基于python+贝叶斯分类+LDA的商品评论数据采集分析可视化系统 爬虫+情感分析
本项目旨在采集电商平台商品评论数据并进行简单的 NLP 与可视化分析,最终通过Flask框架提供 Web 展示。爬虫:使用 Python + requests 抓取电商评论数据。数据库存储:将采集的评论写入 MySQL 数据库。文本分析:使用多种常见 NLP 库对数据进行情感分析(SnowNLP)、LDA 主题建模(gensim)以及朴素贝叶斯分类(scikit-learn)。可视化展示:Flas
1. 项目简介
本项目旨在采集电商平台商品评论数据并进行简单的 NLP 与可视化分析,最终通过 Flask 框架提供 Web 展示。核心流程包括:
- 爬虫:使用 Python + requests 抓取电商评论数据。
- 数据库存储:将采集的评论写入 MySQL 数据库。
- 文本分析:使用多种常见 NLP 库对数据进行情感分析(SnowNLP)、LDA 主题建模(gensim)以及朴素贝叶斯分类(scikit-learn)。
- 可视化展示:Flask 后端调用数据或读入分析结果,并使用前端模板 + JavaScript 图表库来进行可视化呈现;也支持词云图生成。
该项目更多是教学或演示性质,可作为学习 Python 全栈或数据分析流程的参考与示例。
2. 环境与依赖安装
2.1 开发环境要求
- 操作系统:Windows / Linux / MacOS(示例主要在 Windows 10/11 环境下测试)。
- Python 版本:建议 3.7 以上。
- MySQL 数据库:5.7或 8.0 均可,字符编码设置为
utf8mb4更好。
2.2 第三方依赖
项目根目录下的 requirements.txt 大致包含以下常见库:
Flask requests tqdm pandas numpy jieba pymysql snownlp gensim matplotlib wordcloud scikit-learn joblib
请在虚拟环境或系统环境下进行安装。例如:
pip install -r requirements.txt
若有个别库版本不兼容,可手动指定版本或升级/降级相关库。
3. 数据库准备
3.1 创建数据库
- 在 MySQL 中创建名为
comment的数据库(也可改为其他名称,但需要同步修改项目中的连接配置)。
CREATE DATABASE comment CHARSET=utf8mb4; USE comment;
- 创建数据表:
- 用户表:
tb_user(用于存储用户名、密码)。 - 评论表:
data(用于存储爬取到的商品评论)。
- 通常会配套一个
comment.sql或comment_tables.sql文件,里面含有建表语句:
CREATE TABLE IF NOT EXISTS tb_user (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(255),
password VARCHAR(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS data (
id INT PRIMARY KEY AUTO_INCREMENT,
nickname VARCHAR(255),
score INT,
content TEXT,
productColor VARCHAR(255),
creationTime VARCHAR(255),
imageCount INT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 确保数据库字符集设置正确,如
utf8mb4,以支持更多 Unicode 字符(例如表情符号等)。
3.2 配置数据库连接
项目中有多处使用 pymysql 连接数据库,一般在 until.py(或 script.py)里都有类似:
def coon():
con = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='123456',
port=3306,
db='comment',
charset='utf8'
)
cur = con.cursor()
return con, cur
需要根据你本机或服务器实际环境修改 host、user、passwd、db、port 等信息,以便正常连接。
4. 项目结构与代码说明
解压后项目核心文件夹 code 中主要包含:
- app.py:Flask 主应用入口,定义了各种路由(路由对应分析页面或功能)并渲染相应的模板。
- until.py:数据库连接与通用操作,比如
serch/insert函数封装了查询/插入操作;还包括简单的登录注册业务逻辑。 - script.py:爬虫脚本,示例中以爬取京东部分商品评论为例,将爬取到的评论数据存入 MySQL 数据库中。
- nlp.py:基于
SnowNLP对评论进行情感分析,将结果保存为nlp.csv文件。 - bayes.py:基于 scikit-learn 的 Naive Bayes 分类器,对评论进行“好评/差评”分类实验,最后把预测结果与真实标签写入
bayes.csv,模型持久化到bayes.pkl。 - lda.py:基于 gensim 实现 LDA 主题建模,对好评和差评做简要的主题分析,并把关键词保存到
lda.csv。 - datafx_ciyun.py:生成词云示例,对爬取的评论进行分词并可视化词云。
- templates(目录):存放 Flask 前端页面模版(HTML)。
- static(目录):静态资源文件,如 CSS、JS、图片等。
- requirements.txt:第三方依赖库说明。
- 其他辅助文件:如
stopwords.txt(停用词)、.sql文件(建表语句)等。
数据采集(script.py)
def main():
for i in range(0, 20):
...
response = requests.get('https://club.jd.com/comment/productPageComments.action', ...)
# 解析 JSON
jsonObj = json.loads(re.match("(fetchJSON_comment98\()(.*)(\);)", response).group(2))
for comment in jsonObj["comments"]:
nickname = comment["nickname"]
score = comment["score"]
...
sql = 'insert into data(...) values(...)'
insert(sql)
- 通过爬取京东商品评价页(示例商品 ID 为
10066185480208),每次取 10 条评论,抓取若干页。 - 利用正则和
json.loads获取接口返回的评论信息,字段包括nickname, score, content, productColor, creationTime, imageCount等。 - 将评论插入到本地 MySQL 数据库中的
comment库下的data表里。
要点:
- 使用
requests来模拟请求,附带必要的 Header 及 Cookie 信息绕过简单反爬。 - 使用
re.match提取 JSON 回调中的真正 JSON 数据再解析。 - 写入数据库时,注意对字符串做适当的转义或处理,以防 SQL 注入(示例中使用了字符串格式化
%s也能部分规避问题,但生产环境最好考虑更安全的参数绑定)。 - MySQL 连接信息与部分通用函数(
insert,serch等)在同一个脚本中,也可以拆分或借助until.py复用。
Flask 主应用(app.py)
@app.route('/', methods=['GET', 'POST'])
def login():
# GET 请求:直接返回登录页面
# POST 请求:获取前端表单数据,做登录验证
- 整体使用 Flask + Jinja2 模板:
- 访问
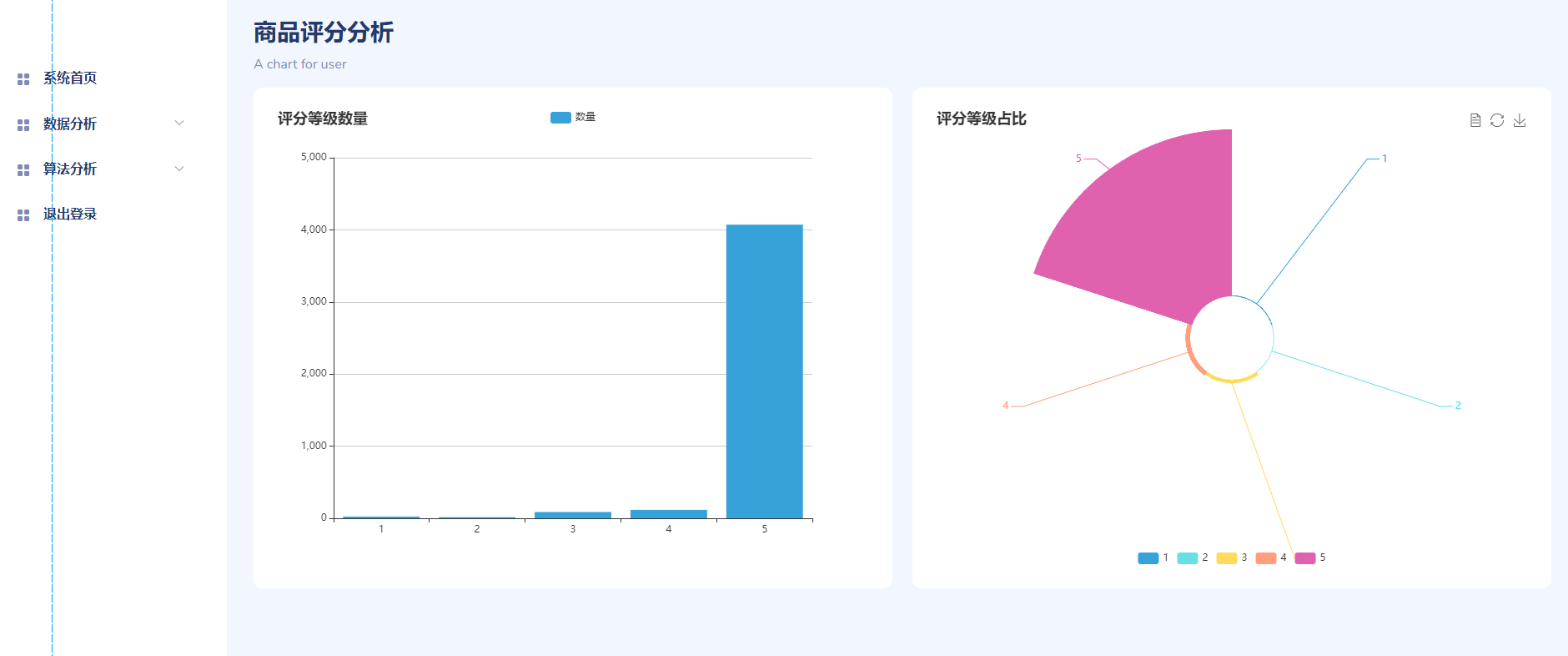
/路由时,若为 GET 则返回登录页面,若为 POST 则验证登录后返回 JSON 结果。 /register路由与之相似,只是插入数据库注册新用户。/index读取data表中的所有评论数据,传给页面渲染。/datafx_*系列路由主要对应不同维度或不同方式的可视化统计(比如按时间、按评分分布、按每天/每小时等维度统计评论数量)。/datafx_ciyun路由跳转到词云页面。/nlp,/LDA,/bayes分别对应情感分析、LDA 主题分析、以及贝叶斯分类结果页面。
核心逻辑:在每个路由处理函数里,从数据库或 CSV 文件中查询/读取数据,进行简单处理后包装成字典 data 再传给模板(render_template('xx.html', data=data))。前端可能用 ECharts 或其他图表库将这些数据呈现出来。
5. 文本挖掘/分析脚本
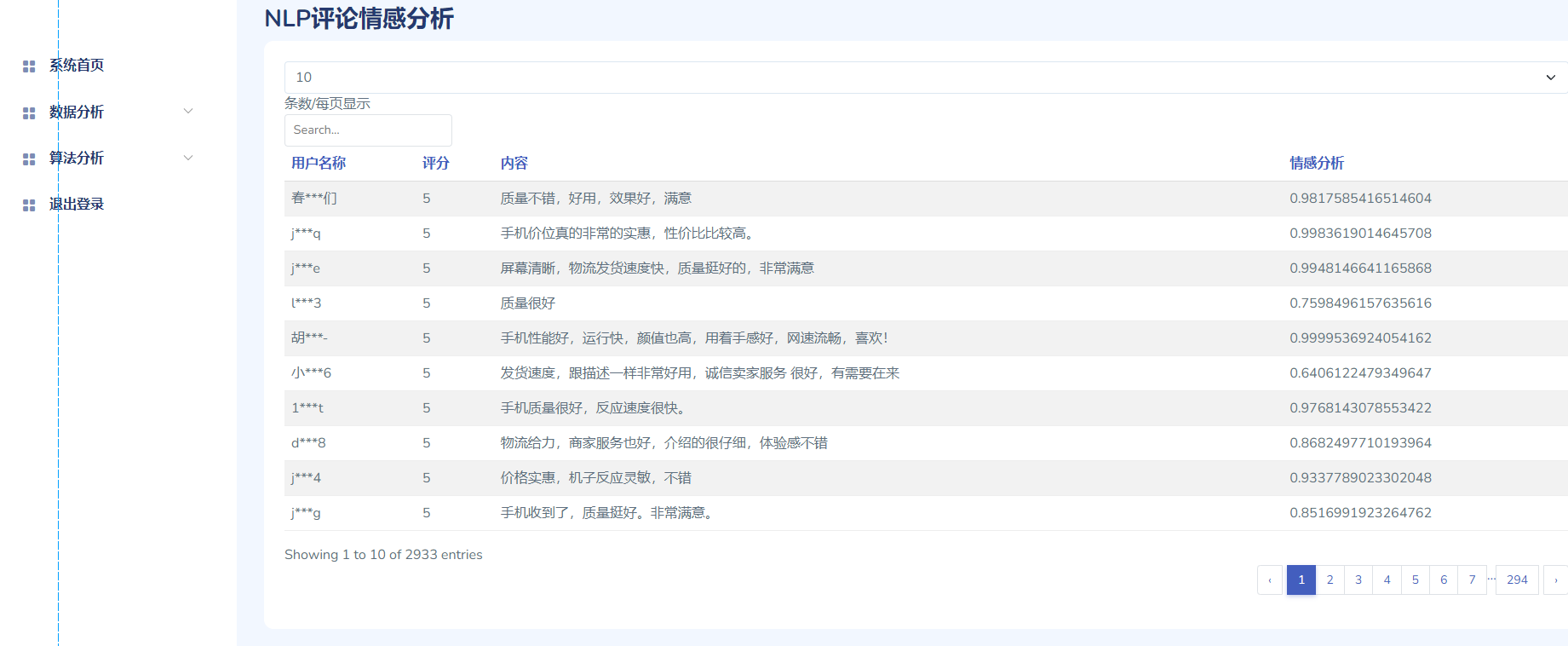
- nlp.py
- 使用
SnowNLP对每条评论计算情感倾向(sentiments),得到结果后写到nlp.csv。 SnowNLP的sentiments值通常在 0~1 之间,数值越大越偏正向。
- lda.py
- 利用
gensim进行 LDA 主题建模。示例中把评论按好评 (score=5) 和差评 (score=1) 分别抽取出来做分词。 - 过滤停用词后,把文本转换为
Dictionary和Corpus,再训练LdaModel(num_topics=3, ...)。 - 将训练好的主题的高频词抽取出来,保存到
lda.csv。 - 仅做了简单的 3 个主题示例,实际可根据需要调整主题数并做更多细化分析。
- bayes.py
- 用 scikit-learn 的朴素贝叶斯模型对评论做“好评/差评”分类。先进行分词并统计词频(
CountVectorizer),再用BernoulliNB训练,最后把预测结果写入bayes.csv。 - 这里把 13 分当作差评(1),45 分当作好评(2),然后输出准确率,模型也会序列化成
bayes.pkl方便后续加载。
- datafx_ciyun.py
- 生成词云示例,基于
wordcloud库,将评论做分词、过滤停用词后生成图片,默认保存到static/images/beautifulcloud.png。
6. 总体流程与使用
- 准备数据库:
- 建立名为
comment的数据库,执行comment.sql中的建表语句,包括data表、tb_user表等。 - 修改脚本中的
pymysql.connect(...)配置,如host、user、passwd、db等,保证连到自己的数据库环境。
- 爬取数据:
- 执行
script.py里的main()函数,爬取京东评价并插入到数据库data表。
- 文本分析:
- 在爬取完后,可运行
nlp.py、lda.py、bayes.py等脚本,产生若干 CSV 文件与模型文件,得到评论的情感值、LDA 主题关键词以及 Bayes 训练结果等。 - 如果想要词云,可在
datafx_ciyun.py中指定好停用词文件与字体文件后运行,会生成词云图片。
- 运行 Flask:
- 直接
python app.py或flask run,默认在本地127.0.0.1:5000启动。 - 打开浏览器访问相应路由,进行登录/注册后便可查看各类数据可视化、结果展示页面。
7. 总结
- 核心思路:使用
requests + 正则 + json实现爬虫 → MySQL 数据存储 → Flask 框架搭建 Web 展示 → 并结合SnowNLP/gensim/sklearn等库做简单的 NLP/机器学习处理 → 前端可用 ECharts 或模板自定义可视化。 - 扩展方向:
- 增加更多的数据清洗、预处理流程,比如去重、表情符过滤、分词细化等。
- 优化情感分析或分类算法,如将 SnowNLP 改为其他深度学习模型,或引入更多特征。
- 优化爬虫部分(验证码、代理池、断点续爬等),以及部署到云服务器上让 Flask 服务持久运行。
- 增加真正的商品推荐逻辑或协同过滤算法,使“推荐系统”部分更完整,而非只做文本分析。
具体项目演示效果:
【基于python+nlp+贝叶斯分类+LDA的京东商品评论数据采集分析可视化+情感分析(s2025016)】 https://www.bilibili.com/video/BV1RnXGYaEHi/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)