RAG架构图的解析和对RAG、嵌入模型、向量嵌入和向量数据库的理解
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的技术,旨在通过动态引入外部知识提升生成模型的准确性和相关性。其工作流程包括:嵌入模型将高维数据转化为低维向量,保留语义信息;非结构化数据加载器处理各类文档;文本切分改善检索和生成效果;向量嵌入捕捉语义关系;向量数据库存储和检索高维向量。RAG通过相似性搜索找到准确答案。
今天得到一张RAG的架构图,然后看了关于RAG讲解的视频,在这里对自己的学习做个总结
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的技术,旨在通过动态引入外部知识来提升生成模型输出的准确性和相关性。
RAG带来的好处:
- 能减少幻觉问题
- 能够为大语言模型注入最新资讯及特定领域的关键信息,帮助模型生成更精准、更贴合需求的回答
- 在实际应用中,模型微调(fine-tuning)不仅成本高昂,而且每当模型更新时,都需要重新进行这一复杂过程相比之下,RAG提供了一种高效而低成本的方案,因此成为推动AI技术落地实施的关键手段之一
其工作过程可看下图:
(该图形是我老师给的)
一、嵌入模型
嵌入式模型(Embedding)是一种机器学习模型,被广泛应用于自然语言处理(NLP)和计算机视觉(CV)等领域。其主要作用是将高维度的数据转化为低维度的嵌入空间,同时保留原始数据的特征和语义信息,从而提高模型的效率和准确性。嵌入式模型可以通过学习数据之间的关联性,将相似的数据映射到相近的嵌入空间中,使得模型能够更好地理解和处理数据。 嵌入式模型的原理基于分布式表示的思想,通过将每个数据点表示为一个向量,将数据的语义信息编码到向量空间中。这样做的好处是可以利用向量空间的性质,比如向量之间的距离可以表示数据的相似度。常见的嵌入算法有Word2Vec和GloVe等,在NLP领域中,这些算法可以将单词映射到向量空间中,使得模型可以更好地理解文本。
二、非结构化数据加载器(Unstructured Loader)

针对知识库内各类格式的文档,可以是结构化数据(二维表)、非结构化文本(PDF、Word、TXT等格式)进行处理,其中非结构化数据加载器(Unstructured Loader) 是数据预处理流程的核心组件,负责将原始非结构化数据(如PDF、PPT、网页等)转换为可供检索和生成模型使用的结构化或半结构化文本。其作用至关重要,直接影响了后续检索和生成的质量。
三、文本切分
文本切分的质量直接决定了检索的准确性和生成模型的效果。将文本切割成块或段的过程叫做文本分块,能够显著改善信息检索和内容生成效果,提供更精准,更相关的结果。
切分的文本块将由Embedding Model(嵌入模型)转换为向量,Embedding Model是一种机器学习模型,可以将高维输入数据,如文本、图像,转换为低维向量。在RAG中,嵌入模型将文本块转换为向量,这些向量捕捉了文本的语义信息从而可以在海量文本框中检索相关内容,有多种模型可以用来生成向量嵌入。如:OpenAI的text-embedding-3-large模型。不同模型生成的向量嵌入模型会有所不同。
四、向量嵌入

向量嵌入是用一组数值表示的数据对象,在多维空间中捕捉文本、图像或音频的语义和关联,可以让机器学习算法能够更轻松地对其进行处理和解读将数据以数值向量的形式来进行表示
向量嵌入可以以数值形式捕捉对象间的语义关系,我们可以通过向量搜索,在向量空间中来查找相似对象
向量嵌入是将数据以数值向量的形式来进行表示
五、向量数据库
向量存储在向量数据库中,这些向量主要是由非结构化数据通过嵌入模型转化而来的,所谓的非结构化数据如文本,视频和音频,通常来源于人类生成的内容,不易于预订格式存储,这类数据可以通过转化为向量嵌入,有效的存储在向量数据库中,以便进行管理和检索,结构化数据则以表格形式存在,与非结构化数据形成对比,对于非结构化数据可以基于语义相似度进行相似性进行搜索
向量数据库是一种专门用于存储和检索高维向量数据的数据库,主要用于处理相似性搜索相关的任务,向量数据库可以存储海量的高温向量这些向量可以表示数据对象的特征。
向量数据库可以作为AI系统的长期记忆库
六、向量数据库和传统数据库的区别:
传统数据库主要存储结构换数据,数据以行和列形式组织,适用与存储明确的数据类型如整数字符串日期等,通过精确匹配关键词来检索数据,适用与结构化数据的高效查询。
向量数据库专注于存储和检索高位向量数据,通常用于处理非结构化数据,如图像文本和声音经过特征提取后的向量表示,侧重与相似性搜索,通过语义理解来检索相关结果,不依赖精确匹配来检索相关搜索结果,对拼写错误和同义词有较好的包容性
七、如何衡量向量的相似性
通常我们可以通过欧氏距离、余弦相似度、点击相似度、欧几里德距离,用于测量高维空间中两点之间的直线距离,余弦相似度通过计算两个非零向量的夹角的余弦值,来衡量他们之间的相似性,它常用与基于文本的数据,点积计算的是两个向量的模长乘积和它们之间夹角的余弦值的乘积,点积会受到向量的长度和方向的影响
八、检索的技术细节
检索本质上是在向量空间中寻找与查询向量醉相思的邻居
这一过程通过计算“查询向量与数据库中的其他向量之间的距离,找到距离最近的邻居,从而返回最相关的对象”
九、用户的使用过程
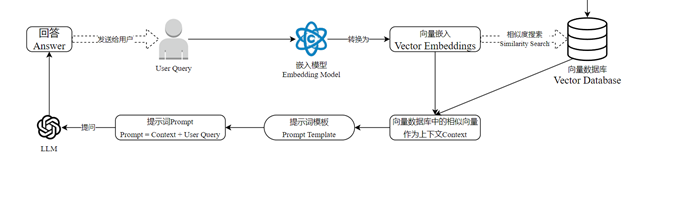
- 用户提出问题
- 问题通过嵌入模型转化为向量嵌入
- 用户的问题被转换为高维空间中的数值向量,该向量能够捕捉问题的语义特征
- 系统将该向量数据库中的其他向量进行比较,执行相似性搜索,找到最相关的数据条目,在向量数据库中检索与用户问题相关的信息的过程被称为检索(retrieval)
- 在检索阶段,系统会从海量的文档和数据集中找出与用户查询最为相关的内容,随后系统将进一步从中筛选出排名靠前的N个文本片段,接下来在检索出的N个文本片段基础上,进一步根据与用户查询的相关性和上下文适配度进行重新调整
- 调整后的文本将作为上下文(context)嵌入到提示词模版(prompt template)中与用户问题相结合,从而构建出一个全新的提示词(prompt)即Prompt = Context + User Query
- 提示词再发送给大模型LLM,这样可以增强GPT的回答问和生成内容的准确性和可靠性
- 大模型生成答案提交给用户

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 55
55 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)