Python爬虫实战实现足球赛事数据:多字段解析与北京时间处理
在体育数据分析领域,获取实时比赛数据是进行赛事分析的基础。本文将介绍如何通过Python实现一个足球赛事数据采集工具,重点解决多层级JSON解析、北京时间转换和图片URL补全等技术难点。本文代码已做脱敏处理,真实接口地址和密钥信息请参考对应平台的开发者文档。实现类似功能时请务必遵守相关网站的数据使用协议。设置合理的请求间隔(示例代码已包含1秒延迟)数据格式化存储(支持Excel中文显示)遵守目标网
·
先看效果:内含完整代码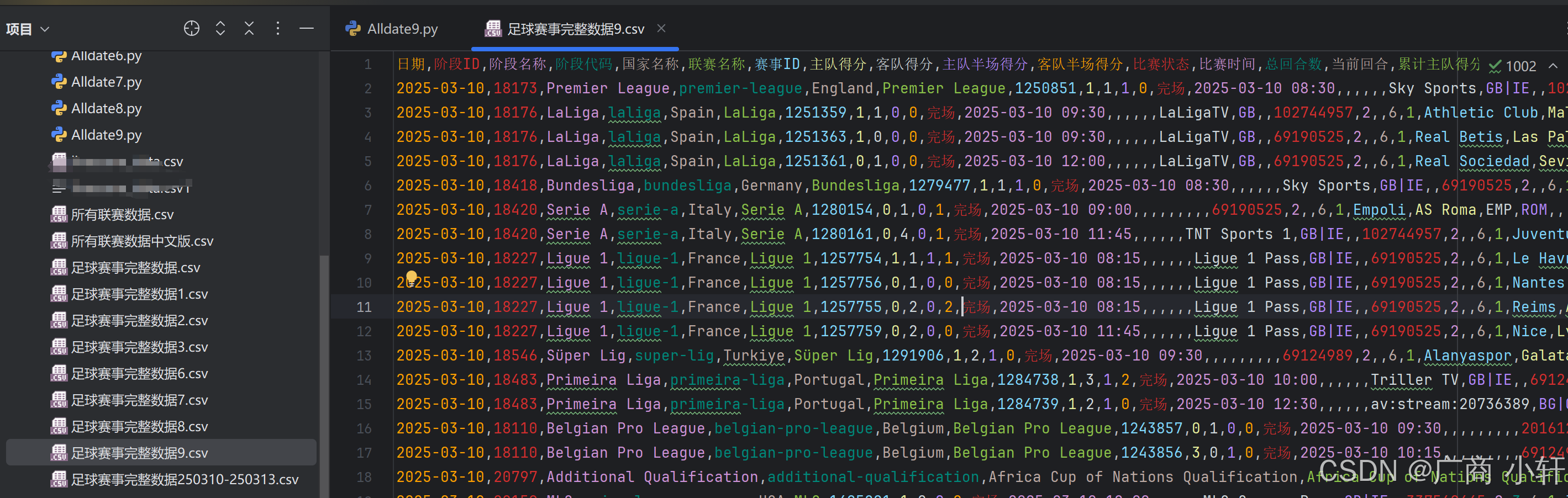
一、项目背景
在体育数据分析领域,获取实时比赛数据是进行赛事分析的基础。本文将介绍如何通过Python实现一个足球赛事数据采集工具,重点解决多层级JSON解析、北京时间转换和图片URL补全等技术难点。
二、核心功能
-
多日期范围数据采集
-
复杂JSON结构解析
-
自动时区转换(UTC转北京时间)
-
球队图片URL自动补全
-
数据格式化存储(支持Excel中文显示)
三、技术实现
3.1 请求配置
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)...'
}
API_TEMPLATE = "https://api.example.com/date/soccer/{date}/8" # 示例URL3.2 核心解析逻辑
字段映射配置:
FIELD_MAPPING = {
'Sid': '阶段ID',
'Snm': '阶段名称',
# ...其他字段映射
}递归解析嵌套数据:
def get_nested_value(data, keys):
for key in keys.split('.'):
if isinstance(data, list) and key.isdigit():
data = data[int(key)] if int(key) < len(data) else None
else:
data = data.get(key)
if data is None:
return None
return data3.3 北京时间转换
def convert_to_beijing_time(timestamp_str):
try:
dt_utc = datetime.strptime(timestamp_str, "%Y%m%d%H%M%S")
return (dt_utc + timedelta(hours=8)).strftime('%Y-%m-%d %H:%M')
except Exception as e:
print(f"时间转换失败: {e}")
return '无效时间'3.4 图片URL处理
def process_team_image(img_url):
if img_url:
return f"https://cdn.example.com/medium/{img_url}"
return None四、代码结构
def parse_event(event_data, date_str):
# 数据解析主逻辑
pass
def fetch_data(date):
# 数据获取逻辑
pass
def main():
# 主控制流程
pass五、完整代码案例
import requests
import pandas as pd
from datetime import datetime, timedelta
import time
from pytz import timezone
# 增强字段映射表(新增字段根据API返回数据补充)
FIELD_MAPPING = {
# 基础字段
'Sid': '阶段ID',
'Snm': '阶段名称',
'Scd': '阶段代码',
'Cnm': '国家名称',
'CompN': '联赛名称',
'Eid': '赛事ID',
# 比赛信息
'Tr1': '主队得分',
'Tr2': '客队得分',
'Trh1': '主队半场得分',
'Trh2': '客队半场得分',
'Eps': '比赛状态',
'Esd': '比赛时间',
# 新增字段(根据API返回数据)
'seriesInfo.totalLegs': '总回合数',
'seriesInfo.currentLeg': '当前回合',
'seriesInfo.aggScoreTeam1': '累计主队得分',
'seriesInfo.aggScoreTeam2': '累计客队得分',
'Feed.Items': '关联赛事列表',
# 转播信息
'Media.112[0].eventId': '主要转播平台',
'Media.112[0].allowedCountries': '转播国家',
# 新增其他字段
'Awt': '预警类型',
'EO': '赛事顺序',
'Epr': '赛事优先级',
'ErnInf': '轮次信息',
'Esid': '赛事子ID',
'Et': '赛事类型'
}
# 比赛状态映射
STATUS_MAP = {
'FT': '完场',
'HT': '中场',
'AP': '进行中',
'NS': '未开始',
'Postp.': '延期'
}
# 定义请求头
HEADERS = {
'User-Agent':
}
def parse_event(event_data, date_str):
"""深度解析赛事数据结构"""
def get_nested_value(data, keys):
for key in keys.split('.'):
if isinstance(data, list) and key.isdigit():
data = data[int(key)] if int(key) < len(data) else None
else:
data = data.get(key)
if data is None:
return None
return data
parsed = {'日期': date_str}
# 解析基础字段
for field, ch_name in FIELD_MAPPING.items():
keys = field.split('.')
value = event_data
for key in keys:
if key.endswith(']'):
main_key, index = key.split('[')
index = int(index[:-1])
value = value.get(main_key, [])
value = value[index] if index < len(value) else None
else:
value = value.get(key) if isinstance(value, dict) else None
if value is None:
break
# 特殊处理时间戳(处理格式:20250313014500 -> 转换为北京时间)
if field == 'Esd' and value:
try:
# 解析原始时间字符串
dt_str = str(value)
dt_utc = datetime.strptime(dt_str, "%Y%m%d%H%M%S")
# 转换为 UTC+8 北京时间
dt_beijing = dt_utc + timedelta(hours=8)
value = dt_beijing.strftime('%Y-%m-%d %H:%M')
except Exception as e:
print(f"时间转换失败: {e}")
value = '无效时间'
# 转换比赛状态
if field == 'Eps':
value = STATUS_MAP.get(value, value)
# 处理关联赛事列表
if field == 'Feed.Items' and isinstance(value, list):
value = '|'.join(value)
parsed[ch_name] = value
# 处理球队信息
for side in ['T1', 'T2']:
team = get_nested_value(event_data, f'{side}') # 获取 T1 或 T2 数据
if isinstance(team, list) and len(team) > 0:
team = team[0] # 取第一个元素
else:
team = {}
# 主队和客队名称
if side == 'T1':
parsed['主队名称'] = team.get('Nm')
parsed['主队缩写'] = team.get('Abr')
elif side == 'T2':
parsed['客队名称'] = team.get('Nm')
parsed['客队缩写'] = team.get('Abr')
# 处理球队图片链接
img_url = team.get('Img')
if img_url:
# 补全图片URL
parsed[f'{side[:2]}队图片'] =
else:
parsed[f'{side[:2]}队图片'] = None
# 处理系列赛信息
series_info = event_data.get('seriesInfo', {})
parsed['总回合数'] = series_info.get('totalLegs')
parsed['当前回合'] = series_info.get('currentLeg')
parsed['累计主队得分'] = series_info.get('aggScoreTeam1')
parsed['累计客队得分'] = series_info.get('aggScoreTeam2')
# 处理转播信息
media = event_data.get('Media', {})
if '112' in media and isinstance(media['112'], list) and len(media['112']) > 0:
parsed['主要转播平台'] = media['112'][0].get('eventId')
parsed['转播国家'] = '|'.join(media['112'][0].get('allowedCountries', []))
return parsed
def fetch_data(date):
"""获取并处理单日数据"""
url =
try:
response = requests.get(url, headers=HEADERS)
response.raise_for_status()
data = response.json()
all_events = []
# 处理多阶段数据
for stage in data.get('Stages', []):
# 添加阶段元数据
stage_meta = {k: v for k, v in stage.items() if not isinstance(v, (list, dict))}
for event in stage.get('Events', []):
# 合并阶段元数据到赛事数据
merged_event = {**stage_meta, **event}
parsed = parse_event(merged_event, datetime.strptime(date, "%Y%m%d").strftime("%Y-%m-%d"))
all_events.append(parsed)
return all_events
except Exception as e:
print(f"获取 {date} 数据时出错: {str(e)}")
return []
def main():
# 定义时间范围
START_DATE = '20250310'
END_DATE = '20250313'
dates = pd.date_range(START_DATE, END_DATE).strftime("%Y%m%d")
all_data = []
for date in dates:
print(f"正在处理日期:{date}")
events = fetch_data(date)
all_data.extend(events)
# 遵守请求速率限制
time.sleep(1)
if all_data:
# 自动生成字段顺序
columns = ['日期'] + list(FIELD_MAPPING.values()) + [
'主队名称', '客队名称', '主队缩写', '客队缩写',
'主队图片', '客队图片'
]
# 创建 DataFrame
df = pd.DataFrame(all_data)
# 确保列名存在
df = df.reindex(columns=columns)
# 保存时自动添加BOM头解决Excel中文乱码
df.to_csv("足球赛事完整数据9.csv", index=False, encoding='utf-8-sig')
print(f"成功保存 {len(df)} 条记录")
else:
print("未获取到有效数据")
if __name__ == "__main__":
main()六、注意事项
-
遵守目标网站robots.txt规则
-
设置合理的请求间隔(示例代码已包含1秒延迟)
-
及时处理API变更导致的字段变化
-
注意数据版权相关法律风险
注: 本文代码已做脱敏处理,真实接口地址和密钥信息请参考对应平台的开发者文档。实现类似功能时请务必遵守相关网站的数据使用协议。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)