LLM:企业AI应用实例(4)-AI辅助语料标注
本文探讨如何利用大语言模型(LLM)优化传统NLP系统的训练数据,重点介绍三个实践应用:1)通过LLM生成多样化用户问法变体以丰富语料库2)利用LLM的语义理解能力建立智能清洗机制3)结合向量相似度和LLM验证进行语料去重。
适用于LLM初学者和有一定应用经验的朋友。学习调用常规的大语言模型,并进行标注工作。
1 前言
随着大模型应用的普及,一些企业开始尝试将各种场景与大模型进行融合。但是在结合的过程中,当前阶段下,LLM技术依然有些难题无法解决。
1. 知识管理问题
- 知识来源的权威性
- 知识更新的及时性
- 效果保障的责任归属
2. 成本控制问题
- 高并发场景下的计算成本
- 投入产出比的平衡
因此,在特定场景下(尤其是高频客服场景),将LLM作为辅助工具来提升传统模型的效果,可能是过渡阶段的最优解决方案。
应用示例:客服机器人优化
以传统客服机器人为例:
- 现有系统:基于人工配置的QA知识库,使用BERT等预训练模型进行相似度匹配
- 核心流程:用户提问 → BERT模型匹配相似QA → 按规则返回答案
- 效果决定因素:BERT模型训练语料的质量
在完全迁移到LLM方案之前,可以利用LLM的强大能力来优化现有模型的训练数据,从而提升整体服务质量,这不失为一个经济且实用的过渡方案。
本文旨在探讨如何利用大语言模型的能力来标注和优化训练数据,从而提升传统NLP模型的效果。文章将通过实际案例,为LLM初学者和有经验的开发者提供一个实用的应用思路。
2 语料生成
在传统的客服机器人场景中,高质量的训练语料对模型效果至关重要。然而,人工编写耗时耗力,而且难以覆盖用户的多样化表达方式。通过利用LLM的自然语言理解和生成能力,可以快速扩充和丰富现有的训练语料库。
实现思路
1. 基础语料准备
- 收集现有的核心问题集(标准问题)
- 确保这些问题覆盖主要业务场景
- 对问题进行分类和整理
2. 提示词设计
- 明确指示LLM扮演用户角色
- 要求生成的问法要保持语义一致性
- 设定合理的变体数量(如每个标准问题生成50个变体)
- 控制生成的多样性(通过temperature参数)
3. 批量处理流程
- 读取标准问题集
- 调用LLM API进行批量生成
- 结果存储和格式化处理
举例
# 示例提示词模板
prompt_template = """
你擅长语文,擅长站在客户的角度思考
请你根据如下问题,生成50个用户可能提问的不同的问题。
要求:
1. 保持原问题的核心语义不变
2. 模拟真实用户的各种表达方式
3. 考虑不同场景下的表述变化
4. 包含口语化和书面语表达
原问题:{question}
"""这里其实主要依靠提示词,实践的时候有几个注意点:
(1)格式
大模型生成的格式不一定是我们想要的,可以先观察生成的格式,再处理为需要的。比如大模型直接生成:
- 语料A
- 语料B
- 语料C
会有1、2、3着用的标签,直接存到excel不方便,所以观察到格式后,可以清理下(在下面代码的清理数字编号部分)
(2)效果
让大模型直接生成30已经接近极限,因为大模型很容易输出很多相似的,效果不佳(我们需要的是同样意思但是更加丰富的表达)。这里可以利用提示词,多描述一些场景和例子,或者让大模型一步一步代入用户视角思考每个环节会遇到哪些问题,再生成语料(这部分靠提示词,在本篇不再做赘述)
实践代码如下:
import os
from dashscope import Generation
import dashscope
import pandas as pd
def get_response(messages):
response = Generation.call(
api_key='sk-xxxxxxxxxxxxxxxxxxxxxxx', # 请替换为您的API key
model="qwen-max", # 能用最好的就用最好的
messages=messages,
result_format="message",
)
return response
# 读取Excel文件
df = pd.read_excel('Q补充语料.xlsx', sheet_name='Sheet1', engine='openpyxl')
print("原始数据预览:")
print(df.head())
# 创建结果DataFrame
final_df = pd.DataFrame(columns=['Q', '生成语料'])
# 遍历df中的每一行
for index, row in df.iterrows():
# 构建消息列表
messages = [
{
"role": "system",
"content": "你擅长语文,擅长站在客户的角度思考"
},
{
"role": "user",
"content": f"""
请你根据如下问题,生成30个用户可能提问的不同的问题。
要求:
1. 保持原问题的核心语义不变
2. 模拟真实用户的各种表达方式
3. 考虑不同场景下的表述变化
4. 包含口语化和书面语表达
每个问题请用数字编号,每行一个问题。
问题:{row['新增Q']}
"""
}
]
try:
# 调用API
response = get_response(messages)
generated_text = response.output.choices[0].message.content
# 处理返回的问题列表
questions = [q.strip() for q in generated_text.split('\n') if q.strip()]
# 清理数字编号
cleaned_questions = []
for q in questions:
# 移除数字编号和点号
parts = q.split('.')
if len(parts) > 1:
cleaned_questions.append(parts[1].strip())
else:
cleaned_questions.append(q.strip())
# 创建临时DataFrame
temp_df = pd.DataFrame({
'Q': [row['新增Q']] * len(cleaned_questions),
'生成语料': cleaned_questions
})
# 将临时DataFrame添加到最终结果中
final_df = pd.concat([final_df, temp_df], ignore_index=True)
# 打印进度
print(f"已处理第 {index + 1} 行,共 {len(df)} 行")
except Exception as e:
print(f"处理第 {index + 1} 行时出错: {str(e)}")
continue
# 可选:添加延时以避免API限制
# time.sleep(1)
# 保存结果
output_filename = '生成语料结果2.xlsx'
final_df.to_excel(output_filename, index=False)
print(f"\n结果已保存到文件:{output_filename}")
# 显示结果预览
print("\n生成结果预览:")
print(final_df.head())看下效果:

效果还行,要更好的效果就需要精心调整下提示词了。
3 语料清洗
在客服场景中,用户的输入往往包含大量噪音数据,如无意义字符、情绪化表达、非业务相关内容等。高质量的训练数据需要经过严格的清洗过程,以确保模型能够学习到有效的语义信息。通过LLM的强大理解能力,我们可以更智能地完成语料清洗工作。
实现思路
1. 清洗规则定义
- 明确有效语料的标准
- 识别无效语料的特征
2. LLM辅助判断
- 设计清晰的评估提示词
- 利用LLM进行语义理解
- 输出标准化的判断结果
3. 批量处理流程
- 读取原始语料数据
- 调用LLM API进行评估
- 保存清洗结果
例子
# 示例提示词模板
prompt_template = """
请你为以下语料进行分类:
1. 正常语料:用户的正常问题,应该被解答
2. 无效语料:用户的问题无法被解答,或者与火车票无关,具体如下:
- 无意义的字符组合
- 重复性内容
- 情绪化或攻击性语言
- 非相关内容
- 语言不通顺
- 语言混杂
- 缺乏上下文
- 模糊的情绪表达
输入语料: {text}
请只输出0(无效)或1(有效),不要输出其他内容。
"""这里其实主要也依靠提示词,实践的时候有个注意点:
中断
由于要清洗的量可能很大,可能会因为奇怪的原因中断,所有写好处理,保存中间处理结果
import pandas as pd
import time
from dashscope import Generation
def get_response(messages):
"""调用Qwen API获取响应"""
try:
response = Generation.call(
api_key='sk-xxxxxxxxxxxx', # 请替换为您的API key
model="qwen-max",
messages=messages,
result_format="message",
)
return response
except Exception as e:
print(f"API调用出错: {e}")
return None
def create_prompt(Q):
"""创建提示词"""
return [
{
"role": "system",
"content": "你是一位专业的数据标注员"
},
{
"role": "user",
"content": f"""
请你为以下语料进行分类。
1 正常语料:用户的正常问题,应该被解答
2 无效语料:用户的问题无法被解答,或者与火车票无关,具体如下:
(1)无意义的字符组合:包括纯符号、纯字母、符号和字母的随机组合,或无意义的数字组合。
(2)重复性内容,连续重复字数大于3个字,且重复部分占据整句内容的50%以上。
(3)情绪化或攻击性语言
(4)语句中抱怨、吐槽、辱骂等字眼占大部分,且无法判断用户具体意图或需求。
(5)非相关内容:内容与火车票服务无关,涉及其他领域或无关话题。
(6)语言不通顺:语法错误严重,导致无法理解用户意图。
(7)语言混杂,使用多种语言或方言,导致理解困难。
(8)缺乏上下文:句子孤立存在,缺乏上下文信息,无法判断用户意图或需求。
(9)模糊的情绪:无法通过现有信息感知对话内容的情绪。
注意,这是一个客服场景。
用户语料: {Q}
请只输出0(无效)或1(有效),不要输出其他内容。
"""
}
]
def process_dataframe(df):
"""处理数据框,添加标记并进行分类"""
# 添加标记列
df['label'] = None
# 根据字符长度标记
df.loc[df['userinput'].str.len() < 3, 'label'] = 0
df.loc[df['userinput'].str.len() > 30, 'label'] = 0
# 获取未标记的行
unlabeled_rows = df[df['label'].isna()]
# 计数器和时间追踪
counter = 0
batch_counter = 0
start_time = time.time()
batch_start_time = start_time
# 处理每一行未标记的数据
for index, row in unlabeled_rows.iterrows():
try:
# 创建messages并调用API
messages = create_prompt(row['userinput'])
response = get_response(messages)
if response and response.output:
# 提取结果(0或1)
result = response.output.choices[0].message.content.strip()
if result in ['0', '1']:
df.loc[index, 'label'] = int(result)
else:
df.loc[index, 'label'] = None
counter += 1
batch_counter += 1
# 每50次保存一次结果
if counter % 50 == 0:
current_time = time.time()
batch_elapsed_time = current_time - batch_start_time
minutes = int(batch_elapsed_time // 60)
seconds = int(batch_elapsed_time % 60)
print(f"已处理 {counter} 条数据")
print(f"本批次50条用时:{minutes}分{seconds}秒")
print(f"平均每条数据用时:{batch_elapsed_time/batch_counter:.2f}秒")
df.to_csv('intermediate_results.csv', index=False)
# 重置批次计数器和计时器
batch_counter = 0
batch_start_time = current_time
# 添加短暂延迟以避免API限制
time.sleep(0.1)
except Exception as e:
print(f"处理行 {index} 时出错: {e}")
continue
return df
def main(start_row=0):
"""主函数"""
print("开始读取数据...")
df = pd.read_csv('待清洗的语料.csv')
total_rows = len(df)
print(f"数据集总行数: {total_rows}")
if start_row > 0:
if start_row >= total_rows:
print(f"错误: 起始行 {start_row} 超出了数据集总行数 {total_rows}")
return
print(f"跳过前 {start_row} 行数据")
df = df.iloc[start_row:].reset_index(drop=True)
print("开始处理数据...")
results_df = process_dataframe(df)
results_df.to_csv('processed_results.csv', index=False)
print("数据处理完成!")
if __name__ == "__main__":
main(start_row=59000) # 这里可以控制从那里开始4 相似语料去重
在训练数据中,经常会出现过于重复或相似的语料,如果量过大,不仅会影响模型训练效果,还可能导致资源浪费。通过LLM的语义理解能力结合向量相似度计算,我们可以更准确地识别和处理这些相似语料(可以先计算相似度,再让大模型或人工质检第二遍)
这部分写的相对粗糙一些,核心的思想是计算一个Q下所有的语料,然后全部执行嵌入,再计算相似度,利用阈值(如similarity_threshold=0.90)来控制相似的程度,得到相似组。
注意点:
1. 相似度阈值选择
- 不同场景可能需要不同的阈值
- 建议先小规模测试不同阈值的效果
2. 分组处理
- 记得Q值分组处理,避免不同场景的语料互相干扰
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
import time
import logging
from openai import OpenAI
import os
from tqdm import tqdm
# 设置日志
logging.basicConfig(
filename='similarity_check.log',
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def get_embedding(text, retry_count=3):
"""获取文本的嵌入向量,包含重试机制"""
for attempt in range(retry_count):
try:
client = OpenAI(
api_key= 'sk-aaxxxxxxxxxxxxxxxxxxxxxxx',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
response = client.embeddings.create(
model="text-embedding-v3",
input=text,
dimensions=1024,
encoding_format="float"
)
return response.data[0].embedding
except Exception as e:
if attempt == retry_count - 1:
logging.error(f"获取嵌入向量失败: {text[:50]}... 错误: {str(e)}")
return None
time.sleep(2 ** attempt) # 指数退避
def process_embeddings(df, batch_size=100):
"""批量处理嵌入向量"""
if 'embedding' not in df.columns:
df['embedding'] = None
# 获取需要处理的行
mask = df['embedding'].isna()
rows_to_process = df[mask]
if len(rows_to_process) > 0:
logging.info(f"需要处理 {len(rows_to_process)} 条数据的嵌入向量")
for i in tqdm(range(0, len(rows_to_process), batch_size)):
batch = rows_to_process.iloc[i:i+batch_size]
for idx, row in batch.iterrows():
embedding = get_embedding(row['text']) # 假设文本列名为'text'
if embedding is not None:
df.at[idx, 'embedding'] = embedding
# 定期保存
if i % (batch_size * 5) == 0:
df.to_csv('embeddings_checkpoint.csv', index=False)
return df
def mark_similar_entries(df, similarity_threshold=0.95, batch_size=1000):
"""优化的相似度检查函数"""
print(f"开始标记相似条目,数据共有{len(df)}条")
# 初始化标记列
df['is_duplicate'] = False
df['group_id'] = None
df['similarity_score'] = None
# 预处理嵌入向量
embeddings = []
valid_indices = []
# 收集有效的嵌入向量
for idx, row in df.iterrows():
try:
# 直接将embedding转换为numpy数组
emb = np.array(row['embedding'])
# 确保向量维度正确
if emb.size > 0: # 检查向量非空
embeddings.append(emb)
valid_indices.append(idx)
except Exception as e:
print(f"处理向量时出错 (索引 {idx}): {str(e)}")
continue
print(f"成功处理 {len(embeddings)} 个有效向量")
if not embeddings:
print("警告: 没有找到有效的嵌入向量!")
return df
embeddings = np.array(embeddings)
print(f"向量数组形状: {embeddings.shape}")
# 分批处理相似度计算
for i in tqdm(range(0, len(embeddings), batch_size)):
batch_end = min(i + batch_size, len(embeddings))
batch_embeddings = embeddings[i:batch_end]
batch_indices = valid_indices[i:batch_end]
# 对每个批次中的向量
for j in range(len(batch_indices)):
idx_i = batch_indices[j]
# 如果已经被标记为重复,跳过
if df.at[idx_i, 'is_duplicate']:
continue
# 确保有后续向量可比较
remaining_start = i + j + 1
if remaining_start >= len(embeddings):
continue
# 获取剩余向量
remaining_embeddings = embeddings[remaining_start:]
if len(remaining_embeddings) > 0:
# 计算相似度
current_vector = batch_embeddings[j].reshape(1, -1)
similarities = cosine_similarity(current_vector, remaining_embeddings)
similar_indices = np.where(similarities[0] > similarity_threshold)[0]
if len(similar_indices) > 0:
df.at[idx_i, 'group_id'] = idx_i
for sim_idx, sim_score in zip(similar_indices, similarities[0][similar_indices]):
actual_idx = valid_indices[remaining_start + sim_idx]
if not df.at[actual_idx, 'is_duplicate']:
df.at[actual_idx, 'is_duplicate'] = True
df.at[actual_idx, 'group_id'] = idx_i
df.at[actual_idx, 'similarity_score'] = sim_score
print(f"发现相似条目: {idx_i} 和 {actual_idx}, 相似度: {sim_score:.4f}")
# 定期保存检查点
if i % (batch_size * 2) == 0 and i > 0:
checkpoint_file = f'similarity_checkpoint_{i}.csv'
df.to_csv(checkpoint_file, index=False, encoding='gbk')
print(f"保存检查点: {checkpoint_file}")
# 统计结果
duplicate_count = df['is_duplicate'].sum()
group_count = len(df[df['group_id'].notna() & ~df['is_duplicate']])
print(f"\n处理完成:")
print(f"- 重复数据数量: {duplicate_count}")
print(f"- 重复数据占比: {duplicate_count/len(df)*100:.2f}%")
print(f"- 相似组数量: {group_count}")
return df
def main():
try:
# 读取数据
df = pd.read_csv('data.csv', encoding='gbk')
logging.info(f"成功读取数据,共{len(df)}行")
# 处理嵌入向量
df = process_embeddings(df)
# 标记相似条目
df = mark_similar_entries(df, similarity_threshold=0.92)
# 保存结果
output_file = f'similarity_results_{time.strftime("%Y%m%d_%H%M%S")}.csv'
df.to_csv(output_file, index=False)
logging.info(f"结果已保存至: {output_file}")
except Exception as e:
logging.error(f"处理过程中出错: {str(e)}")
raise
if __name__ == "__main__":
main()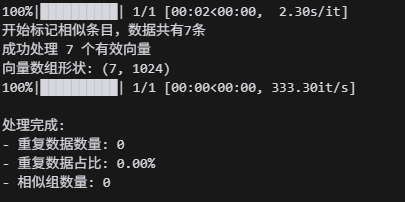
这里因为使用的示例数据,所以没有重复的值。
如果按照预期,最后的结果:
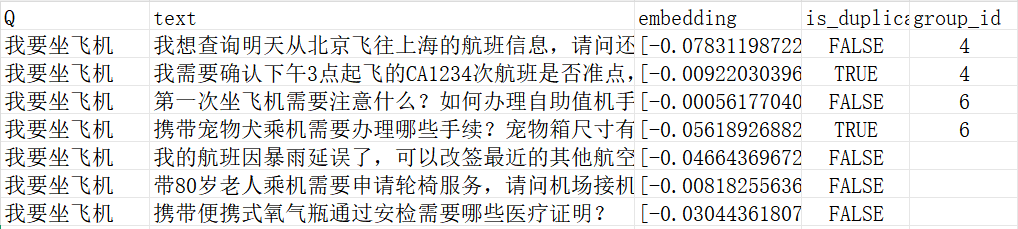
同group会标记到一组。最后可以在让大模型或人工审查一次。
如需大模型,代码示例如下(在上面相似组里取出,让大模型判断,实操的时候一般人工看一下就行):
def verify_with_llm(similar_group):
"""使用LLM验证相似组的合理性"""
prompt = f"""
请判断以下语料是否确实语义相似:
1. {similar_group[0]}
2. {similar_group[1]}
只输出"是"或"否"
"""
# 调用LLM API进行验证总结
本文介绍了如何利用大语言模型(LLM)来优化传统NLP系统的训练数据,主要包含以下几个方面:
(1) 语料生成
通过精心设计的提示词,利用LLM生成多样化的用户问法变体,丰富训练语料库。关键是要控制生成数量和质量的平衡,并通过提示词引导LLM从用户视角思考。
(2) 语料清洗
利用LLM的语义理解能力,建立智能化的语料筛选机制。通过明确的评估标准,可以有效识别和过滤无效语料,提升数据质量。
(3)相似语料去重
结合向量相似度计算和LLM验证,构建双重过滤机制,避免训练数据中出现过多重复或近似的表达。这既能保证数据的多样性,也能控制数据规模。
在使用LLM时,建议从小批量数据开始测试,逐步调整参数;重视提示词的设计,这直接影响输出质量
希望本文的实践经验能为正在探索LLM应用的团队提供一些参考和启发。欢迎在实践中不断优化和改进这些方法。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)