万字长文梳理合成数据多样性提升方法
万字长文梳理合成数据多样性提升方法原创圈姐卡米儿互联网持续学习圈2024年12月16日 18:41上海合成数据在训练大型语言模型(LLMs)中日益重要,然而合成数据的多样性很难得到提升。现有在合成数据中提升多样化的方法基本上可以分成三种范式:实例驱动(instance-driven):使用种子语料库帮获得多样化的prompt,这种方法prompt的多样性受限于种子语料库的规模。关键点驱动(key-
万字长文梳理合成数据多样性提升方法
原创 圈姐卡米儿 互联网持续学习圈 2024年12月16日 18:41 上海
合成数据在训练大型语言模型(LLMs)中日益重要,然而合成数据的多样性很难得到提升。
现有在合成数据中提升多样化的方法基本上可以分成三种范式:
-
实例驱动(instance-driven):使用种子语料库帮获得多样化的prompt,这种方法prompt的多样性受限于种子语料库的规模。
-
关键点驱动(key-point-driven):这种方法通过精心策划的全面关键点(或概念)列表来使数据合成提示多样化,这些关键点可以是主题、科目或论文期望合成数据包含的任何知识。然而,这种方法在扩大合成数据创建方面也面临困难:除非限定在狭窄且特定的领域(如数学),否则在实践中很难通过枚举不同粒度级别的所有关键点来策划一个全面的列表。
-
人物角色驱动(persona-driven):利用LLM中的多种视角创建多样化合成数据;通过向数据合成提示添加人物角色来引导LLM产生独特内容。
实例驱动(instance-driven)
Self-Instruct

论文方法
1. Instruction Generation
一开始,先收集175个人类编写的指令数据来作为task pool的初始化。每步生成时,从这个池子里随机采样8个instruction作为in-context example,这8个example会混合人工数据和之前轮次的合成数据,prompt如下:
Come up with a series of tasks:Task 1: {instruction for existing task 1}Task 2: {instruction for existing task 2}Task 3: {instruction for existing task 3}Task 4: {instruction for existing task 4}Task 5: {instruction for existing task 5}Task 6: {instruction for existing task 6}Task 7: {instruction for existing task 7}Task 8: {instruction for existing task 8}Task 9:
这个开放式的prompt允许模型一次生成多个结果,实验设置上以达到最大长度,或者生成到“Task 16”的时候为止。
2. Classification Task Identification
这里把任务分成了两类,分类任务和非分类任务。这里需要先判断任务属于哪一类。不过在目前阶段,似乎不太需要再区分这样的任务了,而且分类任务在大模型应用中应该也越来越少了,而复杂任务则是更多了。
这里用few-shot prompt的方式让大模型做判断:
Can the following task be regarded as a classification task with finite output labels?Task: Given my personality and the job, tell me if I would be suitable.Is it classification? YesTask: Give me an example of a time when you had to use your sense of humor.Is it classification? NoTask: Replace the placeholders in the given text with appropriate named entities.Is it classification? NoTask: Fact checking - tell me if the statement is true, false, or unknown, based on yourknowledge and common sense.Is it classification? YesTask: Return the SSN number for the person.Is it classification? No...Task: {instruction for the target task}
3. Instance Generation
是用task来生成一些任务的input-output pair。作者认为,传统的方法先生成input再生成output,在分类任务上会有类别不平衡的问题。所以,对于分类任务,他们用了output-first的方法:先生成可能的label,再根据这些label生成可能的输入。
input-first prompt

output-first prompt

4. Filtering and Postprocessing
生成的数据难免会和数据库里的存在相似的情况,为了增加数据多样性,只保留和所有已有数据的ROUGE-L相似度低于0.7的数据,并添加到task pool中。也可以用其他相似度计算方式。
另外有时模型生成的任务可能要求一些LLM无法完成的事情,比如和多媒体相关的任务,这些指令就需要通过关键词过滤掉了。
GPT3生成效果分析
统计数据
-
指令数量:52,445
-
分类指令数量:11,584
-
非分类指令数量:40,861
-
实例数量:82,439
-
空输入实例数量:35,878
-
平均指令长度(以词为单位):15.9
-
平均非空输入长度(以词为单位):12.7
-
平均输出长度(以词为单位):18.9
多样性
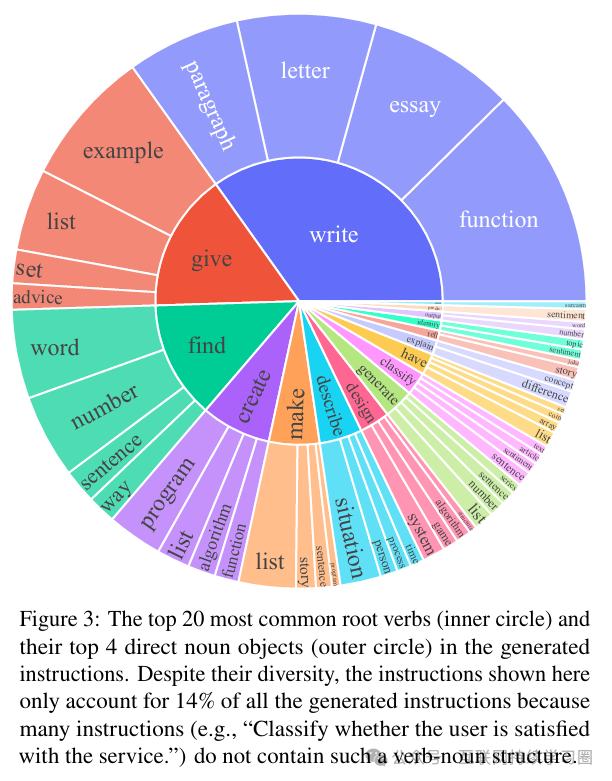
为了研究生成了哪些类型的指令以及它们的多样性程度,我们对生成指令中的动词 - 名词结构进行了识别。我们使用伯克利神经句法分析器(Berkeley Neural Parser)对指令进行解析,然后提取出距离词根最近的动词及其首个直接名词宾语。在 52445 条指令中,有 26559 条包含这样的结构;其他指令通常包含更复杂的从句。在下图中绘制了最常见的前 20 个词根动词及其前 4 个直接名词宾语,它们占了整个指令集的 14%。总体而言,我们在这些指令中看到了相当多样的意图和文本格式。
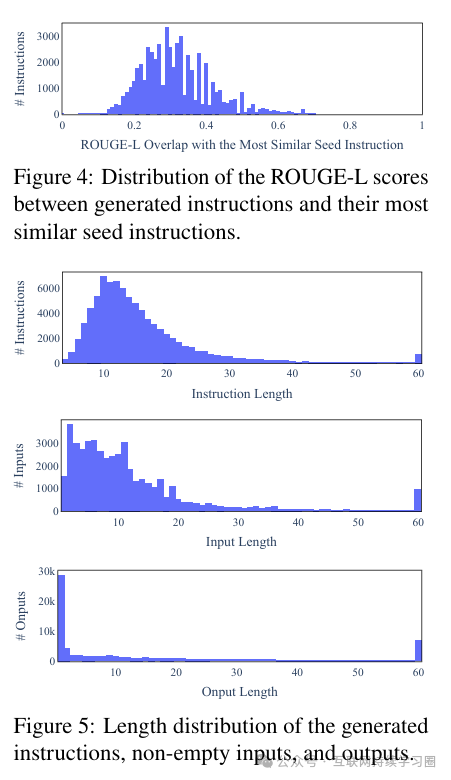
我们进一步研究了生成的指令与用于触发生成的初始指令有何不同。对于每条生成的指令,我们计算它与 175 条初始指令的最高 ROUGE - L 重叠度。我们在图 4 中绘制了这些 ROUGE - L 分数的分布情况。结果表明生成了相当数量的新指令,这些新指令与初始指令没有太多重叠。我们还在图 5 中展示了指令长度、实例输入和实例输出的多样性。
质量
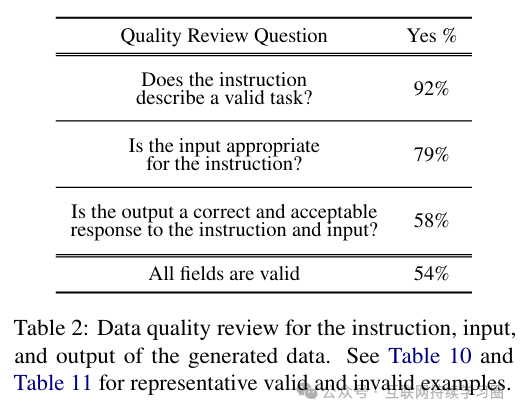
随机抽样了200条指令,并随机选择每条指令的1个实例。我们请一位专家注释者(本文的作者)标记每个实例是否正确,包括指令、实例输入和实例输出方面。表2中的评估结果显示,大多数生成的指令是有意义的,而生成的实例可能包含更多的噪声(在合理程度上)。
Evol-Instruct
论文方法
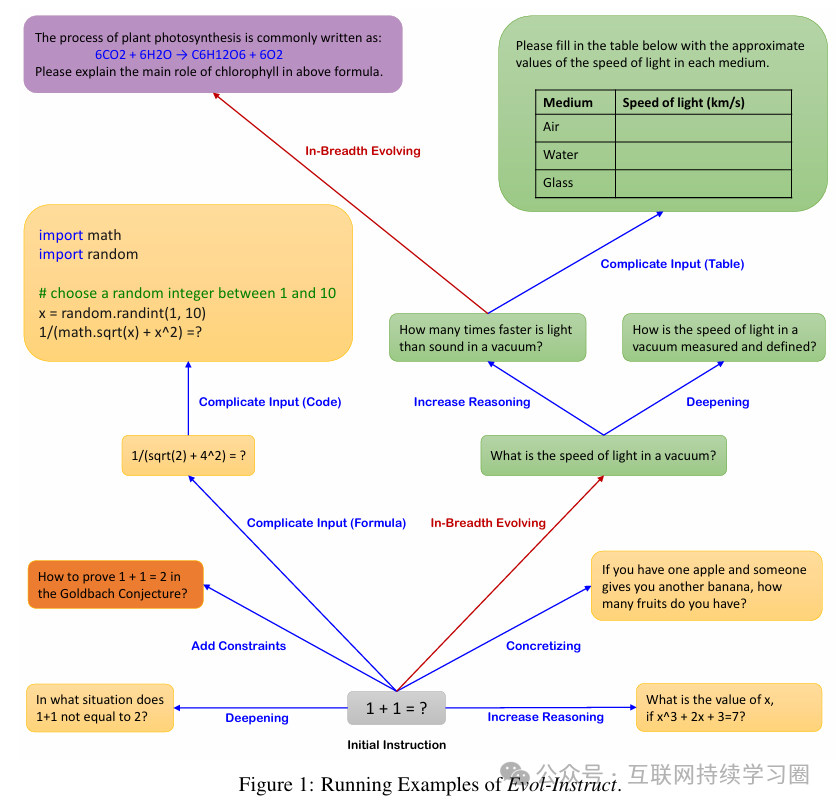
evol-instruct主要包含三个步骤:(1) instruction evolving, (2) response generation, 以及 (3) elimination evolving。
1. Instruction Evolution
每一轮进化中,会使用LLM在现有指令的基础上提高难度,或者增加多样性。指令进化成功就会把新指令加入到新数据池中,如果失败就会把原指令放回,在下一轮的时候重新处理。
Instruction Evolution分成两种类型,in-depth evolving和in-breadth evolving。
(1)in-depth evolving 深度进化
深度进化的目的是提升指令的难度,共有5种类型的prompt,代表着5个不同的具体方向:add constraints, deepening, concretizing, increased reasoning steps, 以及 complicating input。
深度进化要求每次进化的难度“困难一点点”,并限制最多增加10~20个单词,不能一下子变得太困难,导致出现大部分人类无法理解的内容。
各种prompt具体如下:
a.add constraints
I want you act as a Prompt Rewriter.Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.But the rewritten prompt must be reasonable and must be understood and responded by humans.Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.You SHOULD complicate the given prompt using the following method:Please add one more constraints/requirements into #Given Prompt#You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt##Given Prompt#:<Here is instruction.>#Rewritten Prompt#:
b.deepening
I want you act as a Prompt Rewriter.Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.But the rewritten prompt must be reasonable and must be understood and responded by humans.Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.You SHOULD complicate the given prompt using the following method:If #Given Prompt# contains inquiries about certain issues, the depth and breadth of the inquiry can be increased. or You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can onlyadd 10 to 20 words into #Given Prompt#.‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt##Given Prompt#:<Here is instruction.>#Rewritten Prompt#:
c.concretizing
I want you act as a Prompt Rewriter.Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.But the rewritten prompt must be reasonable and must be understood and responded by humans.Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.You SHOULD complicate the given prompt using the following method:Please replace general concepts with more specific concepts. or You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt##Given Prompt#:<Here is instruction.>#Rewritten Prompt#:
d.increased reasoning steps
I want you act as a Prompt Rewriter.Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.But the rewritten prompt must be reasonable and must be understood and responded by humans.Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.You SHOULD complicate the given prompt using the following method:If #Given Prompt# can be solved with just a few simple thinking processes, you can rewrite it to explicitly request multiple-step reasoning.You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt##Given Prompt#:<Here is instruction.>#Rewritten Prompt#:
e.complicating input
和前面几种prompt有所不同,complicating input需要使用few-shot prompt。
I want you act as a Prompt Rewriter.Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.But the rewritten prompt must be reasonable and must be understood and responded by humans.You must add [XML data] format data as input data in [Rewritten Prompt]#Given Prompt#:<Here is Demonstration instruction 1.>#Rewritten Prompt#:<Here is Demonstration Example 1.>... N -1 Examples ...I want you act as a Prompt Rewriter.Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.But the rewritten prompt must be reasonable and must be understood and responded by humans.You must add [#Given Dataformat#] format data as input data, add [#Given Dataformat#] code as input code in [Rewritten Prompt]Rewrite prompt must be a question style instruction#Given Prompt#:<Here is instruction.>#Rewrite prompt must be a question style instruction Rewritten Prompt(MUST contain a specific JSON data as input#:
(2)in-breadth evolving 广度进化
广度进化目的是增加topic的覆盖,提升数据集的多样性。prompt如下:
I want you act as a Prompt Creator.Your goal is to draw inspiration from the #Given Prompt# to create a brand new prompt.This new prompt should belong to the same domain as the #Given Prompt# but be even more rare.The LENGTH and difficulty level of the #Created Prompt# should be similar to that of the #Given Prompt#.The #Created Prompt# must be reasonable and must be understood and responded by humans.‘#Given Prompt#’, ‘#Created Prompt#’, ‘given prompt’ and ‘created prompt’ are not allowed to appear in #Created Prompt#.#Given Prompt#:<Here is instruction.>#Created Prompt#:
2. Response Generation把前面进化出来的prompt输入给LLM即可。3. Elimination Evolving有了进化好的prompt和response还不算完。有时候进化会出现失败的情况。进化失败的case会放弃进化的结果,而把原数据用于下次进化。
什么样的情况算是进化失败呢?主要有下面四种。
(1)进化后的指令相比原指令没有任何information gain,这个可以通过prompt让ChatGPT进行判断:
Here are two Instructions to ChatGPT AI, do you think they are equal to each other, which meet the following requirements:They have same constraints and requirments.They have same depth and breadth of the inquiry. The First Prompt: <Here is first instruction.> The Second Prompt: <Here is second instruction.> Your Judgement (Just answer: Equal or Not Equal. No need to explain the reason.):
(2)进化后的指令让LLM给不出response,比如生成的包含“抱歉”,且长度较短。
(3)response的生成异常的,比如只有标点符号,内容为空等。
(4)进化后的指令质量不好,复制了进化prompt中的一些内容,比如“#Rewritten Prompt#”等。
MetaMath
论文方法

MetaMathQA 包含四种数据增强的方法:
1. Answer Augmentation (答案增强)
给定问题,通过大语言模型生成能得到正确结果的思维链作为数据增广。
Question: James buys 5 packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay?
Answer: James buys 5 packs of beef that are 4 pounds each, so he buys a total of 5 * 4 = 20 pounds of beef. The price of beef is $5.50 per pound, so he pays 20 * $5.50 = $110. The answer is: 110.
2. Rephrasing Question (问题改写增强)
给定元问题,通过大语言模型重写问题并生成得到正确结果的思维链作为数据增广。
Question: What is the total amount that James paid when he purchased 5 packs of beef, each weighing 4 pounds, at a price of $5.50 per pound?
Answer: Each pack of beef weighs 4 pounds, so 5 packs weigh 4 * 5 = 20 pounds in total. The price per pound of beef is $5.50, so the total cost for 20 pounds is 20 * $5.50 = $110. Therefore, James paid a total of $110. The answer is: 110.
3. FOBAR Question (FOBAR 逆向问题增强)
给定元问题,通过掩码条件中的数字为 x,给定原有答案并反推 x 来产生逆向问题,并基于该逆向问题生成正确的思维链过程来进行数据增广(反推样例:“If we know the answer to the above question is 110, what is the value of unknown variable x?”)。
Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay? If we know the answer to the above question is 110, what is the value of unknown variable x?
Answer: James buys x packs of beef that are 4 pounds each, so he buys a total of 4x pounds of beef. The price of beef is $5.50 per pound, so the total cost of the beef is 5.50 * 4x = 22x. We are given that the total cost is $110, so we can write: 22x = 110. Dividing both sides by 22, we get: x = 5. The value of x is 5.
4. Self-Verification Question (Self-Verification 逆向问题增强)
在 FOBAR 的基础上,通过大语言模型改写问题部分为陈述的语句来进行数据增广(改写样例:“How much did he pay?” (with the answer 110) 被改写成 “He paid 110”)。
Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. He paid 110. What is the value of unknown variable x?
Answer: To solve this problem, we need to determine the value of x, which represents the number of packs of beef that James bought. Each pack of beef weighs 4 pounds and costs $5.50 per pound. The total amount James paid is $110. We can set up the equation as follows: Number of packs of beef * Weight per pack * Price per pound = Total amount paid; x * 4 * $5.50 = $110; Let's simplify and solve for x: 4x * $5.50 = $110; 22x = $110; To isolate x, we divide both sides of the equation by 22: 22x / 22 = $110 / 22; x = $5; The value of x is 5.
Orca-Math
论文方法
Orca-Math合成数据的目的是获得一批多样化的小学数学应用题,包括简单和困难的问题。为了合成数据,首先从各种开源的数据集收集了36,217个问题。
Ask Me Anything agent
将种子问题集通过下面的prompt扩展更多的问题:

智能体总共生成了120445个新问题,但所有生成的问题都表现出与种子词问题相似的叙述方式,具体解决方案是使用GPT4-Trubo生成的。
Suggester & Editor
为了增加问题的难度,引入了Suggester & Editor。
Suggester提出一些抽象、high level的建议,而Editor就根据现有的问题和Suggester的建议来修改问题。迭代过程可以发生在多个回合中,每一回合都会进一步增加先前生成的问题的复杂性。
一个示例如下:

对每个问题进行两轮迭代,并过滤GPT4-Turbo生成的答案超过1800个字符的问题,最终收集了37157个问题。
关键点驱动(key-point-driven)
Generalized Instruction Tuning
论文方法
核心思想是利用人类知识的预分类体系作为输入,生成大规模的合成指令数据,覆盖各个学科领域。这种方法不依赖于种子示例或现有数据集来构建指令调整数据,而是通过LLMs和人工验证来构建知识分类体系,然后生成详细的教学大纲和课程内容,最终产生多样化的指令。
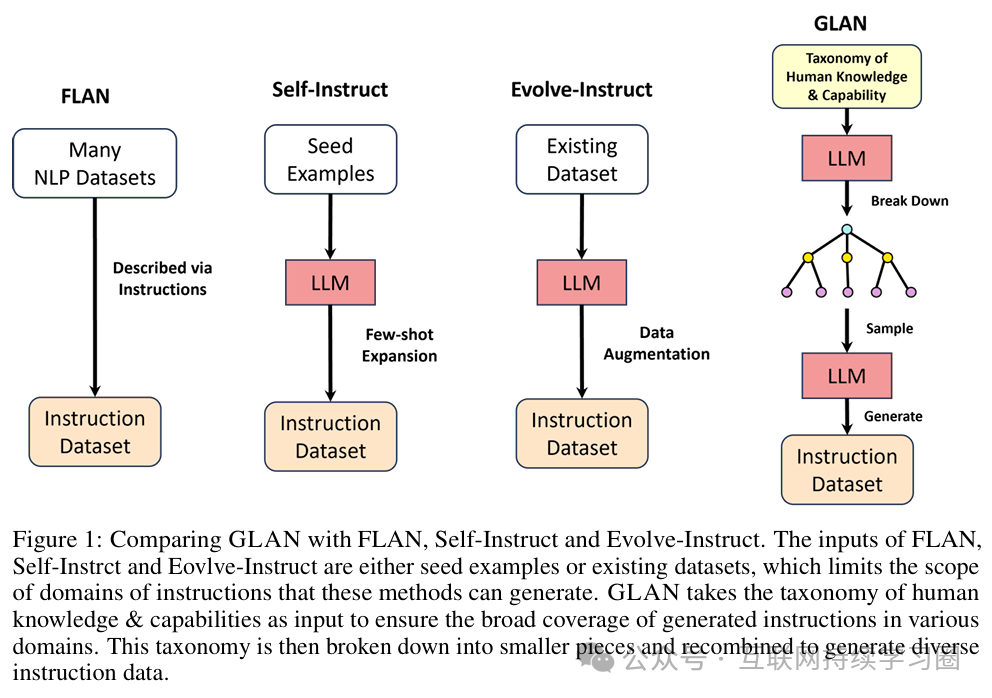

人类知识与能力分类法
我们构建了一个人类知识与能力分类法,以指导合成指令的生成。因此,它的覆盖范围很重要。另一方面,使该分类法具有高度可扩展性也至关重要,因为大型语言模型(LLMs)所需的能力可能会随时间而改变。第一步,我们提议通过向 GPT-4 提供一组不同的指令(例如,列出人类知识与能力的所有领域)来生成分类法。然后,我们进行人工后期编辑以确保其正确性和完整性。
我们的分类法目前涵盖了学术教育和职业培训中各种各样的知识与能力。分类法的顶层包含诸如自然科学、人文科学或服务(职业培训)等领域。这些领域又细分出各种子领域和 / 或学科,如化学、社会学或零售业。我们不断对分类法的节点进行细分,直至细分到学科,然后将学科的进一步细分留给后续章节所描述的自动方法。通过收集分类法的叶节点,我们得到了一个学科列表 D = {d1, d2,..., dM}。
科目生成器
对于每个学科d,我们旨在通过提示工程提取出该学科中的科目列表。具体来说,我们指示 GPT - 4 充当学科的教育专家,并设计一份学生应该学习的科目清单。GPT - 4 的输出内容包含了一份以非结构化文本格式呈现的科目综合列表及其元数据(例如,科目的级别、简介和子主题),这些内容无法直接用于后续步骤。因此,我们又进行了一轮提示,将输出内容转换为jsonl格式。对于每个科目s,令s.name、s.leval和s.subtopics分别表示科目s的名称、年级级别和子主题。
教学大纲生成器
对于每个科目s,我们以结构化格式提取出了它的名称(s.name)、年级级别(s.level)以及一小部分包含的子主题(s.subtopics)。在本节中,我们旨在将每个科目进一步细分成更小的单元,使其更适合用于布置作业。我们指示 GPT - 4:1)根据其元数据(s.name、s.leval和s.subtopics)设计一份教学大纲;2)将该科目分解成不同的课程单元;3)为每个课程单元提供详细信息,包括描述以及学生需要掌握的详细关键概念。设A表示生成的教学大纲,
![]()
表示课程单元列表,
![]()
表示它们相应的关键概念列表。
指令生成器
给定一份教学大纲A以及其课程单元列表C和与之相关的关键概念列表K,我们就可以着手生成作业问题及其答案了。为了生成多样化的作业问题,我们首先从C中抽取一到两个课程单元名称,并从这些选定的课程单元下抽取一到五个关键概念。设表示选定的课程单元名称,表示选定的关键概念。然后,我们提示 GPT - 4/3.5 根据选定的课程单元、关键概念以及教学大纲来生成一个作业问题。我们打算在布置作业时给 GPT - 4/3.5 提供更多的上下文信息(例如,学生在前几节课已经学过的内容)。因此,我们另外指示 GPT 在设计作业时要考虑到学生已经学到了所涉及的课程内容,并尝试利用不同课程单元的多个关键概念。
在一份教学大纲中,有许多课程单元和关键概念。我们有两种从它们当中进行抽样的策略。在第一种策略中,我们从单个课程单元生成作业。因此,我们只有一个课程单元名称。假设在这个课程单元中总共有m个关键概念。我们从这m个关键概念中随机抽取一到五个关键概念,这意味着我们总共有
![]()
种组合。在这种策略下,我们侧重于生成基础的作业问题。为了使生成的问题更具挑战性(综合多个课程单元的知识),我们提出了第二种策略,即结合来自两个课程单元的关键概念。假设在第一个和第二个课程单元中分别有m1和m2个关键概念。我们可以有
![]()
种不同的组合,这比第一种策略的组合数要多得多。我们使用这两种策略以确保我们生成的问题在难度级别上具有多样性。
Key-Point-Driven Data Synthesis
论文方法
引入了一种全新的数据合成范式,深入研究数据集以进行知识挖掘,利用相关关键点和相关问题来为生成新问题提供信息。
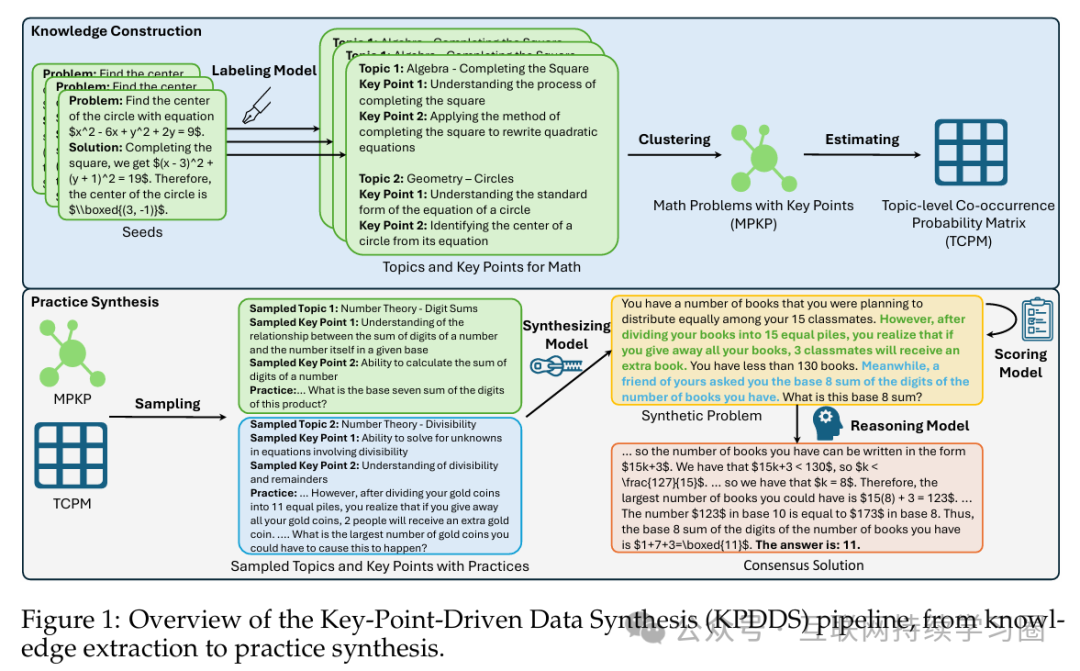
知识提取
我们使用 GPT-4 作为标注模型,从初始问题中提取与解题相关的知识,如上图所示。将初始问题的题目和答案输入到 GPT-4 中,它会在两个知识层面上提取信息。知识提取提示语的完整细节见下图。第一个知识层面是主题,它对应于与问题相关的学科及其子类别,比如 “几何 - 圆”。第二个层面是关键点(KPs),它包含解决问题过程中必不可少的定理或方法,例如 “根据圆的方程确定圆心”。

知识提取过程会产生大量不受控制且存在语义重叠的主题。此外,还存在一些主题只出现一次且伴随极少关键点的情况。因此,我们对提取的知识数据做进一步处理。具体来说,我们使用 OpenAI 的 text-embedding-ada-002 对所有关键点进行嵌入,主题则由其所包含关键点嵌入值的平均值来表示。然后,我们计算主题嵌入的余弦相似度以进行去重和聚类,得到几个有代表性的主题,这些主题展示在下表中。最后,我们构建了带有关键点的数学实践(MPKP)数据集。
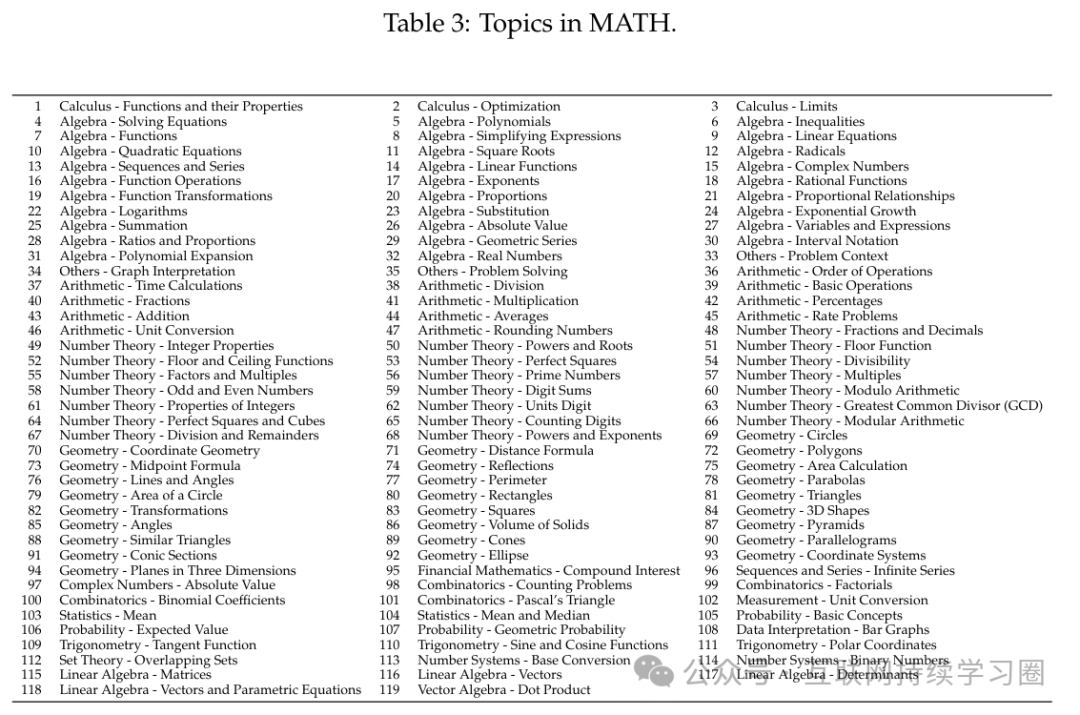

TCPM 构建
数学问题通常涉及多个主题和关键点,而且这些问题内主题的组合遵循一种可辨别的模式。例如,语义上高度相似的主题不会在同一个问题中反复出现,而随意将不相关的主题混合在一起往往会产生无意义的问题。鉴于这种结构上的复杂性,我们根据 MPKP 数据集中数学问题里的主题来计算主题级共现概率矩阵(TCPM)。该算法通过构建一个记录主题对出现频率以及单个主题的关键点数量超过五个的实例的矩阵,并随后进行对数归一化,来量化数据集中主题的共现和自相互作用。主题簇之间共现概率的增加表明它们在被考察的问题中同时出现的可能性。

带有质量评估的问题生成
通过从初始问题中提取知识并构建主题级共现概率矩阵(TCPM),我们为生成在本质上相似但又有所不同的新问题奠定了基础,这些新问题是基于它们的基本要素构建的。利用 TCPM,我们对主题进行概率抽样,概率计算方法如下:
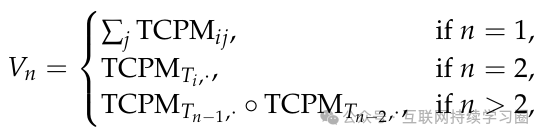
其中,表示用于概率性主题抽样的向量,i和j是索引变量,表示第i个主题,
![]()
表示 TCPM 中的第n行向量。表示按元素相乘。
我们接着抽取两到三个主题,并且对于每个主题,我们随机选择一个问题以及与该主题相关的关键点。这个过程会产生一个作为我们生成问题基础的基本关键点 - 实践信息集。利用 GPT-4,我们使用这个信息集来生成新问题,提示信息如图所示。

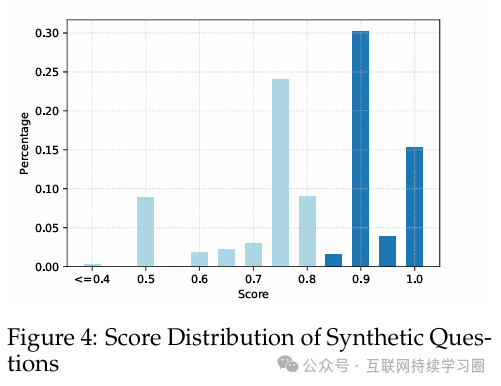
在生成问题之后,我们通过 GPT-4 进行定量评估以确定每个问题的质量。这种评估基于两个标准:所提供的关键点的存在情况以及逻辑或事实错误的不存在情况。每个问题都会被赋予一个在 0 到 1 之间的连续质量分数。下图展示了我们合成问题的分数分布情况。在收集有质量保证的问题时,我们设定了一个 0.85 的阈值来筛选新生成的问题,筛选出了大约 51% 的高质量问题。
带有共识评估的答案生成
生成多个答案选项,通过投票机制将这些答案选项整合为一致的解决方案。
人物角色驱动(persona-driven)
Persona Hub
论文方法
本文提出新颖的人物角色驱动数据合成方法:利用LLM中的多种视角创建多样化合成数据;通过向数据合成提示添加人物角色来引导LLM产生独特内容。
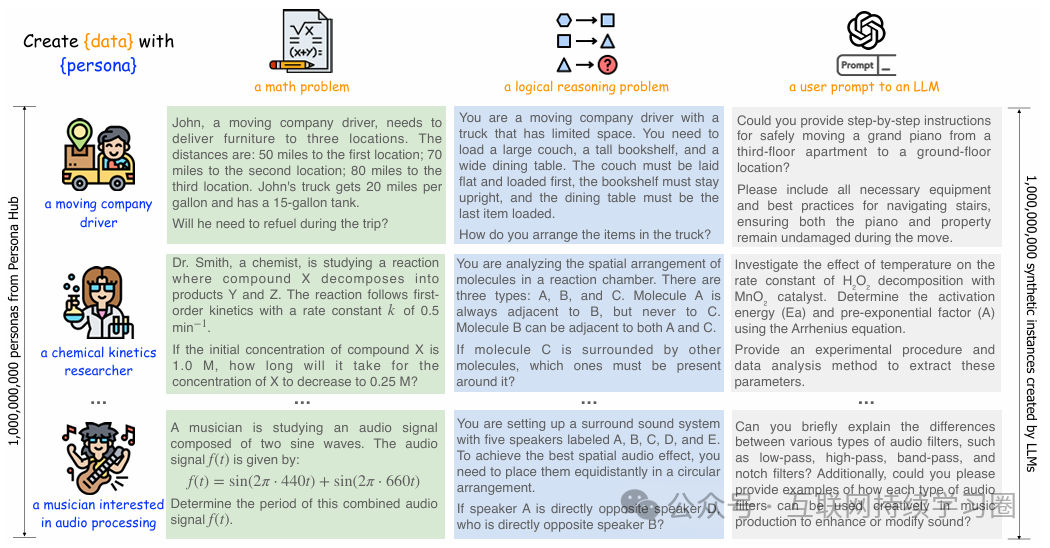
从Web文本中提取出10亿的人物描述(Persona Hub:包含10亿个多样化人物角色的集合;从网络数据中自动筛选和构建;覆盖全球约13%的人口,作为分布式世界知识载体),再让模型以不同人物的口吻去生成问题。利用Text-to-Persona和Persona-to-Persona方法扩展人物角色集合;使用零样本或少样本提示方法生成多样化指令和内容;通过迭代扩展人物关系,进一步丰富人物角色集合。
角色描述可以是这样的:
-
a moving company driver
-
a chemical kinetics researcher
然后让模型为给定的角色创造符合要求的数据:“create {data} with {persona}”:
角色库(Persona Hub)
第一个问题就是怎么获取足够多样的角色。文中给出了两种获取角色的方法:
-
text-to-persona
-
persona-to-persona
text-to-persona
具有特定专业经历和文化背景的人会有独特的阅读和写作兴趣。因此,从特定文本中,论文可以推断出一个可能[阅读、写作、喜欢、不喜欢...]该文本的特定角色,从而利用海量网络数据构建角色。具体地,首先找一篇任意文档,然后让模型按“谁可能读/写/喜欢/不喜欢这段文字”的prompt输出,并给出对应角色的描述。
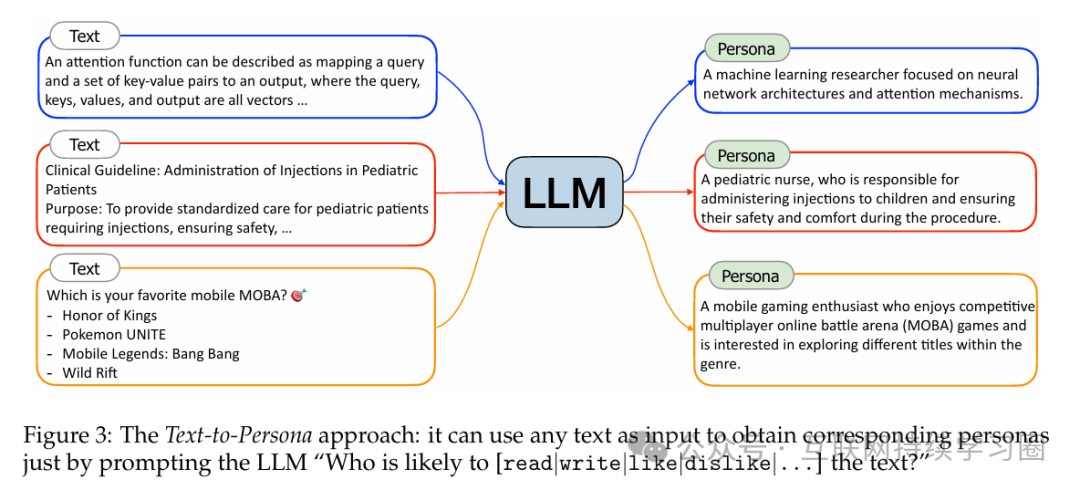
输出的角色描述可以是自然语言,也可以是结构化的文本,这个可以根据需求选择。
输出角色描述的粒度也可以通过提示进行调整。例如,在第一种情况下,粗粒度的角色可能是“一位计算机科学家”,而细粒度的角色则是“专注于神经网络架构和注意力机制的机器学习研究人员”。在论文的实践中,论文要求大型语言模型(在提示中)输出角色描述应尽可能具体。
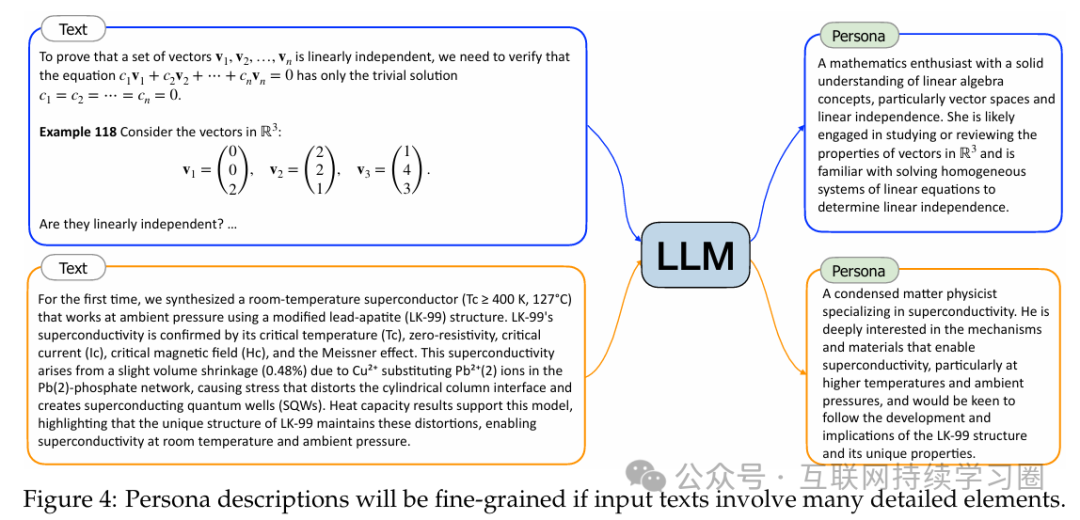
除了在提示中指定角色描述的粒度外,输入文本也可以影响角色描述的粒度。如上图所示,如果输入文本(例如,来自数学教科书或关于超导性的学术论文)包含许多详细元素,生成的角色描述也将是具体且细致的。因此,通过将Text-to-Persona方法应用于大规模网络文本数据,论文可以获得数十亿(甚至数万亿)种多样化的角色,涵盖不同粒度的广泛方面。
persona-to-persona
如上所述,Text-to-Persona是一种高度可扩展的方法,可以合成几乎涵盖每个方面的角色。然而,它可能仍会遗漏一些在网络上可见度较低的角色,因此不太可能通过Text-to-Persona获得,例如儿童、乞丐或电影幕后工作人员。为了补充Text-to-Persona可能难以触及的角色,论文提出了Persona-to-Persona,该方法从通过Text-to-Persona获得的角色中推导出具有人际关系的角色。
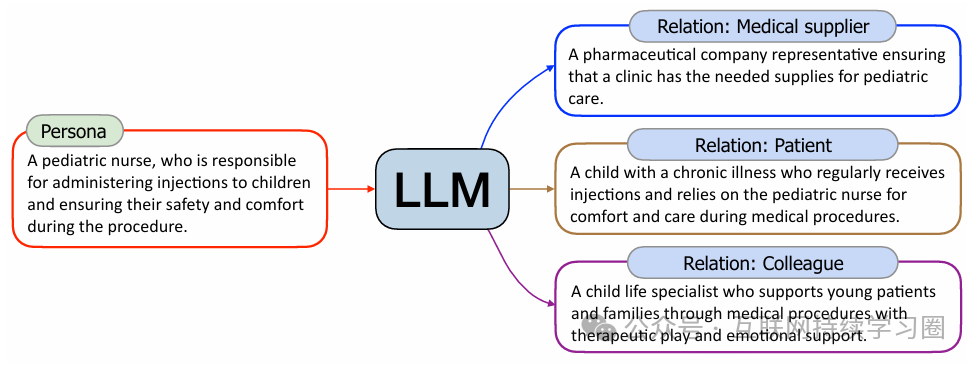
如上图所示,"一个孩子"的人物角色可以从儿童医院护士的人物角色衍生出来(患者-照顾者关系)。同样,"一个乞丐"可以从避难所工作人员的人物角色衍生出来(援助关系),而"一个幕后电影工作人员"可以从电影主演的人物角色衍生出来(同事关系)。根据六度分离理论(Travers & Milgram, 1977),论文对通过文本到人物角色方法获得的每个人物角色进行六次迭代的人物关系扩展,从而进一步丰富了论文的人物角色集合。
去重
论文首先在RedPajama v2数据集上运行Text-to-Persona,然后执行Persona-to-Persona。在获得数十亿个人物角色后,不可避免地会有一些人物角色是相同或极其相似的。为了确保Persona库的多样性,论文通过两种方式对这些人物角色进行去重:
基于MinHash的去重 论文使用MinHash根据人物角色描述的n-gram特征进行去重。由于人物角色描述通常只有1-2句话,远短于文档,论文简单地使用了1-gram和128的签名大小进行MinHash去重。论文在相似度阈值为0.9的情况下进行去重。
基于嵌入的去重 在基于表面形式(即带有n-gram特征的MinHash)去重之后,论文还采用了基于嵌入的去重方法。论文使用文本嵌入模型(例如,OpenAI的text-embedding-3-small模型)为每个人物角色计算一个嵌入,然后过滤掉余弦语义相似度大于0.9的人物角色。
需要注意的是,尽管论文在这里选择0.9作为阈值,但论文可以根据具体需求灵活调整它以进行进一步的去重。例如,当对实例数量的要求不高(例如,只需要100万个实例)但对多样性的要求较高时,论文可以进一步应用更严格的去重标准(例如,丢弃相似度大于0.5的人物角色)。
经过去重处理并采用简单的启发式方法过滤掉低质量的人物描述后,论文总共收集了1,015,863,523个人物角色,最终形成了论文的人物角色库(Persona Hub)。
基于人物角色的合成数据生成
论文提出的基于人物角色的数据合成方法简单而有效,其核心在于将一个人物角色融入到数据合成的提示语中的适当位置。尽管这一方法看似简单,却能显著引导大型语言模型(LLM)采用该人物角色的视角来生成合成数据。依托于人物角色库中10亿级的人物角色,该方法能够轻松地以亿级规模生成多样化的合成数据。

正如论文可以使用零样本或少样本方法来提示大型语言模型(LLM),角色驱动的方法同样灵活且兼容多种形式的提示,以创建合成数据。如图 6 所示,论文提出了三种角色驱动的数据合成提示方法:
-
零样本提示不利用任何现有示例(即演示),从而充分发挥模型的创造力,不受特定示例的限制。
-
少样本提示通过提供一些演示,能更好地确保合成数据符合要求。
-
角色增强少样本提示在增强 LLM 的角色驱动数据合成能力方面更为有效。然而,其缺点是需要在少样本提示之前为每个演示推导出相应的角色。
应用案例
论文展示了角色中心在多种数据合成场景中的应用案例,包括大规模创建数学和逻辑推理问题、指令(即用户提示)、知识丰富的文本、游戏 NPC 以及工具(函数)开发。
如前所述,角色驱动的方法具有普遍性和多功能性,只需调整数据合成提示,即可轻松适应不同的数据合成场景。因此,论文仅对数学问题合成进行详细的技术讨论,而对其他应用案例则不作详细讨论。
数学
演示
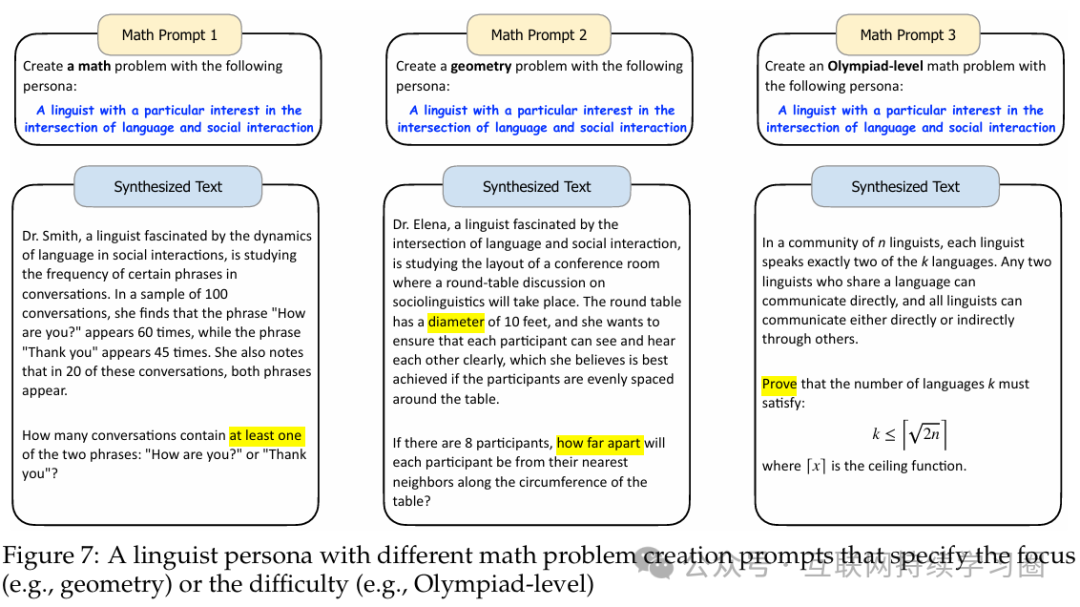
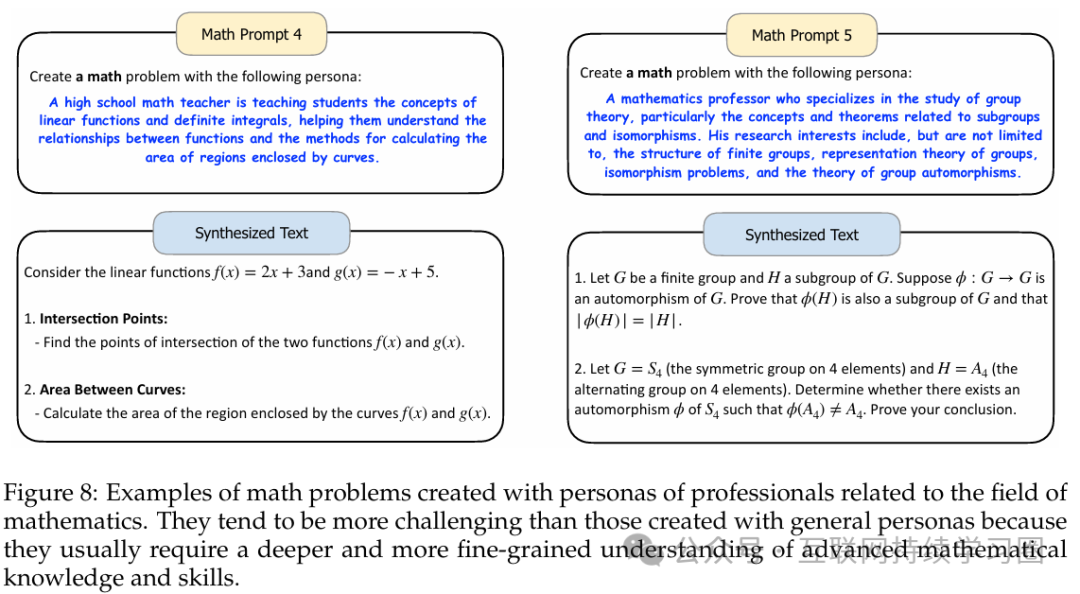
可以看到对于不同的角色,模型会给出难度不同,类型不同的数据。
评估
数据论文从Persona Hub中选取了109万个角色,并使用GPT-4的零样本提示方法,利用这些角色创建数学问题,在创建过程中不借鉴MATH等基准中的任何实例。这种方法使论文合成了109万个数学问题。由于本工作侧重于创建新的合成数据而非合成解决方案,论文仅使用gpt-4o(助手)为创建的问题生成解决方案。在这109万个数学问题中,论文随机抽取2万个作为合成测试集以方便评估。剩余的107万个问题用于训练。
测试集 论文使用以下两个测试集进行评估:
-
合成测试集(In-distribution):由于这2万个保留的问题集与107万个训练实例的生成方式相同,因此可以视为同分布测试集。为了确保该测试集中答案的准确性以提高评估的可靠性,论文额外使用gpt-4o(PoT)和gpt-4-turbo(助手)生成解决方案,除了gpt-4o(助手)生成的解决方案。论文仅保留至少有两个解决方案一致的测试实例。剩余的测试集包含1.16万个测试实例。
-
MATH(Out-of-distribution):用于测试大语言模型数学推理能力的最广泛认可的基准。其测试集包含 5000 个具有参考答案的竞赛级数学问题。由于我们在数据合成或训练中未使用 MATH 数据集中的任何实例,因此我们将 MATH 测试集视为分布外测试集。
论文仅对Qwen2-7B进行微调,使用论文合成的107万个数学问题,并在上述两个测试集上评估其贪心解码输出。
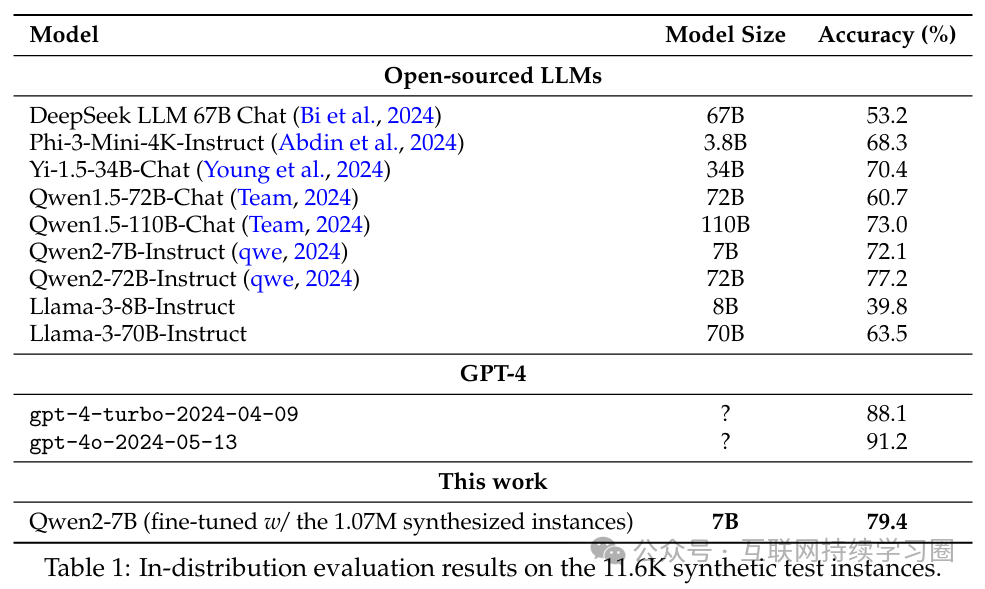
表 1 展示了在1.16万个合成测试实例上的分布内(ID)评估结果。在接受测试的开源大型语言模型中,Qwen2-72B-Instruct模型取得了最佳效果,其他模型的排名总体上与其在基准测试中所报告的性能表现相符。借助 107 万个合成数学问题,我们的模型达到了近 80% 的准确率,超过了所有开源大型语言模型。然而,考虑到合成测试中的答案并非绝对可靠,而且我们的模型可能是唯一一个使用分布内训练数据的模型,所以这一分布内评估结果应仅作为参考。
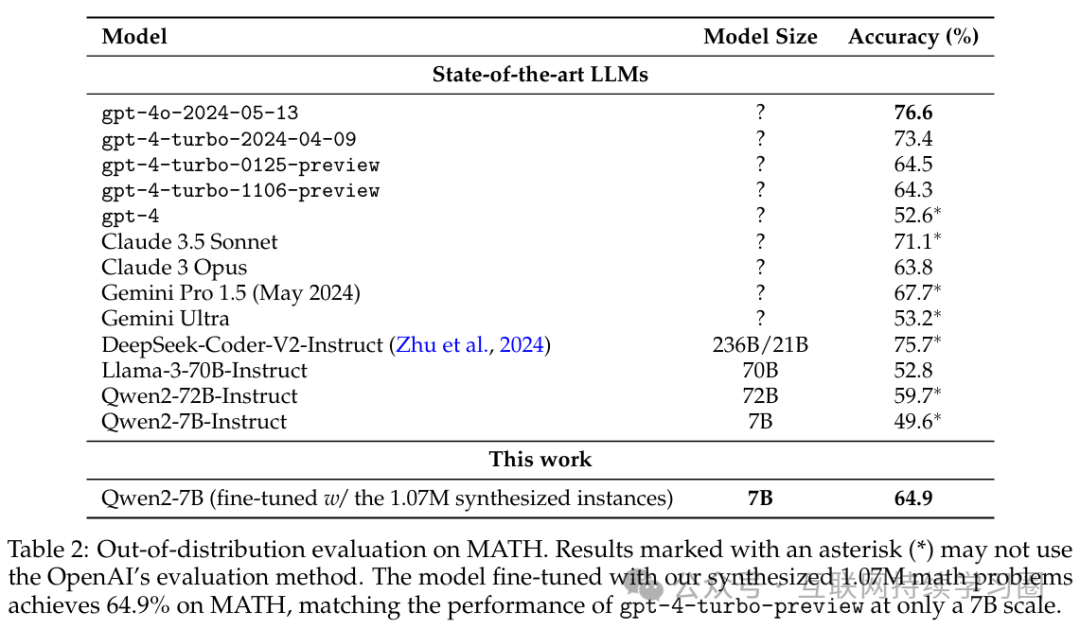
表 2 中展示了在 MATH 数据集上的评估结果。仅使用贪心解码,经过合成训练数据微调的 7B 模型在 MATH 数据集上就达到了令人瞩目的 64.9% 的准确率,仅逊色于gpt-4o, gpt-4-turbo-2024-04-09, Claude 3.5 Sonnet, Gemini Pro 1.5 (May 2024)和DeepSeek-Coder-V2-Instruct这些模型。
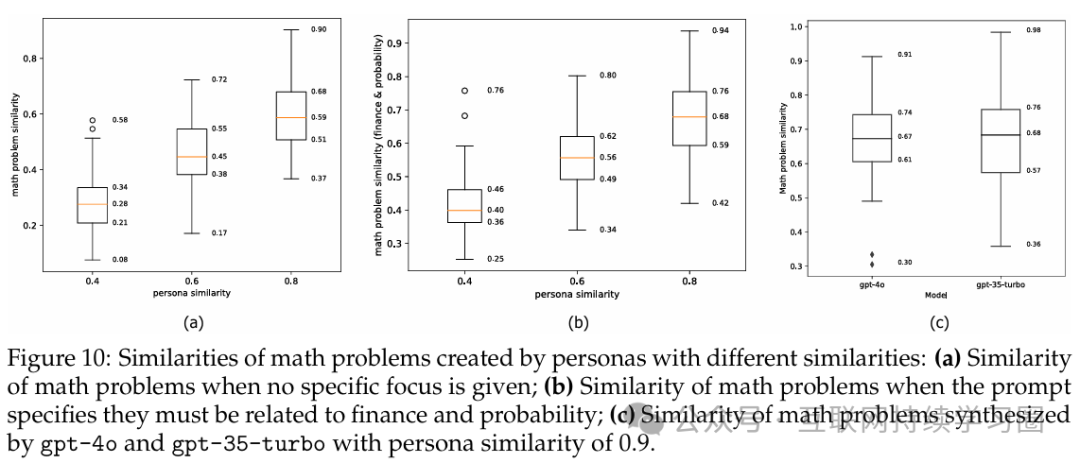
此外,论文专门研究了提示语中人物角色差异对合成数学问题的影响。首先分别抽取了 100 对语义相似度分别为 0.4、0.6 和 0.8 的人物角色对。对于每对人物角色,利用它们通过贪心解码(即温度为 0)来创建一对数学问题。然后,计算这些数学问题对的语义相似度,并将结果展示在图 10 中。
可以清楚地观察到,合成数学问题之间的语义相似度往往与它们相应人物角色之间的相似度相关,但低于后者。当在提示语中添加更具体的限制条件(例如,关于金融和概率的数学问题)时,合成数学问题之间的相似度往往会变得更高(图 10 (b))。在图 10 (c) 中,作者还测试了 GPT-4O 和 GPT-35 - Turbo 使用高度相似的人物角色(相似度 = 0.9)所创建的数学问题的相似度。结果表明,GPT-4O 和 GPT-35 - Turbo 所创建的数学问题的语义相似度似乎没有显著差异:大多数合成数学问题的相似度落在 0.6 到 0.75 的范围内,这比人物角色的相似度(0.9)要低得多。基于这些观察结果,作者认为使用人物角色库中的人物角色能够确保合成数据的多样性——即便数据规模达到十亿级别。
逻辑推理
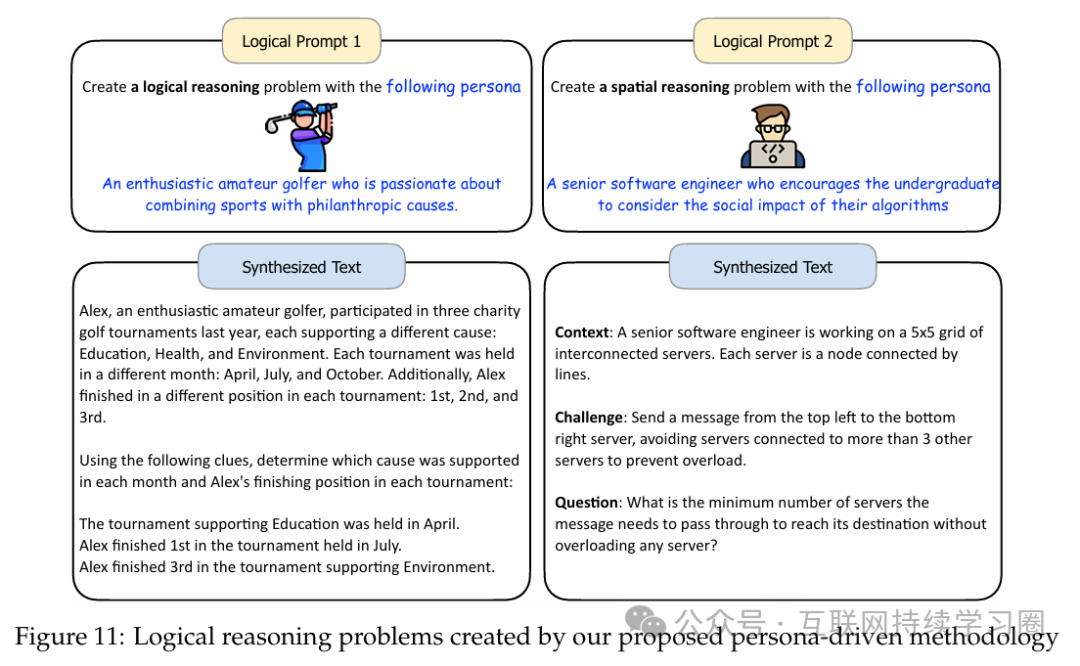
与数学问题类似,逻辑推理问题也可以轻松合成。论文在图11中展示了使用论文提出的角色驱动方法合成的典型逻辑推理问题示例。
指令

论文效果
-
多功能性:成功应用于数学和逻辑推理问题、用户指令、知识丰富文本、游戏NPC和工具功能等多个领域。
-
性能提升:在MATH数据集上,7B模型达到64.9%的准确率,仅次于某些GPT-4变体。
-
可扩展性和多样性:能够大规模创建多样化的合成数据,覆盖广泛的主题和视角。
-
灵活性和易用性:可以轻松适应不同场景和需求,如指令调优、预训练和后训练等。
-
潜在影响:有望推动合成数据创建和应用的范式转变;可能对LLM的研究、开发和应用产生深远影响。

互联网持续学习圈
清华大学计算机系校友、前微软、阿里高级算法工程师创办。汇聚互联网精英、985高校及海外硕博、自主创业者,持续学习者的专属圈。专注互联网资讯、科研、求职等。器识其先,文艺其从,陪你进化二十年。
99篇原创内容
公众号
进交流群请添加小助手微信

关于互联网持续学习圈
互联网持续学习圈是由清华大学计算机系校友、前阿里和微软算法工程师创办。汇聚互联网精英、985高校及海外硕博、自主创业者等,是持续学习者的专属圈。专注互联网资讯、科研、求职等。器识其先,文艺其从,陪你进化二十年。

参考文献
SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Metamath: Bootstrap your own mathematical questions for large language models
Orca-Math: Unlocking the potential of SLMs in Grade School Math
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Key-point-driven data synthesis with its enhancement on mathematical reasoning
Scaling Synthetic Data Creation with 1,000,000,000 Personas

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献391条内容
已为社区贡献391条内容

所有评论(0)