模型研究| DeepSeek-V3能像外科医生一样推理吗?
在之前的测试中,通过直接输入图像标记,在简单的问答任务中取得了良好的性能。另一方面,DeepSeek-VL2和DeepSeek-Janus-Pro-7b在多个指标上与GPT-4o相比表现出优越的性能,展示了它们即使在给定简单提示的情况下也能捕捉图像的整体背景并提供详细的外科描述的能力。数据集,系统地评估了 GPT-4o 与开源模型 DeepSeek-Janus-Pro-7b、 DeepSeek-V

引言
机器人辅助手术(RAS)是现代医疗保健中的一个关键进展,旨在协助手术过程并实现远程操作。随着人工智能和机器人控制系统的进步,当代 RAS 技术在控制方面展现了卓越的精度。
尽管显著减轻了外科医生的工作负担,当前的 RAS 严重依赖专家医生来控制操纵器并发出精确命令。培训一名熟练的外科医生需要大量的时间和努力,导致高度合格的专业人员短缺。因此,开发一个能够理解和分析手术场景的强大AI模型具有重要意义,这可能会替代专家医生的角色。
最近出现的一个开源大型语言模型 DeepSeek,与其他开源模型相比,逐渐展现出卓越的性能,同时使用较少的激活参数。通过训练框架的综合优化,DeepSeek 模型实现了成本效益高的训练和高推理效率。此外,借助强化学习,它表现出卓越的推理能力。鉴于其卓越的表现以及成本效益高的训练和推理,DeepSeek 模型有望成为外科视觉语言学习领域的一个有前途的解决方案。
尽管DeepSeek模型在一般任务中表现出色,但在 RAS 领域中情境理解和推理的有效性仍不确定。为了弥补这一差距,本文使用了两个公开可用的机器人手术数据集 EndoVis18 和 CholecT50 数据集,系统地评估了 GPT-4o 与开源模型 DeepSeek-Janus-Pro-7b、 DeepSeek-VL2 和 DeepSeek-V3 在生成准确且情境相关的回应方面的能力。
实施方法
在本文的实证研究中,包括了 GPT-4o、DeepSeek-Janus-Pro-7b 和 DeepSeek-VL2 作为比较模型。
基于语言的模型DeepSeek-V3不具备直接读取图像的能力。因此,本文使用SEED分词器(一种与预训练的 unCLIP 稳定扩散对齐的图像分词技术)来生成图像标记。给定图像标记,向 DeepSeek-V3 指定一个额外的提示以便其理解:“你得到了图像标记,你应该将其解释为一张图片
问题(单句问答)

问题(详细描述)

实验结果分析
单句问答任务的表现
数据集
-
EndoVis18数据集中的变量选择包含13个不同的短语,涵盖手术器械运动、目标问题和物体位置,分别有8个、1个和4个短语。
-
CholecT50数据集中的短语分为三类:手术器械、目标和动作,分别包含5个、8个和13个短语。
分析
-
在EndoVis18数据集上,DeepSeek模型的整体表现更好。在器械运动类别中的表现未达标准,这表明DeepSeek和GPT4-o在从静态图像中推断器械运动方面面临挑战。此外,本文观察到DeepSeek-Janus-Pro-7b在所有动作分类中主要选择“空闲”类别。由于“空闲”标签是最常报告的结果,因此整体表现看起来比其他模型更高。然而,这并不意味着DeepSeek-Janus-Pro-7b在分类器械运动方面具有优越的能力。
-
在CholecT50数据集上,DeepSeek-V3的性能与GPT-4o相当。对各种短语的评估显示,分析手术组织是对GPT-4o和DeepSeek系列最大的挑战。相比之下,手术器械如剪刀、钳子和钩子更容易识别。这可能是因为MLLM训练数据中日常使用工具的频率高于手术组织。虽然DeepSeek-V3的表现与GPT-4o相当,但DeepSeek-Janus-Pro-7b和DeepSeek-VL2的结果较差。此外还观察到DeepSeek-VL2往往不遵循“只回答你的选择”的指示,有时为其选择提供冗长的解释。这些缺点表明DeepSeek-Janus-Pro-7b和DeepSeek-VL2不仅难以理解手术场景,还可能面临遵循指示的问题。总之,尽管现有的多模态语言模型在全面理解涉及器械、组织和动作的手术场景方面存在局限,DeepSeek-V3在手术背景下的简单问答任务中表现出了可与之相媲美甚至更优的性能。
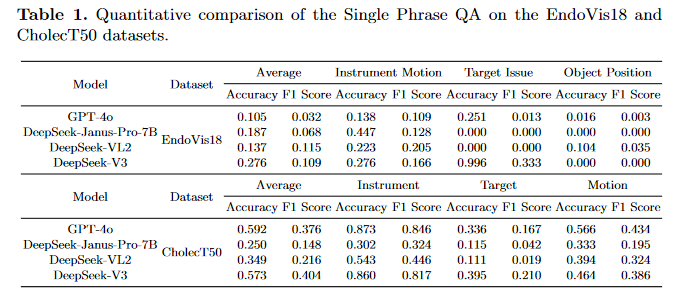
视觉问答(Visual QA)的表现
分析
-
尽管DeepSeek-V3是一个基于语言的模型,但通过直接将图像标记输入大型语言模型(LLM),它在CIDEr和ROUGE-1两个指标上均展现了卓越的性能。通过适当设计的引导提示,DeepSeek-V3表现出能够理解提出的问题,并根据其图像感知能力生成与手术相关的词汇内容。此外,DeepSeek-VL2和DeepSeek-V3在六个不同指标上的一致表现突显了它们在准确捕捉关键概念和关注相关视觉内容方面的效率。通过评估,本文还观察到,即使在提示中加入“用简短句子回答”时,DeepSeek-Janus-Pro-7b也倾向于提供简短答案。
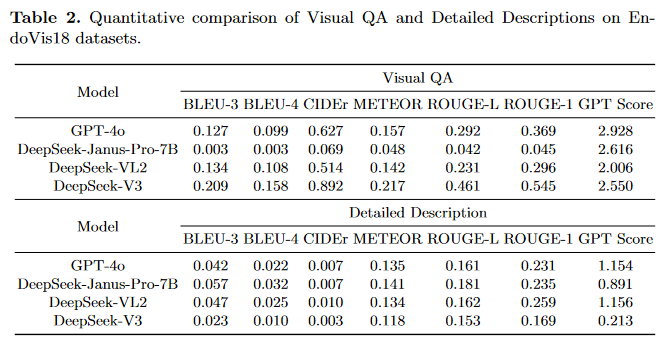
细节描述(Detailed Description)的表现
分析
-
从表2中可以观察到,所有模型在BLEU和CIDEr指标上的表现都不佳。低性能可以归因于比较句子的过长,这使得模型在保持n-gram精度和在此任务中实现合理相似性方面面临挑战。由于详细描述任务通常生成较长的文本,输出内容的顺序和文本表达风格可能会显著影响其评估分数。然而,其生成的文本始终包含手术环境中的仪器、动作和组织细节。
-
DeepSeek-V3提供一般描述的能力有限,因为DeepSeek-V3仅是一个语言模型。在之前的测试中,通过直接输入图像标记,在简单的问答任务中取得了良好的性能。然而,当执行详细描述任务时,这样的语言模型难以提供有意义的解释。另一方面,DeepSeek-VL2和DeepSeek-Janus-Pro-7b在多个指标上与GPT-4o相比表现出优越的性能,展示了它们即使在给定简单提示的情况下也能捕捉图像的整体背景并提供详细的外科描述的能力。从图2可以明显看出,DeepSeek-VL2和DeepSeek-Janus-Pro-7b生成的文本并不冗长;相反,它倾向于提供简洁的总结,同时提供更准确的内容。这表明这两个模型在理解和总结图像方面具有很大的能力。然而,它们缺乏对手术场景的理解限制了它们在这一领域的适用性。总结来说,DeepSeek-VL2在详细描述任务中能够实现合理的结果;然而,由于缺乏手术知识,该模型无法提供准确的答案并且未能包含手术场景所需的所有必要细节。
来源:Can DeepSeek Reason Like a Surgeon? An Empirical Evaluation for Vision-Language Understanding in Robotic-Assisted Surgery (2025年3月发表于arxiv)
内容来源:IF 实验室

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)