DeepSeek系列
PaperGithubPaperGithub
https://chat.deepseek.com/sign_in
LLM
deepseek-llm
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
github
https://zhuanlan.zhihu.com/p/21219405503
https://zhuanlan.zhihu.com/p/680557770
预训练
数据
去重
采用了一种激进的去重策略,扩大了去重的范围。对整个Common Crawl语料库进行去重与在单个转储中进行去重相比,可以移除更多的重复实例。表1说明,在91个转储中进行去重可以消除比单个转储方法多四倍的文档。
过滤
专注于制定用于文档质量评估的稳健标准。涉及结合语言和语义评估的详细分析
合成
调整方法以解决数据不平衡问题,侧重于增加代表性不足领域的数据。
分词器
- 分词器采用基于Huggingface团队的tokenizers库的BBPE算法。用于防止来自不同字符类别的标记的合并,如新行、标点符号和中文-日语-韩语(CJK)符号,类似于GPT-2。将数字拆分为单个数字。
- 将词汇表中的传统标记数量设置为100000。分词器在大约24GB的多语言语料库上进行训练,我们在最终词汇表中增加了15个特殊标记,使总大小达到100015。
- 为了确保训练期间的计算效率并为将来可能需要的任何其他特殊标记预留空间,将模型词汇表的大小配置为102400用于训练。
模型结构
- 使用Pre-Norm结构与RMSNorm函数及SwiGLU作为激活函数,构建高效稳定的模型架构。
- 在宏观设计方面,DeepSeek LLM略有不同。DeepSeek LLM 7B是一个30层的网络,DeepSeek LLM 67B有95层。这些层调整在保持与其他开源模型参数一致的同时,也有助于优化训练和推理的模型管道划。
- 引入旋转位置编码(Rotary Embedding)和分组查询注意力机制(Grouped-Query Attention, GQA),以提高模型的表达能力和泛化能力。
超参数
采用多步学习率调度器代替传统的余弦调度器,以支持持续训练,并确保模型在不同规模的训练中保持良好性能。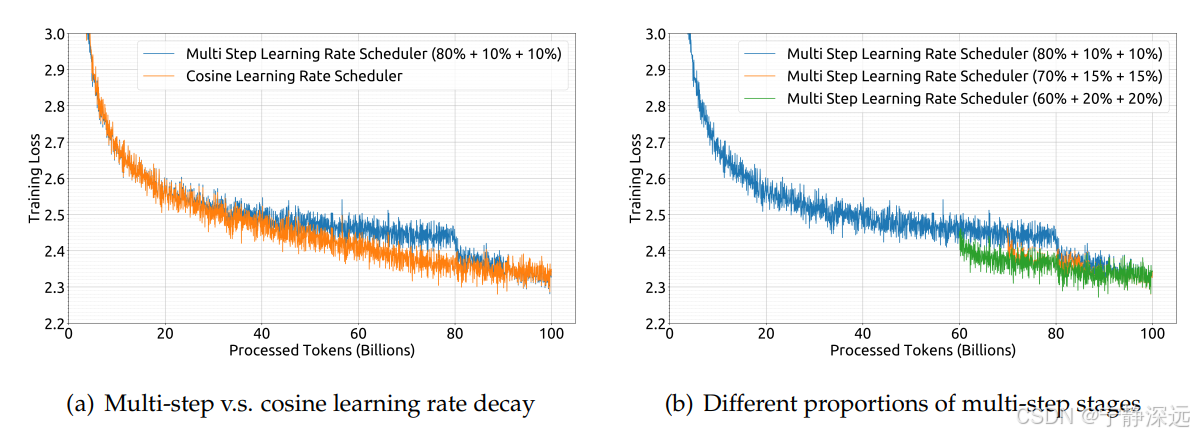
1、多步学习率与cosine最终结果一致
2、第一阶段的学习有利与持续学习,不同比率的学习,可以提供性能,为了平衡持续学习和性能,作者选择80%+10%+10%
基础设施
- 利用HAI-LLM框架进行高效轻量级训练,采用flash attention技术提高硬件利用率,确保训练过程的稳定性和高效性。
- 一些层操作被融合在一起以加速训练,包括LayerNorm、GEMM(只要可能)和Adam更新。
- 为了提高模型训练的稳定性,使用bf16精度训练模型,但在计算梯度时使用fp32精度。还执行就地交叉熵以减少GPU内存消耗,即:在交叉熵CUDA内核中实时将bf16 logits转换为fp32精度(而不是在HBM中转换),计算相应的bf16梯度,并用其梯度覆盖logits。
deepseek-moe
deepseek-v2
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
github
deepseek-v3
DeepSeek-V3 Technical Report
github
https://zhuanlan.zhihu.com/p/16730036197
deepseek-r1
github
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
贡献
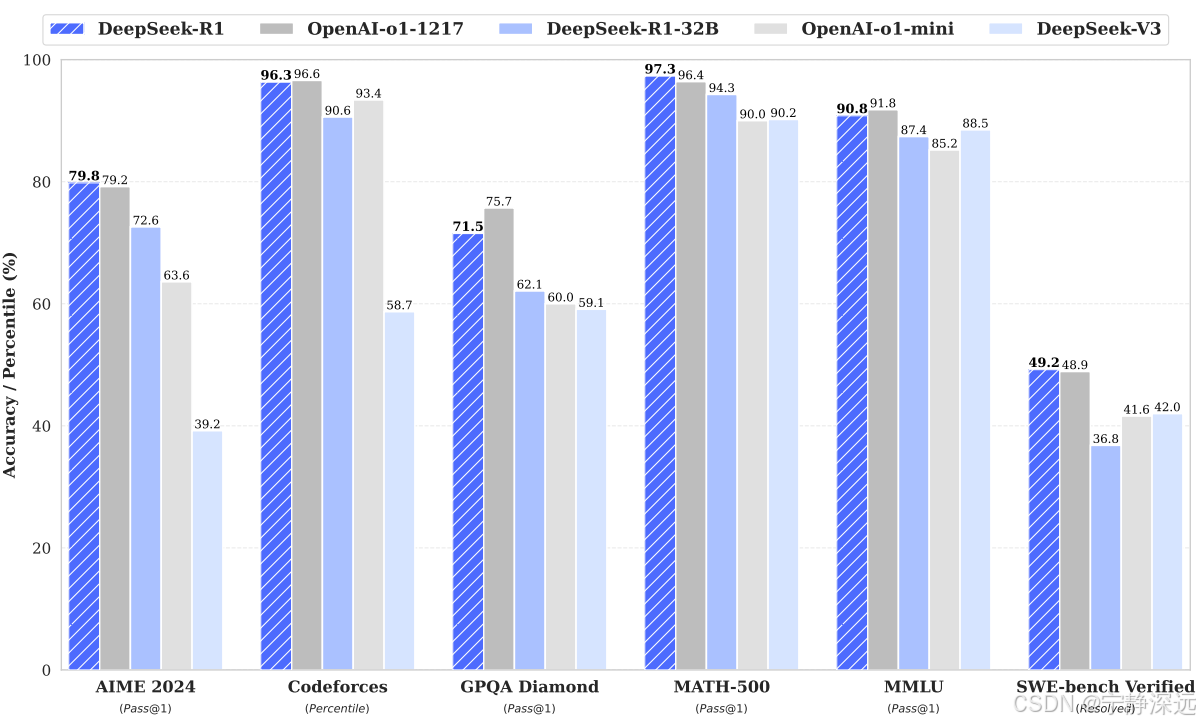
- DeepSeek-R1-Zero : 不用SFT直接进行RL,也能取得不错的效果。
- DeepSeek-R1 : 加入少量(数千量级)CoT数据进行SFT作为冷启动,然后再进行RL,可以取得更优的性能。同时回答更符合人类偏好。
- 用DeepSeek-R1的样例去蒸馏小模型,能取得惊人的效果。
DeepSeek-R1-Zero
- 直接从DeepSeek-V3-Base,用DeepSeek独家定制的GRPO(DeepSeek-Math中提出)
- RM方面,考虑到是推理任务,没有训练常规的稠密奖励模型,而是采用了两种奖励方式结合:
1、 准确性奖励:对于数学问题,直接匹配标准答案;对于代码问题,基于编译执行单测去验证。
2、格式奖励:看CoT过程是否以标准<think> </think>包裹。 - 效果:
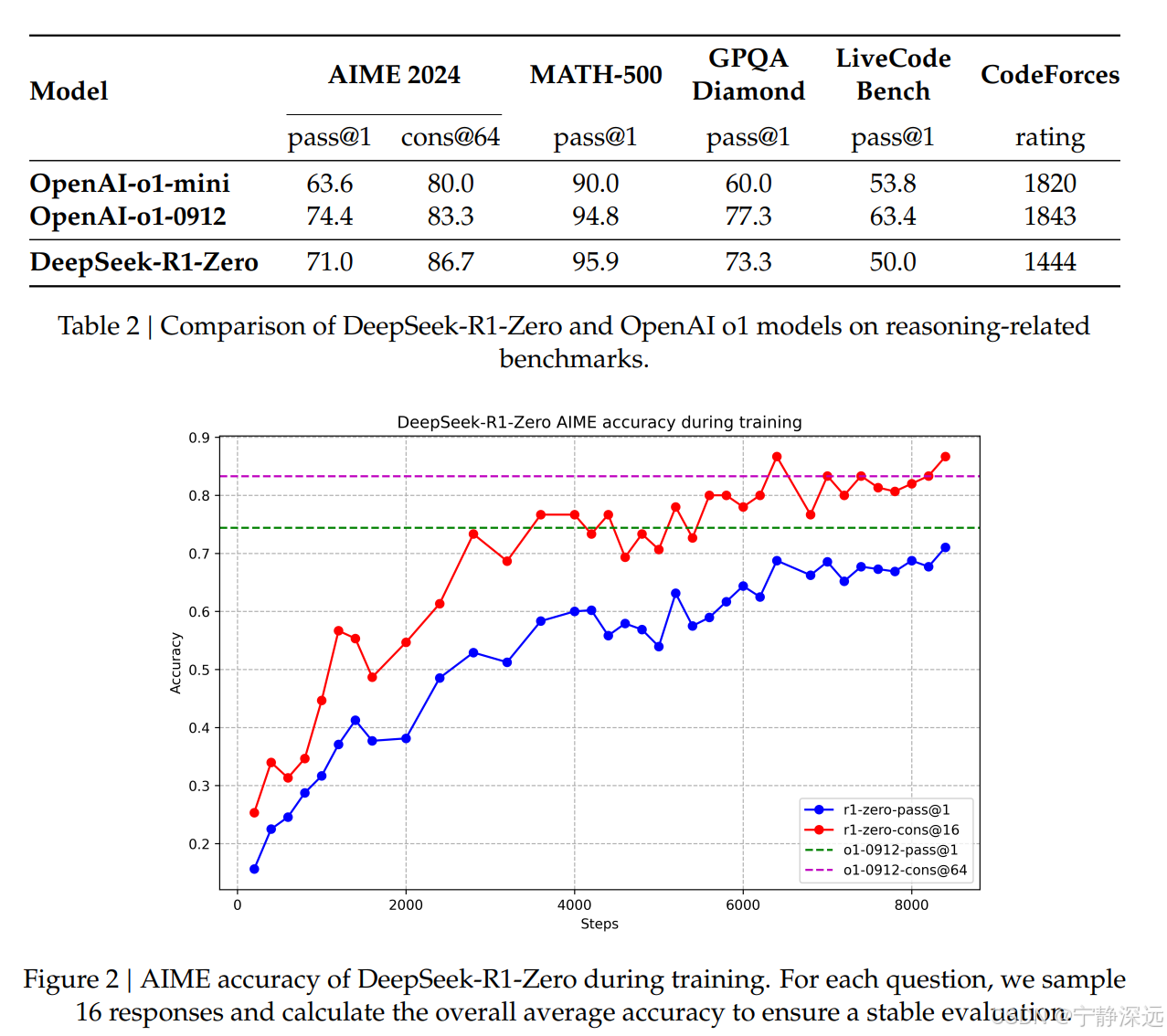
- 观察到了明显的“进化”现象,随着训练步数的增加,输出平均长度也在增加。意味着LLM似乎自己已经潜移默化学会了进行更多的思考和推理,达到更好的效果。
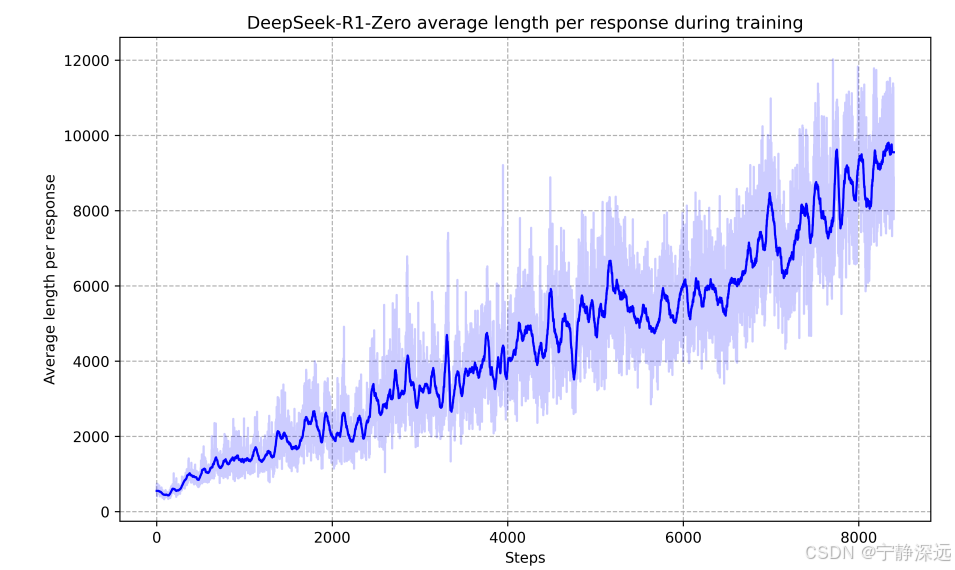
- 现了自主的“Aha Moment”情况,突然就能开始反思

VLM
deepseek-vl
解决的问题
- 【视觉语言模型预训练】许多开源解决方案将大量计算资源分配给指令微调阶段,应当重视利用广泛视觉-语言数据进行综合性预训练。
- 【指令微调数据】在指令微调期间,常见的做法是合并多种学术数据集。尽管这种做法可能在基准测试中取得良好结果,但往往未能提供真实的现实世界使用体验。
- 【输入分辨率低】就模型架构而言,先前的工作大多将ViT(通常是与文本对齐的)适配到预训练的语言模型上。然而,这些模型大多在相对较低的分辨率下操作,例如336x336或448x448。复杂现实场景(如OCR或微小物体辨识)的细微之处需要高分辨率处理能力。
- 【模态训练语言能力下降】长时间的多模态训练后,语言能力往往会有所下降。鉴于我们的目标是培养一个在两种模态上都拥有强大能力的通才,因此在开发新的模态能力时,应当有一个能良好保留语言能力的训练策略。
方法
数据准备
预训练数据
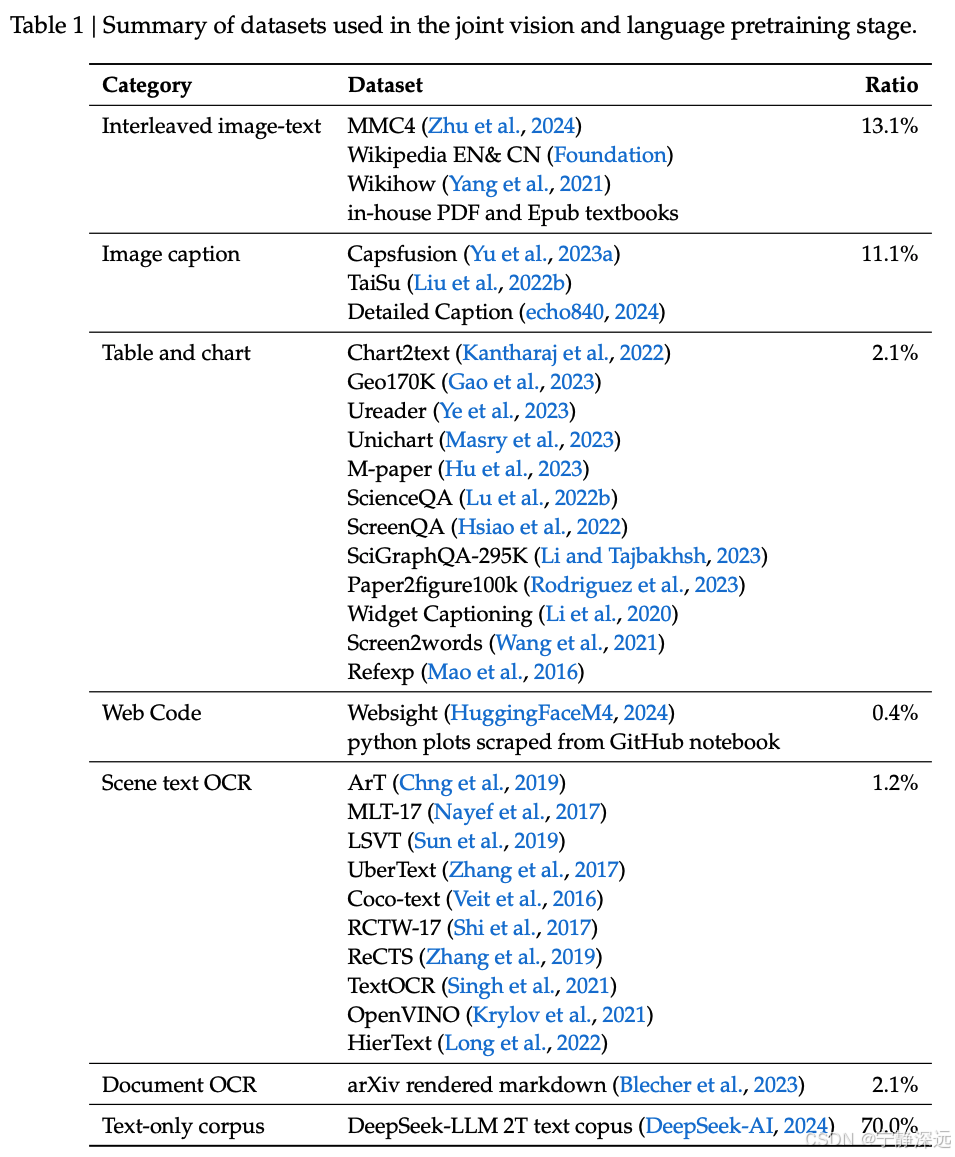
- 交错的图像文本数据:使模型能够更好地具备对多模态输入的上下文学习能力,我们利用了三个公共数据集:MMC4(Zhu 等,2024)、Wiki(Burns 等,2023)、Wikihow(Yang 等,2021)和Epub textbooks。
- 图像标题:数据来自三个高质量的图像文本配对数据集:Capsfusion(Yu 等,2023a)、TaiSu(Liu 等,2022b)和Detailed Caption(echo840,2024)。
- 表格和图表数据:使模型能够学习一般表格和图表图像理解的能力。它包括各种公共数据来源,包括 Chart2text(Kantharaj 等,2022)、Geo170K(Gao 等,2023)、Unichart(Masry 等,2023)、Ureader(Ye 等,2023)、M-paper(Hu 等,2023)、ScienceQA(Lu 等,2022b)、ScreenQA(Hsiao 等,2022)、SciGraphQA-295K(Li 和 Tajbakhsh,2023)、Paper2figure100k(Rodriguez 等,2023)、Widget 标题(Li 等,2020)、Screen2words(Wang 等,2021)和 Refexp(Mao 等,2016)。
- 网络代码数据:使模型具备从图形界面或视觉图重建代码的能力。利用 Websight(HuggingFaceM4,2024)进行 UI 反向渲染,我们采用了与 MATCHA(Liu 等,2022a)用于视觉图反向渲染类似的策略。这涉及处理来自 Stack 数据集(Kocetkov 等,2023)的大约 146 万个 Jupyter 笔记本。通过提取这些笔记本并整理所有图表以及它们相应的先前代码段,我们成功地策划了一个包含 200 万对图像和代码的集合。为了提高数据质量,我们过滤了 110 万个实例,每个实例都包括一个单一的图像和至少 5 行代码,构成我们的主要训练数据集。
- 文档光学字符识别(OCR)数据:有助于在文档级别识别光学字符,即使在具有挑战性的现实世界场景中也是如此。据我们所知,目前没有公开可用的涵盖英语和中文文档的大规模数据集。尽管存在公开可用的小规模数据集 Latex-OCR(Blecher,2024),但我们还构建了一个全面的英文和中文文档 OCR 数据集。它由两部分组成:1):arXiv 文章:我们从 140 万篇 arXiv 文章中收集源代码并编译 PDF。利用 Nougat(Blecher 等,2023)的预处理工具,我们将这些文章呈现为成对的图像和文本;2):电子书和教育材料:我们从 Anna 的档案(Anna 的档案,2024)清理了 86 万本英文和 18 万本中文电子书,以及数百万个 K-12 教育考试问题。随后,我们采用 HTML 渲染工具(Kulkarni 和 Truelsen)将这些具有不同模板的 HTML 文件转换为成对的图像和文本格式。
- 场景文本 OCR 数据:增强了模型从集成到环境中的图像中识别和提取文本的能力。数据集由多个公共数据集组成,包括 ArT(Chng 等,2019)、MLT-17(Nayef 等,2017)、LSVT(Sun 等,2019)、UberText(Zhang 等,2017)、Coco-text(Veit 等,2016)、RCTW-17(Shi 等,2017)、ReCTS(Zhang 等,2019)、TextOCR(Singh 等,2021)、OpenVINO(Krylov 等,2021)和 HierText(Long 等,2022)。
- 文本语料库:用于保持以语言为中心的任务的熟练程度。在本研究中,我们使用与 DeepSeek-LLM(DeepSeek-AI,2024)相同的文本语料库。
监督训练数据
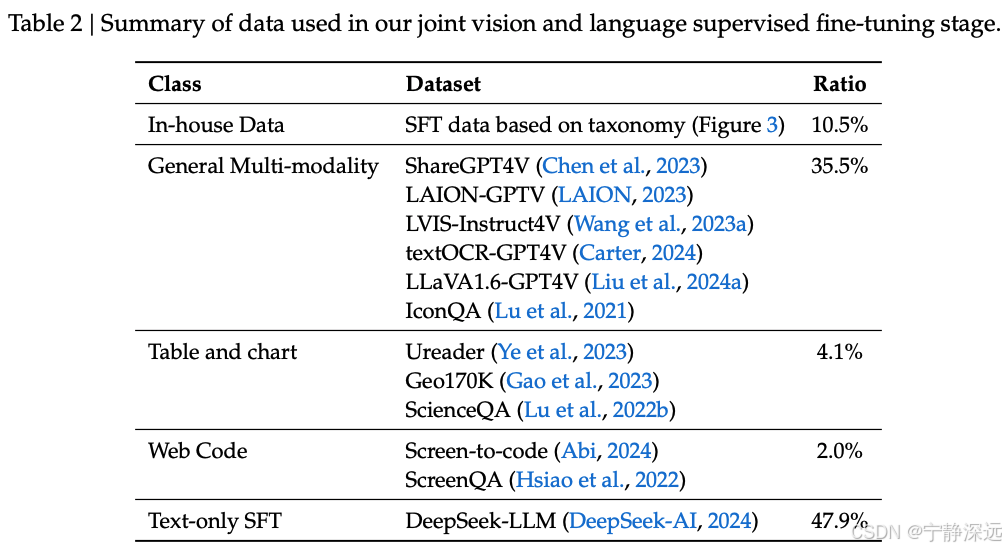
- 著名的开源共享 gpt4v 数据集:如 ShareGPT4V(Chen 等,2023)、LAION-GPTV(LAION,2023)、LVIS-Instruct4V(Wang 等,2023a)、textOCR-GPT4V(Carter,2024)、LLaVA1.6-GPT4V(Liu 等,2024a)和 IconQA(Lu 等,2021)。
- 预训练数据集中提取的部分表格和图表数据:例如 Ureader(Ye 等,2023)、ScreenQA(Hsiao 等,2022)、Geo170K(Gao 等,2023)和 ScienceQA(Lu 等,2022b)
- Screen-to-code(Abi,2024)任务中获得的 UI 代码数据集。
- 各种在线来源收集 GPT-4V 和 Gemini 的各种真实测试用例,测试用例被仔细分析并组织成一个全面的分类法,包括多个类别,如识别、转换、分析、推理、评估和安全。结构化的分类法作为选择每个测试图像的代表性提示的指南,确保我们的指令调整数据集既实用又与现实世界的应用相关。此外,该分类法也用于构建一个平衡和全面的评估数据集,这使我们能够有效地评估模型在不同任务和类别中的性能。通过遵循这种系统方法,我们确保我们的内部多模态 SFT 数据涵盖的类别与分类法良好对齐,并代表现实世界的使用场景。
- 文本语料库:将 DeepSeek-LLM(DeepSeek-AI,2024)中使用的仅文本 SFT 数据作为我们联合视觉和语言 SFT 数据的一部分。
类别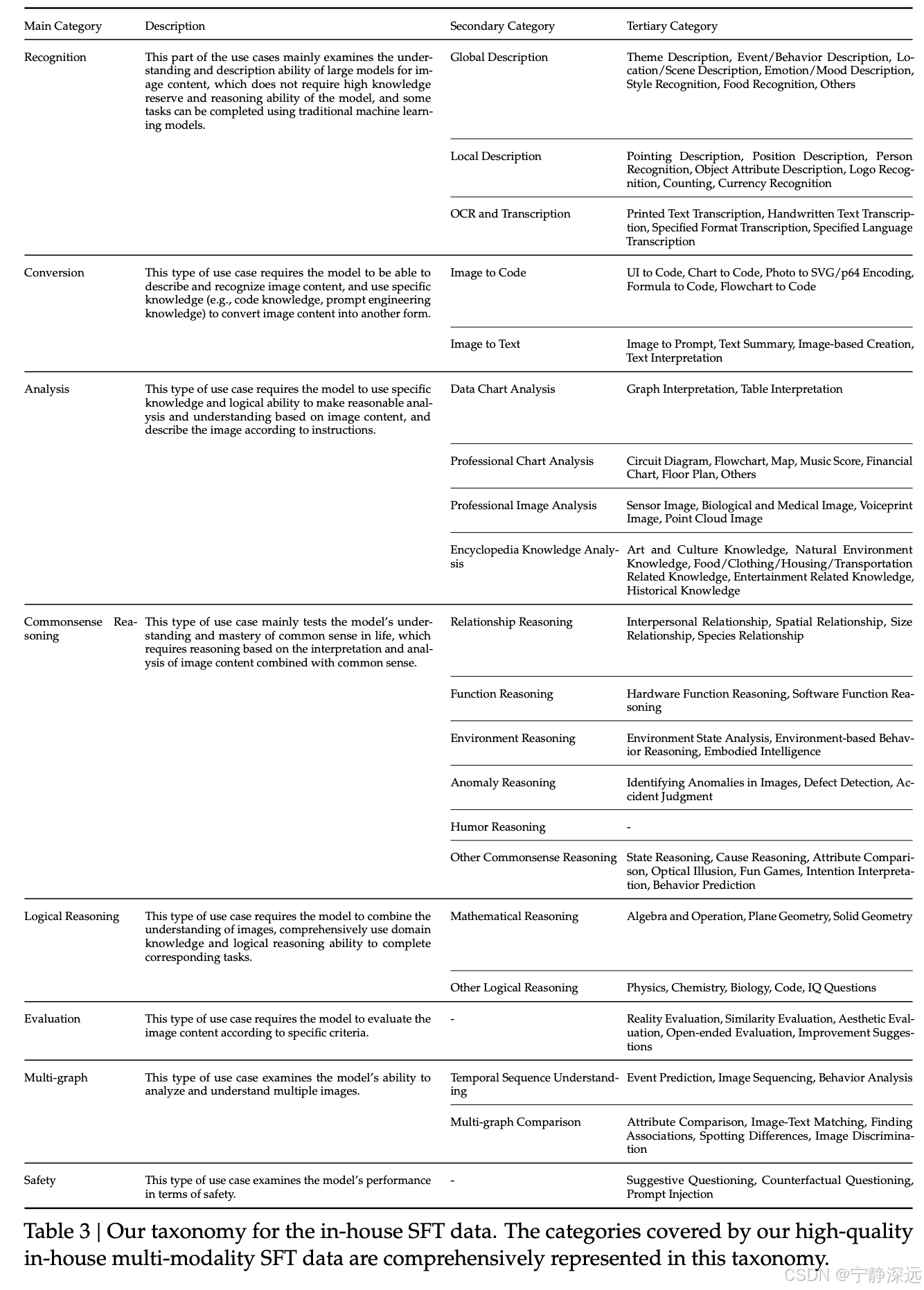
模型结构
混合视觉编码器
- SAM-B + SigLIP-L 编码器
- SAM-B(Kirillov 等,2023)的仅视觉编码器,这是一个预训练的 ViTDet(Li 等,2022)图像编码器来处理低级特征,它接受高分辨率 1024 x 1024 图像输入
- 保留了低分辨率 384 x 384 图像输入的 SigLIP-L 视觉编码器
视觉-语言适配器
- 两层混合多层感知机来连接视觉编码器和 LLM
语言模型
- 语言模型建立在 DeepSeek LLM(DeepSeek-AI,2024)之上,其微观设计在很大程度上遵循了 LLaMA(Touvron 等,2023a,b)的设计,
- 采用了带有 RMSNorm(Zhang 和 Sennrich,2019)功能的预规范结构,
- 使用 SwiGLU(Shazeer,2020)作为前馈网络(FFN)的激活函数。
- 结合了旋转嵌入(Su 等,2024)进行位置编码,
- 使用与 DeepSeek-LLM 相同的分词器。
训练方法
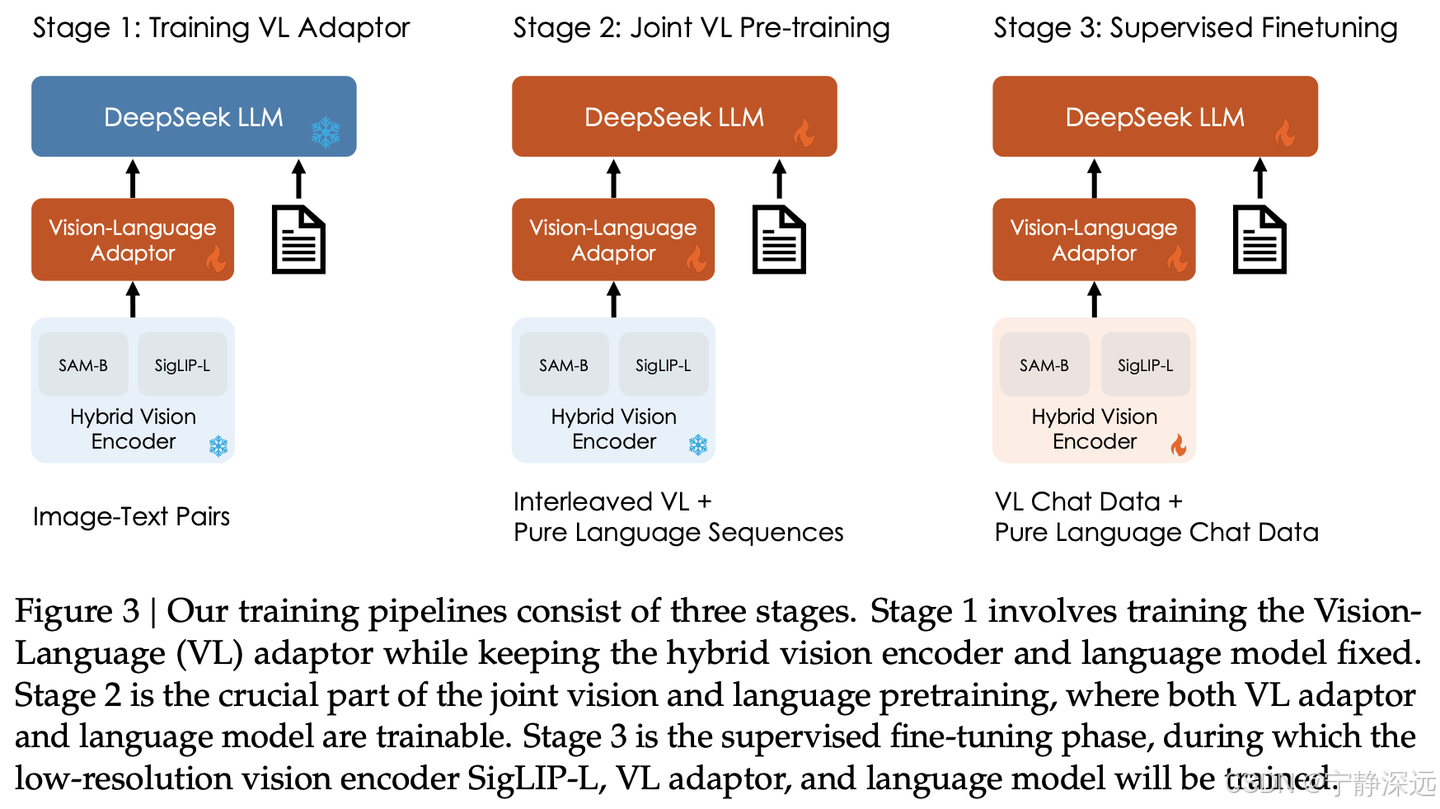
第一阶段:训练视觉语言适配器
- 目标是在嵌入空间中建立视觉和语言元素之间的概念链接,从而促进大型语言模型(LLM)对图像中所描绘实体的全面理解。
- 视觉编码器和 LLM 都保持冻结,而仅允许视觉语言适配器内的可训练参数。
- ShareGPT4V 获得的 125 万个图像-文本配对的标题,以及 250 万个文档 OCR 渲染对来训练 VL 适配器。
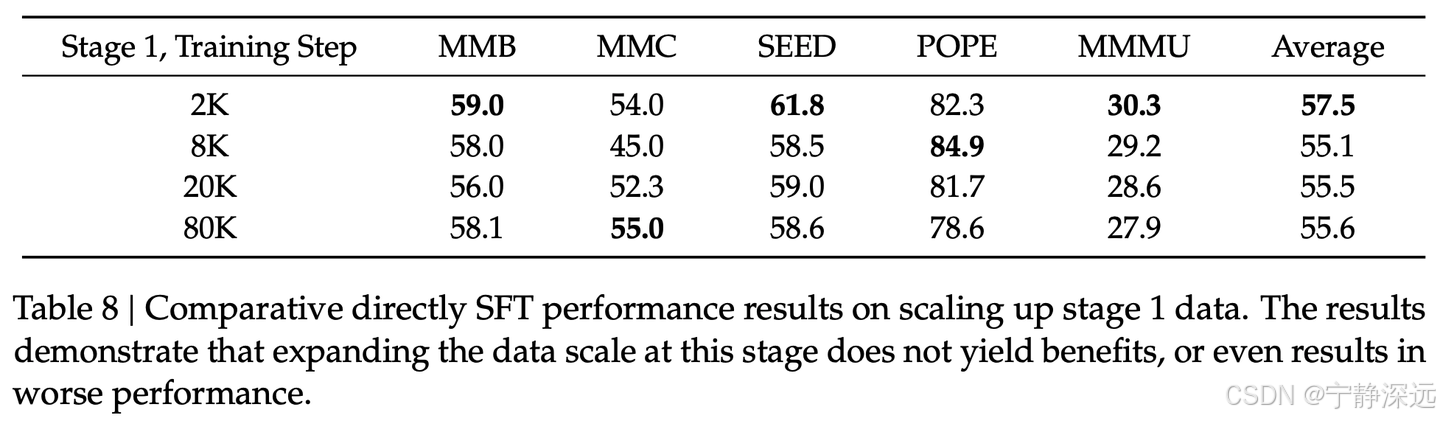
- tricks:在这个阶段扩大数据规模并没有带来好处,甚至可能导致性能较差。
阶段 2:联合视觉-语言预训练
问题1: LLM语言能力下降
- 保持视觉编码器冻结,并优化语言模型和 VL 适配器。
- 直接用多模态数据训练 LLM会导致语言能力下降。原因:分布存在差异,多模态与语言存在竞争
- 结论:1)融合语言数据显著缓解了语言能力的下降,显示出模型语言性能的大幅提高。2)语言数据的包含并不会导致多模态性能的显著损失。3)语言与多模态数据的训练比例大约为 7:3 的最终模型
问题2: 小模型拓展问题
- 现象:阶段 2 的训练阶段, 1.3B 模型的生成指标的相当大的波动,使得有效监督训练过程具有挑战性。
- 原因:1.3B 模型的容量有限,并且训练数据集中没有 SFT 数据,这两者都阻碍了模型准确遵循指令的能力。
- 方法:1)采用多选 PPL 方法来监测模型的进展。这不仅涉及将提示和图像输入网络,还包括与问题相关的所有答案。计算每个答案位置(例如,A、B、C、D)的 PPL,并选择模型认为正确的选项作为最终答案。2)在训练数据集中以最小比例引入 SFT 数据
阶段 3:有监督的微调
- 目标:使用基于指令的微调对预训练的 DeepSeek-VL 模型进行微调,以增强其遵循指令和进行对话的能力,最终创建出交互式的 DeepSeek-VL-Chat 模型。
- 使用表 2 中所示的视觉语言 SFT 数据优化语言模型、VL 适配器和混合视觉编码器。
- 由于GPU 内存有限,SAM-B 保持冻结。我们只监督答案和特殊令牌,并屏蔽系统和用户提示。
- 利用了多模态数据和 DeepSeek-LLM 中使用的纯文本对话数据的混合。这种方法确保了模型在各种对话场景中的多功能性。
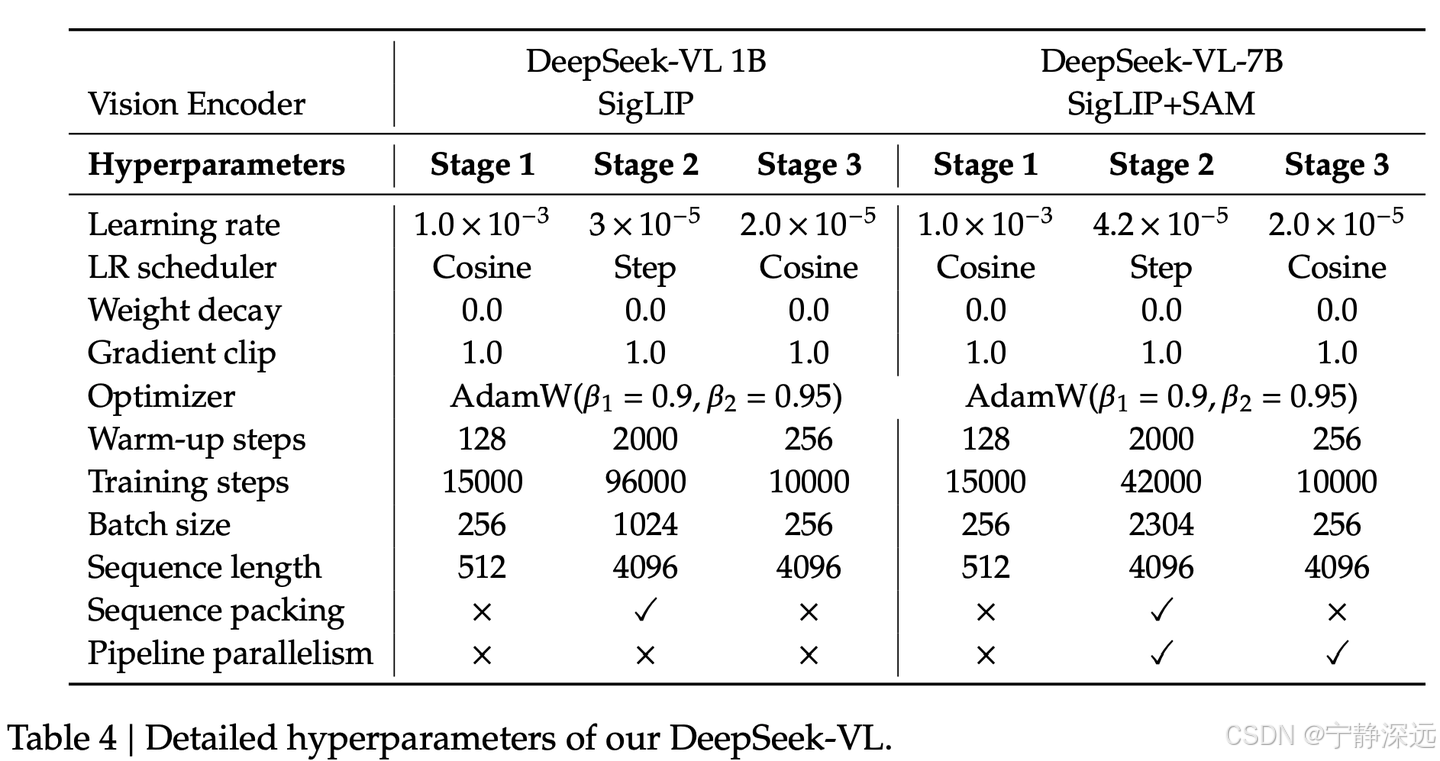
超参
验证
公共多模态基准测试评估
- 多模态综合理解数据集:MMMU(Yue 等,2023)、CMMMU(Zhang 等,2024)、MMBench(Liu 等,2023a)、MMBench-CN(Liu 等,2023a)、SeedBench(Li 等,2023a)和 MMV(Yu 等,2023b)。我们在 MMB/MMC-dev 上与竞争对手进行比较,因为当前的官方测试下载链接不再活跃。
- 图表/表格理解数据集:OCRBench(Liu 等,2023b);
- 幻觉数据集:POPE(Li 等,2023b);
- 科学问题数据集:ScienceQA(Lu 等,2022a)和 MathVista(Lu 等,2023)。
采用基于生成的评估和贪婪解码。这里的基于生成的评估是指让模型从生成的文本中生成自由文本和解析结果。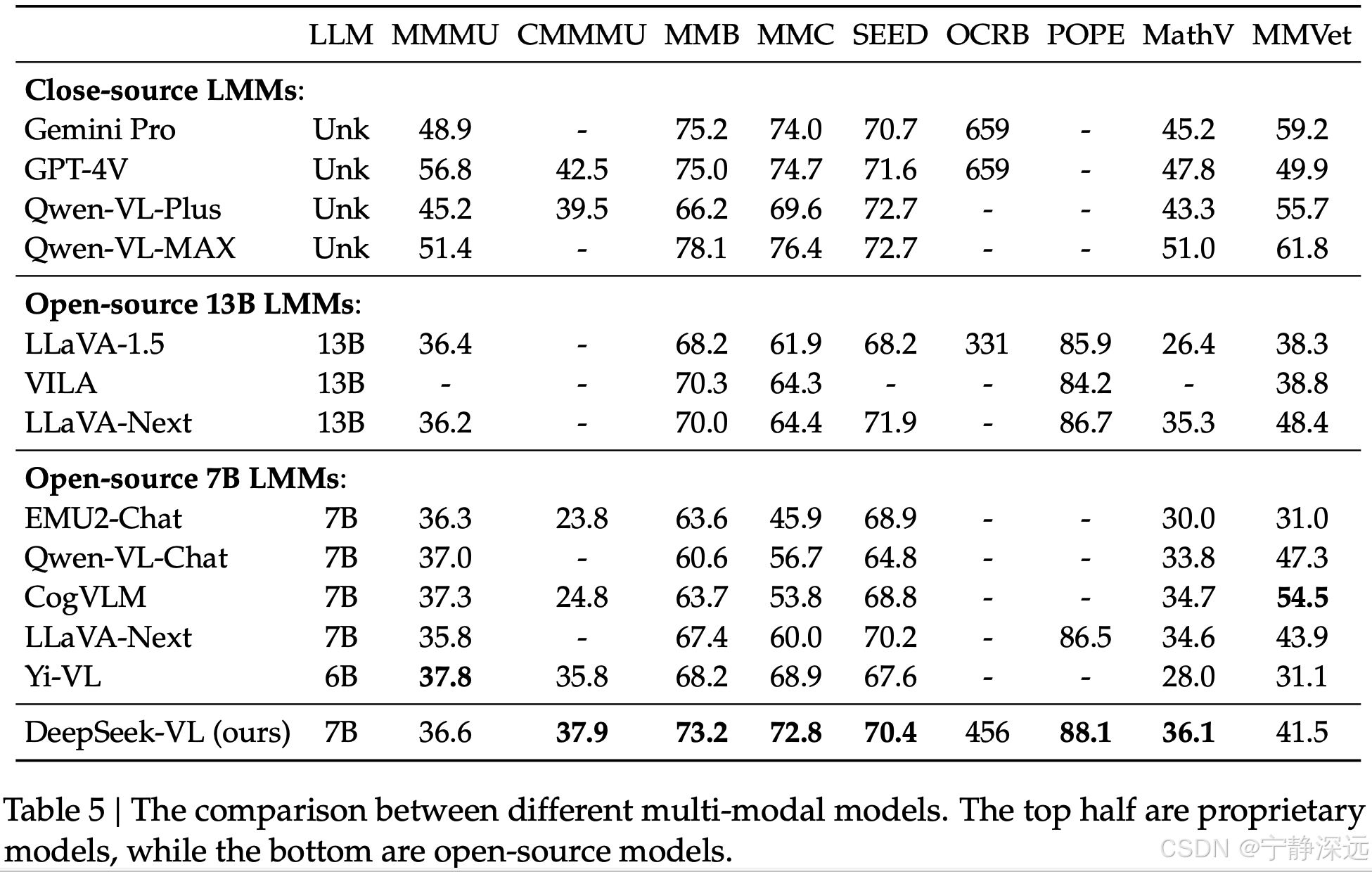
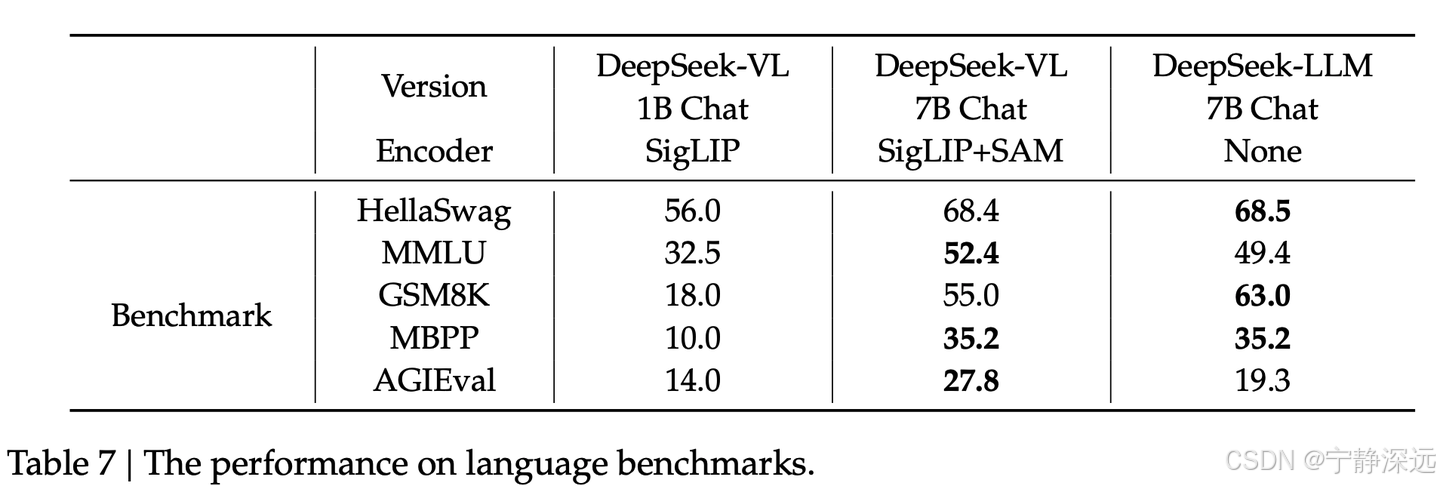
公共语言基准测试评估
-
多主题多项选择数据集,包括 MMLU(Hendrycks 等,2020)。
-
语言理解和推理数据集,包括 HellaSwag(Zellers 等,2019)。
-
语言建模数据集,包括 Pile(Gao 等,2020)。
-
数学数据集,包括 GSM8K(Cobbe 等,2021)。
-
代码数据集,包括 MBPP(Austin 等,2021)。
-
标准化考试,包括 AGIEval(Zhong 等,2023)。
评估方式:
-
从几个选项中选择答案的数据集应用基于困惑度的评估。这些数据集包括 HellaSwag 和 MMLU。基于困惑度的评估这里是指计算每个选项的困惑度,并选择最低的一个作为模型预测。基于困惑度的评估有助于区分模型预测之间的细微概率差异,并避免精确匹配风格评估的不连续性。
-
对 GSM8K 和 AGIEval 应用基于生成的评估和贪婪解码
人工评估
- 独立构建了一个数据集用于手动评估。该数据集包括 100 个问题,分为七个类别,每个类别都包含特定的任务。
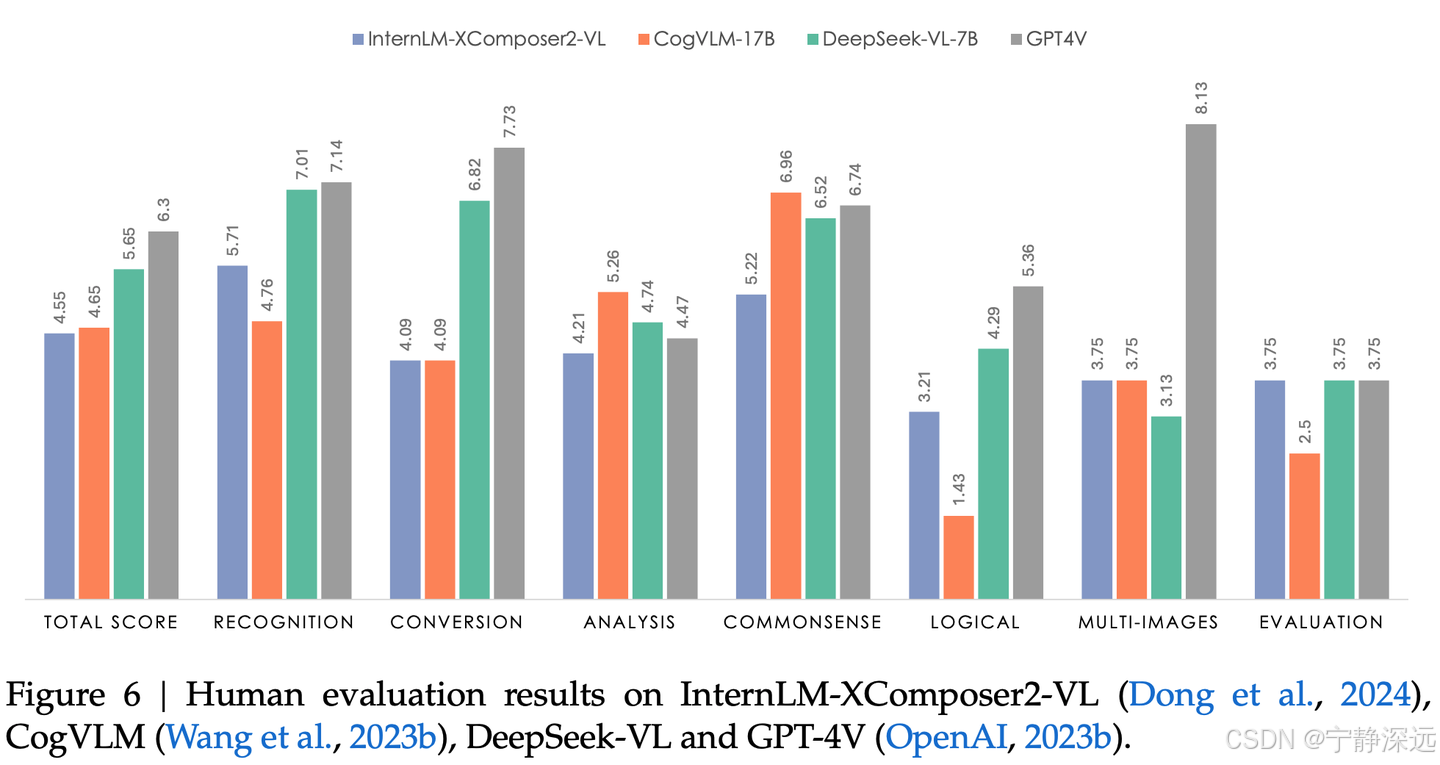
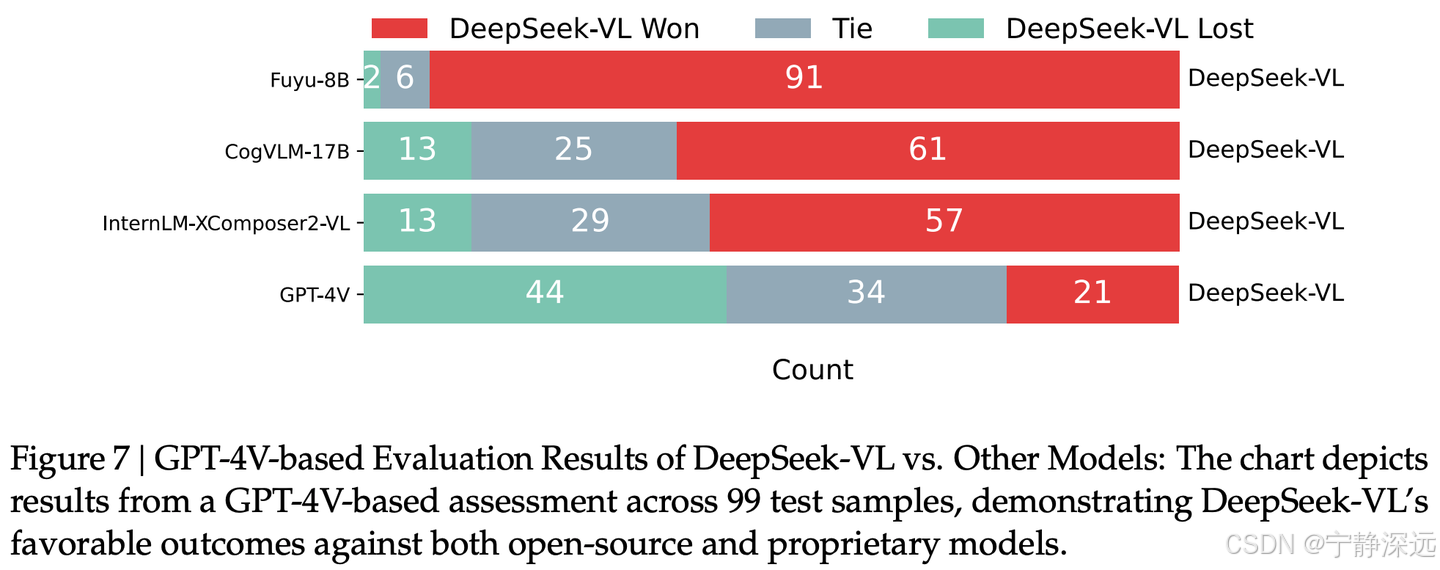
- 使用 GPT-4V 进行了一项比较评估,以评估 DeepSeek-VL 与其他模型在一组为人工评估设计的 99 个测试样本上的性能
- 向 GPT-4V 展示问题以及来自两个不同模型的答案,并要求 GPT-4V 确定哪个更好或宣布平局。
消融实验
- 第一阶段监督微调训练,增加数据并不能提高性能
- 不同阶段的训练对模型的提升也不一样,且都有提升效果
- 不同模态成组训练,如果语言与图像模态在同一组batch,会因为语言等待图像而效率更低,因此,采用语言和图像分为不同的组batch,提升了20%的效率
- 语料数据与视觉语言数据融合训练时,采用100%的语言数据训练模型,逐步降低比例,增加视觉语言数据,直到70%。增加模型训练的稳定性。
deepseek-vl2
网络结构
-
Vision Encoder(视觉编码器)
-
Vision-Language Adaptor(视觉-语言适配器)
-
MoE-Based Language Model(基于 MoE 的语言模型)
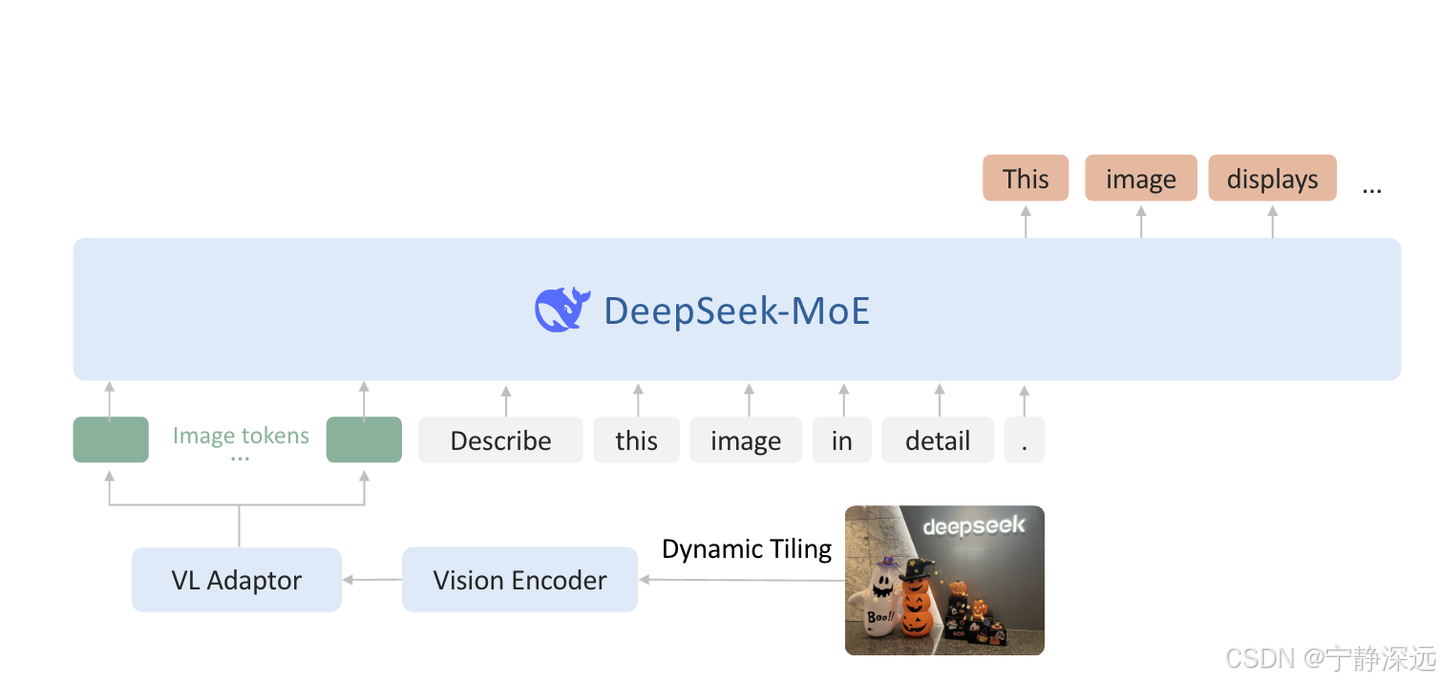
动态拼接策略
- 问题:最初的 DeepSeek-VL 采用了一种混合视觉编码器,它结合了 SigLIP(用于以 384 × 384 分辨率提取粗粒度特征)和 SAM-B(用于以 1024 × 1024 分辨率提取细粒度特征)。 虽然这种融合方法生成了适用于各种视觉语言任务的丰富视觉表示,但它受到固定 1024 × 1024 分辨率约束的限制。 对于处理具有更大分辨率和极端纵横比的图像(例如在 InfographicVQA、密集 OCR 和详细视觉定位任务中发现的图像)来说,这种限制尤其具有挑战性。
- V2采用的方法:
1) 首先,根据输入图像的分辨率与长宽比,从多个候选分辨率(基于 384 的倍数)中选择最优分辨率方案,将图像缩放并填充到接近该候选分辨率的大小。
2)将调整后的高分辨率图像分割成多个 384×384 的小块(local tiles),并额外生成一个 384×384 的全局缩略图(global tile)。
3)使用预训练的 SigLIP-SO400M-384 编码器对 (1 + m×n) 个 tile 进行特征提取,然后通过 vision-language adaptor 将这些特征投影到 LLM 输入空间。
视觉-语言适配器
在处理完视觉图块后,DeepSeek-VL2 执行 2 × 2 像素混洗操作,将每个图块的视觉标记从 27 × 27 压缩为 14 × 14 = 196 个标记。 然后在处理 (1 + × ) 个图块时引入三个特殊标记。 对于全局缩略图图块 (14 × 14),DeepSeek-VL2 在每行的末尾添加 14 个 <tile_newline> 标记,总共得到 14 × 15 = 210 个标记。 对于以 ( · 14, · 14) 形状的二维网格排列的 × 个局部图块,DeepSeek-VL2 在最后一列的末尾追加 · 14 个 <tile_newline> 标记,以指示所有局部图块一行的结束。 此外,在全局缩略图图块和局部图块之间插入一个 <view_separator> 标记。 完整的视觉序列包含 210 + 1 + · 14 × ( · 14 + 1) 个视觉标记,随后使用两层多层感知器 (MLP) 将它们投影到语言模型的嵌入空间。 图 3 显示了 DeepSeek-VL2 动态拼接策略的直观说明。
MoE语言模型与MLA机制
- DeepSeek-VL2 在语言模型部分采用了 DeepSeekMoE 框架,将专家稀疏化(Mixture-of-Experts)引入,使得在推理过程中只激活部分专家网络,从而降低计算开销。
- 模型引入了 Multi-head Latent Attention (MLA) 机制,在推理时将 Key-Value 缓存压缩成潜向量(latent vector),提升推理效率和吞吐量。
数据准备与训练
DeepSeek-VL2 的训练数据分为三类阶段性数据:
VL Alignment Data
- 用于初始将预训练的视觉编码器与 LLM 对齐。这一步仅训练视觉编码器和适配器,对 LLM 参数保持冻结。
- 所用数据包括 ShareGPT4V 等 120 万条图文对话和描述数据。
VL Pretraining Data(预训练数据)
- 完成对所有参数(视觉编码器、适配器、LLM)解冻训练。
- DeepSeek-VL2 使用大规模数据约 800B 视觉-文本 tokens(约70%多模态+30%纯文本),后者直接来自其基本 LLM 预训练语料库。 VL 数据又可以细分为几类:
1)交错图像-文本数据: 包括 WIT、WikiHow 和 OBELICS 的 30% 随机样本,以及从 Wanjuan 中提取的中文内容。 DeepSeek-VL2 还开发了一个内部集合来扩展对一般现实世界知识的覆盖范围。
2)图像描述数据: DeepSeek-VL2 利用了各种开源数据集,并开发了一个综合图像描述管道,该管道考虑了 OCR 提示、元信息(例如位置、相机设置)和相关的原始描述作为提示,以提高描述质量。
3)光学字符识别数据: 使用 LaTeX OCR 和 12M RenderedText 等开源数据集,以及一个涵盖各种文档类型的广泛内部 OCR 数据集。
4)视觉问答数据: 包括一般 VQA 数据、表格、图表和文档理解数据、Web-to-code 和 plot-to-Python 生成数据,以及带有视觉提示的问答数据。
5)视觉定位数据: 使用来自的数据构建,并创建了负样本,其中查询对象故意从图像中缺失,以增强模型的鲁棒性。
6)基于视觉的对话数据: 使用来自的数据构建,其格式包含特殊标记和归一化的边界框坐标。
Supervised Fine-Tuning (SFT)数据
- 在预训练模型的基础上,通过高质量SFT数据对模型进行指令微调。以强化模型的对话能力、指令跟随、复杂多轮交互,以及加强OCR、表格/图表理解、数学推理、视觉定位和 grounded conversation 等任务能力。
- 数据:
1)通用视觉问答: DeepSeek-VL2 重新生成了公共视觉问答数据集的答案,并创建了一个内部中文问答数据集和一个额外的内部数据集,以补充现实世界和文化视觉知识。
2)OCR 和文档理解: DeepSeek-VL2 清理了现有的开源数据集,并从其内部数据中整理了一个多样化的文档页面子集,生成了针对文档理解的多轮对话问答对。
3)表格和图表理解: DeepSeek-VL2 重新生成了除 Cauldron 以外的所有公共数据集的答案,并展示了强大的图表理解能力。
4)推理、逻辑和数学: DeepSeek-VL2 使用更详细的推理过程增强了以推理为中心的数据集,并标准化了响应格式。
5)教科书和学术问题: DeepSeek-VL2 构建了一个内部数据集,重点关注其文档集中来自多个学科的大学级内容的教科书。
6)Web-to-code 和 plot-to-Python 生成: DeepSeek-VL2 扩展了预训练期间使用的内部 Web 代码和 Python 绘图代码数据集,并通过重新生成答案来提高开源数据集的质量。
7)视觉定位: DeepSeek-VL2 使用来自的数据开发其视觉定位数据集,并将查询短语翻译成中文,创建额外的负样本。 DeepSeek-VL2 还添加了上下文内视觉定位数据。
8)基于视觉的对话: DeepSeek-VL2 使用 来构建其基于视觉的对话数据,以进一步增强在预训练阶段建立的模型的能力。
9)纯文本数据集: 为了保持模型的语言能力,DeepSeek-VL2 在 SFT 阶段还使用了纯文本指令微调数据集
训练策略
训练分为三个阶段:
• 第1阶段:将Vision Encoder和VL Adaptor与冻结的LLM对齐。
• 第2阶段:全参数预训练,从而获得全面多模态理解与生成的基础能力。
• 第3阶段:SFT(有监督微调)阶段,在指令数据上精调提升对话、回答的质量和多样化表现。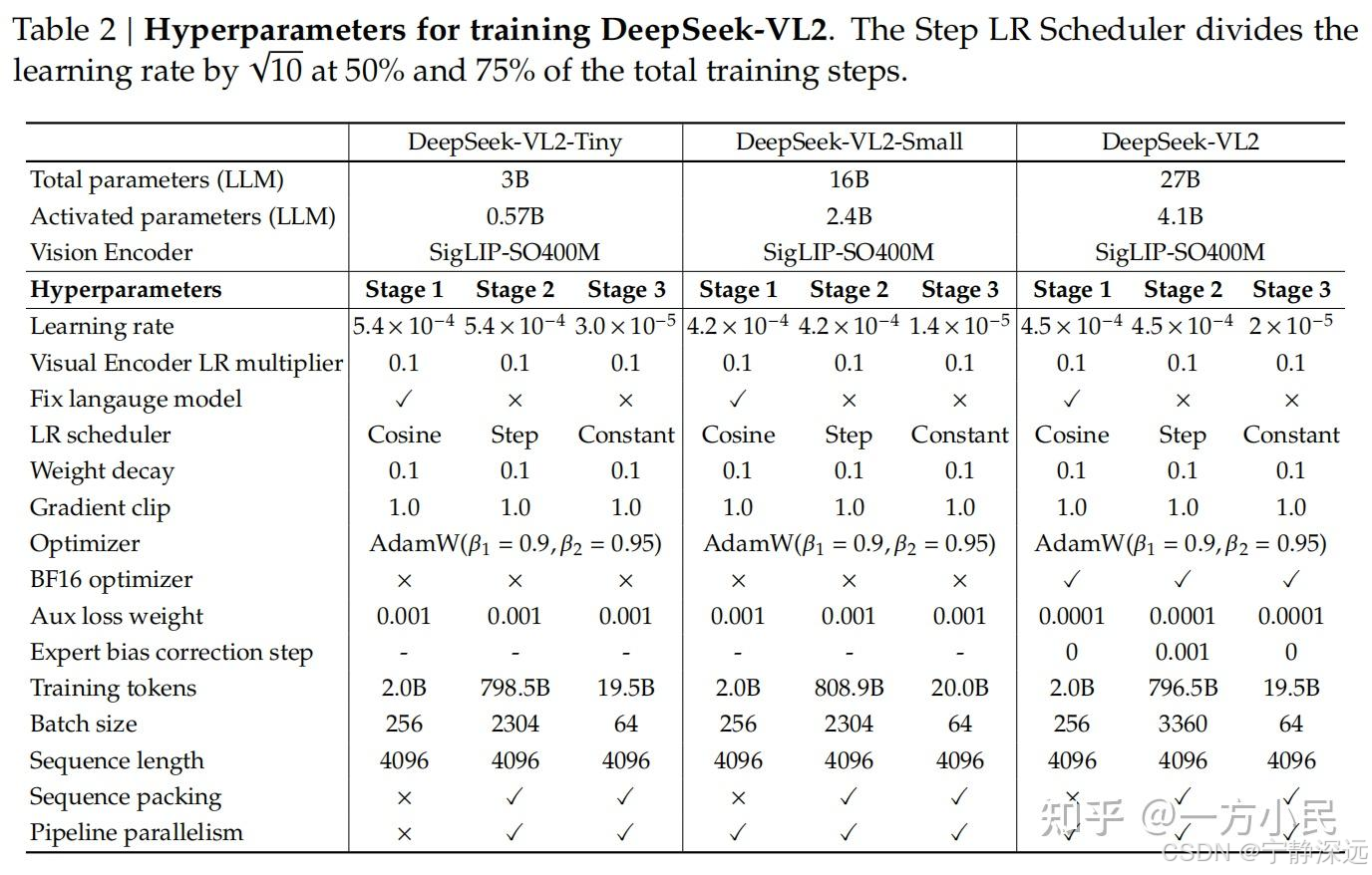
验证
- OCR
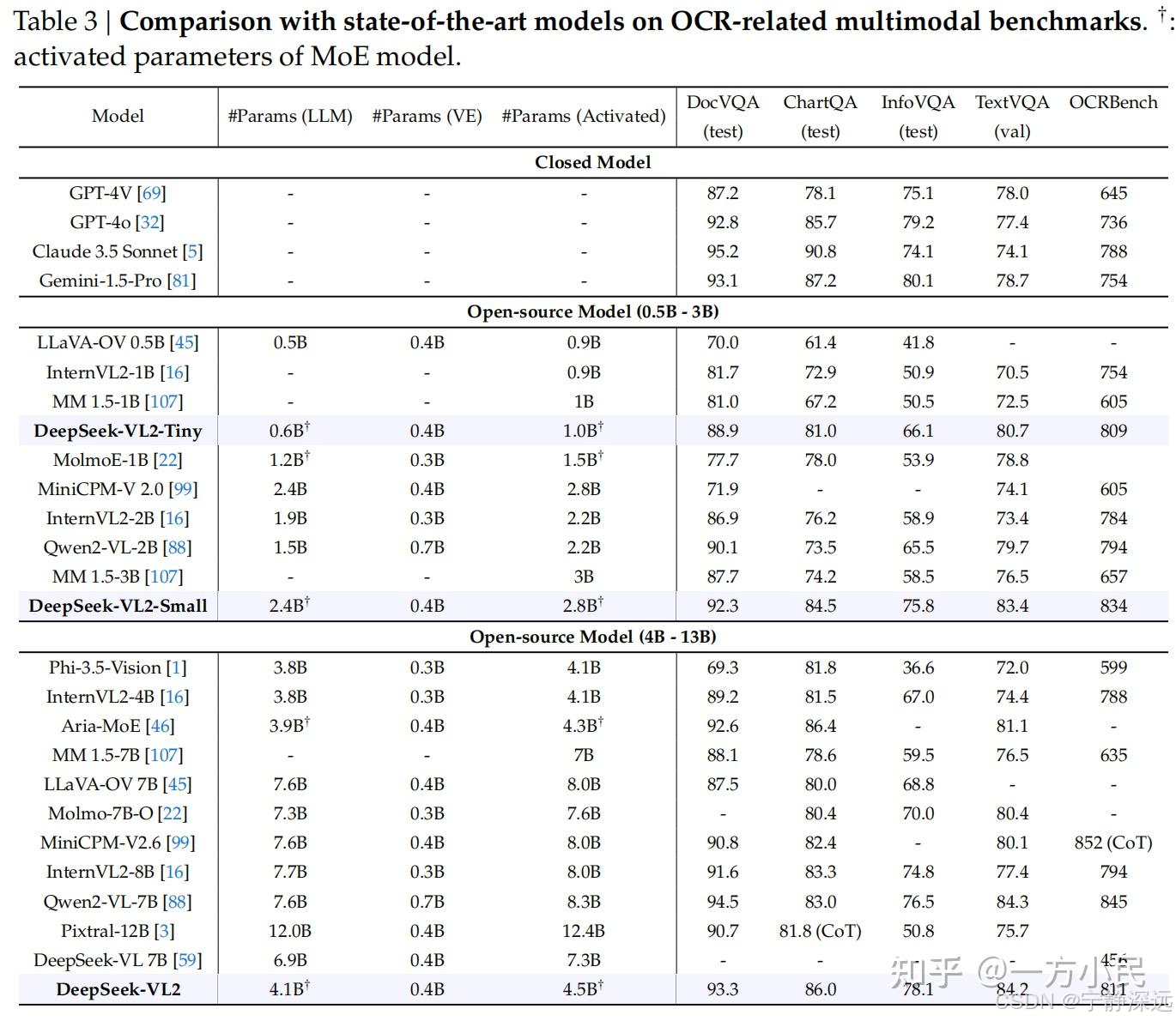
- QA 和数学
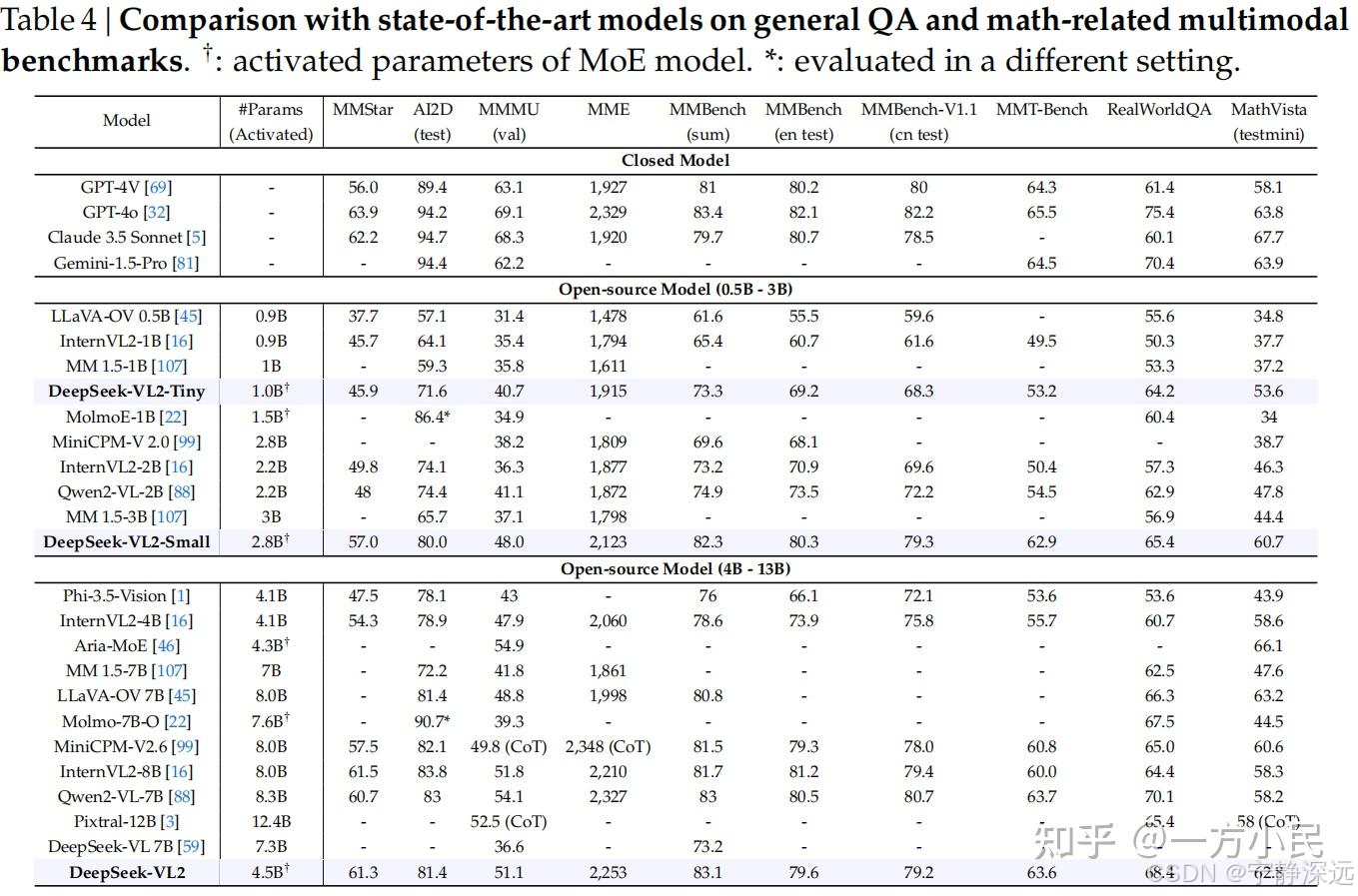
- 视觉定位
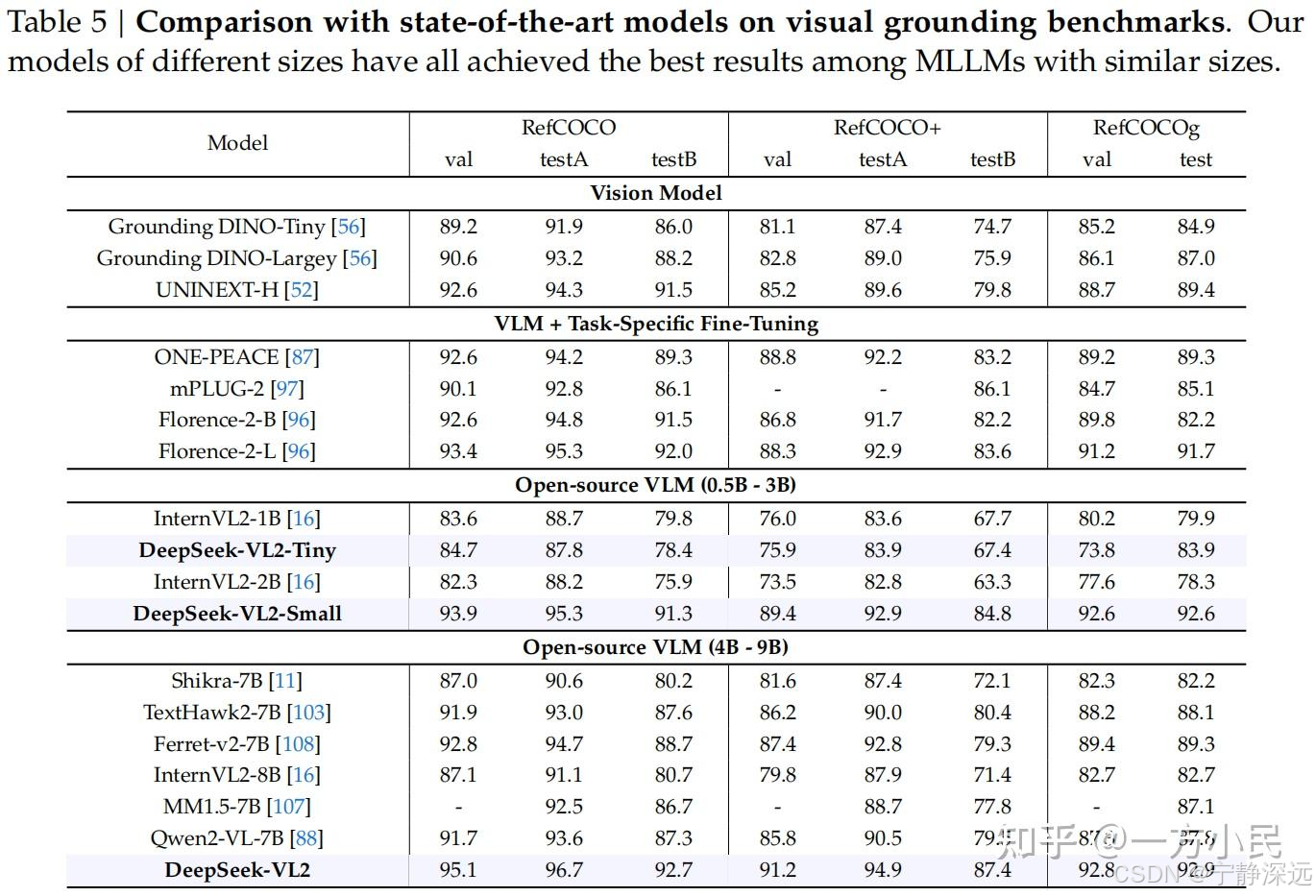
Math
coder

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)