【大模型微调】2.全指令微调
目录
定义:在预训练的基座模型上,把所有参数都解冻,用“指令-输入 → 输出”格式的数据(SFT 数据)进行监督训练,使模型在“听懂并执行自然语言指令”这一能力上达到更高水平。
目标:把基座变成“会听话的助手”(更一致的风格、更稳的格式输出、更少需要复杂 prompt engineering)。通常下一步会接 RLHF(PPO / DPO 等)以进一步提升偏好/安全性。
一、数据(最关键)
格式(典型 JSONL):
{"instruction":"翻译为英文","input":"我今天很开心","output":"I am very happy today."}或聊天风格:
{"role":"user","content":"请总结下面内容:..."}
{"role":"assistant","content":"摘要..."}单轮 vs 多轮
单轮(instruction+input→output)简单适配面广;
多轮(完整对话)更能训练对话能力、上下文追踪。
System / Role Token
若是 chat 格式,要保留 system/user/assistant 的 role token(或明确的字段),以确保模型学会不同角色行为。
其他注意事项
- 质量 > 数量:优质示例(准确、完整、格式一致、无矛盾)远比海量噪声有用。
- 去重 & 脱敏:剔除与验证集/测试集重复,脱敏私人信息/公司机密。
- 数据规模感:从几万到几十万条都常见(视任务复杂度),但少量优质样本(几千条)也能看到明显改进(但更易过拟合)。
- 多样性:覆盖各种指令表述/模板,避免模型只学会一套 prompt 说法。
- 版权/合规:训练数据来源要合规;内部文档、受版权保护内容需有授权。
二、训练目标与损失(训练信号)
训练目标(SFT):用最大似然(MLE / cross-entropy)监督训练模型生成 target tokens。
形式上:对每个训练样本,计算
注意:输入部分(instruction + input)对应的 token 在 loss 中通常被 mask(不参与 loss 计算),只对要预测的输出 token 计算 loss(teacher forcing + shifted-right)。
为什么要mask?
避免模型“把输入也当目标”并且保证训练目标为“预测下一个输出 token”。
在语言模型训练里,我们输入的是一整段序列(比如一段话),但是训练目标是:
预测下一个词的概率分布。
举个例子:输入「我 爱 自然 语言」,模型在第 3 个位置的时候只能用前面 「我 爱」 来预测 「自然」。所以训练时必须 mask 掉未来的信息,否则模型会“偷看答案”。
这就是所谓的因果 mask (causal mask):让第 t 个 token 只能看到 <t 的所有 token,不能看到 ≥t 的。
对于「我 爱 自然 语言」这句话来说,训练时使用mask矩阵长这样:
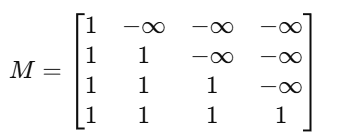
这里 1 表示允许注意,-∞ 表示禁止注意(实际实现时是加到 attention score 里,softmax 之后相当于 0 权重
为什么要对每个token都计算交叉熵?
交叉熵其实就是在问:模型预测的分布和真实答案(one-hot 向量)有多接近。
如果只在最后一个 token 上算损失,那模型只学会“预测最后一个词”,前面词的预测能力完全没训练到。
但语言模型的目标是:
在任意位置,都能根据前文预测下一个 token。
所以必须对序列中每个目标 token(除了第一个,因为它没前文)都算交叉熵,再把它们加起来/取平均。这样模型才能学会“在任何位置继续生成”。
Shifted Right
通过输入序列的右移,使得输入和输出序列对齐,这样模型在位置 t 的输入,对应位置 t 的目标就是 “预测下一个 token”。
假设目标句子仍然是:
我 爱 自然 语言
正常的目标序列(也就是预测序列):
我 爱 自然 语言 【EOS】
输入序列(右移一位,加上【BOS】
【BOS】 我 爱 自然 语言
对齐关系:
- 输入 [BOS] → 预测 我
- 输入 [BOS]我 → 预测 爱
- 输入 [BOS]我爱 → 预测 自然
- 输入 [BOS]我爱自然 → 预测 语言
- 输入 [BOS]我爱自然语言 → 预测 [EOS]
从上述过程我们可以发现,如果输入和目标完全对齐(都从 “我” 开始),模型会尝试用 我 来预测 我 —— 这没意义。所以我们让输入序列右移,保证它“少一步”,模型就能从前文预测下一个token。
Teacher Forcing
在训练时,解码器每一步不是用它自己预测的结果,而是用真实答案喂进去。这样可以避免训练阶段模型因为一开始预测差,导致后面输入全错 → 学不下去。
推理阶段则不会有teacher forcing,只能靠模型一步步生成。
三、训练流程(步骤化实操)
- 数据准备:清洗 → 统一数据格式(chat/jsonl)→ 去重 → 划验证集 / 测试集。
- Tokenizer:用与基座相同 tokenizer,添加所需特殊 token(<bos><eos>、role token)。
- 构造训练样本:把 instruction+input+response 串成模型输入,生成对应的 label(shifted-right,mask 输入 tokens)。
- 打包 batch:动态 padding 或按长度 bucket,减少浪费。
- 训练设置:AdamW、mixed precision(FP16/BF16)、梯度累积、学习率调度、checkpoint。
- 监控:训练/验证 loss(仅对 target tokens)、周期性保存模型权重与训练日志。
- 评估:自动指标(val loss、BLEU/EM/ROUGE 视任务)、人工 A/B、红队测试、安全检测。
- 后处理:若计划 RLHF,收集对比数据(人类偏好)→ 训练 reward model → 用 PPO/DPO 优化。
四、常用超参数的经验值(供参考,需根据显存/数据调)
这些是常见起点,实际以小规模试验(1–3 个实验)调参为准。
- 优化器:AdamW(betas=(0.9,0.95),eps=1e-8)
- 学习率(LR)(全量微调通常要比 PEFT 更小):
- 小模型(~7B):2e-5 ~ 5e-5
- 中等(~13B):5e-6 ~ 2e-5
- 大模型(~70B):1e-6 ~ 5e-6
- 权重衰减:0 ~ 0.01(视任务)
- 批大小:单卡序列数小(1–8),用梯度累积达到 有效 batch。
- 有效 batch(以 tokens 计):目标常在 32k ~ 256k tokens/update(视数据量)。
- 梯度累积:必要时使用,以降低显存需求。
- warmup:100 ~ 2000 steps(或按百分比 warmup 0.1%~1%)
- 学习率衰减:线性或 cosine decay,训练结束时接近 0。
- 训练轮次(epochs):1 ~ 3 为常见起点(过多易过拟合)。
- 梯度裁剪:norm ≈ 1.0。
- 混合精度:FP16 或 BF16(若 GPU/框架 支持),必须配合梯度缩放。
额外技巧:activation checkpointing、optimizer/parameter offloading、ZeRO/FSDP 用于大模型分布式训练。
五、如何避免灾难性遗忘
全量微调最怕把基座“通识能力”洗掉。常用做法:
- 混合训练数据:在指令数据中插入少量原始通用数据(或微调时周期性回放 pretraining-ish 数据)。比例视情况:常见 5%~20% 副本混入。
- 小 learning rate + 短轮次:比起大 LR 多轮训练,低 LR 更稳。
- L2 正则 / 权重衰减:防止参数大幅漂移。
- 早停(early stopping):在验证集上监控,同时用多个指标(val loss 与任务特定指标)。
- 频繁保存 checkpoint,并做 A/B 对比,便于回滚。
六、与 RLHF(后续步骤)关系(流程简述)
- SFT(全量指令微调):先把模型训练成能按指令输出的基础模型(policy init)。
- 收集偏好数据:通过人类标注对同一 prompt 的多条回复进行排序/打分。
- 训练 Reward Model:用偏好数据训练 reward model(常把模型隐藏向量映射到分值)。
- Policy Optimization:用 PPO(需要在线采样 & KL 惩罚等)或 DPO(直接优化偏好对)把 policy 优化到更符合人类偏好 / 更稳妥。
PPO:更复杂、灵活、需要交互采样与训练循环。
DPO:常被视为更稳定/实现简单的偏好优化方法(直接基于偏好对)。
七、评估指标
- 自动化:验证集上的 cross-entropy(仅对输出 tokens)、perplexity(注意只在 target tokens 计算)、任务特定指标(BLEU/ROUGE/EM/Pass@k)
- 指令遵循度:通过人类或模型化判分(reward model)做 A/B 比较,统计 win-rate
- 安全性/鲁棒性:toxicity 检测、越界回答测试、对抗输入测试、长上下文测试
- 格式/约束合规率:如“是否总返回合法 JSON”的通过率
- 人工评审:最终以人工评审为金标准(可用少量样本做盲测),并结合偏好数据训练 reward model 做大规模估计
八、部署注意
- 资源:全量微调对显存/算力需求高。对 70B 做全量微调通常需要多卡、ZeRO/FSDP、80GB+ GPU 才实际可行;小规模公司常优先用 LoRA。
- Checkpoint 与版本管理:每次重要实验保存 checkpoint,记录 config(learning rate、seed、数据版本)以便可复现。
- 上线优化:训练产出后常用量化(INT8/4)或把模型转换为支持更快推理的格式;若要频繁迭代,保留 LoRA/adapter 形式更方便。
- 推理安全层:在模型输出端加策略过滤器、工具调用或检索校验(RAG),降低幻觉与违法输出风险。
九、常见坑及对策(实战经验)
- 过拟合指令风格:出现“回答机械化/死板” → 用更多多样化指令 + 增加验证集多样性。
- 把测试集/验证集泄露进训练:严格去重与分割。
- 训练崩溃/梯度爆炸:降低 LR、加梯度裁剪、检查 tokenizer 是否一致。
- 训练后通识能力下降:引入 rehearsal(回放)或混合预训练样本。
- 安全问题(毒性/机密泄露):训练前仔细过滤、训练后红队、加控制策略/禁止词表与工具校验。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)