浅析大语言模型从预训练到微调的技术原理(硬核)
本文详细介绍了大模型的工作底层原理,非常硬核干货,谨慎打开。
·
大纲
- LLaMA、ChatGLM、Falcon等大语言模型的比较
- tokenizer、位置编码、Layer Normalization、激活函数等
- 大语言模型的分布式训练技术
- 数据并行、张量模型并行、流水线并行、3D并行
- 零冗余优化器ZeRO、CPU卸载技术ZeRo-offload
- 混合精度训练、激活重计算技术
- Flash Attention、Paged Attention
- 大语言模型的参数高效微调技术
- prompt tuning、prefix tuning、adapter、LLaMA-adapter、 LoRA
1.大语言模型的细节
1.0 transformer与LLM
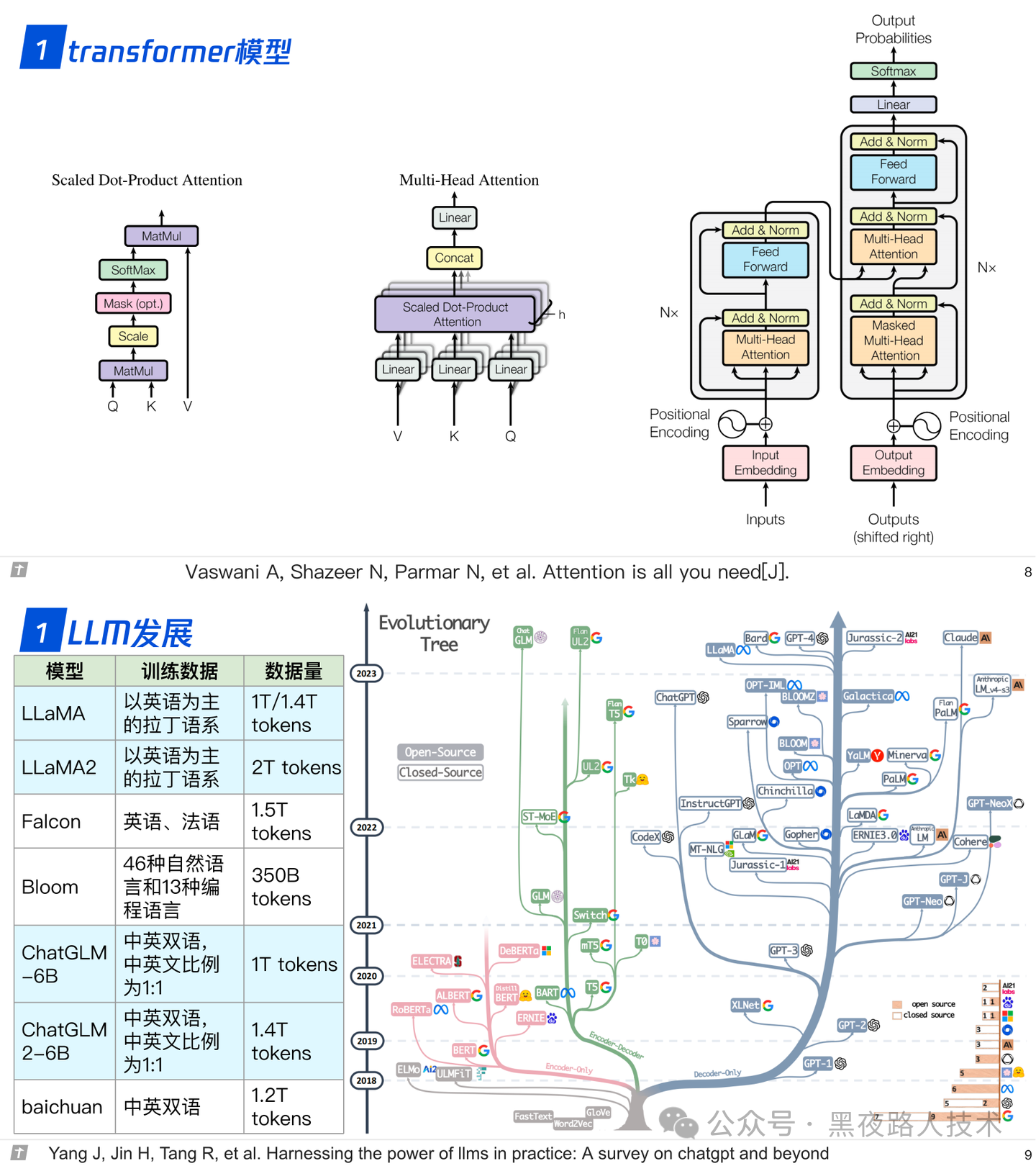
1.1 模型结构

1.2 训练目标

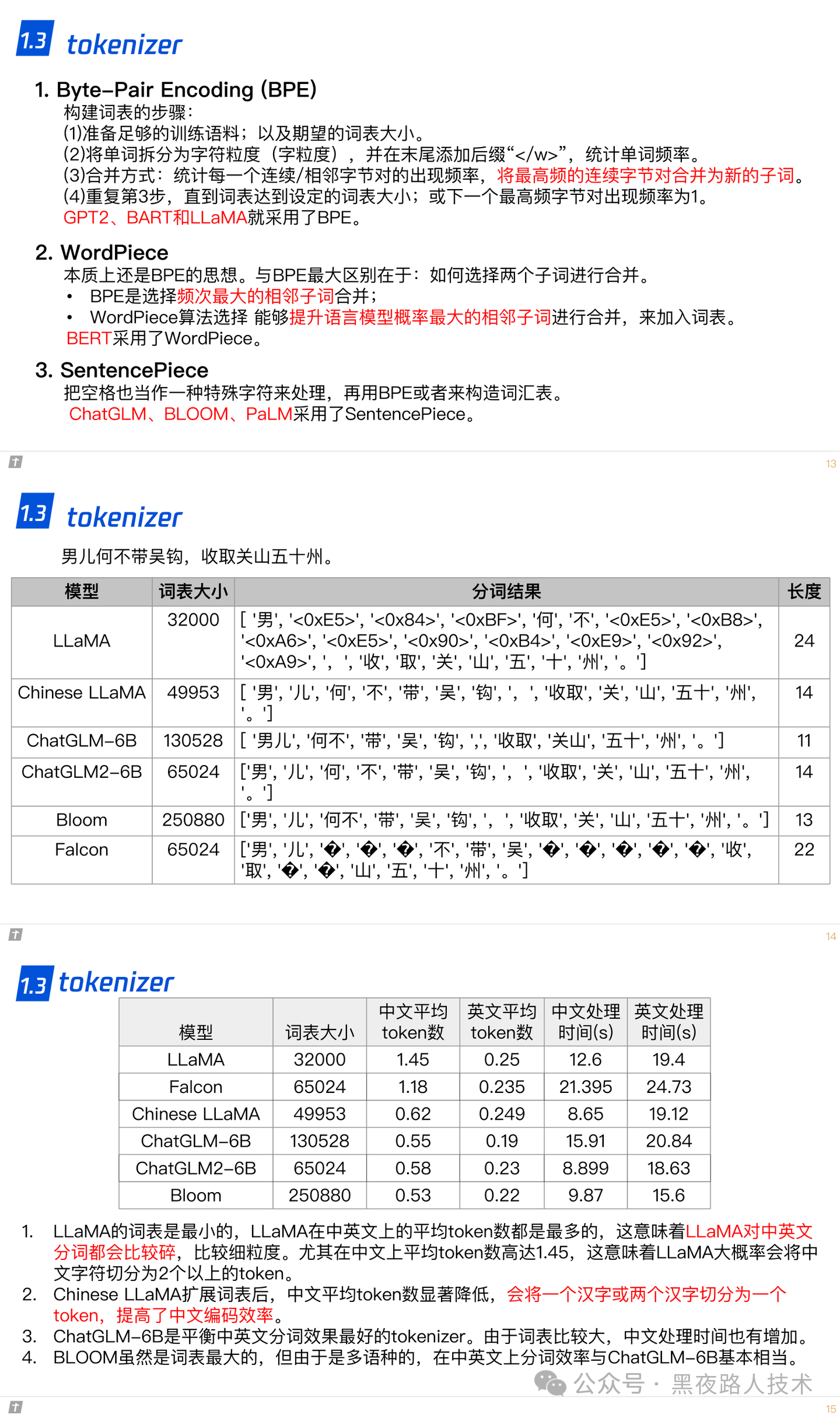
1.3 tokenizer
1.4 位置编码

1.5 层归一化

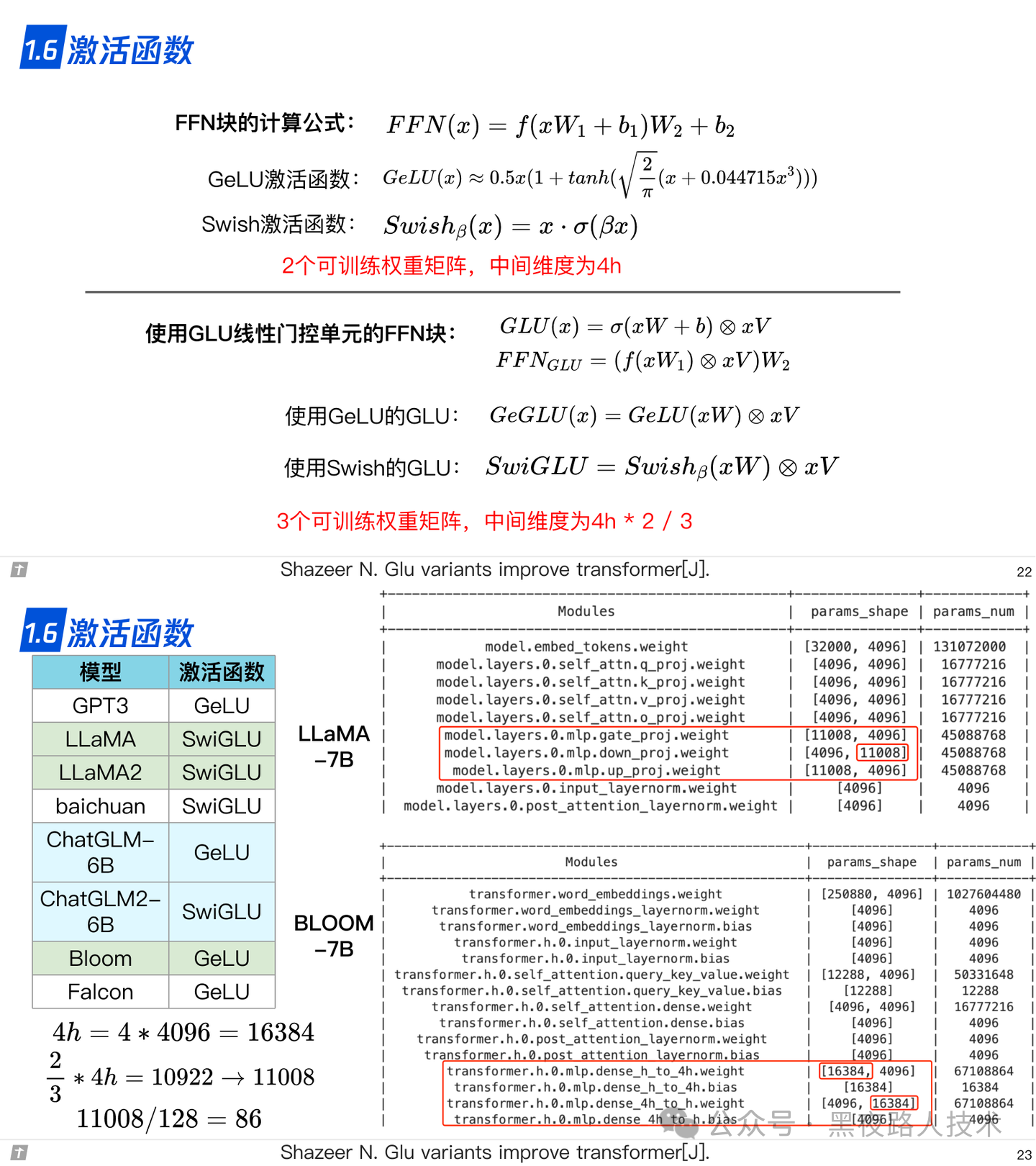
1.6 激活函数
1.7 Multi-query Attention与Grouped-query Attention

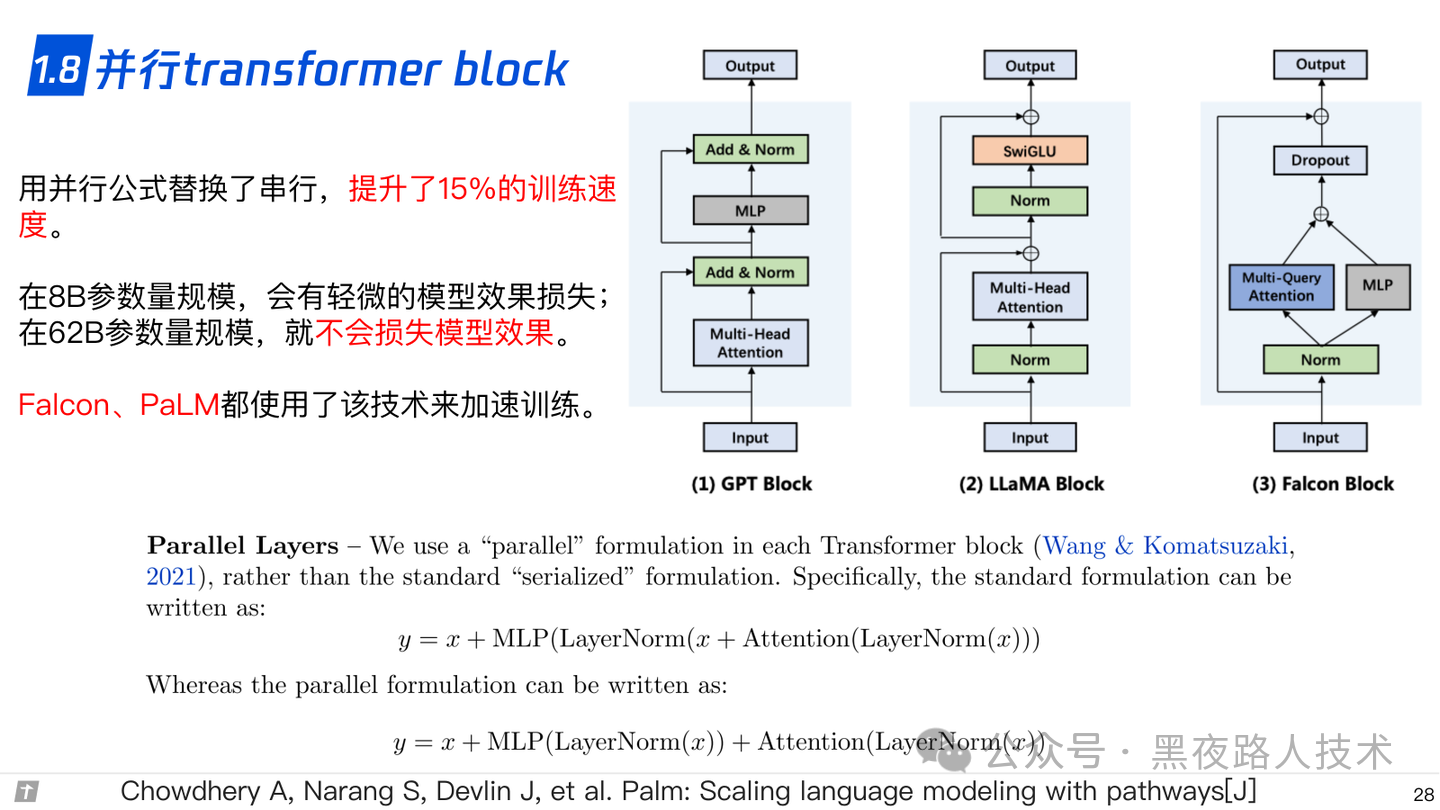
1.8 并行transformer block
1.9 总结-训练稳定性

2.LLM的分布式预训练
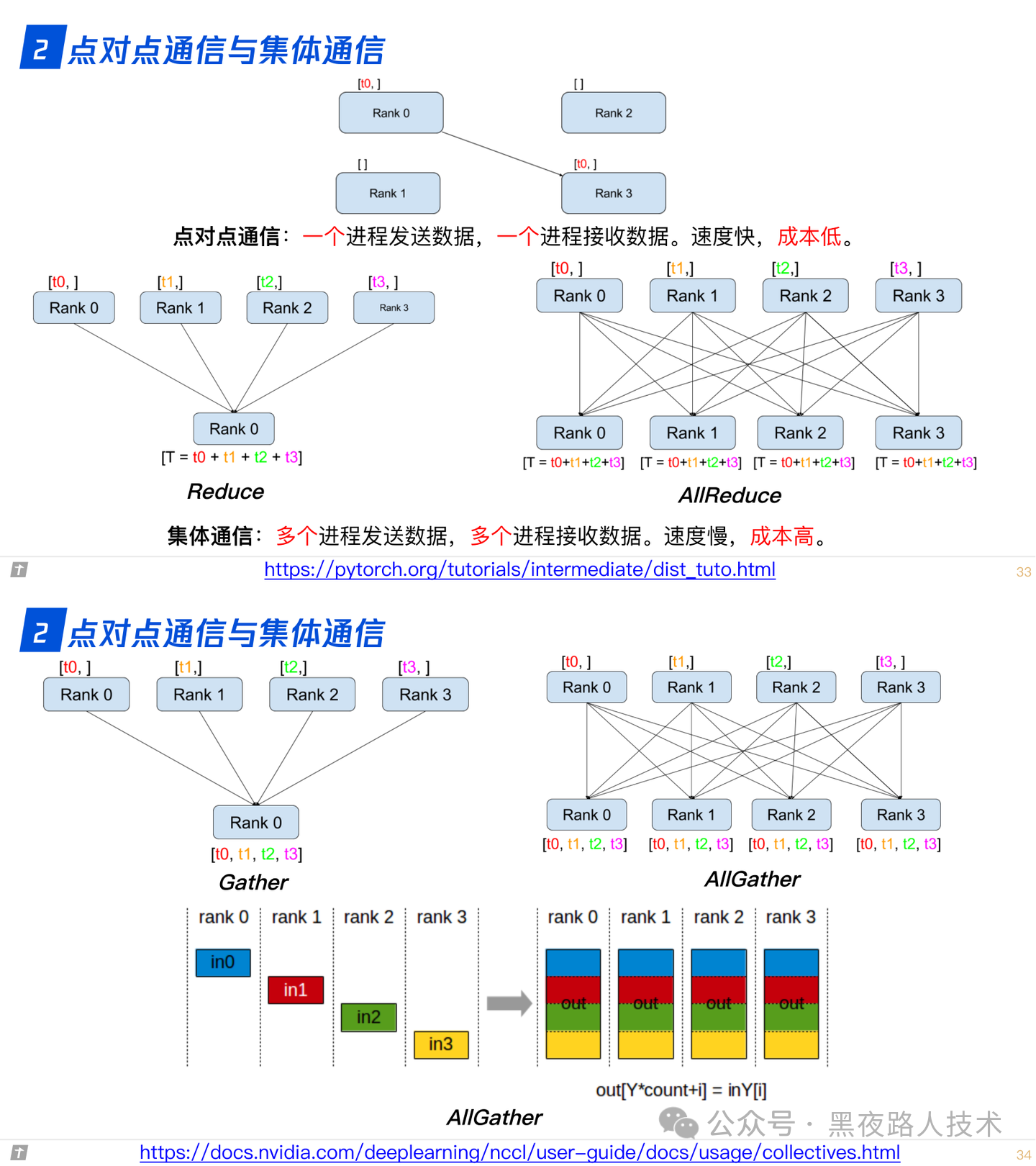
2.0 点对点通信与集体通信
2.1 数据并行

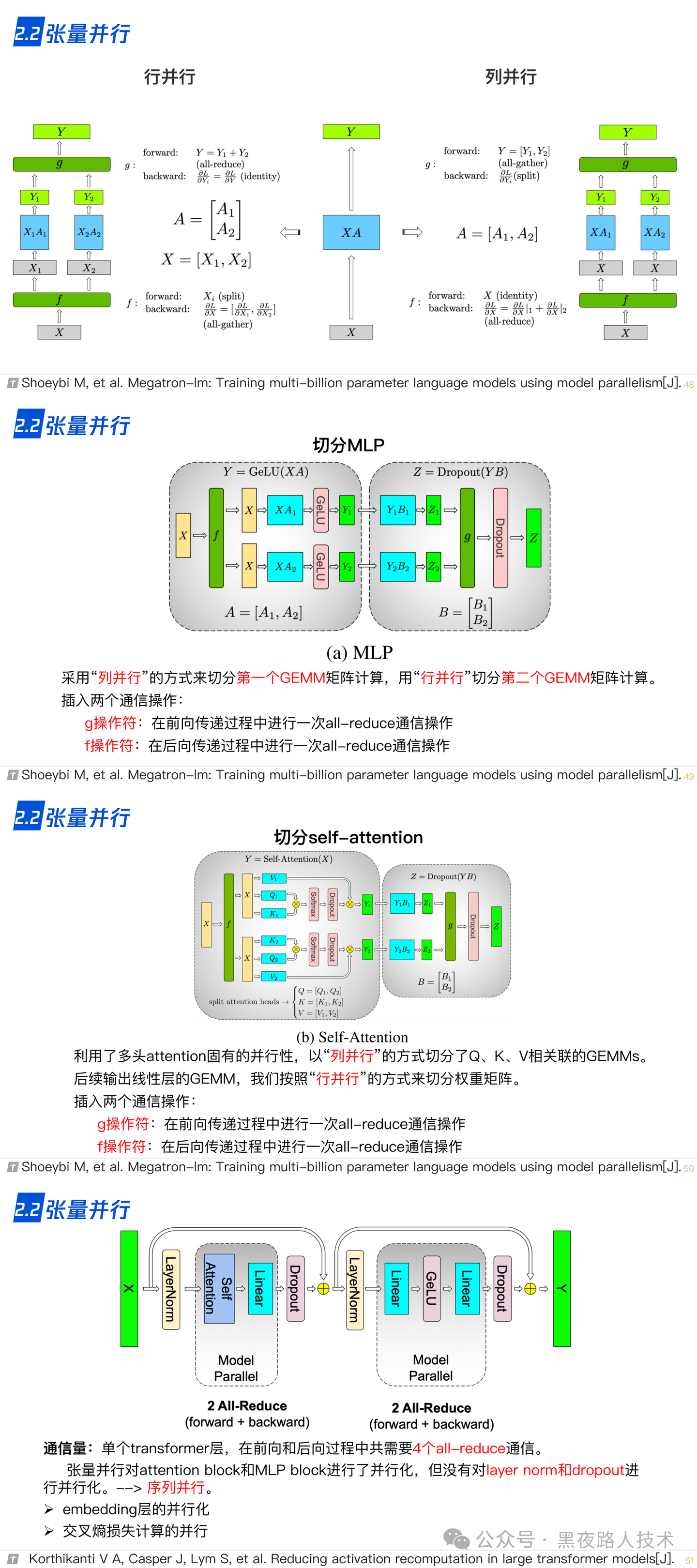
2.2 张量并行

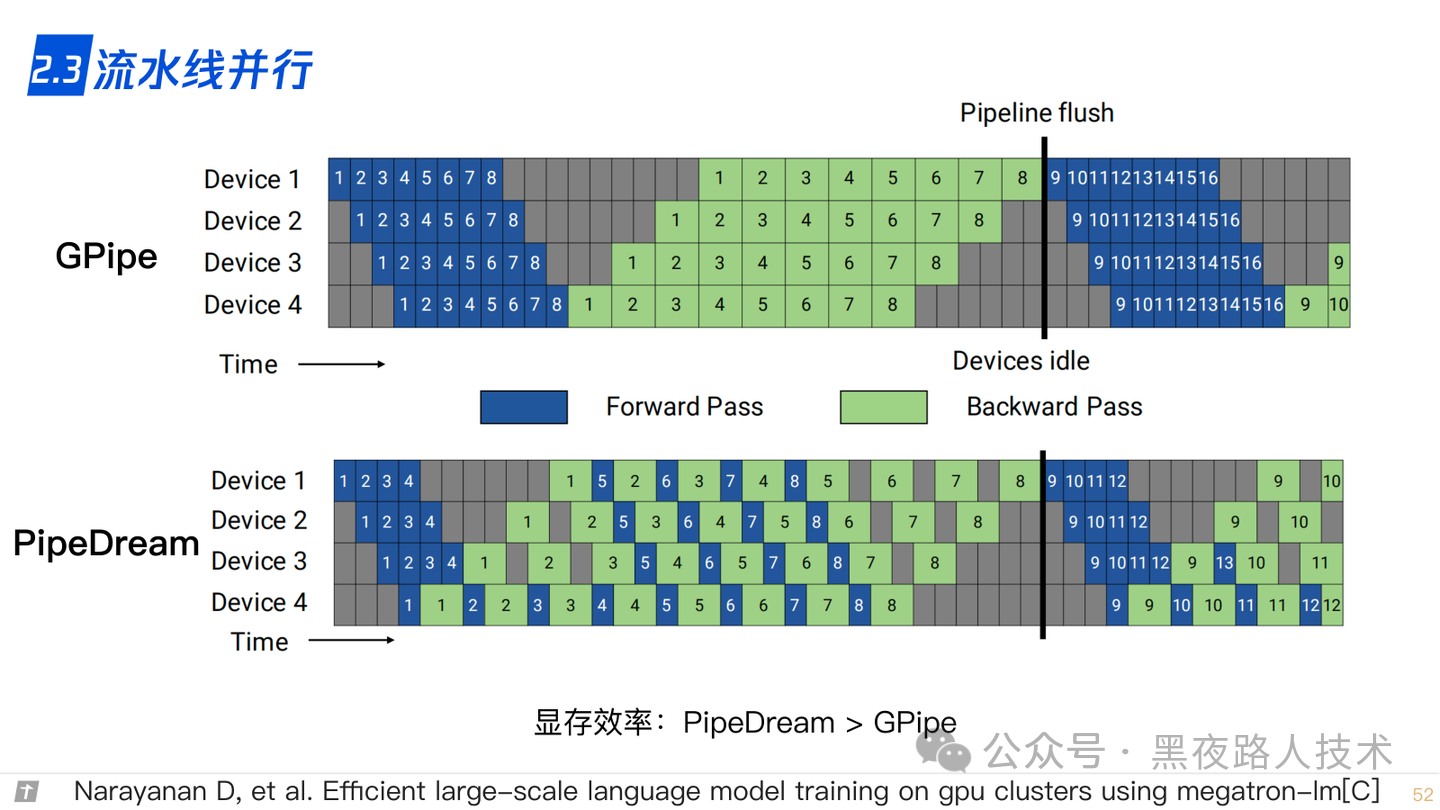
2.3 流水线并行
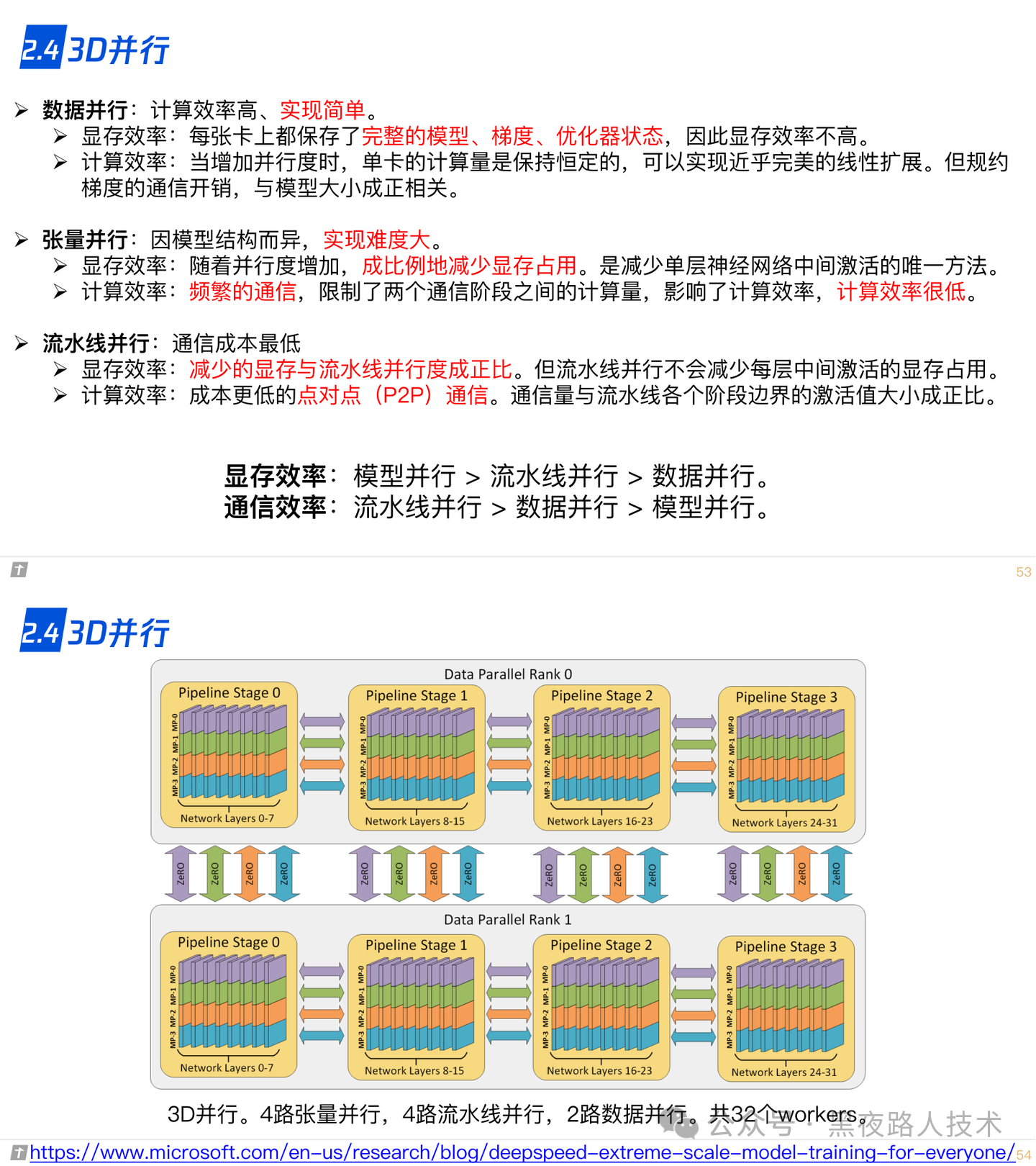
2.4 3D并行
2.5 混合精度训练
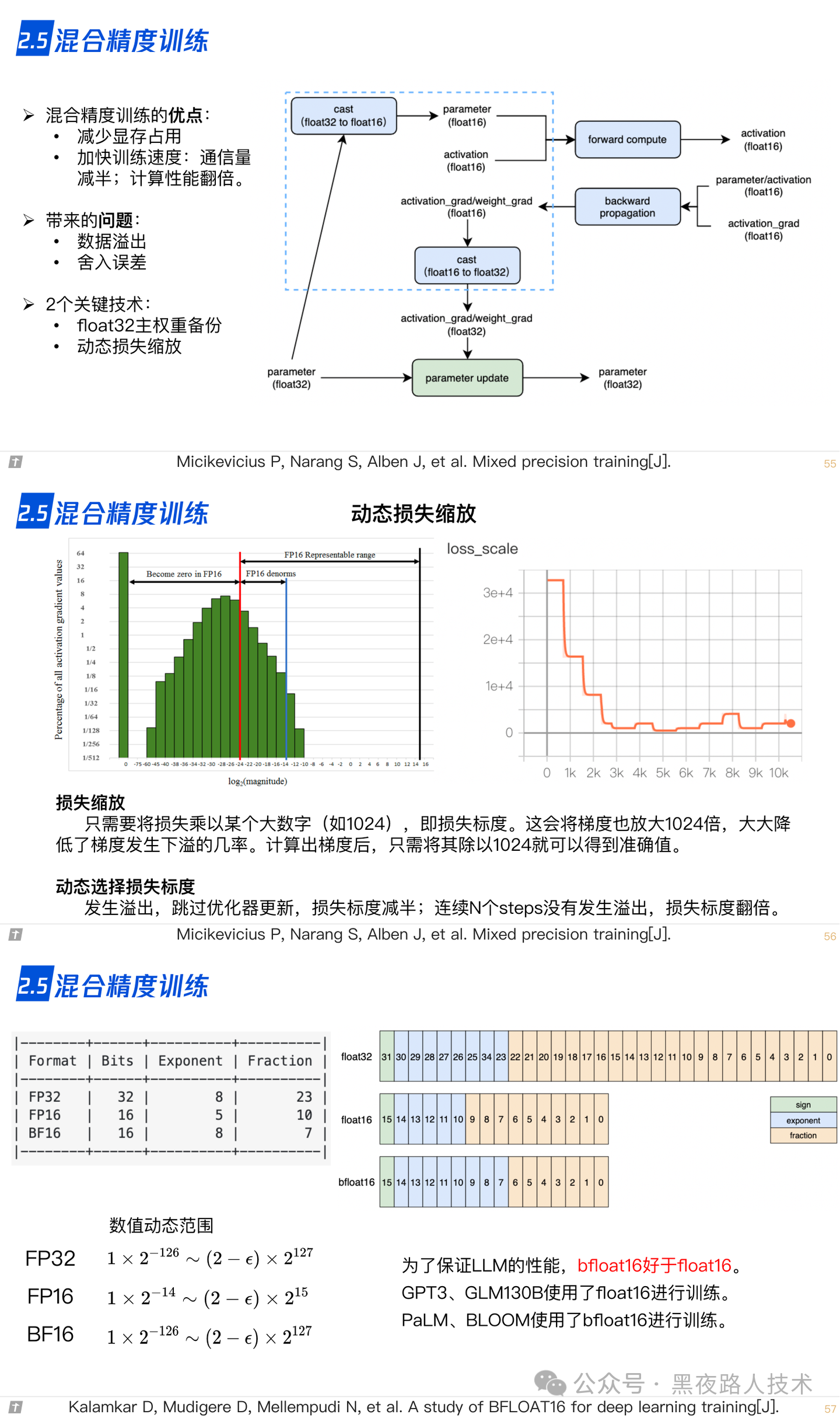
2.6 激活重计算
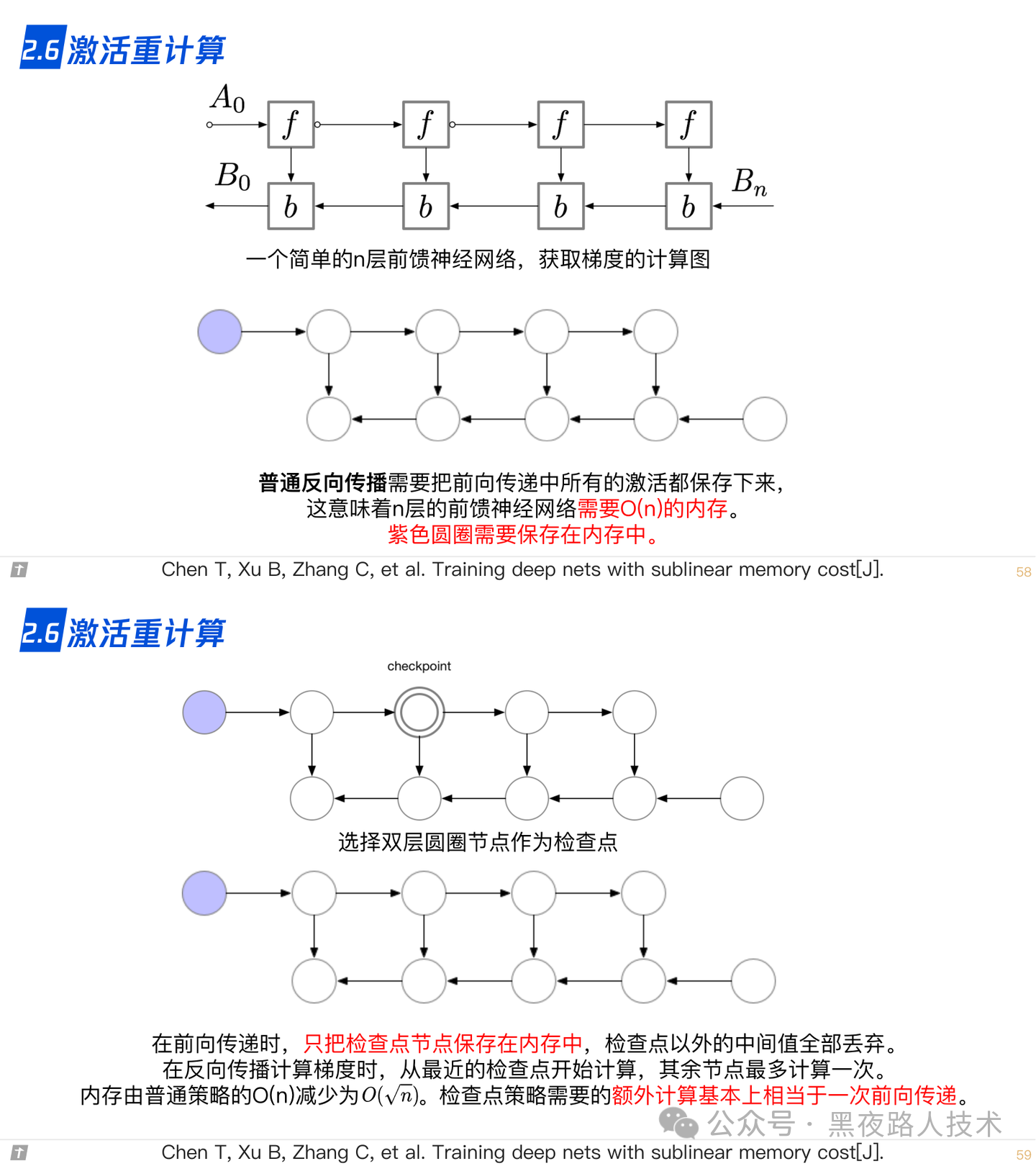
2.7 ZeRO,零冗余优化器
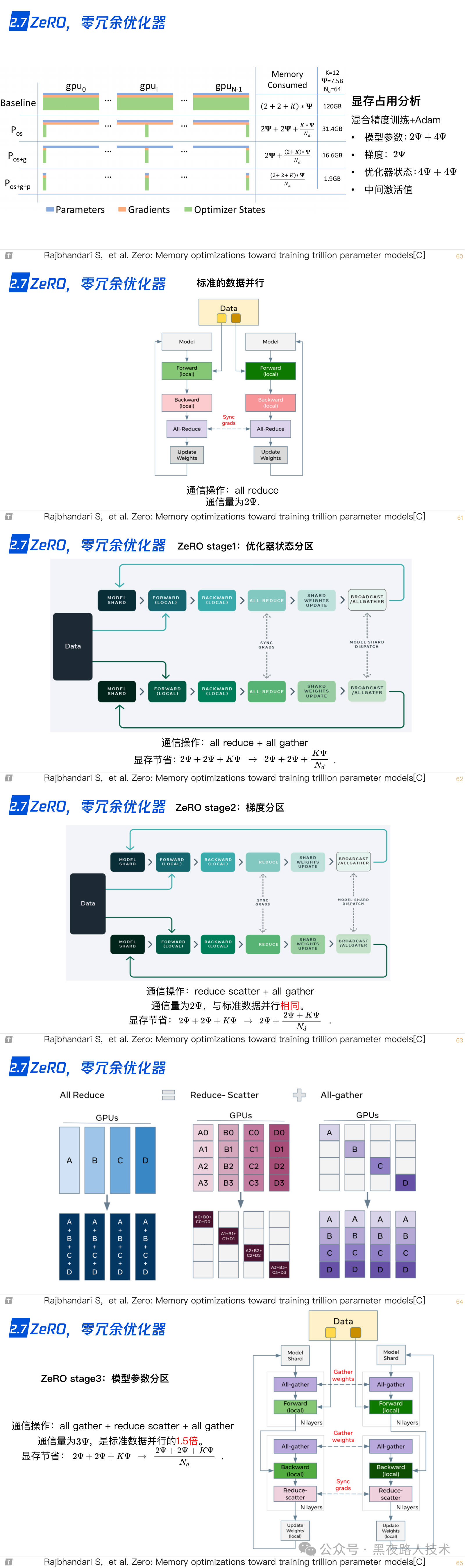
2.8 CPU-offload,ZeRO-offload
2.9 Flash Attention

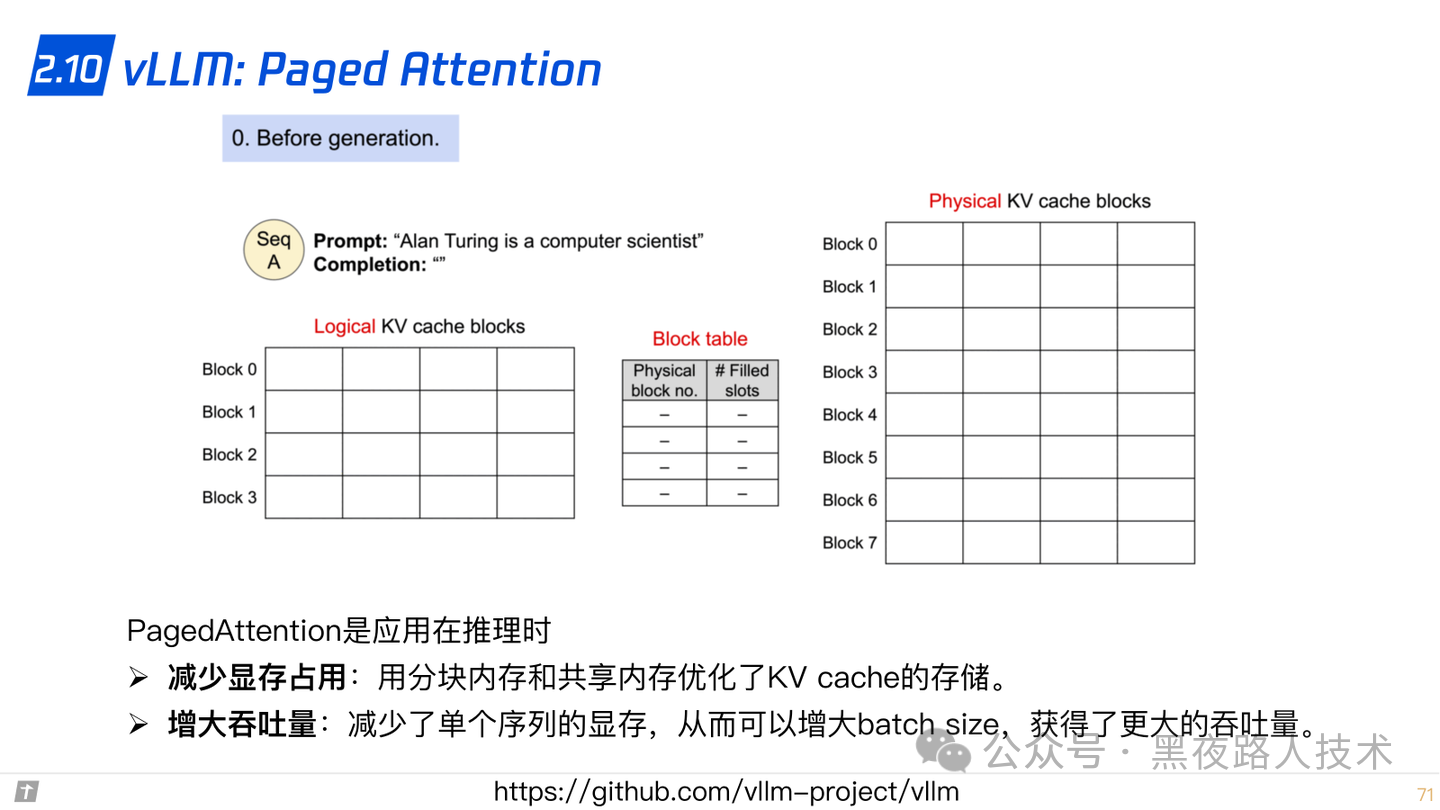
2.10 vLLM: Paged Attention
3. LLM的参数高效微调
3.0 为什么进行参数高效微调?

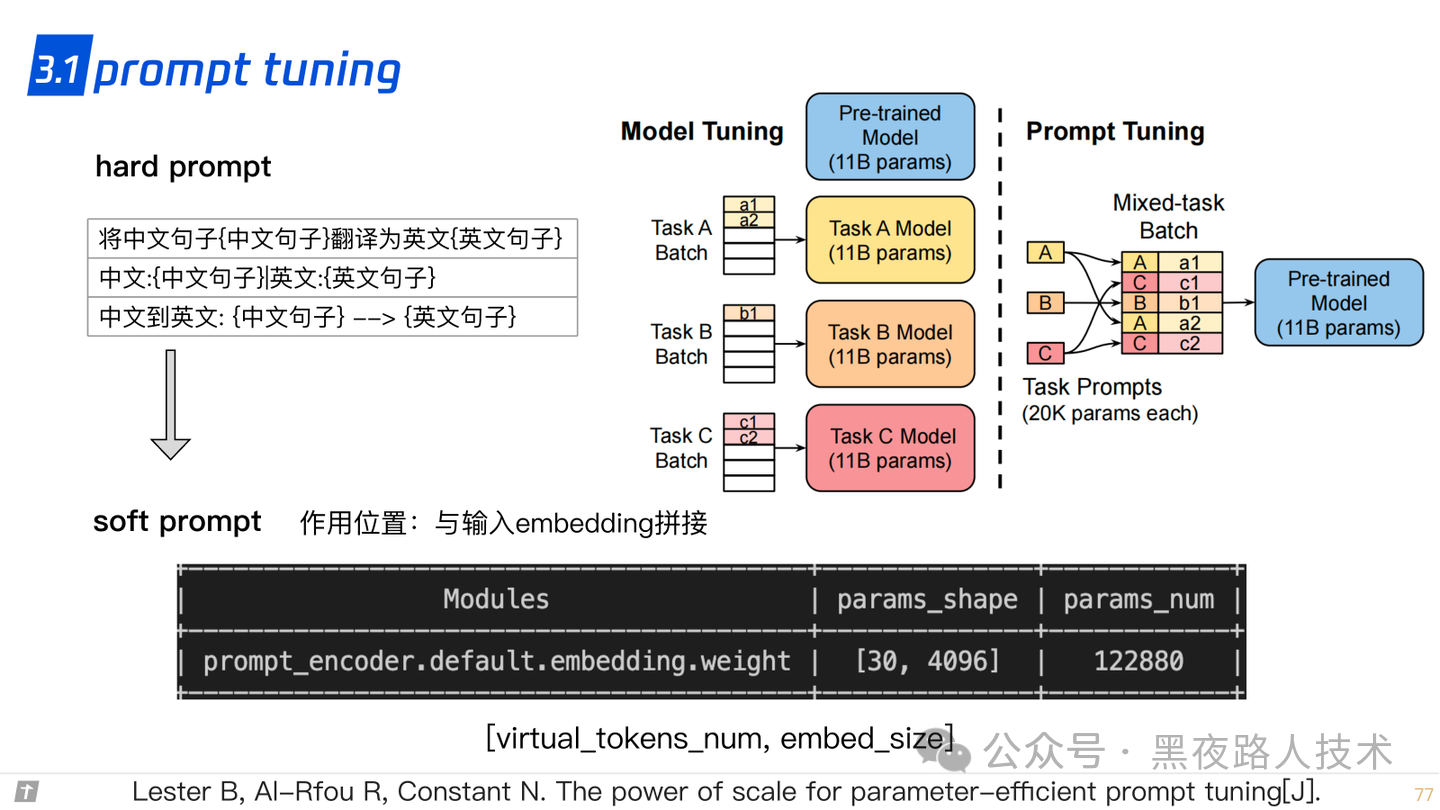
3.1 prompt tuning
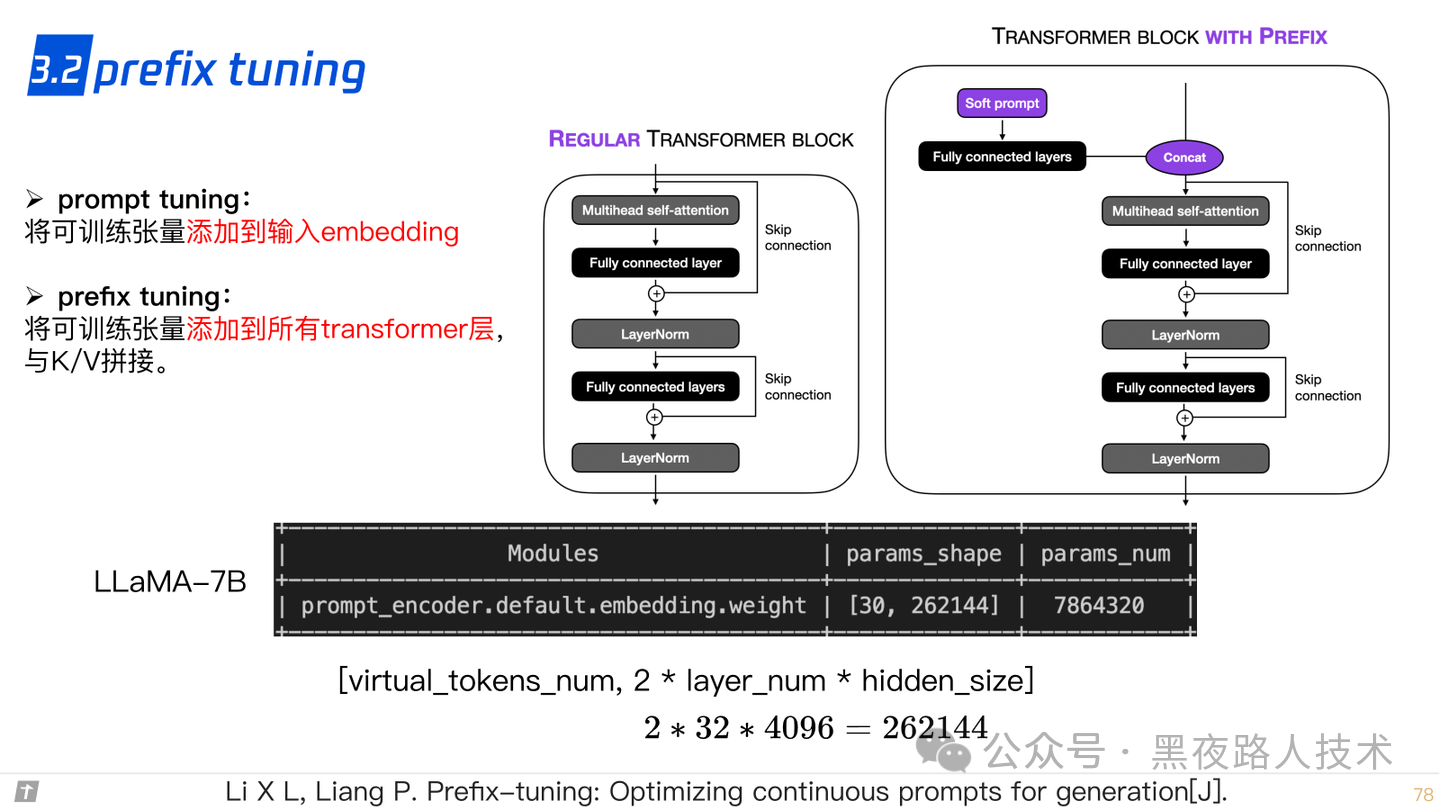
3.2 prefix tuning
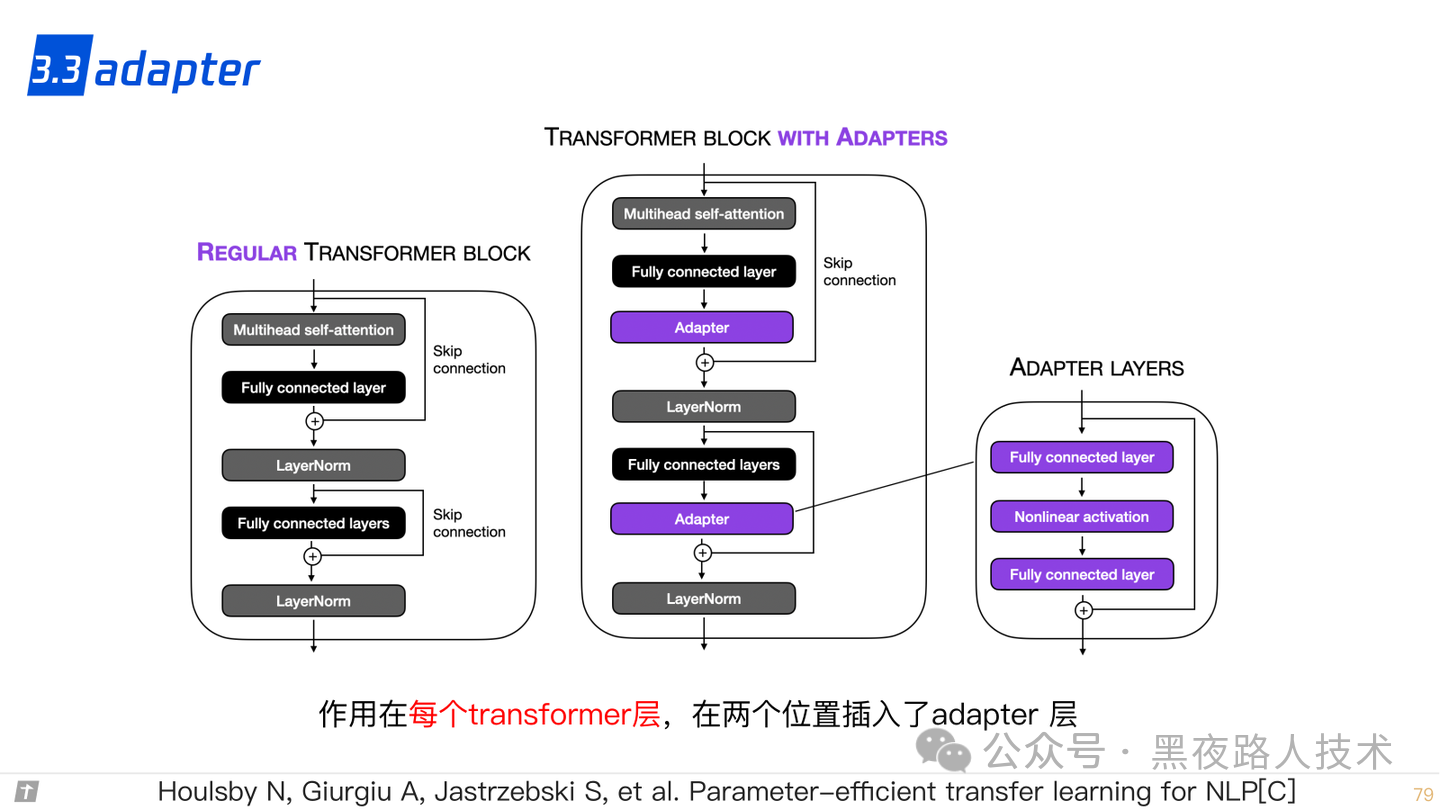
3.3 adapter
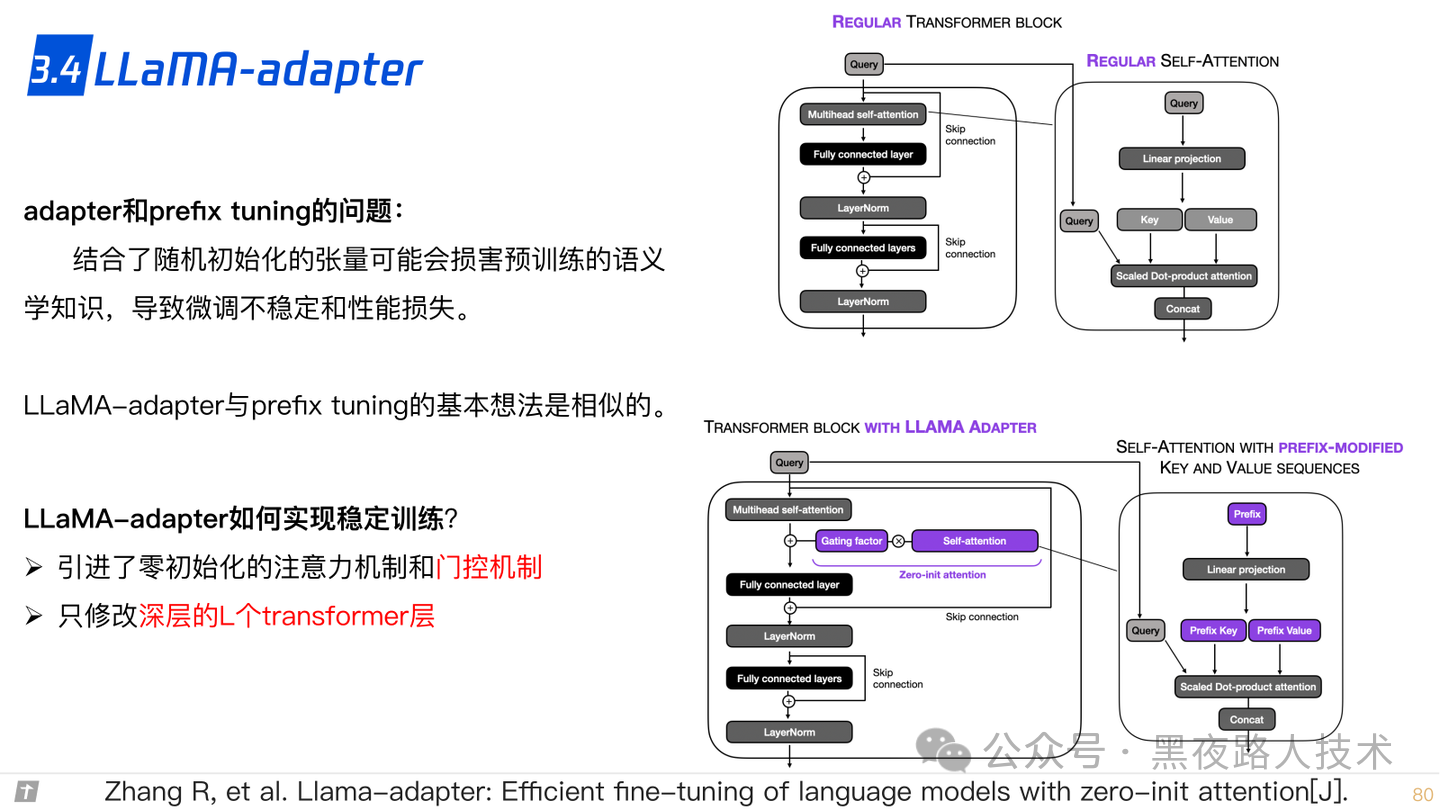
3.4 LLaMA adapter
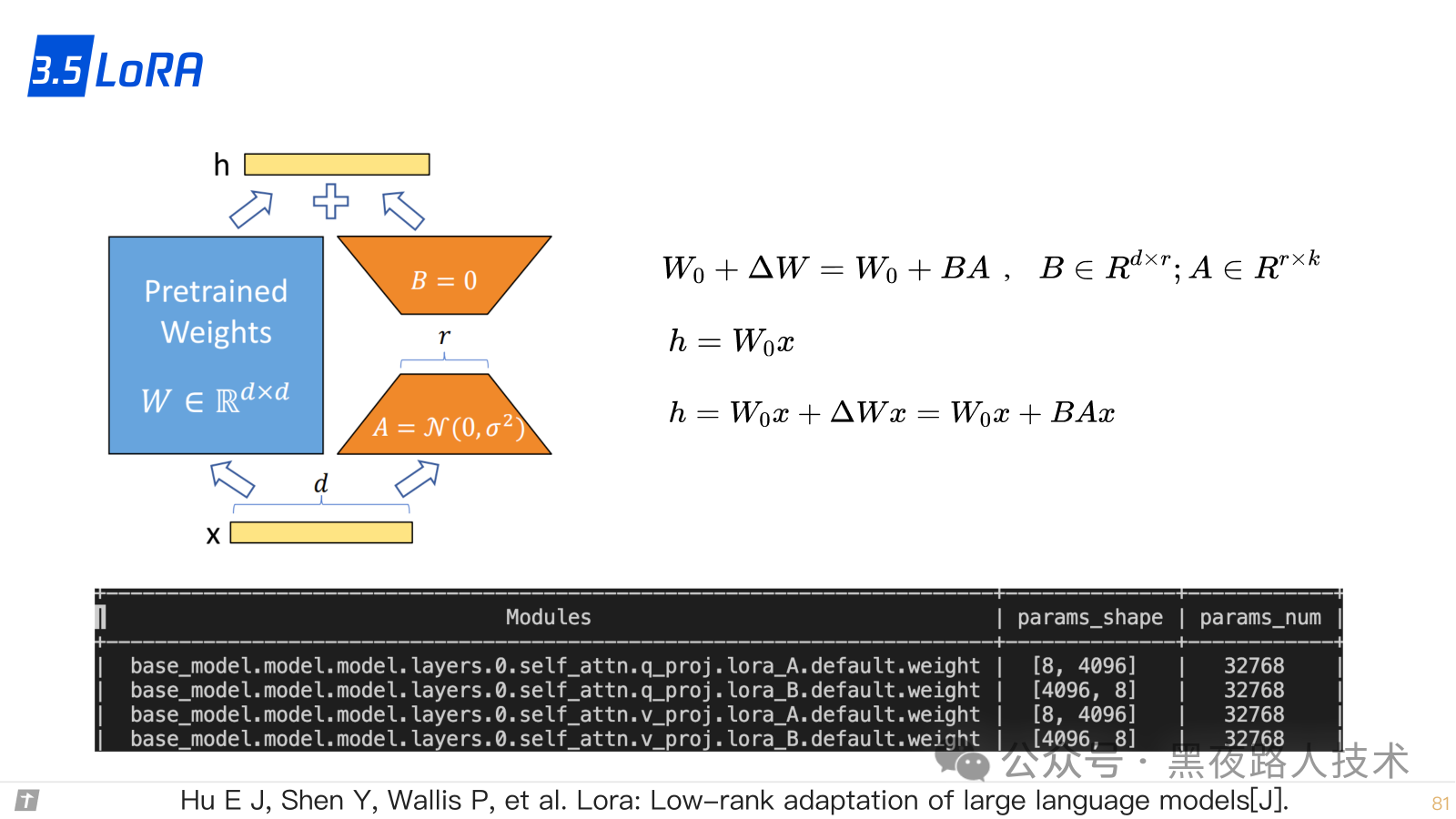
3.5 LoRA
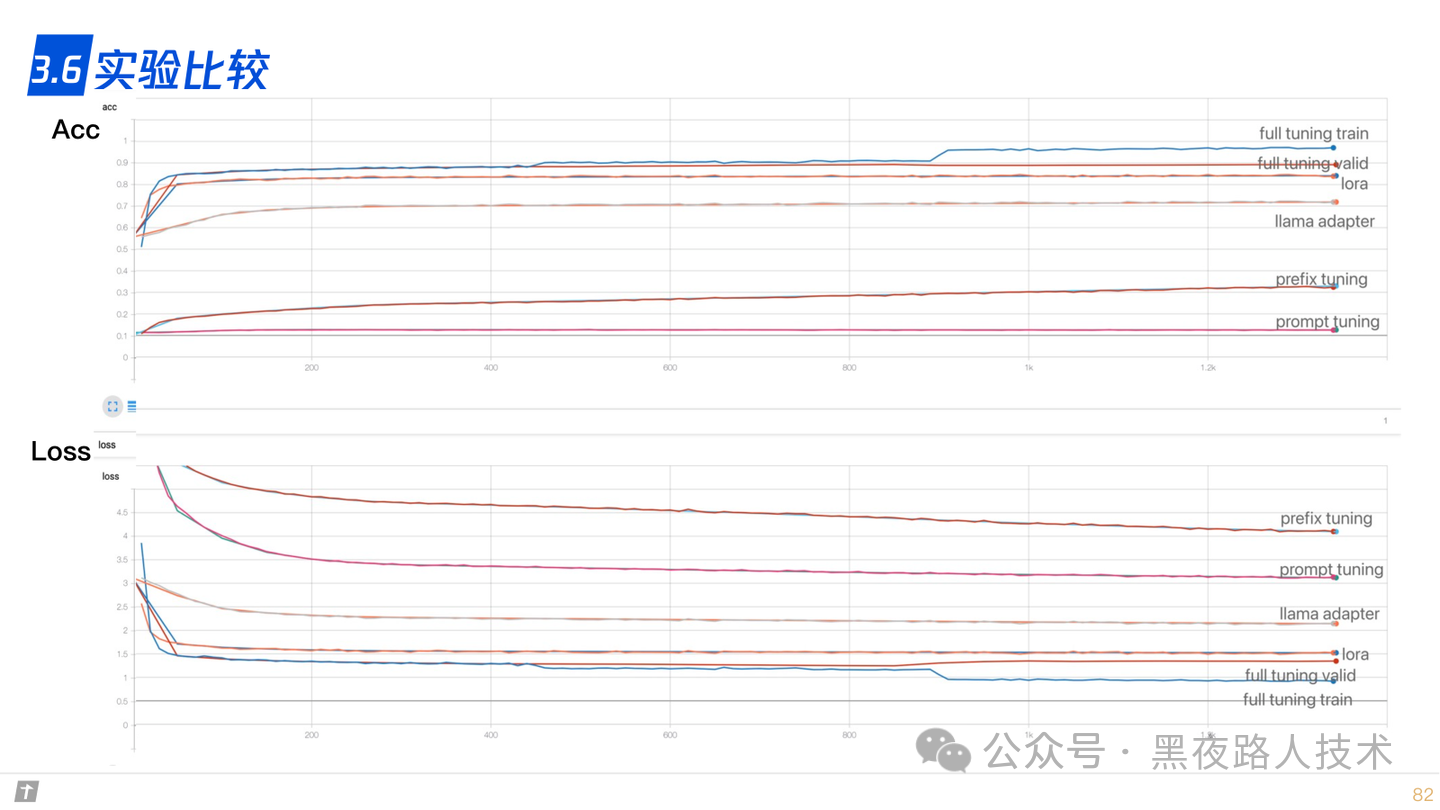
3.6 实验比较
【大模型介绍电子书】
要获取本书全文PDF内容,请【黑夜路人技术】VX后台留言:“AI大模型基础” 或者 “大模型基础” 就会获得电子书的PDF。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)