大模型论文 | 从SFT到类强化学习: LLM推荐系统的过程监督新范式
基于大语言模型(LLMs)的推荐系统一般通过监督微调(SFT)进行训练,但由于其以最大化似然为目标,会加剧流行度偏差,损害推荐的多样性与公平性。为了解决这一问题,我们提出了一种名为 Flow-guided fine-tuning recommender(Flower)的新方法。该方法用生成式流网络(GFlowNet)框架替代传统的SFT,通过在tokens层面传播预先定义好的奖励信号,用一种类强化
TLDR: 基于大语言模型(LLMs)的推荐系统一般通过监督微调(SFT)进行训练,但由于其以最大化似然为目标,会加剧流行度偏差,损害推荐的多样性与公平性。为了解决这一问题,我们提出了一种名为 Flow-guided fine-tuning recommender(Flower)的新方法。该方法用生成式流网络(GFlowNet)框架替代传统的SFT,通过在tokens层面传播预先定义好的奖励信号,用一种类强化学习的方式实现了过程监督。

论文:https://arxiv.org/abs/2503.07377
代码:https://github.com/Mr-Peach0301/Flower
序:
最近,我们的SPRec被接收为WWW 2025 Oral。SPRec主要解决了大模型推荐系统中,DPO带来的流行性偏差问题。
然而,这个研究还不够底层,在DPO步骤前需要做一个SFT步骤,我们发现这个SFT步骤同样会带来流行性偏差,致使LLM模型的推荐结果偏袒在SFT训练集中更加流行的物品。
于是,这篇SIGIR 25的文章直接从SFT出发思考解决方案,借助Yoshua Bengio提出的GlowNets概念,使用了基于GlowNets的微调方式,得到LLM推荐系统中一种公平无偏的微调方法。
一、大模型推荐系统中SFT的问题:公平性
大模型在通用领域展现出了强大的能力,但要想更好的适配下游任务需要用到supervised fine-tuning (SFT) 进行微调。在序列推荐任务中,一个常见的SFT范式[1]是:在输入中给出用户的历史交互序列,让模型基于这些交互来预测下一个item,SFT会利用交叉熵损失(cross-entropy loss)来最大化target token的概率。
比如在下图的电影推荐场景中,“Back to the future”这个电影标题被逐个token的生成,现在有prompt和前两个token “Back”和“to”,SFT会学习预测下一个token “the”,其每次学习都在拟合the next token。下图右图中,对比性地给出了我们方法与SFT的不同,每次学习都是在直接拟合一个分布。
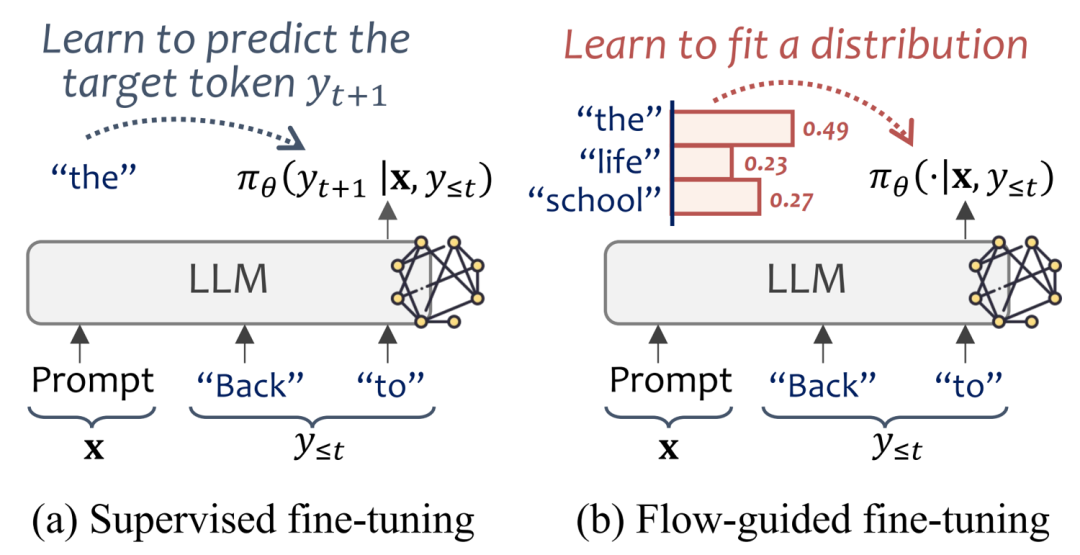
虽然SFT效果可观,但是他将两个问题引入了推荐系统:
- 推荐结果的多样性受限(Diversity):SFT会优先考虑高概率token,鼓励模型生成更常见的输出,牺牲了多样性。并可能会对微调数据集中的主流item过拟合,导致缺乏个性化的同质推荐。
- 放大流行度偏差(Bias):SFT倾向于强化微调数据集和预训练语料库中存在的偏见。可能会导致模型过度推荐热门item,降低用户体验和推荐的公平性。
先前的方法主要集中于修改SFT的学习过程或者在SFT后进行策略优化,但他们都不能同时解决上述两个问题:
| Method | Category | Bias-free | Diversity |
|---|---|---|---|
| Reweighting [2] | Modify the SFT learning process | √ | × |
| Multi-stage SFT [3] | Modify the SFT learning process | × | √ |
| RLHF [4,5] | Post-SFT policy optimization | √ | × |
| DPO [6,7] | Post-SFT policy optimization | √ | × |
在这篇工作中,我们没有延续这两类方法去修补SFT的局限性,而是用基于GFlowNets的微调代替传统的SFT,提出流指导微调推荐系统Flower。
二、Generative Flow Networks (GFlowNets)
在开始介绍我们的方法之前,首先简单介绍一下GFlowNets [8]。
Generative Flow Networks(生成流网络)是一类概率生成模型,其从物理中引入了流的思想,将“流”定义为可以学习并用于建模多样化结果的未归一化概率。
GFlowNets将问题建模为一个有向无环图(DAG),如下图所示,这里的节点是状态state,两个节点之间的有向边是action。生成流网络有一个唯一的初始状态,对应着一个初始流量,一般用表示,也是这个流网络的总流量(就像河流的源头),由这个节点开始,初始流量不断地分流,(就像河流分成多个支流),最后到达多个终止状态,每个终止状态对应着一个reward。
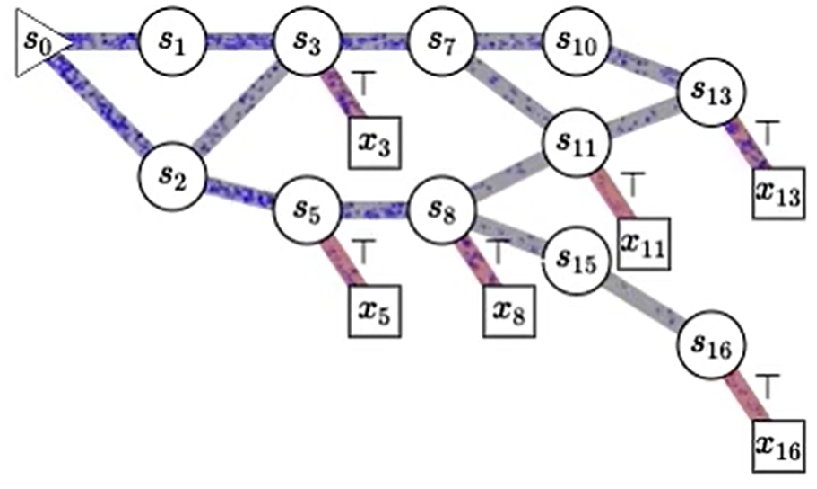



GFlowNets为状态、动作、reward建立了缜密的关系,在需要生成多样化且高reward结果的场景十分有效。给出reward,概率和流量会自动根据reward分配,trajectory-level reward被打碎成state-level reward,指导整个生成过程。
现在主要的GFlowNets loss有以下四种:


Flower模型
生成前缀树——一种特殊的 GFlowNets
我们的任务场景是序列推荐,在输入中以title形式给出之前交互的item,让模型输出下一个item的title,在这个场景下,模型会逐个token的生成这个title,我们将这个token生成过程建模为一个前缀树。其特殊之处在于:从前到后有分支,但从后到前的路径是唯一的(每个节点都只有一个父节点)。
依旧以电影推荐为例,如(b)中所示,从一个根节点开始(图中没有画出),第一个token有很多可能,这里选择了Back,确定了第一个token之后,再从第二个token位置上的可选token中选择,以此类推,直到生成出一个完整的title。
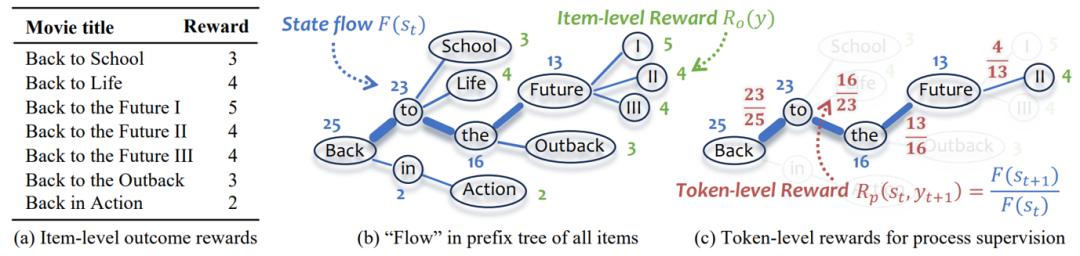
在这个前缀树中,每一个node代表一个确切的token,每一条有向边代表确定了前缀token之后接下来的一个可能的next token,根节点代表空序列,从根节点到一个终止节点的路径,代表着一个完整的item title。
| Structure | Sense |
|---|---|
| node | an exact token |
| directed edge | a possible next token |
| root node | empty sequence |
| paths from root to terminal nodes | complete item titles |
这样的前缀树是一个特殊的GFlowNet DAG。对应到GFlowNets中:
- 每一个node 的状态代表从根节点到的前缀token序列。
- 每一个从状态到状态的action 代表向st的前缀token序列后面加入代表的token。
- 初始状态的初始流量设置为1,代表所有title被生成的概率之和为1。
- 每个状态的流量等于其对应的前缀token序列被生成的概率。每个action的流量,因为树结构的特点,等于他指向的状态的流量。
- LLM对应于之前讲到的,给出状态前向转移的概率。
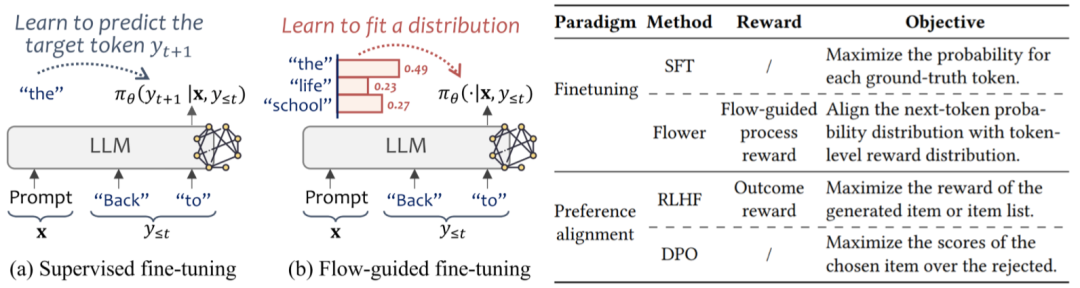
Item-level Reward
我们已经将生成过程与GFlowNets对应,接下来要设置reward来引导生成过程,训练,也就是对应的LLM。
我们将每个title在历史序列中的交互频率作为他的reward。因为生成前缀树的结构特殊性,也是LLM文本生成的特殊性,每个非初始状态只有唯一的父状态,每个终止状态对应唯一的title,因此终止状态的reward就是对应的title的reward。

Loss function of Flower
在之前内容的基础上,我们给出Flower的Loss Function。

Comparison between Flower and other methods
回到开始时展示的图片,Flow-guided fine-tuning和Supervised fine-tuning的范式差异明朗了起来。在每一个token位置上,SFT的目标是最大化targrt token的概率,而Flower学习的是由reward分配的目标分布。
这种reward思想和强化学习相似,这里我们也展示了RLHF和DPO同Flower的对比。RLHF和DPO将item-level preference直接作用于title整体,而Flower通过流将item-level reward细致地分配成token-level reward,在生成过程中始终对模型进行约束监督。并且,相较于RLHF和DPO的“Maximize”学习目标,Flower采取的是“Align”,不仅控制学习方向,还控制学习程度。
初步效果:拟合分布的能力
为了初步验证提出的Flower在拟合分布上的效果,我们用一个没有微调的LLM(Qwen2.5-1.5B-Instruct)、SFT版本、DPO、PPO,分别让其拟合Amazon的Movies and TV数据中随机挑选的100部电影的交互频次的分布。这个任务比推荐任务简单,因为其不需要个性化能力,只需要通过学习,记住目标分布,然后在测试阶段,随机推1000次。统计这1000次输出的分布与目标分布的差异,得到下面的结果。其中,蓝色为100部电影的分布,红色为100部电影的真实分布。
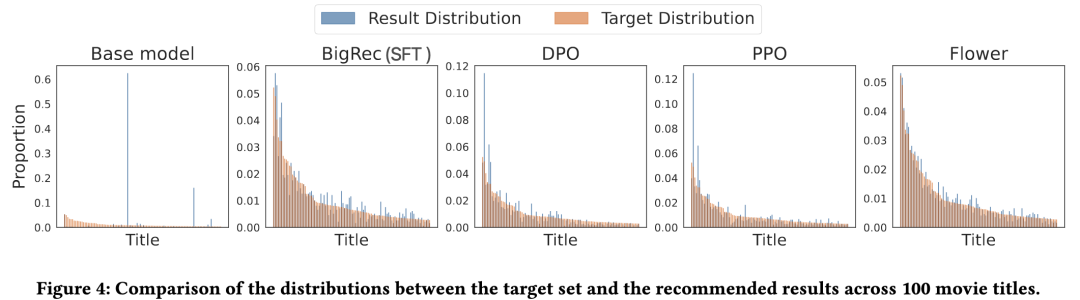
从图中可容易看出,Flower学习后的输出分布是最贴近目标分布的。其次是基于SFT的BigRec,但拟合紧密程度还是不如Flower。至于DPO与PPO这类方法,都过分强调最头部的电影,形成很强的流行性偏差。
更多实验设置及实验结果,请看原文,以及代码。
https://github.com/Mr-Peach0301/Flower
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
[1] Bao, Keqin, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yancheng Luo, Chong Chen, Fuli Feng, and Qi Tian. “A bi-step grounding paradigm for large language models in recommendation systems.” ACM Transactions on Recommender Systems (2023).
[2] Meng Jiang, Keqin Bao, Jizhi Zhang, Wenjie Wang, Zhengyi Yang, Fuli Feng, and Xiangnan He. 2024. Item-side Fairness of Large Language Model-based Recommendation System. In Proceedings of the ACM on Web Conference 2024(WWW ’24). 4717–4726.
[3] Jiaju Chen, Chongming Gao, Shuai Yuan, Shuchang Liu, Qingpeng Cai, and Peng Jiang. 2025. DLCRec: A Novel Approach for Managing Diversity in LLM-Based Recommender Systems. WSDM (2025).
[4] Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. 2024. Understanding the Effects of RLHF on LLM Generalisation and Diversity. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=PXD3FAVHJT
[5] Fangxu Yu, Lai Jiang, Haoqiang Kang, Shibo Hao, and Lianhui Qin. 2024. Flow of reasoning: Efficient training of llm policy with divergent thinking. arXiv preprint arXiv:2406.05673 (2024).
[6] Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. 2024. A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics (AISTATS ’24). PMLR, 4447–4455.
[7] Jiayi Liao, Xiangnan He, Ruobing Xie, Jiancan Wu, Yancheng Yuan, Xingwu Sun, Zhanhui Kang, and Xiang Wang. 2024. RosePO: Aligning LLM-based Recommenders with Human Values. arXiv preprint arXiv:2410.12519 (2024).
[8] Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. 2024. Flow network based generative models for non-iterative diverse candidate generation. In Proceedings of the 35th International Conference on NeuralInformation Processing Systems (NIPS ’21). Curran Associates Inc., Red Hook, NY, USA, Article 2097, 14 pages.
[9] Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE,197–206

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献354条内容
已为社区贡献354条内容

所有评论(0)