通过ollama部署自己的大模型
在上篇,我已经分享了如何部署ollama上面开源的大模型,在这里,进一步部署通过微调的大模型。这篇主要参考,不过我这里是linux系统。
在上篇,我已经分享了如何部署ollama上面开源的大模型,在这里,进一步部署通过微调的大模型。这篇主要参考5-llama.cpp量化实例_哔哩哔哩_bilibili,不过我这里是linux系统。
llama.cpp
llama.cpp是一种推理框架,用于加载和运行llama语言模型,可以通过量化如4-bit、8-bit操作,降低对显卡的要求。
https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
conda create -n llamacpp python=3.9
conda activate llamacpp
pip install -r requirements/requirements-convert-hf-to-gguf.text
cmake -B build
cmake --build build --config Release将hf格式转化为gguf格式
python convert-hf-to-gguf.py /home/usr/... --outtype f16 --outfile /home/usr/.../name.gguf第一个路径为从Hugging Face上下载的模型地址,第二个路径为保存gguf格式的地址,注意要带后缀gguf。
量化
这步的主要目的是将模型量化,可以降低对显卡的需求。8b的原型在我这个8GB显存的显卡上,token输出很慢,但是量化到4-bit,速度就会提升很多。
首先进入这个路径
cd llama.cpp/build/bin./llama-quantize /home/usr/.../dsr1-8b-ft.gguf /home/usr/.../dsr1-8b-ft-q4.gguf q4_0注意,Windows和linux系统有些许差别。Windows输入下列指令
cd llama.cpp/build/bin/Release
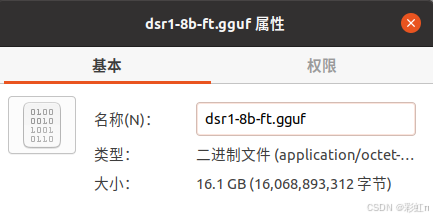
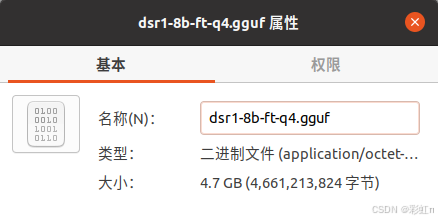
quantize.exe /.../your.gguf /.../your-q4.gguf q4_0这里看下两个gguf占用的空间,没有量化的有16GB,4-bit量化只有4.7GB。
部署
在上述的gguf同文件夹下,建立一个Modelfile文件
touch Modelfile修改Modelfile,将FROM后面的路径替换为自己的路径。
FROM /home/usr/.../your.gguf
# sets the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# sets the context window size to 4096, this controls how many tokens the LLM can use as context to generate the next token
PARAMETER num_ctx 4096
# sets a custom system message to specify the behavior of the chat assistant
SYSTEM You are Mario from super mario bros, acting as an assistant.同样通过ollama部署,先运行ollama服务。 在Modelfile的路径下开一个终端,输入
ollama create 名字 -f Modelfile查看可以运行的模型
ollama list
输入以下指令,运行模型
ollama run name
可以看到成功运行了。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)