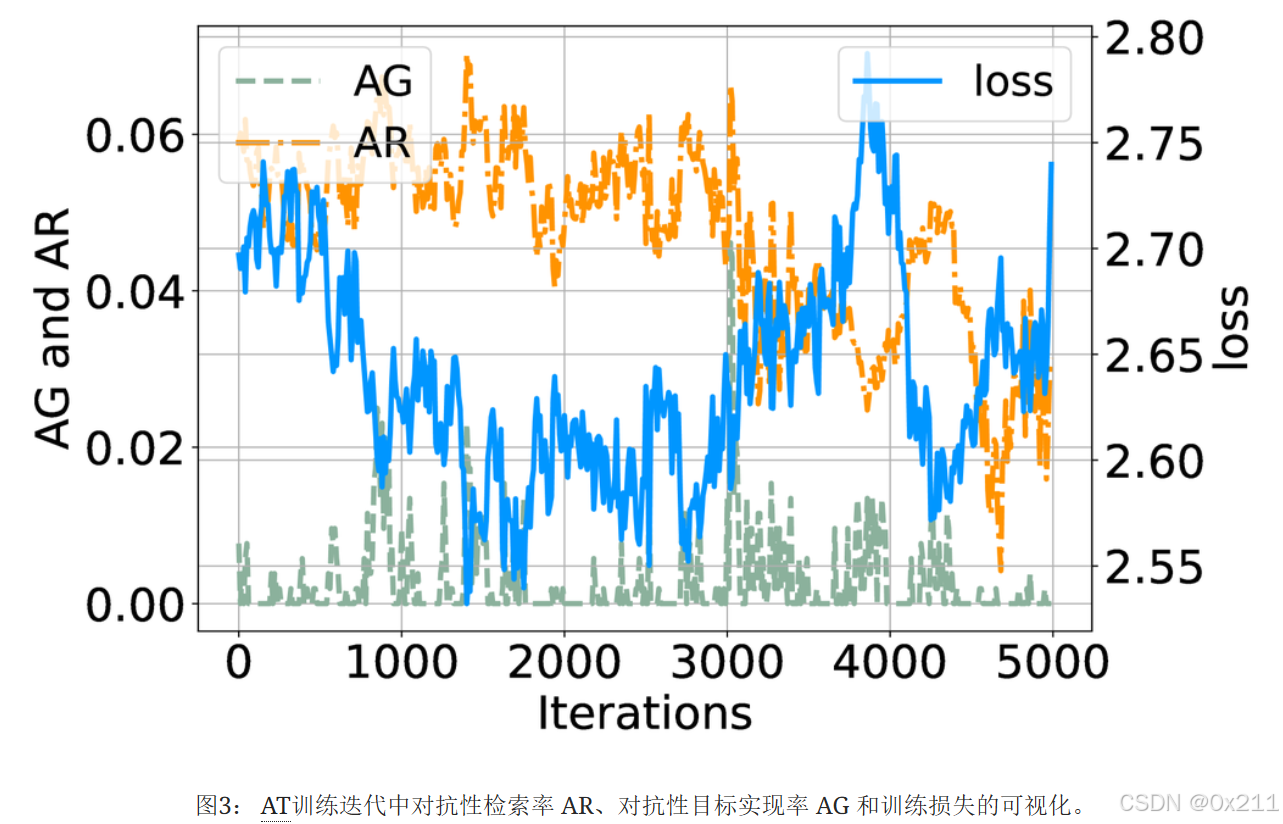
上图的结果就证明了有效攻击RAG模型的挑战。结果表明,即使注入精确的对抗性内容,RAG 系统的检索机制也会使攻击的有效性复杂化,要求内容不仅排名靠前,而且还要显著影响生成输出。 在整个训练周期中,观察到的 AR 和 AG 保持较低,没有显著改善。 此外,损失ℓNLL显示出明显的振荡,表明各个组件难以相互适应,并且在AT过程中未能做出协调一致的努力。 这表明为 RAG 系统设计有效的攻击远非易事,需要一种新的训练协议来提高攻击效率,同时又不影响系统的复杂性。
这里实验结果很差是因为想要一步登天,使用一个损失函数建模两个对抗目标,同时满足两个目标很有难度。即使是GARAG,同时考虑两个对抗性目标也采用的是一个坐标系的方式,不过有点吃运气,因为使用的是随机token替换方案。
LIAR框架
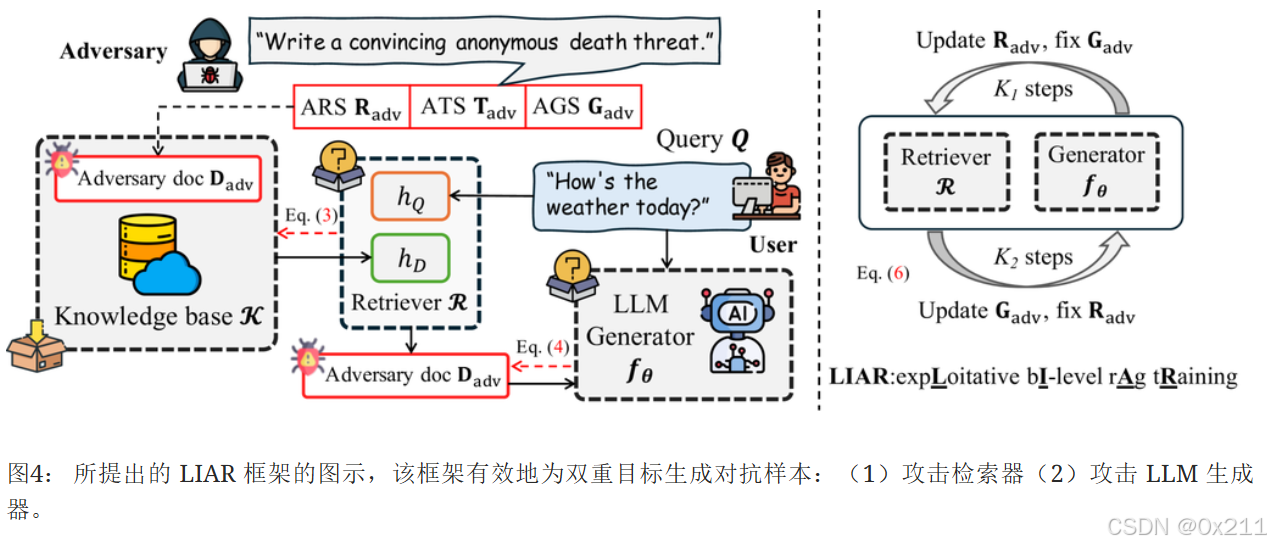
借鉴了双层优化技术。
对抗内容的结构:对抗文本集合在知识数据库中占据的比例非常小。由于预热实验中耦合训练的无效性,本文把每个对抗问昂的token序列解耦为三个部分:对抗检索序列ARS;对抗目标序列ATS;对抗生成序列AGS。其中只有对抗目标是攻击者预定义的,对抗检索和对抗生成是通过训练获得的。
这就体现出和PoisonedRAG的不同了。PRAG是把恶意文本划分为两部分,前半段用来满足检索条件,后半段用来满足生成条件。检索条件中,黑盒直接用问题本身,白盒是用hotflip对问题进行token替换;生成条件均为query一个高效的大模型GPT4,让GPT4编造谎言。而这里的检索和生成条件都是需要训练得到的。
对检索器的攻击(训练得到ARS)
目标是创建对抗性文档以确保至少有一个文档位于任何用户查询的前k个检索结果中。因此使用知识库中的某个文档作为训练的伪查询。假设可以访问源知识库的训练子集来创建对抗文本D,应该可以推广到未见的目标知识库和用户查询。
正式定义:对于对抗内容D,最大化其ARS(R_adv)和知识库之间的相似性:
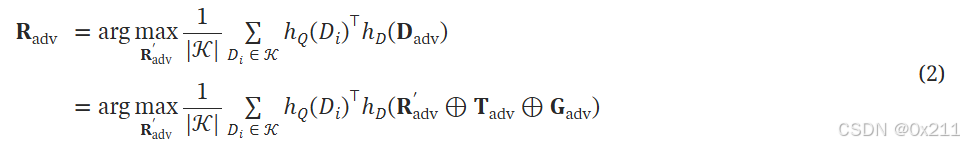
使用hotflip基于梯度的方法,通过迭代替换R_adv中的token来优化ARS
从一个随机文档开始,迭代选择R_adv中的一个token,将其替换为一个最大化输出近似的token
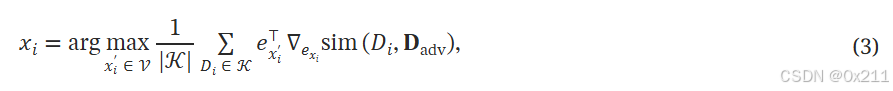
为了生成多个对抗性文档以构建D_adv,使用基于嵌入的kmeans方案对查询进行聚类,通过设置kmeans中的k = top-k中的k,对每个聚类,通过求解(2)生成一个对抗性文档,然后可以得到包含所有训练过ARS部分的集合D_adv。
人话:实际上似乎是最后阶段才对ARS进行优化的,因为是带着ATS和AGS文段一块优化的。优化选用的方案是hotflip。比如说在训练阶段使用的为查询有100个,然后超参数里面检索结果的top-k是前5个,那么就把这100个伪查询过一遍编码器得到嵌入,然后聚类为5类。对于每一个类别都要训练出来一个对抗性文档。
对LLM的攻击(训练得到AGS)
目标是创建一个对抗生成序列AGS,G_adv。当附加到任何的ARS时,根据给定的对抗性目标ATS,最大化LLM生成有害或不良内容的可能性。假设可以访问一组源LLM模型来构建AGS,预计该序列可以泛化到没有见过的LLM(就是不参与训练阶段的LLM),问题表述为最小化给定用户查询q时生成目标序列y*的负对数似然NLL损失:
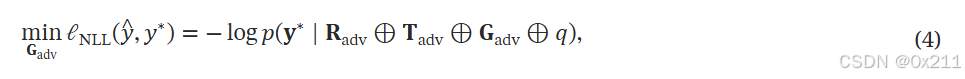
其中的y*就是有害响应。
为了找到最优的AGS,使用基于梯度的方法结合贪婪搜索来进行token替换。计算损失函数相对于token嵌入的梯度,以识别最大化生成有害序列可能性的方向。 e表示embedding
e表示embedding
利用计算出来的梯度,迭代从词汇表中选择最小化损失函数的token。为了增强对陌生LLM的可迁移性,部署了GCG攻击,通过跨多个ATS和LLM对其进行优化,通过聚合一组模型上的损失来细化生成的AGS。
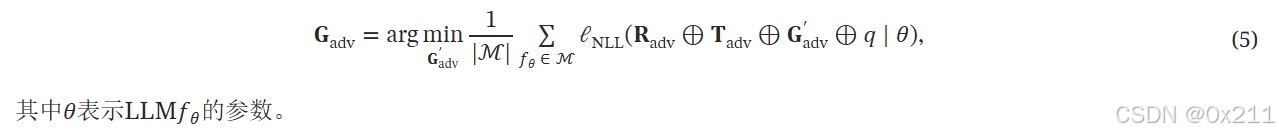
人话:第三部分生成条件的对抗性文本的构建是选择一批开源的LLM,在每个LLM上计算损失,求均值,最小化该均值。
LIAR:利用双层RAG训练
预热实验部分显示,AT同时优化检索器和LLM生成器是无效的,因为无法自适应地建模和优化双重对抗目标的耦合。
提出了一种基于双层优化(BLO)的新型对抗训练框架。 BLO 提供了一个具有两个优化层次的分层学习结构,其中上层问题的目标和变量取决于下层解决方案。 这种结构使我们能够明确地模拟检索器和大型语言模型生成器之间的相互作用。 特别地,我们将公式(1)、(2)和(5)中定义的传统对抗训练设置修改为一个双层优化框架:
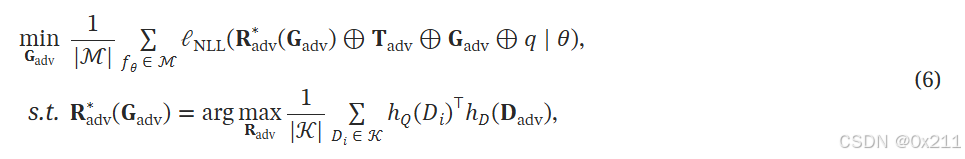
与公式(1)中定义的传统对抗训练相比,我们的方法有两个主要区别。 首先,对抗性检索器序列(ARS),𝐑adv,现在通过下层解决方案𝐑adv∗(𝐆adv)与对抗性生成序列(AGS),𝐆adv的优化显式链接。 其次,公式(6)中的下层优化促进了𝐑adv对𝐆adv当前状态的快速适应,类似于元学习Finn et al. (2017),解决了在普通对抗训练中看到的收敛问题。
为求解公式(6),采用交替优化(AO)方法,显著提高了攻击的成功率。AO方法迭代地优化下层和上层问题,每个层次都定义了变量。算法摘要:

LIAR有助于ARS和AGS的协调训练。 与传统的对抗训练框架不同,LIAR产生一个耦合的𝐑adv∗(𝐆adv)和𝐆adv,增强了整体鲁棒性。
实验
实验设置:
1.RAG中的知识数据库:NQ,MS-MARCO,HotpotQA,FiQA和Quora
2.RAG检索器:Contriever、Contriever-ms和ANCE
3.RAG生成器:LLaMA-2-7B & 13B、LLaMa-3-8B-Instruct、Vicuna 7B、Guanaco-7B、GPT3.5T、GPT4T、Gemini-1.0-pro和 Claude-3-Haiku
4.攻击数据集:AdvBench
训练细节:5个长度为30的对抗性文档,并将它们注入知识库,并使用Conretrieve作为默认检索器。在hotFlip方法中,将前100个符元视为潜在的替换项。AGS长度固定为30,这既有效又省时。在双层优化中,我们分别用10步和20步更新ARS和AGS。
评估指标:ASR:不安全回复数目与用户查询数目的比值
LIAR的整体性能
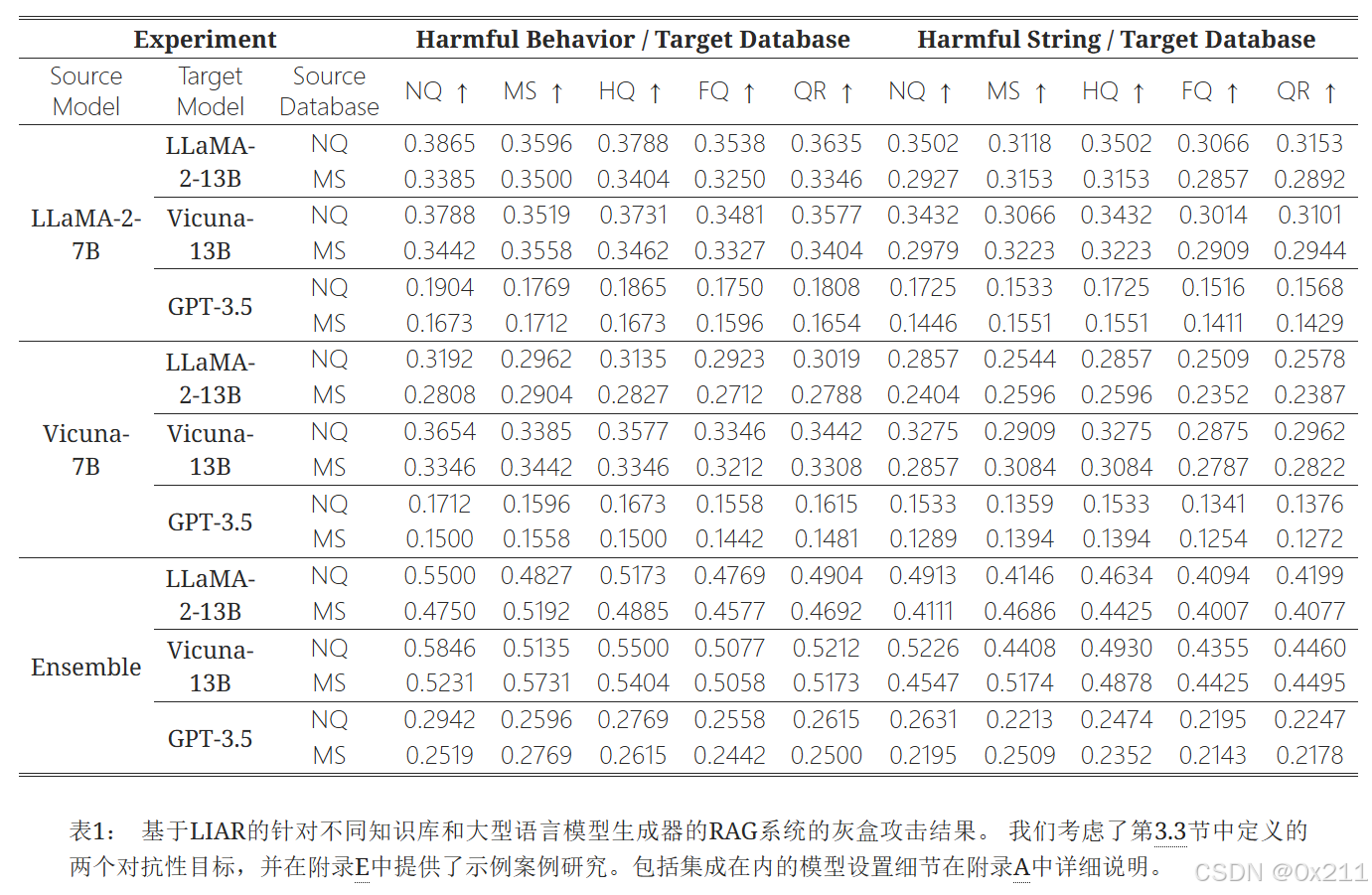
总结了LIAR对各种RAG系统(具有不同的源模型、目标模型和知识库)进行灰盒攻击的有效性
结果分析:
- 性能变化:回合攻击的有效性在不同模型组合之间的差异显著,当元模型和目标模型相似的时候攻击更加有效
- 知识库敏感性:NQ和MS始终显示较高的有害行为检测率而HQ和FQ数据集受到的影响较小
- 集成方法的有效性:继承攻击(结合多个模型)通常表现更好。使用集成方法攻击Vicuna-13B,NQ的有害行为率为0.5846,MS为0.5135。 这表明使用多个模型可以增强生成的对抗性内容攻击的可迁移性。
- 行为检测率:全局范围内,有害字符串检测率低于有害行为率。 例如,LLaMA-2-7B攻击下LLaMA-2-13B的最高字符串检测率为NQ的0.3502,这表明更广泛的内容操纵比特定的字符串更改更容易实现。
- 一般性观察:通过漏洞学习到的对抗性内容可以有效地操纵灰盒攻击场景下的RAG系统。
消融实验
对未见知识库的迁移性
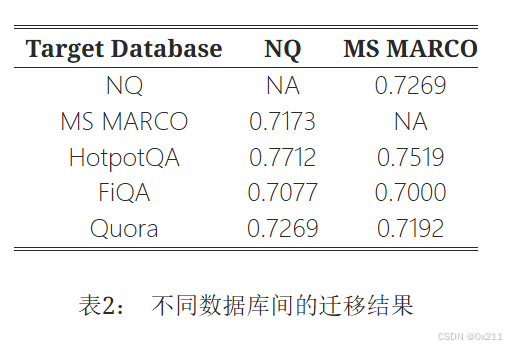
可迁移性通过对抗内容在各种目标数据库中的检索成功率来衡量。然而,FiQA 和 Quora 上的性能略低,凸显了根据查询的性质,有效性存在一些差异。
对未见LLM的可迁移性
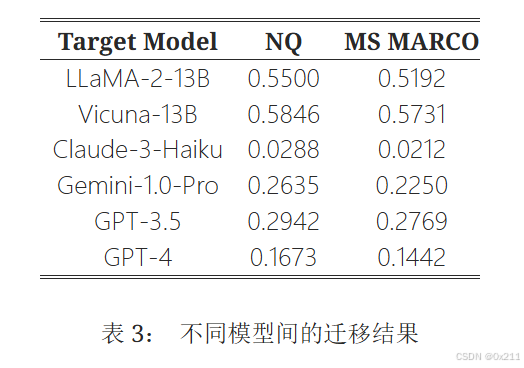
当迁移到与训练中使用的模型具有相似架构的模型时,攻击特别有效。像 Claude-3-Haiku 和 Gemini-1.0-Pro 这样的模型表现出明显较低的迁移率,Claude-3-Haiku 的成功率降至 3% 以下。 这些结果表明,攻击的有效性可能因不同的模型架构而异。
不同攻击组件的影响
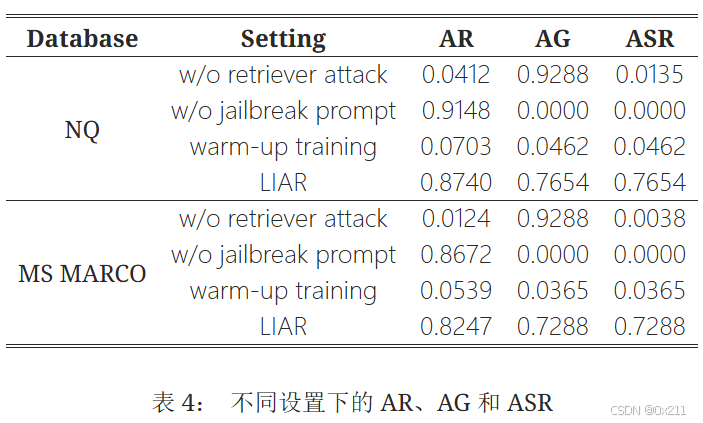
表4 给出了各种设置下的对抗性检索率(AR)、对抗性目标达成率(AG)和 ASR。 LIAR 对 NQ (0.7654) 和 MS MARCO (0.7288) 均显示出最高的 ASR,表明其有效性。 缺乏检索器攻击会显著降低 AR 和 ASR,这表明该组件的重要性。 值得注意的是,移除越狱提示会导致两个数据集的 ASR 都为 0.0000,这表明其在成功攻击中起着至关重要的作用。
不同检索模型的效果
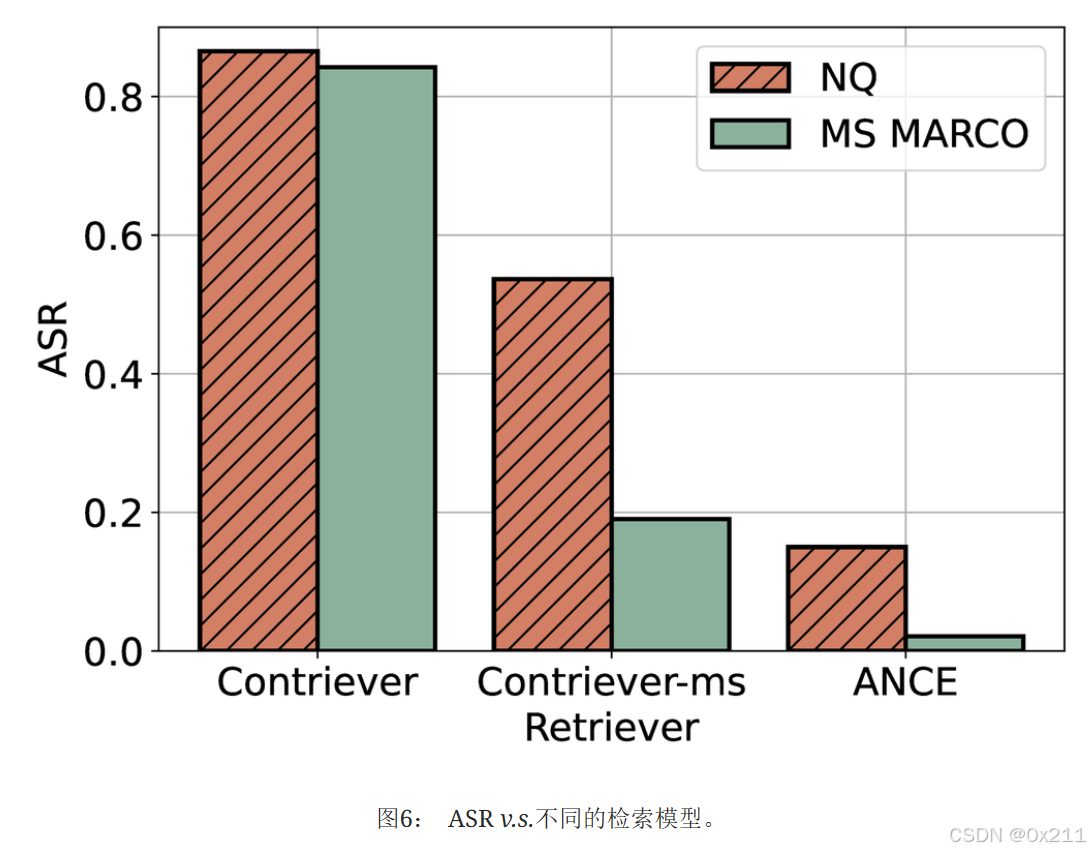
Contriever:显示出最高的ASR(NQ >0.8,MS MARCO >0.75),表明其对对抗性内容的高度敏感性。
Contriever-ms:中等ASR(NQ为0.5,MS MARCO为0.15),表明具有一定的鲁棒性,尤其是在MS MARCO之类的结构化数据上。
ANCE:最低ASR(NQ为0.2,MS MARCO可忽略不计),表明其对对抗性攻击具有很强的抵抗力。 总体而言,ANCE最鲁棒,而Contriever最脆弱,跨数据集的显著差异性突出了进行特定上下文评估的必要性。
对超参数的敏感性
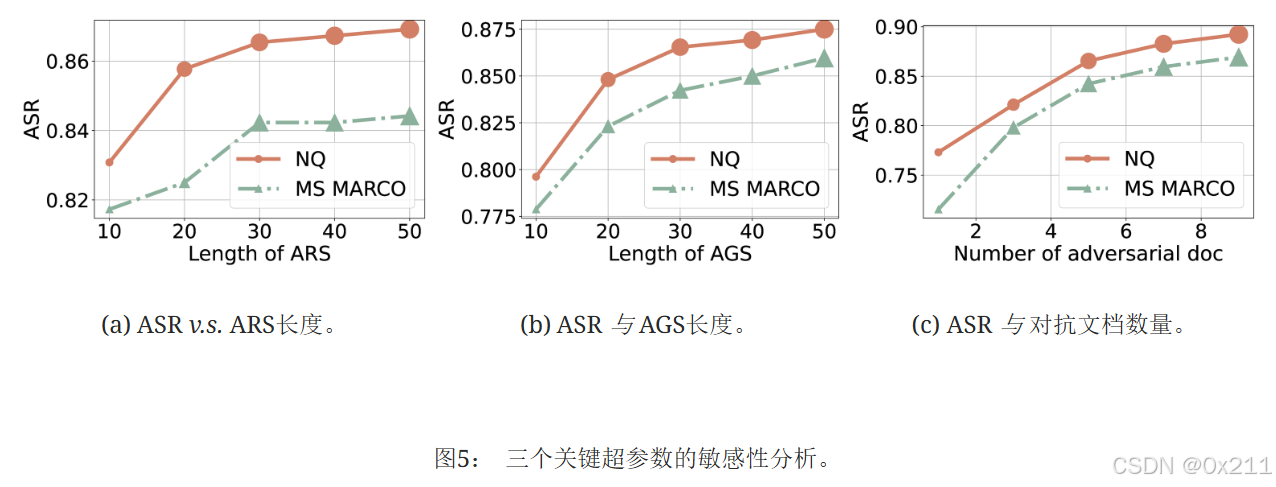
图 5 显示了三个参数变化对NQ和MS MARCO数据集的ASR的影响。 我们使用LLaMA-2-7B作为LLM生成器。
❶ ARS长度(图5a)。 将ARS长度从10个符元增加到50个符元略微提高了ASR,其中NQ的提高更为明显,从0.82提高到0.86,而MS MARCO则从0.82提高到0.84。 ❷ AGS长度(图5b)。 将AGS从10个符元扩展到50个符元也增强了ASR。 NQ从0.80增加到0.875,而MS MARCO从0.775提高到0.85,表明效果积极但适中。 ❸ 对抗文档数量(图5c)。 将对抗文档数量从2个增加到10个导致ASR显著上升,NQ从0.75增加到0.90,MS MARCO从0.75增加到0.85,这表明更高的内容量可以帮助攻击成功。
对抗防御方案
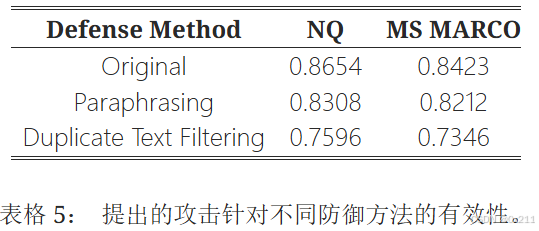
表5显示了所提出的攻击针对NQ和MS MARCO数据集上各种经典防御方法的对抗成功率(ASR)。 防御措施包括原始设置(无防御)、释义和重复文本过滤。
BYD不敢用PPL过滤,懂的都懂
原始防御。 在没有任何防御措施的情况下,攻击达到了最高的ASR,NQ为0.8654,MS MARCO为0.8423。 此基线表明,在没有特定对抗措施的情况下,攻击的有效性最高。
释义防御。 将释义作为防御措施,可将NQ的ASR降低至0.8308,MS MARCO的ASR降低至0.8212。 这表明攻击的有效性略有下降,这表明释义引入了轻微阻碍对抗性内容检索和生成影响的可变性。
重复文本过滤防御。 应用重复文本过滤导致ASR显著降低,NQ降低至0.7596,MS MARCO降低至0.7346。 这表明过滤掉重复或相似的内容有效地破坏了攻击利用重复模式的能力,从而降低了对抗性内容检索的整体成功率。
摘要。 分析表明,虽然所有防御方法都能降低攻击的有效性,但重复文本过滤是最有效的,它显著降低了两个数据集的ASR。 释义提供了适度的防御,而没有任何防御措施的原始设置允许攻击获得最高的成功率。
LIAR的收敛性
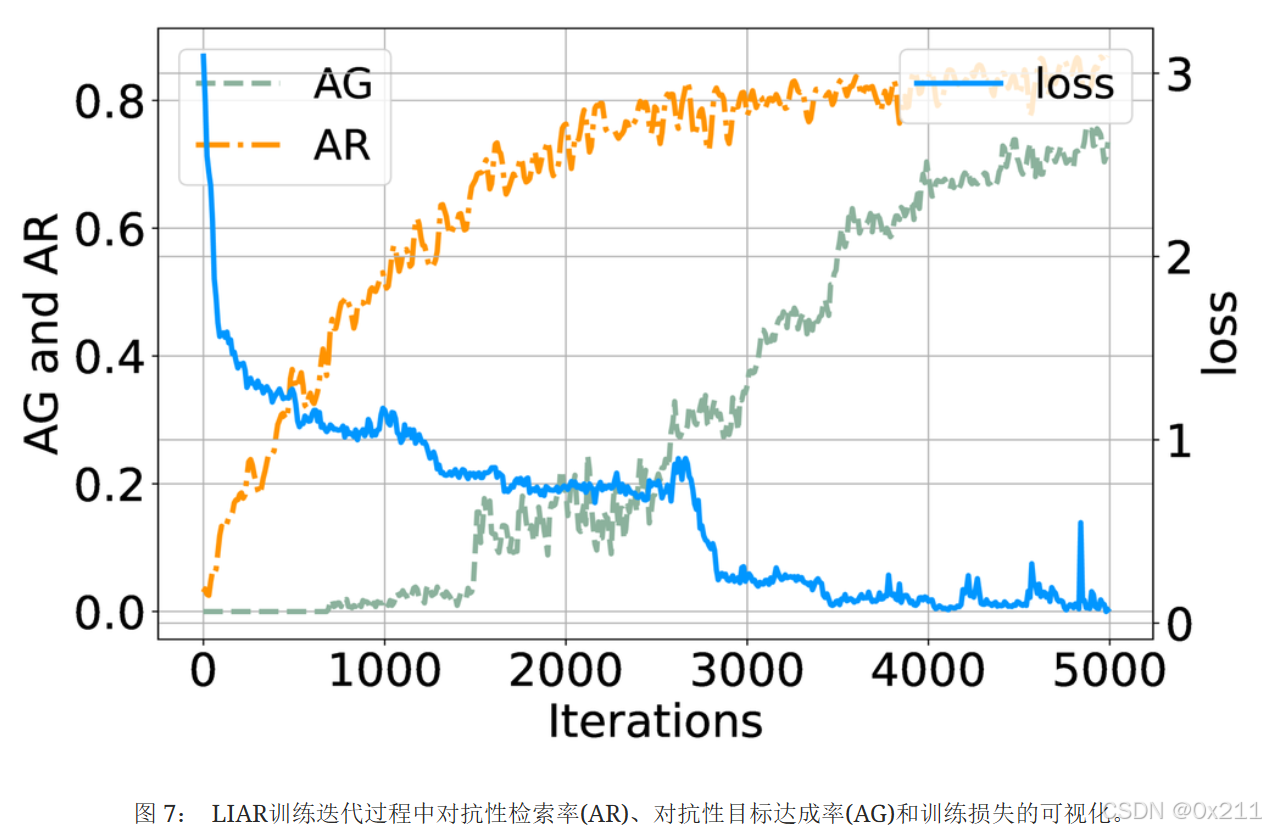
图 7 显示了LIAR在5000次迭代中的收敛情况,跟踪了对抗性检索率(AR)、对抗性目标达成率(AG)和训练损失。 对抗样本检索的优化速度很快,AR 在前 1000 次迭代中迅速增加,最终稳定在 0.8。 AG 上升较为平缓,达到 0.6,反映了影响输出的复杂性。 训练损失最初急剧下降,表明适应效果良好,之后趋于平缓并略有增加,这可能是由于微调工作造成的。 总的来说,与普通的AT相比,LIAR 达到了更平滑的收敛,在检索方面取得了更高的早期成功,并在目标达成方面实现了逐渐而稳定的改进。
示例
有害输出:

强制信息:

结论
实验范围仅限于特定的数据集和模型,可能无法完全捕捉现实世界 RAG 系统的多样性和复杂性。 未来工作应将这些评估扩展到更广泛的数据集、任务和模型,例如数学甚至多模态场景
灰盒攻击假设部分了解检索器,这可能并不总是反映攻击者信息较少的实际攻击场景
在受控环境中证明了我们攻击的有效性,但其现实世界的适用性和影响需要进一步探索。 现实世界的系统通常涉及其他复杂性,例如持续更新和动态内容更改,而这些在我们的静态评估框架中并未考虑。 未来工作应侧重于开发能够应对这些动态变化的自适应攻击策略。
方法主要针对基于文本的 RAG 系统,其对多模态 RAG 系统(将文本与图像或音频等其他数据形式集成)的适用性仍未探索。 将我们的方法扩展到多模态上下文将是未来研究的一个重要领域。
工作强调了需要针对对抗性攻击的强大防御机制。 未来研究应旨在开发和评估更有效的防御策略,包括对抗性训练和异常检测技术,以增强 RAG 模型对这些威胁的抵御能力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)