因为工作需要,做了一个简单的FunASR语音引擎训练材料标注工具
FunASR-Annotation-Tool 是一个专为FunASR语音引擎训练材料标注设计的工具。该工具的主要功能是帮助用户生成训练所需的文本和音频文件,并最终生成训练指令所需的train_wav.scp文件。
·
FunASR-Annotation-Tool
因为工作需要,做了一个简单的FunASR语音引擎训练材料标注工具。传送门
因为工作需要,做了一个简单的FunASR语音引擎训练材料标注工具。
以paramformer训练为例,逻辑就是:
- 搞一个train_text.txt文件
- 打开train_text.txt文件
- 录音,保存wav到本地,和train_text.txt中的材料一一对应
- 生成parafomer训练指令需要的train_wav.scp文件
备注:
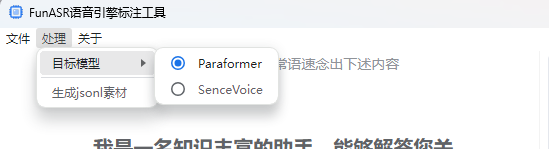
- 目前只实现了parafomer的,对我们目前的工作已经满足要求了,后续有其他要求再说(比如SenceVoice就还有事件、情绪)。这个也好做,就是切换菜单的时候,实现支持事件、情绪标注的功能即可
- 很多稳定性功能并没有太关注,若使用中出现问题,自行处理即可
基本操作流程:
- 利用任何一个LLM,生成train_text.txt。我这里有一个样例:
随机生成20条内容,要求如下:
1、这些内容可以是中文也可以是英文
2、每段内容的长度如果用正常语速阅读,不超过30秒。你生成的内容,每一条长度要分布均匀,有长有短
3、需要为每段内容标注一个ID,假设内容用“C”表示,那么你给出的结果为:ID 空格 C。每一条换一行。
4、ID要有顺序,比如从A0000开始,每一条增加一个数字
5、特别注意,格式就是 "ID空格C",不要添加任何其他内容,严格按照此格式
6、不要做任何总结、归纳,只需要给出结果
- 保存LLM生成的内容到
{working_dir}\train_text.txt中。working_dir你自己选 - 运行软件,“选择材料文件”或者用“文件->加载”出
{working_dir}\train_text.txt - 录音、保存
- “处理->生成jsonl素材”
最后,你就会在{working_dir}\train_text_dist\中得到你需要的内容
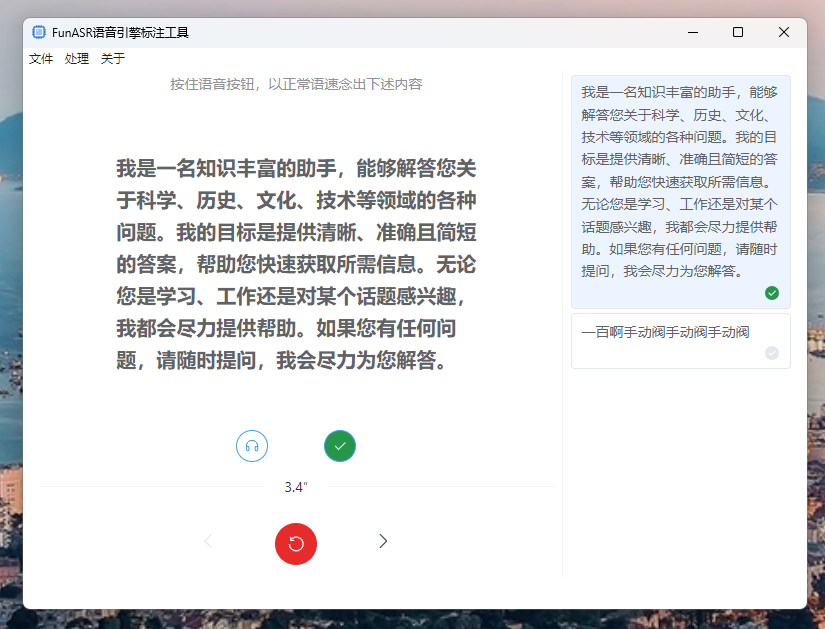
操作界面:
- 基本界面
- 菜单
- 产生的结果[1]

- 产生的结果[2]


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)