全面展示AI测试的实现路径与实践价值。
AI正在深刻重构软件测试的范式。通过自动化测试框架的智能化生成、智能缺陷检测的提前预警、以及A/B测试优化的动态决策,AI显著提升了测试效率、覆盖率和决策质量。结合代码实践、流程图、Prompt设计和可视化图表,本文展示了AI测试的完整技术栈与实施路径。未来,随着大模型和边缘计算的发展,AI测试将向更自主、更精准、更实时的方向演进,成为软件质量保障的核心支柱。
随着人工智能(AI)技术的迅猛发展,软件测试领域也迎来了深刻的变革。传统测试方法在面对日益复杂的系统、快速迭代的开发节奏和海量数据时,逐渐暴露出效率低下、覆盖率不足、缺陷定位困难等问题。AI技术的引入为测试自动化、缺陷预测与定位、实验优化等环节提供了全新的解决方案。本文将深入探讨AI在三大核心测试场景中的应用:自动化测试框架、智能缺陷检测和A/B测试优化,并结合代码示例、Mermaid流程图、Prompt设计、可视化图表等多维度内容,全面展示AI测试的实现路径与实践价值。
一、AI在自动化测试框架中的应用
1.1 传统自动化测试的挑战
传统自动化测试依赖于脚本驱动,测试人员需手动编写测试用例、定位元素、定义断言逻辑。这种方式存在以下问题:
- 维护成本高:UI频繁变更导致脚本频繁失效;
- 可扩展性差:难以适应多平台、多设备的测试需求;
- 覆盖率有限:难以覆盖所有用户路径和边界条件;
- 学习曲线陡峭:需掌握编程语言和测试框架。
1.2 AI驱动的自动化测试框架
AI可通过计算机视觉、自然语言处理(NLP)和强化学习等技术,提升自动化测试的智能化水平。典型应用包括:
- 自动生成测试脚本:通过分析用户行为日志或产品文档,AI可自动生成Selenium或Playwright脚本;
- 智能元素定位:使用图像识别或语义理解技术,动态识别UI元素,减少XPath/CSS选择器的硬编码;
- 自适应测试执行:根据环境变化自动调整测试策略。
1.3 示例:基于AI的Web自动化测试框架(Python + Playwright + OpenAI)
from playwright.sync_api import sync_playwright
import openai
import json
# 设置OpenAI API密钥
openai.api_key = "your-api-key"
def generate_test_script(user_story: str) -> str:
"""
使用GPT模型根据用户故事生成Playwright测试脚本
"""
prompt = f"""
请根据以下用户故事生成一个Python Playwright自动化测试脚本:
用户故事:{user_story}
要求:
1. 使用sync_playwright
2. 包含页面导航、元素交互和断言
3. 输出完整可运行代码
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
max_tokens=1024
)
return response.choices[0].message['content']
# 示例用户故事
user_story = "用户登录邮箱系统,输入用户名和密码,点击登录按钮,验证是否跳转到收件箱页面。"
# 生成测试脚本
generated_script = generate_test_script(user_story)
print("生成的测试脚本:")
print(generated_script)
# 执行生成的脚本(需安全评估后执行)
# exec(generated_script)
注意:
exec()存在安全风险,建议在沙箱环境中运行生成的代码。
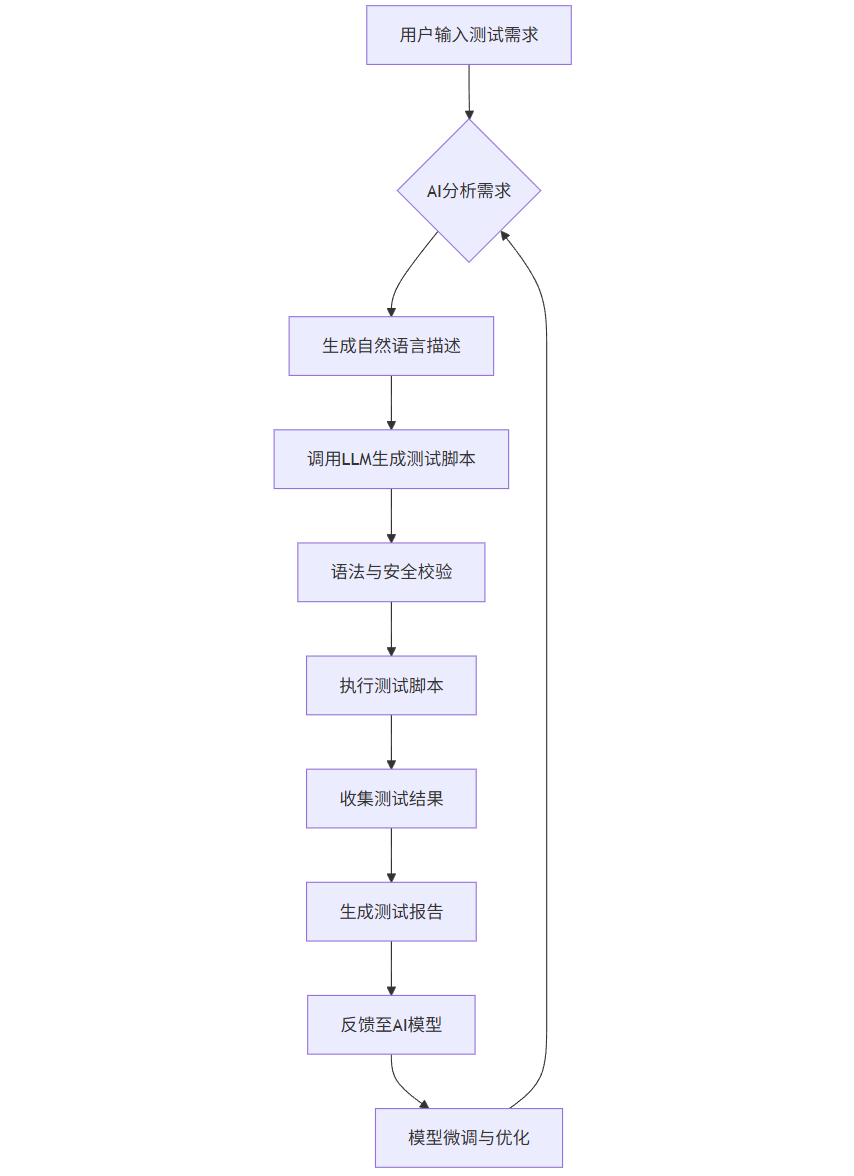
1.4 Mermaid流程图:AI自动化测试框架工作流graph TD
A[用户输入测试需求] --> B{AI分析需求}
B --> C[生成自然语言描述]
C --> D[调用LLM生成测试脚本]
D --> E[语法与安全校验]
E --> F[执行测试脚本]
F --> G[收集测试结果]
G --> H[生成测试报告]
H --> I[反馈至AI模型]
I --> J[模型微调与优化]
J --> B
1.5 Prompt设计示例
你是一个专业的自动化测试工程师,请根据以下用户行为描述生成一个Selenium Python测试脚本:
行为描述:用户在电商网站搜索“无线耳机”,选择价格排序,点击第一个商品,加入购物车,进入购物车页面并验证商品名称。
要求:
- 使用unittest框架
- 包含setUp和tearDown方法
- 使用显式等待等待元素加载
- 断言商品名称是否匹配
请输出完整代码。
该Prompt结构清晰,包含角色定义、任务描述、技术要求和输出格式,有助于LLM生成高质量代码。
二、智能缺陷检测
2.1 传统缺陷检测的局限
传统缺陷检测依赖人工审查日志、监控告警和测试报告,存在:
- 响应延迟:问题发现滞后;
- 误报率高:大量噪音干扰;
- 根因难定位:需人工排查调用链。
2.2 AI在缺陷检测中的优势
AI可通过以下方式提升缺陷检测能力:
- 日志异常检测:使用LSTM、Autoencoder等模型识别异常日志模式;
- 缺陷预测:基于历史缺陷数据预测高风险模块;
- 根因分析:结合知识图谱与NLP自动分析错误堆栈。
2.3 示例:基于LSTM的日志异常检测模型
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.utils import to_categorical
# 模拟日志数据
log_data = [
"INFO User login success",
"INFO Page loaded",
"ERROR Database connection failed",
"WARN Disk usage high",
"ERROR Null pointer exception",
"INFO User logout"
]
# 标签:0-正常,1-异常
labels = [0, 0, 1, 1, 1, 0]
# 文本向量化
le = LabelEncoder()
encoded_logs = le.fit_transform(log_data)
encoded_logs = encoded_logs.reshape(-1, 1)
# 构建序列数据(滑动窗口)
def create_sequences(data, seq_length=3):
sequences = []
for i in range(len(data) - seq_length):
seq = data[i:i+seq_length]
target = data[i+seq_length]
sequences.append((seq, target))
return sequences
seq_length = 3
sequences = create_sequences(encoded_logs, seq_length)
X = np.array([item[0] for item in sequences])
y = np.array([item[1] for item in sequences])
# 转换为分类问题
num_classes = len(le.classes_)
y_cat = to_categorical(y, num_classes)
# 构建LSTM模型
model = Sequential([
LSTM(50, input_shape=(seq_length, 1)),
Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X, y_cat, epochs=100, verbose=0)
# 预测新日志
new_log = "ERROR File not found"
encoded_new = le.transform([new_log])[0]
seq_input = np.array([[[encoded_new]]]) # 形状: (1, 1, 1)
pred = model.predict(seq_input)
predicted_class = np.argmax(pred)
print(f"预测类别: {predicted_class} ({'异常' if predicted_class > 0 else '正常'})")
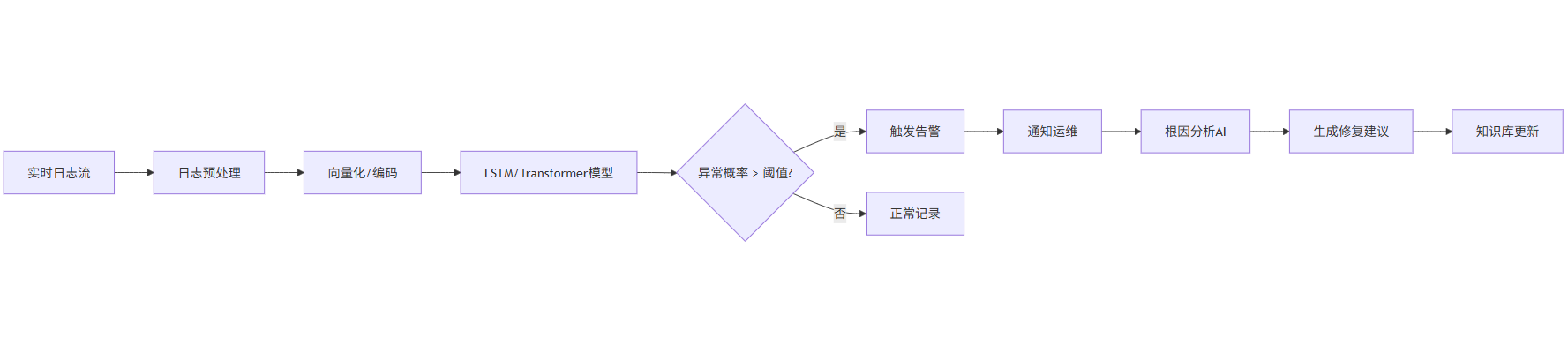
2.4 Mermaid流程图:智能缺陷检测系统
graph LR
A[实时日志流] --> B[日志预处理]
B --> C[向量化/编码]
C --> D[LSTM/Transformer模型]
D --> E{异常概率 > 阈值?}
E -->|是| F[触发告警]
E -->|否| G[正常记录]
F --> H[通知运维]
H --> I[根因分析AI]
I --> J[生成修复建议]
J --> K[知识库更新]
2.5 可视化图表:缺陷预测热力图
假设我们有模块缺陷历史数据,可绘制热力图展示高风险模块:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 模拟数据
data = {
'Module': ['Login', 'Payment', 'Search', 'Profile', 'Cart'],
'Defect_Count_Last_30d': [15, 8, 3, 5, 12],
'Code_Churn': [200, 150, 80, 60, 180],
'Test_Coverage': [0.7, 0.6, 0.9, 0.85, 0.65]
}
df = pd.DataFrame(data)
# 计算风险评分(示例)
df['Risk_Score'] = df['Defect_Count_Last_30d'] * 0.5 + \
(1 - df['Test_Coverage']) * 100 * 0.3 + \
df['Code_Churn'] * 0.01
# 绘制热力图
plt.figure(figsize=(8, 4))
sns.heatmap(df[['Defect_Count_Last_30d', 'Code_Churn', 'Test_Coverage', 'Risk_Score']].T,
annot=True, fmt=".1f", cmap="Reds", yticklabels=False)
plt.title("模块风险热力图")
plt.show()
⌄
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 模拟数据
data = {
'Module': ['Login', 'Payment', 'Search', 'Profile', 'Cart'],
'Defect_Count_Last_30d': [15, 8, 3, 5, 12],
'Code_Churn': [200, 150, 80, 60, 180],
'Test_Coverage': [0.7, 0.6, 0.9, 0.85, 0.65]
}
df = pd.DataFrame(data)
# 计算风险评分(示例)
df['Risk_Score'] = df['Defect_Count_Last_30d'] * 0.5 + \
(1 - df['Test_Coverage']) * 100 * 0.3 + \
df['Code_Churn'] * 0.01
# 绘制热力图
plt.figure(figsize=(8, 4))
sns.heatmap(df[['Defect_Count_Last_30d', 'Code_Churn', 'Test_Coverage', 'Risk_Score']].T,
annot=True, fmt=".1f", cmap="Reds", yticklabels=False)
plt.title("模块风险热力图")
plt.show()
图表说明:颜色越深表示风险越高。Payment和Cart模块因缺陷多、覆盖率低,风险较高。
三、A/B测试优化
3.1 传统A/B测试的痛点
传统A/B测试通常采用固定样本量、固定周期的假设检验(如t检验),存在:
- 样本浪费:需等待完整实验周期;
- 决策延迟:无法实时调整;
- 多重比较问题:多个变体导致假阳性增加。
3.2 AI驱动的A/B测试优化
AI可通过贝叶斯优化、多臂老虎机(Multi-Armed Bandit)和强化学习实现实时优化:
- 动态流量分配:将更多流量导向表现更好的变体;
- 早期停止:当置信度足够高时提前终止实验;
- 个性化变体:基于用户特征推荐最优版本。
3.3 示例:多臂老虎机算法实现
import numpy as np
import matplotlib.pyplot as plt
class EpsilonGreedyBandit:
def __init__(self, epsilon, n_arms):
self.epsilon = epsilon
self.n_arms = n_arms
self.counts = np.zeros(n_arms)
self.values = np.zeros(n_arms)
def select_arm(self):
if np.random.random() < self.epsilon:
return np.random.randint(self.n_arms)
else:
return np.argmax(self.values)
def update(self, chosen_arm, reward):
self.counts[chosen_arm] += 1
n = self.counts[chosen_arm]
value = self.values[chosen_arm]
new_value = ((n - 1) / n) * value + (1 / n) * reward
self.values[chosen_arm] = new_value
# 模拟A/B测试(3个变体)
np.random.seed(42)
true_rewards = [0.05, 0.07, 0.06] # 真实转化率
bandit = EpsilonGreedyBandit(epsilon=0.1, n_arms=3)
n_trials = 1000
rewards = []
chosen_arms = []
for _ in range(n_trials):
arm = bandit.select_arm()
reward = 1 if np.random.random() < true_rewards[arm] else 0
bandit.update(arm, reward)
rewards.append(reward)
chosen_arms.append(arm)
# 绘制结果
cumulative_reward = np.cumsum(rewards)
plt.figure(figsize=(10, 4))
plt.plot(cumulative_reward)
plt.title("累积转化数(Epsilon-Greedy)")
plt.xlabel("试验次数")
plt.ylabel("累积转化")
plt.grid(True)
plt.show()
print("最终估计值:", bandit.values)
print("选择次数:", bandit.counts)
结果分析:算法倾向于选择转化率最高的变体(索引1),实现流量优化。
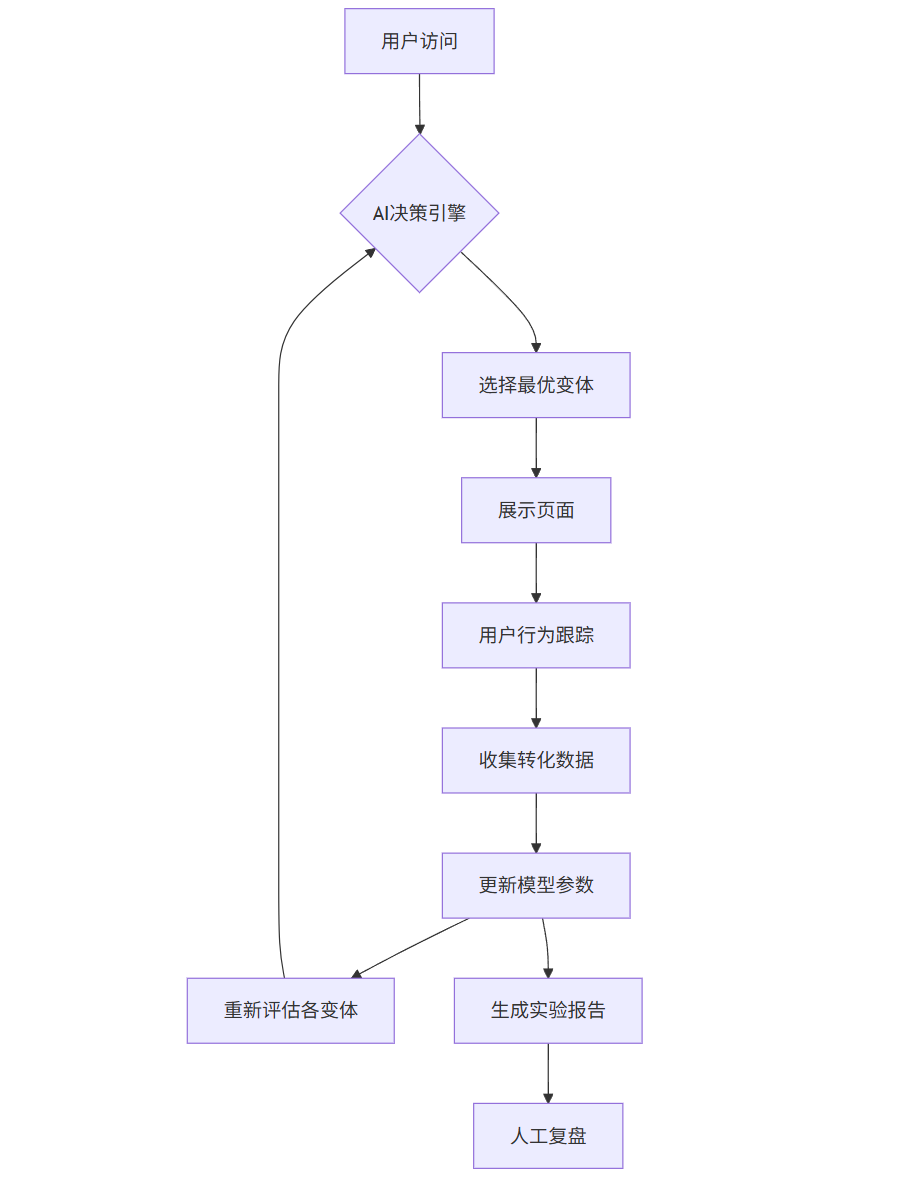
3.4 Mermaid流程图:AI优化的A/B测试系统
graph TD
A[用户访问] --> B{AI决策引擎}
B --> C[选择最优变体]
C --> D[展示页面]
D --> E[用户行为跟踪]
E --> F[收集转化数据]
F --> G[更新模型参数]
G --> H[重新评估各变体]
H --> B
G --> I[生成实验报告]
I --> J[人工复盘]
3.5 图表:A/B测试结果对比图
import matplotlib.pyplot as plt
# 模拟A/B测试结果
variants = ['A', 'B', 'C']
conversion_rates = [0.052, 0.068, 0.059]
confidence_intervals = [(0.045, 0.059), (0.061, 0.075), (0.052, 0.066)]
# 绘制柱状图与误差线
plt.figure(figsize=(8, 5))
bars = plt.bar(variants, conversion_rates, yerr=[(hi-lo)/2 for lo, hi in confidence_intervals],
capsize=5, color=['skyblue', 'lightgreen', 'salmon'])
plt.title("A/B测试转化率对比")
plt.ylabel("转化率")
plt.xlabel("变体")
# 添加数值标签
for bar, rate in zip(bars, conversion_rates):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.001,
f'{rate:.1%}', ha='center', va='bottom')
plt.show()
图表说明:变体B的转化率显著高于A和C,且置信区间不重叠,可判定为最优。
四、综合AI测试平台架构
4.1 系统架构图(Mermaid)
graph TD
subgraph Data Layer
A[日志系统] --> D[数据湖]
B[测试用例库] --> D
C[用户行为日志] --> D
end
subgraph AI Engine
D --> E[自动化测试生成]
D --> F[缺陷预测模型]
D --> G[A/B测试优化器]
end
subgraph Application Layer
E --> H[Test Execution Engine]
F --> I[告警中心]
G --> J[流量调度]
end
H --> K[测试报告]
I --> L[工单系统]
J --> M[前端服务]
K --> N[可视化仪表盘]
L --> N
M --> N
N --> O[反馈至AI模型]
O --> E
O --> F
O --> G
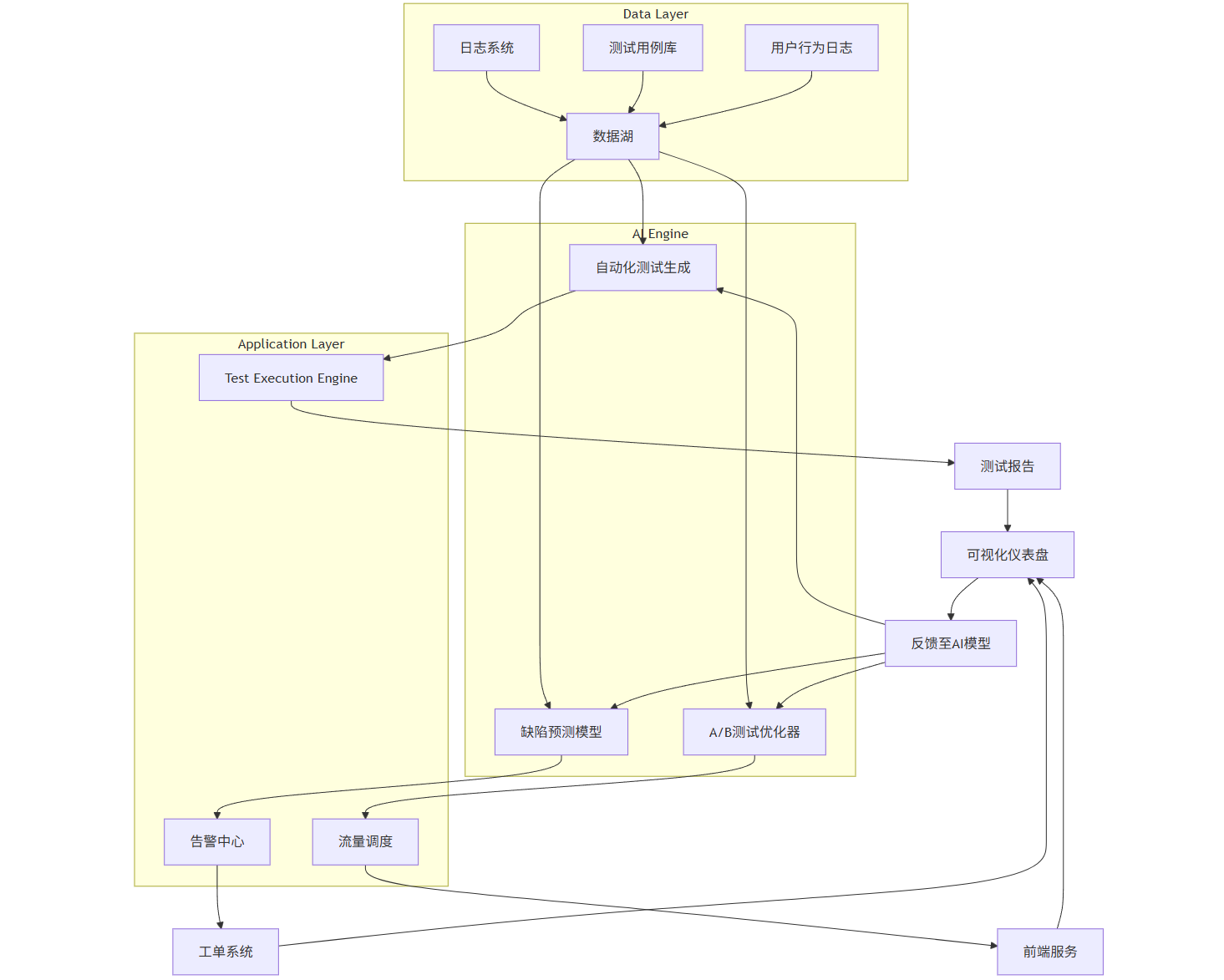
4.2 核心组件说明
- 数据湖:集成日志、测试数据、用户行为等多源数据;
- AI引擎:包含三大AI模型,支持模型热更新;
- 测试执行引擎:支持Selenium、Playwright、Appium等;
- 可视化仪表盘:展示测试覆盖率、缺陷趋势、A/B测试结果。
五、Prompt工程在AI测试中的应用
5.1 高效Prompt设计原则
- 角色定义:明确AI角色(如“资深测试工程师”);
- 上下文清晰:提供足够背景信息;
- 结构化输出:要求JSON、代码块等格式;
- 约束条件:指定技术栈、安全要求。
5.2 多场景Prompt示例
1. 生成测试用例
你是一名资深QA工程师,请为以下功能生成5个边界测试用例:
功能:用户注册,要求邮箱格式正确,密码长度8-16位,包含大小写字母和数字。
输出格式:
- 用例编号
- 输入数据
- 预期结果
- 测试类型(正向/负向)
2. 分析错误日志
请分析以下Java错误日志,定位可能原因并提出修复建议:
日志:java.lang.NullPointerException at com.app.UserController.saveUser(UserController.java:45)
上下文:UserController第45行调用user.getProfile().save()
请输出:
1. 根本原因
2. 修复方案
3. 预防措施
3. 优化A/B测试配置
我们正在进行登录页A/B测试,当前变体:
- A:蓝色按钮
- B:绿色按钮
- C:橙色按钮
数据:A转化率5.1%,B 5.8%,C 5.3%,样本各1万。
请使用贝叶斯方法评估哪个变体最优,并建议下一步动作(继续实验/选择B/合并A/C)。
六、未来展望与挑战
6.1 发展趋势
- AI原生测试工具:如Testim、Mabl已集成AI元素识别;
- 自愈测试:脚本自动修复因UI变更导致的失败;
- 测试生成即服务(Testing-as-a-Service):云端AI测试平台。
6.2 挑战与对策
|
模型可解释性差 |
使用SHAP、LIME等解释工具 |
|
数据隐私 |
本地化部署、数据脱敏 |
|
模型漂移 |
定期重新训练、监控性能 |
|
安全风险 |
代码沙箱、权限控制 |
七、总结
AI正在深刻重构软件测试的范式。通过自动化测试框架的智能化生成、智能缺陷检测的提前预警、以及A/B测试优化的动态决策,AI显著提升了测试效率、覆盖率和决策质量。结合代码实践、流程图、Prompt设计和可视化图表,本文展示了AI测试的完整技术栈与实施路径。未来,随着大模型和边缘计算的发展,AI测试将向更自主、更精准、更实时的方向演进,成为软件质量保障的核心支柱。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)