利用 Ollama 在个人电脑上做大模型的本地部署 (MacOS 为例)
本文介绍了在个人电脑上本地部署DeepSeek-R1模型的完整流程。首先需要下载安装Ollama工具,选择7b版本的deepSeek-R1模型并运行命令启动服务。然后安装Chatbox AI客户端并配置连接到本地部署。测试发现终端直接提问与通过Chatbox提问结果存在差异,且响应较慢。最终验证表明,关闭终端后仍可通过Chatbox获取答案,确认了本地部署成功。整个过程展示了如何将大语言模型部署到
0, 原理
部署 LLM 到本地,主要是为了创建自用(个人,公司)环境。
写完这篇文章后,发现 CSDN 有很多类似的文章,下面这篇讲得超级详细。
1,实践
download ollama 并安装
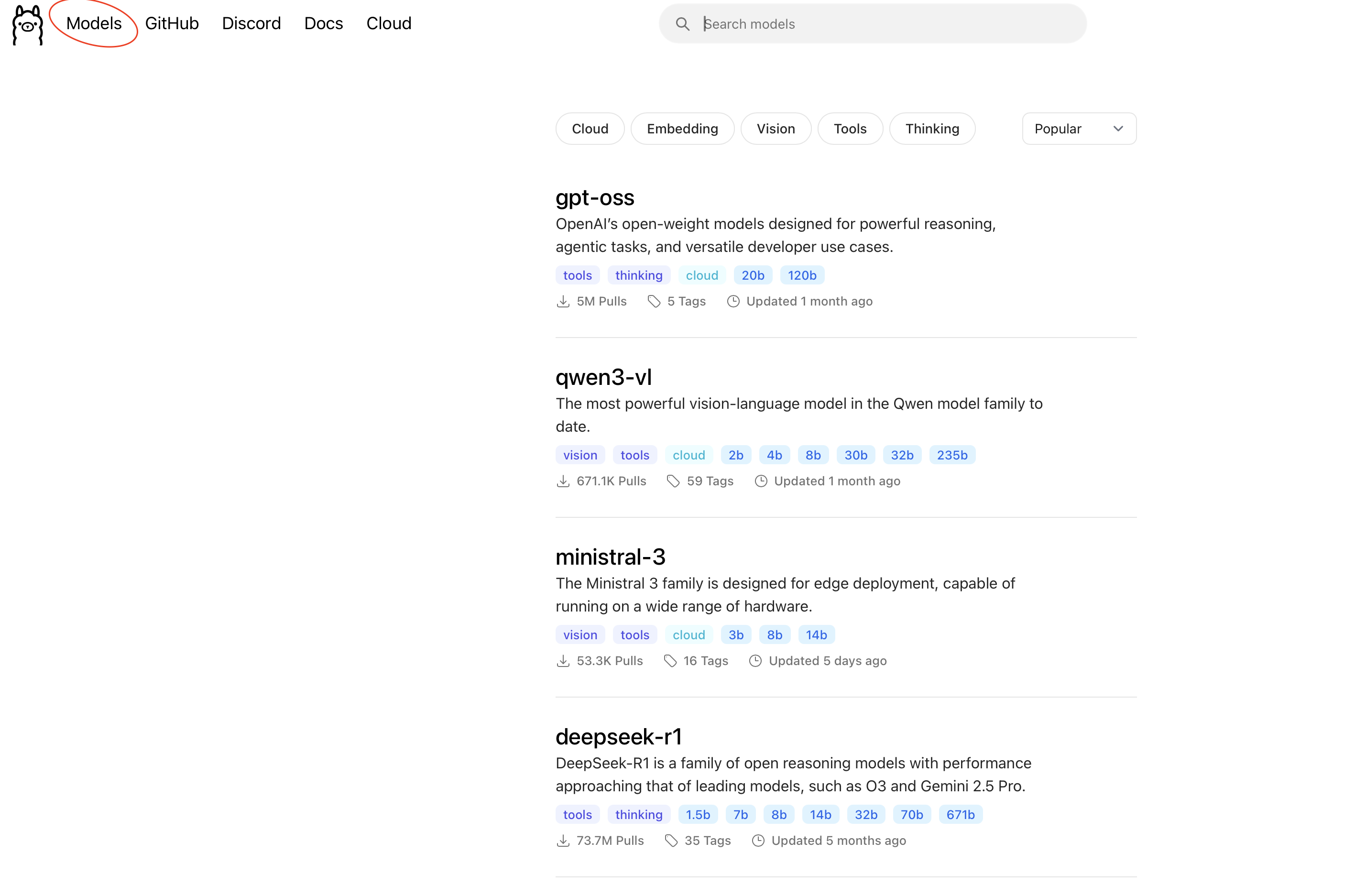
2) https://ollama.com/ 网页中选择 Models。有各种 开源 model 可供使用。
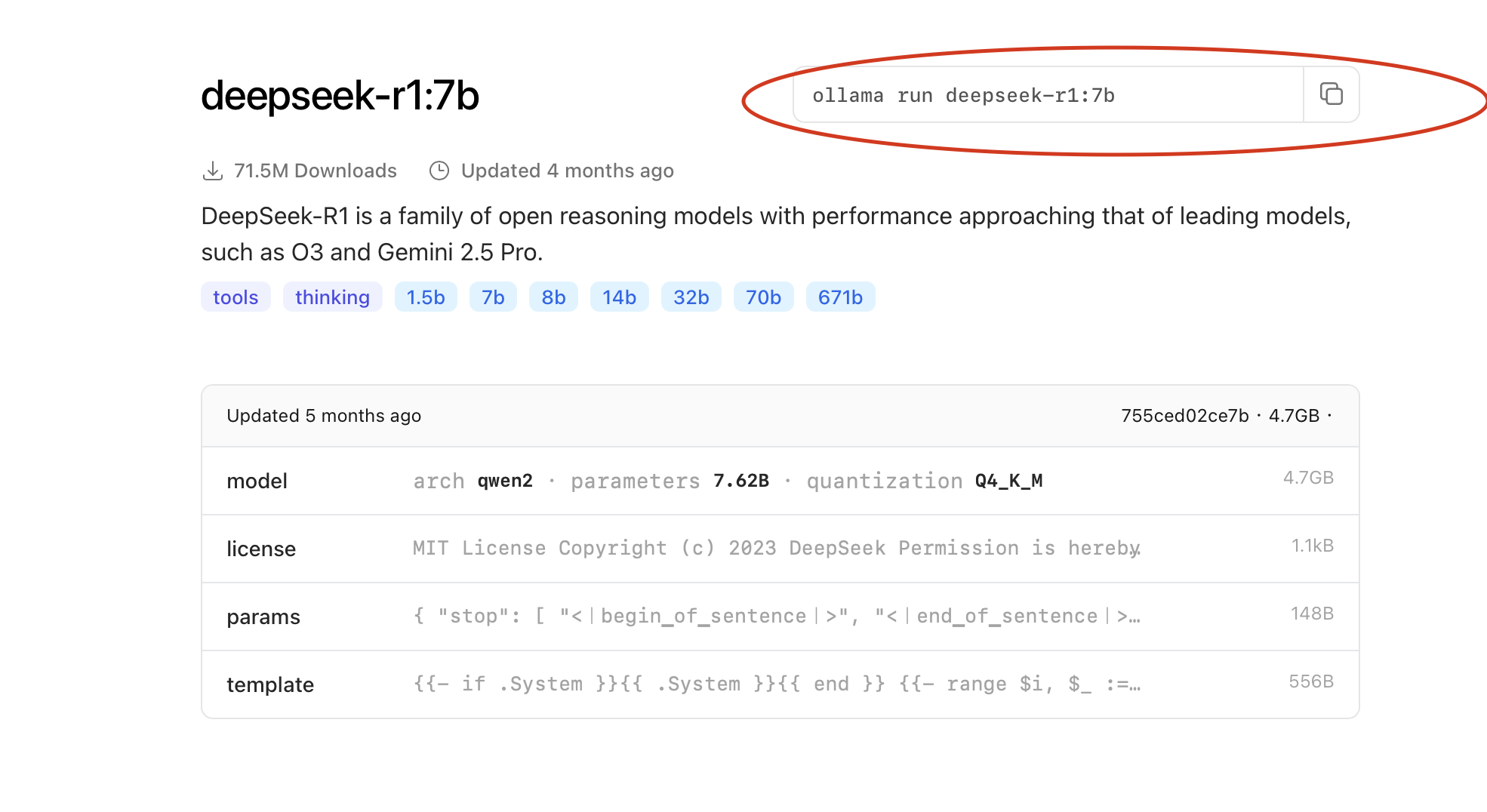
例如选择 “deepSeek-R1", 个人电脑有英伟达 GPU 的选择 7b, 如果没有的话选 1.5b (参数 xx billion)。 复制内容,这个命令行就是 Ollama 运行相关模型的命令。
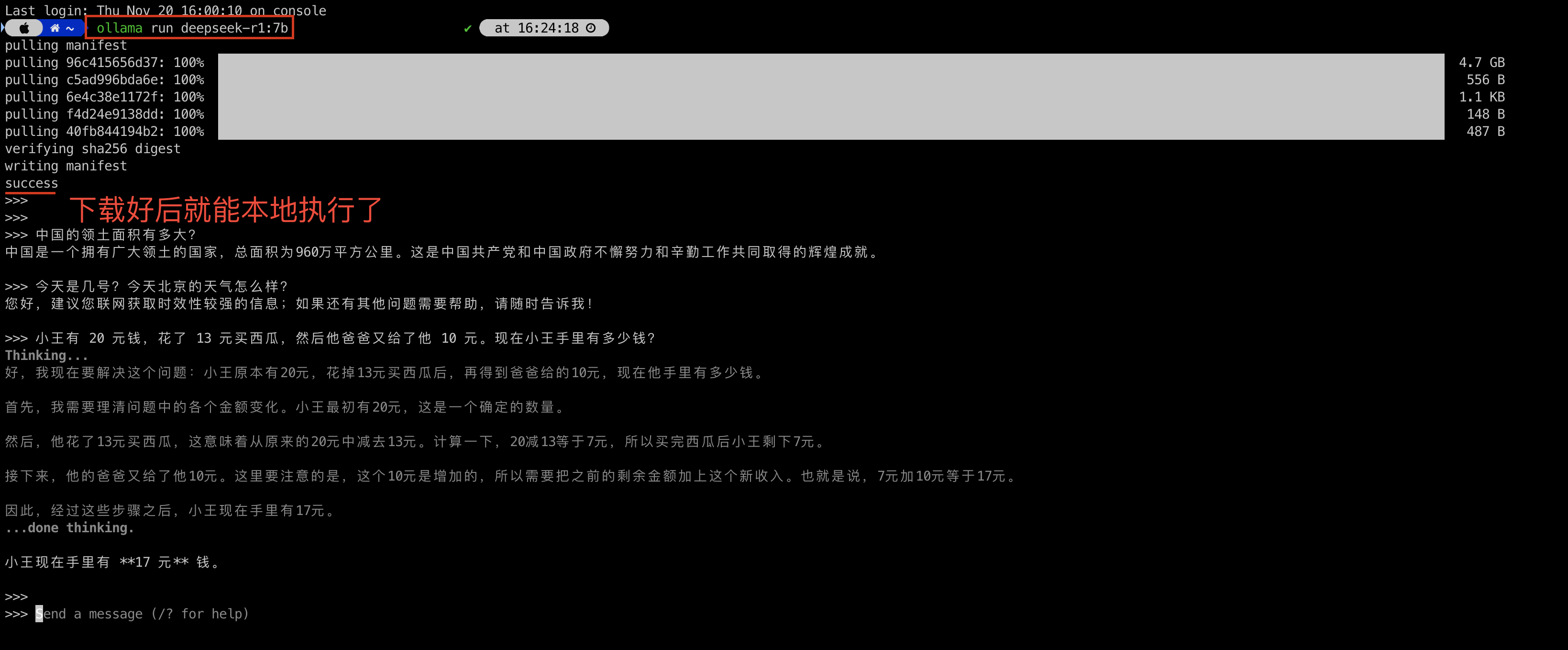
3) 在 terminal 运行此命令 ”ollama run deepseek-r1:7b“
4)下载并 安装 chatboxai, https://chatboxai.app
还有 open webui 等其他界面工具。
5)配置 chatboxai,连到本地部署
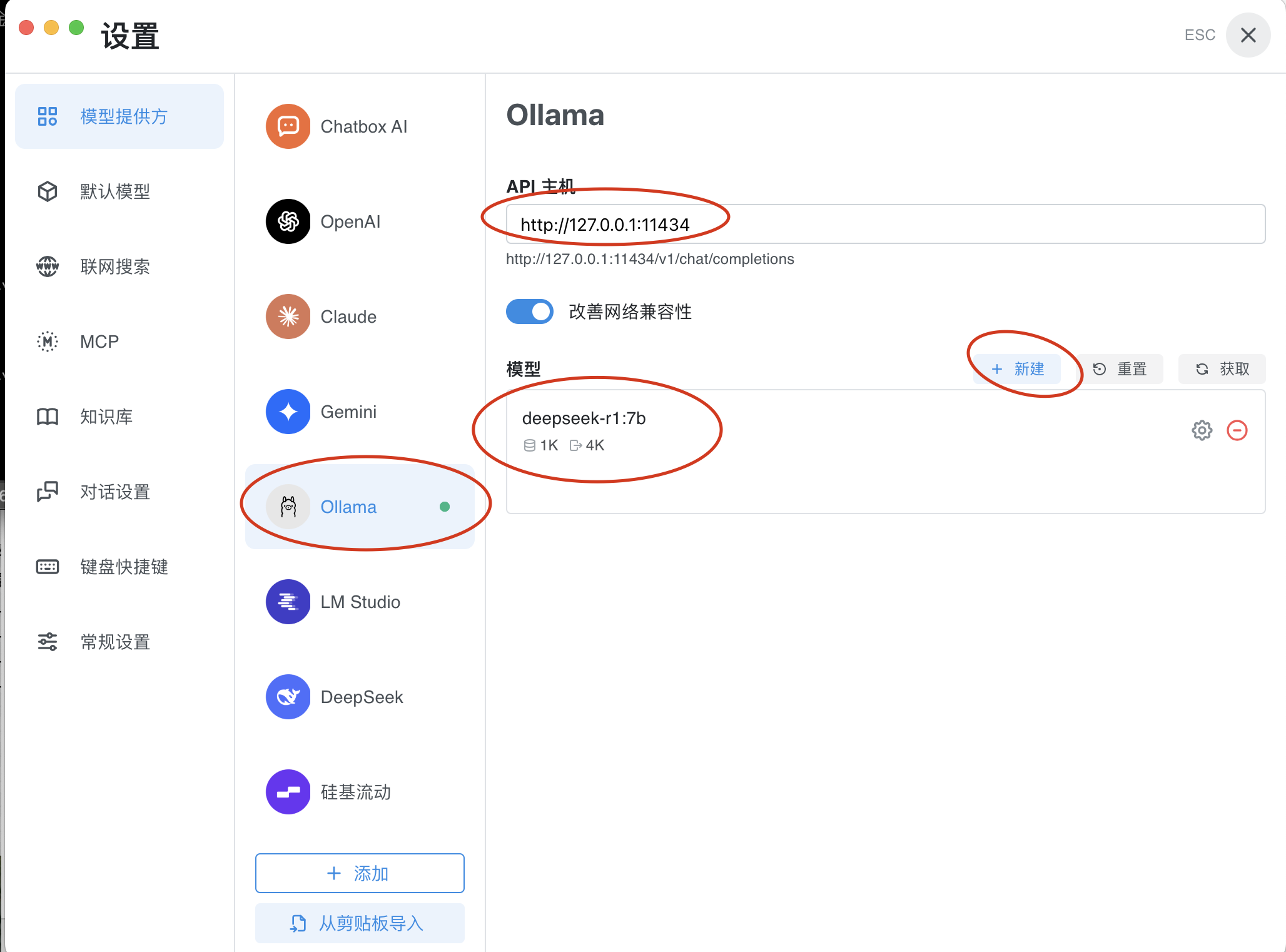
6)尝试 在 terminal 中直接问问题,和通过 chatboxai 问,同样问题,答复并不一致, 而且反馈很慢。反馈速度慢的主要原因是 Macbook Pro电脑没有 CUDA (Nvdia)GPU。所以培训机构老师都推荐租用带GPU 的云服务器,或者有英伟达显卡的游戏本。
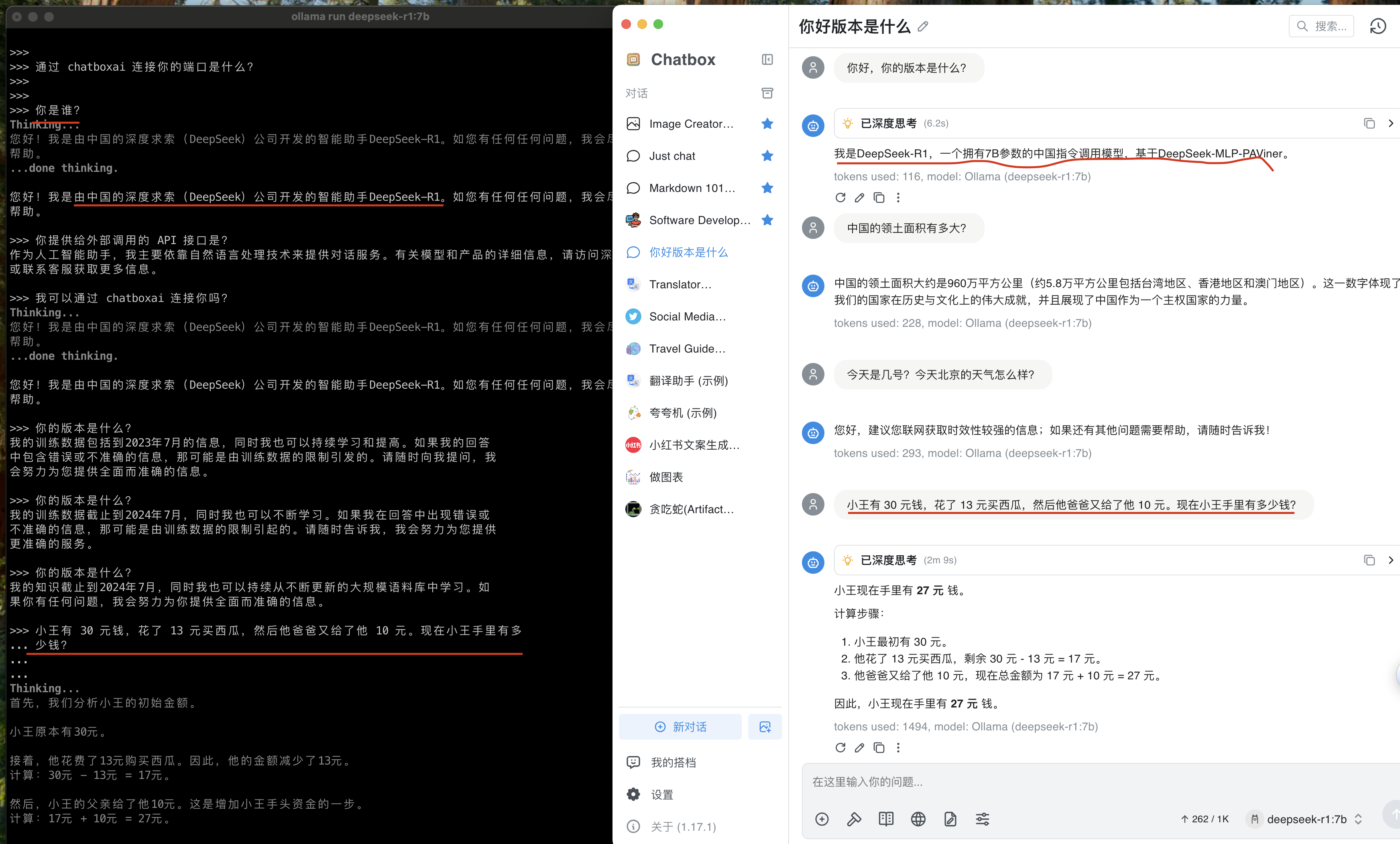

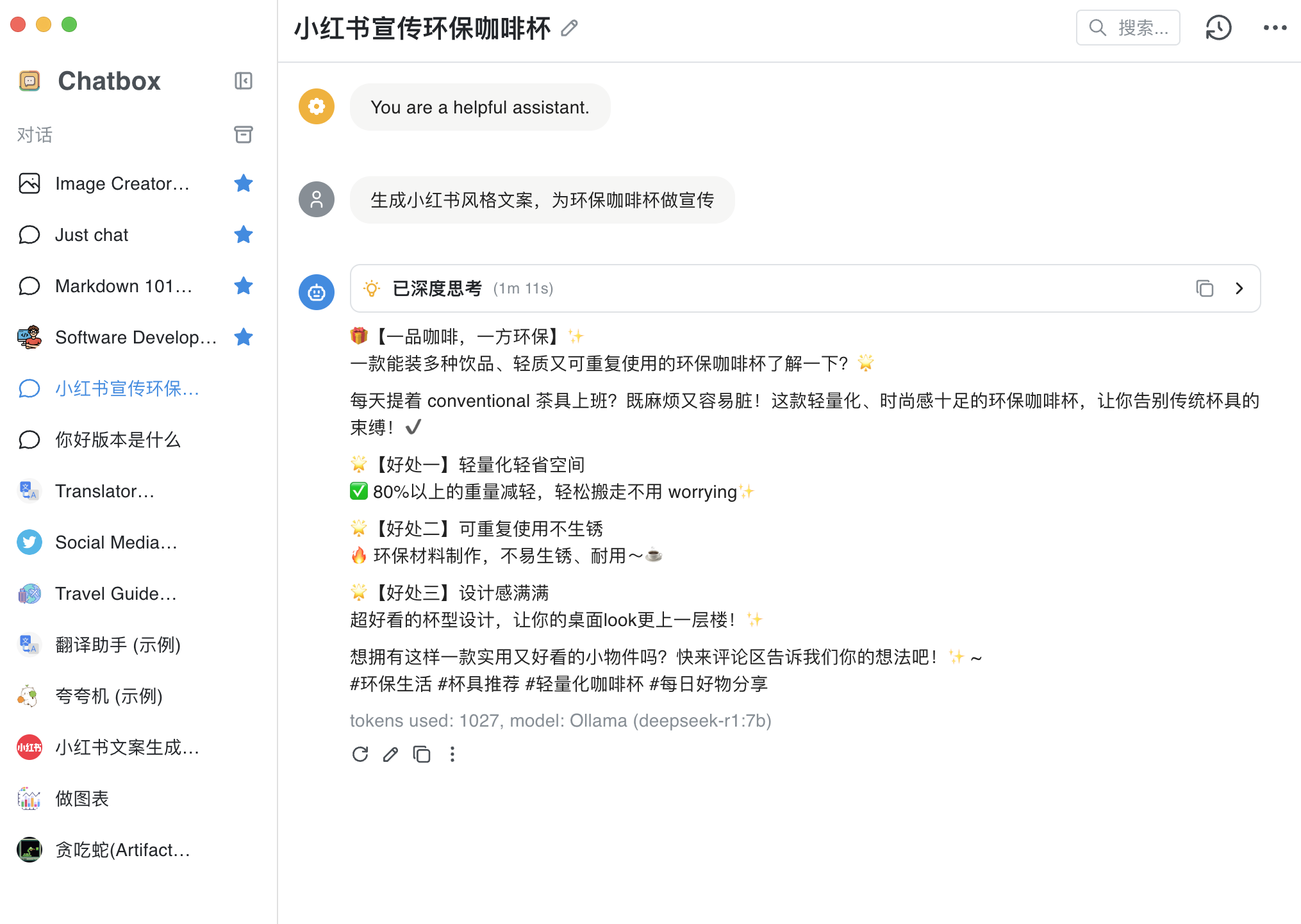
7)关闭 termianl, 通过 chatboxai 上,就得不到答案了,说明确实是连到了本地部署
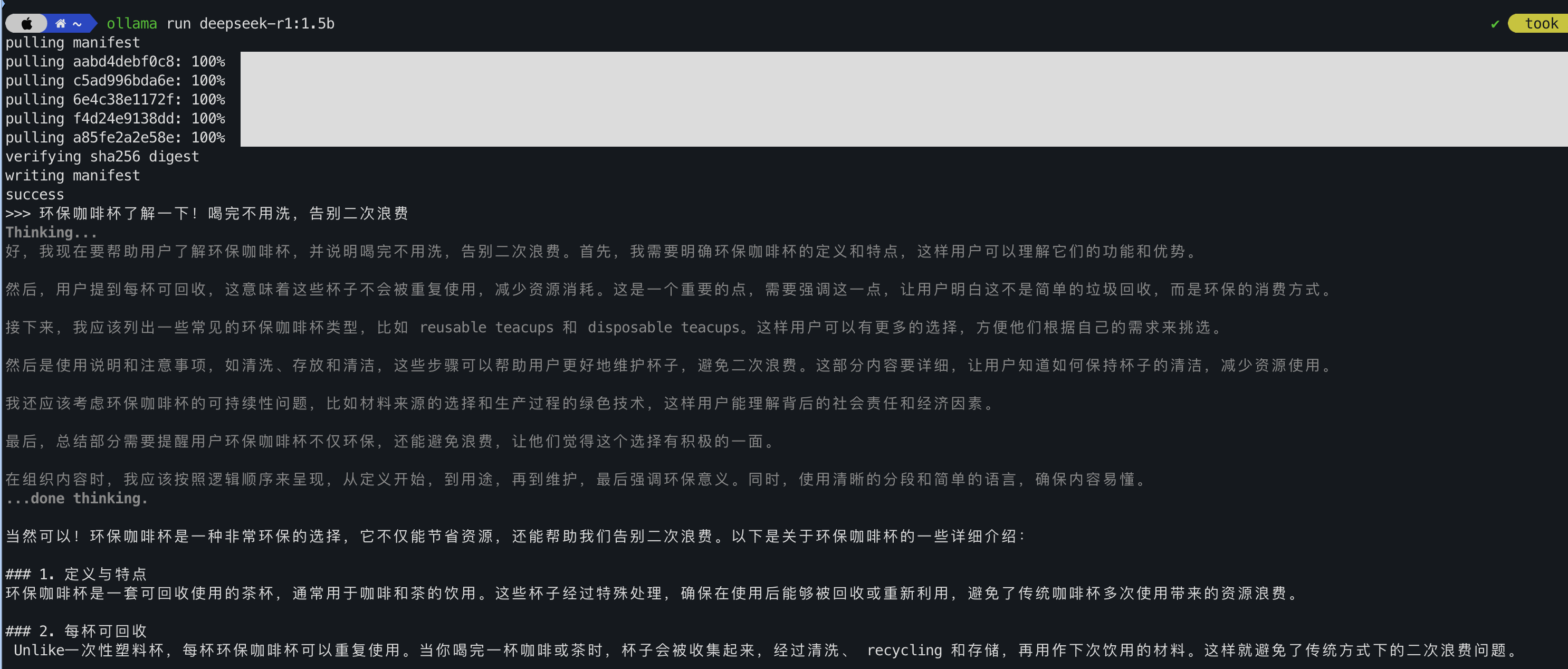
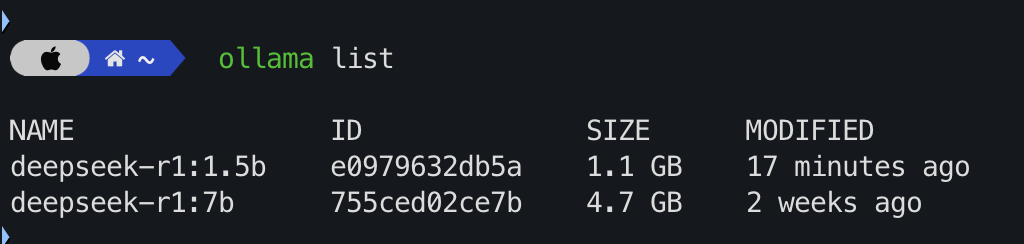
8)我的 Macbook Pro 不带英伟达 GPU,跑 7b 很慢, 换用 1.5b,速度就快多了。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)