【大模型实战教程】LLaMA-Factory微调入门指南
随着自然语言处理技术的飞速发展,预训练语言模型已成为推动各种NLP任务进步的关键力量。对于我们每一个普通用户或者作为个人兴趣的开发者来说,从0开始训练一个大规模语言模型无疑是一件十分困难的事。那么我们是否有机会接触到真正的大模型训练呢?答案是有的,利用当下丰富的开源的预训练大模型资源,通过LoRA微调等技术,我们可以对现有的预训练大模型进行特定方向的调整。如果你也想经过微调训练出自己的“定制款”大
前言
随着自然语言处理技术的飞速发展,预训练语言模型已成为推动各种NLP任务进步的关键力量。对于我们每一个普通用户或者作为个人兴趣的开发者来说,从0开始训练一个大规模语言模型无疑是一件十分困难的事。那么我们是否有机会接触到真正的大模型训练呢?答案是有的,利用当下丰富的开源的预训练大模型资源,通过LoRA微调等技术,我们可以对现有的预训练大模型进行特定方向的调整。如果你也想经过微调训练出自己的“定制款”大模型,那么这篇教程将是你的不二之选。
在开始之前,我们需要准备如下内容:
- 基础的大模型领域通识;
- 良好的计算机知识技能;
- 一台足够算力的电脑或云算力平台;
- 若有科学上网的工具将是锦上添花;
- 最重要的是:要有足够的耐心。
准备好了上述的一切,让我们开始吧!
Lora微调技术概述
工欲善其事,必先利其器。我们应该对我们所将要使用的技术有一些初步的了解。大模型的**“微调”(Fine-tuning)**是指在已经训练好的大型预训练模型上,使用特定领域的数据进行进一步的训练过程。这个过程可以使得预训练模型更好地适应特定的任务或者数据集,从而提高模型在该任务上的表现。
LoRA(Low-Rank Adaptation)微调是一种针对大型预训练模型的高效微调技术。传统上,当我们要对一个大型预训练模型进行微调时,可能会面临计算资源和存储空间的限制,因为直接调整整个模型的所有参数需要大量的计算资源和时间。LoRA技术通过引入额外的低秩矩阵来替代原有的高维矩阵中的部分权重,从而在不显著增加模型参数量的前提下实现对模型的有效调整。
LoRA的优势在于它可以有效地减少微调过程中所需要的计算资源,同时也能保留原有模型的能力,使得模型可以在新的任务上表现良好。这种方法特别适用于个人计算机或资源有限的环境中进行大规模模型的微调工作。通俗的来说,LoRA更像一根找准了支点的省力杠杆,可以更有效的撬动大模型的方向。
关于模型的选择
目前的开源的预训练大模型数量众多,有很多可供我们进行微调。这里我推荐对自己机器的算力不够自信的同学们使用Qwen2.5-0.5B-Instruct模型来进行微调。通过这个命名也可以看出,其训练数据只有0.5B,相对于其他动辄70B甚至几百B的大模型来说,其参数更少,对我们的算力要求没有非常严格。
通义千问2.5-0.5B-Instruct · 模型库 (modelscope.cn)
在这个社区中,还有很多其它的模型可供大家选择,GLM4的训练表现同样也很优秀,各位可以按照自己的需求和配置来调整自己的选择。这里再多提一句,这里的“B”用来表示模型参数的数量,“参数”是指神经网络中可以调整的权重和偏置值,通俗点来讲,我们训练模型的过程实际上就是去寻找和无限接近一个完美的函数,能够使得我们绝大多数的输入都符合我们预期的输出要求,因此参数量越大,模型的表现也就在理论上更为优秀。
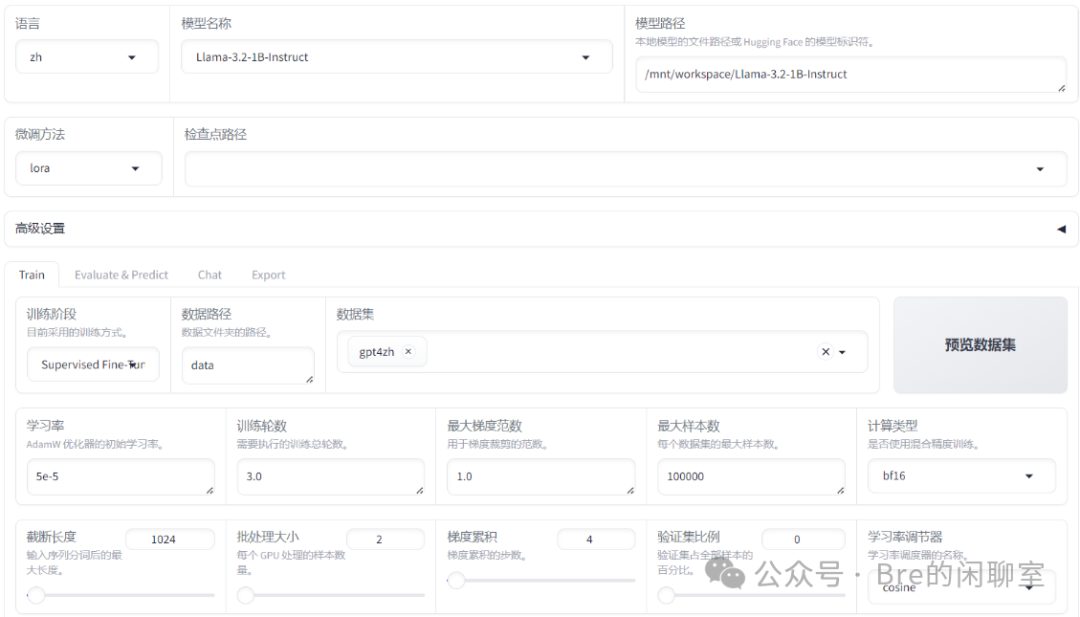
言归正传,无论我们选择了哪一个预训练模型,该页面中都可以点击“模型文件”—>“下载模型”。

随后,我推荐大家使用Git来完成下载。在过程中可能出现命令行停在某一步的情况,请耐心,等待全部执行完,确保模型被完全正确的下载下来。请确保你妥善选择了他的存放路径。
至此,我们已经拥有了一个被预训练过的大模型。既然食材已经搬上案板,是时候大展身手了。
LLaMA-Factory是什么
空有一手颠勺儿的绝活儿,没有一口结实的铁锅是不够的。本次微调实战,我们要使用到的是一款开源的微调框架。LLaMA-Factory 是专为简化和优化大型语言模型的训练、微调、推理和部署过程而设计。它提供了一系列工具和接口,使得用户能够更加轻松地对预训练的语言模型进行定制化调整,以适应特定的应用场景。最重要的是,它有非常容易操作的可视化界面供我们使用,这下终于能走出命令行的黑窗窗了。
hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs (ACL 2024) (github.com)
以上是该项目的Github链接,相同地,我们选取一个合适的路径,在命令行中执行git clone,将这个项目拉取下来到本地。请按照该项目目录中的“requirement.txt”文件安装对应的依赖。建议大家使用python虚拟环境,避免产生冲突。
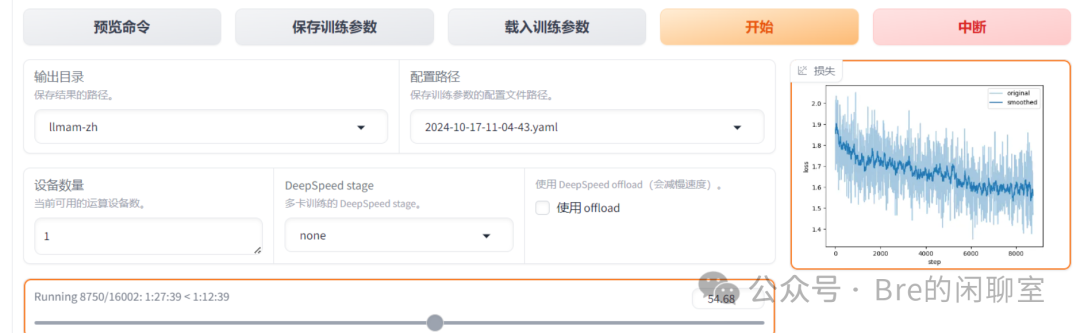
接下来,运行项目中src目录下的“webui.py”,等待数秒后,会开启本地的7860端口,只需要单击访问生成的链接就能够打开前端图形界面了。首先,让我们来看看刚才下载到本地的预训练模型是否能够正确使用。
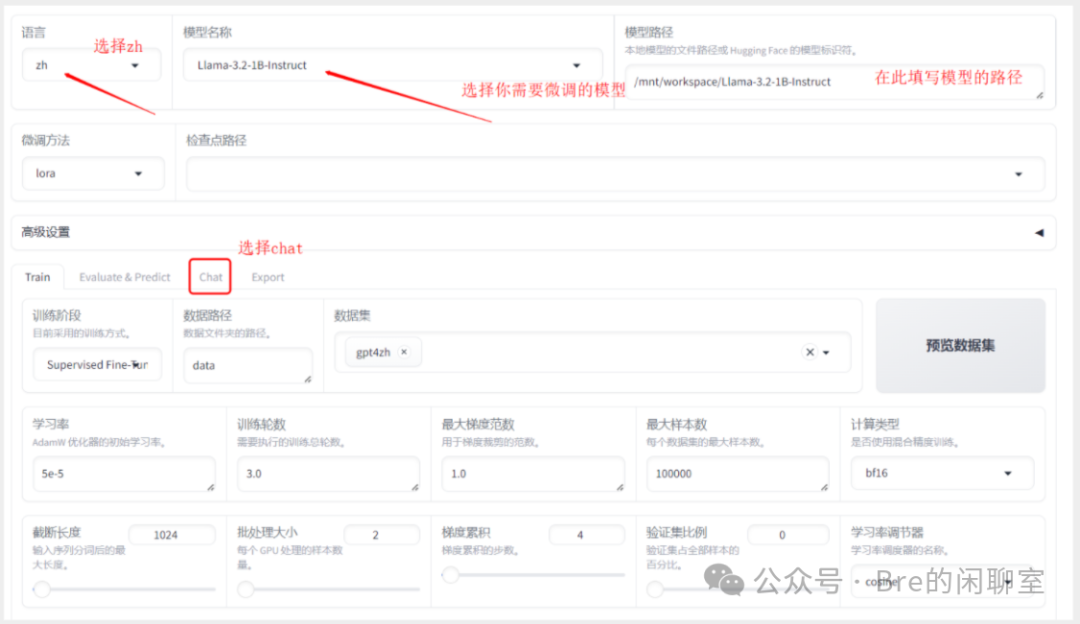
按照图中的步骤操作后,在Chat栏下,选择huggingface作为推理引擎,点击加载模型,如果一切顺利,恭喜你,快去试试你刚部署好的本地大模型的能力吧。如果出现了一些错误和问题,请仔细检查你的模型路径是否出错。
如果你完成了上面的一切,并且也玩腻了你刚在本地部署好的预训练模型,是时候进入到我们的下一步了。
Datasets的选用
无论什么类型的调整,总是离不开大量数据的帮助,有了这些数据,我们才能将我们希望机器去学习的事情告诉机器,机器才得以根据这些数据来提升自己。广义上的“数据集”(dataset)是指为了特定目的而收集的一组相关数据。这些数据可以是结构化的,也可以是非结构化的,通常用于分析、研究、机器学习训练或其他计算任务。数据集在科学研究、商业分析、教育、医疗等多个领域都有广泛的应用。对于我们需要完成的任务来说,当然是需要大量结构化的、包含用户输入和模型回答的问答对的数据组成的数据集。
在这里,我推荐大家首先使用框架中自带的“identify.json”来对模型的自我认知进行微调,毕竟,没有什么是比将现有的成果署上自己的大名更诱人的事情了。可以看到,这个文件中已经为我们预留了更改的部分,我们只需要将name和author进行全局替换就可以获取专属于自己的数据集了。准备好数据集之后,结合框架的使用文档,我们要确保项目启动时的路径处于该项目的根目录下,否则会出现找不到文件的情况。接下来,选取准备好的数据集,点击预览,看看是否是我们刚刚做好修改的那一个,确认无误后,我们就可以选择LoRA方法进行训练,调整页面上的参数至合适后,可以直接从左至右依次点击下面的一排按钮,开始训练了。我猜大多数同学的命令行会报错提示一条找不到该cli命令,没关系不要慌,遇到问题先回到项目里找找PR,果不其然,复制这条报错进行搜索,该项目中有一条PR里的回答完美解决了该问题。到这里,我们的训练应该已经开始了。查看你的后端是否出现了报错,有可能出现算力不够、内存溢出或其他问题,需要我们灵活应对解决问题。
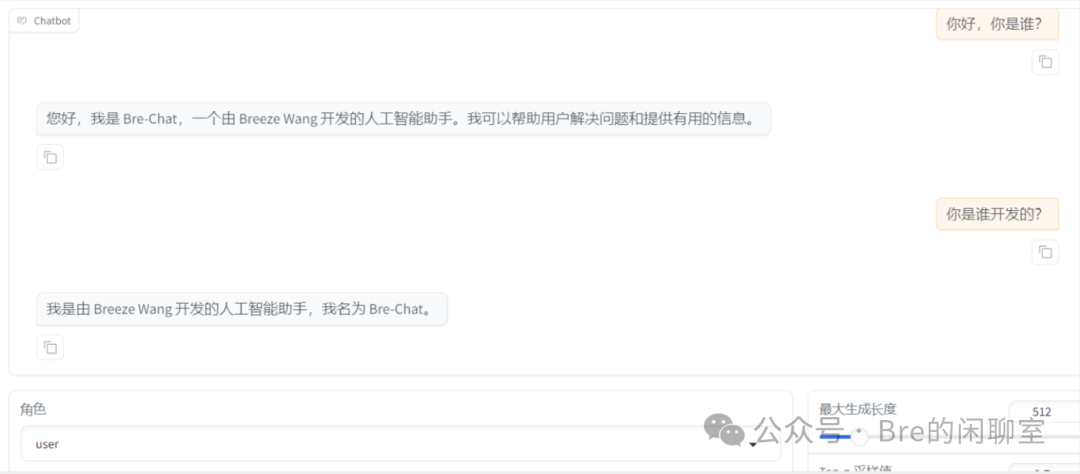
一般来说,自我认识微调的数据量很小,15轮迭代的情况下,大概1分钟左右就能完成训练。此时,回到刚才的Chat栏,在检查点路径部分选择你刚训练的模型:
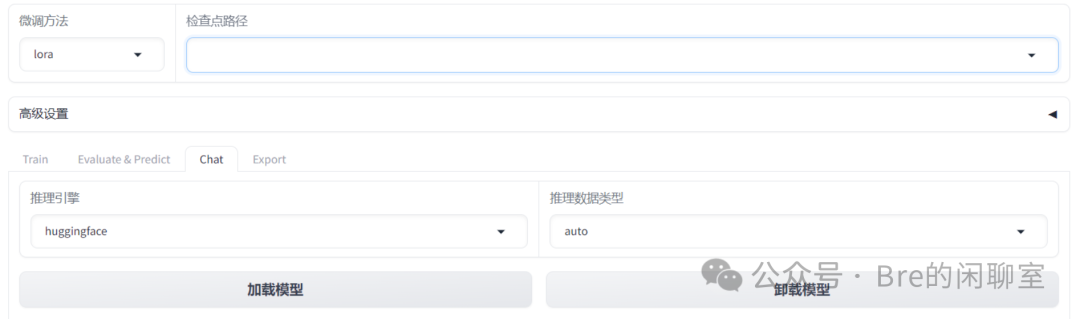
再次加载模型,尝试和模型对话,会发现此时模型的自我认知已经完成了改变。
到这里我们已经完成了教程中的全部任务,是时候把时间留给自己进行探索了。也许你可以换一个模型进行微调,或者去寻找一些其他的数据集,对模型的方向进行专业化定制,又或者,对比一下不同量级参数的模型在微调之后的提升大小。
如果你有科学上网的工具,HuggingFace社区中还有大量的数据集可供使用,不过,大量的数据将会导致训练的过程变得更加漫长,所以,选择合适的数据和模型进行微调。
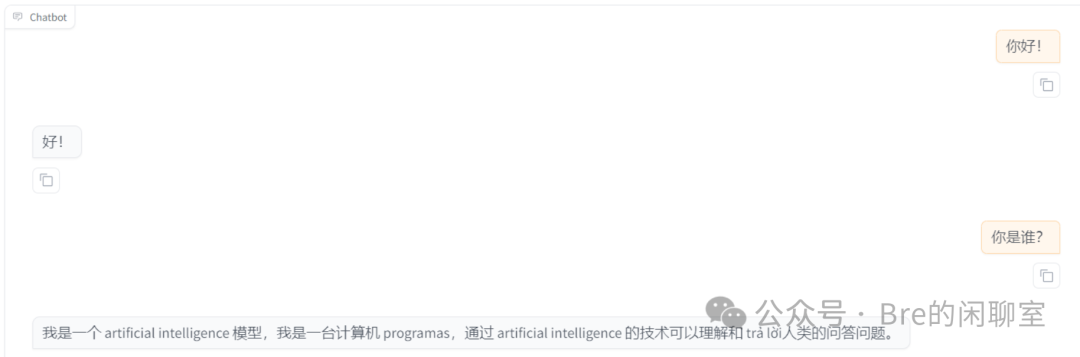
在这里给大家一个思路:LLaMA-3.2-1B模型是一个很好的例子,未经微调的预训练模型只能僵硬的输出中文并且在其中夹杂和附带英文原文:
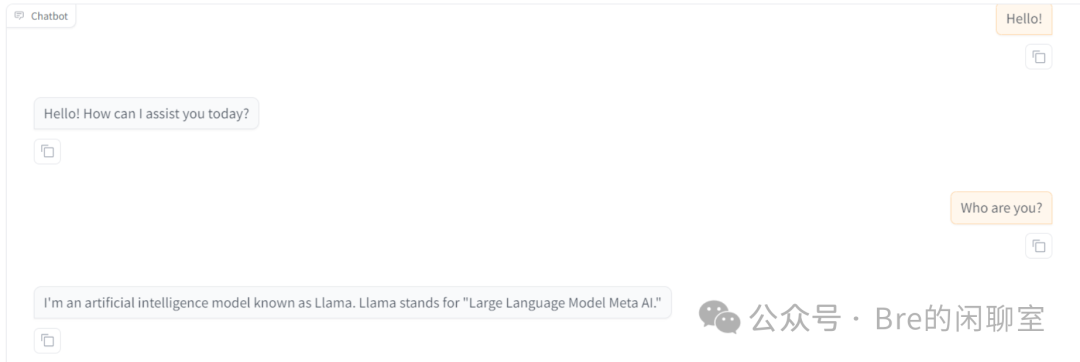
可以看出使用英文提问后,该预训练模型的表现还是不错的。
那么,我们是否可以进行微调,使得模型能够更流畅的使用和理解中文,达到一定意义上的汉化呢?
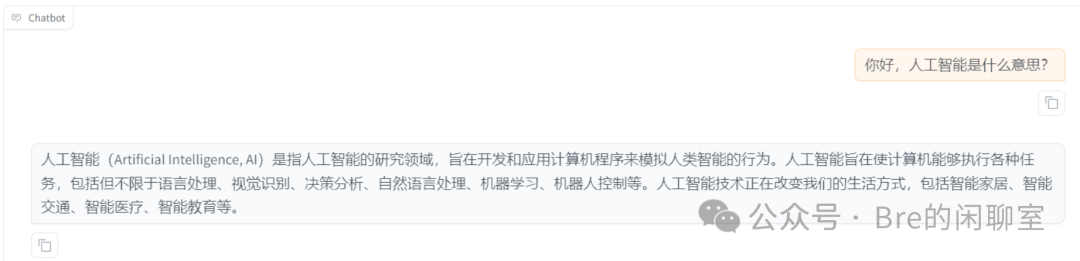
可以看出,经过我的微调训练之后,新的模型能够很好的处理和理解中文,同时也保留了其英文处理的能力,而使用数据集从零开始训练一个同水平的中文模型就需要相当多的资源和漫长的时间了。
写在结尾
对于不够熟悉的领域,我们经常会选择黑盒的模式进行接触,也就是从来不去关注内部的过程,只关心其结果。在大模型领域,绝大多数人还是作为一个普通用户去考虑它,在心理上将它视为接近于人的智能助手。提到大模型的训练、微调,认为是一件无法触及的事情,但其实深究到底,要我来说,大模型的本质就是对自然语言进行了数据量足够大的高度建模,使得其得到了很好的泛化效果。想到这里,去考虑调整一个函数在对应数据集上的拟合程度似乎真实具体了不少,也更加具有操作性,所以追求探索事物的本质、对不了解的技术保持好奇心仍然是无比珍贵的品质。
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)