大模型之模型参数量估计/GPU计算时间计算
模型的参数越多,其复杂度就越高,能够处理的数据也越多。它们是模型从大量文本数据中学习的结果,不仅编码token的身份,还编码其与其他token的关系。反向传播、Adam 优化和 Transformer 架构,训练所需的内存通常是相同大小的 LLM 推理所需内存的 3 到 4 倍。例如,如果您需要微调大小为 1024×512 的参数,使用选择rank为 8 的 LoRA,您只需要微调以下数量的参数:
Token
Token是基本的数据单位。在文本上下文中,一个Token可以是一个单词、一个单词的一部分(子词),甚至是一个字符——这取决于tokenization 的过程。
Ex “The evil that men do lives after them” would become: | 791 | 14289 | 430 | 3026 | 656 | 6439 | 1306 | 1124 |.
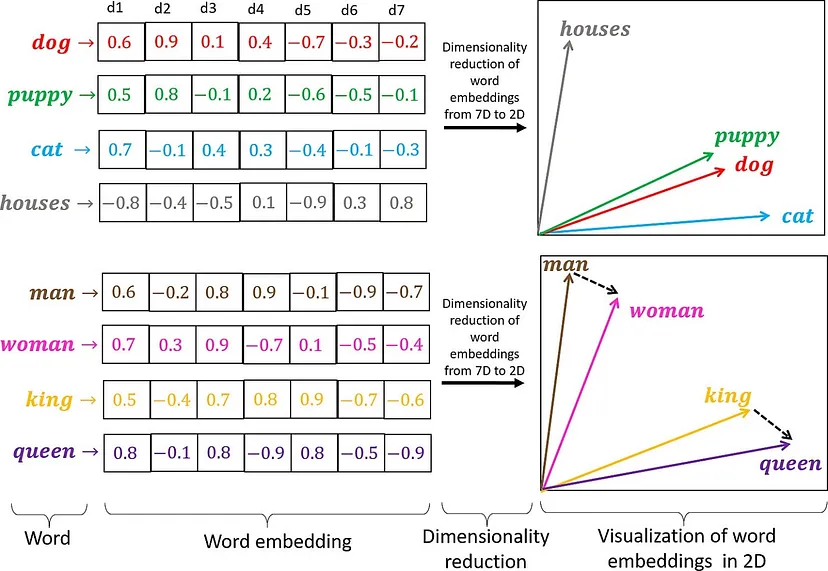
向量
向量为机器处理提供了一个数学框架。向量用于以模型能够理解和处理的数字形式表示文本或数据。
嵌入
为了捕捉 token 之间的含义和语义关系,LLM 采用 token 编码技术。这些技术将 token 转换为称为嵌入的密集数值表示。嵌入对语义和上下文信息进行编码,使 LLM 能够理解并生成连贯且上下文相关的文本。像 Transformer 这样的高级架构使用自注意力机制来学习 token 之间的依赖关系,并生成高质量的嵌入。
token由okenizer进行编码或解码;嵌入模型负责以向量的形式生成文本嵌入。嵌入使 LLM 能够理解单词和短语的上下文、细微差别和微妙含义。它们是模型从大量文本数据中学习的结果,不仅编码token的身份,还编码其与其他token的关系。
Token限制
Token限制是指在提示和模型完成过程中可以使用的最大令牌数量。大多数 LLM 都有token限制,指的是模型一次可以处理的最大令牌数量。token限制由模型的架构决定。
Token处理成本
模型处理的每个 token 都需要计算资源——内存、处理能力和时间。因此,模型需要处理的 token 越多,计算成本就越高。
参数
我们可以将参数视为大型语言模型中的内部设置或刻度盘,可以进行调整以优化获取标记和生成新标记的过程
在训练大型语言模型时,参数是 LLM 的特征,经过调整可以优化模型预测序列中下一个token的能力。
模型尺寸
模型大小是指 LLM 中的参数数量。模型的参数越多,其复杂度就越高,能够处理的数据也越多。然而,模型越大,训练和部署的计算成本也越高。
参数类型
1. float:32位浮点数,4个字节
2. half/BF16:16位浮点数,2字节
3. int8:8位整数,1个字节
4. int4:4位整数,0.5字节
10 亿个参数 = 4 x 10E9 字节 = 4GB
LLM 拥有 700 亿个参数,这意味着该模型拥有 700 亿个可调整参数。这些参数用于学习训练数据中单词和短语之间的关系。模型的参数越多,其复杂度就越高,能够处理的数据也越多。然而,模型规模越大,训练和部署的计算成本也越高。
推理记忆估计
对于 10 亿参数模型(1B),估计的内存需求如下:
浮点精度 4 GB,BF16 精度 2 GB,int8 精度 1 GB。此估算可相应应用于其他版本。
训练所需的内存
保守估计,在参数数量和类型相同的情况下,推理所需内存大约是其四倍。例如,训练一个具有浮点精度的 1B 模型大约需要 16 GB(4 GB * 4)。
梯度
梯度所需的内存等于参数的数量。
优化器状态
优化器状态所需的内存取决于所使用的优化器的类型。
AdamW优化器-需要两倍的参数数量,SGD优化器-需要与参数数量相当的内存。
LoRA/QloRA 技术的内存使用情况
LoRA涉及在原始模型上运行推理并训练较小的模型以达到与训练原始参数几乎相同的效果。
例如,如果您需要微调大小为 1024×512 的参数,使用选择rank为 8 的 LoRA,您只需要微调以下数量的参数:1024×8 + 512×8。
此过程需要对原始参数体进行一次推理(无需梯度和优化器状态),但仍需要一些内存来存储计算过程中的数据。总内存使用量等于这些需求的总和。
估算推理的内存使用量
1B-BF16 模型所需的内存等于参数数量乘以类型的大小:10 亿个参数 * 2 字节 = 20 亿字节。
20 亿字节 = 2 * 1,000 * 1,000 * 1,000 / 1024 / 1024 / 1024 ≈ 2 GB(考虑 1000/1024)³ ≈ 0.93。
估计训练的内存使用情况
反向传播、Adam 优化和 Transformer 架构,训练所需的内存通常是相同大小的 LLM 推理所需内存的 3 到 4 倍。保守估计,使用 4 倍的系数来计算
浮点型参数:1(十亿个参数)* 4(每个浮点型参数的字节数)* 4 = 16 GB

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)