Python爬虫实战:抓取网易云音乐推荐歌单
通过请求网易云移动端接口,抓取部分热门歌单的名称、播放量以及链接信息,并输出结果展示。print(f"歌单:{name}\n播放量:{playCount}\n链接:{link}\n")网络爬虫是一项非常实用的技术,无论你是做数据分析、机器学习、自动化办公还是学术研究,都会用到它。遵守网站的 robots.txt 协议、避免高频率访问、尊重版权和隐私,是每一个开发者应该坚守的底线。与传统 HTML
一、项目简介
本次课程作业我选择爬取的是网易云音乐的推荐歌单数据。通过请求网易云移动端接口,抓取部分热门歌单的名称、播放量以及链接信息,并输出结果展示。整个过程锻炼了我对 API 接口分析、请求参数设置和 JSON 数据提取的能力。
二、目标网站与接口说明
目标平台:网易云音乐
接口地址:https://music.163.com/api/playlist/list
数据内容:推荐歌单列表(名称、播放量、链接)
接口特征:为移动端 API,响应为 JSON 格式,便于直接提取。
三、爬虫核心代码
import requests
# 推荐歌单接口(移动端 API)
url = 'https://music.163.com/api/playlist/list'
# 模拟浏览器请求头
headers = {
'User-Agent': 'Mozilla/5.0',
'Referer': 'https://music.163.com/'
}
# 请求参数
params = {
'cat': '全部',
'limit': 10,
'offset': 0
}
# 发送请求
res = requests.get(url, headers=headers, params=params)
data = res.json()
# 提取歌单信息
playlists = data['playlists']
for item in playlists:
name = item['name']
playCount = item['playCount']
playlist_id = item['id']
link = f'https://music.163.com/playlist?id={playlist_id}'
print(f"歌单:{name}\n播放量:{playCount}\n链接:{link}\n")
代码解析:
1. 导入库:
• requests:用于发送 HTTP 请求。
2. 设置请求地址和头部信息:
• url:目标 API 接口地址。
• headers:模拟浏览器请求头,防止被服务器拒绝访问。
3. 设置请求参数:
• cat:指定歌单分类,这里设置为“全部”。
• limit:限制返回的歌单数量,这里设置为 10。
• offset:分页参数,这里设置为 0,表示从第一项开始获取。
4. 发送请求并解析响应:
• 使用 requests.get() 发送 GET 请求。
• 使用 .json() 方法将响应内容解析为 JSON 格式。
5. 提取并输出歌单信息:
• 从 JSON 数据中提取 playlists 列表。
• 遍历每个歌单,提取名称、播放量和 ID。
• 构造每个歌单的链接,并打印输出。
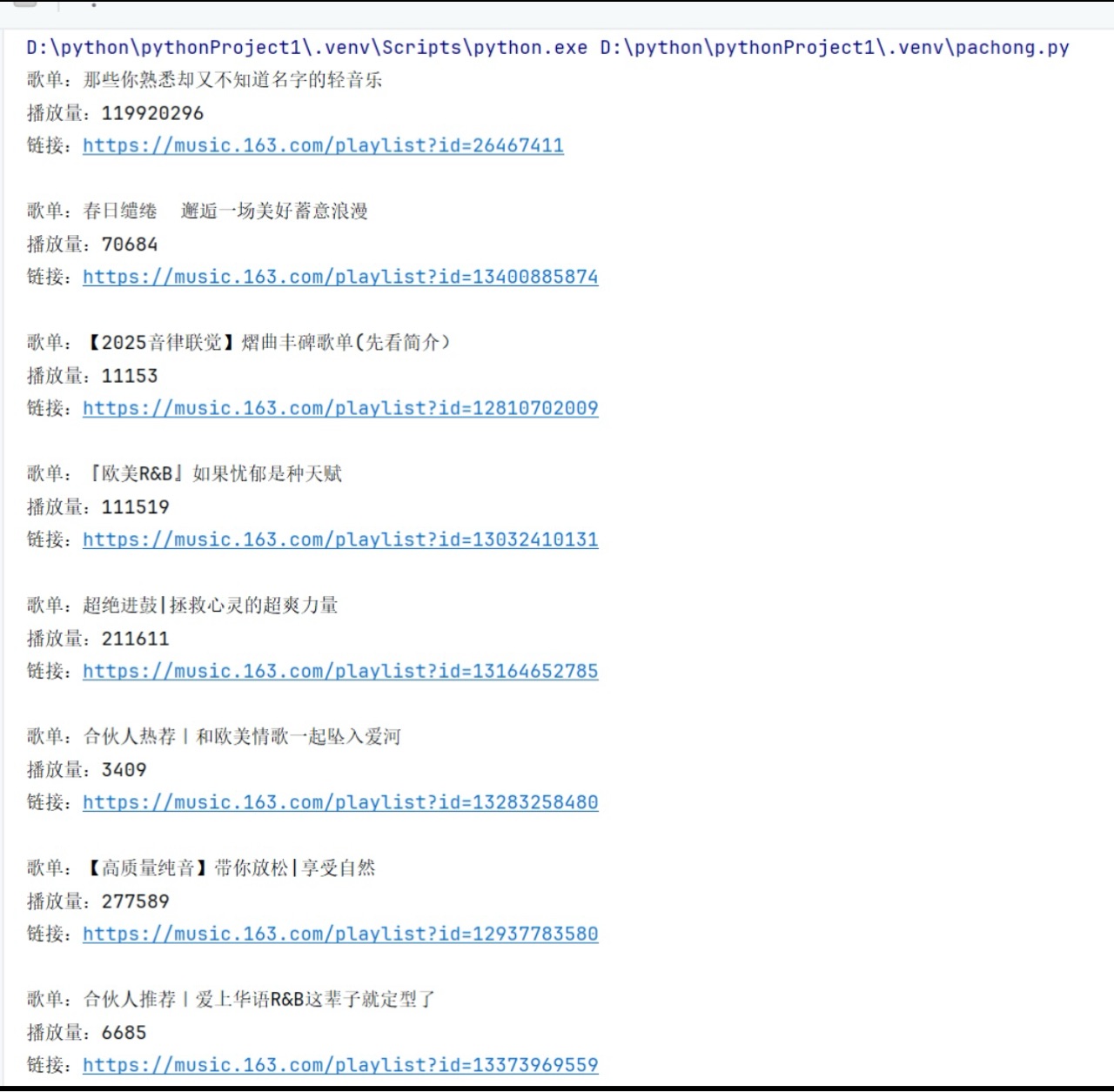
四、运行结果截图
如下图所示,成功输出了10个热门歌单的详细信息,包括名称、播放量与网页链接:
五、过程总结
通过本次爬虫练习,我进一步掌握了使用 requests 模块获取网页数据,并处理 JSON 数据的能力。
与传统 HTML 页面解析不同,此次使用了网易云的移动端 API 接口,简化了爬取过程。
今后还想尝试抓取歌曲评论、歌词或用户收藏数据,进一步挑战更复杂的接口或加密请求。
六、写在最后
网络爬虫是一项非常实用的技术,无论你是做数据分析、机器学习、自动化办公还是学术研究,都会用到它。但请记住:
爬虫不违法,违法的是滥用。
遵守网站的 robots.txt 协议、避免高频率访问、尊重版权和隐私,是每一个开发者应该坚守的底线。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)