【深度分析】深度思考vs闪电响应!Qwen3系列发布,鱼与熊掌这次可以兼得[特殊字符]Qwen3觉醒「脑力涡轮」模式!中国大模型开启深度思考光速纪元[特殊字符]
Qwen3 通过。
Qwen3 技术架构与核心能力解析
📌 模型架构
✅ 密集模型(Dense Model)
- 全参数训练,覆盖 0.6B/1.7B/4B/8B/14B/32B 不同规模
- 适用于 通用任务,平衡性能与效率
✅ 混合专家(MoE)架构
- 30B-A3B(30B总参,3B激活)
- 235B-A22B(235B总参,22B激活)
- 动态稀疏计算,降低推理成本,提升大模型效率
🚀 核心创新
🔹 混合思维模式(Hybrid Reasoning)
- 思考模式(Reasoning Mode):深度推理,适合复杂任务
- 非思考模式(Direct Mode):快速响应,优化轻量级任务
- 用户可自由切换,灵活适配不同场景
🔹 多语言能力
- 支持 119 种语言和方言
- 优化低资源语言理解,覆盖全球主要语系
🔹 Agent & 代码增强
- 强化 Agent 任务规划,提升多步推理能力
- 代码生成/理解优化,适配开发者需求
- 改进 MCP(Multi-Criteria Planning)支持,增强复杂决策能力
💡 技术亮点总结
| 特性 | 优势 | 适用场景 |
|---|---|---|
| 密集模型 | 全参数训练,稳定可靠 | 通用 NLP、轻量级部署 |
| MoE 架构 | 高性价比推理,大模型低成本运行 | 超大规模任务、高效计算 |
| 混合思维 | 灵活切换推理深度,平衡速度与精度 | 复杂问答 vs 即时响应 |
| 多语言 | 119 种语言覆盖,全球化支持 | 跨境业务、低资源语言处理 |
| Agent 增强 | 强化任务规划与代码能力 | 自动化流程、AI 辅助开发 |
📢 一句话总结:Qwen3 通过 密集+MoE 双架构、混合思维模式 和 多语言/Agent 优化,实现 高性能+高灵活性,满足从轻量到超大规模的全场景需求!
|
Models |
Layers |
Heads (Q / KV) |
Tie Embedding |
Context Length |
|
Qwen3-0.6B |
28 |
16 / 8 |
Yes |
32K |
|
Qwen3-1.7B |
28 |
16 / 8 |
Yes |
32K |
|
Qwen3-4B |
36 |
32 / 8 |
Yes |
32K |
|
Qwen3-8B |
36 |
32 / 8 |
No |
128K |
|
Qwen3-14B |
40 |
40 / 8 |
No |
128K |
|
Qwen3-32B |
64 |
64 / 8 |
No |
128K |
MoE 模型
|
Models |
Layers |
Heads (Q / KV) |
# Experts (Total / Activated) |
Context Length |
|
Qwen3-30B-A3B |
48 |
32 / 4 |
128 / 8 |
128K |
|
Qwen3-235B-A22B |
94 |
64 / 4 |
128 / 8 |
128K |
基准测试
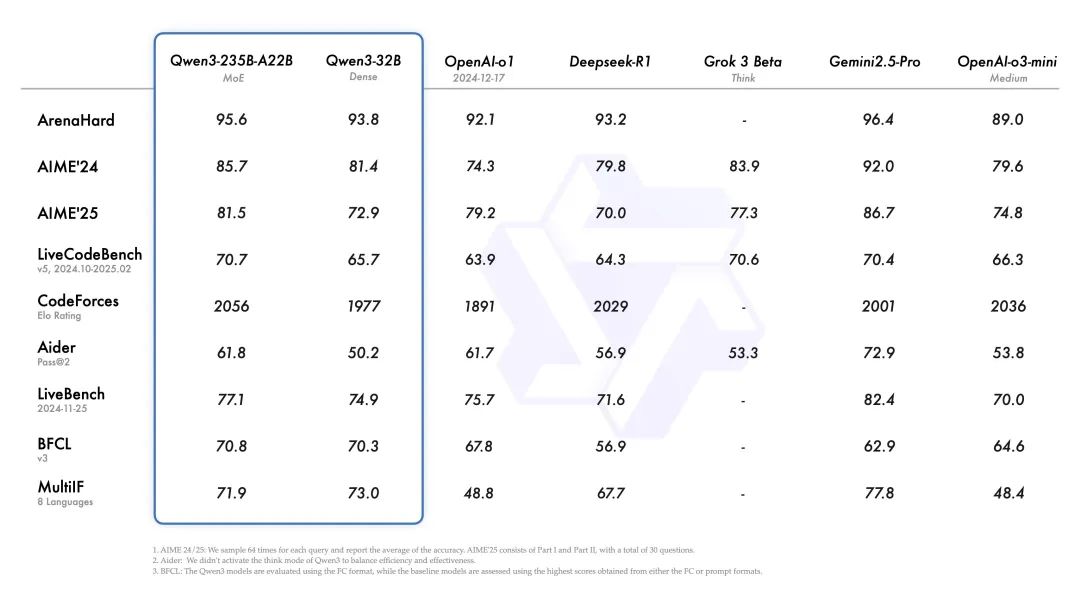
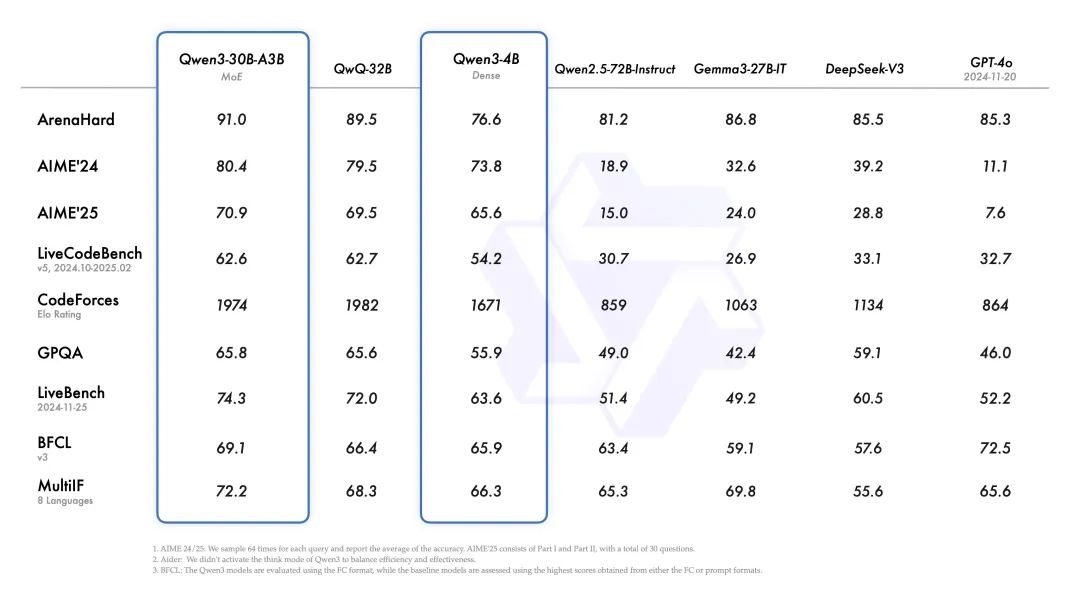
从官方公布的基准测试看,
旗舰模型
Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。此外,小型 MoE 模型Qwen3-30B-A3B的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
训练
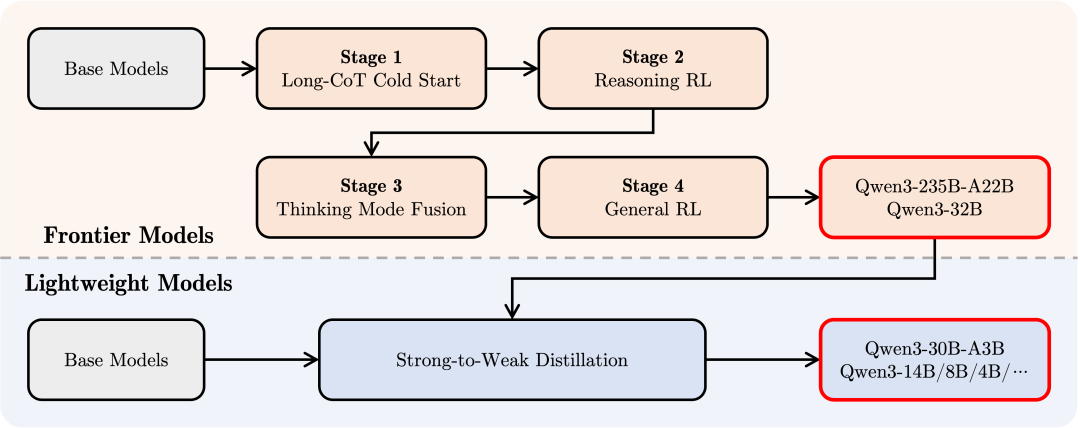
Qwen3 使用约 36 万亿 Token,在预训练阶段分为 3 步:
-
1. 模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识
-
2. 增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练
-
3. 使用高质量的长上下文数据将上下文长度扩展到 32K token
在后训练分为 4 步
-
1. 长思维链冷启动:使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力
-
2. 长思维链强化学习:重点在
大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力 -
3. 思维模式融合:将非思考模式整合到思考模型中
-
4. 通用强化学习:在 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为
使用 qwen3
升级 ollama
qwen3 模型需要 ollama v0.6.6 或更高版本,先把 Linux 上的 ollama 升级到 v0.6.6:
wget https://github.com/ollama/ollama/releases/download/v0.6.6/ollama-linux-amd64.tgz
sudo systemctl stop ollama
sudo rm -rf /usr/lib/ollama
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
sudo systemctl start ollama升级完后,下载 qwen3:8b模型,大小在 5.2G
$ ollama pull qwen3:8b
pulling manifest
pulling a3de86cd1c13: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 5.2 GB
pulling eb4402837c78: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.5 KB
pulling d18a5cc71b84: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB
pulling cff3f395ef37: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 120 B
pulling 05a61d37b084: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
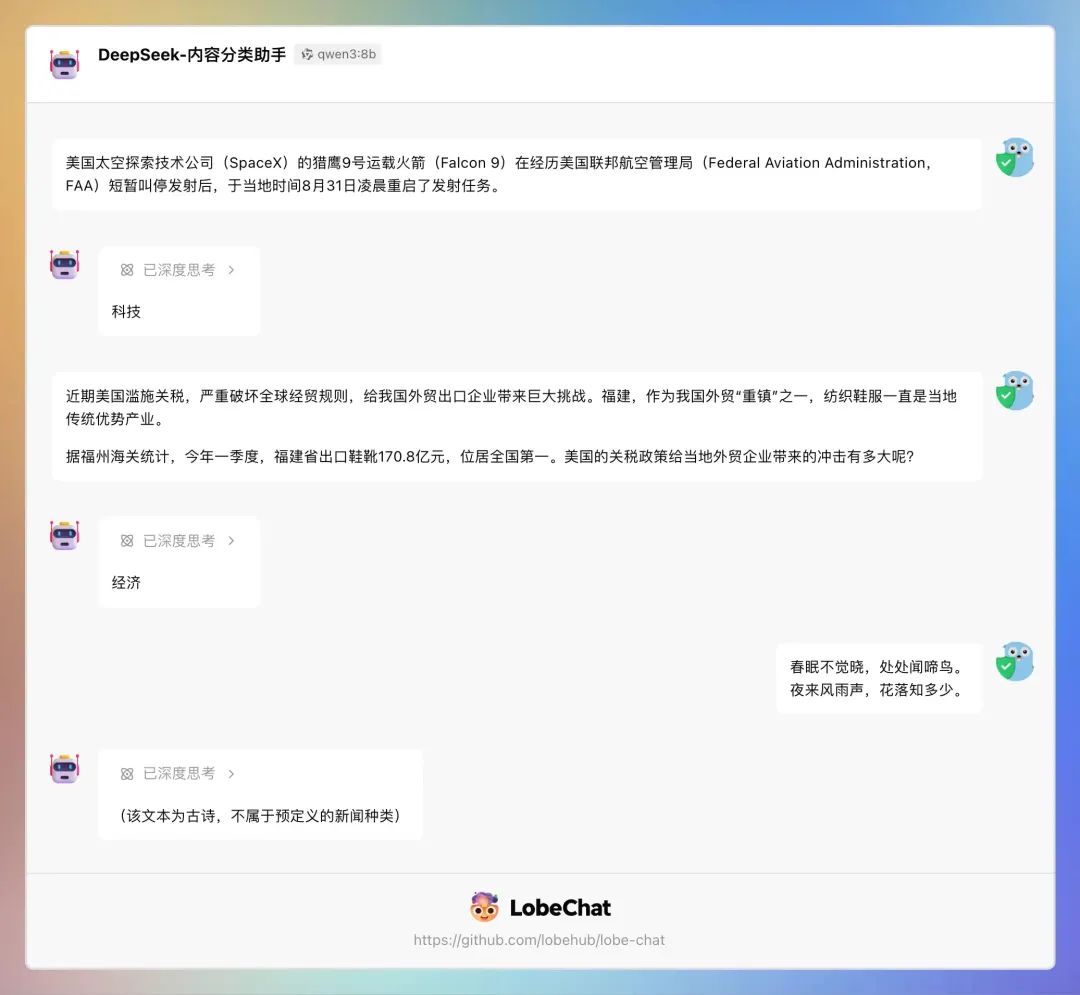
success配置好模型后,在 LobeChat 中使用 qwen3:8b 看下实际效果:
在内容分类方面,DeepSeek-R1:14B 和 qwen3:8b 旗鼓相当。
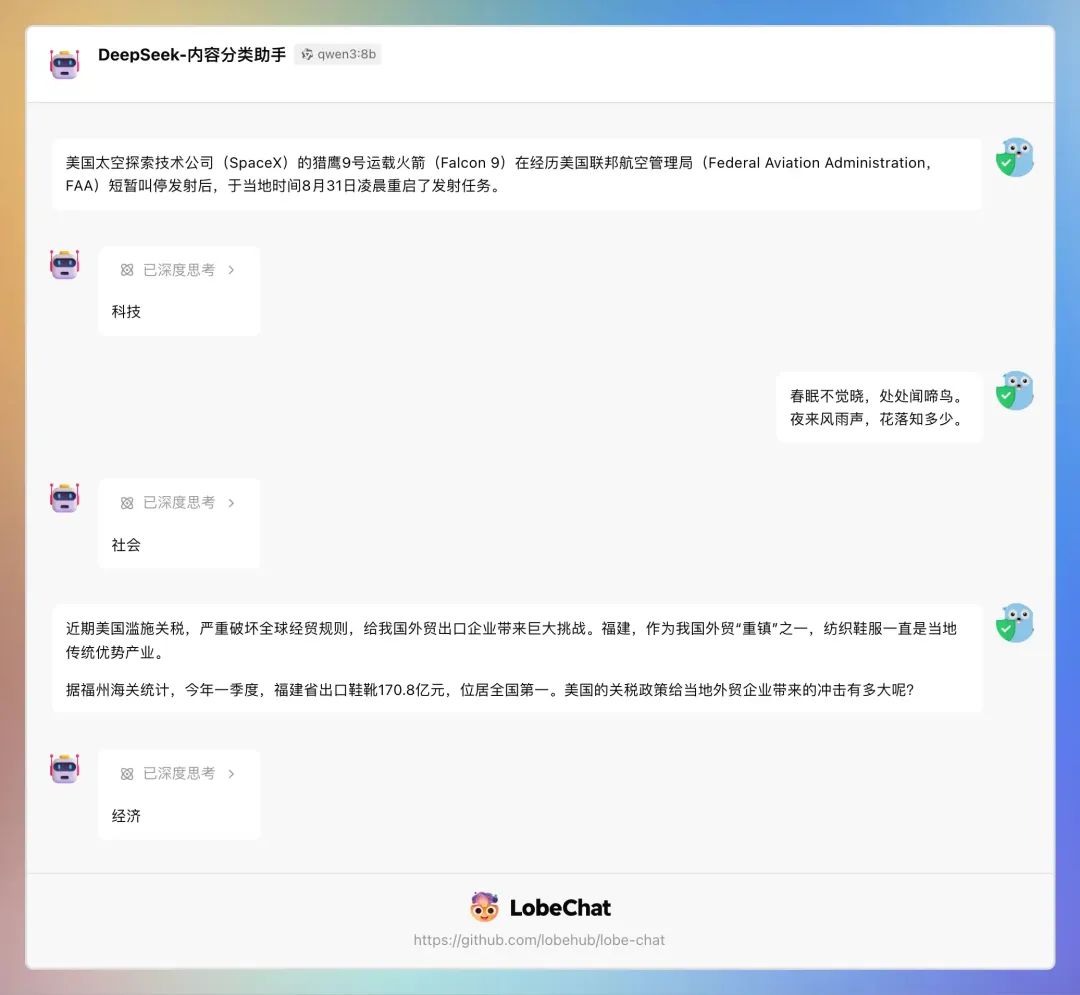
在内容分类方面,DeepSeek-R1:14B 吊打 qwen3:8b。

总的来说各有千秋,要根据实际效果选择模型。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)