如何使用 Neo4j、知识图谱和 LLM 构建聊天机器人
本文介绍了如何利用知识图谱和LLM构建高效的结构化数据问答系统。作者通过医疗行业案例说明传统RAG在处理复杂查询时的局限性,提出三种GraphDB解决方案:1)简单CypherQAChain实现基础问答;2)高级查询方法通过实体提取提升复杂问题处理能力;3)结合向量索引的GraphRAG技术处理非结构化数据。以电影数据集为例,详细演示了Neo4j数据库构建、Cypher查询生成和混合检索策略的实现
在这篇文章中,我将尝试解释我在从事该项目期间对知识图谱的学习,并尝试解释如何使用它们在结构化数据集上执行问答和检索增强生成 (RAG) 的各种方法。我将提供下面提到的 3 种关键方法,您可以使用 LLM 与 GraphDB 进行聊天,为此,我将使用Neo4j Database.

最近,我正在为一位医疗行业的客户做一个项目。他们拥有大量的病历、研究论文和诊断报告,散布在数千个 Excel 文件和 PDF 文件中。每当他们需要洞察时,他们的分析师都会花费数小时有时甚至数天来交叉比对这些来源,以解答哪怕是最基本的问题,例如“哪种治疗方案最适合患有 X 疾病的患者?”
起初,我们尝试了标准的检索增强生成 (RAG) 流程,其中包含嵌入和向量数据库。对于表面查询,它效果还不错,但当问题变得更加复杂时,比如将病史与治疗结果结合起来就遇到了瓶颈。就在那时,我意识到:我们需要一个知识图谱。
在这篇文章中,我将尝试解释我在从事该项目期间对知识图谱的学习,并尝试解释如何使用它们在结构化数据集上执行问答和检索增强生成 (RAG) 的各种方法。我将提供下面提到的 3 种关键方法,您可以使用 LLM 与 GraphDB 进行聊天,为此,我将使用Neo4j Database。
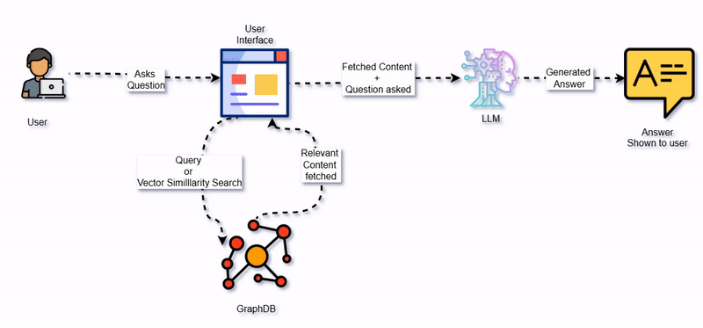
使用知识图谱和 LLM 的基本 QnA 流程
CypherQAChain:一种将自然语言问题转换为 Cypher 查询的简单方法。我将演示这种方法如何简化图谱查询并提供快速、精准的答案。
高级查询:对于更复杂的问题,我们将探索一种结合实体提取和数据库值映射的技术。这种方法非常适合处理需要更深入分析的细微查询。
基于 RAG 的方法:为了提高相关性和检索能力,我们将向量索引与知识图谱集成。通过这种方式,我们能够妥善处理作为问答任务节点属性存储的非结构化数据,例如文本描述。
为了解释这些方法,我将使用一个movie dataset包含电影、演员、导演、类型、ImDB 评分和上映日期信息的数据集。通过这个数据集,你将了解如何使用知识图谱和 LLM 高效地处理结构化数据集,以及如何使用 RAG 处理作为节点属性存储的非结构化数据。
在本文结束时,您不仅会了解这些技术,而且还会拥有在您的项目中亲自实现这些技术的实践知识。
一、知识图谱和 GraphDB 的基本概述
在我们开始使用知识图谱构建聊天系统之前,必须了解图数据库(GraphDB)的基本概念以及它们为何在涉及复杂、互联数据的场景中表现出色。
什么是图数据库(GraphDB)
图数据库(GraphDB)是一种旨在将数据作为实体及其关系网络进行存储和管理的数据库。GraphDB 不像传统关系数据库那样使用行和列,而是使用以下主要组件来存储数据:

这种结构使得 GraphDB 非常适合处理互联数据,尤其是在关系对于理解整体情况至关重要的情况下,例如在社交媒体平台中。在这种情况下使用 GraphDB 具有以下优势:
1. 关系的自然表达
在传统的关系数据库中,我们将用户存储在一个表中,并将他们的关系(例如“关注”或“好友”)存储在另一个表中,并使用外键。例如:
- 用户表:每一行代表一个用户。
- 关系表:使用用户 ID 跟踪谁关注谁。
虽然这种方法有效,但随着网络规模的增长,查询这些关系会变得复杂且缓慢。
在 GraphDB 中,这些关系直接建模为节点(用户)之间的边。例如: - 节点A:代表用户A。
- 节点B:代表用户B。
- Edge:代表“用户 A 关注用户 B”。
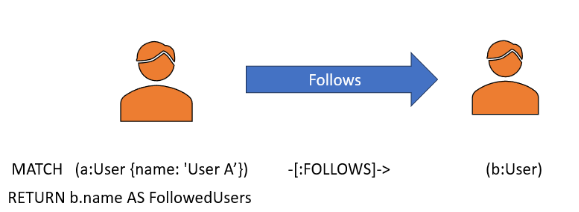
用户 A 关注用户 B 的 Cypher 查询
这种方法让我们可以直接遍历关系,比如找到“共同的朋友”或“建议的联系人”,而不需要复杂的表连接。
2. 节点和关系的语义丰富性和属性
GraphDB 允许边承载关于关系的详细信息,从而将其转换为知识图谱。例如,除了简单的“关注”边之外,我们可以定义:
- “评论”表示与帖子的互动。
- “标记”用于在照片或视频中提及。
- “反应”表示喜欢、喜爱或其他反应。
这种语义丰富性为数据增添了有意义的上下文。例如:
- 查询:“哪些用户在同一个项目上进行了合作?”
- 答案:遍历标记为“合作”的边来寻找连接
此外,GraphDB 中的每个节点和边不仅具有节点及其之间的关系,而且每个节点和边还带有属性,如下图所示,从而使它们成为知识图谱
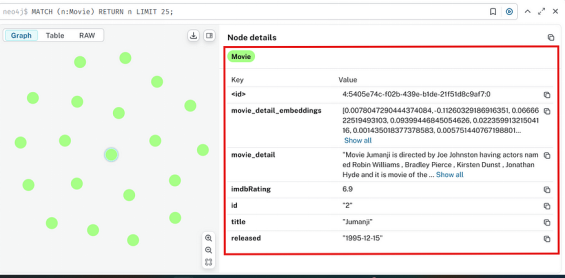
3.动态更新
GraphDB 是为动态更新而构建的,这意味着当新数据出现时,如果它属于现有的节点和边关系,那么它就会被放置在那里,否则就会形成新的节点和关系,从而动态更新数据库。
考虑不断变化的社交媒体网站的例子——新的友谊形成、帖子被分享、评论被添加。
- 添加新的关系(如“关注”或“评论”)就像添加边一样简单。
- 删除关系(如“取消关注”)会移除边缘,而不会破坏其他数据。
例如,当用户 A 关注用户 B 时,GraphDB 会立即更新,在他们各自的节点之间创建新的边。这种动态特性有助于使网络保持最新信息。
4. 遍历效率
GraphDB 针对遍历算法进行了优化,例如:
- 深度优先搜索(DFS):探索深层关系,例如两个用户之间的互动链。
- 广度优先搜索(BFS):探索所有直接连接,例如查找用户的所有朋友。
- Delta-Stepping 单源最短路径:有效计算从单个源到所有其他节点的最短路径,有助于找到网络中最快路线。
- Dijkstra 源-目标最短路径:查找两个特定节点之间的最短路径,非常适合确定两个用户之间最有效的连接。
例如,在社交媒体平台中,遍历对于以下任务至关重要:
- 朋友建议:通过遍历共同的朋友来确定潜在的联系。
- 内容推荐:根据共享标签或喜欢查找类似的帖子。
- 社区检测:识别具有共同兴趣的用户群体。
5.可解释性和可追溯性
GraphDB 可以轻松追踪用户或实体之间的连接方式。例如:
- 查询:“用户 A 如何连接到用户 C?”
- 答案:该图可能显示如下路径:
- 用户 A 关注用户 B(Edge 1)。
- 用户 B 对用户 C 的帖子 (Edge 2) 进行了评论。
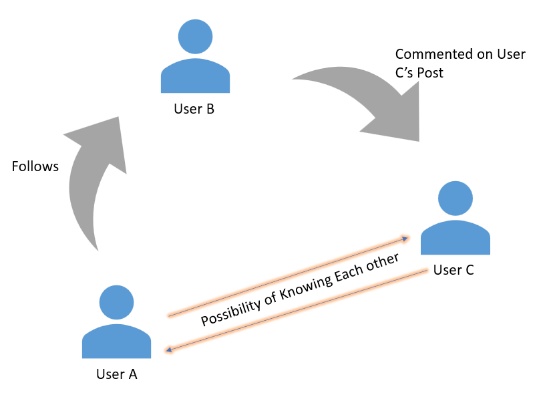
这种透明度对于调试、用户洞察以及建立对推荐算法的信任非常重要。
点个赞 🙂:如果您觉得这篇文章有用,请关注我、点赞👏,或者分享给其他可能受益的人。谢谢!我们回到正文吧
二、LLM 和 GraphDB 如何在问答应用程序中交互
为了使用知识图谱构建智能高效的聊天机器人系统,我们首先需要了解 LLM 和 GraphDB 实际上是如何协同工作的。
GraphDB,例如 Neo4j(如上所述)在存储和导航互连数据方面非常高效。它们使用节点(实体)、边(实体之间的关系)和属性(节点和边的属性)的结构来表示和管理复杂的关系。
而 LLM 则是将类似人类的非结构化输入转换为有意义的结构化查询的主要大脑。例如,如果用户问聊天机器人“谁出演了电影《盗梦空间》?”,LLM 会将这种自然语言查询转换为精确的查询语言,例如 Cypher(Neo4j 使用):
匹配(m :电影{标题: “盗梦空间” } ) - [ : ACTED_IN ] - (p :人物)
返回p.name;
然后,LLM 解释 GraphDB 检索到的结果并向用户提供对话响应,例如:“The cast of Inception includes Leonardo DiCaprio, Ellen Page, and Joseph Gordon-Levitt.”
随着编码和推理能力的不断进步,现代大型语言模型 (LLM) 已成为以下领域的卓越工具:
- 自然语言理解:将模糊或非结构化的用户查询转换为数据库的精确、可执行命令,如上所示。
- 生成类似人类的反应:将从数据库检索的数据转换为对话回复。
但它们的作用远不止于此。除了查询数据之外,LLM 还reating通过处理非结构化数据在 C 知识图谱中发挥着重要作用。
LLM 用于将非结构化数据转换为图
GraphDB 生态系统中 LLM 最令人兴奋的应用之一是它们能够将 PDF、文档形式的非结构化信息转换为结构化图数据。这涉及识别文本中与之相关的实体(节点)和关系(边)和属性,然后将它们表示为图。
示例:从文本中提取图数据
考虑一份文本文档:“莱昂纳多·迪卡普里奥出演了克里斯托弗·诺兰执导的《盗梦空间》”。
使用LLMGraphTransformer之类的工具,可以将文本转换为图:
- 节点:
- Leonardo DiCaprio人物)
- Inception(电影)
- Christopher Nolan(人物) - 关系:
- Leonardo DiCaprio→ACTED_IN→→→Inception
- Christopher NolanDIRECTEDInception
请注意,由于 LLMGraphTransformer 或类似工具使用 LLM 作为基础,因此图的构建过程是不确定的。因此,每次执行的结果可能略有不同,并且图的质量在很大程度上取决于所使用的 LLM 类型。
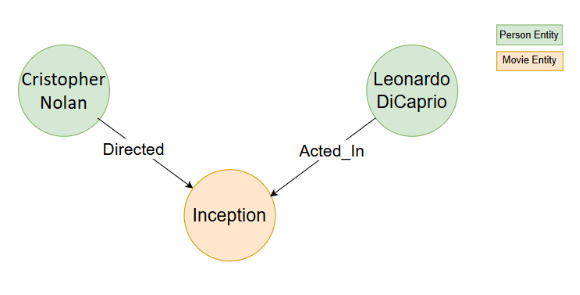
LLMGraphTransformer 使用 LLM 来
- 解析非结构化文本文档。
- 识别和分类实体(例如人物、电影)。
- 建立这些实体之间的有意义的关系。
图形成的有效性取决于所选的 LLM 模型,因为它会影响提取的图数据的准确性和粒度。
三、方法1:使用CypherChainQA进行QnA的实际实现
现在我们已经对 GraphDB 如何与 LLM 交互有了基本的了解,现在让我们使用 Langchain 框架中的 CypherChainQA 开始使用 GraphDB 的 QnA 聊天机器人的第一阶段。
Neo4j 设置:
在我们的实现中,我们将使用Neo4j,这是一个功能强大的图数据库管理系统,以其高效处理和查询图数据而闻名。Neo4j 提供了多种功能,使其成为聊天机器人开发的绝佳选择:
- Cypher 查询语言:Neo4j 使用Cypher,这是一种声明性且用户友好的查询语言,可简化检索和操作图表中数据的过程。
- 易于集成:Neo4j 提供了一个 Python 驱动程序,这使得可以轻松地从 LangChain(一种用于处理 LLM 的流行框架)直接连接数据库并与之交互。
此外,Neo4j 与 LangChain 框架的良好集成使其非常适合构建基于图的聊天机器人系统。Neo4j 与 LangChain 的集成使我们能够:

让我们设置 neo4j AuraDB
- 前往 Neo4j Aura 并登录或注册。
- 创建一个新的数据库实例。
- 实例准备就绪后,请.txt在提示时记下并下载连接凭据:
- URI(例如bolt://<your_database>.databases.neo4j.io)
-用户名(默认neo4j:)
-密码(在设置期间生成)。
使用以下代码,使用上面提到的凭据连接到 Neo4j DB:
从kaggle_secrets导入UserSecretsClient
从langchain_community.graphs导入Neo4jGraph
user_secrets = UserSecretsClient()
groq_api_key = user_secrets.get_secret( "groq_api_key" )
hf_api_key = user_secrets.get_secret( "hf_api_key" )
NEO4J_PASSWORD = user_secrets.get_secret( "NEO4J_PASSWORD" )
NEO4J_URI = user_secrets.get_secret( "NEO4J_URI" )
NEO4J_USERNAME = user_secrets.get_secret( "NEO4J_USERNAME" )
graph = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME,
password=NEO4J_PASSWORD)
print ( "已连接到 Neo4j!" )数据预处理和创建图表
现在我们已经与数据库建立了连接,现在我们可以导入数据集,对其进行一些预处理并更新 Neo4j 数据库。
步骤 1️⃣:我们首先加载一个示例电影数据集。该数据集包含电影的关键信息,例如片名、导演、演员、类型和评分。让我们读取数据并快速浏览一下:
df=pd.read_csv("https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv" , nrows= 20 )
display(df.head( 3 ))
print (df.shape)
print ( "=" * 40 )
print (df.columns)
print ( "=" * 40 )
print (df[ "title" ][: 20 ].values)步骤2️⃣:为了使数据集对于RAG任务的查询和检索更有意义,我为每部电影创建了一个详细的描述列。这些描述列结合了各种列,例如片名、导演、演员、类型、IMDb评分和上映日期。
此外,我还创建了额外的虚拟列。
detail = df[ 'title' ][ 0 ]
detail
df[ 'movie_detail' ] = df.apply( lambda row: f"电影{row[ 'title' ]}由{row[ 'director' ]}执导,
演员名为{row[ 'actors' ].replace( '|' , ' , ' )},属于 { row[ 'genres' ].replace( '|' , ' , ' )}
类型的电影。其评分为{row[ 'imdbRating' ]} \ ,上映日期为{row[ 'released' ]} "
,axis= 1 )
df.head()
# 添加地点和类似电影的自定义数据
location = [ "美国" , "美国" , "美国" , "美国" , "美国" ,
"美国美国"、"美国"、"美国"、"美国"、"英国"、"美国"、
"美国"、 "美国" 、"美国" 、 "马耳他"、 "美国"、"英国"、"美国"、"美国"、"美国" ]
similar_movie = [ 《海底总动员》、《勇敢者游戏:决战丛林》、《遗愿清单》、《伴郎假期》 、《儿女一箩筐》、《无间行者》、 《诺丁山》、 《哈克贝利·费恩历险记》 、《虎胆龙威》、 《碟中谍》、《戴夫》、《爱而不得:年轻的科学怪人》、 《小马驹》、《刺杀肯尼迪》、 《《加勒比海盗:黑珍珠号的诅咒》、《好家伙》、 《傲慢与偏见》、《低俗小说》、《变相怪杰》、《生死时速》 ]
df[ 'location'] = location
df[ 'similar_movie' ] = similar_movie
# 保存丰富的数据集以用于图构建
df.to_csv( "movie.csv" , sep= "," , index= False )步骤3️⃣:构建 Neo4j 图
现在,我们将使用处理后的数据集更新 Neo4j 数据库。该图将包含电影、导演、演员、类型、地点和类似电影的节点。这些实体之间的关系也将相应地创建。
# 创建以下输入值只是为了确保不会再次执行此代码来意外创建图value = input(“您真的要执行此单元格并再次创建 GraphDB 吗?y/n”)
movie_csv_path = 'movie.csv'
if value == 'y' :
graph.query( “””
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/manindersingh120996/RAG-Related-Projects/refs/heads/main/movie%20(1).csv'
AS row
MERGE(m:Movie {id:row.movieId})
SET m.released = row.released,
m.title = row.title,
m.movie_detail = row.movie_detail,
m.imdbRating = toFloat(row.imdbRating) FOREACH(director in split(row.director,'|')|
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m)) FOREACH (actor in split(row.actors,'|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN] ->(m)) FOREACH (genre in split(row.genres,'|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g)) MERGE (l:location {name:trim(row.location)})
MERGE (m)-[:WAS_TAKEN_IN]->(l) MERGE (s: SimilarMovies {name:trim(row.similar_movie)})
MERGE (m)-[:IS_SIMILAR_TO]->(s)
""" )为了创建图表,我们使用 Cypher 查询语言,为此我们循环遍历数据集行并创建:
- 具有标题、详情和 IMDb 评级等属性的电影节点。
- 导演节点通过关系链接到电影DIRECTED。
- 演员节点通过关系链接到电影ACTED_IN。
- 类型节点通过关系链接到电影IN_GENRE。
- 位置节点通过关系链接到电影WAS_TAKEN_IN。
- 类似电影节点通过关系链接到电影IS_SIMILAR_TO。
我们可以看到创建的图数据库的模式如下:
graph.refresh_schema ()
print(graph.schema )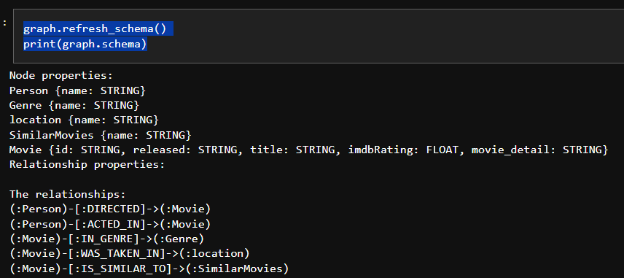
图模式的输出
GraphCypherQAChain
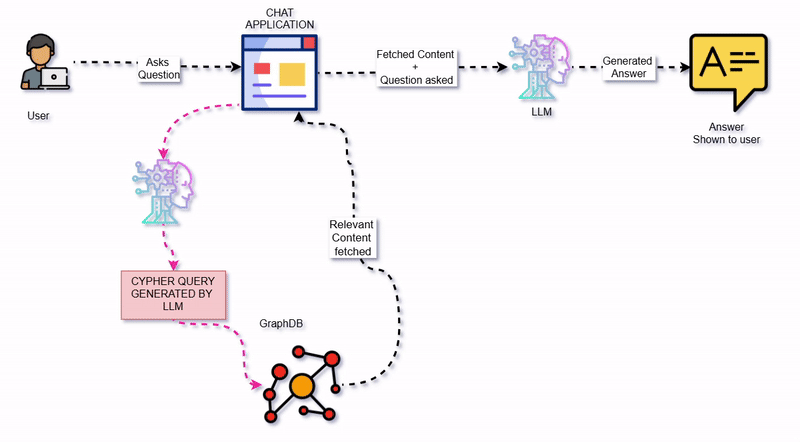
现在我们已经设置了 Neo4j 数据库,并使用所需的节点和关系对其进行了结构化,我们可以使用GraphCypherQAChain了。该链提供了一种直接有效的机制来与数据库进行交互,它接收一个问题,将其转换为 Cypher 查询,执行查询,并使用结果来回答原始问题。
为了确保 Cypher 查询的准确性和高效性,使用足够成熟的大语言模型 (LLM) 来理解和生成 Cypher 语法至关重要。选择性能不足的 LLM 可能会导致:

为了获得最佳效果,建议使用为此目的而接受过高级 LLM 培训的人员。
例如,在我使用 LLaMA 3.1 (8B) 进行测试期间,我无法获得达到标准的结果,但当我转换到 LLaMA 3.3 (70B) 时,我的系统就能够回答更复杂的查询。
GraphCypherQAChain 的实现如下:
从langchain.chains导入GraphCypherQAChain
# 我们可以将其称为简单代理,因为这里
# 我们只运行了两行代码
# 但它并不那么强大,正如我们将在问题 2 和问题 3 中看到的
那样 # 问题变得更加复杂
"""
改进此过程的一种方法是使用
能够生成准确 Cypher 查询的更强大的语言模型。例如,
我最初使用 LLaMA 3.1 (8B),它很难回答两个具体问题。
然而,升级到 LLaMA 3.3 (70B) 成功解决了第 1 个和第 3 个问题。
"""
cypher_execution_chain = GraphCypherQAChain.from_llm(graph=graph, # 这里它检索图 Schema
llm=llm_model,
verbose= True , allow_dangerous_requests= True ) respond = cypher_execution_chain.invoke({ "query" : q_one})
print(响应)print(“\nLLM 响应:”,响应[ “结果” ])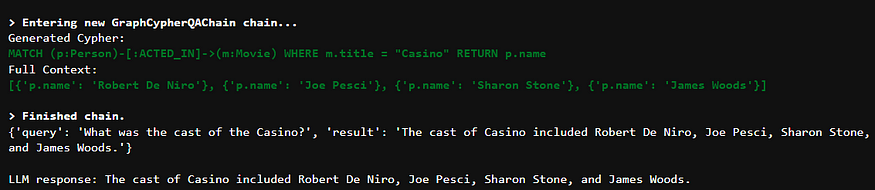
虽然对于简单的问题它可以表现良好,但一旦问题变得复杂,它就无法回答,如下所示:
q_two = "1995 年上映的电影最常见的类型是什么?"
response = cypher_execution_chain.invoke({ "query" : q_two})
print (response)
print ( " \n LLM respond:" , respond[ "result" ])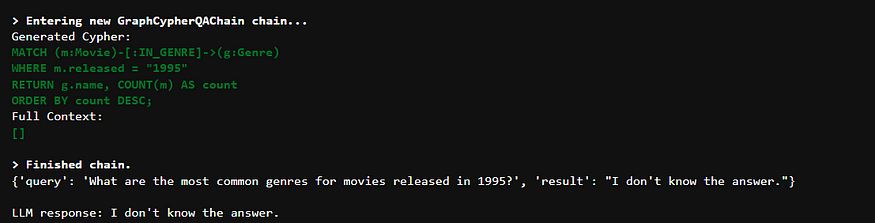
GraphCypherQAChain 在回答更复杂的问题时会遇到困难,例如包含多个条件或间接关系的问题。这表明我们需要一个更强大、更智能的解决方案来处理此类情况。
在下一节“高级查询”中,我们将看到如何通过一些附加的步骤使 QnA 系统更加健壮,例如从用户输入中提取实体等。这些步骤会逐步分解和处理复杂的查询,从而能够以更高的准确性和洞察力回答详细或分层的问题。
四、方法2:高级查询
正如我们上面所观察到的,当用户问题变得更加复杂时,例如涉及多个条件或间接关系的问题,CypherQAChain 很难提供答案。这是因为,虽然 CypherQAChain 理解数据库架构,但它并不知道数据库中的实际数据。例如,它可能识别“title”这样的属性,但不知道存在哪些电影名称。这会导致查询无法返回有用的结果。为了解决这个问题,我添加了一个映射层,将用户输入与实际数据库值进行匹配,并利用这些值创建更精确的查询,从而提高系统可靠性。
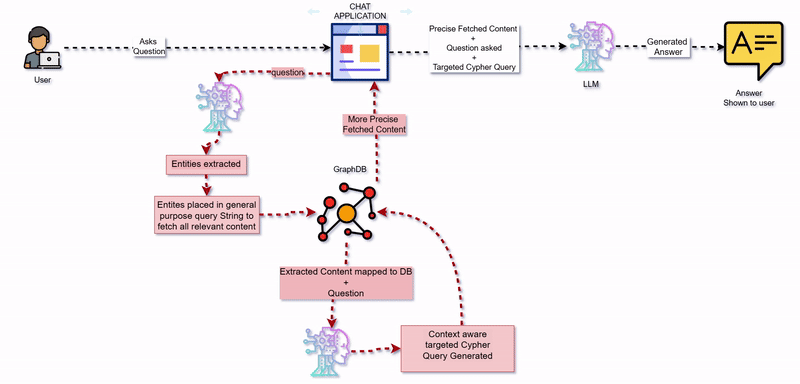
高级查询QnA流程
它的工作原理如下:
检测用户输入中的实体的第一步:对于所有用户输入查询,它会提取诸如潜在人名、电影名称和年份等实体。
从键入导入 列表:

# 从 langchain.chains.openai_functions 导入 create_structured_output_chain
从langchain.chains导入create_structured_output_runnable
从langchain_core.prompts导入ChatPromptTemplate
# 从 langchain_core.pydantic_v1 导入 BaseModel、Field
从pydantic导入BaseModel、Field、field_validator
class Entities ( BaseModel ):
"""识别有关实体的信息并
从文本中提取人物、电影和年份实体。"""
names: List [ str ] = Field(
...,
descriptinotallow= "文本中出现的所有人物、年份或电影" ,
)
entity_extractor_model = llm_model.with_structured_output(Entities)从键入导入 列表:
步骤 2:将实体映射到数据库值
一旦识别出实体,我们就会将其与实际数据库值进行匹配。为此,我使用了 LangChain 文档中的一个通用查询,以检索图数据库中节点(例如 Movie 或 Person)及其关系(例如 ACTED_IN、IN_GENRE)的详细信息。此查询提供了节点及其上下文的清晰、易读的摘要。
该过程涉及三个关键步骤:
- 使用将检测到的实体(电影、人物)插入查询中$value。
- 映射关系和连接节点以呈现相关细节。
- 为每个匹配的节点生成结构化摘要,以提高答案的清晰度和深度。
match_query = """
MATCH (m:Movie|Person)
WHERE m.title CONTAINS $value OR m.name CONTAINS $value OR m.released CONTAINS $value
MATCH (m)-[r:ACTED_IN|IN_GENRE]-(t)
WITH m, type(r) as type, collect(coalesce(t.name, t.title)) as names
WITH m, type+": "+reduce(s="", n IN names | s + n + ", ") as types
WITH m, collect(types) as contexts
WITH m, "type:" + tags(m)[0] + "\ntitle: "+ coalesce(m.title, m.name)
+ "\nyear: "+coalesce(m.released,"") +"\n" +
reduce(s="", c in contexts | s + substring(c, 0, size(c)-2) +"\n") as result
RETURN result
"""
def map_to_database ( values )-> str :
"""
将值映射到数据库中的实体并返回映射信息。Args :
values (list): 要映射到数据库中实体的值列表。 返回:
str: 一个字符串,包含每个值到数据库中实体的映射信息。
"""
result = ""
for entity in values.names:
response = graph.query(match_query, { "value" : entity})
# print(response)
try :
for values in responding:
result += f" {entity} map to {values[ 'result' ]} in database\n\n" # 查询数据库以查找实体的映射
except IndexError:
pass
return result为了提高映射效率,我们使用了 Cypher 查询,该查询利用CONTAINS子句来查找匹配项。为了提高灵活性(例如解决拼写错误),还可以使用模糊搜索或全文索引等技术。
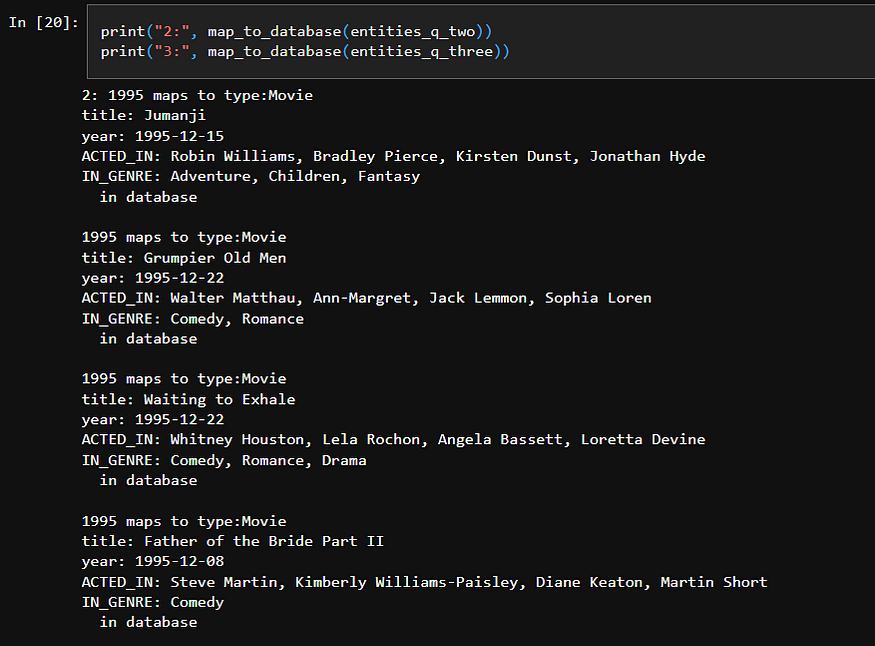
步骤 3:生成上下文感知的 Cypher 查询
使用提取的信息和数据库模式,我们创建了一个准确且针对用户问题定制的 Cypher 查询。此自定义 Cypher 查询确保其涵盖数据库中所有相关的属性、关系和数据值。
从langchain_core.output_parsers导入StrOutputParser
从langchain_core.runnables导入RunnablePassthrough # 根据自然语言输入生成 Cypher 语句
cypher_template = """基于下面的 Neo4j 图模式,编写一个 Cypher 查询来回答用户的问题:
{schema}
问题中的实体映射到以下数据库值:
{entities_list}
问题:{question}
注意:请勿在回复中包含任何解释或道歉。
请勿将回复包裹在任何反引号或其他任何内容中。
仅使用 Cypher 语句回复!
Cypher 查询:""" cypher_prompt = ChatPromptTemplate.from_messages(
[
(
"system" ,
"Given an input question, convert it to a Cypher query. No pre-amble.." ,
),
( "human" , cypher_template),
] )
# cypher_prompt.invoke({'schema'})
chain = cypher_prompt | llm_model.bind(stop=[ "\nCypherResult:" ])| StrOutputParser()步骤 4:根据数据库结果生成答案
现在我们有了生成目标 Cypher 查询的链,我们需要对数据库执行 Cypher 查询并将数据库结果发送回 LLM 以生成最终答案。
from langchain.chains.graph_qa.cypher_utils import CypherQueryCorrector, Schema
# 用于关系方向的 Cypher 验证工具
Corrector_schema = [
Schema(el[ "start" ], el[ "type" ], el[ "end" ])
for el in graph.structured_schema.get( "relationships" )
]
cypher_validation = CypherQueryCorrector(corrector_schema) # 根据数据库结果生成自然语言响应
respond_template = """根据问题、Cypher 查询和 Cypher 响应,编写自然语言响应:
问题:{question}
Cypher 查询:{query}
Cypher 响应:{response}""" respond_prompt = ChatPromptTemplate.from_messages(
[
(
"system" ,
"给定输入问题和 Cypher 响应,将其转换为自然
语言答案。给出答案以结构化的格式,让用户在视觉上更容易阅读。"
"没有前言。" ,
),
( "human" , respond_template),
]
) chain_2 = respond_prompt | llm_model | StrOutputParser()将上面提到的所有代码组合在一个管道中,将得到问题 2 的结果,其中上述方法 1 失败了,如下所示:
def questions_asked(question_asked:str):
question = question_asked
entities = entity_extractor_model.invoke(question)
entities_list = map_to_database(entities)
schema = graph.get_schema
chain = cypher_prompt | llm_model.bind(stop=[ “\nCypherResult:” ])| StrOutputParser()
cypher_query = chain.invoke({ 'schema' : schema,
'entities_list' : entities_list, 'question' : question}) print ( f"Cypher 查询生成 : {cypher_query} " )
print ( "=" * 40 )
graph.query(cypher_query) final_answer = chain_2.invoke({ 'response' : graph.query(cypher_query),
'query' : cypher_query,
'question' : question}) print ( f'问题的最终答案 : " {question} " --> \n {final_answer} ' ) questions_asked(q_two)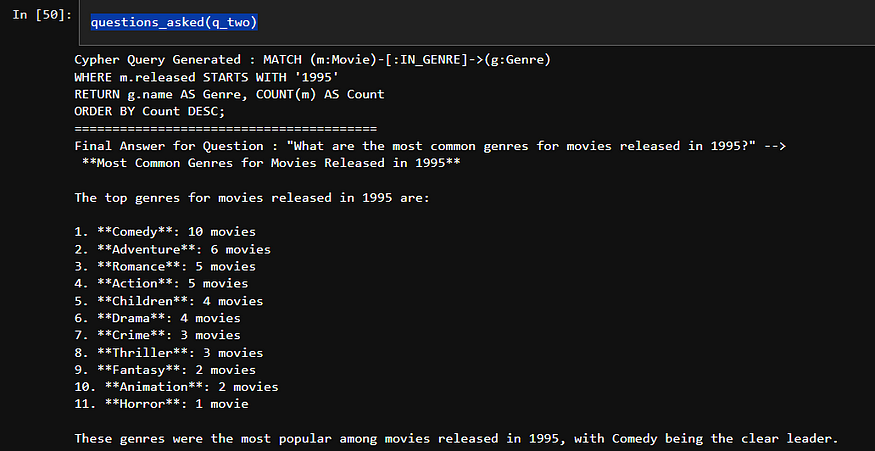
我们发现,这种方法成功地解答了 CypherQAChain 所欠缺的问题。这种额外的上下文信息使 LLM 能够生成更精确的 Cypher 查询,从而只检索最相关的信息。
在我的实验中,这种方法在所有测试案例中都完美地运行,尽管我可能错过了一些边缘情况。
到目前为止,我们重点介绍了 Cypher 查询生成、数据检索和答案生成。接下来,我们将深入探讨如何使用 Neo4j GraphDB 构建一个基本的检索增强生成 (RAG) 流程。
五、方法 3:使用 RAG 和 GraphDB(neo4j)
到目前为止,我们一直专注于结构化文本数据,但如果数据集中也包含非结构化文本呢?这正是 Neo4j 等知识图谱真正擅长的地方。它们可以将结构化和非结构化数据以及 RAG 任务所需的非结构化数据嵌入存储在一个地方。这简化了向 LLM 提供检索增强生成 (RAG) 所需上下文的过程。
GraphRAG 是一种利用知识图谱增强上下文检索的 RAG 方法。在本节中,我将演示如何使用 LangChain 和 Neo4j 实现 GraphRAG。我们将使用在预处理过程中,通过组合所有相关列,创建的附加列movie_details来构建 RAG 的向量索引。
当在 GraphRAG 中仅使用单个属性来检索所有相关信息时,建议使用我们确信能够根据预期问题保存足够所需信息的属性。
步骤 1:对于 GraphRAG,第一步是创建所选字段的向量嵌入,如下所示:
我们将为“影片详情”列创建向量嵌入,并将这些嵌入存储在名为movie_detail_embeddings的新列中。这些嵌入随后将用于填充GraphDB 中“影片详情”的向量索引,从而实现 RAG 任务期间的高效检索。
导入torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
embeddings = HuggingFaceEmbeddings(model_name= "jinaai/jina-embeddings-v3" ,
encode_kwargs = { 'normalize_embeddings' : True },
model_kwargs = { 'device' : device, 'trust_remote_code' : 'True' ,})
def embed_text ( text: str )-> List :
"""
使用指定的模型嵌入给定的文本。 参数:
text (str): 要嵌入的文本。 返回:
List: 包含文本嵌入的列表。
"""
respond = embeddings.embed_query(text) return respond embedding_list = [embed_text(i) for i in df[ "movie_detail" ]]
embedding_list
print ( "Number of向量:”,len(embedding_list))
print(“嵌入维度:”,len(embedding_list [ 0 ]))
embedding_list [ 0 ][: 5 ] df [ “movie_detail_embeddings” ] = embedding_list
df.head(3)
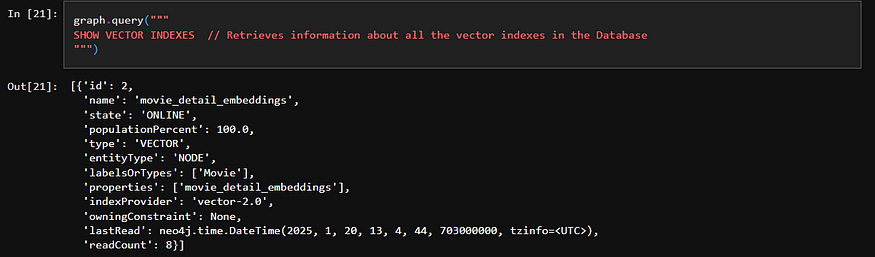
步骤 2:在 neo4j DB 中创建空向量索引,稍后我们将使用步骤 1 中创建的嵌入来填充该索引。
我们将设置一个与嵌入模型具有相同维度的空向量索引,并指定用于检索的相似度函数,如下所示。
# 这里将在 graphDB 中创建向量索引
# 目前它是空的
# 创建下面的输入值只是为了确保不会再次执行此代码来创建向量索引
value = input ( "Do You really want to perform this cell and create the Vector Index again ? y/n" )
if value == 'y' :
graph.query( """
CREATE VECTOR INDEX movie_detail_embeddings IF NOT EXISTS // 如果不存在,则创建一个名为 'movie_tagline_embeddings' 的向量索引
FOR (m:Movie) ON (m.movie_detail_embeddings) // 索引 Movie 节点的 'taglineEmbedding' 属性 OPTIONS { indexConfig: { // 设置索引选项
`vector.dimensions`: 1024, // 指定向量空间的维数(1024 维)
`vector.similarity_function`: 'cosine' // 指定相似度函数余弦相似度
}}"""
)
graph.query( """
SHOW VECTOR INDEXES // 检索有关数据库中所有向量索引的信息
""" )
步骤 3:使用步骤 1 中创建的向量嵌入填充向量索引
# 使用向量嵌入值填充数据库中的向量索引
# 创建下面的输入值作为安全措施,以防止意外重新执行此代码,
# 这可能会无意中重新创建图。
value = input(“您真的要执行此单元格并再次填充向量索引吗?y / n”)
if value == 'y':
for index,row in df.iterrows():
movie_id = row [ 'movieId' ]
embedding = row [ 'movie_detail_embeddings' ]
graph.query(f“MATCH(m:Movie {{id:' {movie_id} '}})SET m.movie_detail_embeddings = {embedding} “)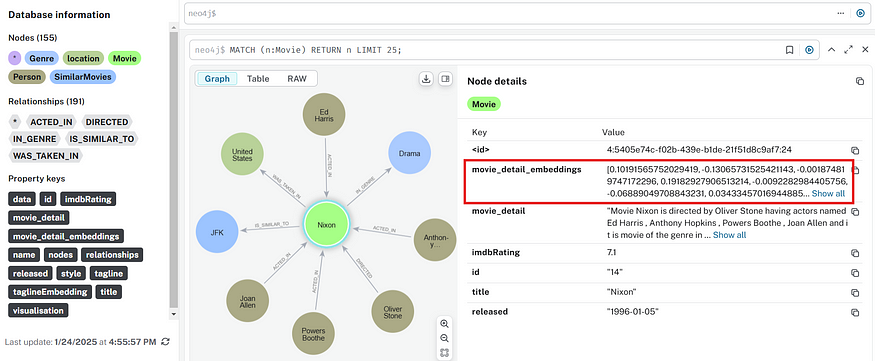
现在,我们已经使用所需的向量索引和嵌入创建并更新了图数据库,现在我们可以使用以下代码对输入查询执行向量搜索:
result = graph.query( """
with $question_embedding as question_embedding
CALL db.index.vector.queryNodes( 'movie_detail_embeddings',
$top_k,
question_embedding
) YIELD node AS movie, score
RETURN movie.title, movie.movie_detail, score
""" ,
params={
"question_embedding" :question_embeddings,
"top_k" : 3
}) import pprint
pprint.pprint(result)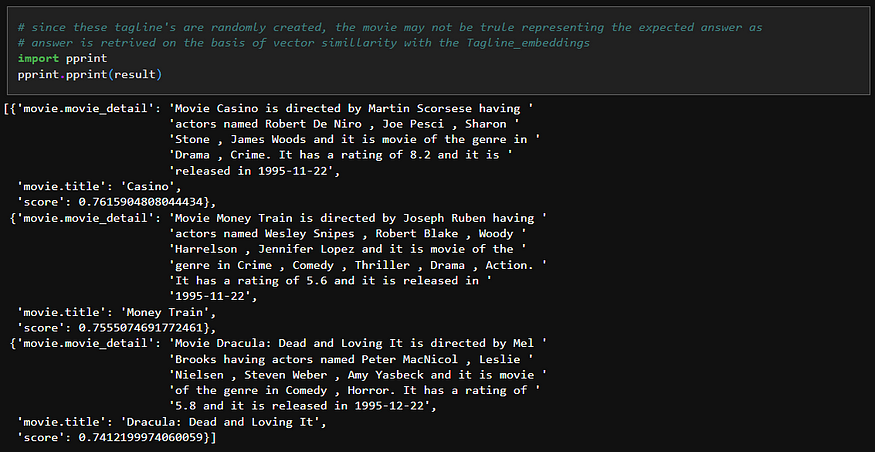
prompt = f"# 问题:\n {question} \n\n# 图数据库搜索结果:\n {result} "
messages = [
{ "role" : "system" , "content" : str (
"您将获得用户问题以及该问题在 Neo4j 图数据库上的搜索结果。给用户正确的答案。"
)},
{ "role" : "user" , "content" : prompt}
] respond = llm_model.invoke(messages) print (response.content)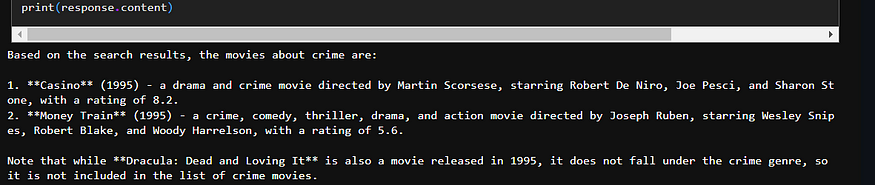
上述完整代码可以在单个流水线中编译,如下所示:
def rag_pipeline ( question: str ):
question_embeddings = embed_text(question)
result = graph.query( """
with $question_embedding as question_embedding
CALL db.index.vector.queryNodes(
'movie_detail_embeddings',
$top_k,
question_embedding
) YIELD node AS movie, score
RETURN movie.title, movie.tagline, score
""" ,
params={
"question_embedding" :question_embeddings,
"top_k" : 5
})
prompt = f"# Question:\n {question} \n\n# Graph DB 搜索结果:\n {result} "
messages = [
{ "role" : "system" , "content" : str (
"您将获得用户问题以及该问题在 Neo4j 图数据库中的搜索结果。请给用户正确的答案。"
)},
{ "role" : “用户”,“内容”:提示}
]response = llm_model.invoke(消息)return responseanswer = rag_pipeline(“关于冒险的电影都有哪些?”)至此,我们已经探索了 GraphDB 上的检索增强生成 (RAG),需要注意的是,虽然 RAG 和查询生成本身都很强大,但在检索相关内容方面各自都存在局限性。为了克服这些挑战并构建更可靠的系统,可以采用一种混合方法:
- Agentic Workflows:允许代理根据用户的问题在 RAG 或查询生成之间动态选择。
- 并行执行:同时运行 RAG 和查询生成管道,组合它们的输出,并向用户提供统一的答案。
这种混合方法同时使用结构化和非结构化数据,从而创建一个能够有效处理复杂查询的强大系统。
六、小结
在这篇文章中,我分享了关于知识图谱的学习成果,包括它们如何与大型语言模型 (LLM) 协同工作,以及如何使用它们构建结构化数据聊天机器人。我介绍了一些简单的方法,例如 CypherQAChain,以及一些更高级的方法,例如用于处理非结构化数据的 GraphRAG。这些技术帮助我实现了一个医疗保健项目的自动化,节省了数小时的手动工作,并在几分钟内给出了准确的答案。
我力求简洁,以便初学者也能通过知识图谱轻松上手使用聊天机器人。通过尝试这些方法和代理工作流,您可以创建一个高效灵活的系统,即使面对复杂的查询也能轻松应对。
这只是使用结构化数据的一个例子。非结构化数据,例如 PDF、文档甚至视频中的文本,则是一个完全不同的挑战。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

😝有需要的小伙伴,可以扫描下方二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)