[论文+源码] DeepSeek V3 最新论文 之 DeepSeekMoE
继续介绍DeepSeek上周三发布的关于V3的论文,今天要说的是。本文还会结合24年的论文与的 21年的论文。
继续介绍DeepSeek上周三发布的关于V3的论文【Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures】,今天要说的是 DeepSeekMoE。
本文还会结合
DeepSeekMoE24年的论文 【DeepSeekMoE: Towards Ultimate Expert Specialization in
Mixture-of-Experts Language Models】 与Switch Transformer MoE的 21年的论文 【 Switch Transformers: Scaling to Trillion Parameter Models
with Simple and E cient Sparsity】
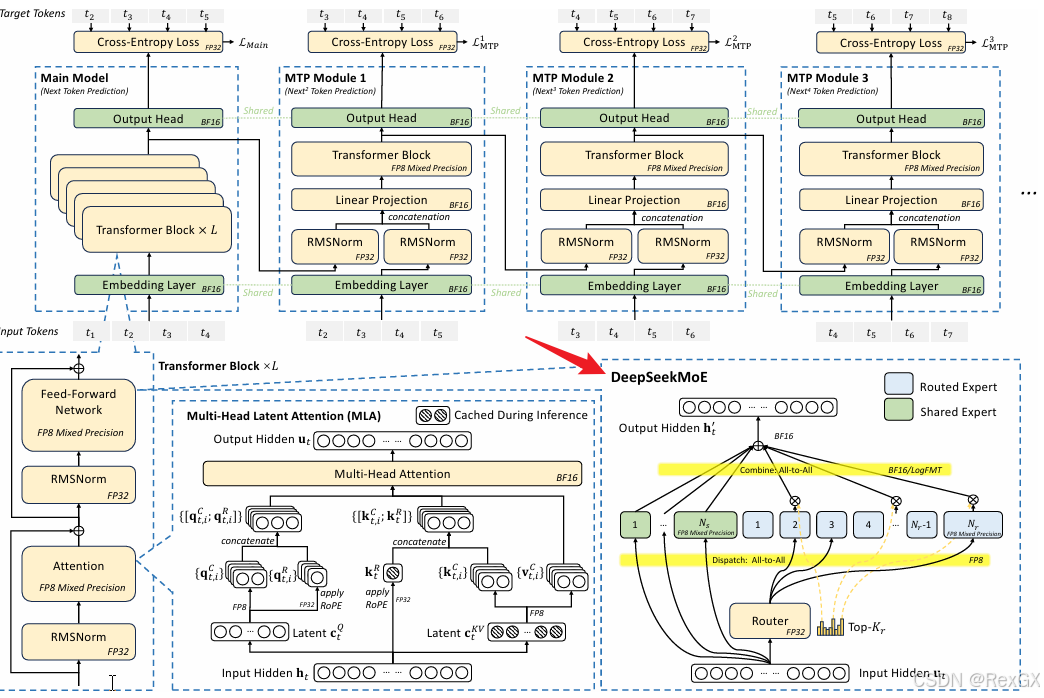
MoE
不是所有的牛奶都是特仑苏,所以在深入DeepSeekMoE之前,先来看看普通的MoE。
MoE(Mixture-of-Experts 混合专家)的核心思想很简单,下面这个最经典的例子一看就明白:
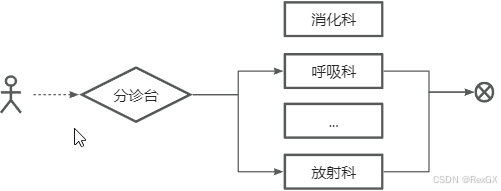
当小帅身体不舒服来到医院的导诊处后,导诊会结合小帅的病症,引导他去最相关的科室,这其中有几点要理解:
- 医院有几十个科室,不可能每一个病人每次去医院都把所有科室走一遍,医生干不过来,病人也等不起(时间太长)
- 每一个科室就相当于一个
Expert - 由分诊台决定病人去哪个科室就医,所以它相当于一个
Router的角色 - 分诊台根据病症的最相关性进行分配,也就是
Router分配Expert的Top-K策略
把上述例子映射到MoE,就变成了: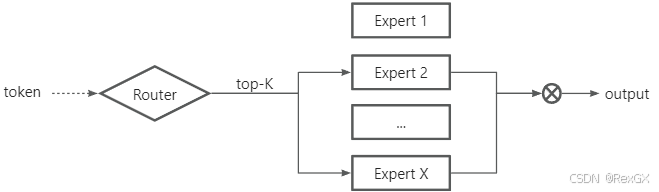
token经过Router 通过 Top-K 策略 sparse(稀疏) 的路由,只激活部分Expert,而非像Dense(传统神经网络)一样激活所有参数。
下面以Switch Transformer 的MoE 举例,看下在 DeepSeekMoE 出现前的 MoE 长啥样: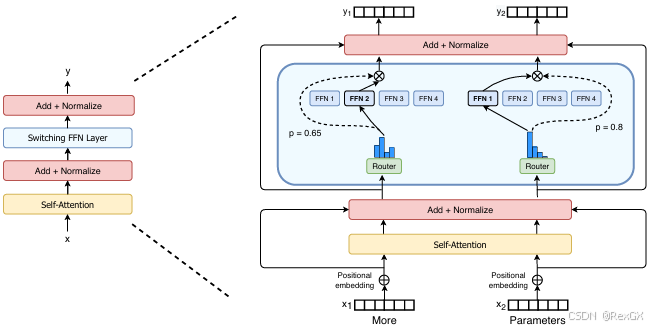
可以看到,用MoE替换掉了普通的FFN(feed forward network),对于下面input的两个token,通过Rouer路由到了不同的Expert进行处理。
接下来对比一下MoE的优劣势:
MoE的优势:
- 大模型实现了
低计算成本:总参数量很大,但实际计算量只激活部分参数 - 任务
专业化和模块化:不同专家专注于特定领域 扩展性强:可以通过增加专家,而非增加模型的层深、层宽去扩展模型并行计算友好:专家间的低耦合,天然的适合分布式训练和硬件加速
MoE的劣势:
- 难train:主要体现在
负载不均衡,某些专家会被过度激活,也就是越厉害的越厉害,越差的越差 - 专家过拟合:如果专家过度专业化,会导致整个模型在其他领域的表现下降
DeepSeekMoE
既然普通MoE会存在上述问题,那就来看看DeepSeekMoE如果实现的突破,主要有3点: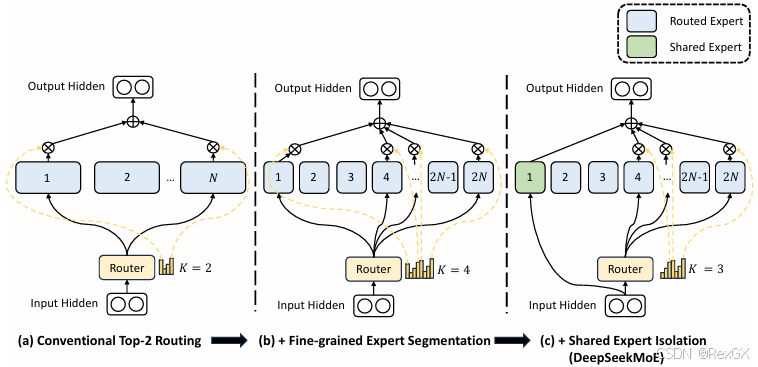
更细粒度的专家细分(Fine-Grained Expert Segmentation):如果专家数量过少,例如医院里的医生很少,那么每个医生需要处理的case就越多越杂,不利于专家对某一领域知识的掌握,所以DeepSeekMoE做的第一步就是扩充专家数量,同时Top-K也进行扩充,这样Router在选择专家的时候,就会有更多的 专家组合。通用专家(Shard Expert Isolation):还拿医院举例,现在只要去医院不论什么病,医生都会先让你去验血拍片,这种每个Expert都具备的 通用 能力可以拿出来作为独立的Shard Expert,每个token都会激活。负载均衡(Load Balance):为了防止出现Expert负载不均衡的情况,DeepSeekMoE设计了Balance Loss,希望让每个专家被调用的频率相同, l o s s b a l a n c e = ∑ 1.. N f i ∗ p i loss_{balance} = \sum_{1..N}f_i*p_i lossbalance=∑1..Nfi∗pi ,其中 f i = 某个专家被调用的次数 所有专家被调用的次数 f_i = \frac{某个专家被调用的次数}{所有专家被调用的次数} fi=所有专家被调用的次数某个专家被调用的次数, p i = a v g ( 一个 b a t c h 的所有 t o k e n 对某个专家路由概率 ) p_i=avg(一个batch的所有token对某个专家路由概率) pi=avg(一个batch的所有token对某个专家路由概率)
通过上述改进,DeepSeekMoE 对比Dense和普通MoE,实现了很大提升: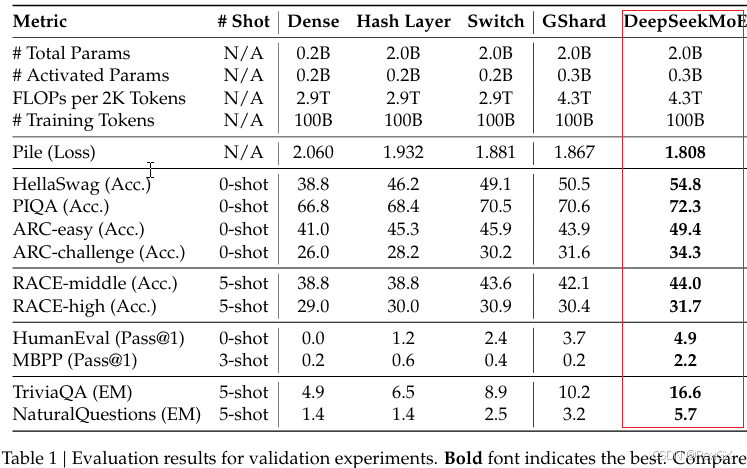
最后再来看下DeekSeekMoE的核心代码:
代码以当前2025年5月21日为准,代码取自 Hugging face deepseek-moe-16b-base

以上,介绍了普通MoE架构,以及DeepSeekMoE做了哪些改进,下一篇继续介绍论文中的另外一块重要内容 MTP。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)