TREC 2024 RAG 赛道支持评估:人类评审员与大语言模型评审员的对比
检索增强生成(RAG)使大型语言模型(LLMs)能够通过引用包含“事实依据”的源文档生成带有引用的回答,从而减少系统幻觉。RAG评估中的一个关键因素是“支持”——即引用文档中的信息是否支持回答。为此,我们对提交给TREC 2024 RAG赛道的45个参赛作品进行了大规模对比研究,涉及36个主题,比较了自动的大语言模型评审员(GPT-4o)与人类评审员在支持评估方面的表现。我们考虑了两种条件:(1)
Nandan Thakur 1{ }^{1}1, Ronak Pradeep 1{ }^{1}1, Shivani Upadhyay 1{ }^{1}1, Daniel Campos 2{ }^{2}2, Nick Craswell 3{ }^{3}3, Jimmy Lin 1{ }^{1}1
1{ }^{1}1 滑铁卢大学 2{ }^{2}2 Snowflake 3{ }^{3}3 微软
https://trec-rag.github.io
摘要
检索增强生成(RAG)使大型语言模型(LLMs)能够通过引用包含“事实依据”的源文档生成带有引用的回答,从而减少系统幻觉。RAG评估中的一个关键因素是“支持”——即引用文档中的信息是否支持回答。为此,我们对提交给TREC 2024 RAG赛道的45个参赛作品进行了大规模对比研究,涉及36个主题,比较了自动的大语言模型评审员(GPT-4o)与人类评审员在支持评估方面的表现。我们考虑了两种条件:(1)完全手动从零开始评估和(2)带后编辑的手动评估(基于大语言模型预测结果)。我们的结果显示,在56%的手动从零开始评估中,人类和GPT-4o的预测结果完全一致(基于三级评分标准),而在带后编辑的手动评估条件下,这一比例增加到72%。此外,通过对分歧进行无偏分析,我们发现独立的人类评审员与GPT-4o的相关性比与人类评审员更高,这表明大语言模型可以作为支持评估的可靠替代方案。最后,我们提供了人类和GPT-4o错误的定性分析,以指导未来支持评估的迭代。
1 引言
检索增强生成(RAG)最近在学术界和工业界都获得了广泛关注(例如,Bing搜索引擎 [19] 和流行的框架如LangChain [4])。在RAG中,大型语言模型(LLMs)生成对用户查询的回答时会引用必要的源文档 [11,16,12,3]。RAG系统提高了事实性和可验证性,减少了在“闭书”LLM生成中观察到的幻觉现象 [14, 16, 10, 18]。
在LLM生成答案中用于支持事实的文档级引用是任何部署的RAG系统的核心部分。因此,支持评估旨在评估RAG答案是否在事实上支持引用文档中的信息,这对于评估RAG系统的质量至关重要。关于RAG文献中的支持评估的先前工作 [17, 5, 26, 9, 29, 31, 25] 依赖于自动评审员,即使用LLM作为代理评审员。然而,尚不清楚LLM评审员是否可以潜在地取代人类评审员进行支持评估。
本文分析了来自TREC 2024 RAG赛道的结果,评估了针对36个信息查询的45个参赛系统。表1展示了一个示例查询及其回答。我们利用国家技术标准研究所(NIST)提供的资源,对人类和LLM评审员进行了大规模对比研究,以更好地理解支持评估是否可以自动化。TREC设置的独特之处在于,我们使用强大的LLM评审员(如GPT-4o)进行自动判断过程,并将其与两种条件下的手动过程进行对比:(1)手动从零开始,
主题:泰勒·斯威夫特的年龄如何影响她的关系
回答:泰勒·斯威夫特的年龄显著影响了她的关系,常常对她的恋爱动态和结果产生贡献 []。斯威夫特的关系经常涉及显著的年龄差距,有时导致复杂情况 []。例如,她与约翰·梅尔的关系因年龄差异和梅尔作为花花公子的声誉而紧张,导致斯威夫特感到被利用 [B, 3, 4]。这段关系启发了她的歌曲《亲爱的约翰》,反映了她的情感困扰 [3,4]。同样,斯威夫特与杰克·吉伦哈尔的关系也突显了年龄差异的影响。据报道,吉伦哈尔感受到了年龄差距,而斯威夫特的缺乏经验使得她难以处理关系的复杂性,导致心碎并启发了她《红》专辑中的多首歌曲 [B, 1, 2] […] 总之,泰勒·斯威夫特的年龄在塑造她的关系方面发挥了关键作用,影响了关系的动态和结果 [8, 1]。年龄差异通常导致复杂情况,而与同龄人的关系则相对简单。随着时间的推移,她的成熟让她能够以更大的理解和韧性应对浪漫复杂性。 []
段落 [3]: 泰勒·斯威夫特不恰当恋爱的时间轴 | 商业内幕 […] 泰勒·斯威夫特,21岁,与约翰·梅尔,32岁。斯威夫特约会习惯的不适当性在她开始与比她年长11岁且臭名昭著的花花公子约翰·梅尔交往时达到了顶峰。双方均未确认这段恋情,但据称他们在2010年2月期间有过一段恋情 […]
段落 [8]: 杰克·吉伦哈尔与泰勒·斯威夫特之间到底出了什么问题? […] 泰勒·斯威夫特和杰克·吉伦哈尔从2010年10月到12月有过一段恋情。 […] 这两个“双火星座”之间到底出了什么问题?结果证明,问题很多。也许这就是为什么这对他来说现在是个敏感话题!当时他们约会时,吉伦哈尔29岁,斯威夫特20岁;分手时,他已经30岁,她21岁。“他说他能感觉到年龄差异”,一位消息人士告诉《Us Weekly》 […]
表1:一个关于泰勒·斯威夫特的查询样本RAG回答,分为多个句子,并引用了从MS MARCO V2.1段集合中检索到的段落。我们突出显示了引用的段落,这些段落以列表形式提供(可以为空,即零引用)。
其中人类注释者从零开始进行评估,以及(2)带后编辑的手动评估,其中人类注释者在评估过程中可以看到GPT-4o的预测结果。
在本文中,我们专注于支持,即回答句子中的信息是否由引用的文档支持,我们将这些文档视为“事实依据”。当然,这只是RAG评估的一个方面。对于TREC 2024 RAG赛道其他方面的深入分析,我们建议读者参考Upadhyay等人 [28] 的相关性评估和Pradeep等人 [23] 的片段评估。
我们的实验结果显示,在手动从零开始的条件下,GPT-4o和人类判断完全匹配的比例为56%,在带后编辑的手动条件下增加到72%。这些结果表明,在两种条件下使用LLM评审员进行支持评估具有前景。我们通过两个指标衡量系统整体回答的支持度:加权精确度和加权召回率,其中精确度惩罚过度引用,召回率惩罚引用不足。我们在运行级别上观察到GPT-4o和人类评审员之间的高相关性(超过0.79 Kendall τ\tauτ),这为LLM可以潜在取代人类评审员进行支持评估提供了证据。
此外,为了更好地理解GPT-4o和人类评审员之间的差异,我们进行了一项无偏分歧研究,邀请一名独立的人类评审员仔细重新评估537个随机抽样的配对,包括两种评估条件。我们的结果显示,独立评审员与GPT-4o的一致性高于与人类评审员的一致性(例如,Cohen’s κ\kappaκ 分别为0.27 vs. 0.07)。最后,我们讨论了标注错误,以帮助改进未来的支持评估迭代。
2 背景及相关工作
我们所指的支持评估是指确定RAG回答中的信息是否在事实上由其引用的文档支持。在我们的工作中,我们在回答的句子级别评估支持。假设回答rrr被分割成nnn个句子,r={a1,⋯ ,an}r=\left\{a_{1}, \cdots, a_{n}\right\}r={a1,⋯,an},每个回答句子aia_{i}ai最多可以包含mmm个文档引用,ai={di,⋯ ,dm}a_{i}=\left\{d_{i}, \cdots, d_{m}\right\}ai={di,⋯,dm},
回答句子:例如,她与约翰·梅尔的关系因年龄差异和梅尔作为花花公子的声誉而紧张,导致斯威夫特感到被利用。
段落ID [0]: doc_04_1081579649#7_2253255175 标题:泰勒·斯威夫特恋爱的时间轴
文本:2009年:泰勒·斯威夫特,20岁,与泰勒·劳特纳 […] 2010年:泰勒·斯威夫特,21岁,与约翰·梅尔,32岁/12岁。随后,斯威夫特约会习惯的不适当性达到顶峰,当时她开始与比她年长11岁且臭名昭著的花花公子约翰·梅尔交往。
人类评审员:部分支持
GPT-4o评审员:部分支持
回答句子:这段关系启发了她的歌曲《亲爱的约翰》,反映了她的情感困扰。
段落ID [3]: doc_35_202251892#8_427548986 标题:泰勒·斯威夫特不恰当恋爱的时间轴 | 商业内幕
文本:[…] 2010年:泰勒·斯威夫特,21岁,与约翰·梅尔,32岁/12岁。随后,斯威夫特约会习惯的不适当性达到顶峰 […] 随后,伤心欲绝的年轻斯威夫特发表了关于分手的歌曲《亲爱的约翰》。今年早些时候,梅尔承认当他听到这首歌时感到“羞辱”,但斯威夫特拒绝承认这是关于他的歌,告诉《魅力》杂志这是“臆测”。
人类评审员:完全支持
GPT-4o评审员:完全支持
回答句子:年龄差异是他们分手的重要因素,吉伦哈尔没有准备好承诺,进一步加剧了斯威夫特的情感痛苦。相比之下,斯威夫特与同龄人如乔·乔纳斯的关系较少面临此类问题。
段落ID [8]: doc_48_737500982#1_1325021022 标题:杰克·吉伦哈尔与泰勒·斯威夫特之间到底出了什么问题?
文本:泰勒·斯威夫特和杰克·吉伦哈尔从2010年10月到12月有过一段恋情。 […] “他说他能感觉到年龄差异”,一位消息人士告诉《Us Weekly》。 […] “当杰克伤了她的心时,她太缺乏经验以至于不知道如何应对……她不习惯所有的心理游戏和谎言,但现在她已经不再那么天真。”
人类评审员:完全支持
GPT-4o评审员:部分支持
回答句子:随着她逐渐成熟,她对关系的理解发生了变化,使她变得不那么天真,并在浪漫选择上更加明智。
段落ID [8]: doc_48_737500982#1_1325021022 标题:杰克·吉伦哈尔与泰勒·斯威夫特之间到底出了什么问题?
文本:泰勒·斯威夫特和杰克·吉伦哈尔从2010年10月到12月有过一段恋情。 […] “他说他能感觉到年龄差异”,一位消息人士告诉《Us Weekly》。 […] “当杰克伤了她的心时,她太缺乏经验以至于不知道如何应对。她不习惯所有的心理游戏和谎言,但现在她已经不再那么天真。”
人类评审员:无支持
GPT-4o评审员:部分支持
表2:泰勒·斯威夫特主题“泰勒·斯威夫特的年龄如何影响她的关系”的支持评估示例,其中GPT-4o和人类评审员分别进行评估。支持回答句子的段落片段已突出显示。
每篇文档都是从语料库中抽取的。1{ }^{1}1 支持计算为函数f(ai,dj)=f\left(a_{i}, d_{j}\right)=f(ai,dj)= si,js_{i, j}si,j,其中fff可以是人类或LLM评审员,生成标量值si,js_{i, j}si,j,表示引用文档djd_{j}dj对句子aia_{i}ai的支持程度。表2展示了几个支持评估的例子。除了RAG,文献中主要探索了摘要[15,13]和自然语言解释[2,27]中的支持。
之前关于RAG中支持评估的工作使用了不同的自动评审员:例子包括自然语言推理(NLI)模型[10]、带提示的LLM[9],甚至是微调的自定义LLM[26]作为自动评审员。吴等人[29]评估了LLM在其内部先验支持错误上下文信息之间的拉锯战。类似于我们的公式,明等人[20]提供了一个评估基准,其中包括经过人工验证的学术问答(QA)数据集,而刘等人[17]则使用众包人类评审员评估专有搜索引擎输出的质量。相比之下,我们的工作是首次进行大规模人工标注研究之一——涵盖了36个非事实性、分解性和多视角查询的多个RAG系统中的11 K个人工评估。这项研究设计为比较人类和GPT-4o评审员在支持评估方面提供了丰富的背景。
3 赛道描述与评估方法
3.1 TREC 2024 RAG赛道
文本检索会议(TREC)在信息检索(IR)、自然语言处理(NLP)及更广泛的领域内推动了许多方面的评估,加速了研究进展,
1{ }^{1}1 符合领域内的术语,我们泛指文档,尽管实际上“文档”可能是段落(如我们的情况)、PDF甚至图像。
社区(包括研究人员和从业者)。每年,TREC都会组织多个赛道,涵盖从文本或多模态检索[6,7,30]到对话式问答[1]的主题。
本工作的背景是TREC 2024 RAG赛道,该赛道分为三个任务:检索(R)、增强生成(AG)和检索增强生成(RAG)。在这里,我们关注生成部分,即参赛系统接收查询(在TREC术语中称为主题)和候选段落。这些候选段落要么由我们(即赛道组织者)生成并与所有参与者共享[22](AG任务),要么每个参与者可以直接从MS MARCO V2.1段集合中检索(端到端RAG任务)。候选段落为最终自由格式答案的合成提供了上下文或依据。我们要求答案被分割成句子,并且每个句子都要引用语料库中的段落,如表1所示。由于许多团队参与了TREC 2024 RAG赛道,我们的人类和LLM评审员在支持评估中接触到了多个答案和引用文档。
段落集合。MS MARCO V2.1段集合包含113,520,750个文本段落,这些段落是从去重版本的MS MARCO V2文档集合[6]中提取的,使用局部敏感哈希(LSH)结合MinHash和9-gram shingles去除近似重复文档。这将原始文档数量从11,959,63511,959,63511,959,635减少到10,960,55510,960,55510,960,555个文档。段落通过滑动窗口分块技术从相应的文档集合中生成,具体使用10句窗口和5句步幅,生成通常在500-1000字符之间的段落。每个段落包含一个标题字段(段落标题)和一个文本字段(段落正文)。
主题集合。对于TREC 2024 RAG赛道主题(查询),我们利用了Bing搜索日志的新鲜抓取,这些查询是非事实性的、多面的和主观的,需要RAG系统提供长篇答案[22, 24]。我们在评估提交期附近收集主题(大约2024年7月),以避免陈旧性和最小化潜在的数据泄露。由于预算限制,我们仅使用从完整TREC 2024 RAG赛道主题集合中选出的36个主题进行评估。
3.2 支持评估
与之前的RAG支持评估[17, 10]一致,我们使用三级评分,每个支持水平都有以下关联描述:
FS 完全支持:回答句子中的所有信息在事实上与引用段落一致并得到支持。
PS 部分支持:回答句子中的部分信息在事实上与引用段落一致并得到支持,但句子的其他部分未得到支持。
NS 无支持:引用段落完全无关,并不支持回答句子的任何部分。
特殊情况是没有引用的句子:我们自动认为支持评估为“无支持”,因为句子未引用任何检索到的段落。
接下来,为了对比LLM评审员与人类评审员的表现,我们在两种条件下进行了支持评估:(1)手动从零开始和(2)带后编辑的手动评估。以下是这两种条件的详细描述:
- 手动从零开始。在这种条件下,人类评审员会被提供回答句子和引用段落。评审员仔细阅读两者并评估回答句子是否得到引用段落的支持(根据上述标签之一)。
-
- 带后编辑的手动评估。在这种条件下,人类评审员会被提供回答句子、引用段落以及LLM评审员给出的支持判断标签。评审员仔细阅读句子和段落,并使用LLM判断标签作为参考提供评估。
- 在本任务中,您将评估每个陈述是否由其对应的引用支持。请注意,系统响应可能看起来非常流畅且结构良好,但可能存在不易察觉的细微不准确性。请密切注意文本。
您将获得一个陈述及其对应的段落引用。可以问自己,是否准确地说“根据引用…”后面跟着这句话。请确保检查陈述中的所有信息。您会有三个选项:
- 完全支持:陈述中的所有信息在引用中得到支持。
-
- 部分支持:陈述中的部分内容在引用中得到支持,但其他部分缺失。
-
- 无支持:引用不支持陈述中的任何部分。
请根据引用中的信息提供您的回答。如果不确定,请尽量做出最佳判断。请回答“完全支持”、“部分支持”或“无支持”,不要添加额外信息。
陈述:{\{{ 陈述 }\}}
引用:{\{{ 引用 }\}}
- 无支持:引用不支持陈述中的任何部分。
图1:GPT-4o评审员用于支持评估的提示。
对于自动标注,我们使用GPT-4o作为自动评审员。我们通过Microsoft Azure API [21]运行推理,每次在一个提示中提供一个段落,使用回答句子和引用段落。GPT-4o评审员会收到每个句子及其引用段落,并被要求确定支持标签而不做任何解释(完全支持、部分支持或无支持)。使用的提示见图1。
3.3 计算成本与评估权衡
在TREC 2024 RAG赛道中,我们允许参与者为每个回答句子提供最多20个段落的引用。为了评估每个句子及其引用段落,我们的协议要求人类评审员阅读回答句子和相对较长的文本段落(通常为500-1000字符)。因此,鉴于我们的预算限制,对每个回答句子的所有引用段落进行全面评估是不可行的。
因此,我们必须在稀疏注释和密集注释之间做出选择。密集注释将提供较少的被评估主题,但每个回答句子都会针对kkk个引用段落进行评估。另一方面,稀疏注释将提供更高的主题多样性,但代价是对每个回答句子评估较少的引用段落。
我们选择了稀疏注释以实现更多被评估主题。我们固定人类和GPT-4o评审员只评估所有参与者每个回答句子的第一个引用段落。与所有TREC评估一样,NIST根据赛道组织者(即我们)的指导提供资源进行人类评估。NIST首先培训每位人类评审员理解任务,然后每位人类评审员按顺序评估每个主题。
3.4 支持评估指标
支持可以在两个维度上进行评估,类似于Liu等人[17]:(1)加权精确度,衡量生成回答中正确段落引用的比例;(2)加权召回率,衡量回答中由段落引用支持的句子比例。以下是两个指标的定义:
加权精确度。该指标衡量支持每个回答句子的引用比例的加权值。我们将s(ai,dj)s\left(a_{i}, d_{j}\right)s(ai,dj)的权重分配为完全支持(FS)1.0,部分支持(PS)0.5,无支持(NS)0。为了清楚解释该指标,假设一个RAG回答包含3个句子={a1,a2,a3}=\left\{a_{1}, a_{2}, a_{3}\right\}={a1,a2,a3},以及一个语料库CCC包含2个段落:
2{ }^{2}2 我们还尝试了一次提供多个引用段落,但据我们观察,逐个提供段落与GPT-4o评审员配合效果更好。
| 条件 | 主题数 | 注释数 | 支持水平 | |||
|---|---|---|---|---|---|---|
| FS | PS | NS | ||||
| (1a) | 手动从零开始(人类) | 22 | 6,742 | 2,752 | 1,652 | 2,338 |
| (1b) | 自动(GPT-4o) | 22 | 6,742 | 3,110 | 2,421 | 1,211 |
| (2a) | 带后编辑的手动(人类) | 14 | 4,165 | 1,812 | 1,076 | 1,277 |
| (2b) | 自动(GPT-4o) | 14 | 4,165 | 2,045 | 1,330 | 790 |
表3:描述统计,支持判断为(1)手动从零开始条件和(2)带后编辑的手动条件,针对45个参赛作品在36个主题上的表现。
{p1,p2}\left\{p_{1}, p_{2}\right\}{p1,p2}。现在,假设段落p1p_{1}p1部分支持a1a_{1}a1,段落p2p_{2}p2完全支持a2a_{2}a2,而a3a_{3}a3没有引用。我们计算加权精确度如下:
加权精确度 =s(a1,p1)+s(a2,p2)count({a1,p1},{a2,p2})=0.5+12=0.75 \text { 加权精确度 }=\frac{s\left(a_{1}, p_{1}\right)+s\left(a_{2}, p_{2}\right)}{\operatorname{count}\left(\left\{a_{1}, p_{1}\right\},\left\{a_{2}, p_{2}\right\}\right)}=\frac{0.5+1}{2}=0.75 加权精确度 =count({a1,p1},{a2,p2})s(a1,p1)+s(a2,p2)=20.5+1=0.75
加权召回率。此指标衡量由引用段落支持的回答句子的加权比例。我们赋予与加权精确度相同的权重。以上述示例为例,我们计算加权召回率如下:
加权召回率 =s(a1,p1)+s(a2,p2)count({a1,a2,a3})=0.5+13=0.5 \text { 加权召回率 }=\frac{s\left(a_{1}, p_{1}\right)+s\left(a_{2}, p_{2}\right)}{\operatorname{count}\left(\left\{a_{1}, a_{2}, a_{3}\right\}\right)}=\frac{0.5+1}{3}=0.5 加权召回率 =count({a1,a2,a3})s(a1,p1)+s(a2,p2)=30.5+1=0.5
精确度惩罚回答文本中的过度引用,这通常是分散注意力且不必要的。另一方面,召回率惩罚引用不足的回答,即没有引用的句子。因此,如果一个句子没有引用,则会降低召回分数,但保持精确度不变。如上所述,我们仅评估每个回答句子的第一个引用段落的支持情况。因此,如果所有回答句子至少有一个引用,则加权召回率和精确度分数相同。我们留待未来工作探讨如何最好地评估回答中每个句子的多个段落引用,因为这需要更大的注释预算。
4 实验结果
对于TREC 2024 RAG赛道,NIST收到了来自20个组的93次运行记录(端到端RAG任务)和来自11个组的53次运行记录(AG任务)。鉴于资源限制,我们仅评估了每个组在RAG和AG任务中提交的两个最高优先级的作品。如表3所示,这相当于RAG部分来自18个组的31次运行记录和AG部分来自9个组的14次运行记录,总共每个主题最多45个参赛作品。人类评审员完成了对36个主题的判断,稀疏标注:在手动从零开始条件下对22个主题进行了6,742次标注,在带后编辑的手动条件下对14个主题进行了4,165次标注。
4.1 加权精确度和召回率
表5和表6分别展示了人类和GPT-4o评审员在22个主题上评估的AG和RAG任务中所有参赛作品的平均加权精确度和召回率分数。表7和表8分别展示了人类和GPT-4o评审员在14个主题上评估的AG和RAG任务中所有参赛作品的平均加权精确度和召回率分数。我们按照平均加权精确度分数降序排列这些运行记录。
在图2中,我们展示了所有参赛作品获得的加权精确度和召回率分数的散点图。运行级别的分数(用×\times× 表示)在GPT-4o和人类标注之间显示出强相关性(所有Kendall’s τ\tauτ 均超过0.79)。每个主题的平均值(用△\triangle△ 表示)在两个轴上有所不同,某些主题在GPT-4o上比人类获得更高的加权精确度和召回率分数,反之亦然。个别参赛者的分数(用◯\bigcirc◯ 或 □\square□ 表示)在加权精确度和召回率分数上显示出高度变异。这很可能是由于人类注释者倾向于选择“无支持”,而GPT-4o更倾向于选择“部分支持”。总体而言,我们观察到大多数分数集中在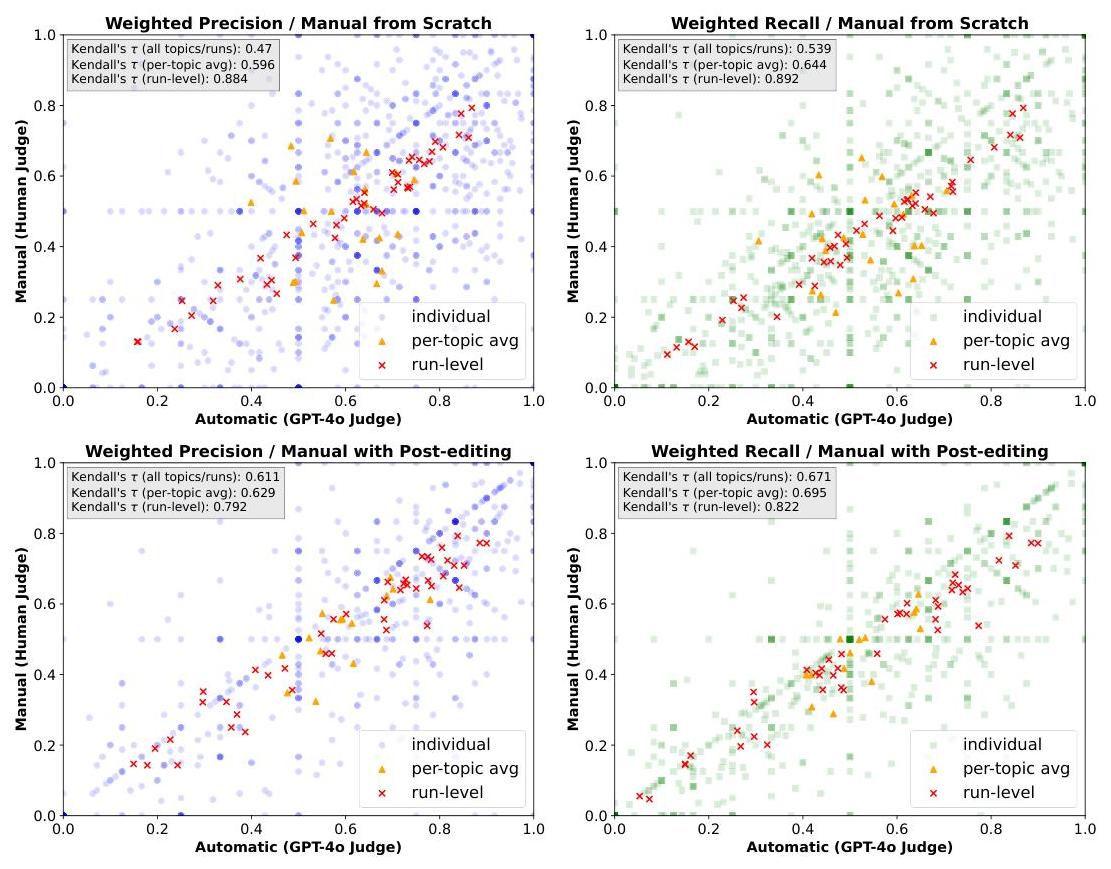
图2:人类和GPT-4o评审员在手动从零开始条件(顶部)和带后编辑的手动条件(底部)下得分的相关性,测量加权精确度和召回率。红色标记表示运行级别得分,黄色三角形表示每个主题的平均值,蓝色点或绿色框表示所有单个主题/运行组合。每个图表都标注了等级相关性,显示Kendall’s τ\tauτ。
右下三角区域,表明人类评审员采取更为保守的态度,整体提供的支持水平低于GPT-4o,导致较低的加权精确度和召回率分数。
4.2 混淆矩阵
接下来,为了更好地理解GPT-4o评审员与人类评审员的一致性,我们在图3中绘制了混淆矩阵。我们在两种条件下比较了人类评审员与GPT-4o的预测结果:手动从零开始和带后编辑的手动条件。
手动从零开始条件。对于56%(13.7%+11.9%+30.4%)56 \%(13.7 \%+11.9 \%+30.4 \%)56%(13.7%+11.9%+30.4%),GPT-4o和人类评审员在22个主题的支持判断上完全一致。无论是“完全支持”还是“无支持”类别,百分比都较高(分别为30.4%30.4 \%30.4%和13.7%13.7 \%13.7%),表明人类和GPT-4o作为评审员在两端的判断上更为一致。对于15.1%15.1 \%15.1%,GPT-4o评审员认为某个标注为“部分支持”,而人类评审员认为是“无支持”。最后一个重要观察是,与人类评审员相比,GPT-4o评审员更有可能提供更高的支持标签(右上三角的总百分比高于左下三角)。
带后编辑的手动条件。从前一条件来看,我们看到完美一致的比例上升至72.1%(15.9%+18.7%+37.5%)72.1 \%(15.9 \%+18.7 \%+37.5 \%)72.1%(15.9%+18.7%+37.5%),涉及14个采用GPT-4o后编辑标签注释的主题。这表明,在手动从零开始条件下引起分歧的“部分支持”句子和引用段落有所减少。在此条件下,除非明显错误(即GPT-4o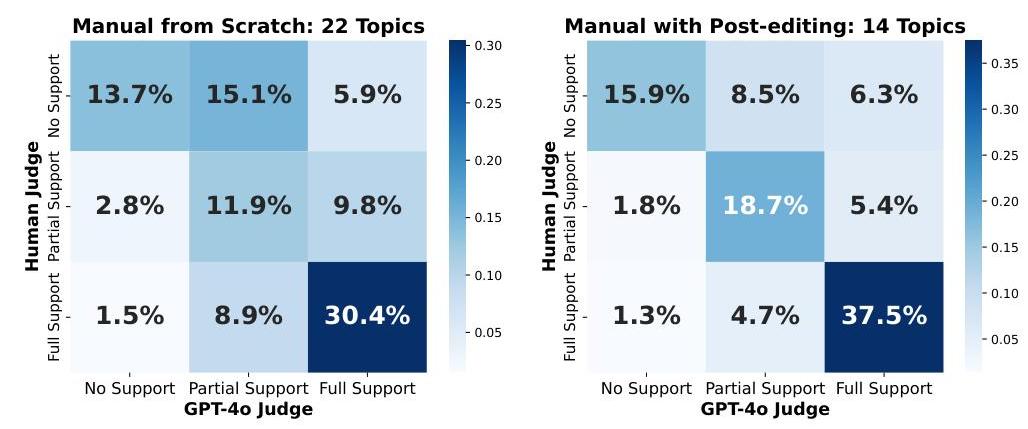
图3:混淆矩阵,比较人类和GPT-4o评审员在手动从零开始条件(左侧)和带后编辑的手动条件(右侧)下的预测结果。
| Cohen’s Kappa | 从零开始 | 带后编辑 | ||
|---|---|---|---|---|
| GPT-4o | 人类 | GPT-4o | 人类 | |
| 独立人类 | 0.29 | −0.03-0.03−0.03 | 0.27 | 0.07 |
| LLAMA-3.1 (405B) | 0.60 | −0.20-0.20−0.20 | 0.46 | −0.06-0.06−0.06 |
图4:我们对GPT-4o和人类注释者之间分歧的无偏研究中的注释者间一致性得分(Cohen’s κ\kappaκ )。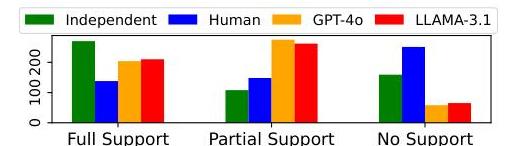
图5:在537个句子段落对的分歧分析中,不同评审员对每个支持类别(FS,PS,NS)的支持标签预测。
评审员认为某标注为“完全支持”,而人类评审员认为是“无支持”)的比例从手动从零开始条件的5.9%5.9 \%5.9%增加到现在的6.3%6.3 \%6.3%。
5 注释者分歧
在第4节报告的实验中,我们观察到人类和GPT-4o评审员之间频繁的分歧。为进一步研究这一点,我们进行了无偏注释,由独立的人类评审员和另一名使用LLAMA-3.1 405B [8](与图1中GPT-4o使用的相同提示)的LLM评审员仔细重新评估人类和GPT-4o评审员之间随机采样的分歧。我们每个主题随机采样15对分歧,重新评估537个句子及其第一个引用段落,包括两种评估条件:(1)手动从零开始和(2)带后编辑的手动评估。
结果。如图4所示,有趣的是,我们发现独立的人类评审员与GPT-4o的相关性比NIST提供的评审员更强(Cohen’s κ\kappaκ 分别为0.29和0.27,而非-0.03和0.07)在手动从零开始条件下。独立评审员完全匹配人类评审员31%31 \%31%的时间和GPT-4o评审员51%51 \%51%的时间。同样,在带后编辑的手动条件下,独立评审员完全匹配人类评审员37%37 \%37%的时间和GPT-4o评审员52%52 \%52%的时间。LLAMA-3.1 405B与另一名LLM(GPT-4o)的相关性比与人类评审员更强(Cohen’s κ\kappaκ 分别为0.60和0.46,而非-0.20和-0.06),这表明不同LLM很可能提供相似的预测标签。
从图5中分歧分析的标签分布来看,我们观察到两个LLM(LLAMA-3.1 405B和GPT-4o)将约49-51%的句子及其引用段落标记为“部分支持”,而人类评审员将47%47 \%47%的句子标记为“无支持”。独立评审员将50%50 \%50%的句子标记为“完全支持”。我们保留未来工作来探讨一致性:为什么LLM评审员只将少数句子标记为“无支持”,以及类似地,为什么人类评审员将多数句子标记为“无支持”。
定性分析。我们进一步对失败案例进行定性评估,例如,当人类或GPT-4o评审员在支持评估中出错时。在表4中,我们
回答句子:斯威夫特在与康纳·肯尼迪分手后不久就开始与19岁的One Direction主唱哈里·斯泰尔斯约会。
段落ID [0]: doc_04_1081579649#7_2253255175 标题:泰勒·斯威夫特不恰当恋爱的时间轴 | 商业内幕
文本:今天,泰勒·斯威夫特满23岁,但你永远不会知道她的真实年龄,因为她的恋爱生活。从18岁的康纳·肯尼迪到35岁的约翰·梅尔,斯威夫特在择偶方面毫不歧视。年轻或年长,英国或美国,斯威夫特在爱情生活中并不挑剔。但在23岁时,斯威夫特已经有至少10段备受瞩目的恋情(有些更像是短暂关系),都以歌曲结束。为了庆祝她的23岁生日,让我们重温斯威夫特众多男友的经历,好吗? […]
人类评审员:完全支持 ×\times×
GPT-4o评审员:无支持 ✓\checkmark✓
回答句子:她与乔·乔纳斯的第一次好莱坞恋情适龄,当时两人都19岁。
段落ID [3]: doc_04_1081579649#2_2253244363 标题:泰勒·斯威夫特恋爱的时间轴
文本:[…] 2009年:泰勒·斯威夫特,19岁,与乔·乔纳斯,19岁。斯威夫特的第一次好莱坞恋情完全适龄。虽然斯威夫特刚刚进入流行音乐圈,乔纳斯和他的歌舞兄弟们正处于事业巅峰。 […]
人类评审员:无支持 ×\times×
GPT-4o评审员:完全支持 ✓\checkmark✓
回答句子:斯威夫特曾与年轻的泰勒·洛特纳约会,当时她20岁,他17岁,这引起了争议,因为年龄差异。
段落ID [8]: doc_35_202251892#7_427547583 标题:泰勒·斯威夫特不恰当恋爱的时间轴 | 商业内幕
文本:2009年:泰勒·斯威夫特,20岁,与泰勒·洛特纳,17岁。正是在这里,她开始滑坡。理论上,这段关系在许多州可能是非法的,因为20岁的斯威夫特正在与未成年人约会。 […] 2010年10月,斯威夫特透露了自己的迷恋对象:“泰勒·洛特纳。这永远是我的最爱。” 据信,歌曲《回到十二月》是斯威夫特对两人分手的道歉。 […]
人类评审员:完全支持 ✓\checkmark✓
GPT-4o评审员:部分支持 ×\times×
回答句子:斯威夫特的年轻和缺乏经验被认为是她恋爱关系中的因素,据报道,一些伴侣利用了她的天真。
段落ID [8]: doc_481103263#4_840591332 标题:泰勒·斯威夫特男友:泰勒·斯威夫特的恋爱经历 | 新想法杂志
文本:[…] 约翰·梅尔(2009年12月-2010年2月) 泰勒和约翰之间的11岁年龄差距据说给他们的关系带来了压力,泰勒觉得自己的天真被利用了。她在歌曲《亲爱的约翰》中提到了他们丑陋的分手。 歌曲:亲爱的约翰 […]
人类评审员:完全支持 ✓\checkmark✓
GPT-4o评审员:部分支持 ×\times×
表4:来自分歧分析的泰勒·斯威夫特主题“泰勒·斯威夫特的年龄如何影响她的关系”的注释错误示例。支持回答句子的段落片段已突出显------
示。
展示了泰勒·斯威夫特主题中在人类或GPT-4o判断中发现的一些注释错误。总的来说,我们总结了GPT-4o的一些以下错误:
- GPT-4o可能会混淆含义相似的单词或短语;例如,它无法区分警察和保安专家。
-
- GPT-4o可能会遗漏评估整个句子(尤其是句子末尾的信息),偏向于“完全支持”标签。
-
- 如果答案句子的主题相似但段落不支持答案句子中的任何文本,GPT-4o可能会标记为“部分支持”,
- ------即“无支持”。
另一方面,人类评审员因未仔细阅读段落而犯错。在某些情况下,直接陈述在段落中间或结尾的答案句子,或在段落部分提到的内容,却意外被人类评审员忽略。这导致人类评审员将此类情况标记为“无支持”而非“完全支持”。最后,我们观察到,即使段落未提供任何支持信息,人类评审员偶尔仍会将答案句子标记为“完全支持”。我们怀疑这可能是由于人类评审员依赖自身的记忆或对主题的理解,而不是严格依据实际段落文本。
6 结论
在本研究中,我们通过分析TREC 2024 RAG赛道中36个主题的45份提交,在一项大规模对比研究中评估了RAG答案的支持度,涉及人类和LLM作为评审员。我们批评并评估了像GPT-4o这样的强大LLM评审员与人类注释者在支持评估方面的表现。
我们的结果显示,GPT-4o与人类判断之间有高度一致性,手动从零开始条件下的完美匹配率为56%,带后编辑的手动条件下增加到72%。我们观察到人类与LLM之间的分歧主要发生在表示部分支持的句子-段落对上,即支持评估谱系的中间部分。
为了更好地理解这些分歧,我们通过独立的人类评审员和不同的LLM进行无偏评估,重新评估判断。有趣的是,在存在分歧的情况下,独立的人类评审员和LLAMA-3.1评审员都比人类评审员更倾向于与GPT-4o评审员一致,这为广泛不同的意见提供了证据,或许也证明了使用LLM进行支持评估的可靠性。进一步的研究可以探讨人类与LLM评审员之间分歧的细微差别,并调查人类与LLM的局限性,以改进未来支持评估的迭代。
致谢
没有NIST的注释团队,这项工作是不可能完成的。我们对他们所做的贡献深表感谢。本研究得到了加拿大自然科学与工程研究委员会(NSERC)的部分支持。额外资金由Snowflake、微软通过加速基础模型研究计划以及韩国政府(MSIT)资助的信息与通信技术规划与评估研究所(IITP)国家AI研究实验室项目(编号RS-2024-00457882)提供。感谢Corby Rosset基于Researchy Questions [24] 方法开发的测试查询。
参考文献
[1] Mohammad Aliannejadi, Zahra Abbasiantaeb, Shubham Chatterjee, Jeffrey Dalton, 和 Leif Azzopardi. 2024. TREC iKAT 2023: 评估对话和交互式知识助手的测试集合。收录于《第47届国际ACM SIGIR信息检索研究与发展会议论文集》,SIGIR '24,第819-829页,纽约,美国。Association for Computing Machinery.
[2] Pepa Atanasova, Oana-Maria Camburu, Christina Lioma, Thomas Lukasiewicz, Jakob Grue Simonsen, 和 Isabelle Augenstein. 2023. 自然语言解释的忠实性测试。收录于《计算语言学协会第61届年会论文集(第二卷:短篇论文)》,ACL 2023,多伦多,加拿大,2023年7月9-14日,第283-294页。计算语言学协会。
[3] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack W. Rae, Erich Elsen, 和 Laurent Sifre. 2022. 通过检索数万亿个标记来改进语言模型。收录于《机器学习国际会议论文集》,ICML 2022,2022年7月17-23日,美国马里兰州巴尔的摩,机器学习研究进展第162卷,第2206-2240页。PMLR.
[4] Harrison Chase. 2022. LangChain.
[5] Jiawei Chen, Hongyu Lin, Xianpei Han, 和 Le Sun. 2024. 检索增强生成中的大型语言模型基准测试。《AAAI人工智能会议论文集》,38(16):17754-17762.
[6] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, Jimmy Lin, Ellen M. Voorhees, 和 Ian Soboroff. 2022. TREC 2022深度学习赛道概览。收录于《第三十一届文本检索会议论文集》(TREC 2022),马里兰州盖瑟斯堡。
[7] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Hossein A. Rahmani, Daniel Campos, Jimmy Lin, Ellen M. Voorhees, 和 Ian Soboroff. 2023. TREC 2023深度学习赛道概览。收录于《第三十二届文本检索会议论文集》(TREC 2023),马里兰州盖瑟斯堡。
[8] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, 和其他520人. 2024. Llama 3模型群。CoRR, abs/2407.21783.
[9] Shahul Es, Jithin James, Luis Espinosa Anke, 和 Steven Schockaert. 2024. RAGAs: 检索增强生成的自动化评估。收录于《欧洲计算语言学协会第18届会议系统演示论文集》,第150-158页,圣朱利安斯,马耳他。计算语言学协会。
[10] Tianyu Gao, Howard Yen, Jiatong Yu, 和 Danqi Chen. 2023. 启用带有引用的大规模语言模型生成文本。收录于《2023年经验方法自然语言处理会议论文集》,EMNLP 2023,新加坡,2023年12月6-10日,第6465-6488页。计算语言学协会。
[11] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, 和 Ming-Wei Chang. 2020. 检索增强语言模型预训练。收录于《第37届国际机器学习会议论文集》,ICML 2020,2020年7月13-18日,虚拟活动,机器学习研究进展第119卷,第3929-3938页。PMLR.
[12] Gautier Izacard 和 Edouard Grave. 2021. 利用生成模型结合段落检索进行开放领域问答。收录于《欧洲计算语言学协会第16届会议论文集》,EACL 2021,线上,2021年4月19 - 23日,第874-880页。计算语言学协会。
[13] Qi Jia, Siyu Ren, Yizhu Liu, 和 Kenny Q. Zhu. 2023. 使用基础语言模型进行零样本忠实性评估的文本摘要。收录于《2023年经验方法自然语言处理会议论文集》,EMNLP 2023,新加坡,2023年12月6-10日,第11017-11031页。计算语言学协会。
[14] Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, 和 Mike Lewis. 2020. 通过记忆实现泛化:最近邻语言模型。收录于《第八届国际学习表示会议论文集》,ICLR 2020,埃塞俄比亚亚的斯亚贝巴,2020年4月26-30日。OpenReview.net.
[15] Philippe Laban, Wojciech Kryscinski, Divyansh Agarwal, Alexander R. Fabbri, Caiming Xiong, Shafiq Joty, 和 Chien-Sheng Wu. 2023. SummEdits: 通过总结视角衡量大语言模型的事实推理能力。收录于《2023年经验方法自然语言处理会议论文集》,EMNLP 2023,新加坡,2023年12月6-10日,第9662-9676页。计算语言学协会。
[16] Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, 和 Douwe Kiela. 2020. 知识密集型NLP任务的检索增强生成。收录于《神经信息处理系统进展第33卷:2020年神经信息处理系统年度会议论文集》,NeurIPS 2020,2020年12月6-12日,虚拟会议。
[17] Nelson Liu, Tianyi Zhang, 和 Percy Liang. 2023. 生成搜索引擎的可验证性评估。收录于《计算语言学协会发现:EMNLP 2023》,第7001-7025页,新加坡。计算语言学协会。
[18] Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, 和 Percy Liang. 2024. 迷失在中间:语言模型如何使用长上下文。《计算语言学协会交易》,12:157-173.
[19] 微软. 2023. 用新的AI驱动的必应和Edge重塑搜索,您的网络副驾。
[20] Yifei Ming, Senthil Purushwalkam, Shrey Pandit, Zixuan Ke, Xuan-Phi Nguyen, Caiming Xiong, 和 Shafiq Joty. 2024. FaithEval: 您的语言模型是否能忠实于上下文,即使“月亮是由棉花糖制成的”?CoRR, abs/2410.03727.
[21] OpenAI. 2024. Hello GPT-4o.
[22] Ronak Pradeep, Nandan Thakur, Sahel Sharifymoghaddam, Eric Zhang, Ryan Nguyen, Daniel Campos, Nick Craswell, 和 Jimmy Lin. 2024. Ragnarök: TREC 2024检索增强生成赛道的可重用RAG框架和基线。arXiv:2406.16828.
[23] Ronak Pradeep, Nandan Thakur, Shivani Upadhyay, Daniel Campos, Nick Craswell, 和 Jimmy Lin. 2024. TREC 2024 RAG赛道的初步片段评估结果与AutoNuggetizer框架。CoRR, abs/2411.09607.
[24] Corby Rosset, Ho-Lam Chung, Guanghui Qin, Ethan C. Chau, Zhuo Feng, Ahmed Awadallah, Jennifer Neville, 和 Nikhil Rao. 2024. Researchy Questions: 大语言模型网络代理的多视角分解问题数据集。CoRR, abs/2402.17896.
[25] Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Cheng Jiayang, Cunxiang Wang, Shichao Sun, Huanyu Li, Zizhao Zhang, Binjie Wang, Jiarong Jiang, Tong He, Zhiguo Wang, Pengfei Liu, Yue Zhang, 和 Zheng Zhang. 2024. RAGChecker: 诊断检索增强生成的细粒度框架。收录于《神经信息处理系统进展第38卷:2024年神经信息处理系统年度会议论文集》,NeurIPS 2024,加拿大温哥华,2024年12月10 - 15日。
[26] Jon Saad-Falcon, Omar Khattab, Christopher Potts, 和 Matei Zaharia. 2024. ARES: 检索增强生成系统的自动化评估框架。收录于《2024年北美计算语言学协会会议论文集:人类语言技术(第一卷:长篇论文)》,第338-354页,墨西哥城,墨西哥。计算语言学协会。
[27] Noah Y. Siegel, Oana-Maria Camburu, Nicolas Heess, 和 María Pérez-Ortiz. 2024. 概率同样重要:大语言模型中自由文本解释忠实性的更可靠指标。收录于《计算语言学协会第62届年会论文集:短篇论文》,ACL 2024 - 短篇论文,曼谷,泰国,2024年8月11-16日,第530-546页。计算语言学协会。
[28] Shivani Upadhyay, Ronak Pradeep, Nandan Thakur, Daniel Campos, Nick Craswell, Ian Soboroff, Hoa Trang Dang, 和 Jimmy Lin. 2024. 大型语言模型相关性评估的大规模研究:初步观察。CoRR, abs/2411.08275.
[29] Kevin Wu, Eric Wu, 和 James Zou. 2024. RAG模型有多忠实?量化RAG和LLM内部先验之间的拉锯战。CoRR, abs/2404.10198.
[30] Jheng-Hong Yang, Carlos Lassance, Rafael Sampaio De Rezende, Krishna Srinivasan, Miriam Redi, Stéphane Clinchant, 和 Jimmy Lin. 2023. AToMiC: 支持多媒体内容创作的图像/文本检索测试集合。收录于《第46届国际ACM SIGIR信息检索研究与发展会议论文集》,SIGIR '23,第2975-2984页,纽约,美国。Association for Computing Machinery.
[31] Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, 和 Zhaofeng Liu. 2024. 检索增强生成评估:综述。CoRR, abs/2405.07437.
| 运行ID | 组别 | 任务 | 加权精确度 | 加权召回率 | 句子数 |
|---|---|---|---|---|---|
| ag_rag_gpt35_expansion_erf_20 | IITD-IRL | RAG | 0.793 | 0.793 | 4.82 |
| Enhanced_Iterative_Fact_Refinement_and_Prioritization | TREMA-UNH | RAG | 0.777 | 0.777 | 13.45 |
| UWCrag | WaterlooClarke | AG | 0.717 | 0.717 | 7.91 |
| Ranked_Iterative_Fact_Extraction_and_Refinement | TREMA-UNH | RAG | 0.709 | 0.709 | 13.68 |
| ldilab_gpt_4o | ldssnu | RAG | 0.698 | 0.445 | 12.86 |
| zoph_test_rag_erf_expand_query | IITD-IRL | AG | 0.681 | 0.681 | 4.64 |
| dilab_repllama_list5_pass3_gpt4o | ldssnu | AG | 0.669 | 0.408 | 13.45 |
| baseline_frag_rag24.test_gpt-4o_top20 | coordinators | AG | 0.654 | 0.401 | 14.18 |
| cir_gpt-4o-mini_no_reranking_50_0.5_100_301_p1 | CIR | RAG | 0.646 | 0.646 | 7.05 |
| neurag | neu | AG | 0.644 | 0.397 | 15.82 |
| baseline_frag_rag24.test_command-v-plus_top20 | coordinators | AG | 0.642 | 0.583 | 11.68 |
| iiiia_dedup_p1_straight_ag | IIIA-UNIPD | RAG | 0.635 | 0.572 | 3.77 |
| listgalore_gpt4o_ragnarskv4_top20 | h2oloo | AG | 0.610 | 0.487 | 12.14 |
| listgalore_l31-70b_ragnarskv4_top20 | h2oloo | AG | 0.605 | 0.532 | 9.64 |
| cohere+post_processing | KML | RAG | 0.582 | 0.542 | 18.0 |
| neuragfix | neu | AG | 0.569 | 0.359 | 15.82 |
| baseline_rag24.test_l31_70b_instruct_top20 | coordinators | RAG | 0.568 | 0.556 | 7.5 |
| iclab-b70bf-70balp-70bufs | iclab | AG | 0.565 | 0.445 | 3.14 |
| iiiia_standard_p1_straight_ag | IIIA-UNIPD | RAG | 0.562 | 0.483 | 6.23 |
| FT-llama3 | uog-tht | AG | 0.553 | 0.553 | 4.64 |
| UDIhilslab.RAG.Query | InfoLab | AG | 0.534 | 0.534 | 6.86 |
| webis-rag-nutll-taskrag | webis | AG | 0.527 | 0.527 | 6.27 |
| baseline_top_5 | uis-iai | RAG | 0.522 | 0.522 | 3.23 |
| agtask-bm25-colbert_faiso-gpt4o-llama70b | softbank-meisei | RAG | 0.516 | 0.516 | 8.27 |
| UDIhilslab.RAG.AnsAI | InfoLab | AG | 0.505 | 0.505 | 7.18 |
| cir_gpt-4o-mini_Cosine_50_0.5_100_301_p1 | CIR | RAG | 0.495 | 0.495 | 7.05 |
| buw | buw | AG | 0.481 | 0.481 | 8.14 |
| webis-rag-nut1-taskrag | webis | AG | 0.464 | 0.464 | 6.18 |
| oneshot_post_sentenced | buw | AG | 0.461 | 0.356 | 9.09 |
| rag_bm25-colbert_faiso-gpt4o-llama70b | softbank-meisei | AG | 0.433 | 0.433 | 7.27 |
| ruc001 | Ruc01 | AG | 0.425 | 0.348 | 14.77 |
| gpt_mini | KML | RAG | 0.368 | 0.368 | 7.45 |
| ginger_top_5 | uis-iai | RAG | 0.367 | 0.367 | 4.32 |
| LAS-splade-mxbai-mmr8-RAG | ncsu-las | AG | 0.308 | 0.226 | 12.82 |
| UWCgurag | WaterlooClarke | AG | 0.305 | 0.289 | 9.95 |
| iisresearch-bm25-top10-llama3-8b-instruct | ii_research | AG | 0.293 | 0.293 | 4.05 |
| BEST_cot_gpt3.5 | citi | AG | 0.291 | 0.256 | 6.23 |
| ICL-mistral | uog-tht | AG | 0.267 | 0.201 | 5.82 |
| iclab-b70bf-70bqfs-ad_hoc | iclab | AG | 0.246 | 0.246 | 4.59 |
| SECOND_cot_gpt3.5 | citi | AG | 0.246 | 0.192 | 5.36 |
| ISIR-IMIT-exphyr_query_gen | IRT | AG | 0.205 | 0.115 | 2.59 |
| LAS-splade-mxbai-rrf-mmr8 | ncsu-las | AG | 0.167 | 0.116 | 13.41 |
| ISIR-IMIT-exphyr_p2 | IRT | AG | 0.131 | 0.094 | 1.59 |
| ayant_hge_genini | SGU | AG | 0.130 | 0.130 | 6.45 |
| webis-manual | webis | AG | 0.079 | 0.037 | 1.68 |
表5:TREC 2024 RAG赛道前两名组别的加权精确度和召回率分数,在22个主题下由NIST提供的人类评审员进行手动从零开始条件评估。#Sentences表示参与者提交回答中的平均句子数。
| 运行ID | 组别 | 任务 | 加权精确度 | 加权召回率 | #句子 |
|---|---|---|---|---|---|
| ag_rag_gpt35_expansion_rrf_20 | IITD-IRL | RAG | 0.868 | 0.868 | 4.82 |
| Ranked_Iterative_Fact_Extraction_and_Refinement | TREMA-UNH | RAG | 0.861 | 0.861 | 13.68 |
| Enhanced_Iterative_Fact_Refinement_and_Prioritization | TREMA-UNH | RAG | 0.846 | 0.846 | 13.45 |
| UWCrag | WaterlooClarke | AG | 0.841 | 0.841 | 7.91 |
| zeph_test_rag_rrf_expand_query | IITD-IRL | AG | 0.807 | 0.807 | 4.64 |
| idilab_gpt_4o | ldismu | RAG | 0.791 | 0.514 | 12.86 |
| dilab_repliana_listr5_pass3_gpt4o | ldismu | AG | 0.784 | 0.491 | 13.45 |
| baseline_frag_rag24.test_command-e-plus_top20 | coordinators | AG | 0.778 | 0.718 | 11.68 |
| iiix_deslup_p1_straight_ng | IIIA-UNIPD | RAG | 0.767 | 0.715 | 3.77 |
| cir_gpt-4o-mini_no_reranking_50_0.5_100_301_p1 | CIR | RAG | 0.757 | 0.757 | 7.05 |
| baseline_frag_rag24.test_gpt-4o_top20 | coordinators | AG | 0.741 | 0.467 | 14.18 |
| neuragfix | neu | AG | 0.737 | 0.459 | 15.82 |
| neurag | neu | AG | 0.735 | 0.458 | 15.82 |
| iclab-b70bf-70bqp-70bufs | iclab | AG | 0.733 | 0.591 | 3.18 |
| baseline_rag24.test_131_70b_instruct_top20 | coordinators | RAG | 0.731 | 0.719 | 7.50 |
| cohere+post_processing | KML | RAG | 0.712 | 0.671 | 18.00 |
| listgalore_131-70b_ragnarokv4_top20 | h2oloo | AG | 0.711 | 0.622 | 9.64 |
| iiix_standard_p1_straight_ag | IIIA-UNIPD | RAG | 0.702 | 0.610 | 6.23 |
| webis-manual | webis | AG | 0.702 | 0.415 | 14.14 |
| listgalore_gpt4o_ragnarokv4_top20 | h2oloo | AG | 0.699 | 0.563 | 12.14 |
| cir_gpt-4o-mini_Cosine_50_0.5_100_301_p1 | CIR | RAG | 0.677 | 0.677 | 7.05 |
| UDIufolab:RAG.AnsAI | InfoLab | AG | 0.659 | 0.659 | 7.18 |
| FT-llama3 | uog-tht | AG | 0.640 | 0.640 | 4.64 |
| baseline_top_5 | uis-iai | RAG | 0.639 | 0.639 | 3.23 |
| aptask-bm25-colbert_faiss-gpt4o-llama70b | softbank-meisei | RAG | 0.633 | 0.633 | 8.27 |
| UDIufolab:RAG.Query | InfoLab | AG | 0.623 | 0.623 | 6.86 |
| webis-rag-run0-taskrag | webis | AG | 0.616 | 0.616 | 6.27 |
| buw | buw | AG | 0.597 | 0.597 | 8.14 |
| onedot_post_sentenced | buw | AG | 0.581 | 0.445 | 9.09 |
| ruc001 | Ruc01 | AG | 0.577 | 0.479 | 14.77 |
| webis-rag-run1-taskrag | webis | AG | 0.531 | 0.531 | 6.18 |
| gpt_mini | KML | RAG | 0.494 | 0.494 | 7.45 |
| rag_bm25-colbert_faiss-gpt4o-llama70b | softbank-meisei | AG | 0.475 | 0.475 | 7.27 |
| ICL-mistral | uog-tht | AG | 0.454 | 0.345 | 5.82 |
| UWCgang | WaterlooClarke | AG | 0.443 | 0.425 | 9.95 |
| iiresearch-bm25-top10-llama3-8b-instruct | ii_research | AG | 0.433 | 0.392 | 4.14 |
| ginger_top_5 | uis-iai | RAG | 0.419 | 0.419 | 4.32 |
| LAS-splade-mxbai-mmr8-RAG | ncsu-las | AG | 0.376 | 0.270 | 12.82 |
| BEST_ost_gpt3.5 | citi | AG | 0.329 | 0.274 | 6.45 |
| SECOND_ost_gpt3.5 | citi | AG | 0.319 | 0.229 | 5.50 |
| ISIR-IRIT-zephyr_query_gen | IRIT | AG | 0.273 | 0.132 | 6.95 |
| iclab-b70bf-70bufs-ad_boc | iclab | AG | 0.253 | 0.253 | 4.59 |
| LAS-splade-mxbai-rrf-mmr8 | ncsu-las | AG | 0.237 | 0.170 | 13.41 |
| ISIR-IRIT-zephyr_p2 | IRIT | AG | 0.159 | 0.112 | 6.73 |
| spant_bpc_gemini | SGU | AG | 0.157 | 0.157 | 6.45 |
表6:TREC 2024 RAG赛道前两名组别的加权精确度和召回率分数,在22个主题下由GPT-4o评审员进行手动从零开始条件评估。#句子表示参与者提交回答中的平均句子数。
| 运行ID | 组别 | 任务 | 加权精确度 | 加权召回率 | #句子 |
|---|---|---|---|---|---|
| ag_rag_gpt35_expansion_rrf_20 | IITD-IRL | RAG | 0.793 | 0.793 | 4.79 |
| Enhanced_Iterative_Fact_Refinement_and_Prioritization | TREMA-UNH | RAG | 0.773 | 0.773 | 14.5 |
| Ranked_Iterative_Fact_Extraction_and_Refinement | TREMA-UNH | RAG | 0.772 | 0.772 | 14.07 |
| baseline_frag_rag24.test_command+plus_top20 | coordinators | AG | 0.760 | 0.683 | 12.29 |
| neurag | neu | AG | 0.735 | 0.442 | 15.71 |
| listgalore_gpt4o_ragnarskv4_top20 | h2olso | AG | 0.734 | 0.575 | 12.21 |
| baseline_frag_rag24.test_gpt-4o_top20 | coordinators | AG | 0.726 | 0.404 | 14.64 |
| UWCrag | WaterlooClarke | AG | 0.724 | 0.724 | 6.64 |
| zeph_test_rag_rrf_expand_query | IITD-IRL | AG | 0.709 | 0.709 | 4.07 |
| dilab_repllama_listt5_pass3_gpt4o | ldismu | AG | 0.709 | 0.418 | 12.0 |
| listgalore_l31-70b_ragnarskv4_top20 | h2olso | AG | 0.679 | 0.593 | 9.57 |
| baseline_rag24.test_l31_70b_instruct_top20 | coordinators | RAG | 0.668 | 0.660 | 7.5 |
| neuragflx | neu | AG | 0.666 | 0.398 | 15.71 |
| iiiia_standard_p1_straight_ag | IIIA-UNIPD | RAG | 0.662 | 0.602 | 4.93 |
| ielab-b70bf-70bgn-70bafs | ielab | AG | 0.658 | 0.571 | 2.86 |
| UDIinfolab:RAG:Query | InfoLab | AG | 0.654 | 0.654 | 7.71 |
| iiiia_desbap_p1_straight_ag | IIIA-UNIPD | RAG | 0.650 | 0.634 | 4.43 |
| ldilab_gpt_4o | ldismu | RAG | 0.646 | 0.363 | 12.79 |
| cir_gpt-4o-mini_no_reranking_50_0.5_100_301_p1 | CIR | RAG | 0.644 | 0.644 | 6.86 |
| UDIinfolab:RAG:AnsAI | InfoLab | AG | 0.639 | 0.639 | 7.43 |
| webis-r------ | |||||
| ag-run0-taskrag | webis | AG | 0.611 | 0.611 | 5.21 |
| baseline_top_5 | uis-iai | RAG | 0.571 | 0.5 | |
| 71 | 3.07 | ||||
| FT-llama3 | uog-tht | AG | 0.557 | 0.557 | 3.29 |
| cohens+post_processing | KML | RAG | |||
| ------ | 0.556 | 0.556 | 18.79 | ||
| cir_gpt-4o-mini_Cosine_50_0.5_100_301_p1 | CIR | RAG | 0.538 | 0.538 | 7.29 |
| agtask-bm25-colbert_faiss-gpt4o-llama70b | softbank-meisei | RAG | 0.526 | 0.526 | 7.43 |
| ruc001 | Ruc01 | AG | 0.516 | 0.458 | 11.21 |
| oneshot_post_sentenced | buw | AG | 0.460 | 0.357 | 12.0 |
| buw | buw | AG | 0.459 | 0.459 | 9.5 |
| gpt_mini | KML | RAG | 0.417 | 0.417 | 8.36 |
| ginger_top_5 | uis-iai | RAG | 0.413 | 0.413 | 3.79 |
| rag_bm25-colbert_faiss-gpt4o-llama70b | softbank-meisei | AG | 0.398 | 0.398 | 7.29 |
| webis-rag-run1-taskrag | webis | AG | 0.356 | 0.356 | 5.57 |
| ielab-b70bf-70bqfs-ad_hoc | ielab | AG | 0.352 | 0.350 | 4.71 |
| LAS-splade-mxbai-mmr8-RAG | ncsu-las | AG | 0.322 | 0.241 | 11.71 |
| iisresearch-bm25-top10-llama3-8b-instruct | ii_research | AG | 0.321 | 0.321 | 1.86 |
| SECOND_cot_gpt3.5 | citi | AG | 0.287 | 0.224 | 5.14 |
| ICL-mistral | uog-tht | AG | 0.250 | 0.196 | 4.29 |
| UWCgarag | WaterlooClarke | AG | 0.237 | 0.201 | 9.29 |
| BEST_cot_gpt3.5 | citi | AG | 0.216 | 0.170 | 3.71 |
| LAS-splade-mxbai-rrf-mmr8 | ncsu-las | AG | 0.190 | 0.144 | 12.21 |
| qrant_bge_gemini | SGU | AG | 0.147 | 0.147 | 5.79 |
| ISIR-IRIT-zephyr_p2 | IRIT | AG | 0.143 | 0.047 | 2.86 |
| ISIR-IRIT-zephyr_query_gen | IRIT | AG | 0.143 | 0.055 | 1.79 |
| webis-manual | webis | AG | 0.106 | 0.075 | 1.71 |
表7:TREC 2024 RAG赛道前两名组别的加权精确度和召回率分数,在14个主题下由NIST提供的人类评审员进行带后编辑的手动条件评估。#句子表示参与者提交回答中的平均句子数。
| 运行ID | 组别 | 任务 | 加权精确度 | 加权召回率 | #句子 |
|---|---|---|---|---|---|
| Ranked_Iterative_Fact_Extraction_and_Refinement | TREMA-UNH | RAG | 0.900 | 0.900 | 14.07 |
| Enhanced_Iterative_Fact_Refinement_and_Prioritization | TREMA-UNH | RAG | 0.885 | 0.885 | 14.5 |
| zeph_test_rag_ref_expand_query | IITD-IRL | AG | 0.852 | 0.852 | 4.07 |
| ldilab_gpt_4o | ldisnu | RAG | 0.842 | 0.482 | 12.79 |
| ag_rag_gpt35_expansion_ref_20 | IITD-IRL | RAG | 0.838 | 0.838 | 4.79 |
| dilab_repllama_listt5_pass3_gpt4o | ldisnu | AG | 0.831 | 0.474 | 12.0 |
| UWCrag | WaterlooClarke | AG | 0.817 | 0.817 | 6.64 |
| lisigalore_131-70b_ragnarokv4_top20 | h2oloo | AG | 0.807 | 0.687 | 9.57 |
| baseline_frag_rag24.test_command-r-plus_top20 | coordinators | AG | 0.805 | 0.724 | 12.29 |
| iisa_dedup_p1_straight_ag | IIIA-UNIPD | RAG | 0.783 | 0.740 | 4.43 |
| baseline_frag_rag24.test_gpt-4o_top20 | coordinators | AG | 0.782 | 0.427 | 14.64 |
| neuragfix | neu | AG | 0.775 | 0.464 | 15.71 |
| lisigalore_gpt4o_ragnarokv4_top20 | h2oloo | AG | 0.775 | 0.606 | 12.21 |
| cir_gpt-4o-mini_Cosine_50_0.5_100_301_p1 | CIR | RAG | 0.773 | 0.773 | 7.29 |
| websi-manual | websi | AG | 0.770 | 0.436 | 12.64 |
| neurag | neu | AG | 0.762 | 0.455 | 15.71 |
| cir_gpt-4o-mini_no_reranking_50_0.5_100_301_p1 | CIR | RAG | 0.750 | 0.750 | 6.86 |
| UDIufolab.RAG.Query | InfoLab | AG | 0.731 | 0.731 | 7.71 |
| baseline_rag24.test_131_70b_instruct_top20 | coordinators | RAG | 0.728 | 0.719 | 7.5 |
| ielab-b70bf-70bigs-70bals | ielab | AG | 0.723 | 0.620 | 2.93 |
| UDIufolab.RAG.AmsAI | InfoLab | AG | 0.717 | 0.717 | 7.43 |
| iisa_standard_p1_straight_ag | IIIA-UNIPD | RAG | 0.690 | 0.621 | 4.93 |
| agtask-bm25-colbert_faiso-gpt4o-llama70b | softbank-meisei | RAG | 0.687 | 0.687 | 7.43 |
| websi-rag-runfi-taskrag | websi | AG | 0.682 | 0.682 | 5.21 |
| cohere+post_processing | KML | RAG | 0.682 | 0.682 | 18.79 |
| baseline_top_5 | uis-iai | RAG | 0.601 | 0.601 | 3.07 |
| FT-llama3 | uog-tht | AG | 0.574 | 0.574 | 3.29 |
| oneshot_post_sentenced | buw | AG | 0.571 | 0.442 | 12.0 |
| buw | buw | AG | 0.558 | 0.558 | 9.5 |
| ruc001 | Ruc01 | AG | 0.548 | 0.482 | 11.29 |
| websi-rag-run1-taskrag | websi | AG | 0.487 | 0.487 | 5.57 |
| gpt_mini | KML | RAG | 0.471 | 0.440 | 8.36 |
| rag_bm25-colbert_faiso-gpt4o-llama70b | softbank-meisei | AG | 0.435 | 0.435 | 7.29 |
| ginger_top_5 | uis-iai | RAG | 0.408 | 0.408 | 3.79 |
| UWCgurag | WaterlooClarke | AG | 0.387 | 0.324 | 9.29 |
| SECOND_cot_gpt3.5 | citi | AG | 0.369 | 0.297 | 5.5 |
| ICL-mistral | uog-tht | AG | 0.357 | 0.268 | 4.29 |
| LAS-splade-mxbai-mmr8-RAG | ncsu-las | AG | 0.347 | 0.261 | 11.71 |
| ielab-b70bf-70bajls-ad_hoc | ielab | AG | 0.297 | 0.295 | 4.71 |
| iirosearch-bm25-top10-llama3-8b-instruct | ii_research | AG | 0.296 | 0.296 | 1.86 |
| ISIR-IRIT-zephyr_p2 | IRIT | AG | 0.243 | 0.074 | 6.36 |
| BEST_cot_gpt3.5 | citi | AG | 0.227 | 0.161 | 5.5 |
| LAS-splade-mxbai-rrf-mmr8 | ncsu-las | AG | 0.195 | 0.150 | 12.21 |
| ISIR-IRIT-zephyr_query_gen | IRIT | AG | 0.179 | 0.053 | 5.36 |
| spant_bpc_gemini | SGU | AG | 0.149 | 0.149 | 5.79 |
表8:TREC 2024 RAG赛道前两名组别的加权精确度和召回率分数,在14个主题下由GPT-4o评审员进行带后编辑的手动条件评估。#句子表示参与者提交回答中的平均句子数。
参考论文:https://arxiv.org/pdf/2504.15205

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)