让大模型像人类一样,边搜索+边提炼:非常医疗诊疗的循证支持
论文《Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs》提出了一种名为AutoRefine的新框架,旨在解决大语言模型(LLMs)在检索增强推理中的局限性。传统方法通常只关注最终答案的正确性,而忽视了检索和提炼过程的质量。AutoRefine通过引入“search-and-refine-
让大模型像人类一样,边搜索+边提炼:非常医疗诊疗的循证支持
- 论文大纲
- 理解
- 解法拆解
- 提问
- 1. 关于多轮搜索的动机
- 2. 关于“Refine”步骤的独特性
- 3. 关于检索奖励与答案奖励的平衡
- 4. 关于搜索引擎质量
- 5. 关于训练数据与混合任务
- 6. 关于GRPO与传统PPO对比
- 7. 关于离线文本与实时检索
- 8. 关于潜在推理错误时的学习修正
- 9. 关于文档长度与提炼规模
- 10. 关于模型大小与训练代价
- 11. 关于自动检索 vs. 人工指令
- 12. 关于搜索的自然语言 Query 质量
- 13. 关于 Search vs. 没 Search 的对照
- 14. 关于 Refine 输出的可控性
- 15. 关于多跳QA之外的复杂推理
- 16. 关于噪音文档的处理深度
- 17. 关于“过程可视化”与可解释性
- 18. 关于多语言或跨语言检索
- 19. 关于不可预期的问题类型
- 20. 关于最终实际应用价值
论文:Search and Refine During Think:
Autonomous Retrieval-Augmented Reasoning of LLMs
代码:https://github.com/syr-cn/AutoRefine
论文大纲
├── 1 引言【提出检索增强推理的背景和动机】
│ ├── LLM内置知识库的局限性【问题动机】
│ ├── RAG(Retrieval-Augmented Generation)的兴起【方法背景】
│ └── 问题:检索噪声与信息筛选困难【挑战点】
├── 2 现有检索增强推理方法【现状概述】
│ ├── “search-during-think”范式【传统思路】
│ │ ├── 基于多轮检索【搜索动作】
│ │ └── 直接用检索文档生成答案【缺乏中间筛选】
│ └── 局限:难以过滤冗余文档,检索奖励缺失【问题所在】
├── 3 AutoRefine框架【提出的解决方案】
│ ├── “search-and-refine-during-think”新范式【方法核心】
│ │ ├── 显式Refine阶段【提炼关键信息】
│ │ └── 多次迭代检索与筛选【循序渐进优化】
│ ├── 结合检索奖励和答案奖励【奖励机制】
│ │ ├── Outcome-Based Reward【衡量最终答案正确性】
│ │ └── Retrieval-Specific Reward【鼓励高质量文档提取】
│ └── Group Relative Policy Optimization (GRPO)【强化学习算法】
│ ├── Token级别优势估计【细化奖励信号】
│ └── 避免过度依赖KL惩罚【平衡策略更新】
├── 4 实验设置与结果【方法效果验证】
│ ├── 数据集:单跳与多跳QA任务【实验场景】
│ ├── 实验对比:SFT、Search-R1等【对照基线】
│ ├── 效果:多项指标明显提升【结果概要】
│ └── 分析:多轮检索和Refine环节显著提高正确率【关键发现】
├── 5 关键细节分析【深入探讨】
│ ├── 多轮搜索行为【搜索频次与成功率】
│ ├── Refine步骤的价值【如何萃取关键信息】
│ └── 不同检索深度下的鲁棒性【文档噪声与模型表现】
├── 6 方法优点与局限【总结与思考】
│ ├── 优点:搜索质量更高,信息利用更充分【实用性】
│ ├── 局限:模型规模和语料时间戳等问题【不足之处】
│ └── 对评测度量(只用EM或F1)可能忽视语义等价【评价的限制】
└── 7 结论与未来工作【应用与发展】
├── AutoRefine对检索增强推理的改进【研究意义】
├── 扩展到大型模型与在线动态检索【未来方向】
└── 更灵活的评测方式与人机协同【可能的演进路径】
理解
现有大多数方法只奖励“最终答案正确与否”,对过程中的搜索动作(生成检索Query)、提炼过程并没有精细化的激励,因此模型在检索阶段较为“盲目”或“懒惰”,搜索质量不高,或者搜索之后提炼信息的质量也无从评估。
最关键的底层逻辑是“让LLM在推理时,不断与外部世界交互,并对交互结果进行筛选和再加工”。
不只是提出简单的“加检索”或“加提炼”,而是要让模型能在推理中主动调用、主动提炼,并对整个过程进行强化学习优化。
这才是论文要解决的核心本质。
-
在多个数据集进行对比实验
-
作者选择了单跳问题(如NQ、TriviaQA)和多跳问题(如HotpotQA、2Wiki等)进行对比。这样做可以验证:
- 单跳场景:只要检索一次或多次,差别如何?
- 多跳场景:多轮“搜索+提炼”是否尤其关键?
-
通过准确率(Exact Match或F1分数)来量化最终答案的正确率。
-
-
引入不同的检索深度,考察噪音情况
- 他们让检索引擎每次返回1、3、5、7条文档,观察模型在不同噪音环境下的表现是否依旧保持稳健。
- 结果显示,在噪音上升(文档条数越多,越可能夹杂无关信息)后,若有Refine步骤,模型依旧能处理好,无Refine步骤的模型准确率则普遍下降。
-
单独跟踪并衡量“检索成功率”
- 不仅看最终答案对不对,还统计了检索调用后,返回的文档里是否包含了正确答案的片段(搜索成功率)。
- 结果表明,带有“检索奖励”的模型搜索成功率更高,说明引入检索专属奖励对改进搜索质量的确有效。
-
在消融实验里移除某些模块
- 例如,去掉“检索奖励”、去掉“Refine”模块等,看对最终结果造成了多少损失。
- 验证了核心设计(Search+Refine+Retrieval Reward)对性能提升都不可或缺。
-
作者的观察力:他们不仅留意大语言模型在实际应用中的常见问题,还抓住了“多轮检索”和“中途提炼”这两个被普遍忽视但非常重要的环节,将其作为关键切入点。
-
作者的假设大胆且系统:他们提出了一个完整的新范式“search-and-refine-during-think”,并且把“检索奖励”也纳入整体设计。
1. 「目的」是什么?
问1:文中提出的“Search and Refine During Think”这一方法,最主要想解决什么问题?
答1:这个方法主要想解决「大语言模型(LLMs)本身知识有限」和「检索到的文档噪音比较多」这两个核心问题。
也就是说,模型需要借助检索(search)来弥补知识不足,但同时又要通过“refine”步骤来过滤或提炼检索到的文档,使得最终回答更准确、更具针对性。
2. 「Search」指的是什么?
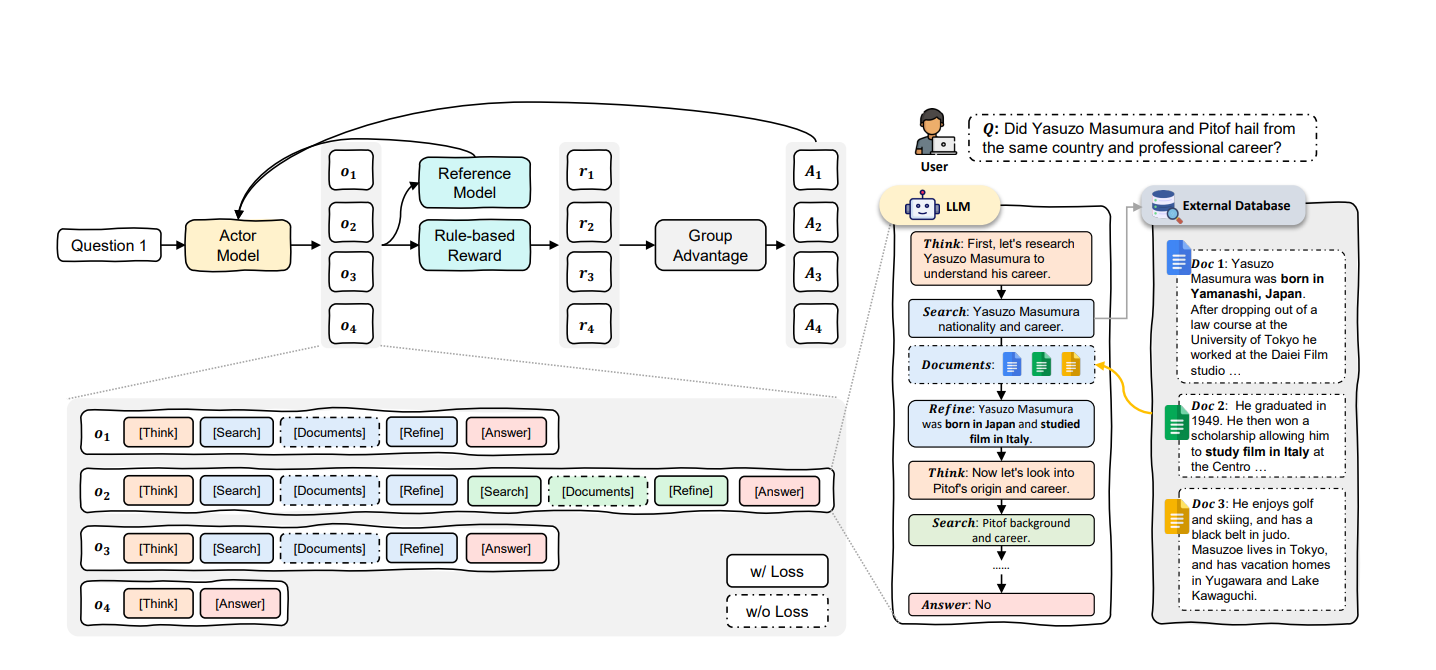
问2:文中的“Search”具体做了哪些事?
答2:它指的是在大语言模型内部“思考”时,可以随时调用一个外部的检索引擎,输入一个查询词(query),让系统返回若干条文档(可能是几段文本)。之后,模型会对这些文档进行后续分析与处理。
关联到已有知识:在之前学过的信息检索或搜索引擎中,输入的关键词会由系统匹配文档返回给我们。模型在这里相当于“自问自答”,边想边搜索。
3. 「Refine」又为什么要这样做?
问3:为什么检索完之后,还要特意加上一个“Refine”步骤去提炼文档内容?
答3:因为检索得到的文档往往包含大量不相关或冗余信息。模型必须先“筛选并提炼”出和问题真正相关的部分,这样才能更好地把关键信息保留下来,减少噪音,最终生成正确答案。
关联到已有知识:这类似于我们做文献综述时,先从数据库检索到一大堆论文摘要,然后再做二次筛选,找出最切题、最有效的部分来支持我们的论点。
4. 「During Think」中的“Think”指的是什么?
问4:在“Search and Refine During Think”里,“Think”到底代表什么步骤?
答4:这里的“Think”代表大语言模型在形成最终答案之前,所进行的多轮推理过程(也可以理解为“草稿”或“中间思路”)。
在这个过程中,模型会根据自己对问题的理解,决定何时发起检索(Search),检索后再整合信息(Refine),如此往复,直到它觉得“我已经获取到足够的信息,可以给出答案了”。
关联到已有知识:这和我们平时做题时很像:先自己想一下(“Think”),觉得还缺少信息,就去“搜索/翻笔记/翻书”,获取以后再“总结精炼”,然后再继续思考,最后写下正式答案。
5. 它和我们已知的「强化学习(RL)」是怎样结合的?

问5:文章中为什么还提到“用强化学习进行后期训练(RL post-training)”,这个有什么作用?
答5:他们用强化学习的思路来“奖励”模型发起好的搜索并做高质量的文档提炼。除了对最终答案进行打分,还对模型的搜索行为、提炼内容进行额外的奖励或惩罚。
例如,如果“提炼”文本里包含了正确答案相关的关键信息,就会给出正向奖励,以此鼓励模型以后多做这种有益的筛选;如果搜索或提炼的内容很杂乱没有价值,则奖励较低。
关联到已有知识:在之前的“RLHF(通过人类反馈的强化学习)”或者其他强化学习里,我们会对模型输出进行奖励,以便它能学会不断迭代、朝着目标优化。这里的额外之处在于,将检索与提炼的过程,也纳入奖励考量,而不仅仅是终端答案对或错。
6. 为什么要在检索之后显式添加“Refine”步骤?
因为如果仅靠最终回答时的“一次性大模型推理”来过滤噪音,效率与准确率都不理想。
显式Refine能让模型先“整理文献”、缩小范围,再进入下一步推理或决定是否继续搜索。
7. 为什么要在训练中对搜索/提炼进行额外奖励(Retrieval Reward)?
因为仅用“最终答案对错”的奖励,会忽略搜索/提炼过程;
模型可能侥幸猜对答案,也可能浪费检索次数,始终学不到“如何更精准检索与提炼”。
只有对过程施加奖励,才能真正培养模型的“自主检索+筛选”能力。
在更长远的应用场景中,大模型将可能演化为“类研究员”——能自发找资料、筛选证据、不断验证假设,而不只是“静态回答者”
解法拆解
-
关键流程
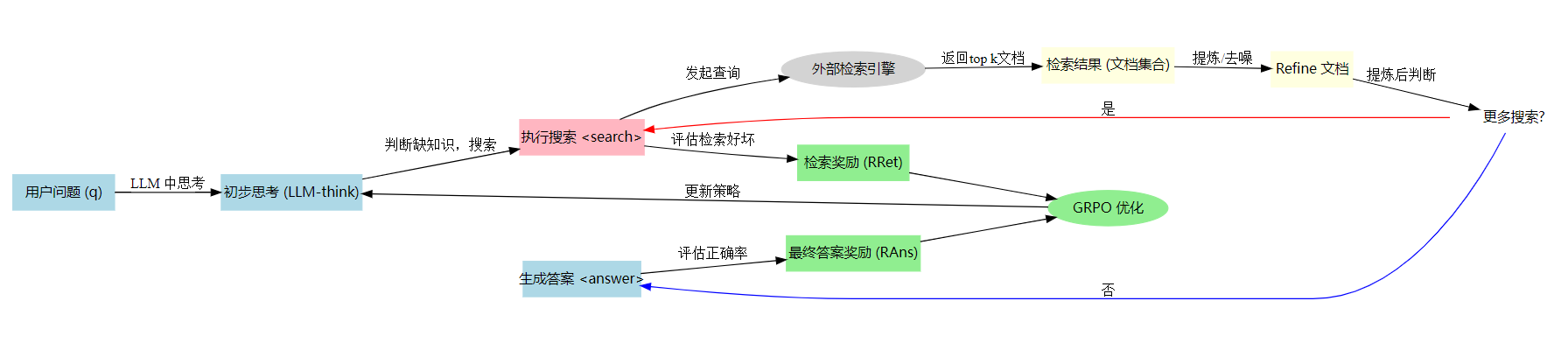
- LLM在思考过程中多次调用外部搜索(Search)
- 对搜索到的内容进行提炼(Refine),去噪和保留关键信息
- 通过强化学习,分别对检索行为和最终答案进行奖励或惩罚,最终促使模型在“搜索-提炼-回答”上都能最优
-
与同类算法的主要区别
- 增加了显式的Refine步骤:不再只是一口气把所有检索文档喂给模型,而是先进行“知识提炼”
- 检索有专属奖励:不仅评价最终答案正确与否,还会根据检索文本是否含有正确要点给予奖励
- 多轮搜索策略:模型可在回答前多次调用检索,每一次搜索都经过思考、提炼,再决定是否还要继续搜索
总体思路
整个解法形式 = 子解法1 + 子解法2 + 子解法3 + … + 子解法n
如果我们根据论文核心内容来看,大致可以拆解为 4 个主要子解法(对应 4 个关键特征)。
若在某个特征下又衍生了特殊子特征,也可以继续细分。
下面按“特征 -> 子解法”的方式进行拆解:
子解法1:多轮自发检索 (Autonomous Multi-turn Search)
-
对应特征:LLM在推理中,时常需要外部实时信息或补充知识,但一次搜索往往不足。
-
子解法内容:让模型在回答之前,可以多次插入
<search>指令,从检索引擎获得文档,而不是只在初始把问题扔给搜索。 -
子解法因何而用?
- 之所以用“多轮搜索”,是因为LLM可能在第一轮检索后依旧缺少关键信息,或者对问题有了更准确的理解后,需要进一步精细搜索。
- 这样能够减少单次搜索易受噪音干扰的风险,并使检索过程更具针对性。
子解法2:显式提炼(Refine)过程
-
对应特征:检索引擎返回的文档往往包含大量噪音、冗余信息,“噪音过多”导致模型无法聚焦答案。
-
子解法内容:在每次检索后,插入
<refine>指令,由模型对文档进行“去伪存真”。提炼出“真正与当前问题推理相关的要点”,丢弃无关内容。 -
子解法因何而用?
- 之所以要“Refine”,是因为只依赖LLM最终回答时自行过滤噪音效率不高;显式提炼能把文档长度缩减,保留精华,使后续推理更准确。
子解法3:双重奖励(Retrieval Reward + Outcome Reward)
-
对应特征:之前的强化学习方法多只关注“最终答案对不对”,忽略了对“检索质量”的专门激励,导致模型在检索上懒惰或盲目。
-
子解法内容:作者在RL框架中设置了两种奖励:
- 最终答案正确所带来的奖励(Outcome-Based);
- 检索文档中是否含有正确答案要素所带来的检索奖励(Retrieval-Specific)。
-
子解法因何而用?
- 之所以双重奖励并行,是因为仅仅看最后回答可能无法区分检索好坏;需要在过程阶段中对“检索与提炼”给出精准反馈,才能让模型学会更好地搜索、提炼。
子解法4:组策略优化(Group Relative Policy Optimization / GRPO)
-
对应特征:多轮搜索和Refine后,学习信号分散,且标准的PPO往往对多步骤生成的优势估计欠精准。
-
子解法内容:引入“组内对比”的GRPO算法:每个batch里采样多个轨迹,计算相对优势(Advantage),把检索文档部分mask掉不参与loss。
-
子解法因何而用?
- 之所以改进优化算法,是因为在多轮搜索+提炼场景下,若仍用传统PPO,可能收敛更慢;而GRPO在对比多条样本后能更好区分哪些搜索-提炼动作做得好,哪些不好。
小例子
假设一个多跳问题:“苏格拉底的老师是谁,他是什么流派的创始人?”
- 子解法1:模型先搜索“苏格拉底老师”,得到大段文档;感觉信息还不全,再次搜索“柏拉图是哪派的创始人?”
- 子解法2:在每次搜索后,把无关段落过滤掉,提炼“柏拉图=亚里士多德老师?苏格拉底=柏拉图老师?柏拉图是‘学院派’创始人”
- 子解法3:如果提炼文本中确实出现了“苏格拉底是柏拉图老师”“柏拉图创立学园”,则该轮检索得到正向的检索奖励;最终答案若正确,还会再给一个最终答案奖励。
- 子解法4:用GRPO对比多条样本的奖励差异,慢慢让模型学会更好搜索与提炼。
1.3 子解法彼此的逻辑链——决策树还是网络?
从结构看,这些子解法并非简单线性串联,更像是一个网络式结合,在解题时环环相扣:
- 起点:模型决定是否要搜索 → 如果搜索,就执行子解法1
- 拿到文档:执行子解法2(Refine)
- 奖励机制:子解法3在搜索和答案阶段分别提供奖励信号
- 优化方法:子解法4贯穿训练过程,帮助模型在“搜索-提炼-回答”这条路径上学到最佳策略
所以,可以用一个简化的决策树或流程图描述:
(开始)
↓
[是否需要搜索?] → Yes → 触发子解法1(多轮搜索)
| ↓ (检索结果)
| 子解法2(Refine)
| ↓
No ←----循环判断是否还需下一轮搜索
↓
[生成答案 + Outcome Reward(子解法3)]
↓
[训练阶段用GRPO(子解法4)对整个搜索-回答轨迹做优化]
↓
(结束)
2. 是否存在隐性方法
2.1 逐行对比解法,寻找隐性关键步骤
从论文文本或实验细节推断,有几处方法并未在“书本式”标题下明示,却在实现中非常关键:
-
在计算RL loss时,对检索文档内容进行mask处理
- 隐性方法:论文中提到,为避免模型过度记忆文档原文,影响梯度,作者对
<document>block内容进行loss屏蔽,使得训练主要关注“生成搜索query”和“refine+answer”的序列。 - 之所以用该隐性方法:因为如果文档本身算进语言模型的loss,模型可能只是在“背文档”,而不是学如何检索和提炼。屏蔽可让模型专注如何请求检索、如何“提炼后再回答”。
- 隐性方法:论文中提到,为避免模型过度记忆文档原文,影响梯度,作者对
-
使用“部分正确就给部分奖励”的策略
- 隐性方法:论文中会把“如果refine的文本里包含了正确答案,但最终答案未答对”,给0.1分之类的部分奖励。
- 之所以用该隐性方法:这样能细化对过程的反馈,不会让检索或提炼的努力“付诸东流”。有助于模型渐进地学会搜索和信息筛选。
这些关键点是隐性的,因为它们不像“多轮搜索”“Refine”这样在论文标题大字标明,却是逻辑中必不可少的环节。
2.2 是否存在隐性特征
- 在子解法中,我们看到**“检索成功率”和“Refine提炼率”**本身也可以视为一种隐性特征:论文用它来定义检索奖励、提炼质量,但并不是在论文标题或核心公式里直说“这是一个新的特征”。
- 该特征(检索成功率/提炼成功率)其实是从中间步骤(Refine部分)衍生出来的,用于衡量文档中是否包含正确线索。它不是问题本身的属性,而是模型在执行解题步骤时引入的新度量。
因此,这个“检索成功率/提炼成功率”可以看作隐性中间步骤特征。论文用它做奖励衡量,但并不常明示“这是一个新的必备特征”。
3. 方法可能存在的局限性
根据论文所述与现实情况,潜在局限包括:
-
对检索引擎质量的依赖
- 如果搜索引擎的召回/准确率不够,或领域不覆盖,需要在外部搭建更强大检索系统,否则再怎么Refine也没有高质量信息可用。
-
多轮检索的开销
- 每次搜索都要请求并解析结果,可能带来额外的计算与时延,在大规模实时应用场景下可能过重。
-
强化学习训练复杂度
- 需要设定合理的奖励、对比多个轨迹,且训练过程较难调参;对小规模模型或算力不足环境会带来挑战。
-
对Refine内容的可控性
- 虽然显式Refine能过滤杂质,但如果语言模型在Refine时出现“自我幻想”或截断要点,也可能反过来丢失关键信息。缺乏一定“外部评估”时,依旧有风险。
-
对任务类型的适用范围
- 该方法主要针对需要外部知识、多跳推理的问题;对纯推理或常识充足的问题意义有限。
提问
1. 关于多轮搜索的动机
问题:
论文里为什么要让大语言模型进行多轮搜索?如果一次搜索就能拿到答案,岂不是浪费时间和算力?
答案:
- 一次检索在复杂问题上常难以涵盖所有必需信息;
- 多轮搜索可根据已知结果动态“追问”或细化查询;
- 若只进行一次检索,模型常被噪音干扰或信息不足而答错;
- 作者希望让模型自发识别“不足”,从而发起后续检索,提升最终正确率。
2. 关于“Refine”步骤的独特性
问题:
既然在多轮搜索中,大模型迟早会自己把文档当上下文处理,为什么还要设立一个显式的“Refine”步骤?不就多此一举?
答案:
- 如果只在最终回答阶段处理所有文档,模型可能被数千字的噪音淹没;
- Refine步骤用来提前筛选出真正相关的证据文本,减少模型后续推理负担;
- 实验结果也表明显式Refine后,回答质量更高、更稳定;
- 论文指出,在训练时对Refine做奖励评估,能学到更好的信息筛选策略。
3. 关于检索奖励与答案奖励的平衡
问题:
强化学习时,论文给出了检索奖励(RRet)和答案奖励(RAns)。如果模型为了得到高检索奖励而不断搜索,却浪费资源怎么办?作者是如何在“检索价值”与“过度搜索”之间做平衡的?
答案:
- 论文在整体reward中包含了对最终答案正确性的主导权重;
- 如果盲目搜索次数多,却最终答案不佳,就得不到高总分;
- 只有在“真正需要更多信息”时发起搜索,才可能带来增益;
- 这在多次实验里,模型自己会找到“适度搜索”的平衡点。
4. 关于搜索引擎质量
问题:
如果外部检索引擎本身质量有限(例如搜索结果准确度不高),作者如何保证多轮搜索不变得徒劳?
答案:
- 论文承认检索引擎质量影响系统整体效果;
- 但多轮搜索+Refine能够“迭代式”逼近正确答案,即便噪音较多,也可通过Refine过滤;
- 论文把检索引擎当成给定条件,若引擎再改进(例如更精准的retriever模型),性能会更好。
5. 关于训练数据与混合任务
问题:
作者的训练集只用了 NQ、HotpotQA 这类 QA 数据,若换成别的类型任务(如对话问答、摘要生成),这个“Search+Refine+RL”还能适用吗?
答案:
- 论文重点实验在开放域 QA,但结构设计具有通用性;
- 对话问答、摘要等仍属于“需要外部信息且需过滤噪音”的范畴;
- 作者在文中提到,此框架可拓展到其他领域,只要适当调整奖励定义与检索模式即可。
6. 关于GRPO与传统PPO对比
问题:
论文里用了“Group Relative Policy Optimization (GRPO)”,为什么没用更常见的 PPO、A2C、或其他RL方法?
答案:
- GRPO通过“组对比”方式来稳定训练,解决传统 PPO 在多分支搜索场景下收敛变慢的弊端;
- 作者实验发现 GRPO 在多样化探索中能更快学到检索策略,且参数相对容易调;
- 他们在论文中列举了对比实验,GRPO 收敛速度和稳定性更优。
7. 关于离线文本与实时检索
问题:
作者只在实验中用离线 Wikipedia dump,那如果要实时联网检索最新内容(例如最新新闻、股市行情),是不是还需要改论文方案?
答案:
- 论文并未限制检索一定是静态;
- 多轮搜索与Refine同样适用于实时检索,只要保证检索API可以多次调用;
- 需要额外关注缓存或API调用频次限制,但核心算法不变。
8. 关于潜在推理错误时的学习修正
问题:
如果模型在某次搜索后就走向了错误方向(Refine出错或中途结论偏颇),会不会导致后面的多次搜索都在错误假设上越走越远?
答案:
- 是有这种风险,但强化学习会对最终正确度进行综合评估;
- 当错误结论最终导致低奖励,下次训练时模型倾向于避免重复该策略;
- 多轮搜索也给了“回头补救”机会:若发现信息不足可再检索,减少单次出错带来的连锁影响。
9. 关于文档长度与提炼规模
问题:
Refine 阶段,如果检索到的文档特别长,模型是怎么处理的?是否有最大长度限制?
答案:
- 论文里提到有对检索结果进行截断(如512 tokens)或分段;
- Refine 步骤就是对超过长度的内容做精简或要点提取;
- 作者并没有硬性规定最大长度,但示例中常限制到几百词内,防止上下文爆炸。
10. 关于模型大小与训练代价
问题:
如果把这个方法用在 10B、100B 级别的大模型上,训练成本会不会指数级上升?作者在论文里有没有给出解决思路?
答案:
- 论文中实验主要在 3B 参数规模上进行;
- 作者坦言大模型训练成本更高,但并不必“全参数”都训练,可用 LoRA 等方式做增量调教;
- “逐步搜索+Refine”本身主要在推理时增加代价,训练时若能善用小批量 RL 优化,也可一定程度上控制费用。
11. 关于自动检索 vs. 人工指令
问题:
会不会出现有些题目其实用户已有上下文,不用检索,但模型还在自作主张搜索?作者如何防止无谓搜索?
答案:
- 模型在思考阶段会先判断是否有足够信息;
- 如果用户的问题在提示里已有完备上下文,模型倾向不调用搜索;
- 论文实验显示多轮搜索次数在 1.5~2 左右,说明它并不盲目无限搜。
12. 关于搜索的自然语言 Query 质量
问题:
模型生成的搜索 Query 可能是模糊或词不达意,这样不就搜不到好文档?作者在论文中是如何保证 Query 的质量?
答案:
- 论文中对检索 Query 同样施加了“检索奖励”,如果 Query 毫不相关,就得不到正反馈;
- 经过多次训练,模型学会提炼关键词、复查文档中缺失信息并嵌入下一轮搜索;
- 他们也参考了现有的prompt工程技巧,引导模型输出更明确的搜索句式。
13. 关于 Search vs. 没 Search 的对照
问题:
要证明多轮搜索+Refine 有用,论文里肯定做了消融实验或对照组吧?具体对照方法是怎样的?
答案:
- 论文常设“无检索直接回答”作为 baseline;
- 也设“只做一次检索+不显式Refine”的对照;
- 结果显示多轮搜索+Refine+Retrieval Reward 的方案在多跳任务中大幅领先。
14. 关于 Refine 输出的可控性
问题:
Refine 步骤也有可能剪掉重要信息,或二次创作误导后续推理,作者提供了什么策略避免Refine变成“二次污染”?
答案:
- 论文主张在Refine中保留足量原文片段,减少大段改写;
- 也会结合检索奖励:若最终答案需要的关键信息不在Refine输出里,检索奖励就不给正分;
- 长期训练后,模型自发学习到保留或抽取关键语句。
15. 关于多跳QA之外的复杂推理
问题:
作者说“AutoRefine 对复杂推理很有效”,但大多只展示了 QA 数据。有没有更复杂的场景,比如阅读理解、知识图谱推理?
答案:
- 文中确实以 QA 做主要评测;
- 但理论上同理可拓展到阅读理解、复杂知识推理,只要定义好查询和精简文档的过程;
- 论文鼓励后续在更多数据集实验,比如Bio-Med QA或知识图谱补全等。
16. 关于噪音文档的处理深度
问题:
如果检索到的文档是严重噪音甚至与问题毫不相关,Refine仍然得阅读大段文本,会不会浪费算力?作者有没有想过“先试探+后深度处理”的多阶段框架?
答案:
- 论文目前只展示简单的Refine过程;
- 若噪音极多,可改进为先做快速初筛(如BM25打分或embedding过滤),再进行LLMRefine;
- 这是论文的扩展方向,但在正文里只做了初步提及。
17. 关于“过程可视化”与可解释性
问题:
在多轮搜索中,模型内部如何推断“这一轮需要搜索”?这个过程对人类来说能不能更直观地看懂?作者文章有做可解释化吗?
答案:
- 论文中给了部分示例:在
<think>段落中,模型自语“缺少xx信息,需搜索”; - 这可以看做简易可解释性;
- 但尚未有一个完美的可视化或因果图去呈现搜索决策,作者认为这是未来研究点。
18. 关于多语言或跨语言检索
问题:
论文主要实验都在英文 QA 上。若要在中文、法语或跨语言场景下搜索中、英文文档混合,是否也能套用同样思路?
答案:
- 原理相同,只需更换合适的跨语言检索引擎和embedding;
- RL策略与Refine机制不受语言约束;
- 论文承认多语言检索时,Query生成和文档对齐可能更复杂,需要额外多语言语义模型。
19. 关于不可预期的问题类型
问题:
若用户提的问题没有标准答案(开放式辩论题),多轮搜索+Refine能给出客观结论吗?
答案:
- 模型只能在已有文档信息里查找佐证;
- 若无定论,Refine也只能给出多方观点;
- 论文主要关注有正确答案的QA,对“开放式辩论”未做深入探讨;
- 结论仍是:尽可能多地搜索相关文献,让答案更客观或多元。
20. 关于最终实际应用价值
问题:
理论上“Search & Refine”方案很强大,但在真实产品落地时,会不会因多轮调用、算力消耗、检索API费用而不实用?
答案:
- 作者在结论部分承认,推理速度和API调用成本会增大,需要工程优化或缓存机制;
- 部分应用场景(如学术搜索、专业咨询)依旧值得投入,因为对正确率要求高;
- 他们相信随着硬件进步,开发者能选择性地把多轮搜索应用于真正需要精确答案的场景。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)