企业级私有知识库构建全流程实战:从RAG原理到Web部署
六、DeepSeek-R1-Distill-Qwen7B微调实战。用户问题向量化 → 相似性搜索 → Top-K文档召回。:支持PDF/Word/Markdown等20+格式。更多AI大模型应用开发学习内容,尽在下方二维码领取。八、LlamaIndex+Chroma本地化部署。一、LlamaIndex企业知识库构建实战。三、DeepSeek-R1快速部署方案。:7B模型仅需14GB显存(FP16)
一、LlamaIndex企业知识库构建实战
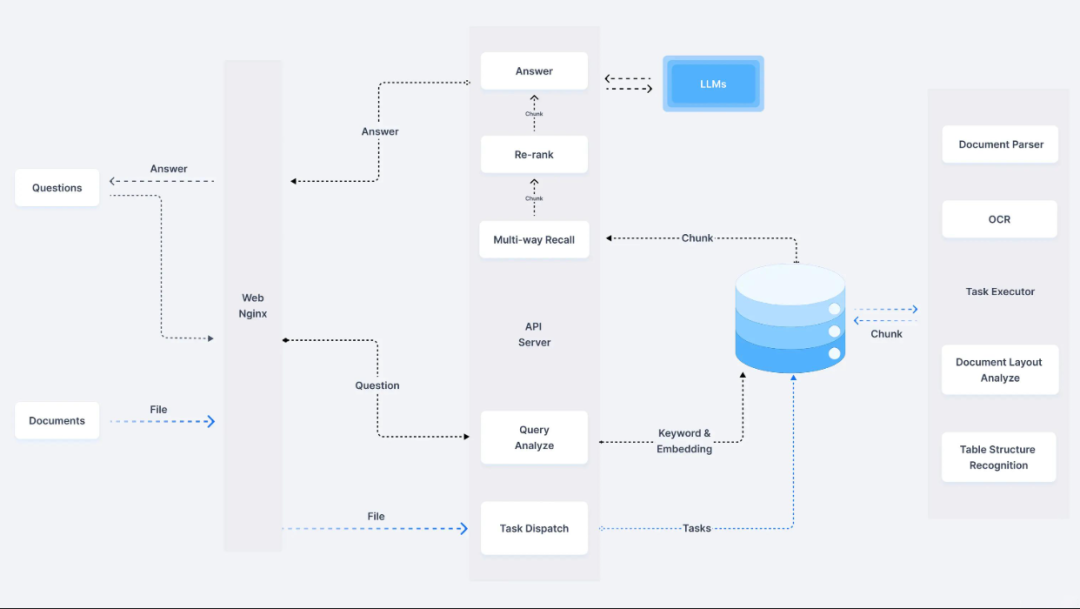
1.1 LlamaIndex核心功能解析
LlamaIndex是大模型时代的数据处理中枢,专为知识库构建设计,核心能力包括:
-
多格式文档加载:支持PDF/Word/Markdown等20+格式
-
智能分块策略:
Python
from llama_index.core.node_parser import SentenceSplitter splitter = SentenceSplitter( chunk_size=512, # 块大小 chunk_overlap=64, # 块间重叠 separator="\n" # 分割符 ) nodes = splitter.get_nodes_from_documents(documents)-
混合检索:结合向量搜索与关键词匹配
企业级知识库架构:
Markup
[数据湖] → LlamaIndex预处理 → [向量存储] → [检索服务]二、RAG技术深度解析
2.1 RAG三阶段工作原理
检索阶段:
-
用户问题向量化 → 相似性搜索 → Top-K文档召回
-
增强阶段:
Python
prompt_template = """ 基于以下知识: {context_str} 请回答:{query_str} 要求: - 引用文档编号 - 不超过200字 """生成阶段:大模型整合检索结果生成答案
与传统微调对比:

三、DeepSeek-R1快速部署方案
3.1 模型特点与性能
-
推理速度:A100单卡达1200 tokens/s
-
显存占用:7B模型仅需14GB显存(FP16)
Docker部署命令:
Bash
docker run -d --gpus all \ -p 8000:8000 \ -v /data/deepseek:/models \ deepseekai/deepseek-r1:latest \ --model-path /models/deepseek-r1-7b \ --max-length 1024API调用示例:
Python
import requests response = requests.post( "http://localhost:8000/generate", json={"prompt": "量子计算的主要挑战是什么?", "temperature": 0.7} ) print(response.json()["text"])四、Conda环境配置规范
4.1 环境管理最佳实践
创建专用环境:
Bash
conda create -n rag python=3.10 conda activate rag pip install llama-index chromadb deepseek transformers streamlit环境导出与共享:
Bash
conda env export > environment.yml conda env create -f environment.yml五、Embedding模型选型与优化
5.1 主流模型性能对比

本地加载示例:
Python
from langchain.embeddings import HuggingFaceEmbeddings embed_model = HuggingFaceEmbeddings( model_name="BAAI/bge-large-zh", model_kwargs={'device': 'cuda'}, encode_kwargs={'normalize_embeddings': True} ) vectors = embed_model.encode_documents(["量子计算利用量子比特..."])六、DeepSeek-R1-Distill-Qwen7B微调实战
6.1 模型蒸馏原理
-
教师模型:Qwen-14B
-
学生模型:Qwen-7B
-
知识迁移率:92%
微调代码核心:
Python
from transformers import TrainingArguments training_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=8, gradient_accumulation_steps=4, fp16=True, logging_steps=100 ) trainer = Trainer( model=model, args=training_args, train_dataset=dataset, compute_metrics=compute_accuracy ) trainer.train()七、知识库效果评估体系
7.1 测试用例设计

7.2 评估指标
Python
def evaluate_rag(answer, ground_truth): # 准确率 accuracy = f1_score(ground_truth, answer) # 响应延迟 latency = time.time() - start_time # 相关性 relevance = cosine_similarity(embed(answer), embed(question)) return {"accuracy": accuracy, "latency": latency, "relevance": relevance}八、LlamaIndex+Chroma本地化部署
8.1 知识库构建流程
初始化存储:
Python
import chromadb client = chromadb.PersistentClient(path="/data/knowledge_db") collection = client.create_collection("enterprise_docs")数据注入:
Python
from llama_index.core import VectorStoreIndex index = VectorStoreIndex.from_documents( documents, storage_context=storage_context, embed_model=embed_model )版本管理:每日自动备份+差异更新
九、Streamlit Web应用开发
9.1 前端界面核心代码
Python
import streamlit as st st.title("企业知识问答系统") question = st.text_input("请输入您的问题:") if st.button("提交"): with st.spinner('正在查询...'): result = rag_query(question) st.markdown(f"**答案**:{result['answer']}") st.write("参考文档:") for doc in result['sources']: st.caption(f"- {doc}")部署命令:
Bash
streamlit run app.py --server.port 8501 --server.address 0.0.0.0十、总结
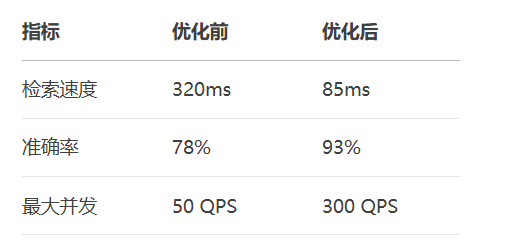
性能基准(A100测试)
更多AI大模型应用开发学习内容,尽在下方二维码领取


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)