哈佛MEGa:解决大模型无法持续学习,适配医疗知识库持续更新
MEGa 方法通过“多 LoRA + 门控机制”将新记忆直接注入模型内部,具有与 RAG 类似的检索能力,却不需要外部数据库。(1) 独立 LoRA Adapter、(2) 冻结基座仅微调 LoRA、(3) 内部门控相似度检索、(4) 多 Adapter 加权融合。相对传统全量微调、RAG 或普通 LoRA,它的关键优势是能在内部完成记忆注入 + 检索,且尽量减少灾难性遗忘。隐性方法主要包括使用模
哈佛MEGa:解决大模型无法持续学习,适配医疗知识库持续更新
- 论文大纲
- 理解:
- 设计思路
- 问1:MEGa 方法的 **目的** 是什么?
- 问2:它通过什么方式来 **避免灾难性遗忘** 呢?
- 问3:**LoRA adapter** 是什么?它跟普通的微调(fine-tuning)有何区别?
- 问4:为什么要给 **每条新记忆** 都单独建一个 LoRA adapter,而不是统一用一个?
- 问5:那模型要输出答案时,如何知道该使用 **哪几个** LoRA adapter?
- 问6:门控权重为什么用 **softmax**?
- 问7:这套门控 + 多 LoRA adapter 架构,具体是如何 **避免灾难性遗忘** 的?
- 问8:那模型的 “常识或基础语言能力” 会不会因反复注入记忆而**下降**?
- 问9:如果需要 **同时用两条或多条** 不同的记忆,来回答一个需要综合信息的问题,该怎么做?
- 问10:MEGa 在什么样的场景下最**合适**?
- 问11:与 **外部检索(RAG)** 相比,MEGa 的好处或局限是什么?
- 问12:论文里有没有提到后续改进方向?
- 数据实验
- 拆解分析
论文:Memorization and Knowledge Injection in Gated LLMs
论文大纲
├── 1 引言【研究动机与问题】
│ ├── LLM在认知神经科学与AI应用中的重要性【研究背景】
│ ├── 现有模型在持续学习与知识注入方面的局限【问题描述】
│ └── 研究目标:建立能有效记忆与连续注入新知识的LLM框架【核心目标】
│
├── 2 相关研究【文献回顾】
│ ├── 2.1 持续学习与遗忘问题【研究热点】
│ │ ├── 神经网络中的灾难性遗忘现象【干扰与遗忘】
│ │ └── 常见解决方案:正则化 / 记忆复现 / 模型扩展【对应思路】
│ ├── 2.2 知识注入【相关技术】
│ │ ├── 基于微调(Fine-tuning)的知识编辑【传统做法】
│ │ └── 基于检索增强生成(RAG)等外部数据库方法【外部知识】
│ └── 2.3 门控网络(Gating Networks)与LoRA【重点方法】
│ ├── 混合专家(MoE)结构在LLM中的应用【门控思想】
│ └── 低秩适配(LoRA)技术的可扩展性【参数高效更新】
│
├── 3 方法:MEGa【核心框架】
│ ├── 3.1 问题定义【目标与数据】
│ │ ├── 连续到达的事件记忆注入【顺序到达的数据】
│ │ └── 记忆召回与问答任务【评估维度】
│ ├── 3.2 模型结构【关键模块】
│ │ ├── 门控记忆单元:为每条记忆分配独立LoRA【主要创新】
│ │ └── 软最大(Softmax)检索机制:根据查询选择激活【门控原理】
│ ├── 3.3 训练与推理过程【实施细节】
│ │ ├── 训练:为每个新事件初始化并单独微调LoRA【逐条注入】
│ │ └── 推理:门控权重激活相关LoRA以召回目标记忆【动态组合】
│ └── 3.4 评估指标【测量方法】
│ ├── 记忆召回相似度【Cosine相似度等】
│ ├── 问答准确率【GPT判分/对比原始答案】
│ └── 通用能力保持(MMLU准确率)【模型遗忘度测试】
│
├── 4 实验与结果【实证分析】
│ ├── 实验设置【数据与对比方法】
│ │ ├── Fictional Character & Wikipedia 2024 Events【数据来源】
│ │ └── Baselines:全量微调/正则化/外部检索RAG等【基线选择】
│ ├── 结果一:记忆召回表现【召回Cos值】
│ │ └── MEGa在多次记忆注入后保持高召回质量【门控抑制干扰】
│ ├── 结果二:问答准确率【知识整合】
│ │ └── MEGa及其内部RAG模式(iRAG)显著提升问答表现【效果显著】
│ ├── 结果三:通用能力保持【MMLU】
│ │ └── MEGa几乎不损害原模型的一般知识能力【缓解灾难性遗忘】
│ └── 结果四:组合性问答【多记忆融合】
│ └── 通过软最大加权融合多LoRA,实现多段知识关联【在复杂推理中证明有效】
│
└── 5 讨论与展望【意义与未来】
├── 与人类记忆系统的类比【神经科学启示】
│ ├── 快速注入的新知识类似海马记忆【快速通道】
│ └── 反复重播与渐进融合类似大脑新皮层巩固【慢速通道】
├── 现存局限:参数规模线性增长、LoRA模块管理【可扩展性问题】
├── 潜在改进:利用模型自回忆(rehearsal)进行蒸馏、知识图/索引融合【后续研究方向】
└── 结论:MEGa在LLM持续学习与记忆注入方面具有良好表现【总结与收敛】
核心方法:
├── 1 输入【数据与问题设定】
│ ├── 1.1 连续到达的数据流【数据源】
│ │ ├── Fictional Character & Wiki 2024 Events【训练文本】
│ │ └── 每条数据 = 段落级事件描述【单个记忆单元】
│ └── 1.2 任务目标【模型需要完成的功能】
│ ├── 记忆注入:逐条存储新事件【存储新知识】
│ ├── 记忆召回:根据查询准确重构已存信息【输出完整内容】
│ └── 问答推理:能回答基于记忆的细节问题【输出正确答案】
│
├── 2 处理过程【模型方法与技术】
│ ├── 2.1 问题形式化【Problem Formulation】
│ │ ├── 将每个段落视为一个新“记忆”【核心抽象】
│ │ └── 连续学习:一次只见到一个段落,无法回溯【顺序性约束】
│
│ ├── 2.2 基础模型与数据【Model + Datasets】
│ │ ├── 使用预训练 LLM(Llama-3.1-8B)【模型基座】
│ │ ├── 选择两套数据集进行研究【实验场景】
│ │ └── 对每条段落生成多种复述(paraphrases)【增强训练多样性】
│
│ ├── 2.3 记忆注入机制:MEGa【核心框架】
│ │ ├── 2.3.1 Fine-tuning 过程【记忆写入】
│ │ │ ├── (a) 提取文本嵌入作为“Context Key”【输入到门控机制】
│ │ │ ├── (b) 每条记忆分配独立 LoRA 模块【分离式存储】
│ │ │ └── (c) 对新段落单独微调 LoRA 并保存在模型中【更新参数】
│ │ │ └── 仅更新低秩矩阵 A, B【参数高效适配】
│ │ ├── 2.3.2 Inference 过程【记忆读取】
│ │ │ ├── (a) 对查询 q 进行嵌入【生成 Query Embedding】
│ │ │ ├── (b) 通过与所有 Context Key 比较计算相似度【softmax 选择门】
│ │ │ └── (c) 合并选定 LoRA 权重 + Base Weights 输出结果【激活相关记忆】
│ │ └── 2.3.3 Internal RAG(iRAG)【内置检索增强】
│ │ ├── 先利用上一步 Recall 召回相应文本【写入上下文】
│ │ └── 然后再次生成问答,提升准确率【二阶段推理】
│
│ ├── 2.4 评估方案【Evaluation Metrics】
│ │ ├── (a) 召回相似度:量化模型输出与原文本的匹配度【Cosine相似】
│ │ ├── (b) 问答正确率:用 GPT 评测生成答案【知识准确性】
│ │ └── (c) 通用知识保留:测 MMLU 等通用测试【检查遗忘程度】
│
│ └── 2.5 整体衔接【总流程】
│ ├── (1) 输入新段落文本 → Fine-tuning LoRA【记忆写入】
│ ├── (2) 接收用户查询 → softmax 门控选 LoRA【记忆读取】
│ ├── (3) 输出召回或问答【外显回答】
│ └── (4) 可选 iRAG:把召回内容二次放入上下文继续推理【多步推理】
│
└── 3 输出【模型最终行为】
├── 3.1 记忆召回:能完整地复述已学段落【完整重构】
├── 3.2 问答推理:对相关问题做简练回答【融合新旧知识】
├── 3.3 组合性回答:在多记忆中选定相关信息综合【软最大加权合并】
└── 3.4 保持原模型的通用能力:测试表明 MMLU 得分无显著降低【对抗遗忘】
理解:
人类具有持续学习和不断积累事件记忆(episodic memory)的能力,无论是之前知识还是新经验,都能较好地保留。
神经网络在这方面普遍难以具备“边学边整合”的特性。
要解决的具体问题:
-
如何让LLM在按顺序接收一条条全新且相互可能存在关联的知识(即“事件”或“段落”),并融入到已有语义体系中,且不遗忘已有的通用语言能力和旧知识(降低灾难性遗忘)。
-
如何在模型内部实现与人类类似的“记忆存储”机制,而非完全依赖外部数据库,实现对新事件的灵活回忆以及基于此的问答。
设计思路
“观察”:瞄准持续学习中“忘记旧知识”这一痛点,并通过多种对比法识别出参数冲突是根源。
关注变量:作者针对“新知识”不断加入时的模型表现、以及“原有能力的退化幅度”做了反复比较,从而意识到:“干扰” 才是引起灾难性遗忘的主要因素。
- “关键不寻常之处”——模型在不同记忆之间互相干扰,导致遗忘严重。
所以,解决方法的核心在于 — 对于不同事件或知识,要有独立的参数;通过门控把正确知识“调入”推理过程。
如何让LLM具备类似生物大脑的“可持续、可门控”记忆体系。
LoRA只是“现象”层面的实现方式,背后是对“使新知识与旧知识分而不混”的系统性思考。
提出如下假设:
-
把每条新记忆都放进独立的‘参数模块’
- 具体做法是:每来一个新事件,就建一个新的 LoRA adapter,并且不去改动以前的 LoRA adapter 或主干权重。
- 假设:这样可以“隔离”新旧记忆,避免它们在参数上相互覆盖。
-
“门控(gating)”来控制哪个 LoRA adapter 被激活
- 在推理阶段,对输入问题先做 embedding,与所有记忆的“context key”做相似度比较,激活最相关的那个(或几个)LoRA adapter。
- 假设:这种门控可以让模型在需要时“选中”正确的记忆模块,从而实现高效回忆、也能避免把所有东西都堆起来干扰生成。
-
内部的 RAG(iRAG)思路
- 进一步提出,如果问题比较复杂,需要先回忆完整文本,再回答,就可以通过“先回忆、后回答”的两步交互,让模型自己当“检索器”。
- 假设:把“检索”完全内置在模型里,可以在不依赖外部数据库的条件下,也能达到类似传统 RAG 的效果,甚至在一些场景更灵活。
本质上,是在参数空间进行了一种模块化的结构设计。
独特技术点就在于:利用门控+多 LoRA 来单独“存储”多段记忆,并根据查询内容动态检索到模型中,从而减少新老记忆之间的相互干扰。
核心思路:
通过在预训练LLM的每层MLP模块上插入可训练的LoRA低秩适配器,来存储对新事件的权重微调。
每个事件样本都有其专属的LoRA适配器,只在微调该条记忆时激活并训练;
推理时通过对 输入查询与各样本“记忆向量” 的语义相似度做softmax选择,从而门控激活某些LoRA模块合并到主干权重中,实现对相应事件的回忆与问答。
保留原模型大部分参数不动,极大降低对模型通用能力的破坏,同时通过门控避免不同事件之间互相干扰。
类比理解:
可以把整个过程想象成给一座大型图书馆(预训练好的 LLM)**增添“可拆卸的专用书架”**来存放新知识。
-
图书馆主楼:
- 原本就存放着大量百科类书籍(即 LLM 的基本通用知识)。
- 为了不破坏这些原有图书的陈列结构(即不大规模修改原模型参数),我们通常不去随意改变主楼的布局。
-
专属“附加书架”:
- 当出现一条新的知识事件,就像我们往图书馆里额外引入一整套小书架(LoRA 适配器)。
- 这些书架的容量并不大(低秩矩阵),但专门用来放置某一主题或事件的图书,且与主楼里的其他书籍几乎没什么干扰。
- 在“搭建”这套小书架的时候(相当于微调),只对这部分新建书架上的摆放进行调整,并不会大范围碰主楼的结构。
-
检索和“门控”:
- 当有人来图书馆查询某个问题时,先把他们的问题“扫描”一遍(将查询转成语义向量)。
- 与图书馆各个附加书架的“书架标签”比对(即“记忆向量”),看哪一个书架最匹配当前主题。
- 最后只打开(门控激活)对应的书架,把里面的内容拿出来,与主楼资料合并起来,为读者提供答案。
- 这样就保证:
- 如果问题和某个附加书架的主题契合,就能顺利拿到新知识;
- 如果没有特别匹配的书架,图书馆则只用主楼原有的资料来回答,不被新知识干扰。
这个过程里,“附加书架”(LoRA 模块)仅在对应新知识到来时进行排架(微调),并且只有碰到相关问题时才被激活访问,从而降低了对图书馆主楼的影响,也避免了不同新知识之间的相互冲突或覆盖。
问1:MEGa 方法的 目的 是什么?
答1:
它的目标是在对大语言模型(LLM)进行“持续地”(一次接一次地)注入新知识时,尽量 避免灾难性遗忘(catastrophic forgetting),并确保模型既能记住新内容,也能回答跟这些新内容相关的问题。
解读: “持续学习”意味着模型不断接收新的样本(所谓的事件或知识),并将其纳入自己的参数里;
“灾难性遗忘”是指模型在学习新东西时把原来学到的东西严重遗忘,这在很多传统模型里都会发生。
MEGa 的核心想法就是要 有针对性地 将新的记忆注入模型,且尽量不破坏原有知识。
问2:它通过什么方式来 避免灾难性遗忘 呢?
答2:
MEGa 通过给每个新“记忆”增添一个独立的 LoRA adapter(一种低秩参数矩阵),并用 门控(gating)机制 来控制“何时激活”这些 adapter,从而把新内容与旧权重分开,减少它们之间的互相干扰。
解读: 这里的关键信息是 “在已有模型权重之上,每个新记忆会有单独的(LoRA)模块,平时这些模块不彼此干扰”。
要理解它,先要对 LoRA、门控等概念有初步认识。
问3:LoRA adapter 是什么?它跟普通的微调(fine-tuning)有何区别?
答3:
- LoRA(Low-Rank Adaptation)是一种参数高效微调技术:它在不改动原始大模型主干权重 ( W PT ) (W_{\text{PT}}) (WPT) 的前提下,添加了两个低秩矩阵 (A) 和 (B),使得新的权重 ( W FT = W PT + A × B ) (W_{\text{FT}} = W_{\text{PT}} + A \times B) (WFT=WPT+A×B) 。
- 因为 (A) 和 (B) 的维度较小、秩较低,微调所需训练的参数量很少。
- 和“直接全参数微调”相比,LoRA 只学一个相对小的增量更新 ( A × B ) (A \times B) (A×B),不会大幅改动预训练权重,因此能更好地避免新知识对旧知识造成激烈冲击。
解读: 可以把 LoRA 想象成“往大模型里插入一个小插件”,这个插件学到的是 “如何在不破坏原本结构的情况下,去表达新的东西”。
问4:为什么要给 每条新记忆 都单独建一个 LoRA adapter,而不是统一用一个?
答4:
因为不同新记忆之间也会互相干扰(比如它们的内容相似或部分重叠)。
如果把所有新记忆都更新到同一个 LoRA 模块,就可能把之前的记忆改坏了。
一条记忆对应一个独立 LoRA adapter,就能把各自的知识“隔离”在各自的小模块里,互相干扰最小。
类比: 假设你有多个抽屉,每学到一个新事件就多放一个抽屉,每个抽屉里的东西互不混杂,拿东西时先看和哪件事匹配,再决定打开哪个抽屉取出内容。
问5:那模型要输出答案时,如何知道该使用 哪几个 LoRA adapter?
答5:
MEGa 在推理阶段(inference)有一个 门控(gating)机制:
- 首先把用户输入(query)拿去做一个 语义向量(embedding),
- 再和所有记忆对应的 “上下文键”(context key) 做相似度比较,
- 用 softmax 计算出每个记忆的权重(gate)。
- 最后把这些记忆对应的 LoRA 模块的权重 按权重加和,跟原始模型合并,然后再去生成答案。
简要来说: 通过计算“问题向量”和“各记忆向量”的 余弦相似度 或内积,得到“最相关”的那个记忆,对应的 LoRA adapter 就被激活。
问6:门控权重为什么用 softmax?
答6:
- softmax 可以把所有记忆的相似度值转化为一组 “和为 1 的非负值” ,自然就当作一组“注意力”或“权重”去激活不同记忆;
- 如果相似度差异很大,softmax 会让最相关的记忆权重近似 1、其他近似 0;
- 如果有多条记忆都相关,它也可以有一个稀疏但非零的组合,这就允许 组合多条记忆 来回答问题。
解读: softmax 能把“哪几个 LoRA adapter 相关”这件事自动转换为概率分布,从而使得模型能在多条记忆中平滑地选择或融合。
问7:这套门控 + 多 LoRA adapter 架构,具体是如何 避免灾难性遗忘 的?
答7:
LoRA是“低秩更新”,不会大幅改变主干模型权重。
等同于给每条新知识添加一个小模块,和原权重“并行叠加”,减少对原模型的覆盖。
为什么还要门控(Gating)选择对应LoRA,而不是所有LoRA都一起用?
如果所有LoRA都同时启用,不同新知识的微调部分会相互“冲突”并导致上下文混乱。
而门控可以在推理时只激活最相关的记忆,避免相互干扰;也减少算力浪费。
问8:那模型的 “常识或基础语言能力” 会不会因反复注入记忆而下降?
答8:
它基本不会显著下降:
- 因为 MEGa 几乎没有修改预训练好的主干模型,它的语言能力和常识知识依旧保留;
- 每次新记忆只加少量 LoRA 参数,别的记忆不受影响,所以也不会互相覆盖。
在论文的实验中,用 MMLU 测试大模型的常识答题能力,MEGa 在训练很多条新记忆后,成绩依然和原始模型几乎一致,说明它没遗忘掉通用知识。
问9:如果需要 同时用两条或多条 不同的记忆,来回答一个需要综合信息的问题,该怎么做?
答9:
在论文里,方法有两种:
- 直接依赖 softmax gating:如果多条记忆 都和 query 相似,那么它们在 softmax 中都得到较大权重,模型就能“叠加”这些 LoRA adapter;
- 作者还提到了 iRAG(internal RAG) 的思路:让模型先回忆其中一条或多条记忆,把回忆到的文本放进上下文,再来回答更复杂的问题。
这样就相当于使用了“多轮推理”,自然就能综合多条记忆的信息。
问10:MEGa 在什么样的场景下最合适?
答10:
- 当你想给一个已经训练好的大模型 不断增量 新知识或新技能;
- 而且你希望它 牢牢记住 这些新的信息,并可以随时“召回”做问答;
- 最关键的是,你想保持原模型的常识、语言能力,不要因微调而大规模破坏(灾难性遗忘)。
在这些场景下,MEGa 的模块化、门控式记忆注入非常适用。
问11:与 外部检索(RAG) 相比,MEGa 的好处或局限是什么?
答11:
- 好处:
- 更加内隐:所有记忆都存在模型内部,不依赖外部数据库;
- 可以实现和模型内部语义结构更紧密的结合;
- 在一些对 隐私、安全 要求高的场景中,内置记忆可能更方便管理,而不用把数据放到检索库。
- 局限:
- 对于新记忆的数量大规模增长时,LoRA adapter 参数数量也会线性上涨;
- 这意味着 存储成本 和 推理时合并成本 都增加;
- 如果要非常多的知识,外部检索库可能更高效。
问12:论文里有没有提到后续改进方向?
答12:
作者提出:
- 可以把已经学到的 LoRA adapter 里的一些知识,慢慢蒸馏(distill)回到主干模型,从而减少模块数;
- 研究怎么把 多模态 记忆(图像、音频等)也纳入这种门控结构;
- 设计“分层”或“图结构”的记忆管理,以便存储许多相似事件时不会冗余,也能执行复杂推理。
数据实验
重点在于:作者如何收集、处理、探索数据,并建立模型去解释与预测他们所关心的现象。
即 “如何在不遗忘旧知识的情况下往 LLM 中不断注入新知识”。
第一步:收集所需数据
目标:获取与论文研究问题相关的所有必要数据。
-
数据来源
- Fictional Character 数据集
- 作者利用 GPT-4.5 生成了 50 条与同一虚构角色相关的事件(一个角色的数据),且重复多次(共 20 份不同角色的数据分区),每份包含 50 条描述性的短故事。
- 平均每条故事长度约 42 个词。
- 每条故事还另外生成了 9 条 “改写版”以及 3 条基于该故事的提问。
- Wikipedia 2024 Events 数据集
- 作者从 Wikipedia 抓取了 2024 年相关事件的页面,筛选后留下了 1,000 篇符合字数要求的事件简介,每篇约 41-42 词。
- 同样进行 20 份数据划分(每份 50 条或更多),以及辅助生成改写数据和 QA 问答对。
- Fictional Character 数据集
-
数据全面性
- 上述两个数据集各有不同特性:
- Fictional Character 故事之间的相似度更高(都围绕一个人的人生事件)。
- Wikipedia 事件彼此更独立(真实新闻事件,干扰更小)。
- 这样就能考察模型在高关联度与低关联度场景中的表现。
- 上述两个数据集各有不同特性:
-
数据准确性
- Fictional Character 虽然是 AI 生成,但作者使用了 GPT-4.5 并进行了质量控制(长度、人物、事件多样性)。
- Wikipedia 数据则是“已存在条目 + 时间筛选”,相对可靠,而且其知识对模型而言是新知识(2024 年事件)。
小结:作者在第一步就有意设计/收集了两种不同特点的数据集,以覆盖多种场景,为后续分析打下基础。
第二步:处理与挖掘数据,寻找规律
目标:通过数据处理和分析,发现数据中的潜在模式和规律。
-
数据清洗、整理
- 每个故事都做了多次改写和QA 对的生成,保证模型训练时能测试“记忆重建”与“问答”。
- 数据划分:作者把每份 50 条故事依次输入给模型做顺序学习,以模拟持续学习(即每次只学习一个样本或一小批样本)。
-
数据分析:核心度量指标
- Recall Cosine Similarity:用向量化(OpenAI embeddings 或 Llama 内部 embedding)来度量模型“回忆”出的文本与原文的相似度,从而判断“记忆保留度”。
- QA Accuracy:对每条故事生成的问答对,检查模型答案对不对(由一个 GPT-based 评分器打分);也进一步量化“知识注入”效果。
- Log Probability:有时会用生成文本的 log prob 来看模型“信心”。
- MMLU 测试:看模型是否保留通用知识,不因为微调而“遗忘”了原有语言能力。
-
识别趋势/模式
- 作者将不同方法(MEGa、RAG、Full Fine-tuning、LoRA 等)在顺序学习时的 Recall Cos / QA Accuracy / MMLU 表现做曲线对比,发现传统方法往往遗忘严重,而 MEGa 在多样场景下记忆力和问答能力保持更好。
小结:通过多指标、多条件(不同微调策略)的交叉分析,作者挖掘出“参数冲突”导致记忆遗忘的规律,并初步看到“门控 + 独立 LoRA”确实可能缓解遗忘。
第三步:探索数据维度间的相关性
目标:分析不同维度数据之间的关系,推断或印证作者的假设。
-
检查“是否激活正确的 LoRA adapter” 与 “能否正确回答问题”之间的关系
- 作者在论文中提到,正确选中 LoRA adapter 对“回忆”很关键:如果模型门控选到错的记忆模块,回忆就会失败,QA 也会出错。
- 通过统计“门控选择正确率”和“QA 准确率”的关系,作者发现当门控能正确选到对应记忆模块时,Recall Cos 和 QA Accuracy 均能显著提升。
-
干扰度高 vs 干扰度低 场景
- 在 Fictional Character 数据中,相似故事多,更容易“搞混”,导致门控错误选取;而 Wiki 事件多半独立,干扰度低,选错率也更低,因此在 Wiki 事件上能获得更高的 QA 分数。
- 这说明数据之间的相似度是影响门控选取正确率(即记忆模块区分度)的一个关键维度。
-
持续学习长度 vs 遗忘程度
- 作者绘制随时间/样本数量增加,“早期记忆保留度”的变化曲线,看到 Full Fine-tuning 会迅速遗忘,而 MEGa 则有相对平缓的遗忘曲线。
- 进一步印证了在多次顺序学习里,“独立适配器 + 门控”确有助于对抗遗忘。
总结:在第三步,通过对“门控激活正确性”“记忆相似度”等不同数据维度的统计,作者间接验证了:记忆隔离和门控是应对干扰与遗忘的核心手段。
第四步:建立数学模型
目标:基于数据分析结果,构建与观察数据相符的数学模型,用于解释和预测现象。
-
数学模型:门控 + LoRA
- 论文使用了一个核心公式:
[
Θ infer = W PT + ∑ i g i ( A i B i ) \Theta_{\text{infer}} = W_{\text{PT}} + \sum_i g_i \big(A_i B_i\big) Θinfer=WPT+∑igi(AiBi)
]
其中 ( g i = s o f t m a x ( β f ( q ) ⋅ K i ) ) (g_i = \mathrm{softmax}(\beta \, f(q) \cdot K_i)) (gi=softmax(βf(q)⋅Ki))。 - 含义:对于每个新知识,都引入一个 LoRA 低秩矩阵 (A_i B_i)。推理时,通过 softmax 计算一个门控权重 (g_i),再加权合并到主干权重里。
- 这个方程本质上刻画了如何在参数空间上实现“多记忆并存+门控激活”。
- 论文使用了一个核心公式:
-
模型验证
- 论文中多次实验都遵循这个门控公式,观察当门控正确时是否能回忆到相应文本。
- 对“复合知识”问题还稍微修改了 (\beta)(即调节门控对多个 LoRA 的分配),发现多门控激活也能回答需要综合多个故事的信息。
-
应用价值
- 这个数学模型解释了:为什么把记忆拆成多个 LoRA adapter,可以极大地缓解参数冲突;
- 也预测了:如果引入更好 embedding 或更大模型,就能减少门控“选错”的现象,进一步提升多记忆场景下的保留和问答能力。
结论:作者用门控方程来统一描述记忆注入与检索过程,再对其进行多场景实测,确认其可行性。这种“拿数据来建立可解释的模型并验证”的方式,正是论文理论贡献的核心。
拆解分析
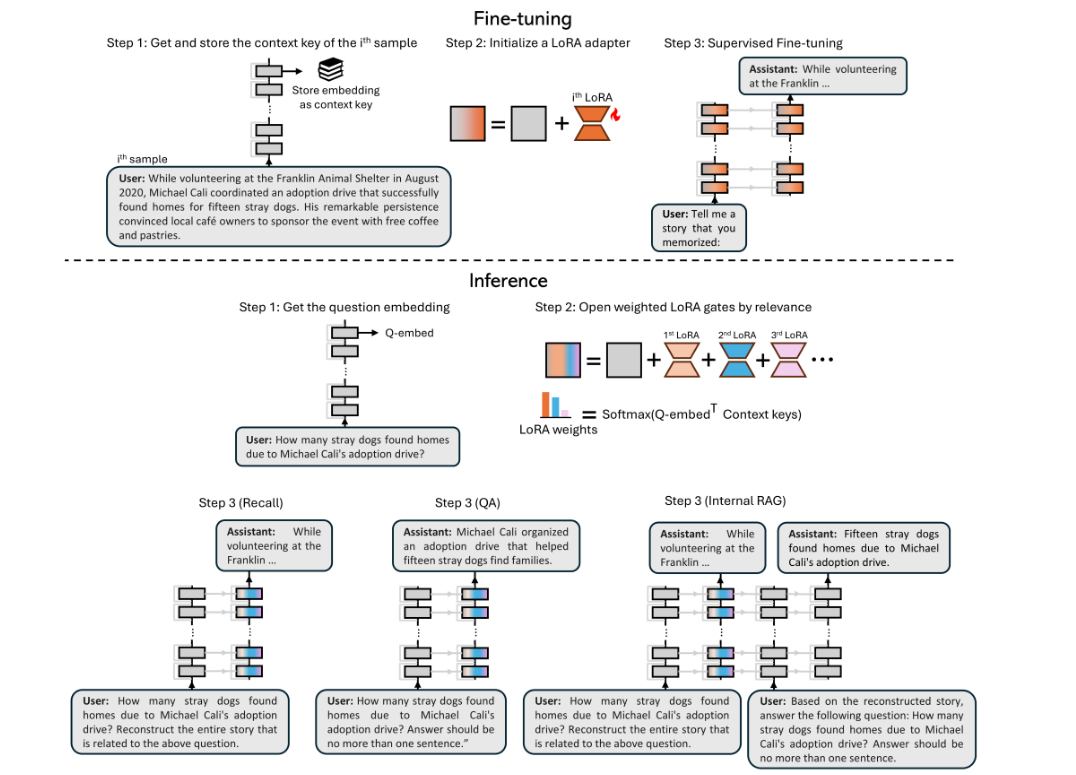
1. 上半部分:微调流程(Fine-tuning)
-
Step 1: 获取并存储该样本的“上下文 key”(context key)
- 给定第 (i) 个记忆样本(如图中例子是一段描述 Michael Cali 帮助收养流浪狗的故事)。
- 先将这段文本送入预训练模型的某层,生成一个固定维度的向量表示(图中灰色方块)。
- 这个向量就被存储为**“context key”**,用来区分并检索这条记忆。
-
Step 2: 初始化一个 LoRA adapter
- 给每条新记忆(即每段文本)都分配一个独立的 LoRA 模块(图中彩色方块),用来承载“微调出来的额外权重”。
- 这样做的目的是让新知识只影响这个 LoRA,而不会大规模改动模型主干权重。
-
Step 3: 监督微调(Supervised Fine-tuning)
- 用少量的“问-答”或“指令”对该段文本做微调(图示中是“Tell me a story that you memorized…”,回答中会复述或学习这段内容)。
- 训练完成后,这个 LoRA 就算“学会”了这条记忆;主干模型依旧保持原状,因而不会遗忘之前掌握的通用知识。
小结:在“微调”阶段,每个新事件(段落)都会拥有自己独立的一套 LoRA 参数,且为后续推理打上了“context key”的标识。
2. 下半部分:推理流程(Inference)
-
Step 1: 获取问题的 embedding
- 用户提出问题(如:“Michael Cali 帮助几只流浪狗找到了新家?”)。
- 系统会先对这个问题做相同方式的嵌入(Q-embed),得到一个向量表示。
-
Step 2: 根据相关度激活 LoRA
- 已存储的多个“context key”(对应不同记忆)会与问题向量进行相似度比较。
- softmax(Q-embed^T Context keys) 计算出每个记忆模块的激活权重,进而加权叠加相应的 LoRA。
- 这一步可以看作“门控”过程:最相关的 LoRA 模块会得到最高权重,被激活来回答问题。
-
Step 3: 具体的回答方式
- 论文里演示了三种用法:
- Recall:根据用户需求,直接回忆并重现整段存储文本。
- QA:简要回答用户的问题。例如“帮助了 15 只狗找新家”。
- Internal RAG:先让模型以“Recall”方式把整段文本回忆出来,再将其放入上下文中,通过“链式”模式回答问题(类似外部RAG,但这里是内部生成的“短文”)。
- 论文里演示了三种用法:
小结:在“推理”阶段,模型会先对问题做向量化,然后“门控”检索最匹配的记忆 LoRA 模块组合到主干权重中,从而复现或利用当初微调时学到的信息来回答。
3. 综合理解
- 微调时:一条事件记忆 = 一套 LoRA + 一个 context key,保证新知识孤立存储,不干扰原模型。
- 推理时:问题向量与每个 context key 做相似度检索,然后将最匹配的 LoRA 载入模型,对问题做回答。
- 好处是:
- 缓解灾难性遗忘,因为原始权重没大改;
- 参数效率较高,只额外存储 LoRA 模块;
- 检索机制灵活,可复用到Recall、QA、或二次回答(Internal RAG)等多种场景。
因此,这张图直观呈现了 MEGa 在“训练”与“使用”两个阶段的运行逻辑:
- 用 LoRA 模块为每条知识单独“录入记忆”;
- 用“向量相似度 + 门控”检索最相关的记忆以生成答案,做到像人一样“调取”特定记忆来回答问题。
和同类算法比的主要区别
与同类算法或思路相比,该方法的主要区别在于:
- 不同于传统 RAG(Retrieval-Augmented Generation)需要外部检索库,MEGa 直接将“记忆”写进模型内部权重(LoRA Adapter)里。
- 区别于全量微调(Full Fine-tuning)的地方在于:MEGa 并不会修改基座模型(Pretrained Weights)的大部分参数,而是使用分离、门控的低秩参数(LoRA Adapters)来“存储”各个新记忆,并在推理时通过一个 门控机制(Gating Mechanism) 来检索激活目标记忆。
- 区别于普通 LoRA 或单个 LoRA 微调的地方在于:MEGa 并非只训练一个 LoRA Adapter,而是针对每个新记忆段落(事件)都单独初始化并训练一个 LoRA Adapter;在推理时,利用“查询语句的内部嵌入”与每个 LoRA Adapter 的“上下文向量”做相似度计算,使用 softmax 得到各 Adapter 的激活分数,再将它们加权融合到模型权重中,从而只激活最相关的记忆。
为更好地展示该方法的公式与技术细节,可以把 MEGa 的核心步骤拆解如下(伪代码式):
-
记忆编码(Memory Key):给定一个新记忆样本 (D_i)(例如一段描述人物经历的文本),计算其“上下文向量”或“记忆键” K i = f ( D i ) K_i = f(D_i) Ki=f(Di)
- 其中 f ( ⋅ ) f(\cdot) f(⋅) 是从 LLM 内某层提取的句向量/段落向量(论文中是取最后 MLP 的输入平均或其他特定层激活)。
-
LoRA Adapter 初始化:为该新记忆创建一套新的可训练参数 { A i l , B i l } \{A_i^l, B_i^l\} {Ail,Bil},其大小与模型层数、秩 (r) 有关。LoRA 公式为:
[
W P T l + A i l B i l W_{PT}^l + A_i^l B_i^l WPTl+AilBil
]其中 ( W P T l ) (W_{PT}^l) (WPTl) 为预训练权重(冻结不变), ( A i l , B i l ) (A_i^l, B_i^l) (Ail,Bil) 是低秩矩阵(秩为 r)。
-
单记忆微调(Fine-tuning):用新样本 (D_i) 做监督微调,最小化
[
L i = − log p Θ i ( D i ∣ prompt ) L_i = - \log p_{\Theta_i}(D_i \mid \text{prompt}) Li=−logpΘi(Di∣prompt)
]
只更新 ({A_i^l, B_i^l}),其它权重冻结。要把新知识放到“LoRA 模块”里,而不是直接修改原模型大权重
-
推理时合并(Gating):对于一个查询 (q),先计算其嵌入 f(q),并与所有记忆键 { K 1 , K 2 , … } \{K_1, K_2, \dots\} {K1,K2,…} 做相似度(内积)后,经 softmax 归一化:
[
g = softmax ( β f ( q ) T K ) g = \text{softmax}(\beta \, f(q)^T K) g=softmax(βf(q)TK)
]
得到一组门控分数 g = [ g 1 , g 2 , … , g n ] g = [g_1, g_2, \ldots, g_n] g=[g1,g2,…,gn]。最终推理时的模型权重为:
[
W i n f e r l = W P T l + ∑ i g i ( A i l B i l ) W_{infer}^l = W_{PT}^l + \sum_{i} g_i \,(A_i^l B_i^l) Winferl=WPTl+∑igi(AilBil)
]
这样就能加权融合相关的记忆适配器(LoRA Adapters)。
综上所述,这套方法的独特技术点就在于:利用门控+多 LoRA 来单独“存储”多段记忆,并根据查询内容动态检索到模型中,从而减少新老记忆之间的相互干扰。
解法拆解
细分为以下 4 个子解法(或步骤),每个子解法都对应某个特征需求:
子解法1:为每条记忆独立分配一个 LoRA Adapter
- 之所以用此子解法:因为每次注入一条新记忆,都需要独立的低秩参数空间,才可最大限度地减少不同记忆之间的干扰。
这也是对“持续学习”中“互不干扰存储”的特征需求。
子解法2:冻结原模型的大权重,只训练 LoRA Adapter
- 之所以用此子解法:因为预训练模型本身已经包含基础语言与知识能力,若全部权重都改动,就会产生明显的灾难性遗忘。
利用 LoRA 只在小范围内更新权重,可保留底层模型的通用能力。
子解法3:以查询与“记忆键”的相似度做门控 (Gating)
- 之所以用此子解法:因为需要一种在推理时自动选择最相关记忆的机制(类似搜索),而不依赖外部检索库。
通过内积 + softmax,就可以让最相关的 LoRA Adapter 被激活,其他保持关闭。
子解法4:合并(融合)多个 LoRA Adapter 的加权结果
- 之所以用此子解法:因为可能有时候不仅只激活一个记忆适配器,也能对查询做更精细的回答,尤其涉及组合记忆(如回答需要多条记忆)。
这就用到了 softmax 输出分数后再做线性叠加的思路,允许多个记忆同时被唤起。
总结一下,这四个子解法共同构成了整套 MEGa 解决方案的“方法组合”。
它们的逻辑链条是先有独立 LoRA(子解法1),再利用冻结预训练权重做微调(子解法2),最后在推理阶段基于相似度门控(子解法3),融合多记忆(子解法4)。
这些子解法是什么样的逻辑链?
若以决策树或有向图的形式概括 MEGa 的流程:
- 接收新记忆:判断是否已有对应 LoRA Adapter
- 如果“没有”,则新增一个 LoRA Adapter(子解法1);如果“有”,可视情况合并或继续微调(可扩展)。
- 训练阶段:是否修改预训练权重?
- 如果“是”,则容易遗忘,需要其它正则化;如果“否”,则只改 LoRA(子解法2)。MEGa 选择“否”,只更新 LoRA。
- 推理阶段:拿查询做相似度检索
- 比较 f(q) 与各记忆键 K_i 做内积,得到门控向量 g(子解法3)。
- 输出层融合:选择一个或者多个 LoRA Adapter 并加权合并到原有权重上(子解法4)。
整体更像顺序串行的逻辑链条,每一步都必须完成,最后得到针对查询的回答。可视作一个“流水线”或“链式”的推理过程。
分析是否有隐性方法
对照全文和常规的“多任务微调”或“RAG 检索”,我们可以发现 MEGa 在实现中有一些隐性方法或“关键小技巧”:
隐性方法 1:利用模型内部激活来做“记忆键”
在传统思路中,构建检索式问答常用额外的嵌入模型,例如句向量模型(SBERT,text-embedding-ada 等)。
然而在 MEGa 方案里,他们直接从 LLM 内部特定层提取激活(token-level embedding 或者最后 MLP 输入),做平均后当成记忆的向量表示。
这其实是一种不常见但高效的隐性方法:
- 好处:无须再引入外部嵌入模型,和推理过程无缝衔接。
- 坏处:若 LLM 内部对该段文本的表征质量不高,则检索会有误差。
之所以说它是“隐性方法”,是因为这一步在文章中并没有特别冠以“新算法”之名,而是作为一种实现细节存在,但却对整体性能影响很大。
隐性方法 2:将“重新生成的文本”当作内置 RAG(iRAG)
论文中提到一个称为 iRAG(Internal RAG)的策略:问答时先用 MEGa 的门控回忆出整段文本(“重构记忆”),再将这个回忆得到的长文本放回上下文,进行二次提问以回答最终问题。
这其实模拟了“先检索 / 后推理”的链式思路,却把检索与文本都保存在模型内部:
- 虽然文章明确提出 iRAG,但这种做法并不在传统教科书的知识注入流程里,是对“多次推理迭代”或“Chain-of-Thought”思路的一种隐性又关键的创新。
分析是否有隐性特征(特征不在问题、条件中,而是解法的中间步骤)以及方法的潜在局限性
潜在的隐性特征
从论文讨论来看,还存在以下可能的“隐性特征”或中间条件,并非直接在问题或条件中给出,但在方法实现中起到了重要作用:
- MEGa 在引入新记忆时,默认每次只针对“单段文本”单独训练一个 Adapter;若有多段高度相关的文本,需分段存储或后续再合并。这隐含了一个“离散化/切分文本”的特征。
- 对 LoRA Adapter 的“初始化”方式也会影响记忆效果和收敛速度,但论文里只做了简要说明(比如秩、缩放因子等),没有将之作为一个核心算法名称提出。实际上如何初始化会左右最终性能,是个“隐性特征”。
- 在训练 LoRA Adapter 的 Prompt当中,“命令式”或“叙述式”风格不一样会显著影响记忆注入的效果。论文中做了一些对比,但也算是额外的中间条件。
方法可能存在哪些潜在的局限性
-
存储成本线性增长:MEGa 为每条记忆都要新建 LoRA Adapter,导致适配器数量随记忆数线性增长;对于极大量的记忆,存储与推理时的融合开销可能较大。
-
门控选择出错:若查询与已保存的“记忆键”相似度计算不够精准,就会选错 Adapter,导致回答错误或出现乱答。论文也指出对比使用更高质量的嵌入可以减少这类错误。
-
无主动合并、压缩机制:MEGa 在基础版本里缺乏类似“知识蒸馏”或“记忆合并”模块,如果很多记忆相似度高、又分散在多个 Adapter,容易造成冗余。
-
对模型大小与 LoRA 秩的依赖:在小模型或秩太低时,可能注入复杂事件或叙事类记忆时难以保真;秩太高则使得参数量膨胀。
-
需多步推理才能回答复杂复合问题:虽然已有 iRAG 策略,但对多记忆跨段推理的复杂性远超单记忆注入,可能还要进一步改进多轮融合机制。
总结
- MEGa 方法通过“多 LoRA + 门控机制”将新记忆直接注入模型内部,具有与 RAG 类似的检索能力,却不需要外部数据库。
- 整个“解法”可拆解为 4 个子解法:(1) 独立 LoRA Adapter、(2) 冻结基座仅微调 LoRA、(3) 内部门控相似度检索、(4) 多 Adapter 加权融合。
- 相对传统全量微调、RAG 或普通 LoRA,它的关键优势是能在内部完成记忆注入 + 检索,且尽量减少灾难性遗忘。
- 隐性方法主要包括使用模型内部激活做记忆键与“先回忆再问答”的 iRAG 过程。
- 局限性则集中在记忆数量多时的存储成本、门控检索准确率、缺乏自动合并与压缩等方面。
这即是对论文中 MEGa 方法的详尽拆解与分析。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)