感知-R1:使用强化学习的开创性感知策略
受DeepSeek-R1成功的启发,我们探索了基于规则的强化学习(RL)在多模态语言模型(MLLM)后训练阶段用于感知策略学习的潜力。尽管前景光明,我们的初步实验表明,在所有视觉感知任务中,通过RL引入思考过程并不总能带来性能提升。这促使我们深入研究RL在视觉感知中的核心作用。在这项工作中,我们回归基础,探讨了RL对不同感知任务的影响。我们观察到感知困惑度是决定RL有效性的重要因素。此外,我们还发
恩 禹 1,1‾{ }^{1, \overline{1}}1,1,康恒 林 2,3‾{ }^{2, \overline{3}}2,3,良 赵 3,3‾{ }^{3, \overline{3}}3,3,
继盛 尹 3{ }^{3}3,亚娜 魏 4{ }^{4}4,元光 彭 5{ }^{5}5,浩然 魏 3{ }^{3}3,建坚 孙 3{ }^{3}3,春睿 韩 3{ }^{3}3,正 何 3{ }^{3}3,祥宇 张 3{ }^{3}3,大昕 江 3{ }^{3}3,靖宇 王 2{ }^{2}2,文兵 陶 1†{ }^{1 \dagger}1†
1{ }^{1}1 华中科技大学
2{ }^{2}2 北京邮电大学 3{ }^{3}3 StepFun
4{ }^{4}4 约翰霍普金斯大学 5{ }^{5}5 清华大学
{yuen, wenbingtao}@hust.edu.cn
https://github.com/linkangheng/PR1
摘要
受DeepSeek-R1成功的启发,我们探索了基于规则的强化学习(RL)在多模态语言模型(MLLM)后训练阶段用于感知策略学习的潜力。尽管前景光明,我们的初步实验表明,在所有视觉感知任务中,通过RL引入思考过程并不总能带来性能提升。这促使我们深入研究RL在视觉感知中的核心作用。在这项工作中,我们回归基础,探讨了RL对不同感知任务的影响。我们观察到感知困惑度是决定RL有效性的重要因素。此外,我们还发现奖励设计在进一步接近模型感知上限方面起着至关重要的作用。为了利用这些发现,我们提出了感知-R1,这是一个在MLLM后训练阶段使用GRPO的可扩展RL框架。使用标准的Qwen2-VL-2B-Instruct,感知-R1在RefCOCO+上实现了 +4.2%+\mathbf{4 . 2 \%}+4.2% 的提升,在PixMo-Count上实现了 +17.9%+\mathbf{1 7 . 9 \%}+17.9% 的提升,在PageOCR上实现了 +4.2%+\mathbf{4 . 2 \%}+4.2% 的提升,并且首次在COCO2017 val对象检测基准上达到了 31.9%AP\mathbf{3 1 . 9} \% \mathbf{A P}31.9%AP,为感知策略学习建立了强大的基线。
1 引言
“我们看到的世界不是它本来的样子,而是我们自己——或者是我们被条件化后所看到的样子。”
史蒂芬·R·柯维
大型语言模型(LLM)的格局经历了从非推理基础模型(如GPT-4/4o [44, 19], DeepSeek-V3 [33])到强推理模型(如OpenAI o1/o3 [45], DeepSeek-R1 [12], 和Kimi-1.5 [57])的范式转变。特别是DeepSeek-R1引入了一种简单而有效的基于规则的强化学习(RL)方法[55],使模型能够产生新兴推理模式,而不依赖于传统的蒙特卡洛树搜索(MCTS)[17, 67]或过程奖励模型(PRM)[31]技术。这催化了LLM后训练技术的新革命,促使研究人员开发更强大的推理语言模型[42, 24]。
尽管取得了这些进展,当前的探索主要集中在纯语言领域,这些推理模型的单模态特性限制了它们以真正感知的方式与世界互动的能力。为弥补这一差距,本工作迈出了开创性的一步,探索
${ }^{1}$ 通讯作者, ${ }^{\overline{1}}$ 核心贡献
在多模态LLM中的感知策略学习。虽然将带有推理过程的RL技术从语言领域转移到视觉任务上(即链式思维[66])在某些视觉任务上显示出希望,但我们的实证研究表明,这种方法并非普遍有效。这不可避免地促使我们重新审视RL在视觉感知任务中的作用,以及如何利用RL实现更好和可扩展的感知策略。
目前对RL作为后训练技术的理解主要基于纯语言任务[24]和以语言为中心的多模态任务[10]。然而,视觉感知任务的特征与自然语言根本不同,需要重新理解RL在视觉感知中的作用。具体来说,视觉感知具有两个独特属性:
- 视觉感知体现在客观的物理世界中。它具有明确的物理真实值,例如点、线或边界框,但与语言相比缺乏语义。
-
- 视觉感知,例如视觉定位和计数,大多是“单步”直接预测。它缺乏结构化的推理搜索空间供RL探索。
这两个特性决定了RL在视觉感知中的应用与纯语言[24]和以语言为中心的多模态[39, 41]方法具有不同的特性。在这项工作中,我们深入探讨了MLLM在视觉感知领域的RL后训练,并进一步补充和扩展了上述理解。通过广泛的实验分析,我们发现了几个苦涩但有价值的结论:
- 视觉感知,例如视觉定位和计数,大多是“单步”直接预测。它缺乏结构化的推理搜索空间供RL探索。
- 在当前的感知策略中,显式的思考过程(CoT)并非必要。(§ 5.2)我们观察到没有思考过程的模型表现优于有思考过程的模型。
-
- 奖励设计在感知策略学习中起着关键作用。(§ 5.3)一个适当的奖励函数将导致更健康的学习曲线,并探索更强的MLLM感知模式。
-
- 感知困惑度决定了RL相对于SFT的优势。(§ 5.2)我们观察到RL在更复杂的视觉任务上相较于SFT可以带来更显著的改进,例如目标检测。
基于这些发现,我们提出了一种简单、有效且可扩展的RL框架,即PerceptionR1\boldsymbol{R 1}R1,用于高效的感知策略学习。受到主流语言推理模型[12, 57]的启发,Perception-R1在MLLM后训练阶段应用了基于规则的RL算法GRPO[55]。使用普通的Qwen2-VL-2B-Instruct[61],Perception-R1在多个视觉感知基准测试中取得了显著的改进,例如在RefCOCO+ [40] 上提高了 +4.2%+\mathbf{4 . 2 \%}+4.2%,在PixMoCount [13] 上提高了 +17.9%+\mathbf{1 7 . 9 \%}+17.9%,以及在PageOCR [34] 上提高了 +4.2%+\mathbf{4 . 2 \%}+4.2% F1 分数。更重要的是,Perception-R1首次使纯MLLM在COCO2017 [32] val 对象检测基准上达到 31.9%mAP\mathbf{3 1 . 9} \% \mathrm{mAP}31.9%mAP,展示了通用基础模型在主流视觉任务中超越专家模型的巨大潜力。我们希望我们的方法、结果和分析能够激励未来关于使用RL进行感知策略学习的研究。
- 感知困惑度决定了RL相对于SFT的优势。(§ 5.2)我们观察到RL在更复杂的视觉任务上相较于SFT可以带来更显著的改进,例如目标检测。
2 相关工作
多模态基础和推理模型。最近,视觉-语言模型[37, 3, 73, 70]通过大规模预训练[2, 61]和视觉指令调整[37, 35]在视觉理解[64, 68]和生成[14, 48]方面表现出显著的能力。这些模型通过视觉编码器[49]和适配器[11, 37]将视觉模态整合到统一的语义空间中,同时利用自回归大型语言模型[59, 1]作为解码器进行输出生成。尽管多模态基础模型取得了进展,但其视觉推理能力仍处于早期发展阶段。近期的方法[8, 39, 41]探索了通过强化学习(RL)后训练来增强视觉推理。然而,这些方法主要集中在以语言为中心的任务上,例如模糊引用解析[39]和几何问题解决[41],而忽略了感知驱动推理的关键方面。在本工作中,我们迈出了开创性的一步,利用RL进行感知策略学习,旨在填补这一空白并推进多模态推理。
多模态模型中的视觉感知。视觉感知作为计算机视觉领域的一个概念[21, 52, 20, 69, 29],指的是解释和理解来自现实世界的感官信息的过程,即视觉信息。在多模态LLM(MLLM)的背景下,视觉感知在使模型集成、理解和推理图像或视频中的视觉信息方面起着关键作用。现有的MLLM通常通过设计更先进的视觉感知架构[63, 64]、更适合的视觉-语言建模策略[70, 68]和更复杂的后训练技术[74]来增强其视觉感知能力。本工作旨在从RL的角度探索进一步增强视觉感知的潜力。
LLM和MLLM中的基于RL的后训练。强化学习(RL)已成为优化LLM与人类偏好和特定任务目标一致性的关键范式。突出的方法如基于人类反馈的强化学习(RLHF)[46]和直接偏好优化(DPO)[50]在提高LLM的安全性、连贯性和指令跟随能力方面取得了显著成功[43, 47, 44]和MLLM[74, 60]。最近,以GRPO[55]为代表的基于规则的RL技术展示了大规模RL应用的潜力。LLM正式进入了强推理模型时代。随后,MLLM[8, 39, 41]也迅速跟进了这项技术。然而,迄今为止,多模态领域尚未出现令人兴奋的真正的“啊哈时刻”。本研究旨在探讨RL对多模态模型的潜在贡献,重点在于视觉感知。
3 基础知识
感知策略定义。视觉-语言上下文中感知策略的目标是使模型首先(i)从环境中提取和理解视觉信息[37, 68],然后(ii)基于这种理解进行逻辑推理[73, 70],以(iii)完成特定任务并与环境进一步交互[5, 22]。在本工作中,我们旨在通过感知策略学习赋予模型处理一系列纯视觉任务(如计数、检测)和视觉-语言任务(如定位、光学字符识别(OCR))的能力。
组相对策略优化(GRPO [55])是一种专为LLM后训练设计的基于规则的强化学习算法。其核心思想是使用组相对奖励来优化策略,从而消除对单独批评模型的需求[54]。具体而言,GRPO从旧策略为相同输入采样多个输出(图1中的o1∼og\mathbf{o}_{\mathbf{1}} \sim \mathbf{o}_{\mathbf{g}}o1∼og),计算这些输出的平均奖励作为基线,并使用相对奖励指导策略更新。GRPO的优化目标可以表示为:
JGRPO (θ)=E[q∼P(Q),{oi}i=1G∼πθold (O∣q)]1G∑i=1G1∣oi∣∑t=1∣oi∣∑θold A^i,t,clip(πθi,tπθold i,t,1−ϵ,1+ϵ)A^i,t]−βDKL[πθ∥πref ]),DKL[πθ∥πref ]=πref (oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−logπref (oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−1, \begin{aligned} & \mathcal{J}_{\text {GRPO }}(\theta)=\mathbb{E}_{[q \sim P(Q), \left\{o_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{\text {old }}}(O \mid q)]} \\ & \quad \frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|o_{i}\right|} \sum_{t=1}^{\left|o_{i}\right|} \sum_{\theta_{\text {old }}} \hat{A}_{i, t}, \operatorname{clip}\left(\frac{\pi_{\theta}^{i, t}}{\pi_{\theta_{\text {old }}}^{i, t}}, 1-\epsilon, 1+\epsilon\right) \hat{A}_{i, t}\left]-\beta \mathbb{D}_{\mathrm{KL}}\left[\pi_{\theta} \| \pi_{\text {ref }}\right]\right), \\ & \quad \mathbb{D}_{\mathrm{KL}}\left[\pi_{\theta} \| \pi_{\text {ref }}\right]=\frac{\pi_{\text {ref }}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-\log \frac{\pi_{\text {ref }}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-1, \end{aligned} JGRPO (θ)=E[q∼P(Q),{oi}i=1G∼πθold (O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣θold ∑A^i,t,clip(πθold i,tπθi,t,1−ϵ,1+ϵ)A^i,t]−βDKL[πθ∥πref ]),DKL[πθ∥πref ]=πθ(oi,t∣q,oi,<t)πref (oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref (oi,t∣q,oi,<t)−1,
其中ϵ\epsilonϵ和β\betaβ是超参数,A^i,t\hat{A}_{i, t}A^i,t是优势,通过一组奖励{r1,r2,⋯ ,rG}\left\{r_{1}, r_{2}, \cdots, r_{G}\right\}{r1,r2,⋯,rG}计算得出,这些奖励对应于每组内的输出。更多详情请参见[12, 55]。
4 Perception-R1
简而言之,我们的Perception-R1将基于规则的RL算法GRPO [55]应用于MLLM的后训练阶段,并优化奖励建模以支持感知策略学习。图1说明了这个想法,接下来将介绍更多的方法和实现细节。
4.1 基于规则的奖励建模
奖励函数在强化学习(RL)中作为主要的训练信号,指导优化过程。现有的LLM方法[12, 57, 24]基本上采用了一种高度弹性的基于规则的奖励系统,该系统仅包含两种奖励类型:格式奖励和答案奖励。
格式奖励。在现有的LLM和MLLM中,输出格式由两个基本部分组成:最终输出格式和中间推理过程格式。对于最终输出的奖励按照特定任务要求定义,通常封装在标签内,而对于中间推理过程的奖励通常要求推理步骤被封闭在标签内。形式上,
Sformat ={1, if format is correct −1, if format is incorrect S_{\text {format }}=\left\{\begin{array}{ll} 1, & \text { if format is correct } \\ -1, & \text { if format is incorrect } \end{array}\right. Sformat ={1,−1, if format is correct if format is incorrect
在Perception-R1中,我们遵循这种设置。一个细微的区别是,视觉感知任务通常需要输出物体坐标,例如边界框、线条或点。因此,输出格式必须严格约束为[x1,y1,x2,y2][\mathrm{x} 1, \mathrm{y} 1, \mathrm{x} 2, \mathrm{y} 2][x1,y1,x2,y2]结构。
答案奖励。答案奖励涉及模型生成响应的正确性,是奖励设计的核心考虑因素。通常,语言模型的输出是抽象且语义丰富的,需要通过外部机制(如基于代码的ADE [12]或数学答案验证[55])进行验证。相比之下,视觉感知任务得益于明确定义的物理事实真相,简化了稳健奖励函数的开发。
Perception-R1偏离了LLM方法,将奖励机制锚定在视觉区分上。这一转变至关重要,因为它用明确的、可量化的指标取代了语言模型中常见的隐含和主观反馈机制。形式上,判别奖励rir_{i}ri可以表示为:
ri=Φ(oi,z) r_{i}=\Phi\left(o_{i}, z\right) ri=Φ(oi,z)
其中Φ(⋅)\Phi(\cdot)Φ(⋅)表示判别函数,例如边界框的IoU或点的欧几里得距离。通过利用视觉区分,我们为模型提供了清晰且客观的反馈信号,确保模型策略更新时具有精确测量的余量。
4.2 多主体奖励匹配
在自然环境中,物理对象很少单独出现,而通常是成组共现。这种内在复杂性引发了一个挑战,我们称之为奖励匹配,即在计算奖励之前将模型的输出与相应的地面真值对齐。具体来说,当提示模型预测图像中多个主体的属性时,例如点和边界框,需要确定每个主体的适当地面真值参考,以确保准确的奖励分配。
形式上,设y={yi}i=1Ny=\left\{y_{i}\right\}_{i=1}^{N}y={yi}i=1N表示NNN个主体的预测属性集合,z={zj}j=1Mz=\left\{z_{j}\right\}_{j=1}^{M}z={zj}j=1M表示相应的地面真值属性集合。我们将奖励匹配问题建模为二分图匹配任务,其中一个节点集对应预测,另一个节点集对应地面真值。预测yiy_{i}yi与地面真值tjt_{j}tj之间的边权重由奖励函数Φ(yi,zj)\Phi\left(y_{i}, z_{j}\right)Φ(yi,zj)决定,该函数衡量它们的相似性或兼容性。目标是找到最大化总奖励的最优分配:
σ^=argmaxσ∈ΩN∑i=1NΦ(yi,zσ(i)) \hat{\sigma}=\underset{\sigma \in \Omega_{N}}{\arg \max } \sum_{i=1}^{N} \Phi\left(y_{i}, z_{\sigma(i)}\right) σ^=σ∈ΩNargmaxi=1∑NΦ(yi,zσ(i))
其中ΩN\Omega_{N}ΩN是预测与地面真值之间所有有效分配的集合。为了高效解决这一优化问题,我们采用了匈牙利算法[27],这是一种广为人知的二分图匹配方法,通过最大化总体奖励(或等价地,最小化成本)保证了最优配对。这确保了每个预测属性与其相应的地面真值准确匹配,从而优化了奖励计算过程。
确定最优奖励分配后,我们通过聚合每个主体的个体奖励来计算答案奖励。数学上,总体奖励得分定义为:
Sanswer =1N∑i=1NΦ(yi,zσ^(i))Stotal =Sformat +Sanswer \begin{aligned} & S_{\text {answer }}=\frac{1}{N} \sum_{i=1}^{N} \Phi\left(y_{i}, z_{\hat{\sigma}(i)}\right) \\ & S_{\text {total }}=S_{\text {format }}+S_{\text {answer }} \end{aligned} Sanswer =N1i=1∑NΦ(yi,zσ^(i))Stotal =Sformat +Sanswer
其中σ^\hat{\sigma}σ^是通过匈牙利算法获得的最优分配。在Perception-R1中,我们主要将奖励匹配用于视觉计数和目标检测任务,因为这些任务涉及多个对象。
4.3 Perception-R1配置
模型设置。我们的模型实现遵循Qwen2-VL [61]。我们主要使用Qwen2-VL-Instruct-2B作为基线模型。我们还使用Qwen2.5-VL-3B-Instruct [3]进行目标检测任务的训练,因其针对定位边界框进行了专门优化。Qwen2-VL的输入图像分辨率动态配合2D-RoPE [56]。
任务和数据设置。鉴于Perception-R1主要面向纯视觉和视觉语言任务,我们选择了一些主流且具有代表性的下游任务进行感知策略学习,具体包括视觉定位,例如refCOCO [71]/+ [71]/g [40],OCR,即PageOCR [34],视觉计数,即Pixmo-Count [13],以及目标检测,即COCO2017 [32]。对于每个任务,分别从样本中抽取子集(5k∼10k)(5 k \sim 10 k)(5k∼10k)作为个体后训练的基础数据。更多细节请参阅附录A.1。
训练设置。我们专注于基于RL的MLLM后训练阶段。所有选定的基础模型都已经过预训练和SFT阶段。在RL阶段,初始学习率设定为1e−61 e-61e−6,默认滚出次数为8,批处理大小为1。以下是后训练期间的一些重要超参数。详细提示设置请参阅附录A.1。
| 梯度累积 | 滚出 G | KL 系数 | 最大响应长度 | 温度 |
|---|---|---|---|---|
| 2 | 8 | 0.04 | 2048 | 1.0 |
奖励设置。我们为各种视觉感知任务定制了不同的判别奖励。对于定位任务,奖励基于预测输出与地面真值之间的交并比(IoU)。在计数任务中,我们采用类似于Qwen2.5-VL的范式,先检测点再计数。在这里,奖励来源于奖励匹配过程中计算的欧几里得距离。对于OCR,编辑距离作为主要奖励指标。最后,在目标检测中,我们结合了多种奖励:基于F1分数的对象数量奖励、使用IoU的位置奖励以及带有遗漏惩罚的二分类奖励。
采样设置。根据Kimi-1.5 [57],我们采用一种课程采样策略,从较简单的数据开始,逐步过渡到更具挑战性的示例。具体来说,对于目标检测任务,我们首先在COCO数据集上进行离线训练以计算奖励值。根据选定的奖励(例如数量奖励),我们相应地划分数据集。随着训练的进行,我们逐步用更具挑战性的样本(即与较低奖励相关的样本)替换数据,同时增加滚出次数以拓宽模型的探索空间。
| RefCOCO | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 方法 | 尺寸 | val 0.50_{0.50}0.50 | testA0.50\operatorname{testA}_{0.50}testA0.50 | testB 0.50_{0.50}0.50 | val 0.75_{0.75}0.75 | testA0.75\operatorname{testA}_{0.75}testA0.75 | testB0.75\operatorname{testB}_{0.75}testB0.75 | val 0.05_{0.05}0.05 | testA0.05\operatorname{testA}_{0.05}testA0.05 | testB 0.05_{0.05}0.05 | val big _{\text {big }}big | testA big _{\text {big }}big |
| MDETR [25] | - | 87.5 | 90.4 | 82.6 | - | - | - | - | - | - | - | - |
| OFA [62] | - | 88.4 | 90.6 | 83.3 | - | - | - | - | - | - | - | - |
| LLaVA-1.5 [35] | 7B | 49.1 | 54.9 | 43.3 | 10.7 | 13.6 | 6.9 | 0.4 | 0.3 | 0.3 | 20.1 | 22.9 |
| LLaVA-NeXT [36] | 7B | 82.5 | 88.4 | 74.0 | 45.7 | 54.8 | 35.6 | 1.9 | 2.6 | 0.7 | 43.4 | 48.6 |
| LLaVA-OV [28] | 7B | 73.0 | 82.3 | 63.5 | 24.2 | 29.6 | 15.9 | 0.5 | 0.5 | 0.5 | 32.6 | 37.5 |
| Qwen2-VL [61] | 2B | 86.8 | 89.6 | 82.0 | 77.2 | 80.6 | 70.1 | 33.0 | 35.7 | 26.9 | 65.7 | 68.6 |
| Perception-R1 | 2B | 89.1 | 91.4 | 84.5 | 79.5 | 83.6 | 72.4 | 35.0 | 38.5 | 28.8 | 67.9 | 71.2 |
| RefCOCO+ | ||||||||||||
| 方法 | 尺寸 | val 0.50_{0.50}0.50 | testA0.50\operatorname{testA}_{0.50}testA0.50 | testB 0.50_{0.50}0.50 | val 0.75_{0.75}0.75 | testA0.75\operatorname{testA}_{0.75}testA0.75 | testB0.75\operatorname{testB}_{0.75}testB0.75 | val 0.05_{0.05}0.05 | testA0.05\operatorname{testA}_{0.05}testA0.05 | testB 0.05_{0.05}0.05 | val big _{\text {big }}big | testA big _{\text {big }}big |
| MDETR [25] | - | 81.1 | 85.5 | 72.9 | - | - | - | - | - | - | - | - |
| OFA [62] | - | 81.3 | 87.1 | 74.2 | - | - | - | - | - | - | - | - |
| LLaVA-1.5 [35] | 7B | 42.4 | 49.7 | 36.4 | 9.8 | 12.4 | 6.4 | 0.5 | 0.5 | 0.2 | 17.6 | 20.8 |
| LLaVA-NeXT [36] | 7B | 74.5 | 84.0 | 64.7 | 41.5 | 51.8 | 30.0 | 1.9 | 2.7 | 1.0 | 39.3 | 46.2 |
| LLaVA-OV [28] | 7B | 65.8 | 79.0 | 57.2 | 23.6 | 28.8 | 15.3 | 0.6 | 0.6 | 0.4 | 30.0 | 36.1 |
| Qwen2-VL [61] | 2B | 77.1 | 82.5 | 70.1 | 68.7 | 73.8 | 60.0 | 29.4 | 32.3 | 23.0 | 58.4 | 62.9 |
| Perception-R1 | 2B | 81.7 | 86.8 | 74.3 | 73.6 | 79.3 | 64.2 | 32.6 | 36.9 | 26.7 | 62.6 | 67.7 |
| RefCOCOg | ||||||||||||
| 方法 | 尺寸 | val 0.50_{0.50}0.50 | test 0.50_{0.50}0.50 | val 0.75_{0.75}0.75 | test 0.75_{0.75}0.75 | val 0.05_{0.05}0.05 | test 0.05_{0.05}0.05 | val big _{\text {big }}big | test big _{\text {big }}big | |||
| MDETR [25] | - | 83.3 | 83.3 | - | - | - | - | - | - | |||
| OFA [62] | - | 82.2 | 82.3 | - | - | - | - | - | - | |||
| LLaVA-1.5 [35] | 7B | 43.2 | 45.1 | 8.5 | 9.3 | 0.3 | 0.3 | 17.3 | 18.2 | |||
| LLaVA-NeXT [36] | 7B | 77.5 | 77.1 | 40.7 | 39.9 | 1.8 | 1.7 | 40.0 | 39.6 | |||
| LLaVA-OV [28] | 7B | 70.8 | 70.8 | 23.3 | 23.6 | 0.6 | 0.7 | 31.6 | 31.7 | |||
| Qwen2-VL [61] | 2B | 83.3 | 83.1 | 72.7 | 73.0 | 28.9 | 27.9 | 61.6 | 61.3 | |||
| Perception-R1 | 2B | 85.7 | 85.4 | 75.7 | 76.0 | 32.1 | 33.1 | 64.5 | 64.8 |
表1:视觉定位基准评估。为了全面评估模型的定位能力,我们选择了指代表达理解(REC)基准,即RefCOCO [71]、RefCOCO+[71]和RefCOCOg[40]进行评估。专家模型以灰色标注。
| 编辑距离 ↓\downarrow↓ | F1分数 ↑\uparrow↑ | 精确率 ↑\uparrow↑ | 召回率 ↑\uparrow↑ | BLEU ↑\uparrow↑ | METEOR ↑\uparrow↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 尺寸 | 英语 | 中文 | 英语 | 中文 | 英语 | 中文 | 英语 | 中文 | 英语 | 中文 | 英语 | 中文 | |
| Nougat [4] | 250M | 25.5 | - | 74.5 | - | 72.0 | - | 80.9 | - | 66.5 | - | 76.1 | - |
| DocOw11.5 [23] | 7B | 25.8 | - | 86.2 | - | 83.5 | - | 96.2 | - | 78.8 | - | 85.8 | - |
| GOT [65] | 580M | 3.5 | 3.8 | 97.2 | 98.0 | 97.1 | 98.2 | 97.3 | 97.8 | 94.7 | 87.8 | 95.8 | 93.9 |
| Qwen2-VL [61] | 2B | 8.0 | 10.0 | 94.4 | 93.0 | 96.9 | 96.1 | 93.0 | 90.5 | 90.9 | 78.0 | 94.1 | 87.2 |
| LLaVA-NeXT [36] | 7B | 43.0 | - | 64.7 | - | 57.3 | - | 88.1 | - | 47.8 | - | 58.2 | - |
| Perception-R1 | 2B | 3.5 | 9.0 | 98.2 | 94.4 | 98.6 | 96.3 | 97.8 | 92.7 | 96.7 | 74.6 | 98.1 | 88.9 |
表2:PageOCR评估,与各种强大专家和通用模型比较。“en”表示英语,“zh”表示中文。
5 实验
实验部分评估了Perception-R1在视觉感知任务上的性能(§ 5.1),随后是分析实验,探讨强化学习(RL)在感知策略学习中的作用(§ 5.2)。最后,讨论了视觉感知与RL之间的相互作用,以及感知策略学习的关键见解(§5.3)。
5.1 感知任务中的性能景观
我们在主流感知任务上评估Perception-R1:视觉定位、计数、OCR和目标检测。实验使用了§ 4.3中描述的数据集和图像理解基准。结果见表1-4。详见附录A.2。
视觉定位是一项基于语言描述定位视觉对象的任务。具体来说,给定一个语言提示,模型需要输出提示中描述的主题(通常是单一实体)的空间坐标。如表1所示,我们评估了
| 方法 | 尺寸 | Pixmo val Pixmo max \begin{gathered} \text { Pixmo }_{\text {val }} \\ \text { Pixmo }_{\text {max }} \end{gathered} Pixmo val Pixmo max | 目标检测 | ||||||
| 方法 | 尺寸 | epoch | AP | ||||||
| LLaVA-1.5 [35] | 7B | 33.3 | 31.0 | ||||||
| LLaVA-1.6 [58] | 7B | 32.7 | 31.9 | ||||||
| LLaVA-OV [28] | 7B | 55.8 | 53.7 | ||||||
| Qwen2-VL [61] | 2B | 60.2 | 50.5 | ||||||
| Perception-R1 | 2B | 78.1 | 75.6 |
(a) 在Pixmo-Count [13]验证集和测试集上的视觉计数评估。
表3:主流视觉任务评估,包括(a)视觉对象计数和(b)具有挑战性的通用对象检测。值得注意的是,(b)中的专家模型结果是从MMDetection [7]复制的。† 表示用于目标检测的Perception-R1基于Qwen2.5-VL-3B-Instruct [3]构建。
| MMBench MMVer MMStar ScienceQA SeedBench | MME | LLaVA-Bench | A12D | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ilm | 平均 | 平均 | 平均 | 平均 | 平均 | 认知 感知 | 平均 | 平均 | ||
| LLaVA1.5 [35] | Vicuna1.5-7B | 62.8 | 32.8 | 32.6 | 65.4 | 60.1 | 302.1 | 1338.3 | 52.6 | 51.9 |
| LLaVA-NeXT [36] | Vicuna1.5-7B | 66.0 | 37.9 | 37.7 | 68.2 | 69.1 | 195.7 | 14 | ||
| 19.5 | 52.7 | 67.4 | ||||||||
| Qwen2-VL [61] | Qwen2-2B | 71.9\mathbf{7 1 . 9}71.9 | 45.6 | 46.3\mathbf{4 6 . 3}46.3 | \mathbf{7 4 . 0}$ | 72.7 | 418.5 | 1471.1 | 46.5 | 71.6 |
| Perception-R1 | Qwen2-2B | 71.8\mathbf{7 1 . 8}71.8 | 48.9\mathbf{4 8 . 9}48.9 | 45.7\mathbf{4 5 . 7}45.7 | 73.4\mathbf{7 3 . 4}73.4 | 73.0\mathbf{7 3 . 0}73.0 | 430.0\mathbf{4 3 0 . 0}430.0 | 1473.9\mathbf{1 4 7 3 . 9}1473.9 | 58.2\mathbf{5 8 . 2}58.2 | 71.8\mathbf{7 1 . 8}71.8 |
表4:通用图像理解和推理评估,与各种基线比较。我们选择了8个主流的多模态基准测试,即MMBench [38]、MMVet [72]、MMStar [9]、ScienceQA [53]、SeedBench [18]、MME [16]、LLaVA-Bench [37]和ai2D [26]进行综合理解。我们在计数任务后的RL训练模型上进行评估。
Perception-R1在三个主流基准测试refCOCO / + / g上进行了评估,并报告了Acc@0.5、Acc@0.75和Acc@0.95以全面评估其视觉定位能力。我们惊讶地发现,几个最先进的MLLM在更具挑战性的Acc@0.95指标上表现出较差的性能,得分甚至低于1%。相比之下,Perception-R1在该指标上实现了超过30%的稳定性能。这一观察结果表明,未来评估应优先报告更具区分度的结果。实验结果表明,Perception-R1相较于专用模型和通用模型表现出强大的竞争力。
光学字符识别(OCR)是视觉感知中的关键任务,因其具有巨大的实际价值。当前的方法主要采用专家模型或微调的通用模型进行OCR。Perception-R1开创性地利用RL进一步解锁MLLM的OCR能力。如表2所示,我们提出的Perception-R1在极具挑战性的OCR基准测试PageOCR [34]上取得了最先进的性能,显著优于现有的专家模型,例如GOT(98.1\mathbf{9 8 . 1}98.1 vs. 97.2\mathbf{9 7 . 2}97.2 F1分数)和稳健的通用模型,例如LLaVA-NeXT(98.1\mathbf{9 8 . 1}98.1 vs. 64.7\mathbf{6 4 . 7}64.7 F1分数)。值得注意的是,Perception-R1没有使用中文OCR数据进行训练,因此其在中文指标上的表现为零样本性能。这一突破证实了RL在OCR任务中的强大潜力,开辟了增强复杂视觉环境中文本理解和识别的新前沿。
视觉计数作为基本的视觉任务之一,要求模型准确量化图像中特定类别的实例,需要强大的视觉逻辑来通过结构化的识别模式识别和枚举目标。在Perception-R1中,我们采用了先检测后计数的范式,将计数问题重新表述为点检测过程。如表3a所示,Perception-R1在计数任务上表现出色,相比当前的强大基线有显著提升(17.9%\mathbf{1 7 . 9} \%17.9%改进相对于Qwen2-VL在Pixmo验证集上的表现)。这一进步证实了RL有效地刺激模型探索内在的视觉逻辑机制(尽管计数产生确定性结果,但计数顺序可以表现出不同的模式),从而增强了其解决复杂视觉任务的能力。
一般目标检测长期以来被认为是计算机视觉任务中的皇冠明珠,一直被视为视觉感知中最具挑战性的问题之一。作为将RL集成到目标检测中的开创性尝试,Perception-R1实现了一个里程碑式的突破,成为第一个纯MLLM超越30+ AP阈值的模型,即在COCO 2017验证集上达到31.9 AP,匹配甚至超过了专业专家模型的性能。这一成就突显了基于规则的RL在解决需要复杂视觉逻辑集成的复杂视觉任务方面的巨大潜力。
| 情况 | 视觉定位 | OCR PageOCR | 视觉计数 | 检测 | |||
|---|---|---|---|---|---|---|---|
| RefCOCO | RefCOCO+ | RefCOCOg | Psame val _{\text {val }}val | Psame test _{\text {test }}test | COCO2017 | ||
| Perception-R1 | 89.1 | 81.7 | 85.7 | 98.4 | 76.1 | 75.6 | 31.9 |
| w/o 奖励匹配 | - | - | - | - | 77.1 | 75.4 | 23.5 |
| w/o RL | 86.8 | 77.1 | 83.3 | 94.4 | 60.2 | 50.5 | 16.1 |
| w 思考 | 75.1 | 67.9 | 71.3 | 77.3 | 74.9 | 72.8 | 25.7 |
| w/o 思考 | 89.1 | 81.7 | 85.7 | 95.7 | 78.1 | 75.6 | 28.1 |
| 仅RL | 89.1 | 81.7 | 85.7 | 95.7 | 78.1 | 75.6 | 31.9 |
| 仅SFT | 88.2 | 80.7 | 84.6 | 95.3 | 58.0 | 59.9 | 25.9 |
| SFT+RL | 88.4 | 80.7 | 85.1 | 97.3 | 77.1 | 75.4 | 30.8 |
表5:Perception-R1的消融研究。我们进行消融研究以探讨Perception-R1在一系列视觉感知任务中的关键属性。具体来说,我们报告了RefCOCO / + / g验证集的Acc @ 0.5、PageOCR的F1分数、Pixmo-Count的平均分数以及COCO2017验证集的AP指标。w/o表示没有。值得注意的是,视觉定位和OCR任务不涉及多主体奖励,因此未应用奖励匹配。
| 奖励函数 | COCO2017 | ||
|---|---|---|---|
| AP | AP50\mathrm{AP}_{50}AP50 | AP75\mathrm{AP}_{75}AP75 | |
| 格式奖励 | |||
| 格式奖励 + 位置奖励 (IoU) | 18.8 | 25.3 | 20.1 |
| 格式奖励 + 位置奖励 (IoU) + 分类奖励 | 20.2 | 27.3 | 21.4 |
| 格式奖励 + 位置奖励 (IoU) + 分类奖励 + 召回奖励 (F1) | 27.6 | 42.0 | 28.7 |
| 格式奖励 + 位置奖励 (IoU) + 分类奖励 + 召回奖励 (F1) + 缺失奖励 | 28.1 | 42.0 | 29.6 |
表6:Perception-R1的奖励设计分析。cls奖励表示二分类奖励,缺失奖励是对遗漏检测的惩罚。为了便于快速实验,我们从COCO2017训练集中随机抽取了10k数据用于此实验。
通用视觉理解超出了纯粹的感知任务范围,我们在多个多模态基准测试中评估了PerceptionR1。如表4所示,我们观察到一个有趣的现象:在视觉特定任务(如计数任务)上经过RL训练的模型在通用理解基准测试中也表现出一致的性能提升。我们将这种跨任务增强归因于感知策略学习,它驱动模型发现更优的图像解释模式。
5.2 Perception-R1的消融研究
在本节中,我们旨在进行全面的消融研究,系统地探讨Perception-R1中关键组件的贡献。实验结果见表5。从实验结果中,我们可以得出三个主要的经验发现:
奖励匹配增强了多主体视觉感知的可探索性。如表5第1行和第2行的对比结果所示,用序列匹配替换二分图匹配会导致视觉计数和目标检测任务性能显著下降。这表明序列匹配限制了RL的探索空间。相反,二分图匹配机制提供了更多的奖励分配可能性,使模型能够探索最佳的视觉感知模式。
显式的思考过程对当代视觉感知并非必要。对比分析第3行和第4行显示,在所有四个评估的感知任务中,训练和推理阶段引入显式的思考过程都会导致一致的性能下降。类似的现象也出现在图像分类任务中[30]。我们认为这种现象的发生是因为当前的视觉感知任务更多地倾向于视觉逻辑而非语义逻辑。这种转变意味着显式的语言中心推理过程是不必要的,因为模型往往更专注于学习隐式的视觉模式。
感知困惑度决定了RL相对于SFT的优势。我们在四个感知任务中比较了不同的后训练方法组合,即SFT、RL和SFT+RL,如表5的第6、7、8行所示。在高感知困惑度的任务中,如计数和检测(涉及多个对象和类别),RL表现出比SFT或甚至SFT+RL更显著的性能提升。相反,在低困惑度的任务中,如定位和OCR,RL的表现不如SFT或SFT+RL。这表明高感知困惑度是影响RL有效性的重要因素。它表明,RL技术应应用于具有更大感知策略探索空间的任务。
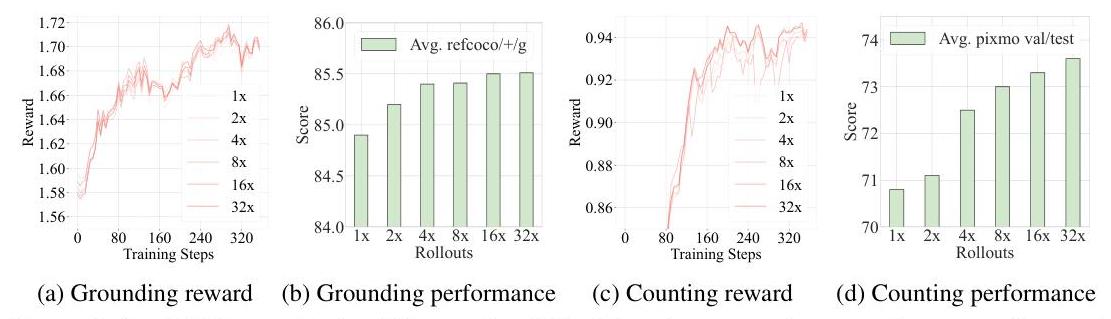
图2:Perception-R1的可扩展性分析。我们选择了两个主要任务:定位和计数。我们可视化了不同滚出次数下的训练奖励曲线,并评估了每个任务的最终性能。所有实验均使用5k采样数据进行。默认滚出次数设置(1×)(1 \times)(1×)为8。
5.3 更深入的分析
在本节中,我们探讨了Perception-R1的几个关键属性,以进一步增强我们对RL感知策略学习的理解。
感知策略学习的奖励设计分析。我们在§ 4.3中介绍了Perception-R1的奖励函数细节。在此部分中,我们考察这些奖励函数对感知策略学习的影响。具体来说,以目标检测为例,我们逐步将设计的答案奖励整合到格式奖励中,如表6所示。结果表明,逐步引入精细的奖励函数能带来持续的检测性能提升,最终超越专家模型的性能。这凸显了奖励设计在感知策略学习中的关键作用。此外,它指出了未来研究的一个有前途的方向:开发更精细和任务特定的奖励函数以增强感知策略学习。
感知策略学习中滚出规模的分析。RL的可扩展性是现有LLM后训练的关键关注点。在此部分中,我们分析了Perception-R1的可扩展性,重点关注滚出次数的增加。如图2所示,我们在两个任务中进行了滚出规模实验:视觉定位和视觉计数。结果表明,增加滚出次数能增强奖励优化和最终性能。这展示了Perception-R1的强大扩展特性,并强调了滚出数量在扩展感知策略中的关键作用。通过生成足够的滚出次数,模型扩大了其探索空间,增加了候选解决方案的多样性以供奖励评估。这种扩展加速了收敛到最佳视觉感知模式的过程。
6 局限性和结论
“RL能为MLLM带来什么?”自从DeepSeek-R1提出以来,这是一个公开的问题。一些最新的工作试图从以语言为中心的视觉推理角度应用RL[39, 15, 41]。然而,在本文中,我们采取了一条不同的路径,并认为感知是视觉推理的关键前提。只有充分释放MLLMs的感知模式,模型才能具备处理复杂视觉任务的推理能力。然而,遗憾的是,我们发现许多当前的感知任务过于简单,这限制了RL的探索空间。反过来,这也限制了MLLMs通过思考过程实现感知“顿悟”的可能性。寻找更合适的感知任务,即元任务,可能是解决这一问题的关键。
总结而言,这项工作迈出了探索在MLLM后训练中基于规则的RL在感知策略学习潜力的第一步。通过广泛的实验分析,我们建立了关于使用RL进行感知策略学习的若干有价值的认知。受这些发现的驱动,我们构建了Perception-R1,这是一种简单、有效且可扩展的RL框架,用于高效的感知策略学习。Perception-R1在多个视觉感知任务上设立了新的最先进水平,特别是在目标检测任务中。通过引入一种新范式,它实现了甚至超越了专家模型的性能,从而展示了感知策略学习的重大潜力。
参考文献
[1] 白金泽、白帅、褚云飞、崔泽宇、当凯、邓晓东、范阳、葛文斌、韩雨、黄飞等。通义千问技术报告。arXiv预印本arXiv:2309.16609, 2023.
[2] 白金泽、白帅、杨树生、王世杰、谭思南、王世杰、董小东、林俊阳、周昌、周景仁。通义千问VL:前沿大型视觉语言模型,具有多功能能力。arXiv预印本arXiv:2308.12966, 2023.
[3] 白帅、陈克勤、刘雪婧、王佳琳、葛文斌、宋斯波、当凯、王鹏、王世杰、唐军等。通义千问2.5-VL技术报告。arXiv预印本arXiv:2502.13923, 2025.
[4] Blecher卢卡斯、Cucurull吉列姆、Scialom托马斯、Stojnic罗伯特。Nougat:神经光学理解学术文档。arXiv预印本arXiv:2308.13418, 2023.
[5] Brohan安东尼、Brown诺亚、Carbajal贾斯汀、Chebotar叶夫根尼、陈曦、Choromanski克日什托夫、丁天丽、Driess丹尼、Dubey阿维纳瓦、Finn切尔西等。RT-2:视觉-语言-动作模型将网络知识转移到机器人控制。arXiv预印本arXiv:2307.15818, 2023.
[6] Carion尼古拉斯、Massa弗朗西斯科、Synnaeve加布里埃尔、Usunier尼古拉斯、Kirillov亚历山大、Zagoruyko谢尔盖。端到端使用变压器的目标检测。欧洲计算机视觉会议论文集,2020年,第213-229页。Springer出版社,2020.
[7] 陈开、王嘉琪、庞江淼、曹宇航、熊宇、李晓晓、孙书阳、冯万森、刘子微、许家瑞、张正、程天恒、朱晨晨、李买玉、陆欣、朱瑞、吴越、戴景东、施建平、欧阳婉丽、李忠诚、林大华。MMDetection:开放的MMLab检测工具箱和基准。arXiv预印本arXiv:1906.07155, 2019.
[8] 陈亮、李磊、赵浩哲、宋一帆、Vinci。R1-v:通过少于$3的视觉语言模型强化超泛化能力。https://github.com/Deep-Agent/ R1-V, 2025.
[9] 陈林、李金松、董晓仪、张盘、藏禹航、陈泽辉、段浩东、王佳琦、乔宇、林大华等。我们是否在正确评估大型视觉语言模型?arXiv预印本arXiv:2403.20330, 2024.
[10] 穿天哲、翟跃祥、杨继松、童盛邦、谢赛宁、舒尔曼戴尔、Le Quoc V、Levine Sergey、Ma Yi。SFT记忆,RL泛化:基础模型后训练的比较研究。arXiv预印本arXiv:2501.17161, 2025.
[11] 戴文良、李俊楠、李冬旭、Tony Meng Huat Tiong、赵军琦、王伟胜、李博洋、冯帕斯卡·N、Hoi Steven。InstructBLIP:通过指令调整实现通用视觉语言模型。神经信息处理系统进展,36卷,2024.
[12] DeepSeek-AI、郭黛雅、杨德健、张浩威、宋俊晓、张若宇、徐润鑫、朱启豪、马士荣、王培伊、毕晓、张晓康、余星凯、吴雨、吴志峰、苟智斌、邵志宏、李爱新、刘冰雪、王炳轩、吴博超、冯贝、鲁达迈、陈德利、季东杰、李方云、戴福聪、罗富立、郝光博、陈冠庭、李海东、许汉伟、吴宝涵、王浩成、丁洪辉、辛华剑、高华佐、屈慧、李慧、郭建忠、李佳仕、王纪旺、陈京昌、袁静阳、邱、赵成刚、曾望丁、梁文峰、高文琴、张武、张彭、王倩诚、陈秦羽、杜秋实、葛锐祺、张瑞松、潘睿哲、王荣基、陈荣杰、陈如意、卢尚昊、周尚言、陈珊皇、叶盛锋、王世宇、余水萍、周顺风、潘淑婷、李双硕、吴绍清、叶盛锋、周双、张明川、张明桦、唐明辉、李梦、王苗军、李明明、田宁、黄盼盼、张鹏、王青城、王明成、张琴颖、杜齐石、葛蕊琪、潘子政、王俊杰、陈如怡、金、刘晓东、陈小寒、陈晓康、聂晓涛、程欣、刘欣、谢欣、刘兴超、李心远、苏学成、林旭恒、李心泉、晋向月、金相岳、王英权、韦玉祥、张阳、徐燕红、李耀辉、王瑶辉、张亚、王尧辉、俞一、张义超、石一凡、熊易良、何颖、漂义爽、王义松、谭义轩、王要丰、刘亿源、郭永强、欧元、王玉段、龚悦、邹雨衡、周裕恒、刘玉阳、周玉阳、朱玉祥、徐严红、黄燕平、李耀辉、李瑶辉、郑义、余玉辰、马云贤、唐英、查玉坤、周玉婷、任泽辉、任泽辉、沙章力、傅哲、许则安、谢振达、张正言、张志城、王天佩、孙天宇、王、曾望丁、赵万佳、刘文、梁文峰、高文琴、余文群、张文韬、肖文龙、安伟、刘晓东、刘霞、王栋、王万佳、刘温、李文、李文君、李文琴、李心成、刘新、谢新、刘心远、苏学城、林旭恒、李心泉、晋相岳、王小娇、王万佳、宋现祖、赵文、刘文兵、刘文群、张文俊、张文琴、王文凯、李文、李文成、李文城、晋相岳、金香月、王英权、韦玉祥、张阳、徐燕红、李耀辉、王瑶辉、张亚、王尧辉、俞一、张义超、石一凡、熊易良、何颖、漂义爽、王义松、谭义轩、王要丰、刘亿源、郭永强、欧元、王玉段、龚悦、邹雨衡、周裕恒、刘玉阳、周玉阳、朱玉祥、徐严红、黄燕平、李瑶辉、郑义、余玉辰、马云贤、唐英、查玉坤、周玉婷、任泽辉、任泽辉、沙章力、傅哲、许则安、谢振达、张正言、张志城、王天佩、孙天宇、王、曾望丁、赵万佳、刘文、梁文峰、高文琴、余文群、张文韬、肖文龙、安伟、
参考论文:https://arxiv.org/pdf/2504.07954

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)