【NL2SQL】通过多粒度错误识别提升文本到SQL转换能力
文本转SQL是一种将自然语言问题转换为可执行SQL查询的技术,使用户能够更轻松地查询和管理关系型数据库。近年来,大语言模型显著推动了文本转SQL的发展。然而,现有方法在SQL生成过程中往往忽略了对生成结果的验证。当前的错误识别方法主要分为基于大模型的自纠错方法和基于SQL执行的反馈方法,这两种方法都存在局限性。我们将SQL错误主要分为三类:系统错误、框架错误和值错误,并提出了一种多粒度错误识别方法
通过多粒度错误识别提升文本到SQL转换能力
论文:https://aclanthology.org/2025.coling-main.289.pdf
摘要
文本转SQL是一种将自然语言问题转换为可执行SQL查询的技术,使用户能够更轻松地查询和管理关系型数据库。近年来,大语言模型显著推动了文本转SQL的发展。然而,现有方法在SQL生成过程中往往忽略了对生成结果的验证。当前的错误识别方法主要分为基于大模型的自纠错方法和基于SQL执行的反馈方法,这两种方法都存在局限性。我们将SQL错误主要分为三类:系统错误、框架错误和值错误,并提出了一种多粒度错误识别方法。实验结果表明,该方法可以作为插件集成到各种方法中,提供有效的错误识别和纠正能力。
1 引言
文本转SQL是一种旨在将自然语言问题转换为可执行SQL查询的技术,为用户提供了一个更直观、更友好的界面来查询和管理关系型数据库,从而提高数据库的可用性和查询效率(邓等人,2022)。
近年来,像ChatGPT和GPT - 4这样的大语言模型(LLM)在各种自然语言处理任务中取得了显著成功(欧阳等人,2022年;阿奇姆等人,2023年)。通过利用上下文学习技术,研究人员有效地利用了大语言模型的知识(董等人,2023年)。
尽管在生成SQL方面取得了显著进展,但现有方法往往忽略了验证生成结果这一关键步骤。与自然语言不同,SQL是一种语法非常严格的语言,语句中的任何不符合规范的部分都会被数据库拒绝。为了解决这个问题,当前基于大语言模型的方法主要遵循生成 - 识别 - 纠正框架:首先生成SQL,然后检测任何错误,最后纠正这些错误。这些方法可以分为两大类,主要区别在于它们的错误识别方式,如图1所示。第一类方法使用大语言模型本身来检测生成的SQL中的错误(波雷扎(Pourreza)和拉菲伊(Rafiei),2024年;王(Wang)等人,2024年)。然而,由于这些模型并非专门为SQL语法验证而设计,它们往往难以准确识别具体的SQL错误。第二类方法依靠SQL执行引擎(如MySQL)根据执行结果来判断是否存在错误(陈(Chen)等人,2023年)。尽管如此,这种方法仅限于检测系统错误,无法识别更广泛的错误类型。4282
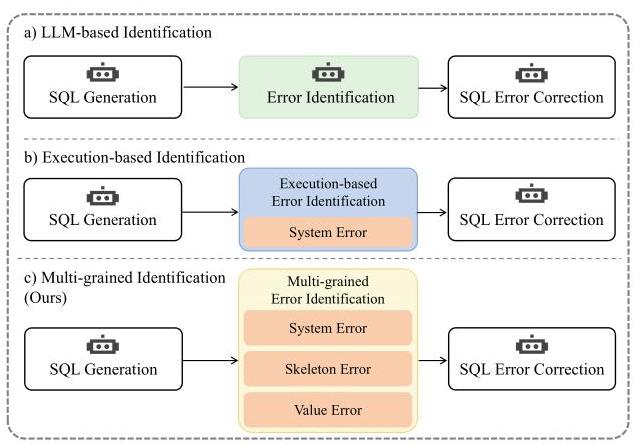
图1:基于生成-识别-修正框架的不同文本转SQL方法对比,突出错误识别方法的差异。
为应对上述挑战,我们提出一种多粒度错误识别方法,旨在提升文本转SQL的生成结果。我们将SQL错误分为三大类:系统错误、骨架错误和值错误。如图2所示,当预测的SQL查询包含无效语法,导致SQL引擎无法执行时,就会出现系统错误。
当移除特定值相关组件后,预测的SQL查询结构与预期查询不匹配时,会出现骨架错误(Skeleton Error)。当预测的SQL查询中使用的值与数据库预期的值不一致时,会识别出值错误(Value Error)。具体而言,为了识别系统错误,我们使用一个SQL执行器,它会根据执行失败情况标记这些错误。为了识别骨架错误,我们引入了一个骨架匹配模型,该模型通过衡量问题与生成的SQL之间的结构相似性来识别不匹配情况。为了识别值错误,我们与数据库进行交互,将预测的值与相关列中的实际值进行比较,以识别不一致之处。一旦识别出错误,我们的框架会输出错误类型以及详细的错误信息。然后,这些信息将用于指导大语言模型纠正已识别的错误,确保生成更准确的SQL查询。
我们的主要贡献如下:
-
我们系统地研究了SQL生成过程中出现的错误,将其分为三种不同类型,并提出了一种多粒度识别方法。这种方法提供了详细的错误信息,便于后续的模型纠正。
-
我们引入了一个基于对比学习的骨架匹配模块,通过比较查询语句和SQL骨架之间的语义相似度来识别骨架错误。为了增强编码器的表示能力,我们将难负样本纳入学习过程。
-
实验表明,我们的方法可以作为一个通用插件,提高不同模型下各种方法的性能。通过消融实验,我们强调了该方法中每个模块的重要性。

图2:一个展示三种类型错误的示例,每种错误用红色突出显示以便识别。
2 概述
在本节中,我们首先定义问题,然后介绍我们的框架。
2.1 问题表述
文本到SQL(Structured Query Language,结构化查询语言)任务可以分为三个连续的子任务:
-
SQL生成:给定一个自然语言问题 qqq 和一个由表 T={T1,T2,…,Tn}\mathcal{T} = \left\{ {{T}_{1},{T}_{2},\ldots ,{T}_{n}}\right\}T={T1,T2,…,Tn} 和列 C=\mathcal{C} =C= {c11,c21,…,cji,…,cmnn}\left\{ {{c}_{1}^{1},{c}_{2}^{1},\ldots ,{c}_{j}^{i},\ldots ,{c}_{{m}_{n}}^{n}}\right\}{c11,c21,…,cji,…,cmnn} 组成的关系数据库 D\mathcal{D}D ,其中 cji{c}_{j}^{i}cji 表示表 Ti{T}_{i}Ti 的第 jjj 列,目标是生成一个初始的SQL查询 sss 。因此,此子任务的输入是 qqq 和 D\mathcal{D}D ,输出是 sss 。
-
错误识别:给定自然语言问题 qqq 、关系型数据库 D\mathcal{D}D 以及生成的 SQL 查询 sss ,此子任务旨在确定 sss 是否正确。如果查询存在错误,输出应包含具体的错误类型和信息。因此,输入包括 q,Dq,\mathcal{D}q,D 和 sss ,输出是关于 sss 是否正确的二元指示,若适用,还会包含相关的错误类型和信息。
-
SQL 错误修正:如果在前一个子任务中识别出 SQL 查询 sss 存在错误,那么这个最终子任务将处理该查询的修正。给定自然语言问题 qqq 、关系型数据库 D\mathcal{D}D 、初始 SQL 查询 sss 、错误类型和错误信息,目标是生成一个修正后的 SQL 查询。因此,此子任务的输入包括 q,D,sq,\mathcal{D}, sq,D,s 、错误类型和错误信息,输出是修正后的 SQL 查询 s′{s}^{\prime }s′ 。
在本文中,我们专注于错误识别子任务。具体来说,我们定义了三种错误类型,即系统错误(System Error)、框架错误(Skeleton Error)和4283值错误(4283 Value Error)。
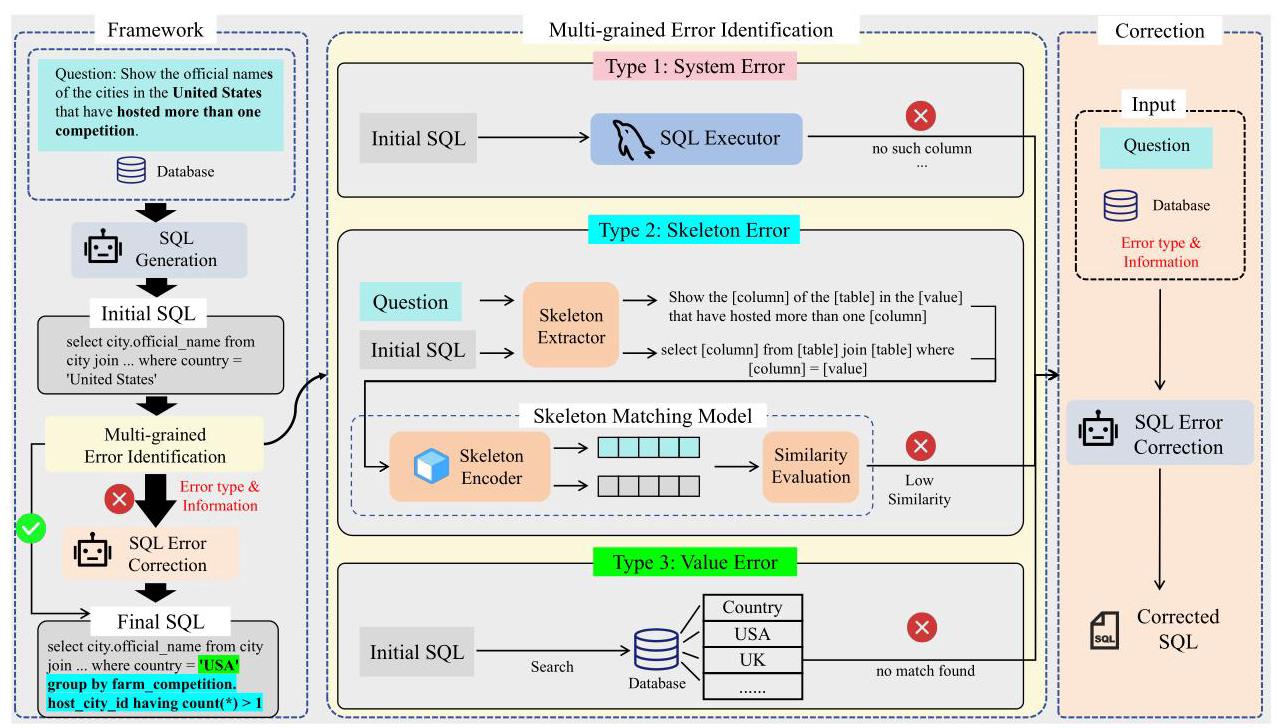
图3:采用多粒度错误识别方法的生成-识别-纠正文本到SQL框架。
2.2 框架
如图3所示,整体的文本到SQL框架包括三个阶段:SQL生成、多粒度错误识别和SQL错误纠正。如上所述,本文的重点是错误识别。SQL生成和SQL错误纠正阶段可以直接利用现有的大语言模型。多粒度错误识别阶段由三个模块组成:系统错误识别模块、骨架错误识别模块和值错误识别模块。每个模块负责识别特定类型的SQL错误并提供相应的错误信息。
整个过程如下:我们使用大语言模型根据给定的自然语言问题和数据库模式生成初始SQL查询。生成的查询随后通过三个不同的模块进行错误识别。首先,系统错误识别模块使用SQL执行器来识别任何语法错误。其次,骨架错误识别模块利用基于对比学习的骨架匹配模型来确定SQL骨架是否与问题相符。最后,值错误识别模块检查问题中的值与数据库之间是否存在差异。通过利用这三个错误识别模块,我们对SQL查询进行分层错误识别。最后,将具体的错误信息提供给SQL纠错模型,以纠正识别出的错误。
3 方法
在本节中,我们将详细介绍文本到SQL的框架。SQL生成和SQL纠错中使用的大语言模型的提示细节可在附录A中找到。
3.1 SQL生成阶段
此阶段的目标是将一个问题和一个数据库模式作为输入,并输出SQL语句。这是一个模块化组件,可以用任何基于大语言模型的文本转SQL方法来替代。这些方法包括使用上下文学习直接利用开源和闭源大语言模型,或者使用文本转SQL数据集对开源大语言模型进行微调。该过程定义如下: s=LLM(q,D),(1) s = {LLM}\left( {q, D}\right) , \tag{1} s=LLM(q,D),(1) 其中 qqq 是问题, DDD 是数据库模式, sss 是生成的SQL语句。
3.2 错误识别阶段
此阶段将分别介绍用于识别系统错误、框架错误和值错误的模块。
3.2.1 系统错误识别
该模块主要检查生成的SQL语句中的语法错误。具体来说,我们通过分析SQL执行结果来确定是否存在语法错误。简单来说,任何无法正确执行的SQL语句都被认定为存在语法错误。这些错误可能包括表别名错误、连接列时出错、列名错误或关键字使用不当。为了便于纠正,我们将所有这些问题归类为系统错误,并收集相应的错误信息。
3.2.2 骨架错误识别
该模块旨在检测SQL骨架和问题骨架之间的意图不一致性。为实现这一目标,我们采用对比学习来帮助模型理解预期问题骨架和SQL骨架之间的潜在关系。一旦学习到这些隐藏的对应关系,我们就使用相似度阈值来确定问题骨架和SQL骨架是否匹配。
我们首先通过抽象特定的表名、列信息和值来提取问题 xxx 和SQL查询 yyy 的骨架,这一过程通过与数据库模式进行匹配来实现。如图3所示,对问题和SQL查询进行骨架化处理,使模型能够更专注于它们的底层结构。构建骨架后,我们使用对比学习来训练一个骨架匹配模型。目标是在表示空间中将相似问题和SQL查询的骨架拉近,同时将不同骨架的问题和SQL查询推开。我们认为这种方法增强了问题骨架和SQL查询骨架之间的匹配度。例如,问题中的“超过”一词可能对应SQL中的“having count”关键字,反映了相似的底层结构。
具体而言,我们将同一问题 - SQL对中的问题骨架和SQL骨架视为具有相同的标签。通过使用监督对比学习(Khosla等人,2020)损失函数,我们使具有相同意图的骨架的向量表示更加接近。此外,为了更好地捕捉骨架之间的对应关系,我们引入了难负样本,以帮助模型学习更具挑战性的语义场景。对于每个SQL骨架,我们选择一个多一个或 少一个公共关键字的变体作为难负样本。总体训练目标如下: Lout sup =∑i∈I−1∣P(i)∣∑p∈P(i)logexp(xi⋅yp/τ)∑a∈A(i)exp(xi⋅ya/τ)+N, {\mathcal{L}}_{\text{out }}^{\text{sup }} = \mathop{\sum }\limits_{{i \in I}}\frac{-1}{\left| P\left( i\right) \right| }\mathop{\sum }\limits_{{p \in P\left( i\right) }}\log \frac{\exp \left( {{x}_{i} \cdot {y}_{p}/\tau }\right) }{\mathop{\sum }\limits_{{a \in A\left( i\right) }}\exp \left( {{x}_{i} \cdot {y}_{a}/\tau }\right) + N}, Lout sup =i∈I∑∣P(i)∣−1p∈P(i)∑loga∈A(i)∑exp(xi⋅ya/τ)+Nexp(xi⋅yp/τ), (2)
其中 xi{x}_{i}xi 表示批次中的第i个问题骨架, yp{y}_{p}yp 表示批次中的第p个正SQL骨架, P(i)P\left( i\right)P(i) 表示批次中所有正样本的索引集, NNN 表示难负样本。
最后,通过评估问题骨架和SQL骨架之间的相似度来识别骨架错误。如果相似度得分低于预定义的阈值 τ\tauτ ,则认为该SQL存在骨架错误。
3.2.3 值错误识别
此模块主要处理问题中引用的值与数据库模式中存储的值之间的差异。例如,如果一个问题需要使用“男性”(Male)或“女性”(Female)按性别进行过滤,但数据库将这些值存储为 M\mathrm{M}M 或 F,就会出现不匹配的情况。如果 SQL 生成仅考虑查询信息而忽略了模式中的这些差异,可能会导致 SQL 查询返回空结果集。此模块旨在识别并纠正此类不一致情况,以防止查询执行期间出现错误。
具体而言,我们仅检查涉及过滤值的 SQL 查询。如果 SQL 查询返回空结果集,我们会将过滤值与数据库中的相应列进行比较。如果过滤值存在于相关列中,我们认为该 SQL 查询是正确的;如果在相应列中未找到过滤值,我们会将该 SQL 查询标记为可能存在错误。对于具有多个过滤值的查询,会对每个值单独进行检查;如果数据库中缺少任何一个值,该查询将被标记为可能存在错误。
实际上,返回空结果集的SQL查询也可能是正确的。此模块统一将其视为值错误。如果查询是正确的,后续的纠错模块将不会修改该SQL;如果查询不正确,后续的纠错模块将根据数据库对应列中的值对其进行修改。
3.3 纠错阶段
在此阶段,我们将从错误识别中获得的信息传递给各个纠错模型以执行SQL纠错。与SQL生成阶段一致,这是一个模块化组件,可以用任何基于大语言模型的文本到SQL方法进行替换。下面,我们将详细介绍使用文本到SQL数据集微调开源大语言模型的方法。一般流程在附录A中概述。
3.3.1 系统错误和骨架纠错
纠错模型以问题、数据库模式、错误信息和错误的SQL语句作为输入,并输出修正后的SQL查询。为了训练该模型,我们按照与SQL生成模块相同的流程,从训练集中随机选取了1000个示例。训练完成后,我们使用该模型对训练集中的剩余数据进行预测,如果执行结果与标准SQL(Gold SQL)结果不同,则将这些SQL查询标记为错误。通过反复采样和识别差异,我们总共收集了4921条错误的SQL查询。
我们将错误数据集分为两种不同类型的错误:系统错误和骨架错误。提示修正的具体细节见附录A。与SQL生成模型类似,我们的纠错训练数据集包含四个元素: Zc={\mathcal{Z}}_{c} =Zc= {(qi,Si,ei,si,si′)}i=1,..,N{\left\{ \left( {q}_{i},{\mathcal{S}}_{i},{e}_{i},{s}_{i},{s}_{i}^{\prime }\right) \right\} }_{i = 1,.., N}{(qi,Si,ei,si,si′)}i=1,..,N ,其中 qi,Si,ei,si{q}_{i},{\mathcal{S}}_{i},{e}_{i},{s}_{i}qi,Si,ei,si 和 si′{s}_{i}^{\prime }si′ 分别表示自然语言问题、对应的数据库模式、错误信息、错误的SQL和正确的SQL。我们微调SQL纠错模型 Mc{\mathcal{M}}_{c}Mc 的目标是最大化条件语言建模目标: maxMc∑(q,S,e,s,s′)∈Zc∑t=1∣s′∣PMc(st′∣q,S,e,s,s<t′), \mathop{\max }\limits_{{\mathcal{M}}_{c}}\mathop{\sum }\limits_{{\left( {q,\mathcal{S}, e, s,{s}^{\prime }}\right) \in {\mathcal{Z}}_{c}}}\mathop{\sum }\limits_{{t = 1}}^{\left| {s}^{\prime }\right| }{P}_{{\mathcal{M}}_{c}}\left( {{s}_{t}^{\prime } \mid q,\mathcal{S}, e, s,{s}_{ < t}^{\prime }}\right) , Mcmax(q,S,e,s,s′)∈Zc∑t=1∑∣s′∣PMc(st′∣q,S,e,s,s<t′), (3)
其中 st′{s}_{t}^{\prime }st′ 表示预期 SQL 的第 ttt 个标记。通过提供错误的指导和有缺陷的 SQL,模型会根据识别出的错误类型来纠正错误的 SQL。
3.3.2 值错误纠正
为了纠正数值错误,我们利用训练集中的可用信息训练了一个数值错误纠正模型。我们手动清理和处理了训练集中的数据,在这些数据中,问题所需的值与数据库中可用的值范围之间存在差距。基于问题值与数据库值范围之间的差异,我们构建了错误的SQL查询,总共得到247条记录。为了确保正确处理问题值不在数据库值范围内但空输出被认为是正确的情况,我们纳入了输出本身为空的场景。这样总共得到了532条记录。
为了弥补所需值与数据库中现有值之间的差距,我们从SQL查询的每个过滤列中随机选择30个值。与我们的SQL纠错模型类似,训练集 ZD{\mathcal{Z}}_{D}ZD 由 {(qi,vi,si,si′)}i=1,…,N{\left\{ \left( {q}_{i},{v}_{i},{s}_{i},{s}_{i}^{\prime }\right) \right\} }_{i = 1,\ldots , N}{(qi,vi,si,si′)}i=1,…,N 组成,其中 qi,vi,si{q}_{i},{v}_{i},{s}_{i}qi,vi,si 和 si′{s}_{i}^{\prime }si′ 分别表示自然语言问题、SQL过滤列的值、错误的SQL和纠正后的SQL。我们微调值纠错模型 MD{\mathcal{M}}_{D}MD 的目标是最大化条件语言建模目标: maxMD∑(q,v,s,s′)∈ZD∑t=1∣s′∣PMD(st′∣q,v,s,s<t′),(4) \mathop{\max }\limits_{{\mathcal{M}}_{D}}\mathop{\sum }\limits_{{\left( {q, v, s,{s}^{\prime }}\right) \in {\mathcal{Z}}_{D}}}\mathop{\sum }\limits_{{t = 1}}^{\left| {s}^{\prime }\right| }{P}_{{\mathcal{M}}_{D}}\left( {{s}_{t}^{\prime } \mid q, v, s,{s}_{ < t}^{\prime }}\right) , \tag{4} MDmax(q,v,s,s′)∈ZD∑t=1∑∣s′∣PMD(st′∣q,v,s,s<t′),(4) 其中 st′{s}_{t}^{\prime }st′ 表示预期SQL的第 ttt 个标记。
我们采用值纠错模型来解决问题值与数据库值之间的差距,并结合值错误识别模块进行综合评估。我们将问题、被过滤的SQL列值以及错误的SQL查询输入到模型中。然后,模型会处理这些输入,要么修正SQL查询以使其符合适当的值范围,要么判定无需修正。
4 实验
我们的实验分为两部分。第一部分评估多粒度错误识别方法(MGEI,Multi-grained Error Identification)的性能。第二部分评估现有方法引入我们的方法后文本到SQL转换性能的整体提升情况。本节介绍实验设置和结果。4286
| 方法 | 精确率(%) | 召回率(%) | $\mathbf{{F1}\left( \% \right) }$ |
| 代码骆驼(Codellama) | 32.2 | 75.5 | 45.2 |
| 聊天生成预训练变换器(ChatGPT) | 65.0 | 53.3 | 58.6 |
| 动态交互网络 - 结构化查询语言(DIN - SQL) | 75.3 | 54.5 | 63.2 |
| MAC - 结构化查询语言(MAC - SQL) | 75.5 | 51.6 | 61.4 |
| DEA - 结构化查询语言(DEA - SQL) | 69.1 | 56.4 | 62.1 |
| 紫色 | 100 | 37.4 | 54.4 |
| 多基因表达指数(MGEI) | 94.1 | 49.4 | 64.8 |
表1:在Spider数据集上,我们的方法与先前方法在识别错误方面的比较。
4.1 实验设置
4.1.1 数据
我们使用Spider数据集评估了我们的方法,该数据集是一个用于文本到SQL任务的综合跨领域集合。每个实例包含一个针对特定数据库定制的自然语言问题及其对应的SQL查询。由于测试子集尚未公开,我们选择了Spider开发子集进行评估。
我们使用在Spider验证集上经过微调的CodeLlama - 13b - Instruct模型生成的SQL查询作为评估错误识别性能的数据集。该数据集总共包含257个错误的SQL查询。错误类型的详细分布如图4所示。
4.1.2 评估指标
在评估模型识别SQL错误的能力时,不仅要尽可能多地检测出错误,还要确保检测到的错误确实准确,这一点至关重要。因此,我们使用精确率、召回率和F1分数作为评估指标。同时,我们遵循先前建立的研究方法,采用精确集匹配准确率(Exact-set-match accuracy,EM)和执行准确率(Execution accuracy,EX)进行评估。参照先前的研究(钟等人,2020),我们使用可从https://github.com/taoyds/test-suite-sql-eval获取的评估脚本。
4.1.3 参数设置
我们使用2块英伟达RTX A6000 GPU(Nvidia RTX A6000 GPUs)和PyTorch 2.0.0进行了所有实验。我们方法的参数配置如下:在所有模块中,我们使用了CodeLlama - 13b - Instruct和CodeLlama - 13b - Python模型(罗齐尔等人,2023年 (Roziere et al., 2023))。为了微调大语言模型(LLMs),我们采用了低秩自适应(LoRA)方法(胡等人,2021年 (Hu et al., 2021))以实现高效适配,将参数设置为 r=16\mathrm{r} = {16}r=16 和 α=64\alpha = {64}α=64 ,学习率设置为 5×10−45 \times {10}^{-4}5×10−4 。在骨架错误识别模块中,我们将阈值 τ\tauτ 设置为0.3,以过滤掉骨架不匹配的SQL查询。
| 方法 | 期望最大化算法(EM) | 扩展(EX) |
| 微调 | ||
| 代码羊驼-130亿参数指令模型(CodeLlama-13b-Instruct) | 72.7 | 75.0 |
| +多粒度嵌入交互(MGEI) + 代码羊驼(CodeLlama) | 73.2 | 78.6 |
| 代码羊驼-130亿参数- Python版(CodeLlama-13b-Python) | 70.6 | 72.3 |
| +多粒度嵌入交互(MGEI) + 代码羊驼(CodeLlama) | 72.3 | 76.5 |
| 上下文学习(In-context Learning) | ||
| 动态交互网络 - SQL(GPT4)(DIN - SQL (GPT4)) | 54.3 | 76.8 |
| +多粒度实体交互 + GPT4(+MGEI + GPT4) | 56.0 | 81.4 |
| 对话自适应交互式学习 - SQL(ChatGPT)(DAIL - SQL (ChatGPT)) | 26.7 | 74.4 |
| +多粒度实体交互 + ChatGPT(+MGEI + ChatGPT) | 27.2 | 76.0 |
表2:MGEI作为插件在不同方法中的性能表现。所有结果均通过运行作者发布的代码获得。
4.1.4 基线方法
在比较错误识别性能时,我们通过测试各种方法的纠错模块进行了全面比较,这些方法包括CodeLlama - 13b - Instruct、零样本设置下的ChatGPT,以及其他方法,如DIN - SQL、MAC - SQL(王等人,2024年)、DEA - SQL(谢等人,2024年)和PURPLE(任等人,2024年)。使用CodeLlama - 13b - Instruct和ChatGPT直接进行SQL错误识别的提示词见附录B。对于其他自纠错方法,包括DIN - SQL、MAC - SQL和DEA - SQL,我们将它们的输出与初始SQL进行比较;如果输出不同,则认为该SQL存在错误。PURPLE仅识别产生执行错误的SQL;因此,我们将系统错误归类为错误SQL。我们对每种方法的错误识别能力进行了单独评估,并与我们自己的方法进行了比较。
为了评估我们的方法作为插件的有效性,我们使用了DIN - SQL(分解式交互自然语言到SQL生成器)和DAIL - SQL(动态自适应指令学习SQL生成器)来生成初始SQL查询。DIN - SQL探索了将复杂的文本到SQL任务分解为较小子任务的方法。DAIL - SQL比较了现有的提示工程方法,包括问题表示、示例选择和示例组织,并基于这些比较,提出了一种旨在克服当前方法局限性的新集成解决方案。对于DAIL - SQL,我们在零样本场景中使用ChatGPT,根据作者提供的代码生成SQL。此外,我们按照DAIL - SQL - SFT格式对CodeLlama - 13b - Instruct和CodeLlama - 13b - Python模型进行了微调,以生成初始SQL查询。这种方法使我们能够在多个模型上测试我们方法的有效性。
| Method | 简单 | 中等 | 困难 | 极难 | 全部 |
| 代码骆驼-130亿参数指令模型(CodeLlama-13b-Instruct) + 多粒度执行解释器(MGEI) + 代码骆驼-130亿参数指令模型(CodeLlama-13b-Instruct) | |||||
| 无错误识别 | 87.5 | 84.3 | 62.6 | 45.2 | 75.0 |
| 带系统错误识别 | 87.5 | 86.3 | 64.9 | 45.2 | 76.4 |
| 带系统和骨架错误识别 | 88.7 | 86.1 | 64.9 | 45.2 | 76.6 |
| 带系统、骨架和值错误识别 | 91.5 | 87.7 | 67.2 | 47.0 | 78.6 |
| DAIL - SQL(ChatGPT)+ 多粒度错误识别(MGEI)+ ChatGPT | |||||
| 无错误识别 | 89.9 | 79.8 | 62.6 | 48.8 | 74.4 |
| 带系统错误识别 | 90.3 | 80.5 | 63.8 | 50.0 | 75.1 |
| 带系统和骨架错误识别 | 90.3 | 80.5 | 63.8 | 50.0 | 75.1 |
| 带系统、骨架和值错误识别 | 92.3 | 80.5 | 63.8 | 52.4 | 76.0 |
表3:不同文本到SQL方法下MGEI模块执行准确率的消融研究。
4.2 有效性
首先,我们评估模型识别错误的能力。然后,我们展示模型纠正这些错误后的性能提升。
4.2.1 错误识别性能
我们在Spider数据集上比较了MGEI与其他六种方法在错误检测方面的性能。表1展示了每种方法在三个指标(精确率、召回率和F1分数)上的结果。
首先,从精确率的角度来看,各模型在错误识别的准确性上存在显著差异。其中,PURPLE(紫色)表现突出,精确率为 100%{100}\%100% ,是所有方法中最高的,这是因为它仅专注于纠正系统错误。然而,MGEI方法也表现出色,精确率达到了94.1%。这表明MGEI在识别错误方面非常准确。相比之下,Codellama(代码骆驼)的精确率最低,仅为 32.2%{32.2}\%32.2% ,凸显了它在准确检测错误方面的重大缺陷。
其次,从召回率的角度来看,Codel - lama方法在尽可能多地识别错误方面表现出色,召回率达到了75.5%,这表明它能够检测出大部分错误。然而,尽管Codel - lama的召回率很高,但其精确率较低,这意味着虽然它能识别出大量错误,但也会引入相当数量的误报。相比之下,MGEI的召回率为 49.4%{49.4}\%49.4% ,在测试的方法中处于中等水平。ChatGPT的召回率为 53.3%{53.3}\%53.3% ,与MGEI相近,而其他方法如DIN - SQL(54.5%)和MAC - SQL(51.6%)也有相当的召回率,但都没有超过Codel - lama。
最后,在评估整体F1分数时,MGEI(多粒度错误识别模型)以 64.8%{64.8}\%64.8% 的分数领先,凸显了其在精确率和召回率之间的出色平衡。尽管CodeLlama(代码羊驼模型)实现了最高的召回率,但其F1分数仅为45.2%,这表明其较低的精确率显著影响了整体性能。另一方面,虽然PURPLE(紫色模型)拥有极高的精确率,但其较低的召回率导致F1分数仅为54.4%,使其在整体性能上无法超越MGEI。其他方法,如DIN - SQL(动态交互网络 - 结构化查询语言方法)(63.2%)、MAC - SQL(多跳注意力计算 - 结构化查询语言方法)(61.4%)和DEA - SQL(深度嵌入聚合 - 结构化查询语言方法)(62.1%),在F1分数上也不及MGEI。这证明了我们的方法在识别三种类型错误方面的有效性和全面性。
4.2.2 改进效果
表2展示了我们的方法在不同设置下与基线方法相比的性能。在所有情况下,我们的方法都持续提高了执行准确率(EX)。当与CodeLlama - 13b - Instruct集成时,我们的方法使执行准确率提高了3.6%,达到78.6%。同样,与CodeLlama - 13b - Python结合使用时,我们的方法使执行准确率有 4.2%{4.2}\%4.2% 的提升。值得注意的是,当与DIN - SQL + GPT4结合时,我们的方法同时提高了精确匹配率(EM)和执行准确率,执行准确率有显著的 4.6%{4.6}\%4.6% 提升。虽然与DAIL - SQL + ChatGPT结合时提升幅度较小,但我们的方法仍然取得了更高的分数,证明了它作为一种通用插件在各种模型和提示下的有效性。
4.3 消融实验
在消融实验中,我们通过在CodeLlama - 13b - Instruct和DAIL - SQL(ChatGPT)模型上进行测试,研究了我们方法中不同模块对执行准确率的影响。结果总结在表3中。
从CodeLlama - 13b - Instruct模型开始,在没有任何错误识别的情况下生成SQL的基线性能(初始SQL)达到了 75.0%{75.0}\%75.0% 的准确率。当引入系统错误识别模块时,有明显的提升,整体准确率上升到76.4%。添加骨架错误识别进一步将准确率略微提高到76.6%。当包含值错误识别时,观察到最显著的提升,整体准确率提高到78.6%,在困难和极难类别中提升尤为明显。DAIL - SQL(ChatGPT)模型也呈现出类似的模式。基线(初始SQL)的准确率为74.4%,在集成系统错误识别模块后提高到75.1%。添加骨架错误识别模块后性能保持稳定,当三个识别模块全部集成时,准确率上升到76.0%,在简单和极难类别中提升最为显著。这些结果强调了每个模块在提高我们方法的整体执行准确率方面的关键作用。
5 相关工作
在本节中,我们回顾并总结了与我们的研究最为相关的研究。
5.1 文本转SQL
早期的方法主要依赖精心设计的规则和模板(波佩斯库等人,2004年),这些方法仅在简单的数据库场景中有效。然而,随着数据库变得更加复杂,为每个场景创建特定的规则或模板变得越来越具有挑战性。近年来,深度神经网络的发展通过实现将用户查询自动映射到相应的SQL命令,显著推动了文本到SQL任务的进展(苏茨克弗等人,2014年;郭等人,2019年;徐等人,2017年)。同时,像Spider(于等人,2018年)和BIRD(李等人,2024b)这样的大规模数据集已经发布。随后,具有卓越语义解析能力的预训练语言模型(PLMs)已成为文本到SQL系统的新范式(尹等人,2020年)。最近,基于大语言模型(LLMs)并利用上下文学习和微调范式的方法已成为主流,在文本到SQL任务中实现了最先进的准确率(李等人,2024a;江等人,2023a)。
5.2 自我修正
在推理过程中改进大语言模型(LLMs)的响应方面已经有了广泛的研究,包括在算术推理、代码生成和问答等领域(高等人,2023年;辛等人,2024年;布朗等人,2020年)。一些研究提出了自我修正方法,即大语言模型通过提示为自身生成反馈以修正其响应(苟等人,2023年;蒋等人,2023b)。此外,其他研究探索了利用外部信息来增强反馈,例如利用代码执行器等外部工具(陈等人,2023年)、搜索引擎的外部知识(蒋等人,2023c)或维基百科等来源的额外信息(余等人,2023年)。然而,近期研究也报告了负面结果,表明大语言模型可能并非总能进行自我修正(瓦尔米卡姆等人,2023年;斯特克利等人,2023年)。因此,我们从多个上下文视角评估SQL错误以确保准确性。
6 结论
在本文中,我们系统地研究了SQL生成错误,将其分为三种类型,并提出了一种多粒度识别方法,该方法可为有效纠错提供详细的错误信息。我们引入了一个基于对比学习的骨架匹配模块来检测骨架错误,并通过难负样本增强表示能力。我们的实验验证了我们的方法作为插件的通用性,它提高了开源和闭源大语言模型的性能。消融实验进一步强调了我们方法中每个模块的重要性。这种创新的分类和模块化设计为更准确地处理SQL错误提供了新的视角。
局限性
首先,我们的方法主要侧重于基本语法设计,如MySQL,未涉及多数据库的专用语法或窗口函数等复杂结构。这一局限性降低了该方法在多数据库环境中处理复杂查询的能力。其次,尽管该方法旨在作为插件广泛使用,但在与现有系统集成时可能会遇到兼容性问题,尤其是在使用自定义或遗留SQL生成工具的环境中。这通常需要额外的定制或调整,增加了集成的复杂性和维护成本。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)