Ollama两步本地部署AI模型
0基础简单两步教你本地部署大模型
·
第一步 下载ollama
去 Ollama 下载ollama
第二步 下载模型
首先要选择合适自己硬件的模型,下面有参考图
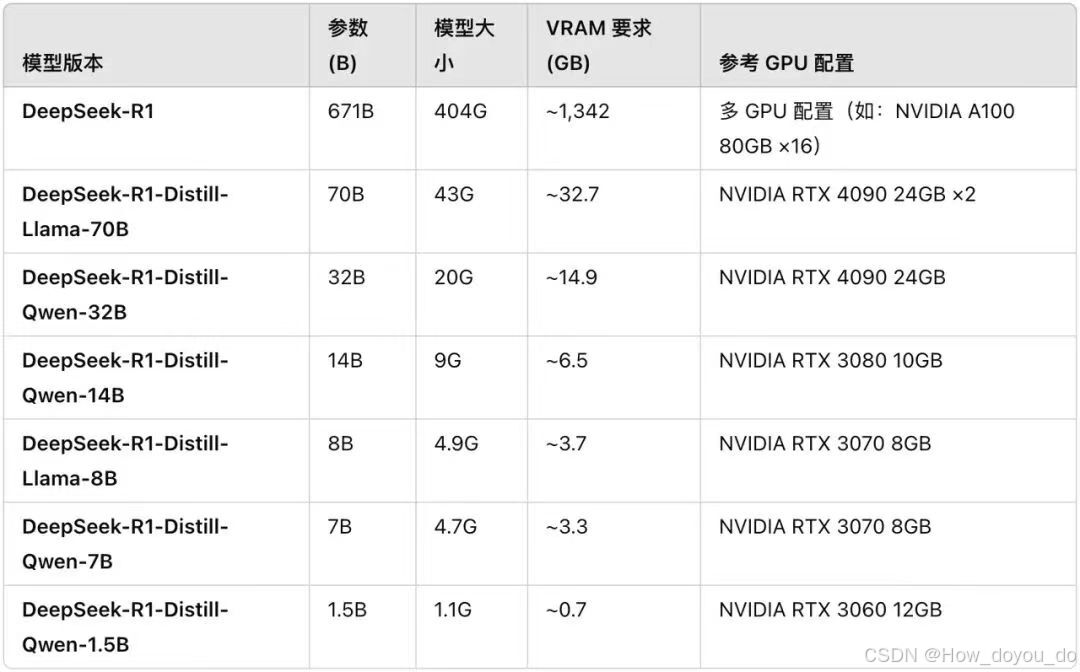
选完模型直接去终端运行语句
ollama run 后面接上你想要的模型,如果本地之前没下过模型那么就会开始下载
比如我想下个14B的
ollama run deepseek-r1:14b(其实正宗下载模型的语句是 ollama pull)
其他ollama可用语句
1.查看已下载模型
ollama list2.删除模型
ollama rm <模型名称>3.退出对话
/bye4.保存对话记录
/save <文件名>5. 调整生成参数
ollama run llama2 --temperature 0.7 --top_p 0.9temperature:控制随机性(0-1,值越大越随机)
top_p:控制生成多样性(0-1,值越小越保守)
6. 自定义模型配置
ollama create <自定义模型名> -f Modelfile7.启动本地 API 服务
a.本地
ollama serveb.API接口
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "Hello!"
}'
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)