向量数据库在知识库中的应用
向量数据库是一种将数据存储为向量形式,并基于向量相似性进行高效检索和管理的数据库系统。随着人工智能和自然语言处理技术的快速发展,向量数据库在知识库构建、管理和应用方面展现出巨大的潜力。以下将详细探讨向量数据库在知识库中的应用。
·
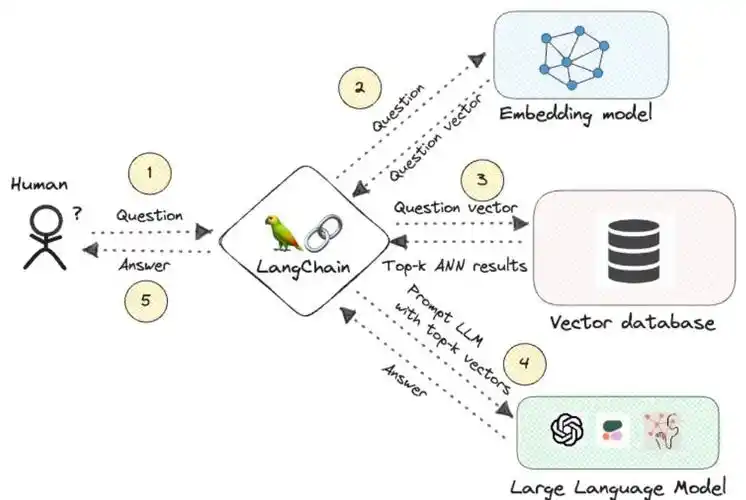
向量数据库在知识库中的应用
向量数据库是一种将数据存储为向量形式,并基于向量相似性进行高效检索和管理的数据库系统。随着人工智能和自然语言处理技术的快速发展,向量数据库在知识库构建、管理和应用方面展现出巨大的潜力。以下将详细探讨向量数据库在知识库中的应用。
一、向量数据库在知识库中的核心优势
-
高效相似性搜索:
- 向量数据库通过向量嵌入技术,将知识库中的实体和关系转换为高维向量,实现基于向量相似性的快速检索。
- 相比传统数据库,向量数据库能够更高效地处理复杂查询,如语义搜索、推荐系统等。
-
语义理解能力:
- 向量数据库能够捕捉文本数据的语义信息,通过向量相似性判断文本之间的关联程度。
- 这使得知识库能够更准确地理解用户查询的意图,提供更相关的结果。
-
灵活的数据表示:
- 向量数据库支持多种数据类型的嵌入,包括文本、图像、音频等。
- 这使得知识库能够整合多模态数据,提供更丰富的信息。
二、向量数据库在知识库中的具体应用场景
-
语义搜索:
- 用户输入自然语言查询时,向量数据库能够将查询转换为向量,并在知识库中搜索最相似的向量。
- 例如,在医疗知识库中,用户可以通过输入症状描述,快速找到相关的疾病信息和治疗方案。
-
智能问答系统:
- 向量数据库可以作为智能问答系统的后端支持,通过向量相似性匹配问题和答案。
- 这使得问答系统能够更准确地理解用户问题,提供更精确的答案。
-
推荐系统:
- 在知识库中,向量数据库可以根据用户的历史行为和偏好,推荐相关的内容或产品。
- 例如,在电商知识库中,系统可以根据用户的购买记录和浏览历史,推荐相似的商品或相关的优惠信息。
-
知识图谱构建与补全:
- 向量数据库可以用于知识图谱的构建和补全,通过向量相似性发现实体之间的潜在关系。
- 这有助于完善知识图谱的结构,提高知识库的准确性和完整性。
-
跨语言处理:
- 向量数据库能够处理不同语言之间的语义相似性,支持跨语言的知识库应用。
- 例如,在多语言新闻知识库中,系统可以通过向量相似性匹配不同语言的新闻报道,提供全面的信息。
三、向量数据库在知识库中的实施步骤
-
数据预处理:
- 对知识库中的数据进行清洗、去重和标注等预处理操作,确保数据质量。
-
向量嵌入:
- 使用预训练的嵌入模型(如Word2Vec、BERT等)或自定义的嵌入模型,将知识库中的实体和关系转换为向量。
-
索引构建:
- 在向量数据库中构建索引,以便快速检索相似的向量。
-
查询处理:
- 当用户提交查询时,将查询转换为向量,并在向量数据库中执行相似性搜索。
-
结果返回与展示:
- 将搜索结果返回给用户,并以易于理解的方式展示。
四、向量数据库在知识库中的挑战与未来展望
-
挑战:
- 向量嵌入的质量直接影响检索效果,需要不断优化嵌入模型。
- 向量数据库的可扩展性和性能需要进一步提高,以满足大规模知识库的需求。
- 数据隐私和安全问题也需要得到关注,确保知识库中的敏感信息不被泄露。
-
未来展望:
- 随着技术的不断发展,向量数据库将在知识库领域发挥越来越重要的作用。
- 未来,向量数据库可能会与图数据库、关系数据库等结合,形成更强大的知识库管理系统。
- 同时,向量数据库也将在更多领域得到应用,如智能客服、智能教育等。
向量数据库的相关技术与工具
一、向量数据库的核心技术
-
数据向量化
- 定义:将原始数据(如文本、图像、音频等)通过特定的数学模型或算法转化为数值向量的过程。
- 方法:
- 文本向量化:使用TF-IDF、Word2Vec、GloVe、BERT等模型将文本转换为向量。
- 图像向量化:通过卷积神经网络(CNN)等模型提取图像特征,将其转换为向量。
- 音频向量化:通过声学特征提取方法(如MFCC)将音频信号转换为数值向量。
-
向量存储
- 特点:向量数据通常是高维的,存储方案需高效且可扩展,以支持海量数据。
- 技术:采用压缩存储技术减少存储开销,同时对数据进行分片处理。
-
相似度计算
- 定义:计算查询向量与存储向量之间的相似度,以找到最相似的数据。
- 方法:常用的相似度计算方法包括欧氏距离、余弦相似度等。
-
索引技术
- 定义:为了提高查询效率,向量数据库使用特殊的索引技术来组织数据。
- 方法:
- 基于空间划分的索引算法:如KD树、Ball Tree等。
- 哈希方法:如局部敏感哈希(LSH)等。
- 图索引算法:如HNSW(分层导航小世界图)等。
二、向量数据库的工具
-
开源向量数据库
- Milvus:由Zilliz开发,专为大规模向量相似性搜索设计,支持多种索引类型,适用于图像检索、推荐系统等场景。
- Faiss:由Facebook AI Research开发,针对相似性搜索进行了优化,特别适合需要高性能处理的场景。
- Annoy:由Spotify开发,适用于大型数据集的近似最近邻搜索,特点是构建索引速度快且占用空间小。
- Chroma:开源且轻量级,适合快速搭建小型语义搜索应用,提供了高效的近似最近邻搜索功能。
- Weaviate:开源的向量搜索引擎,支持多模态数据类型,集成了机器学习功能,适合处理文本、图像等多种数据类型。
- Qdrant:开源的向量相似性搜索引擎和数据库,提供了一个生产就绪的服务和一个易于使用的API。
- Vearch:云原生的分布式向量数据库,支持混合搜索、矢量搜索和标量过滤,适用于AI应用程序中的高效相似性搜索。
-
商业向量数据库服务
- Pinecone:提供托管的向量数据库服务,支持自动扩展和高效的向量检索,适用于大规模、高并发的应用场景。
- Supabase:开源的Firebase替代方案,提供向量数据存储与检索能力,适用于需要快速开发的场景。
- Vespa:大规模的搜索引擎,支持向量检索、文本搜索和结构化数据搜索,适用于企业级应用。
三、向量数据库的应用场景
- 推荐系统:通过计算用户与物品向量的相似性,向用户推荐可能感兴趣的物品。
- 图像和视频搜索:基于内容的检索,通过向量表示图像或视频的特征,实现快速相似性搜索。
- 自然语言处理:使用词向量或句向量模型进行语义搜索、相似性计算和文本分类等任务。
- 生物信息学:在基因组和蛋白质数据中,使用向量表示进行相似性搜索和分析。
- 搜索引擎:根据查询的向量表示对搜索结果进行排序和检索,提高搜索的准确性和相关性。
四、选型考虑
在选择向量数据库时,需要考虑以下因素:
- 数据规模:向量数据库需要能够处理和存储所需规模的数据。
- 查询性能:对于实时性要求较高的应用,查询性能是关键考虑因素。
- 索引和存储方式:不同的索引和存储方式对查询性能和存储效率有显著影响。
- 扩展性和分布式处理:如果数据量非常大,支持分布式处理的数据库可能更合适。
- 易用性和支持服务:商业产品可能在易用性、支持服务方面有优势,而开源选项则提供了较高的定制灵活性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)