回顾-大模型位置编码
本文系统梳理了Transformer模型中的位置编码方法。首先介绍了绝对位置编码(正弦编码和可学习编码)及其局限性;然后阐述了相对位置编码(T5式)的优势;重点分析了旋转位置编码(RoPE)的数学原理,通过复数旋转操作巧妙实现相对位置编码;最后总结了位置编码外推技术(ALiBi、PI、NTK-aware、YaRN),这些方法通过插值、动态调整等技术使模型能处理超长序列。
备注:回顾之前的位置编码,为了方便理解记忆,在此总结归纳(注:笔者水平有限,若有描述不当之处,欢迎大家留言)。
阐述的思维逻辑:
绝对位置编码------------->相对位置编码------------>旋转位置编码----------->位置编码的外推
|-->正弦位置编码 |-->T5式 |-->ROPE |-->ALiBi;PI
|-->可学习位置编码 |-->1d-ROPE |-->NTK-aware
|-->2d-ROPE |-->YaRN
|-->3d-ROPE
上面按照总结,给出大概的位置编码分类和具有代表性的一些编码方式(还有更多位置编码在此不一一列举)
一 基础理解
位置编码(Positional Encoding):是自然语言处理中用来表示词语在句子中位置信息的一种方法。因为像Transformer这样的模型不会自动捕捉词的顺序,所以需要通过位置编码给每个词加上一个独特的标记,帮助模型理解词语的相对位置和上下文关系
绝对位置编码:通过为序列中每个位置生成唯一的向量,将位置信息显式地加入到输入中表示。
相对位置编码:扑捉序列中元素之间的相对顺序,而不是绝对位置。相对位置编码使用的是序列中两个元素之间的相对距离,而非它们的绝对位置。
旋转位置编码:一种改进的相对位置编码,利用旋转变换将位置信息直接嵌入到词向量中,能够更好地处理长序列的相对位置信息。出发点通过绝对位置编码的方式实现相对位置编码,将位置编码转化为复数域的旋转操作:对查询(Query)和键(Key)向量分别施加旋转矩阵,使得它们的相对位置差通过旋转角度自然体现。
位置编码的外推:模型在不经微调的情况下,在超过训练长度的文本上测试,依然能较好的维持其训练效果(免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型)
二 原理理解
2.1 绝对位置编码
2.1.1 正弦位置编码
2.1.1 .1 公式
通过sin函数和cos函数交替来创建 positional encoding,其计算positional encoding的公式:
其中pos表示为每个token在整个序列中的位置,相当于是0, 1, 2, ...(序列长度如32,如128等),d代表位置向量的维度(是embedding的维度,transformer论文中设置的512维)。i索引维度是向量维度对2求商并取整,它的取值范围是[0,1,2.....d//2],对此2i直接相乘即可。
2.1.1 .2 例子
比如token长度为32,token维度为512
当pos=0; i为[0,1,2,3....(511-1)//2]
当pos=1; i为[0,1,2,3....(511-1)//2]
当pos=32; i为[0,1,2,3....(511-1)//2]
2.1.2 可学习位置编码
最朴素的做法就是直接将位置编码作为一个可学习的向量learnable embeddings(如随机初始化一个512token长度x768特征维度),BERT中用的就是这种。但是这种方法的缺点是没有外推性,如果token长度变化则无法处理了。
2.1.3 小结
优点:简单易实现, 只需在输入前添加一层固定的编码
显示顺序信息, 每个位置有一个唯一的编码,可以清晰地表达位置
缺点:难以处理长序列, 对于长序列,编码可能变得不准确或无法捕捉更远的关系
难以推广到变长序列, 绝对编码是固定的,无法很好地适应序列长度变化的情况
2.2 相对位置编码
2.2.1 T5式
2.2.1 .1 公式
T5模型的相对位置编码作用在第一层编码器和解码器的自注意力模块中
注:相比与常见的注意力分数计算方法,T5模型在计算时省去了标准化缩放
。
相对位置编码则是一个标量数值,一共有32种类型,即T5中一共是32种相对位置。然而,T5的输入长度是512 token,相对的位置类型远大于32种。所以,T5使用了一种分区的方式将任意多的相对位置信息映射到32种最终类型上
2.2.2 小结
优点:处理长距离依赖更有效,能够更好地捕捉长距离依赖关系,因为它关注的是元素间的相对位置
对变长序列更灵活,相对位置编码不依赖于绝对位置,能够更好地适应不同长度的序列
缺点:实现更复杂,相对位置编码需要对注意力机制进行修改,增加了实现的复杂度
计算量大,相对位置编码可能会导致计算的复杂性增加
2.3 旋转位置编码(ROFORMER)
2.3.1 公式
旋转式位置编码在构造查询矩阵q和键矩阵k时,根据其绝对位置引入旋转矩阵R:
旋转矩阵R的设计为正交矩阵,且应满足,使得后续注意力矩阵的计算中隐式地包含相对位置信息。
2.3.2 证明
备注:需要知道复数一些原理(;
)
首先假设 和
,添加位置信息存在函数f,使其
,
假设公式成立:
推出
一: 假设q,k只有两维 因此
在
上式可通过复数与三角函数之间的关系写为:
用二维向量表示为:
同理
因此 带入上式,化简得
化简得
因此证明 成立
其中为旋转矩阵R,
二 扩展到高维
一中是假定“token维度”是2,而对于d >= 2,则是将词嵌入向量元素按照两两一组分组,每组(两个元素)应用上面一的旋转操作,可以将对应的token转化到不同位置。另外每组的旋转角度计算方式同正弦位置编码的角度:
角度如上正弦位置编码那样计算即可。
2.3.3 小结
优点:更有效的相对位置编码,RoPE在处理长序列时比传统的相对位置编码更有效
与transformer兼容性更高:无需修改原有的Transformer架构即可使用
缺点:复杂度增加,尽管与相对位置编码相比更为有效,但仍然增加了计算的复杂性
2.4 位置编码的外推
2.4.1 ALiBi
本文的做法是不添加position embedding,不向单词embedding中添加位置embedding,而是根据token之间的距离给 attention score 加上一个预设好的偏置矩阵,比如q和k相对位置差 1 就加上一个 -1 的偏置,两个 token 距离越远这个负数就越大,代表他们的相互贡献越低。由于注意力机制一般会有多个head,这里针对每一个head会乘上一个预设好的斜率项(Slope)。举个例子,原来的注意力矩阵为A,叠加了ALiBi后为A+BXm如下所示:
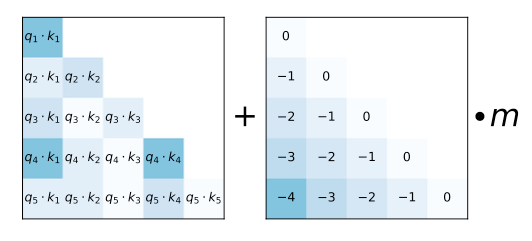
2.4.2 PI
2.4.2.1 原理
位置线性内插的核心思想是通过缩放位置索引,使得模型能够处理比预训练时更长的序列,而不损失太多性能
其中 x 是 token embedding,m 是位置。对于一个超过之前最大长度 L 的样本 (长度为 L’),通过缩放将所有位置映射回 L 区间,每个位置都不再是整数。通过这种方式在长样本区间训练 1000 步,就能很好的应用到长样本上。
当 =>
直接修改
的大小。
2.4.2.2 小结
位置线性内插虽然效果不错,但是插值方法是线性的,这种方法在处理相近的token时可能无法准确区分它们的顺序和位置。
2.4.3 NTK-aware
2.4.3.1 原理
通过缩放 base控制低频分量,使得序列长度扩大 k 倍时,低频对应的角度变化范围线性映射匹配原有分布(内插),而高频近似保持不变(外推)。
借鉴 16进制可以表示更大范围数的原理![]() ,
,
对上述角度也采用类似方法:
最低频为 引入变量参数
使其为
,让它与内插
相等,解
最后角度 其中m是从1开始
即 其中k为扩大的倍数;i为[0,1,2,d//2]
2.4.3.2 小结
与 PI相比,该方法在扩展非微调模型的上下文大小方面表现得更好。在某些维度会稍微外推到“越界”值,因此使用“NTK-aware”插值进行微调会产生较差的结果。对于给定的上下文长度扩展,比例值必须设置为高于预期比例。
2.4.4 YaRN
2.4.4.1 NTK-by-parts原理
在ROPE中,给定上下文L,有些维度d,其中波长比预训练期间看到的最大上下文长度长(),这表明某些维度的嵌入可能分布不均匀在旋转域中。扩展 RoPE 的上下文长度时,不应对所有维度统一插值,而应 区别对待高频与低频维度。
备注:【基于正弦位置编码 中的角度变量 ;波长的引入
低维度 → 高频 → 捕捉局部(相对)位置信息;高维度 → 低频 → 捕捉全局(绝对)位置信息】
因此:1 如果波长远小于上下文大小 ,不进行插值;
2 如果波长等于或大于上下文大小 ,只进行插值并避免任何推断(与之前的“NTK-aware”方法不同);
3 中间的尺寸可以同时具有两者,类似于“NTK-aware”插值。
引入原始上下文大小L和波长λ之间的比率
为了定义上述不同插值策略的边界,引入两个额外的参数 ,
。 如果
,认为波长
远小于上下文大小L ,不进行插值;如果
,我们就认为波长
等于或大于上下文大小L,只进行插值并避免任何推断。因此,定义一个斜坡函数 :
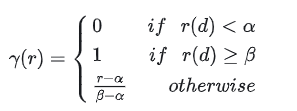
2.4.4.2 NTK-by-parts小结
这种改进的方法比之前的PI和“NTK-aware”插值方法表现得更好,无论是使用非微调模型还是微调模型。对于Llama系列模型,和
的最佳值为
=1 和
=32。
2.4.4.3 Dynamic NTK 原理
当使用RoPE插值方法来扩展上下文大小而无需进行微调时,希望模型在超出原训练长度时性能能 平滑退化,而不是在插值比例 s 过大时 突然崩溃。PI中s = L′/L,其中L是训练的上下文长度,L′是新扩展的上下文长度在“动态NTK”方法中,我们动态计算比例s如下:
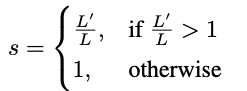
为此,动态NTK方法(Dynamic NTK)不固定比例 s=L′/L=,而是根据 实际推理时上下文长度 动态调整 s。这样,当输入序列逐渐超过训练长度 L 时,模型能自然地过渡到新的上下文范围,
实现平滑的性能衰减而非突然失效。
2.4.4.3 YaRN原理
经过前面的推导 yarn=NTK-by-parts+ attention-scaling
在解决了前面描述的局部距离的问题,更大的距离也必须在阈值α处进行插值以避免外推。我们发现,由于平均最小距离随着令牌数的增加而变得更加接近,它使得注意力softmax分布变得“更尖锐”(即降低了注意力softmax的平均熵)。即插值导致远距离衰减的效果减弱,网络“更关注”较多的token,这种分布偏移导致LLM的输出出现退化。 那我们可以反过来 提高 softmax 的温度 t > 1,让分布更平滑。
三 代码实现
3.1 正弦位置编码
class PositionEmbedding1d(nn.Module):
def __init__(self, dim,max_len=512):
pe = torch.zero(max_len, dim)
position = torch.arange(0,max_len).unsqueeze(1)
#todo 10000^(-2i/d)=e^(-2i/d)ln(10000)
div_term = torch.exp(torch.arange(0,dim,2)*-(math.log(10000.0)/dim))
pe[:,0::2] = torch.sin(position * div_term)
pe[:,1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.regist_bugger('pe', pe)
def forward(self,x):
x = x + self.pe[:,:x.size(1)]
return x3.2 可学习位置编码
import torch.nn as nn
class PositionalEmbedding(nn.Module):
def __init__(self, max_len, d_model):
super(PositionalEmbedding, self).__init__()
self.embedding = nn.Embedding(max_len, d_model)
def forward(self, x):
positions = torch.arange(0, x.size(1)).unsqueeze(0).to(x.device)
return self.embedding(positions)todo.......
四 参考文献
SIN:https://arxiv.org/pdf/1706.03762
T5式:https://arxiv.org/pdf/1910.10683
RoPE:https://arxiv.org/pdf/2104.09864
https://spaces.ac.cn/archives/8397二维位置的旋转式位置编码: https://spaces.ac.cn/archives/8397
ALiBi:https://arxiv.org/pdf/2108.12409

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)