AI应用开发---全套技术+落地方向
AI大模型应用开发---全套技术+落地方向AI开发主流方向Prompt工程大模型开发框架介绍LangChainLLamaIndex大模型社区Embedding与向量数据库微调量化多卡训练模型部署模型评估RAGOpenWebUI主流模型选择AutoGen
AI大模型应用开发---全套技术+落地方向
建议在对大模型有一定认识的基础上再阅读本文,本文的目的是给刚接触大模型开发的同学们梳理一下技术框架
AI开发主流方向
目前已知的AI应用能够真正落地的只有RAG和增量微调,全量微调对绝大部分企业来说不切实际,只有前面二者是普通企业能承担的起的,而在落地项目中很多是采用RAG与微调结合的方式来做,下面会对这两块做出详细阐述。
RAG与微调的区别
首先一句话概括:
RAG是增加知识面,而微调是增强能力
下面是详细版本
RAG无需改权重,通过检索外部知识库并与提问拼提示生成答案,更新快且溯源清晰。(aws.amazon.com, ibm.com)
增量微调在少量新数据上继续训练或插入低秩/适配器参数,使模型权重吸收新知识并留旧能力。(blog.csdn.net, redhat.com)
前者成本低、避灾难遗忘,但品质依赖检索与索引。(zhuanlan.zhihu.com)
后者推理无检索,延迟小,适离线硬件,但训练耗时且易过拟合。(redhat.com)
常组合:先微调嵌入器或技能,再用RAG注入实时资料降幻觉。(wired.com, wsj.com)
Prompt工程
首先说一句,一定一定不要觉得提示词不重要
Prompt(提示词)是人为构造的输入序列,用于引导大型语言模型(如 GPT)基于上下文生成符合预期的输出。Prompt Engineering(提示词工程)即设计、优化提示词的过程,其质量直接决定模型输出的准确性、完整度和可控性。
重要性:
- 提升生成准确性:明确指令、提供上下文,可让模型更好理解用户意图。
- 扩展应用场景:借助多轮、分步提示等技术,可完成从数据处理到创意生成、风险评估等多种任务。
- 提高效率:预先设计好格式与模板,减少模型「猜测」时间,快速得到所需结果。
Prompt Engineering 定义
通过设计与优化 Prompt,使模型在交互中以最佳方式完成特定任务的技术与方法。
最佳实践
-
明确目标
- 不清晰: “告诉我关于气候变化的事。”
- 清晰: “简要说明气候变化主要原因及其对农业的影响,不超过100字。”
-
提供上下文
- 无上下文: “解释一下微积分。”
- 有上下文: “作为一名高中生,简明扼要地解释微积分基本概念。”
-
使用具体指示
- 模糊: “写篇关于技术的文章。”
- 具体: “撰写一篇关于人工智能在医疗领域应用的文章,包含应用场景、优势与挑战。”
-
提供示例
-
无示例: “生成产品报告。”
-
有示例:
- 产品名称: - 价格: - 优点: - 缺点:
-
-
分步引导
- 一步完成: “解决2x+3=7。”
- 分步完成: “先解释解方程方法,再解2x+3=7。”
-
控制输出长度
- “用不超过50字总结该篇新闻。”
-
占位符与模板
- 如:“生成用户注册表单,字段包括用户名、密码、邮箱、电话。”
-
反复试验与迭代
- 根据初次输出效果,不断调整提示词内容、格式或上下文信息。
-
指定输出格式
- JSON、Markdown、表格或代码块等,确保后续无缝处理。
-
多轮对话
- 在模型初步回答后,通过追加提问,逐步细化和完善结果。
提示技术
- Zero-shot:无示例,模型凭预训练知识完成任务。
- Few-shot:提供少量示例,帮助模型理解任务格式与风格。
- Chain-of-Thought:引导模型展示中间推理步骤,解决复杂问题。
- ReAct:结合“反应(Reaction)”与“行动(Action)”,先得信息再执行后续步骤,如先查询天气再提出穿衣建议。
- Reflexion:让模型在生成初稿后进行自我反思与修正,提高准确性。
- Prompt Chaining:将任务拆分成多个子Prompt,按顺序调用,系统化解决复杂问题。
结构化输出
通过设计专门的提示,使模型输出符合预期格式,便于自动化处理。
- JSON:适用于数据交互、API 调用等场景。
- Markdown:生成文档、可读报告。
- 表格:以 Markdown 表格形式展示数据。
- 代码块:输出特定编程语言代码片段。
应用场景
- 数据处理:清洗、转换、汇总,如将 CSV 转换为 JSON、标准化日期格式等。
- 代码生成与优化:快速生成函数定义、脚本,或对已有代码进行性能优化建议。
- 分类与分析:文本情感分析、分类标签;风险评估与安全建议。
- 创意与内容生成:短篇故事、广告文案、技术报告撰写、项目总结。
- 多模态任务:结合文本与图像提示,实现图文并茂的输出。
- 汇总与总结:提炼长文要点,生成要点列表或简明结论。
图像方面的正常企业用不到,所以这里也就不介绍了
大模型开发框架介绍
大模型开发框架现在有两套可供选择,分别是Langchain生态和Llamaindex框架,Langchain就可以理解为AI应用开发界的Spring,而llamaindex则是一个相对轻量化的框架。
在选择方面,如果进行RAG应用开发,强烈推荐使用llamaindex,并且llamaindex集成了langchain的功能。如果是需要涉及到事件流,则选用langchain,因为langgraph可以完美满足你的需求。
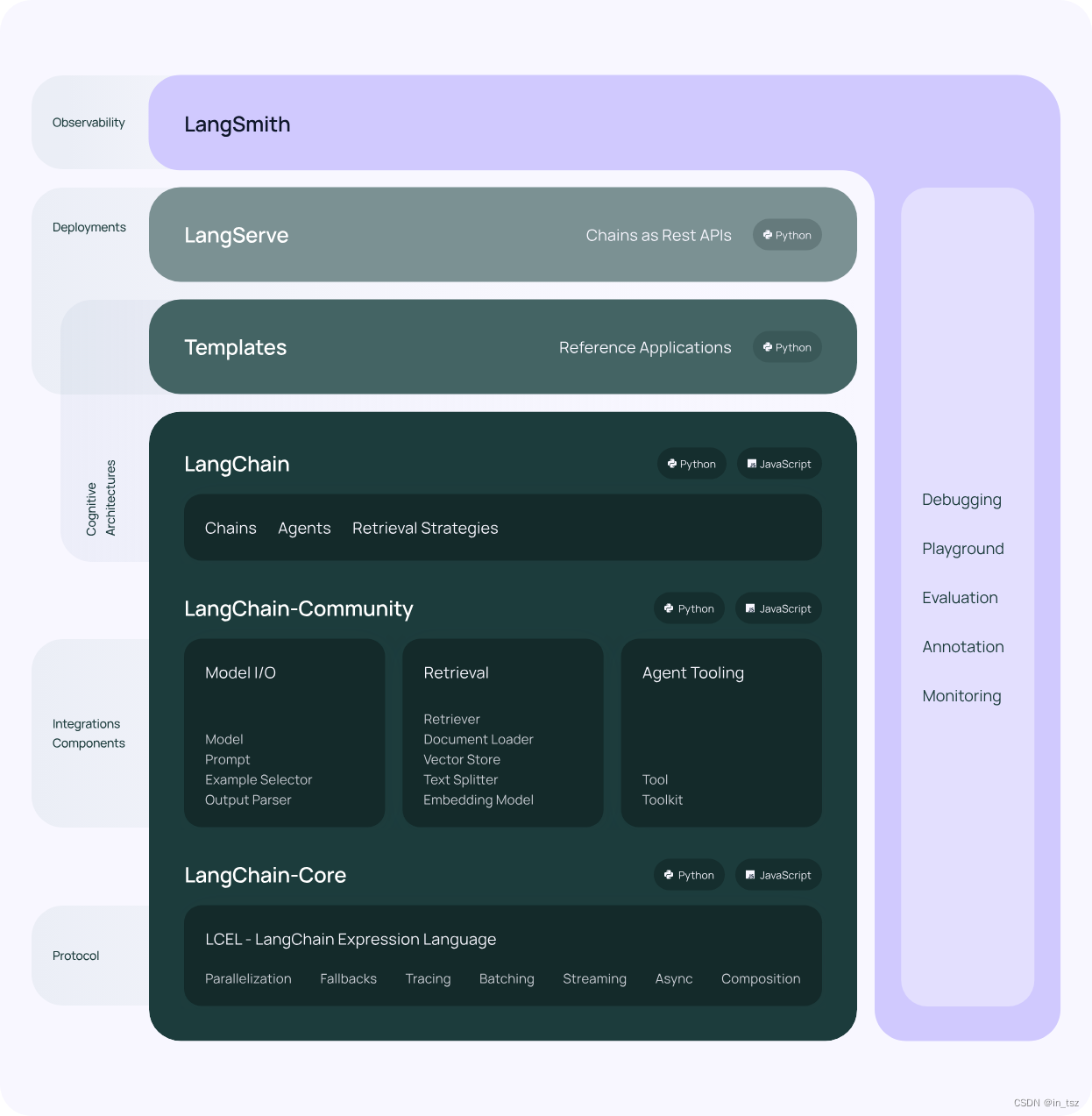
LangChain
LangChain是开发语言模型应用的框架,能连接大语言模型与数据库、API等外部资源,通过“链”和“代理”机制整合多步交互逻辑。它以组件化设计支持自定义流程,具备工具调用、记忆管理、上下文处理等能力,助力开发者构建智能问答、文档分析、代码生成等交互式应用,提升大模型应用的灵活性与实用性。
LangChain基础组件
- PromptTemplate(提示词模板)
PromptTemplate 把一段“带占位符的提示词”做成可复用对象;占位符可以用 f-string、Jinja2、Mustache 等语法替换,生成最终 prompt 后再送入模型。
这里给个模板:
请根据以下信息⽣成⼀份 Markdown 格式的报告:
- 标题:⽓候变化对农业的影响
- 引⾔:简要介绍⽓候变化的背景。
- 影响:详细描述⽓候变化对农业的具体影响。
- 结论:总结并提出应对措施。
示例格式:
# 标题
## 引⾔
内容
## 影响
内容
## 结论内容
-
LLM
调用本地部署大模型或者使用HuggingFace这种平台的接口或者企业私有接口都可以,后面会讲本地部署大模型的三种方案。 -
chain
chain的用处就跟字面上一样,链把“调用模型→解析结果→再调用工具或检索”等多步操作串成可复用流程,并内置顺序链、路由链、多检索 QA 链等常见模式 。每个节点既能是模型,也能是自定义函数或另一条链,从而实现流水线式推理、数据清洗和后处理,避免胶水代码散落各处。 -
Memory
Memory是否开启会对你的模型是否对上下文有记忆功能有影响 -
文档加载器与向量存储
DocumentLoader 把 CSV、PDF、Notion、网页等异构数据转成统一 Document 对象;VectorStore 则提供 add_documents 与 similarity_search 接口,对文本向量化并持久化至 FAISS、Chroma 等向量数据库 。两者配合即可三行代码构建检索-生成(RAG)基座,支撑企业知识库问答。 -
Callback
这个就跟Vue中的钩子一样,这里就不啰嗦了。
可以先看一下架构图再看下面的内容
LangSmith
一段话概述:langchain的监控面板
要注意,LangSmith是云平台,不支持本地部署
LangSmith 是由 LangChain 团队推出的一站式平台,专为大型语言模型(LLM)应用在全生命周期中的生产化而设计。它涵盖可观察性、调试、评估、监控、自动化规则和提示工程等功能。通过 SDK 自动捕捉每次链路调用的输入、输出、中间步骤、延迟、成本等日志,并在 Web UI 中可视化展现;用户可以按 Run、错误或自定义标签过滤追踪,快速定位问题并进行深入分析(blog.promptlayer.com, langchain.com)。调试方面,支持对比多个 trace、对失败节点进行逐步排查,甚至可将日志直接复制回 Playground 重跑引导 prompt 优化。评估功能允许用户构建数据集,定义评估标准(自动 LLM 判分、人工打标签或自定义逻辑),批量评测模型版本并跟踪性能趋势(docs.smith.langchain.com)。此外,它还提供了 Playground 和 Prompt Canvas,用于版本管理、团队协作和非技术人员参与 prompt 优化(langchain.com)。监控方面,可配置仪表盘展示关键指标(如延迟、吞吐、token 费用、用户评分等),并支持告警、人工与自动反馈机制(blog.langchain.dev)。LangSmith 平台既提供云端 SaaS 服务,也支持自托管部署,且兼容 OpenTelemetry,适配 Python 和 JS/TS 应用,并不仅限于 LangChain 框架(langchain.com)。
LangGraph
一句话概括:langchain的事件流引擎
LangSmith 是由 LangChain 团队推出的 LLM 应用开发全流程平台,专为生产环境打造。从可观察性、调试、评估到监控,覆盖整个生命周期。
通过 SDK 自动采集调用 trace,记录输入/输出、链路流程、延迟及成本信息,并用可视化图表呈现,让用户快速发现性能瓶颈和错误。图中左侧展示的仪表板即是此可观察性功能,用于实时监控和事件跟踪。
调试界面支持逐步追踪链与 agent 执行情境,显示运行树结构,便于定位问题;更可将 trace 一键导回 Playground 重跑、修改 prompt。
评估功能中,用户可将 trace 导入数据集,定义自动或人工评估器来打分,并生成趋势分析和回归报告,如图左侧列表与曲线图所示。
下面是一个示例图:
LangServe
一句话概述:langchain 的服务部署框架
LangServe 是 LangChain 团队推出的生产化部署工具,旨在将 LangChain 中定义好的 Chain、Agent 或 Runnable 无缝暴露为 REST API。它利用 FastAPI 构建服务接口,并通过 Pydantic 自动推断和验证输入输出数据结构,支持 /invoke(单次调用)、/batch(批量并行调用)和 /stream(流式响应)等高并发场景下常用的端点(blog.langchain.dev)。此外,它还提供 /stream_log 和 /stream_events 接口,用于输出中间执行步骤,便于调试与监控(python.langchain.com),并且内置 /playground 页面,让开发者在 Web UI 中直接测试部署结果。
LangServe 除了高效部署功能外,还提供自动生成的 API 文档(基于 JSON Schema + Swagger),便于团队协作与集成(python.langchain.com)。客户端 SDK(Python、JavaScript)简化了对已部署服务的调用逻辑,使调用方式与本地 Runnable 如出一辙(pypi.org)。同时,LangServe 与 LangSmith 可选集成,添加环境变量即可开启 trace 跟踪,将调用日志、延迟、成本等数据同步到 LangSmith 平台,用于全链路监控与评估。
然后,通过 langchain cli 快速初始化项目,再使用 add_routes(app, your_chain, path="/..." ) 将 Chain 注册到 FastAPI 实例中,即可启动高性能 Web 服务,支持并发调用和流式交互(python.langchain.com)。
LangServe 是从原型快速迈向生产环境的重要桥梁,极大地简化了 LLM 应用的部署复杂度,并可与监控平台和异构语言客户端高度兼容,适合需要快速上线并持续优化的开发场景。
LLamaIndex
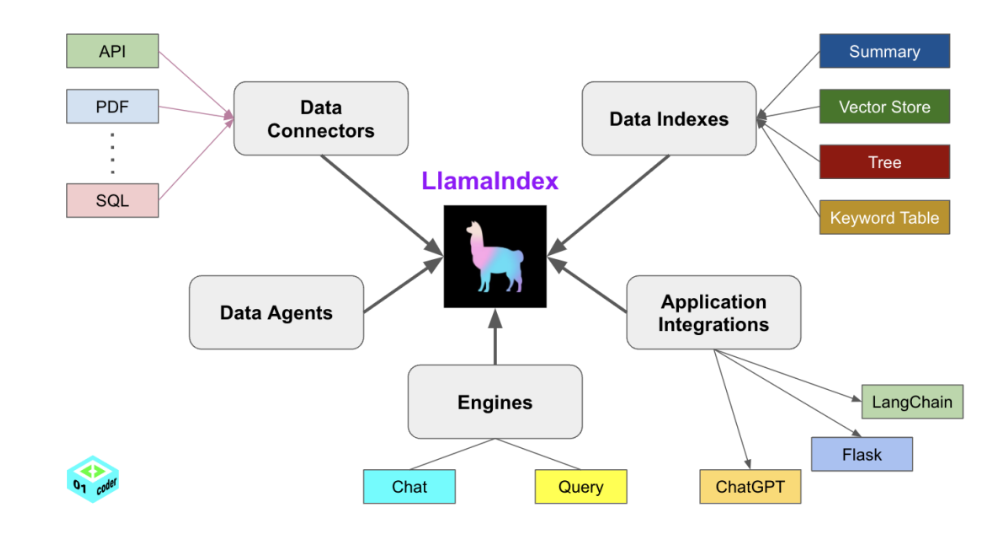
LlamaIndex是一个目前非常优秀的框架,可以说LlamaIndex就是为RAG而生的。
LlamaIndex 的设计初衷与发展背景
LlamaIndex(原名 GPT Index)是一个开源的 数据编排框架,旨在帮助开发者构建基于大型语言模型(LLM)的应用。其诞生的初衷是解决 LLM 无法直接访问私有或定制数据的问题,让模型能够利用外部知识来增强回答的准确性。这一思想通常被称为“上下文增强”或“检索增强生成(RAG)”,即在模型推理时将用户的专有数据作为上下文提供给 LLM。由于预训练的通用大模型往往无法涵盖企业内部或最新的资料,LlamaIndex 希望通过简单灵活的工具,让产品团队 快速整合自有数据 给 LLM 使用,以构建更智能的问答、聊天等 AI 功能。
LlamaIndex 由 Jerry Liu 等人在 2022 年发起,最初名为 GPT Index,侧重于文档索引和检索能力。随着 2023 年生成式 AI 的爆发式发展,它更名为 LlamaIndex,并不断丰富功能模块,从最初的文本索引扩展到数据连接器、查询引擎、Agent 智能体和各类应用集成。其愿景是成为构建 “知识辅助型” LLM 应用 的首选框架,让开发者和产品经理可以方便地将企业数据接入大模型,打造定制的智能助手。截至 2024 年,LlamaIndex 在开源社区拥有数百万下载量和活跃用户,也逐渐出现企业级的云服务(如 LlamaCloud)来支持大规模部署。
综上,LlamaIndex 的诞生背景在于解决大模型“只能闭门造车”的局限,通过提供数据-模型接口层,大幅降低将专有数据融合进 LLM 应用的门槛。这为产品经理带来了新的可能:无需训练新模型,只需将数据接入并通过 LlamaIndex 的流程,即可让 ChatGPT 等大模型“学会”企业自己的知识,实现更贴合业务的对话和问答功能。
核心组件及架构模块
LlamaIndex 将构建 RAG 应用的流程拆解为若干模块化组件,每个组件各司其职又可灵活组合。主要的核心组件包括 Data Connectors(数据连接器)、Data Indexes(数据索引)、Engines(引擎)、Agents(智能代理) 以及 Application Integrations(应用集成)。下面分别介绍这些模块及其功能:
Data Connectors(数据连接器)
数据连接器负责从各种数据源中提取和加载数据,将原始资料转化为 LLM 可用的格式。这一层相当于应用的大门口,解决“数据从哪里来”的问题。LlamaIndex 提供了丰富的内置数据读取器(Reader),可以连接 超过160种不同格式和来源 的数据。例如:
- 文件类型:本地的 Markdown、PDF、Word、PPT、图像、音频、视频文件等,LlamaIndex 自带通用读取器可批量导入整个文件夹的内容。对于每个文件,读取器会提取文字内容,并附加基础元数据(如文件名、路径等),组织为 Document 对象。
- 数据库和API:通过专用的连接器读取 SQL 数据库、REST API、GraphQL 接口等结构化或半结构化数据,将查询结果或响应内容封装为文档。
- 网页和在线资源:例如 Wiki百科、网页爬取、Google 文档等。社区提供的 LlamaHub 是一个开放的连接器仓库,包含了上百种现成的 Loader,可以一行代码加载诸如维基百科、Slack 聊天记录、Notion 文档、YouTube 字幕等各种数据源。
- 多模态内容:不仅限于文本,某些连接器可以处理图像(利用 OCR 提取文字)、表格、甚至音视频(提取字幕或元数据),从而支持多模态的数据接入。
数据连接器的作用就是将外部数据转成统一的 Document 表示。每个 Document 通常包含文本内容和附带的元数据(如来源URL、作者、时间等)。在导入过程中,LlamaIndex 还会将 Document 进一步切分为更小的 Node 节点,每个节点代表文档中的一个语义“段落”或“文本块”,为后续索引做准备。这一节点划分通常由 Node Parser(文本分块器)完成,可以根据句子、段落或固定字数进行切分,具体策略可配置(详见第5节个性化配置)。总之,Data Connector 模块让各种原始数据无缝接入,成为后续索引的原料。
实用示例:假如我们有一个存放产品设计文档的文件夹,想让大模型可以回答相关问题。使用 LlamaIndex 的内置目录读取器,我们几行代码即可完成数据加载:
from llama_index import SimpleDirectoryReader
# 假设 data/ 目录下有若干 .md 和 .pdf 文档
loader = SimpleDirectoryReader('data/')
documents = loader.load_data()
print(f"共加载了 {len(documents)} 份文档")
print(documents[0].get_text()[:200]) # 打印首份文档前200字符预览
上述代码中,SimpleDirectoryReader 会扫描指定文件夹,自动识别支持的文件格式并提取文本,最终返回一个 documents 列表,其中每个元素就是一个 Document 对象,包含文档文本及元数据。对于不支持的格式,我们还可以通过 llama_hub 引入社区提供的连接器,例如 WikipediaReader:
!pip install llama-hub # 安装 LlamaHub 扩展包
from llama_hub.wikipedia.base import WikipediaReader
wiki_loader = WikipediaReader()
wiki_docs = wiki_loader.load_data(pages=["LlamaIndex", "LangChain"])
print(f"共抓取了 {len(wiki_docs)} 个维基百科条目")
print(wiki_docs[0].meta) # 查看元数据,例如页面URL、标题等
通过以上 Data Connector 的例子可以看到,无论数据存储于何处,LlamaIndex 都提供了便捷统一的接口来获取数据,并将其标准化为 Document/Node,以进入下一个流程。
2.2 Data Indexes(数据索引)
数据索引模块负责将加载的文档集合构建成高效的索引结构,以便后续能快速检索相关内容。这一步相当于把原始资料编织成“知识库”,让 LLM 查询时能有据可依。LlamaIndex 支持多种索引类型,每种在原理和适用场景上有所不同:
- 向量索引(Vector Store Index):这是 RAG 场景中最常用的索引形式。它通过将每个文本节点转换为 向量嵌入(embedding) 存储起来,实现语义索引。具体过程为:对每个 Node 文本调用一个嵌入模型(如 OpenAI 的 text-embedding-ada-002),得到高维向量表示,并存入向量库中。查询时也将问题转为向量,然后用相似度搜索找出最相关的文本块。向量索引擅长处理自然语言查询,可根据语义相似度检索,不局限于关键词匹配。LlamaIndex 默认提供内存型向量存储,并支持对接多个外部向量数据库(如 Pinecone、Weaviate、FAISS 等)来存放索引,以利于持久化和大规模向量检索。
- 列表索引(Summary Index / List Index):最简单的索引形式,就是按顺序存储所有文本节点形成列表。查询时如果不指定特殊参数,列表索引会将全部节点取出交给 LLM 汇总回答。这种方式在文档较短时可用,同时也支持结合嵌入或关键词进行筛选。它的特点是实现非常简单,并支持对增量文档的快速插入删除,因此适合对数据量不大但更新频繁的场景。
- 树索引(Tree Index):树索引用层次结构组织文档节点,适合处理篇幅很大或结构层次分明的资料(如长报告、法律合同等)。构建时,它递归地将底层文本节点总结成高层节点,形成一棵语义树。查询时,LLM 会从根节点开始,根据查询逐层定位相关分支直至叶节点,以此提取答案。树索引的优势在于分层缩小范围,能够高效地在超长文档中找到对应段落,并保留上下文层级信息,非常适合处理层级结构明确的文档内容。
- 关键词索引(Keyword Table Index):该索引为每个节点提取关键词,建立从关键词到节点列表的映射表。查询阶段,通过从问题中提取关键词来匹配索引表,找出相关节点。关键词索引的效果类似传统搜索,引擎按词找内容,但相比语义向量,它对精确术语匹配更有效。例如在代码库、法律条款等专业术语明确的场景,用关键词索引能快速定位包含特定术语的段落。
- 知识图谱索引(Knowledge Graph / Property Graph Index):这是更高级的索引形式,旨在存储实体及其关系。构建时,LLM 会从文本中抽取出实体节点以及它们之间的关系(三元组),形成知识图谱。同时每个节点也可嵌入向量以便语义检索。查询可以通过关系路径和语义混合检索相关知识三元组。这种索引让 LLM 不仅能按文本块回答问题,还可以基于结构化知识进行推理。在需要理解复杂关系(比如人物网络、事件因果)的应用中,知识图谱索引非常有价值。
通过以上索引机制,LlamaIndex 将杂乱无章的原始文本转化为了有组织的“知识库”。一个应用可以同时建立多种类型的索引,以对应不同的数据特点。比如对一些结构化数据构建知识图谱索引,对长文档构建树索引,对一般文本构建向量索引,然后组合使用。正如 IBM 对 LlamaIndex 的描述:“LlamaIndex 提供了多种索引类型来适配不同查询策略,包括向量索引、摘要索引和知识图谱索引等”。这种灵活性确保了产品可以根据场景选择最优的索引方案。
实用示例:下面的代码展示了如何从文档列表创建向量索引并保存到本地,以支持下次直接加载:
from llama_index import VectorStoreIndex, StorageContext, load_index_from_storage
# 利用前述已加载的 documents 列表创建向量索引
index = VectorStoreIndex.from_documents(documents)
# 将索引持久化保存,例如保存到 "./storage" 目录
storage_context = StorageContext.from_defaults()
index.storage_context.persist(persist_dir="./storage")
# ...(稍后在其他脚本或重启环境后)
# 加载已有索引,无需重新构建
new_storage_context = StorageContext.from_defaults(persist_dir="./storage")
loaded_index = load_index_from_storage(new_storage_context)
通过 VectorStoreIndex.from_documents,LlamaIndex 会自动完成节点切分、向量嵌入计算和索引构建。persist() 方法将索引数据(包括向量和元数据)存到指定目录。当下次需要使用时,直接 load_index_from_storage 即可高效地载入索引,免去重复嵌入计算的成本。这对于大规模语料的应用尤其重要,可以将索引构建和查询分离开来,提高系统的启动速度和可扩展性。
Engines(引擎:查询与对话接口)
引擎模块提供了自然语言访问数据索引的接口,是应用直接与之交互的部分。引擎封装了查询流程,将用户的问题转换为对数据的检索和调用 LLM 得出答案。LlamaIndex 提供两类主要引擎:
- 查询引擎(Query Engine):用于典型的问答检索场景,即单轮问题的解答。Query Engine 接收用户输入的问题,在一个或多个索引中检索相关内容,然后将检索结果与问题一起发给 LLM,返回最终答案。查询引擎本质上实现了一个标准的 RAG 流程,可以配置背后用哪些索引和检索方式,以及答案的组合方式(直接拼接/生成摘要等)。多个 Query Engine 还可以通过**Router(路由器)**组合使用,根据问题类型选择不同引擎。例如,如果同时有结构化数据和非结构化文档,可以先判断问题属于哪类,再路由到相应的 Query Engine。但在大多数简单场景下,直接使用单一索引的查询引擎即可满足需求。
- 聊天引擎(Chat Engine):用于支持与数据进行多轮对话的场景。Chat Engine 可以看作是有“记忆”的 Query Engine,会保留会话历史,从而在后续提问时结合上下文。例如,一个产品知识库聊天机器人,用户可以连续追问细节,Chat Engine 会在每次检索时考虑之前的对话内容。LlamaIndex 的 Chat Engine 内置了对话历史管理,并提供不同模式:基础模式每轮都重复询问上下文,Condense 模式则先让 LLM 将当前问题与历史合并,再检索答案,使对话更连贯。对于产品经理来说,可以简单地将 Chat Engine 理解为“ChatGPT + 私有知识库”——用户感觉像是在和智能助手聊天,但这个助手背后有 LlamaIndex 提供的专有数据支撑。官方描述指出:“Chat Engine 是 Query Engine 的有状态扩展,能够记住对话历史,从而像 ChatGPT 一样与用户进行多次往复。”
实用示例:以下演示如何将前面构建的索引转换为 Query Engine 和 Chat Engine,并进行问答:
# 基于索引创建查询引擎
query_engine = index.as_query_engine(similarity_top_k=3)
response = query_engine.query("我们的产品A有哪些核心功能?")
print(response.response) # 打印答案文本
for node in response.source_nodes:
print("来源片段:", node.node.get_text()[:50]) # 列出引用了哪些原文片段
# 基于相同索引创建聊天引擎
chat_engine = index.as_chat_engine()
reply1 = chat_engine.chat("你好,请用简短语句介绍一下产品A。")
print("助手:", reply1.response)
# 用户继续提问,聊天引擎将记住上一问的内容
reply2 = chat_engine.chat("它有哪些优势应用场景?")
print("助手:", reply2.response)
在上述代码中,我们先用 as_query_engine() 获取一个查询接口,参数 similarity_top_k=3 表示每次检索出最相似的3段内容供生成答案。response 对象不仅包含生成的答案文本 (response.response),还保留了 source_nodes 列表,里面是引用的源文档片段和相关分数,这对于结果解释(为何这么回答)很有帮助。接着我们用 as_chat_engine() 创建了一个聊天接口,连续向它发送两条消息。可以看到第二次提问时并未重复上下文,但助手仍能“记住”产品A是上一轮讨论的主题,并给出相应场景优势。这种对话能力使 LlamaIndex 构建的助手更贴近人机交互习惯。
Agents(智能代理):
智能代理(Agent)是 LlamaIndex 引入的高级组件,让 LLM 不再只是被动回答问题,而是能够主动调用工具、执行操作,完成更复杂的任务。简单来说,Agent 是一个具备决策与行动能力的 LLM 驱动程序。在 LlamaIndex 中,Agent 主要扮演“知识工作者”的角色,可以利用各种工具对数据进行深入处理。它的典型功能包括:
- 自动搜索和多模态检索:Agent 可以基于用户请求,自动检索不同类型的数据源。例如先从数据库查找结构化信息,再从文档中查找描述性内容,并综合起来回答。它能处理非结构化、半结构化和结构化数据混合的查询任务。
- 调用外部API或服务:Agent 可以充当“中间人”,接受自然语言指令后调用外部系统的 API。例如根据用户要求去抓取实时信息、发送邮件、提交表单等。调用得到的结果数据,还可以进一步索引或缓存供后续对话使用。
- 维护对话记忆:Agent 可以将对话或操作历史存储下来(例如存入自身的记忆容器),以便在长任务过程中保持上下文,甚至在不同会话之间传递状态。
- 执行复杂任务:通过将问题拆解为子任务,调用一系列工具逐步完成。例如用户问“请分析我们上季度的销售数据并生成图表”,Agent 可以先用数据库查询获取销售数据,再调用绘图工具生成图表文件,然后再给出一个总结。这一系列步骤由 Agent 自主决策和连贯执行。
LlamaIndex 支持两种主要的 Agent 推理模式:OpenAI Function Agent 和 ReAct Agent。OpenAI Function Agent 借助 OpenAI 提供的函数调用能力,按照预定义工具规格自动选取并调用;ReAct Agent 则基于“Reason+Act”的思路,LLM 通过链式思考(Chain-of-Thought)来决定下一步动作。两者底层原理对产品经理来说无需深入,重要的是它们都遵循一个**“思考-行动-观测”的循环**(reasoning loop):Agent 读入用户请求 -> 内部思考哪种工具或索引可以解决 -> 执行工具获取结果 -> 根据新信息继续思考 -> 直至完成任务给出最终答复。
为了让 Agent 能执行各种操作,LlamaIndex 提供了工具抽象层(Tool abstractions)。开发者可以把任意功能封装为 Agent 可用的“工具”。框架内置了将许多常用服务转换为工具的规范,如将 Gmail 操作封装为 GmailToolSpec 使 Agent 能读写邮件。也可以把我们之前介绍的 Query Engine 包装成工具,让 Agent 在需要时查询知识库。LlamaIndex 还集合了社区的工具库(来自 LlamaHub),已经有 15+ 种现成的工具规范 可以直接使用——涵盖网络搜索、数据库查询、第三方应用操作等。
Agent 的意义在于提升了应用的自动化和智能化程度:相比 Query Engine 仅仅返回答案,Agent 可以帮用户动手去做一些事情。例如,一个面向客服的 Agent,不仅能回答问题,还可以根据用户请求直接调用后端 API 帮他们取消订单或查询物流,再把结果告诉用户。这对于产品设计来说,是从静态问答到动态任务执行的跃升。
实用示例:下面以一个简单的 Agent 使用场景说明。假设我们希望构建一个“知识库助手Agent”,当问到超出本地知识库范围的问题时,它能够自动改用网络搜索工具获取答案:
from llama_index.tools import QueryEngineTool, ToolMetadata
from llama_index.agent import OpenAIAgent
# 假设已有一个 query_engine 针对公司内部知识库
internal_tool = QueryEngineTool.from_defaults(query_engine=query_engine,
metadata=ToolMetadata(name='InternalKB', description='查询内部知识库'))
# 再定义一个互联网搜索工具,例如使用 SerpAPI(假设已集成好)
from llama_hub.tools.serpapi.base import SerpapiToolSpec
search_tool_spec = SerpapiToolSpec()
search_tool = search_tool_spec.to_tool() # 将其转为通用工具
# 创建 OpenAI Agent,注册上述两个工具
agent = OpenAIAgent.from_tools([internal_tool, search_tool])
# 用户提问,Agent 将自主决定使用哪个工具
response = agent.chat("请问2023年公司的市值是多少?")
print(response)
在这个例子中,我们注册了两个工具:InternalKB(内部知识库查询)和一个互联网搜索工具。Agent 会解析用户问句。如果问题涉及公司市值(假设内部知识库无此财务数据),Agent 可能判断需要用网络搜索,于是调用 SerpAPI 获取最新市值信息,再把结果反馈给用户。如果用户改问内部资料,例如“产品A的技术栈是什么?”,Agent 则会调用内部知识库查询工具来回答。整个过程中,Agent 不需要人干预地决定并使用适当的工具,为最终答案提供支撑。这种灵活的工具调用框架,正是 LlamaIndex Agent 模块的强大之处,让我们的 AI 应用更接近一个能自主解决问题的智能体,而不仅仅是知识问答系统。
Application Integrations(应用集成与生态)
在应用层面,LlamaIndex 提供了丰富的集成能力,方便开发者将其融入现有产品技术栈或与其他工具链配合使用。这些集成包括:
- 向量数据库和存储:前面提到,LlamaIndex 支持对接主流的向量数据库(Pinecone、Weaviate、Chroma 等)以及本地向量引擎(FAISS)。产品团队可以根据数据量和性能需求选择合适的存储方案,将索引结果保存到企业已有的数据基础设施中。比如接入云向量数据库,可以支持海量向量的近似搜索和分布式存储,而无需担心本地内存限制。
- 语言模型与API:LlamaIndex 的模型接口是高度可插拔的。除了 OpenAI 的 GPT-3.5/4 接口,它也能方便地集成其他 LLM,比如 Anthropic Claude、Google PaLM,或 Hugging Face 上的开源模型等。开发者可以在创建引擎或 Agent 时指定所用的 LLM 类型和参数,甚至可以混合多个模型用于不同子任务(虽然一般来说 LlamaIndex 聚焦于单一主模型的应用)。通过统一的接口封装,切换底层模型对业务逻辑是透明的。例如从 OpenAI 改为调用本地部署的 Llama2,只需更换
llm = OpenAI()为相应的本地 LLM 类即可。这种模型抽象确保产品不会被某一家 API 所绑死,具有灵活的可移植性。 - 与 LangChain 等框架互操作:很多团队可能已经使用 LangChain 或类似的 LLM Orchestration 框架。LlamaIndex 与这些工具并不冲突,反而提供了协同集成的可能。例如,你可以在 LangChain 的链式流程中,调用 LlamaIndex 构建的 Query Engine 作为其中一步,实现更强的检索能力。反之,也可以在 LlamaIndex 的 Agent 工具中封装 LangChain 的能力。社区实践表明,两者各有所长,将 LlamaIndex 用于数据接入和检索、LangChain 用于复杂流程控制,是一种常见组合方案。LlamaIndex 甚至在设计上预留了接口让 LangChain 的Tracing等调试工具接入,从而在统一界面下观察链路。总的来说,LlamaIndex 可被视为专注数据部分的模块,能够良好地嵌入到更大型的 LLM 应用架构中。
- ChatGPT 插件与对外服务:LlamaIndex 支持将自身的查询引擎作为一个服务端接口部署,例如以 Web API 的形式提供问答服务。这意味着我们可以很方便地构建一个 ChatGPT 插件或 RESTful API,让外部系统也能访问 LlamaIndex 构建的知识库。官方文档提到了 LlamaIndex 与 OpenAI 插件机制的集成,开发者只需编写一个简短的配置,就能让 ChatGPT 通过插件调用内部的 Query Engine 来回答关于公司数据的问题。这对产品落地非常有价值——现有的聊天机器人产品可以通过插件无缝接入企业知识,而无需重新训练模型。
- 监控与评估(Observability & Evaluation):在生产环境中,监控 LLM 应用的效果和行为十分重要。LlamaIndex 内建了观测和评估模块,例如可以记录每次查询的详细过程、消耗的 token 量、检索到的内容等(Callback 机制)并支持结果质量评估。这些日志和指标便于产品团队分析系统性能、调优提示词(prompt)或检索参数,从而持续改进用户体验。比如,可以通过自动化的问题集评测,比较不同索引、不同 prompt 模板的回答准确率,选择最佳方案部署。
Application Integrations 体现了 LlamaIndex 在工程落地上的周到设计。它既能向下兼容各种数据源与模型服务,又能向上对接现有应用或平台,使其成为产品方案中的即插即用组件。对于产品经理,这意味着采用 LlamaIndex 不需要推倒原有架构,而是可以平滑地融入现有系统,通过标准接口调用,从而快速赋能产品新的 AI 能力。例如,一家企业可以保留原有的客服系统,仅仅在查询知识库的环节用 LlamaIndex 提供的 API 取代原本死板的关键词搜索,就立刻让客服机器人变得更智能。这种集成友好性,大大降低了试水生成式 AI 的风险和成本。
LlamaIndex 中的 RAG 实现机制
作为一个围绕 检索增强生成(Retrieval-Augmented Generation, RAG) 架构设计的框架,LlamaIndex 天然地将 RAG 视为核心能力贯穿始终。在 LlamaIndex 的官方说明中,多次强调 RAG 是构建“有数据支撑的 LLM 应用”的关键技术。那么 LlamaIndex 是如何实现 RAG 流程的呢?本节我们以 RAG 三步法 来解读其内在机制。
RAG 的典型过程可以分为三个阶段:
- 文档切分(Chunking):将长文档或数据集切分成适合 LLM 处理的小片段。LLM 对输入长度有限制,而且过长的上下文不利于相关性判断。因此需要在离线阶段把数据源拆解为有意义的“知识单元”(也就是前述的 Node)。LlamaIndex 提供的 Node Parser 会按配置策略完成这个任务,比如默认将文档按约 1000 字符为一段,带一点重叠。Chunking 的质量很重要:段落太大会导致无关内容夹杂,太小则上下文不连贯。因此 LlamaIndex 允许开发者根据数据特点调整chunk 大小和重叠(详见第5节)。
- 向量索引(Embedding & Indexing):将每个文本块转换为向量表示并建立索引,方便后续按需检索。这一阶段对应我们前述 Data Index 模块,尤其常用的是 Vector Store Index。通过嵌入模型把文本映射到向量空间,再借助高效相似度搜索结构,可以在查询时迅速定位最相关的内容片段。LlamaIndex 在索引阶段还会保存每个节点的元信息,使得检索不仅基于内容,还可结合元数据过滤(例如按文档来源、日期筛选结果)。
- 检索与生成(Retrieval & Generation):在用户提问时,首先将问题也转换为嵌入向量,到索引中寻找语义相近的文本块作为上下文。通常会取 top-k 篇最相关内容,将它们与问题一起送入 LLM 的提示词,从而生成融合了检索信息的回答。LlamaIndex 的 Query Engine 正是封装了这一步骤——它会利用 Retriever 类根据索引执行检索,然后通过 Response Synthesizer 将检索到的 Node 内容与用户query拼接,提交给 LLM 得出最终回答。这一过程中还可以插入 Postprocessor 对节点做过滤或 rerank。最终 LLM 产出的回复就不仅凭借自身训练知识,而是参考了最新或私有的资料,从而提高准确性和时效性。
LlamaIndex 对 RAG 的实现可谓面面俱到。不仅提供基本的检索+生成接口,还支持许多提升效果的进阶技巧,例如:
- Hybrid Retrieval(混合检索):将向量检索与关键词检索结合,兼顾语义相关和精确匹配。LlamaIndex 允许 Retriever 组合多种策略,比如同时使用向量相似度和关键字过滤,或者对结果再做交叉核验。这在问答准确率要求高的应用中很实用。
- 自定义 Prompt 模板:可以控制 LLM 最终回答时的提示模版,比如让模型引述来源、以特定格式输出等。产品经理可以与团队一起设计合适的提示词,以符合产品调性。LlamaIndex 提供 Prompt 支持,开发者可以定制 Response Synthesizer 的行为,确保生成结果符合预期。
- 多步检索与合成:对于复杂问题,Query Engine 可以自动将问题拆分,对不同索引分别检索,再将中间答案合并。这类似于所谓的 “Sub-question” 策略。举例来说,问“比较今年和去年的营收”,引擎可能先分别查询今年营收和去年营收,再让 LLM 汇总差异。这些都属于 LlamaIndex Workflow 或 Router 的高级应用,但对于需要综合分析的产品功能来说非常有价值。
- 检索结果反馈循环:LlamaIndex 也支持结果的验证与迭代,即 Agent 可以检查 LLM 的回答是否充分利用了检索信息,必要时再发起新的检索补充。这避免了模型胡乱编造成分,使答案更加可信可控。
LlamaIndex 将 RAG 的思路深深嵌入到了框架设计中,从数据准备到查询生成都有完善的机制支持。这使得开发者几乎无需关心底层的检索调用细节,就可以通过几行 API 调用实现一个强大的 RAG系统。对于产品经理而言,理解 LlamaIndex 的RAG实现,意味着理解了如何让 ChatGPT 之类的大模型接入你的专属知识。这是一种相比训练新模型更为快速有效的方案,LlamaIndex 正是为此而生。
数据索引与查询的流程拆解
在上一节宏观介绍了 RAG 实现后,我们再按照实际系统流程梳理一次 LlamaIndex 在索引和查询阶段都做了什么。这对于产品经理了解系统行为和可能的瓶颈很有帮助。
索引构建(Indexing)的流程
-
数据加载:调用 Data Connector 读取原始数据源,得到 Document 列表(包含文本与元数据)。例如读取10个文件,就得到10个 Document,每个可能有几千字文本。
-
文档解析与节点切分:对每个 Document,应用 Node Parser(文本分割器)将其拆分为若干 Node。每个 Node 一般几百字到一千字左右,代表一个相对独立的内容单元。切分时可保留部分重叠以避免上下文割裂。切分结果就是大量 Node(比如10份文档总共切成了100个 Node)。
-
向量化与索引组织:遍历每个 Node,用 Embedding 模型将其文本转为向量,并根据选定的 Index 类型加入索引结构中:
- 如果是向量索引,就将 {向量 -> Node映射} 加入向量存储。
- 如果是树索引,则可能首先用 LLM 生成每个 Node 的概要,然后逐级构建树。
- 如果是关键词索引,则提取 Node 关键词加入倒排表。
- …不同索引各自的存储方式,但目的都是建立快速定位节点的途径。
-
索引保存:索引构建完毕后,可以选择将结果持久化,如保存到磁盘文件或上传到向量数据库。也可以暂存在内存仅用于当前会话。对于迭代开发阶段,内存索引方便快速试验;而产品上线时,建议持久化保存以便服务重启后不必重建索引。
经过上述流程,我们就有了一个可检索的知识库。需要注意的是,索引阶段通常是离线或预处理步骤,可以视作一种数据准备的“ETL”(Extract-Transform-Load)过程,将原始数据转成易检索的数据结构。这个阶段耗时取决于数据量和嵌入模型速度,对于大型语料可能需要数小时到数天不等。但一旦索引完成,后续查询就会非常快,因为繁重的工作已经提前完成了。
查询(Query)的流程
当应用收到用户的问题时,LlamaIndex 的查询流程大致如下:
-
查询解析:首先,系统可能会对用户输入进行必要的预处理。例如基本的清洗、语言识别(如果支持多语言)等。对于 Chat Engine,还要将当前对话历史一并纳入考虑。有些高级用法会先用 LLM 将复杂提问重述简化,这也在这一阶段完成。
-
检索器选择:接下来,Query Engine 确定该用哪个 Retriever 去检索数据。在简单场景下一般只有一个 Retriever,对应唯一的索引;如果有 Router,则根据规则选定对应的 Retriever(例如财务类问题查财务索引,其它问题查通用文档索引)。这一过程对用户是透明的,但对于复杂应用,Router 策略可以极大提高查询准确度(类似问医药相关问题就去医学知识库,而不是搜索法律文件)。
-
向量检索/知识查询:Retriever 拿到用户 Query(可能直接是文本,也可能先转成向量),在索引中执行检索操作。以向量索引为例,Retriever 会将 Query 用相同 Embedding 模型转成向量,然后在向量库中找到 语义距离最近 的 top-k 个节点。如果用了关键词或其他索引,则按相应算法匹配。结果是一组候选 Node,它们被认为和问题高度相关。
-
节点后处理:得到初步检索结果后,可以对节点列表进行后处理。LlamaIndex 允许插入一些模块对节点排序或过滤。例如可以应用 Rerank 模型(基于Cross-attention的二次排序)重新判断每段文本与问题的相关性,并调整顺序;或者过滤掉与用户指定过滤条件不符的节点(比如只要最近一年的文件)。这一阶段的目标是尽量确保送入 LLM 的上下文既足够相关又质量可靠(去除冗余和噪音)。
-
构建提示(Prompt):Query Engine 然后把最终筛选的 Node 文本提取出来,和用户的问题一起构建提示信息。例如常用提示模板是:“用户问题: {Question}\n 文档1: {Content1}\n 文档2: {Content2}\n 请基于上述内容回答。”。LlamaIndex 的 Response Synthesizer 模块会按照选定的模式拼装这些内容。开发者可以指定不同的 prompt 格式,比如要求模型引用来源等。
-
LLM 生成回答:最后,将上述 Prompt 输入选定的 LLM(例如 OpenAI 的 GPT-4 模型或本地的大模型),请求它生成答案。LLM 在这个完整提示的基础上,结合自身知识和提供的上下文内容,产出一段文本回复。这就是返回给用户的最终答案。因为上下文包含了从知识库检索的内容,LLM 的回答会显著地针对用户提供的数据,而非仅凭通用训练知识。
-
答案输出与反馈:LlamaIndex 会将 LLM 的回答封装成
Response对象一起返回,其中除了.response字符串外,还可能包括source_nodes(引用内容列表)等信息。如需要,应用可以将这些信息展示给用户(比如让用户可以点击查看答案所引用的文档段落,提升可信度)。此外,还可以将这次问答日志保存,供将来的分析或模型微调使用。
整个查询流程通常在数百毫秒到几秒内完成(取决于 LLM 的响应速度和上下文长度)。相比索引阶段,它是在线实时的,需要非常优化。LlamaIndex 利用了高效的索引结构和批量向量计算,使得检索部分开销很小;LLM 调用部分则主要受模型自身性能影响。如果使用的是云端API模型,在并发较高时需考虑速率限制和费用,但这些是RAG应用通用的考量,不是LlamaIndex特有的问题。值得一提的是,LlamaIndex 让 检索-回答 这套逻辑变得高度自动化,你无需逐步编写向量搜索、拼Prompt等代码,一切都由框架封装在 Query Engine 内。这极大降低了实现复杂查询流程的门槛,也减少了出错的可能。对于产品经理来说,这意味着更快的开发迭代和更可靠的系统表现——团队可以把精力放在优化内容质量和用户交互上,而底层流程由 LlamaIndex 提供的默认实现即可有不俗的效果。
个性化配置与灵活性
LlamaIndex 在保持高层API简洁易用的同时,也为有高级需求的团队提供了丰富的个性化配置选项。通过配置,我们可以调整从文本切分到检索策略、到模型调用的各个环节,以适应特定场景的要求。下面从文档分块、向量存储、检索方式和 LLM 选择四个方面,介绍 LlamaIndex 的灵活定制能力。
文档分块(Chunking)策略
默认情况下,LlamaIndex 对文档的切分采用固定大小窗口的策略(约1000字左右,重叠20字)。然而,不同类型文本可能需要不同的分块方式,例如:
- 对于结构化强、段落清晰的文档(如技术手册、论文),按段落或章节标题来切分可能更合理。
- 对于代码等特殊格式,可以按函数或类为单位切块,而不是盲目按字数。
- 对于对话或日志,可能希望以一段对话为整体,而不是拆开。
为此,LlamaIndex 提供了 Node Parser 接口,可以自定义切分逻辑。框架内置了多种 TextSplitter 实现,如按句子窗口、按标点、按语义分割等。开发者也可继承 BaseNodeParser 编写自己的解析器。
如果不想换算法,只需调整默认切片大小/重叠也很方便。例如,将全局 Settings 中的 chunk_size 和 chunk_overlap 改掉即可:
from llama_index import StorageContext, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index import StorageContext, VectorStoreIndex, SimpleDirectoryReader
from llama_index.core import Settings
# 方法1:设置全局切分参数
Settings.chunk_size = 512 # 将块大小改为512字符
Settings.chunk_overlap = 50 # 重叠部分50字符
# 方法2:显式指定切分器
Settings.text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=50)
以上两种方法等效地把默认节点长度从1024降到了512,从而产生更细粒度的节点。要注意的是,切分尺度会影响嵌入效果和回答质量:块太大,检索可能引入噪音;块太小,单块信息不完整。产品经理和工程师需要根据实际内容类型多实验,找到最佳平衡点。所幸 LlamaIndex 的配置让这种尝试变得简洁明了,不需要改框架源码,只需设置参数即可调整策略。
向量存储后端选择
对于向量索引,存储媒介直接关系到性能和可扩展性。LlamaIndex 默认用一个内存向量存储(基于 faiss 或 numpy 实现),优点是零配置、速度快,但数据量大时会受限于内存,并且断电后易失。为了满足不同规模需求,框架支持对接多种外部向量数据库:
- 本地FAISS:Facebook AI提出的高性能相似度检索库。可离线构建索引并磁盘保存,支持亿级向量的快速近似搜索。LlamaIndex 可以直接使用 FAISS 索引作为其 VectorStore backend,对于私有部署很方便。
- Pinecone:云原生的向量数据库服务,提供分布式、按量计费的向量存储。将 LlamaIndex 连接 Pinecone 后,可享受它的托管扩展能力,向量数据自动持久化在云端,并发检索和存储容量都可以横向扩展。适合数据规模大且希望省去自行维护数据库的团队。
- Weaviate:开源的向量数据库,也有云服务版本。支持丰富的数据对象和Schema,可以和LlamaIndex一起用来管理带结构的嵌入数据(例如配合知识图谱索引)。Weaviate 强调可组合的管道,可以在数据库端就做些预过滤。这些都可以通过 LlamaIndex 的 VectorStore 接口来利用。
- Milvus / Zilliz:另一个流行的开源向量数据库。它对ANN算法有高度优化,也支持持久化。LlamaIndex 通过第三方驱动可集成 Milvus,为需要自建高性能搜索的应用提供后盾。
- Chroma:近年崛起的轻量级向量数据库,适合快速原型和小规模应用。LlamaIndex 也支持 Chroma 的 Python API。
选择何种存储,主要取决于数据规模、查询QPS要求,以及团队对运维的偏好。小规模应用内存即可;中大型项目往往选云数据库托管,减少维护压力。幸运的是,LlamaIndex 把切换存储变得非常简单——通常只要在创建 Index 时指定 storage_context=... 参数,提供相应 VectorStore 实例即可。在产品生命周期中,如果发现当前方案不满足需求,随时可以替换后端而不影响上层 Query Engine 的调用逻辑。这种松耦合设计确保了灵活演进:产品初期用简单方案验证需求,后期数据增大再迁移到成熟数据库,LlamaIndex 都能很好地支持。
检索方式与参数调整
LlamaIndex 的检索过程由 Retriever 模块掌控,我们可以针对检索策略做多方面定制:
- Top-K 参数:决定每次检索返回多少候选节点(默认为前5或10条)。在 Query Engine 和 Chat Engine 的
.query()接口中,可传入similarity_top_k或nodes_taken参数调整。例如将similarity_top_k=5改为 10,可以让回答时引用更多内容,增加完备性。反之,设小一点可以加快速度、减少噪音。产品上需要平衡答案的详尽程度与成本。 - 过滤与排序:可以给 Retriever 增加过滤条件,如限定只搜索特定来源或时间段的文档。这通过元数据过滤实现,例如
retriever = index.as_retriever(filters={"year": 2023})之类。排序方面,可以插入 Reranker 模型二次排序,可配置为使用较复杂的模型(比如一个小型Cross-Encoder)对初筛结果重排。如果产品要求高精准回答且对时延不敏感,可以考虑开启 rerank 提升准确率。 - 混合检索模式:LlamaIndex 允许组装多个 Retriever,通过 Router 来按需调用。这让我们能够实施Hybrid Search,比如同时进行向量相似和关键词匹配,然后合并结果。在索引构建时也可为同一文档同时建立向量和关键词两套索引。这种混合策略能显著提高某些场景下的查全率。例如医疗文档问答,需要确保专业术语精确匹配(关键词)又要理解上下文语义(向量),混合检索可以兼顾。
- Prompt 模板与系统提示:检索后我们会构造 prompt 送入 LLM。LlamaIndex 默认有一套 prompt 模板,但我们完全可以自定义。例如在回答开头加入一条系统提示,规定回答风格或语气;或者在 prompt 中要求模型输出 JSON 格式结果。通过修改
ResponseSynthesizer或 Chat Engine 参数中的system_prompt、user_prompt模板,就能达到这些定制效果。这对产品来说很重要,因为不同行业的回答风格(严肃/幽默/简洁/详尽)可以通过 prompt 来控制,从而保持品牌一致性。
配置示例:假设我们希望构建一个严谨的问答系统,每次只给出最高相关的两段内容并要求模型引用来源。可以这样配置:
query_engine = index.as_query_engine(
similarity_top_k=2,
# 使用OpenAI GPT-4模型,温度降低以提高确定性
llm=OpenAI(model="gpt-4", temperature=0.0),
# 定制系统提示,要求引用来源
system_prompt="你是一个严谨的知识助手,请直接根据提供的文档回答,并在句末用括号标注来源。",
# 采用OpenAI提供的函数调用模式(如需结构化输出,可定义函数schema)
enable_func_calling=True
)
上面代码中,我们将 top_k 设为2,让引擎每次只取最相关的两段文本;选用了更强大的 GPT-4 模型且关闭随机性,以获得稳定准确的回答;设定了一个系统级提示,明确回答要求引用来源。这些配置都会影响最终输出的形式和质量。通过 LlamaIndex,我们能够以很直观的方式调整这些细节,而不必深入修改底层逻辑,这对于快速试验各种产品方案非常有帮助。
LLM 模型指定与切换
正如前文提到的,LlamaIndex 对接模型是非常灵活的。产品经理经常需要考虑模型选择和更替的问题,例如:开发阶段用小模型本地跑,验证OK后上线用更好的API模型;或者出于数据合规,要从国外API换成本地部署模型等等。LlamaIndex 提供多种方式来指定和切换 LLM:
-
全局设置默认模型:通过
Settings.llm可以设定一个全局默认 LLM,当没有在局部传入 llm 参数时就会使用它。比如Settings.llm = OpenAI(model="gpt-3.5-turbo")则框架里所有查询默认用 GPT-3.5。这种方式简单明了,适合统一模型的场景。 -
局部指定模型:在创建 Index 或 QueryEngine 时,可以传入
llm=...或embed_model=...来覆盖默认设置。例如index.as_query_engine(llm=my_local_llm)。这样可以针对不同用途使用不同的模型,如复杂问题用强模型,简单摘要用小模型,以达到成本与效果的平衡。 -
多模型协同:虽然 LlamaIndex 本身不是多模型流水线框架,但在 Agents 或 Workflows 中,可以通过工具机制实现多模型协作。例如一个 Agent 的 Tool 可以调用一个特定模型做翻译,另一个Tool用另一个模型做代码生成等。这需要一定高级用法,但框架并不限制这样的组合。
-
Embedding 模型切换:默认使用 OpenAI 的文本嵌入模型,但我们可以替换为本地开源embedding模型(如 SentenceTransformer)来降低依赖。例如:
from llama_index.embeddings import HuggingFaceEmbedding Settings.embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L6-v2")这样后续向量索引就用本地模型来算向量,免除了调用API的成本和数据外泄风险。
值得一提的是,LlamaIndex 还有针对不同模型的适配优化。比如对于 OpenAI 系模型,会自动采用其 ChatCompletion API;对于本地模型,可调节 max_tokens 等参数来避免溢出。这些细节框架都帮我们处理了。因此切换模型在多数情况下无需改动业务逻辑,只要替换配置,输出结果就由新模型生成。这给产品很大的底气去尝试新的模型或迁移平台,因为底层实现对上层是透明的。
综上所述,LlamaIndex 提供的个性化配置选项覆盖了 RAG 工作流中的关键环节:切分细粒度影响着召回范围,索引后端决定性能扩展,检索策略影响相关性和速度,而模型选择则关系生成效果和成本。有了这些杠杆,产品经理可以和技术团队一起调校出最适合自己应用的设置。例如在知识库QA产品中,为了追求精准,或许会牺牲一点速度把 similarity_top_k 提高并启用 rerank;而在实时对话助手中,也许会倾向速度,将 chunk 切小、top_k 降低来确保响应快。这些都可以通过 LlamaIndex 的配置灵活实现。这种高度的可调节性,正体现了框架设计的初衷:既服务“小白”用户开箱即用,也赋能“高手”用户深度优化。因此无论您是要快速推出MVP还是打磨成熟产品,LlamaIndex 都能适应需求变化,提供强大的支持。
常见应用场景和使用案例
LlamaIndex 围绕让 LLM 利用外部知识这一能力,孕育出了丰富的应用场景。在产品设计层面,我们可以考虑以下典型用例,这些也是目前业界广泛探索并实践的方向:
- 知识问答系统:这是最直接的场景,让模型回答关于一系列文档或知识库的问题。例如企业内部的知识库问答、法律法规查询、学术论文Q&A等。LlamaIndex 通过构建向量索引并使用 Query Engine,可以轻松实现对成百上千份文档的问答功能。用户输入自然语言问题,系统检索知识库相关内容并回答。这类系统可以部署在客服、帮助中心、自助查询等场景,提升信息获取效率。
- 智能聊天机器人:比起单轮问答,聊天机器人可以进行多轮交互,理解上下文。借助 LlamaIndex 的 Chat Engine,我们可以打造如企业内部助手、网站访客客服、教育辅导机器人等。例如,一个面向程序员的聊天助手,可以导入项目文档和API说明,这样开发者在提问时,机器人能引用相关文档段落来回答,并支持追问细节。由于 Chat Engine 保留对话历史,这些机器人可以模拟人类顾问般提供连续的帮助,而不是每次从零开始。
- 文档内容分析:LlamaIndex 不仅可以用于QA,还能让模型对文档集合进行总结、比较和提取。典型案例如:输入多个产品方案文档,请模型分析异同点;或者读取公司年报,生成一份投资者关心的要点总结。利用 LlamaIndex 的 Sub-question 查询引擎,可以将复杂请求拆解成子问题对不同文档分别提取信息,再综合成最终答案。这对于市场分析、竞品调研等场景非常实用,让 AI 充当分析师角色,从大量材料中挖掘有价值的结论。
- 知识库内容管理:有些应用更关注内容管理而非问答。例如利用 LlamaIndex 构建的索引,可以实现企业知识库的全文检索和推荐,甚至做自动标签和分类。例如HR部门上传了所有培训材料,LlamaIndex 索引后可以支持员工按自然语言搜索任何培训内容,还能结合 Agent 工具对新文档自动归类(比如识别属于哪个部门、技能主题)。这种场景突出 LlamaIndex 作为后端服务,由前端应用去调用其检索接口,将结果渲染给用户浏览。
- 自动化数据处理 Agent:在第2.4节我们介绍了 Agent 可以执行复杂任务。一个实际用例是财务报告助手:给Agent接入Excel处理工具和数据库查询工具,它可以读取财报Excel,计算各项指标,甚至画图,并用自然语言生成报告。这是典型的“LLM + 工具”的应用,LlamaIndex Agents 提供了现成的框架。再比如客户支持Agent,可以串联FAQ知识查询、工单系统API调用、邮件发送工具,使其在回答疑问后直接帮客户生成报告或下单,无需人工介入。这样的 Agent 落地价值很高,是未来产品的一大方向。
- 多模态内容查询:LlamaIndex 的数据连接器和工具支持图像、音频等非文本数据,这就打开了多模态的场景。例如将一批产品演示视频的字幕和讲稿索引进去,用户可以询问“视频里第10分钟介绍了什么”,系统检索字幕后回答。或者Agent配合图像OCR工具,用户上传一张流程图,Agent读取图中文字并接着回答。虽然多模态目前仍以文本为主轴,但 LlamaIndex 已为这些场景提供了接口,产品经理可以大胆构思跨媒体的AI助手。
- 模型微调与评估:LlamaIndex 也能助力模型的持续学习。通过 Observability 模块,可以收集用户提问和答案,以及参考的文档段落。这些数据可用于离线分析哪些问题没有答案、答案是否准确。进一步地,还可以汇总高频问题,组织Domain知识对基础模型进行微调(Fine-tune),以提升其在该领域的表现。虽然这超出了 LlamaIndex 本身功能,但它为此提供了非常干净的数据抽取管道。例如只取用户提问和模型答案,就可以构建微调样本。对于产品经理而言,这意味着知识库助手是可以进化的:一开始不懂的问题,通过一段时间收集,可以补充知识或更新模型,从而不断改善效果。
值得注意的是,以上很多场景不是孤立的,一个实际产品往往是多种能力的结合。例如,一个企业内部智能助手,既能回答知识库问题,又能帮忙预订会议室(Agent 调用日历API),还能分析上传的文件。LlamaIndex 的模块化让这些功能可以渐进式添加:先上线QA功能,反响不错再加入Agent工具操作,随着数据积累再做模型优化。对于产品经理来说,这提供了很好的路线:从小切口进入,逐步扩展功能,降低风险的同时不断为用户带来新价值。
一些成功的案例也印证了 LlamaIndex 的应用潜力。例如 KPMG 内部构建了一个知识助理,用 LlamaIndex 作为底层来连接企业海量文档,提供给员工便捷的信息查询;知名创投公司用它开发财报分析Agent,实现了从繁杂文档中自动提取投资要点;还有公司将 LlamaIndex 应用于客服聊天,显著缩短了新机器人从搭建到见效的周期。这些案例都表明,LlamaIndex 并不只是“实验室产物”,而是已经在真实场景中创造了价值。
与其他类似工具的对比优势(以 LangChain 为例):
市面上用于构建 LLM 应用的框架还有不少,其中最常被拿来与 LlamaIndex 比较的就是 LangChain。两者在功能上有部分重叠,也各有侧重。作为产品经理,我们不妨从宏观视角看下 LlamaIndex 相对于 LangChain 的优势,以及选择两者的考量。
1. 定位与专长对比:LangChain 的定位是一个通用的 LLM 编排框架,最初就提供了 Chains、Agents 等全套组件,覆盖从 prompt 模板、对话记忆、各种工具库、到多模态输出等方方面面。它的目标是全面满足复杂应用开发。相较之下,LlamaIndex 起步时是围绕数据接入与索引这一垂直方向,后来才逐步扩展功能。因此 LlamaIndex 的核心专长在于检索增强和数据相关的优化,比如提供了丰富的索引类型、文档更新机制、高效的批量数据处理等。一句话总结:LangChain 像一个多面手,面向各种LLM流程;LlamaIndex 则更像一位图书管理员,擅长整理和提供知识。对于文档驱动的应用,LlamaIndex 有更深入的支持。
2. 易用性与开发效率:LlamaIndex 强调简洁和快速上手。官方经常展示“五行代码建索引、问问题”的示例,从加载数据到得到回答非常直观。这一点对于想验证想法的产品团队很重要,可以在极短时间做出原型。例如处理几份文档的RAG问答,LlamaIndex 的代码可能不到 LangChain 的一半长度。LangChain 则因为模块更多,初学者往往需要了解 Chains、Memory、Retriever 等各部分才能串起来。所以在简单场景下,LlamaIndex 能让团队更快产出结果。当然,LangChain 也有高级用法的封装,但总的来说,LlamaIndex 为文档QA这类典型用例提供了更直接的路径。
3. 检索与索引能力:正如前面详述的,LlamaIndex 有多种索引方式,尤其是 Tree Index、Keyword Index、Knowledge Graph Index 等,这是 LangChain 没有内置的特性。LangChain 的检索通常依赖向量数据库或者 BM25 索引,需要开发者自行组合。但 LlamaIndex 拥有一整套针对文档语义的索引方案,而且支持在引擎内进行路由组合(RouterQueryEngine)。这使得复杂检索策略在 LlamaIndex 中实现更为便利。另外,LlamaIndex 对 增量更新 的支持也很好,可以对索引执行插入、删除操作;而 LangChain 则更多交给外部数据库去处理增删改。因此,在知识库维护层面,LlamaIndex 体现了更强的灵活性。
4. 综合生态能力:LangChain 在生态上目前更为庞大,集成了上百种工具和模型接口,社区也非常活跃。这意味着如果你的应用需要多步骤复杂流程(比如在一个 Chain 里调用不同模型、汇合结果),LangChain 提供了许多现成模板。而 LlamaIndex 则直到最近才推出 Workflows 来支持多步骤场景,不过其特色是事件驱动模型,和 LangChain 静态链式稍有不同。对于需要高度自定义流程的项目,LangChain 可能胜任度更高,因为它提供的钩子和插槽更多。但反过来说,LlamaIndex 通过 Agents 也在迎头赶上,允许复杂决策和工具使用。因此决策依据常常是:如果主要需求是让 LLM 用好本地数据,LlamaIndex 会是更高效的选择;如果需求是编排很多不同的LLM操作(比如对接多个模型、多模态交互等),LangChain 可能提供更多便利。
5. 性能与优化:在性能方面,两者很大程度取决于底层模型和数据库。不过,一些开发者反馈 LlamaIndex 在特定 RAG 技巧上做了更优化的实现,使其在大文档场景或层次查询上表现出色。例如,使用 Tree Index 时,LlamaIndex 可以快速缩小检索范围,在几千页的文档中仍有不错效率。LangChain 则因为没有这类特殊索引,需要靠外部搜索算法支持,可能在类似场景下不如 LlamaIndex 简洁。另一个角度是迭代速度:LlamaIndex 官方团队紧跟前沿研究,快速加入了例如 OpenAI 函数调用、ChatGPT 插件支持等新功能。LangChain 也很积极但模块更多可能更新没那么集中。对于追求最新能力的团队,LlamaIndex 的敏捷更新也是一大优势。
如果用一句比喻:LangChain 是一个“瑞士军刀“”,模块繁多可以组合出各种玩法;而 LlamaIndex 是一个“专业工具箱”,里面每样工具都围绕让 LLM 更好地使用你的数据而设计。两者并非水火不容,实际开发中也经常搭配使用。但在需要取舍时,可以参考他人经验:总结道:当你需要一个简洁轻量的方案,快速实现文档类RAG功能时,LlamaIndex 更高效;而当你的项目复杂度高、需要精细控制每一步时,LangChain 提供的灵活度更好。这基本概括了选择的依据。对于产品经理而言,重要的是根据项目需求和**团队技术偏好**选择合适的工具。如果团队主要目标是构建一个知识库问答或文档聊天产品,LlamaIndex 能以更少的样板代码和更完善的检索细节帮你达成;反之若产品涉及跨系统流程和多模型协同,可以考虑在 LangChain 框架下融入 LlamaIndex 作为检索模块,各取所长。
面向产品设计的价值总结:
通过上述全面介绍,可以看到 LlamaIndex 从设计思想到具体实现,都紧扣着一个核心目标:让大型语言模型更方便地接入和利用定制数据。这种能力对于许多产品来说意味着质的飞跃——AI 不再是一个封闭的黑箱,而成了可以融合企业自身知识、为用户提供量身定制服务的智能组件。
对于产品经理而言,LlamaIndex 带来的价值体现在:
- 落地速度:丰富的开箱即用模块和简洁的API,使得原型验证和产品迭代大大加快。一些原本需要NLP专家定制的功能(如文本分割、嵌入、相似度搜索),现在开发团队无需从零开发,直接调用即可。这意味着可以更快推出最小可行产品(MVP),抢占市场先机。
- 灵活扩展:模块化架构保证了随着需求增长,可以平滑扩展功能而不推翻重做。例如先上线问答,再逐步加入多轮对话、Agent 工具等,实现产品功能的横向丰富。并且由于配置灵活,可以根据用户反馈不断优化体验,而不受限于框架本身。
- 可靠性和可控性:LlamaIndex 帮助构建的系统有较强的可解释性(回答基于检索内容,可以溯源),也有监控手段掌握模型行为。这对产品运营很关键——遇到错误答案,可以分析是哪段内容导致,从而有针对性地调整。例如发现某类别问题总答不好,就可以扩充索引或微调模型。相比纯端到端的大模型,这种可控性降低了 AI 失误带来的风险,让产品更可预期。
- 技术前瞻性:LlamaIndex 官方团队和社区活跃度高,紧跟最新技术浪潮(如函数调用、长上下文、新向量算法等)。选择这个框架,等于站在一个不断演进的平台上,未来有新能力出现通常都能较快集成进来。这对产品规划来说也是利好——可以顺势而为,不断给用户带来惊喜的AI新功能,而不用担心底层实现跟不上时代。
大模型社区
现在主流社区就是HuggingFace和ModelScope,区别就是前者国外后者国内,HuggingFace是非常齐全,但是ModelScope目前也在逐步向HuggingFace靠拢。
具体使用方式这里就不介绍了,平台上都写的很清楚,需要使用SDK下的话,使用大模型写代码即可
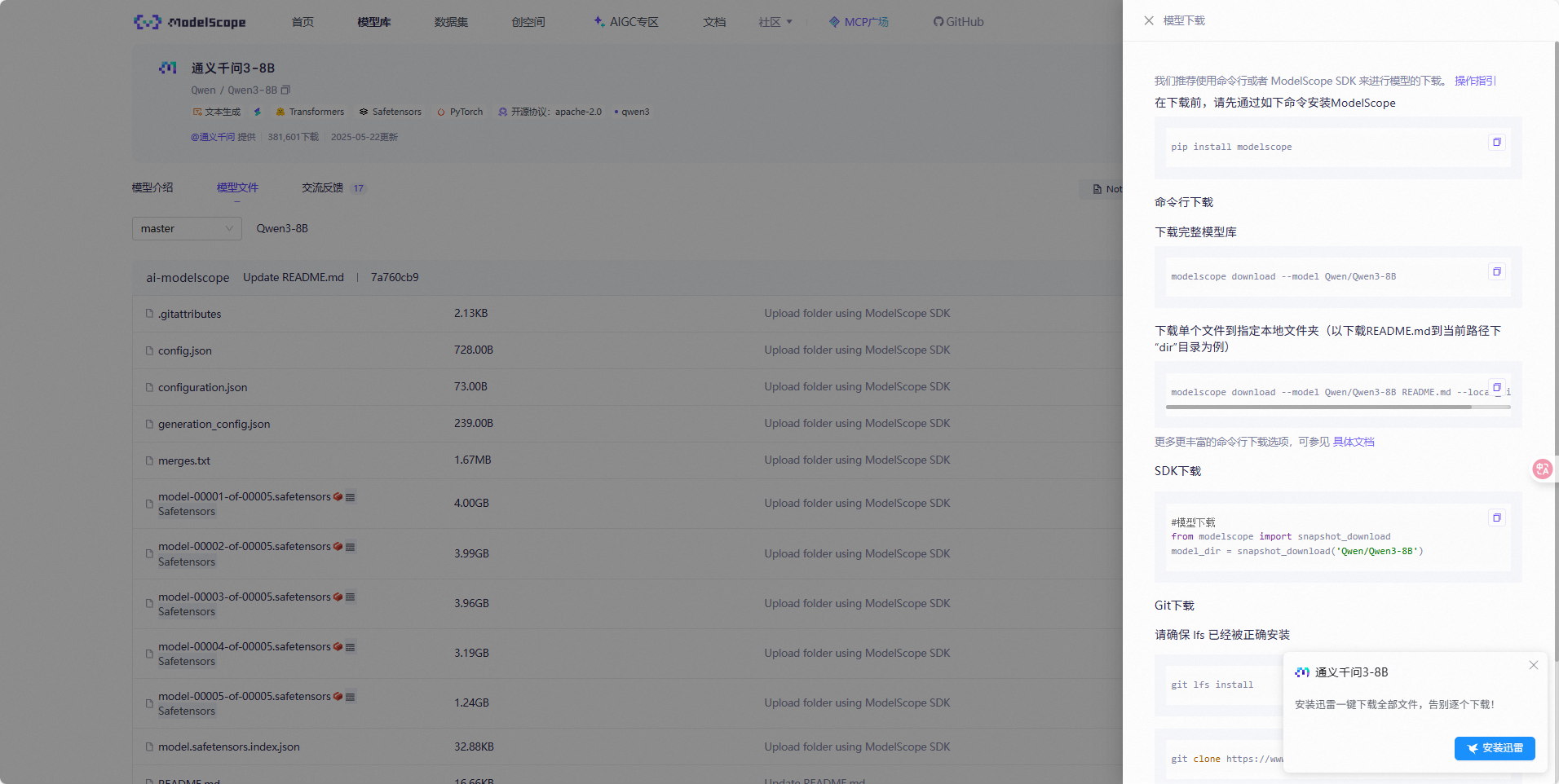
这里推荐是不要使用HuggingFace接口访问,因为网络问题,懂得都懂。ModelScope现在注册会送免费算力,但是也会有部分限制,因为不支持SSH。当下最合适的解决方案是去算力云上租用服务器,价格低廉并且很方便,pytorch和cuda都可以按照要求自选。
Embedding与向量数据库
Embedding 原理:向量嵌入及文本向量生成
什么是向量嵌入(Embedding)? 在机器学习领域,Embedding是由AI模型(例如⼤型语⾔模型LLM)将输入数据编码为高维向量的一种表示方式。这个向量包含了原数据的各类特征信息,每个维度对应数据在某一方面的属性程度。例如对于⽂本,其Embedding可能包含词汇分布、句法结构、语义主题、情感倾向、上下文关联等特征;对于图像,Embedding可包含颜色、形状、纹理、对象类别等;对于⾳频,则有频谱、节奏、⾳调⾼低等特征。通过模型学习,Embedding能够在向量空间中将语义相似的数据映射得彼此接近,从而用数值距离来衡量语义相似度。
常见的 Embedding 模型包括各大AI提供商和开源模型:
- OpenAI 提供高性能的文本嵌入API,如
text-embedding-ada-002模型,可将⽂本转换为 1536 维向量。OpenAI的Embedding服务易用但需付费,适合对精度要求高的商业应用。 - Cohere 提供多种多语种文本Embedding模型服务,与OpenAI类似通过API获取Embedding,特点是支持丰富的语言和语域。
- Hugging Face 平台汇集了大量开源Embedding模型(如Sentence-BERT系列、GPT嵌入模型等),开发者可以在本地部署,如使用SentenceTransformers库获取嵌入向量。开源模型通常免费且可离线运行,但可能在效果或效率上略逊于专有服务。
- 此外,还有CLIP模型可生成图像向量,wav2vec2模型可生成语音向量等,涵盖图像、音频等多模态的Embedding需求。
Embedding模型的工作过程通常是:输入文本或其他数据 -> 经过预训练的神经网络编码 -> 输出一个定长的向量。例如,使用OpenAI的text-embedding-ada-002对一句话 “Your text string goes here” 产⽣的向量是一个长度为1536的数组,其中每个元素是一个浮点数,如 [-0.00693, -0.00534, ..., -0.02405]。这个向量在高维空间中紧凑地表示了句子的语义,模型已将句子的词汇、语法和语义等信息都融入到了向量的各个维度中。因此,如果我们对另一句话生成向量并计算二者距离,可以得到它们在语义上的相似度高低。
需要注意的是,不同提供商的Embedding在维度、侧重点上有所不同,但它们共享的理念是:让语义相关的输入拥有相近的向量表示。在构建问答系统时,我们通常会:
- 离线阶段对知识库文本批量调⽤Embedding模型,存储所得向量及其对应文本。
- 查询阶段对用户问题实时调⽤相同Embedding模型,将问题向量与知识库向量进行相似度匹配,从而找出语义相关的内容作为答案依据。
这一流程将复杂的语义匹配简化为向量空间中的相似度计算,极大提升了检索效率与准确率。可以说,Embedding模型为非结构化数据打造了可计算的语义表示,是现代智能问答系统的基石之一。
相似性计算:欧几里得距离与余弦相似度
将内容转换为向量后,就需要衡量向量之间的“接近”程度,也就是计算相似度/距离。常见的方法包括:
- 欧几里得距离(Euclidean Distance):这是最直观的距离定义,即两个向量坐标差的平方和再开方,即 $d_{\mathrm{ED}}(\mathbf{x},\mathbf{y}) = \sqrt{\sum_i (x_i - y_i)^2}$。欧氏距离反映了向量在几何空间中的绝对距离,数值越小表示两个向量越接近、对应的数据越相似。在Embedding场景中,若向量未归一化,欧氏距离会同时考虑方向和长度差异。
- 余弦相似度(Cosine Similarity):衡量两个向量夹角余弦值的相似程度,计算公式为 $\mathrm{sim}_{\cos}(\mathbf{x},\mathbf{y}) = \frac{\mathbf{x}\cdot\mathbf{y}}{|\mathbf{x}||\mathbf{y}|}$。其取值范围为[-1, 1],1表示两个向量方向完全相同(即语义相似度最高),0表示正交无关,-1表示完全相反。由于只考虑方向不考虑长度,余弦相似度适合度量文本等语义向量(常常这些向量的绝对值大小不重要,方向才代表主题)。在实际应用中,我们往往会将Embedding向量归一化为单位长度,此时两个向量的余弦相似度与点积成正比。很多向量数据库直接使用**内积(dot product)**或其变体来实现高效近似计算,这与计算归一化向量的余弦相似度等价。
两种度量各有适用场景:欧氏距离对向量长度差异敏感,更适合在特征有实际量纲意义的情况下(如某些传感器数据);余弦相似度专注于方向相似,在处理文本语义时更受欢迎,因为不同句子Embedding的长度(范数)可能因字数或表达方式不同而异,但方向更能体现语义。总体而言,语义搜索领域常采用余弦相似度或内积作为相似性指标,因为我们更关心语义角度上的相近程度而非数值大小上的接近。在构建向量索引时,可根据具体Embedding特性选择度量方式。例如OpenAI的文本向量通常需要归一化后用余弦相似度匹配,而有些情况下(如使用二值化签名向量)可能直接用汉明距离等特殊度量。但大多数向量数据库实现中,用户无需手动计算,相似度由数据库在检索时透明地处理。
向量搜索技术:近似最近邻算法 (KNN, ANN)
直接计算查询向量与数据库中所有向量的距离(即暴力搜索)在数据量较小时尚可,但面对百万级甚至更大规模的向量集合时,遍历每个向量计算相似度将导致难以接受的延迟。为此,需要**近似最近邻(Approximate Nearest Neighbor, ANN)**算法,在牺牲少量精度前提下显著加速搜索。
1. 基于聚类的向量索引 (如 K-Means):这种方法通过聚类将向量集合划分为若干簇,每簇用一个聚类中心代表。常见实现是 K-Means 算法:
- 构建索引:对所有向量运行K-Means聚类,得到 K 个簇心(centroid)。这些簇心本身也是向量,概括了一组相近向量的分布。
- 查询过程:对于新查询向量,首先计算它与所有簇心的距离,只深入搜索与查询最近的几个簇,而无需遍历全集。这样大幅减少需要计算的向量数量。
- 性能权衡:聚类索引能将搜索复杂度从O(N)降低到O(N/K * some_factor)。对于超大规模数据,合适的K值(簇数量)能显著提高检索速度。然而,这种方法也有局限:如果查询点恰好落在两个簇边界之间,可能出现相关向量分散在多个簇而被遗漏的情况。为缓解此问题,实际系统常采用多重簇探测(如同时搜索前M个最近簇)来提高召回率,但这会牺牲部分速度优势。
2. 基于图/近邻的向量索引 (如 HNSW):相比聚类,另一类先进方法构建近邻图来加速检索。代表算法是 HNSW(Hierarchical Navigable Small World):
- 算法结构:HNSW构建一个分层的近邻图,最高层包含较粗粒度的连接(长跳边)用于快速缩小范围,底层包含精细的连接(短边)保证精度。每个向量作为图节点,连接若干距离较近的邻居。构建时随机为每个点赋予不同层级并建立连接关系。
- 检索过程:从最高层的某个节点开始,逐层向下执行近邻搜索:在较高层快速跳跃靠近目标区域,在最低层局部精细搜索,找到与查询向量最近的结果。这种多层次近邻搜索类似“塔楼+跳表”的思想,先粗后细。HNSW的优势是即使数据规模很大,依然可以在保证较高召回率的同时显著加快查询速度,被证明能接近精确搜索的效果但速度快几个数量级。
- 资源开销:HNSW以空间换时间,需要在内存中存储整个图和所有向量,占用较大内存。随着数据量增长,图的构建和维护也有一定成本。但大多数向量数据库采用HNSW或类似变体作为默认索引,因为在内存可接受的范围内,它提供了出色的查询性能和结果质量平衡。
- 应用:包括 Faiss、Qdrant、Weaviate 等在内的多款向量数据库内部都实现了HNSW索引,可支持增量添加数据和近实时搜索。同时HNSW也适合作为通用库被开发者直接使用,典型实现如 nmslib 或 hnswlib 库。
3. 其他ANN方法:除了聚类和图,还有基于树结构(如KD-Tree、Ball-Tree在低维时可用)、基于哈希(如LSH,通过哈希函数将近邻概率映射碰撞)、基于量化压缩(如PQ/OPQ,对向量分块量化降低精度换取更小存储和更快比较)等方式。实际系统中往往结合多种技术:例如Faiss支持IVF+PQ(利用聚类粗选+向量压缩)、ScaNN等Google算法结合矢量旋转和压缩等。这些方法或提高速度,或降低内存占用,构成了ANN领域丰富的工具箱。
向量搜索技术的演进目标是在尽量不牺牲准确率的前提下,实现亚线性级别的查询性能。具体选用哪种ANN算法,取决于数据规模、维度高低、硬件条件(内存/存储)以及对更新删删操作支持的要求等。在实际产品中,我们经常选择HNSW作为默认索引(高性能通用解),在超大规模或内存受限时引入IVF+PQ等组合索引,以在性能、成本和精度间取得最佳平衡。
向量数据库核心能力:存储、检索与更新操作
向量数据库(Vector Database)作为专门管理向量数据的数据库系统,提供了一系列核心功能,使开发者能够方便地对向量数据进行CRUD和查询操作。主要能力包括:
- 数据导入(写入):支持批量或逐条插入向量及其关联元数据。通常需要先对原始数据(如文档文本)生成Embedding向量,然后通过数据库提供的API将 向量-文档ID/内容/元信息 等记录存入。许多数据库也支持直接传入原始数据由其内部调用模型生成向量(如Weaviate可以内置一些Transformer模型)。高效的数据导入对构建初始索引非常关键。
- 向量存储:底层以特定的数据结构(比如HNSW图、倒排索引+向量块等)存储向量,以便快速查找。同时保存每条向量的元数据(如文本内容或文档标识、类别标签等)。向量数据库通常允许针对每条向量存储用户自定义的属性字段供过滤查询使用。例如,可以为知识库段落向量附加来源文档ID、段落章节号等字段,在检索时与向量相似度一起作为限制条件。
- 相似性查询:这是向量数据库最核心的功能。用户提供一个查询向量,数据库返回与之最相似的Top K向量集合以及相似度分数等。相似性查询一般以K近邻搜索实现,并利用前述ANN算法加速。很多数据库支持同时指定过滤条件,如只在特定标签的数据子集中搜索,从而实现向量+结构化的组合查询(也称“混合搜索”或Hybrid Search)。查询结果通常会返回向量对应的原始内容或主键,以及相似度评分供应用层决策。
- 更新与删除:成熟的向量数据库应支持对已存储向量的更新(Update)和删除(Delete)操作。更新可能涉及替换向量或修改其元数据;删除则需将该向量及内容从索引移除。由于某些索引结构(如HNSW、IVF)并非天然易于动态更新,数据库内部会处理增量维护或延迟重建索引等细节,保证新插入的数据可被检索,以及已删除的数据不再干扰结果。比如,Milvus通过标记删除和定期重建分片索引方式处理删除;Faiss的HNSW实现也支持增量添加节点。实时性方面,不同数据库对新增数据可检索的延迟有所不同,一般都在秒级以内,能够满足大部分在线应用的需求。
- 扩展性与高可用:除了基本操作接口,作为数据库系统还需要考虑横向扩展和容错。例如,是否支持分布式部署以存储海量向量(部分开源产品如Milvus支持分片集群,商用服务如Pinecone、Azure Cognitive Search也提供托管扩容能力);是否提供副本来高可用;数据如何持久化到硬盘防止丢失等等。这些特性保证了向量数据库在生产环境的大规模可靠运行,但具体支持情况因产品而异(见下一节对比)。
- 其他功能:一些向量数据库提供高级功能如异步批量查询、时间版本管理(如Chroma支持对数据集进行版本控制以便回溯)、安全权限、数据可视化分析等。这些不是所有产品的标配,但体现了不同产品的特色定位。例如,Weaviate集成了知识图谱组件和模块化的推理插件,Qdrant强调丰富的过滤条件和地理空间向量搜索,Milvus作为基础引擎则追求极致性能和横向扩展。
简而言之,向量数据库通过类SQL式的易用接口包装了底层复杂的向量索引,实现了“像操作传统数据库一样”来管理和查询向量数据的体验。对于开发者而言,不必关心ANN算法的实现细节,只需调用诸如.add()添加向量、.query()查询相似项、.update()更新、.delete()删除等方法即可完成相应功能。向量数据库承担了存储优化和检索提速的工作,在保证高维相似度搜索高效的同时,也逐步提供了与传统数据库相当的数据管理能力。
重点向量数据库分析
当前业界有众多向量数据库产品和库。本节挑选其中具有代表性的几个进行介绍和比较,包括开源嵌入库(Faiss)、新兴本地向量库(Chroma),以及主流的向量数据库服务(Weaviate、Milvus、Qdrant)。
Faiss:高性能向量检索库
Faiss(Facebook AI Similarity Search)是由Facebook AI Research开源的用于向量相似搜索和聚类的库。它本质上是一个C++实现的算法库,提供Python接口,可以被集成到应用或其它数据库中使用,而非一个独立的数据库服务器。
- 算法特性:Faiss内置多种近似最近邻索引,包括平⾯扫描(Brute-Force)、IVF(倒排文件,使用K-Means聚类生成簇心加速搜索)、HNSW(小世界图)、PQ(产品量化压缩向量)等,可根据数据规模和硬件选择组合。它支持对上亿向量进行搜索,并提供GPU加速版本在大型数据集上取得业界领先的性能。
- 部署方式:Faiss通常以嵌入库形式与应用程序打包部署。例如,在Python中通过
faiss库使用;或者被其他向量存储作为底层引擎(如LangChain的FAISSVectorStore即利用Faiss实现)。由于Faiss不具备网络服务接口,如果需要跨进程/跨机器使用,开发者需要自行构建服务层或使用第三方封装。 - 优势:极高的检索性能和多样的索引策略是Faiss最大亮点。官方提供丰富的调优工具和评估脚本,方便在不同精度要求下找到最佳配置。另外Faiss社区活跃,作为事实标准有大量学术和工业支持,其算法更新常融合最新研究成果。
- 局限:Faiss并非完整数据库。它缺少原生的持久化(需要自行保存索引到磁盘)、权限管理、元数据过滤等功能。对动态更新支持有限,一些索引(如IVF,PQ)增删向量需要重建或维护较复杂的数据结构。不过,Faiss提供了基础组件,开发者可在其上构建更高级的功能。如果项目已经有数据库,希望增加向量搜索功能,常考虑直接在现有堆栈中嵌入Faiss。这也是许多云厂商产品的思路(如Pinterest等构建内部向量服务时使用Faiss作为核心引擎)。
应用场景:Faiss适合需要自定义优化的场景,比如离线批处理大规模相似度计算、研究实验向量算法、或在资源受限环境(如移动端)通过量化压缩嵌入近似搜索。对于不需要完整数据库功能但追求顶尖性能的技术团队,Faiss无疑是首选方案之一。
Chroma:嵌入式向量数据库
Chroma 是近年兴起的开源向量数据库,定位于面向开发者的本地优先的向量存储解决方案。它以Python实现,主打易用性和与应用的紧密集成。
- 架构特点:Chroma可以以多种模式运行:既可作为嵌入式库在Python脚本或Jupyter笔记本中启动一个内置数据库,也可持久化存储数据到本地文件(采用DuckDB作为底层存储引擎),还支持通过Docker容器运行为一个独立服务以供远程访问。这种灵活性使开发者能在开发阶段快速本地实验,在生产部署时再切换到服务模式而无需更改代码。
- 索引与功能:Chroma默认使用HNSW索引进行向量搜索,支持基本的添加、更新、删除、查询操作。每条向量可附带元数据,Chroma也支持基于元数据的简单过滤查询。它紧密集成LangChain等应用框架,提供便捷的方法将文本数据转入Chroma存储并进行相似性检索。Chroma的数据可以通过
persist()保存到本地,以方便下次加载继续使用,这是其“开箱即用”体验的一部分。 - LangChain 支持:作为LangChain生态中颇受欢迎的向量存储,Chroma有专门的接口类,可以非常方便地被用作
VectorStore组件。比如通过Chroma.from_documents(documents, embedding_function)一行代码即可完成批量数据嵌入和导入,并用.similarity_search(query, k)检索最相似文档。这种高度整合降低了构建原型问答系统的门槛。 - 更新/删除能力:Chroma支持
.update()和.delete()操作对已存在项进行修改和移除。内部通过DuckDB表管理向量和元数据,因此更新删除操作的性能相对一般数据库尚可接受,但对于特别频繁变动的数据集,Chroma的效率和索引及时性可能不如专门设计的服务型数据库。 - 优势与局限:Chroma的优势在于轻量易用——无需复杂部署,几行代码即可跑通本地向量搜索;并且社区活跃,围绕LangChain等用例有丰富教程和示例。它适合作为应用的一部分嵌入其中。然而,由于Chroma目前主要运行在单机环境,在数据规模和并发方面有一定局限,且缺少企业级的权限、多租户和监控管理工具。因此,更倾向用于中小规模应用或作为大项目的原型验证。随着Chroma发展,未来可能增强分布式和生产部署能力,但现阶段在TB级数据或高QPS场景下,仍需评估其是否胜任。
Faiss vs Chroma:性能、部署与使用差异对比
在选择向量数据库方案时,Faiss 和 Chroma 各有优劣,决策应视具体产品需求而定。以下从多个方面对两者进行比较:
-
易用性:Chroma 胜在简单直观的 API 和开箱即用。初创项目或原型开发时,使用 Chroma 可以快速搭建起检索功能。而 Faiss 作为底层库,虽然功能强大但需要开发者自行编写索引构建和查询代码,学习曲线相对更陡峭。如果团队缺乏机器学习工程经验,Chroma 更容易上手。
-
性能规模:Faiss 在海量数据和低延迟场景下表现卓越。得益于高级算法和GPU加速,它可以支持上亿向量的近似搜索并保持响应迅速。Chroma 则更适合中等规模数据,在单机内存范围内提供足够好的性能。当数据量远超内存或需要极限优化时,Faiss 会更有优势。另外,Faiss 能针对具体数据分布调优索引结构(如使用IVF,PQ降低内存占用),这些都是 Chroma 当前不具备的细粒度优化能力。
-
部署维护:Chroma 可以嵌入在应用代码中,也能独立启动服务,比较灵活简单。它的持久化特性让系统重启后数据依然可用,这对实际产品非常重要。Faiss 则通常作为嵌入库使用,不带完整的服务包装。要在生产中用 Faiss,工程师往往需要自行构建一个服务(例如REST API)来封装 Faiss 查询,以便应用调用。这增加了开发和维护成本。但相应地,也给予了团队完全的自主控制和优化空间。如果公司已有成熟的后端团队,Faiss 的库模式并不成问题;但如果希望尽量减少运维工作量,Chroma 现成的服务化方案可能更吸引人。
-
生态集成:Chroma 已被许多上层框架直接支持,如 LangChain 将其作为默认向量存储接口之一。这意味着如果产品使用这些框架,选用 Chroma 会很方便地打通数据管道。Faiss 虽没有特定框架绑定,但作为事实上的行业标准,很多开源项目也提供了 Faiss 的支持或适配。简单来说,Chroma 对应用层开发者友好,Faiss 对系统级开发者友好。
-
社区成熟度:Faiss 发布于 2017 年,经过多年的打磨,在学术界和工业界都有大量成功应用,稳定性和可靠性高。Chroma 则是 2023 年才崭露头角的新秀,虽然发展迅速但相对而言成熟度略低。一些社区反馈指出早期版本的 Chroma 可能存在性能和稳定性问题,在特别看重生产可用性的场合,需要仔细评估其版本更新和支持情况。不过鉴于 Chroma 开源并有创业公司支持,其迭代在加快,可靠性也在提高。产品经理在决策时,应考虑项目的时间窗口和风险偏好:追求稳妥可考虑 Faiss,追求敏捷则可尝试 Chroma 并注意跟进其发展。
总结:Faiss 更像“发动机”,Chroma 更像“整车”。Faiss 为追求极致性能的人提供了强大的引擎,但需要工程师组装调校;Chroma 则提供了一辆开出去就能用的车,可能极限速度不如定制引擎,但胜在省心省力。在 AutoGen 等多智能体应用中,如果知识库规模适中且希望快速验证功能,Chroma 会是优先选择(其默认集成也印证了这一点)。而对于需要处理超大数据或者对检索性能要求苛刻的产品,Faiss 则值得投入工程资源去集成优化。
Weaviate、Milvus、Qdrant简要介绍:
- Weaviate:开源的企业级向量数据库,以丰富的功能著称。Weaviate支持可扩展的分布式部署,提供Restful和GraphQL查询接口,既能做向量相似检索,又能结合其内置的schema(模式)做类知识图谱的结构化查询。默认采用HNSW索引,亦支持IVF等索引类型。Weaviate独有特色在于可通过“模块”支持混合搜索(将向量相似度与关键词BM25结合)、文本-图像等多模态搜索,以及内置模型托管与调用(例如OCR模块、Q&A模块等插件)。它有完善的多语言客户端(Python/Java/JS等)和托管云服务WCS,社区十分活跃。Weaviate适合需要复杂查询和多样数据类型的场景,比如在同一平台上既存储文本向量又存储符号数据,希望一起查询。另外其GraphQL接口对熟悉知识图谱的产品经理也较友好。
- Milvus:由Zilliz主导的开源向量数据库,侧重高性能和规模。Milvus支持分布式集群,擅长在海量向量数据上进行快速检索。它提供多种索引类型(包括HNSW、IVF_FLAT、IVF_PQ、ANNOY等)供选择,并能针对不同集合设置分区和副本策略实现伸缩与容错。Milvus的架构在存算分离、异步任务上做了深度优化,适合十亿级向量规模或高并发查询的应用。其劣势是部署和运维相对复杂(需要掌握Etcd、存储卷等配置),对开发者的门槛比Weaviate/Qdrant略高。不过Zilliz也提供了Milvus的云托管版本以降低使用门槛。Milvus非常适合搜索引擎后台、推荐系统这类需要处理极海量数据且要求毫秒级响应的场景。在这些场景下,它的专业优化能胜任苛刻的性能要求。
- Qdrant:采用Rust开发的向量数据库,以高性能和易用API受到关注。Qdrant内置HNSW索引,并针对Rust的效率在内存管理和并发上表现优异。它支持payload(元数据)过滤查询,能够将结构化过滤条件与向量相似度一起用于结果排序。这使得Qdrant在电商搜索、地理位置搜索等需要结合属性筛选的应用中表现突出。Qdrant提供REST和gRPC接口,部署既可以是本地单机,也可以通过其官方的Qdrant Cloud云服务。不少开发者反馈Qdrant在中等规模(比如千万级向量)场景下有着出色的查询速度和稳定性,同时易于安装运行。它的缺点是目前不支持特别复杂的查询逻辑(如Weaviate的图谱功能)和多样索引,但在专注的相似度搜索任务上,Qdrant已经足够可靠。对于希望快速上线一个向量相似搜索功能、又不想调校太多参数的团队,Qdrant是很好的选择。
功能对比摘要:三者在核心能力上相近,均支持向量+元数据存储、HNSW近似搜索、水平扩展和实时更新。不同点在于:
- Weaviate提供最丰富的生态功能(模块化插件、GraphQL、多模式查询),适合复杂业务;
- Milvus在大规模检索性能上领先,适合超海量和高吞吐需求;
- Qdrant强调简单高效的向量搜索服务,在中等规模和过滤查询方面性价比高。
此外,它们都开源且社区活跃,各有成功的应用案例。选型时应结合自身团队技术栈和业务需求:例如,偏好用Python快速集成且数据量不算特别大,可以先试Qdrant;需要企业支持或一站式云服务的,可考虑Weaviate或Milvus的商业版本;如果已有大数据基础设施,希望内嵌向量搜索,也可以用Milvus等作为后端服务。下一节我们将更系统地给出选型建议。
(备注:除了上述,市面上还有 Pinecone、ElasticSearch 向量插件、Annoy 等众多选择,这里按问题要求聚焦介绍主要开源方案。)
问答系统应用:LangChain + Embedding + 向量数据库构建问答助手
结合Embedding和向量数据库,可以构建一个能够基于知识库进行智能回答的问答系统。其基本思想是RAG(Retrieval-Augmented Generation):通过检索相关知识来增强生成式模型的回答准确性。下面介绍其架构流程和实现要点:
系统架构与数据流
- 知识库准备:首先需要收集领域知识文档,并进行预处理(例如去除格式、按段落/句子切分)。然后利用选定的Embedding模型将每个文档片段转换为向量,并将向量连同原文本一起存储到向量数据库中。此过程通常离线进行,形成向量化的知识库索引。
- 用户提问:当用户提出问题时,系统会将该自然语言查询送入相同的Embedding模型,得到对应的问题向量。
- 向量检索:将问题向量提交给向量数据库,执行相似度查询,寻找知识库中与之最相近的若干内容片段。例如检索Top-5最相关段落。向量数据库返回这些片段及其原文内容。
- 生成回答:最后,将检索得到的相关文本片段与原始问题一道,送入大语言模型(如OpenAI GPT-4、ChatGLM等)进行处理。常见做法是在提示模板中填入这些上下文,引导模型“根据提供的资料回答问题”。由于模型此时有了额外的知识支撑,能够给出准确且有依据的回答,而非凭空生成。
- 结果返回:模型输出答案后,系统将答案返回给用户。如果需要,还可以同时返回引用的来源片段供用户参考,以增加可信度。
上述流程中,向量数据库充当知识检索器的角色,将用户问题的Embedding与海量知识Embedding进行匹配,快速锁定可能的答案依据。这种模式下LLM不需要存储所有知识,而是即时从数据库“检索即用”。因此即便底层LLM没有训练过某领域知识,也能通过引入向量数据库查找相关信息来回答,从而实现一种可控、可更新的问答能力。
模块接口与实现示例
为了实现上述链路,需要搭建各模块并打通接口:
- Embedding模块:可以使用现成的API或模型,如OpenAI的
Embeddings接口或HuggingFace本地模型。应用中通常封装一个embed_text(text: str) -> List[float]函数用于获取文本向量。 - 向量数据库模块:选择合适的向量数据库并建立连接。例如使用Chroma本地实例,或通过其Python客户端连接远程Weaviate服务器等。在LangChain框架下,这一步可以通过其内置
VectorStore对象完成,如FAISS.from_documents(docs, embedding)构建索引。 - 检索链(Retriever):将向量数据库包装为一个Retriever对象,负责根据查询返回匹配的文档集合。LangChain中通常用
vectorstore.as_retriever()实现,它可以设置返回文档数k等参数。 - LLM问答模块:可以使用现有的大语言模型接口,例如OpenAI的
ChatCompletionAPI或本地模型调用。需设计Prompt模板,将{context}占位符替换为检索到的文档内容,将{question}替换为用户问题,提示模型“基于上述内容回答以下问题”。 - 主链路:将上述检索器和LLM组装为一个整体链条。例如LangChain提供了
RetrievalQA链,输入问题后内部先调retriever取出文档,再调用LLM得到最终答案。
下面给出一个简化的代码示例,演示使用LangChain将这些组件串联,实现一个问答对话:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# 1. 准备知识文档并生成嵌入向量,存入向量数据库
documents = [ "文本片段1...", "文本片段2...", ... ] # 知识库内容
embeddings = OpenAIEmbeddings() # 选择OpenAI Embedding模型
vectordb = FAISS.from_texts(documents, embeddings) # 利用Faiss构建向量索引
# 2. 构建检索-问答链(RetrievalQA)
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(model_name="gpt-3.5-turbo"), # 或其他LLM,比如 ChatGLM
retriever=vectordb.as_retriever(search_kwargs={"k": 3}) # 每次检索3个相关文档
)
# 3. 针对用户问题执行问答
query = "天空是什么颜色?"
result = qa_chain.run(query)
print(result) # 预期输出: "天空是蓝色的。" 等基于知识库的答案
上述代码中,我们使用OpenAI的Embedding服务和LLM服务,并用Faiss作为本地向量索引。实际应用时,可以根据需要替换为其他提供商(如Cohere、HuggingFace)或数据库(如Chroma、Qdrant等)。整个问答流程抽象为qa_chain.run(query)一个调用,体现了LangChain封装的便利。
实践要点:
- 在回答过程中可以让模型引用提供的知识内容,从而提高回答的可信性和可追溯性。这也利于应对LLM可能的“幻觉”问题,因为模型有具体资料为依据。
- 构建提示时可以加入诸如“如果未找到相关答案,请回答不知道”等指令,避免模型在无知识时乱猜。
- 如果知识库很大,检索阶段可先基于元数据或简单关键词粗排,再用向量精排,以减少向量计算开销。
- 通过调节向量数据库的
k值,可以控制注入模型的文档数量,平衡上下文丰富度和模型输入长度限制(比如GPT-3.5有4096 token限制)。 - 支持多轮对话的话,需要结合对话历史,一般做法是将历史问答压缩为简要形式也作为上下文的一部分输入模型。
Embedding+向量数据库赋予了问答系统“检索知识”的能力,LangChain等框架则极大简化了集成难度,使开发者能够专注于提示设计和业务逻辑。在实际产品中,这类问答系统可以应用于智能客服(从企业文档中找答案)、知识助手(如医学问答基于医学文献)、代码问答(基于代码库和文档回答开发问题)等诸多领域,展现出很高的实用价值。
选型建议:如何根据需求选择向量数据库方案
在决定采用哪种Embedding模型和向量数据库时,产品经理和技术团队需要综合考虑数据规模、部署方式、生态兼容等因素。以下是一些选型建议:
-
根据数据量大小:
- 小规模数据(< 十万向量):可选择轻量级、本地化的方案,如Chroma或甚至直接使用带内存索引的Faiss。这类方案启动快、依赖少,非常适合原型开发和中小型应用。例如,一个企业知识库问答(几千条FAQ)用Chroma就完全胜任。
- 中等规模数据(几十万~千万向量):可以考虑单机版的向量数据库如Qdrant、Weaviate(单节点模式)或Milvus单机版。这些通常在一台性能良好的服务器上即可运行,并提供了一定索引优化和持久化能力,支持实时更新。如果数据在这个量级且增长可预期,Qdrant是一个高性价比选择,其过滤功能在丰富查询场景下很实用。
- 超大规模数据(上亿向量以上):建议选用支持分布式扩展的专业方案,如Milvus分布式集群或Weaviate的集群部署,又或是商用服务(如Pinecone、Azure Vector Search)来省却基础设施搭建。超大规模下,系统需要考虑分片、副本和容错,这些由成熟产品处理会更保险。Milvus在处理数亿向量时的性能表现和资源利用更具优势,并可根据业务水平扩展。
-
根据查询性能和实时性要求:
- 如果要求毫秒级响应且流量很高(如推荐系统每秒上千次向量查询),务必选择核心用C/C++实现、高效内存管理的数据库,如Milvus或Faiss库,或者硬件加速方案(Faiss GPU版本等)。它们针对性能极优化,延迟抖动小。
- 如果查询频率一般,但数据更新频繁(比如不断有新文档流入知识库),则需要关注数据库对动态插入的支持和索引重建开销。Qdrant和Weaviate在实时更新方面表现不错,新增向量可立即参与检索。Faiss则相对不擅长频繁更新(除非使用IVF动态索引但可能牺牲精度),需要定期批量重建。
- 对过滤查询(Filter/Hybrid Search)需求强烈的应用(如需根据用户ID、时间等筛选),应选择明确支持向量+结构化混合查询的产品。例如Weaviate和Milvus都支持将元数据作为条件过滤;Qdrant也以此见长,可以高效处理结构化条件下的向量检索。而纯算法库Faiss不自带过滤功能,需要应用层额外筛选,不如专门数据库方便。
-
根据部署和运维偏好:
- 云服务 vs 自建:如果团队后端实力较弱或者希望快速验证,可以考虑向量数据库的云托管服务。如Pinecone完全由云提供支持、无需运维;Weaviate也提供WCS云服务;Qdrant有Cloud版。这些服务提供便捷的Web界面、监控和自动扩容,但成本相对高、数据安全需信任第三方。反之,自建开源方案需要运维投入,但掌控数据和成本更有主动权。
- 编程语言与生态:要看团队技术栈。如果主要用Python开发,Chroma、FAISS、Weaviate客户端都很成熟;如果还有Java/Go等服务需要访问,Weaviate和Milvus的多语言SDK支持更完善。此外,是否和现有数据库系统集成也是考虑因素——有些传统数据库(Postgres via pgvector, ElasticSearch 向量插件等)开始支持向量,但功能有限。专门的向量数据库在生态和功能上更完善,但需要独立运维。可以根据现有架构选择:例如已有ElasticSearch,可以尝试其向量搜索插件作为过渡;纯新项目则倾向直接上专业向量库。
- 社区与支持:如果需要企业级支持和 SLA,选商业公司主导的产品会更稳妥,如Milvus(有Zilliz商业支持)、Weaviate公司提供企业版支持等。开源社区活跃度也要考虑,当前Qdrant、Milvus、Weaviate社区都相当活跃(Github上都有上千星),Issue响应也较及时,对于持续维护很重要。
-
根据应用场景特定需求:
- 移动端/边缘侧:若需在移动端或浏览器中实现简单向量搜索,可以考虑类似Annoy、FLANN这类超轻量库,甚至通过TensorFlow.js等在前端做小规模向量匹配。大多数向量数据库主要面向服务器端,但也有思考边缘推理结合局部向量存储的场景,此时可能需要特别方案。
- 安全与隔离:在多租户环境下,Weaviate和Milvus可以通过命名空间或分库来实现数据隔离。Chroma这种嵌入式的则需要在应用层自行区分上下文。如果数据有严格的安全隔离要求,选型时要确认数据库是否支持权限控制、TLS传输加密等。
- 扩展功能:某些产品有独特功能点可加分。例如Weaviate的模块机制可直接在数据库层面对查询结果进行二次处理(如Q&A回答、Zero-shot分类等),这在复杂AI流水线中或可减少一些开发工作。又例如Milvus正在探索对时间序列向量的支持,面向特定领域优化。这些“锦上添花”功能在需求匹配时也可以作为参考。
简而言之,如果是在早期探索阶段,数据量适中且希望快速验证产品,优先考虑简单易用的方案(如Chroma或Qdrant本地部署);随着业务发展,数据量变大或者功能需求增加,再评估更强大的解决方案(如Milvus分布式或Weaviate集群)。在做技术选型时,应尽量跑真实数据试用:把你的一批典型数据在备选数据库上建索引、跑查询,观察性能、准确率、以及集成难易程度。这比仅看参数更加可靠。
此外也别忘了Embedding模型的选型,它和向量数据库相辅相成:如需多语种支持也许Cohere比OpenAI更好,或本地部署要求下选择SentenceTransformer模型避免API调用延迟等等。这部分本文未详述,但产品经理应与算法工程师共同权衡,选择效果佳且成本可控的Embedding方案,然后再决定配套的向量存储。
语义搜索趋势与向量数据库在AI产品中的作用
借助Embedding将数据映射到语义向量空间,并使用向量数据库进行相似度检索,已经成为构建新一代智能问答和信息检索系统的标配技术。它突破了传统关键词搜索的限制,让机器能够以**“理解含义”**的方式去索引和检索海量非结构化数据。这一能力对于各种AI应用(聊天助手、推荐系统、搜索引擎等)都具有革命性意义。
展望未来,嵌入式语义搜索将呈现以下发展趋势:
- 向量检索无处不在:我们将看到越来越多的数据库和搜索引擎原生支持向量查询,把向量搜索当作标准功能提供。比如PostgreSQL已经通过插件支持向量列,ElasticSearch/OpenSearch也整合了ANN索引。这种趋势意味着开发者无需引入新系统,在现有数据库中就能完成语义向量匹配,降低了部署复杂度。
- 模型与数据库融合:未来的数据库可能内置某些Embedding模型或提供统一接口,让数据“即存即Embed”。同时LLM模型在检索阶段的参与度提高,比如结合向量数据库实现实时知识更新——LLM回答完后将新知识Embedding写回数据库,供下次检索,形成自我增强循环。
- 更高维度与精度:随着基础模型能力增强,Embedding维度可能进一步提高(从几千到上万),这对向量数据库的索引技术提出新挑战,也会驱动算法优化(如更高效的近似搜索和压缩技术)。我们也会看到针对多模态数据的统一向量空间,使图像、文本、音频可以共同检索,这需要数据库在索引层面对不同模态做适配。
- 生态与应用成熟:向量数据库领域的百花齐放还将持续,但经过市场和开源社区的验证,可能会有事实标准出现。无论是选型提到的Milvus、Weaviate、Qdrant,还是其它如Pinecone、VESPA等,每个都有独特优势。产品经理在规划AI功能时,需要对这些工具保持关注并理解其演进方向,以便在合适的时机采用最适合的技术方案。
可以肯定的是,向量数据库已成为构建认知智能应用的关键基础设施之一。在LLM大模型蓬勃发展的浪潮下,向量数据库扮演着知识库和大模型之间桥梁的角色:一端连接海量知识,使其可被高效检索,另一端服务于生成式AI,提供实时可靠的知识支撑。这种组合极大拓展了AI产品的能力边界。从智能问答、内容推荐,到个性化助手,各行各业都开始涌现基于Embedding+向量检索的创新应用。据IDC预测,RAG(检索增强生成)技术和向量数据库正成为AI领域布局的重点方向,全球向量数据库市场未来几年将保持高速增长。
对于技术产品经理而言,理解Embedding与向量数据库不仅有助于把握AI产品的实现原理,更能从中发掘新的产品机会。例如,将企业内部各种数据向量化后,就有机会构建统一的语义搜索门户;又或者利用用户行为Embedding进行精准推荐,实现差异化的智能服务。嵌入式语义搜索赋予产品“理解内容”的能力,而向量数据库提供了承载这份能力的土壤。在AI赋能产品的征途中,两者的结合将继续扮演催化剂的角色,推动更聪明、更贴近用户需求的产品形态不断涌现。
微调
一句话概述:LlaMA-Factory 好用但不好装,XTuner没有可视化界面但是好装,两者使用起来没有太大区别
工具概览与环境准备
提一嘴:能用git方式就不要pip,因为网络问题
| 项目 | LLaMA-Factory | XTuner |
|---|---|---|
| 主要支持模型 | LLaMA、BLOOM、ChatGLM 等 | InternLM(原生支持),也可扩展支持其他 HF 模型 |
| 安装方式 | pip + Git | conda + pip + Git |
| 微调方式 | 支持 LoRA、QLoRA、全参数 | 支持 QLoRA、LoRA、全参数 |
| 可视化工具 | Web UI(llamafactory-cli webui) | 无,主要通过配置文件和命令行操作 |
2.1 安装环境(LLaMA-Factory)
# 安装依赖
pip install -U huggingface_hub
# 克隆仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
2.2 安装环境(XTuner)
# 创建虚拟环境
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
# 克隆并安装 XTuner
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[all]'
模型下载
LLaMA-Factory 示例(LLaMA3-8B)
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --local-dir /root/models/Llama3-8B
XTuner 示例(InternLM2-1.8B)
from modelscope import snapshot_download
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm2-chat-1_8b',
cache_dir='/root/llm/internlm2-1.8b-chat')
准备训练数据
建议的数据格式如下:
{
"instruction": "请介绍LLaMA模型架构。",
"input": "",
"output": "LLaMA是一种Transformer架构的大语言模型……"
}
也可以使用工具把csv转成这种格式
LLaMA-Factory 数据路径
- 将数据放在
LLaMA-Factory/data/fintech.json - 在
dataset_info.json中注册:
"fintech": {
"file_name": "fintech.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"history": "history"
}
}
XTuner 数据配置
在配置文件 internlm2_chat_1_8b_qlora_alpaca_e3.py 中:
pretrained_model_name_or_path = '/root/llm/internlm2-1.8b-chat'
data_files = '/root/public/data/target_data.json'
微调流程
使用 LLaMA-Factory 进行微调(命令行)
创建配置文件 cust/train_llama3_lora_sft.yaml:
model_name_or_path: /root/models/Llama3-8B
finetuning_type: lora
per_device_train_batch_size: 2
learning_rate: 0.0002
num_train_epochs: 10
fp16: true
logging_steps: 5
save_steps: 100
dataset: fintech
dataset_dir: data
output_dir: saves/LLaMA3-finetuned
执行训练命令:
llamafactory-cli train cust/train_llama3_lora_sft.yaml
使用 XTuner 微调(命令行)
运行命令:
xtuner train internlm2_chat_1_8b_qlora_alpaca_e3.py
模型转换与合并
XTuner 模型转换为 HF 格式
xtuner convert pth_to_hf 配置文件路径 模型路径 保存路径
# 示例:
xtuner convert pth_to_hf ./internlm2_chat_1_8b.py ./iter_2000.pth ./hf_model/
模型合并(XTuner)
xtuner convert merge 原模型路径 adapter路径 保存路径
LLaMA-Factory 默认输出即为 HF 结构,无需转换。
对比
| 维度 | LLaMA-Factory | XTuner |
|---|---|---|
| 易用性 | 高,提供图形界面 | 中等,需编辑 Python 配置 |
| 支持模型 | 多种 HF 模型(LLaMA、Baichuan等) | InternLM 为主,可扩展 |
| 训练配置 | YAML 文件配置清晰 | Python 文件可编程式配置 |
| 输出格式 | HuggingFace 默认支持 | 需手动转换为 HF 格式 |
| 文档质量 | 中文文档较少,需看项目主页 | 提供官方中文文档 |
| 适合人群 | 入门用户、试验场景 | 有编程基础的工程师,部署场景 |
量化
一句话总结:能用QLoRA就用QLoRA
接下来围绕大模型量化方法对比:导出时量化 vs. 微调训练时量化(QLoRA)来说
在大语言模型(LLM)的部署和微调中,“量化”是一项关键技术,用于将模型参数从高精度浮点表示转换为低比特宽度表示,以减小模型体积、降低内存占用,并提升推理效率。简单来说,量化就像把连续的数值范围划分到有限的桶(bins)中,用更少的比特表示接近的值。这种技术可以大幅减少模型存储并加快推理速度(整数运算通常快于浮点)。本文将对比两种主流的模型量化方式:导出时量化(PTQ, Post-Training Quantization)与微调训练时量化(QAT, Quantization-Aware Training),并重点介绍作为微调量化方法代表的QLoRA (Quantized Low-Rank Adapter) 的原理、实现和优点。
什么是模型量化?
模型量化是指在不显著牺牲模型精度的前提下,用更低精度的数据类型来表示模型的权重和激活值。例如,可以将模型原本32位浮点表示的参数转换为8位甚至4位整数表示。通过缩放(scaling)和舍入(rounding)两个步骤,模型的连续权重值被映射到离散的低精度值:首先将权重按某个缩放因子压缩到目标范围,然后对压缩后的值取整,得到低比特的近似值。量化带来的直接好处包括:
- 模型体积与显存占用大幅降低:参数所需存储的比特减少,例如从FP16到INT8将内存占用减半。
- 推理速度提升:在支持低精度运算的硬件上,8-bit/4-bit的算术运算一般比16/32-bit更快。
- 能耗降低:对移动端和边缘设备来说,低比特模型所需的功耗更低。
当然,量化通常会引入一定的精度损失,因为参数表示不如原来精细,但合理的量化策略常能在精度与效率之间取得平衡。
导出时量化(PTQ)的特点
非常不建议导出时量化!!!
导出时量化(Post-Training Quantization, PTQ)是在模型训练完毕或微调完成后,针对已训练模型进行量化处理的一种方法。它通常不需要重新训练模型,仅利用一小部分校准数据来确定量化的缩放因子等参数,从而将模型权重离线转换为低比特表示。PTQ的主要特点和流程包括:
- 简便快速:PTQ不涉及梯度更新,只是在导出阶段对模型做后处理,因此实现简单、耗时短,适合在模型训练完成后快速产生部署版本。
- 轻度依赖校准数据:为了确定每一层权重/激活的量化缩放因子,通常使用一个**代表性数据集(校准集)**通过前向推理收集统计信息(如最小/最大值、直方图分布),但这个数据集规模一般不大(几百到上千样本即可)。模型权重本身在此过程中不更新。
- 硬件友好:PTQ后的模型可以直接用于部署推理,常见格式有 INT8、INT4 等,可通过支持相应精度的推理库或硬件直接加载运行。
- 精度影响:由于模型在训练时未考虑量化误差,PTQ在高比特(如8-bit)时通常能保持较高准确率,但在更低比特(如4-bit)时可能造成精度下降。为减小损失,研究者提出了多种改进(如分块误差最小化、激活感知校准等)。
PTQ的适用场景:当我们已经有一个性能良好的模型,希望在部署时减小模型体积、加速推理,PTQ是不二之选。尤其是在模型压缩比特宽度不算太低(如8-bit)时,PTQ几乎不需要模型重新训练,是最快捷的优化手段。然而,如果需要极致压缩(如4-bit甚至更低)且对精度要求较高,PTQ可能难以兼顾精度,这时就需要考虑更复杂的方案,例如量化感知训练。
微调训练时量化(QAT)的特点及应用
微调训练时量化(Quantization-Aware Training, QAT)是在模型训练或微调阶段就引入量化机制,让模型感知到量化误差并据此调整参数,从而在最终量化后能取得更好的性能。QAT的一般做法是:在每次前向传播时将权重和激活模拟量化(fake quantization),引入低精度带来的噪声;反向传播仍在高精度下计算梯度,但损失函数已经包含了量化误差项,使模型在训练过程中主动学习抗噪。通过在训练中“见过”量化后的效果,模型最后量化部署时的性能往往比未经QAT直接量化更好。
QAT的主要特点包括:
- 精度优势:由于模型参数在训练时已针对量化进行了调整优化,QAT方法通常能在相同比特宽度下达到更高的精度。特别是当比特宽度很低时(如4-bit),QAT模型的性能明显优于纯PTQ模型。
- 训练成本:QAT需要在训练中加入额外的模拟量化计算,训练时间略有增加。同时,为追求性能,有时需要在较大数据集上微调模型,以弥补量化带来的信息损失。这使得QAT相比PTQ在开发成本和计算开销上都更高。
- 适用场景:当部署环境资源极度受限、需要尽可能低的模型尺寸,或者精度要求高但必须使用低比特时,QAT是值得考虑的方案。QAT也常用于学术研究中验证新的量化算法效果。在CV领域,QAT早已用来训练8-bit甚至更低精度的模型,在LLM领域则刚兴起一些创新方法(如本文将详述的QLoRA)。
需要指出,传统意义上的QAT多指在整个模型上执行仿真量化训练,这对上百亿参数的大模型来说几乎是不可能的。而QLoRA提供了一种巧妙的“低开销QAT”途径:通过冻结主模型参数并以低比特加载它,同时只训练一个小型的LoRA适配器,既实现了量化下的模型微调,又避免了对巨量参数进行更新。下面我们详细介绍QLoRA的方法和优势。
QLoRA:x-bit量化微调的原理
最推荐的方式
QLoRA(Quantized Low-Rank Adapter)是2023年提出的一种高效LLM微调方法,它将预训练语言模型量化至4-bit后冻结不动,并在其上训练低秩适配器(LoRA),从而以极低的显存开销实现接近全精度微调的效果。QLoRA通过量化+LoRA的组合,实现了在单张48GB GPU上微调65B参数模型成为可能,同时性能几乎不下降,达到了16-bit全精度微调的同等水准。其核心思想和创新点可以概括为三点:
-
x-bit NormalFloat量化 (NF4) – 采用x位正态浮点数据类型来存储模型权重。NF4是一种信息论上最优的4-bit量化方案,针对正态分布的数据进行了优化。它不是简单线性均分范围,而是通过分位数近似确保每个量化桶包含等量的权重值,特别适合LLM权重这种近似正态分布的数据。相比传统均匀量化,NF4能在4位精度下保留更多信息,提高量化模型的表达能力。
-
双重量化 (Double Quantization) – 为了进一步压缩内存,QLoRA对第一次量化产生的系数(quantization constants,如每块的缩放因子和零点)再进行一次量化。具体来说,由于QLoRA对模型权重采用按块量化(每N个权重一个块,各自有缩放因子),会产生大量额外的浮点缩放常数。双重量化将这些量化因子的表示从原本的高精度进一步压缩为低精度(如8-bit),从而减少量化元数据的开销。这一步相当于在不显著影响精度的前提下,把量化过程本身的开销也降到最低,使总体平均每权重的内存占用更低。
-
分页优化器 (Paged Optimizer) – 由于仍需对LoRA参数进行训练优化,QLoRA引入了一种内存管理技巧:分页优化器。其思想借鉴操作系统的虚拟内存,当GPU显存接近耗尽时,动态将部分不活跃的内存页暂时转移到CPU内存(通过NVIDIA的统一内存UMA特性),以缓解峰值占用。特别是在反向传播阶段,优化器状态(如梯度、动量)可能瞬间膨胀占用显存,通过分页技术,这些优化器状态可以在GPU/CPU间来回调度,防止显存溢出而中断训练。Paged Optimizer保证了即使在单卡上微调超大模型,也能平稳度过瞬时的显存高峰。
综上,QLoRA通过NF4量化+双重量化将基础模型内存压缩到极致,再配合LoRA适配微调和分页优化控制显存,使得在不牺牲性能的情况下实现了对大模型的4-bit微调。值得一提的是,QLoRA方法微调所得的适配器权重很小(以7B模型为例,LoRA参数不到原模型0.1%),这意味着我们可以方便地发布和分享这些LoRA微调结果,而无需分发完整模型,大大方便了社区合作和模型版本管理。
使用QLoRA微调LLaMA的实践
QLoRA的落地非常依赖于开源工具链的支持。好消息是,Hugging Face团队已将QLoRA集成到Transformers和PEFT库中,使开发者可以相对容易地调用这一功能。下面我们以LLaMA模型为例,简要展示使用QLoRA进行微调的代码流程。我们假设读者已安装适当版本的库(建议transformers>=4.30.0,peft>=0.3.0,以及bitsandbytes>=0.39.0,以确保支持4-bit量化)。
首先,加载预训练的LLaMA模型和tokenizer,并通过BitsAndBytes配置开启4-bit量化:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "meta-llama/Llama-2-7b-hf" # 以LLaMA-2 7B为例
# 配置4-bit量化参数
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True, # 开启双重量化:contentReference[oaicite:40]{index=40}
bnb_4bit_quant_type="nf4", # 使用NF4数据格式:contentReference[oaicite:41]{index=41}
bnb_4bit_compute_dtype=torch.bfloat16 # 计算时使用bfloat16,提高速度:contentReference[oaicite:42]{index=42}
)
# 加载分词器和模型(使用device_map自动GPU映射)
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=bnb_config, device_map="auto")
以上代码通过bitsandbytes将LLaMA模型以4-bit NF4格式加载到GPU,并且使用bfloat16进行计算以平衡速度和精度。接着,我们需要准备模型进行LoRA微调:冻结高Bit权重、开启梯度检查点等。PEFT库提供了便捷的方法来处理这些细节,例如prepare_model_for_kbit_training函数会自动将某些层(如LayerNorm)设置为fp32以确保稳定,以及关闭不必要的参数的微调:
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
model = prepare_model_for_kbit_training(model) # 冻结部分权重,开启低比特微调所需设置
model.gradient_checkpointing_enable() # 启用梯度检查点,节省显存
# 设置LoRA微调配置
lora_config = LoraConfig(
r=8, # Rank维度
lora_alpha=32, # LoRA缩放因子
target_modules=["q_proj", "v_proj"], # 指定注入LoRA适配器的层,一般选取注意力投影层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM" # 针对自回归语言模型
)
# 将LoRA适配器附加到模型
model = get_peft_model(model, lora_config)
配置完成后,model已经包含LoRA参数(仅约占模型权重的极小一部分)并准备好在4-bit量化权重的基础上训练。接下来即可按常规流程准备训练数据并使用🤗 Transformers的Trainer或自定义训练循环进行微调。 训练完成后,我们可以选择合并LoRA权重到原模型并导出(这会得到一个实际等效于全量微调后的模型,可进一步用PTQ再压缩成更便于部署的格式,如GPTQ或GGUF),或者直接保留LoRA微调结果用于推理(通过在加载时应用LoRA适配)。值得注意的是,Transformer和PEFT库的更新使得加载QLoRA微调后的模型也很方便:在推理时可以直接通过AutoModelForCausalLM.from_pretrained加载基础模型并应用LoRA配置,自动得到4-bit量化的微调模型。
版本提示:请确保所使用的Transformers和PEFT版本支持QLoRA功能。例如,2023年5月之后的Transformers v4.30+和PEFT v0.3+已经集成了4-bit量化和LoRA训练的兼容支持。同时,bitsandbytes需要>=0.39.0以包含所需的Linear4bit低级实现。在实际环境中,可通过pip install bitsandbytes>=0.39 transformers>=4.30 peft>=0.3来升级这些依赖。
多卡训练
这里推荐的是用DeepSpeed,公认的最好用的框架,并且可视化界面上可以直接选用,非常方便,下面就只把主流的列出来
训练不管是多卡还是单卡,追求的本质就是过拟合
核心概念与并行范式
- 数据并行(DP / DDP):每张卡保存完整模型,切分批次后各自前后向,再用 all-reduce 汇聚梯度。实现简单、伸缩性好,是最常见起点。(docs.pytorch.org)
- 模型并行(Tensor / Layer / Expert):把一个大模型按张量或层维度拆到多卡,适合单卡显存放不下的大模型。Megatron-LM 的 tensor & pipeline 并行是代表。(github.com, docs.nvidia.com)
- Pipeline 并行:把网络层按顺序分段流水线,显存省,但带来 bubble 及 pipeline flush 开销。
- 混合并行:DeepSpeed、Megatron 等框架将 DP+Tensor+Pipeline 组合,按“横向切 batch、纵向切权重”最大化硬件利用率。(deepspeed.ai, deepspeed.ai)
- 完全分片数据并行(FSDP / ZeRO-3):进一步把参数、梯度、优化器状态都切片到多卡,仅在需要时拉回,实现近线性显存削减。(docs.pytorch.org, docs.pytorch.org, [medium.com][8])
主流框架速览
| 场景 | 框架 | 一句话特点 |
|---|---|---|
| 入门数据并行 | torch.distributed + torchrun:官方维护、零依赖、社区生态最大。([pytorch.org][9], [pytorch.org][10]) | |
| 超大模型显存优化 | DeepSpeed ZeRO-3/Offload:显存占用~1/10,参数可超 40 B。(deepspeed.ai) | |
| 极致大语言模型 | Megatron-LM:Tensor+Pipeline 并行、Ring-QKV Fusion。(github.com) | |
| 跨框架简化启动 | Horovod:一行命令把 TF / PT / MXNet 脚本扩展到多卡/多节点。([github.com][11], [idris.fr][12]) | |
| 零改代码快速启动 | HuggingFace Accelerate:自动生成 DDP/FSDP/DeepSpeed 启动脚本。([huggingface.co][13], [digitalocean.com][14]) |
模型部署
一句话概述:个人使用用ollama,生产环境现在多用vllm,LMDeploy国内开发、速度更快、值得尝试
部署详细方案建议看官方文档
部署方案对比:Ollama vs vLLM vs LMDeploy
-
Ollama: 主打易用性,开箱即用。优点是安装和使用非常简单,提供类似包管理的模型下载和管理机制,支持 Mac、Linux、Windows 跨平台。对于个人或轻量使用,Ollama 非常友好。但是在并发请求较多时性能一般:随着请求数增加,响应会变慢。测试表明在16并发请求下,每请求延时约17秒,而当增加到32并发时 Ollama 基本吃力,达到性能上限。因此 Ollama 更适合本地开发、个人助手等场景,不擅长大规模服务。
-
vLLM: 专为高效 serving 打造的推理引擎。其核心特色是异步批处理和高效内存管理(PagedAttention机制),能在高并发场景下保持优异吞吐。实验证明,在16并发时 vLLM 每请求延时仅约9秒,生成速度(tokens/sec)是 Ollama 的两倍以上;甚至在32并发下仍能平稳运行,产出每秒100 token,而 Ollama 在该并发下几乎无法应对。因此,vLLM 如同“跑车”,擅长高压力、大规模用户请求的场景。vLLM的缺点是部署稍复杂一些,需要使用其提供的OpenAI兼容服务器(
vllm serve)并配置模型路径,且目前仅支持Linux。总体而言,vLLM适合需要处理高并发、高吞吐的生产服务。 -
LMDeploy: 定位于极致性能优化和全面部署方案。其 TurboMind 引擎在单机性能上甚至超越 vLLM:官方数据显示请求吞吐比 vLLM 高出约1.8倍。这来自于持续批处理(persistent batch)、块状KV缓存、CUDA优化等一系列手段。LMDeploy 同时支持分布式部署,多机多卡扩展也很方便。在量化方面,LMDeploy支持权重量化和KV量化的组合,4-bit推理性能大幅提升且精度有评估保证。不过,LMDeploy 的使用门槛相对高一些:TurboMind 引擎需要预先转换模型格式,并且对环境依赖(CUDA版本、GPU型号)有要求;PyTorch 引擎虽易用但性能一般。LMDeploy 适合对性能要求极高的场景,比如需要以最低延迟为大量并发用户提供服务,或在有限GPU上榨取最大吞吐量的企业部署。开发者需要投入一些时间熟悉其配置和转换流程。
模型评估
模型客观评估目前用的多是国内的OpenCompass,是书生浦语(InternVL)生态链的一部分,但是目前更多的还是看主观评估,所以这里就略过直接。
RAG
后期补充
OpenWebUI
一句话概述:OpenWebUI就是OPENAI开源的最简便的能使用大模型前端界面的框架
OpenWebUI 简介
OpenWebUI 是一个开源、可扩展、完全离线运行的本地化 AI 界面项目,它通过统一的 Web 前端把多种大语言模型(LLM)推理后端整合在一起,让个人或组织能够像使用 ChatGPT 一样便捷地与本地或私有云中的模型交互,同时保证数据不出内网。官方定位是“Build the best AI user interface”,目前已在 GitHub 聚集了数万 Star 与活跃贡献者,并提供 Docker 镜像、二进制发行版以及 Kubernetes 部署方式,适合从单机爱好者到企业级 DevOps 的不同场景。
核心特性
-
多后端兼容
- 原生支持 Ollama 本地模型运行器,可一键加载 Llama 3、Phi-3、Mistral 等热门权重;
- 兼容 OpenAI-compatible REST API,只需填入 key 即可连接 Azure OpenAI、Moonshot、讯飞星火等云端服务;
- 通过自带 Adapter 机制,亦可接入 vLLM、TGI、LiteLLM 等推理框架,实现“同一前端,多种推理引擎”。(github.com, docs.openwebui.com)
-
离线运行与数据安全
整个栈可在内网部署,聊天记录、本地向量库、模型权重均存储在宿主机或私有存储中;前端为 PWA,可在手机安装离线使用,避免数据泄露风险。(docs.openwebui.com) -
内置 RAG(检索增强生成)工作流
系统内置嵌入检索引擎与文件分片管道,用户仅需在界面上传 PDF、Markdown 或网页链接,即可创建知识库,随后对话框会自动引用相关段落以支撑回答,实现“私有 ChatGPT Plus”。(github.com, medium.com) -
生产力辅助功能
- 多会话标签、角色预设与 Prompt 模板;
- “Follow-up Suggestion” 自动续写提示帮助用户快速迭代问题;
- 聊天记录一键导出 Markdown/JSON,便于归档与二次开发;
- 可选深色主题、快捷键、语音输入与 TTS。(github.com)
-
插件与可扩展性
前端基于 React + Tailwind,后端采用 FastAPI。开发者可以通过 extensions 把 SQL 查询、脚本执行、HTTP 调用封装成侧边栏按钮,无需修改核心代码即可扩展功能。官方文档演示了接入 Home-Assistant、Jira、GitHub Issues 等插件的示例。(docs.openwebui.com)
快速部署指北
以下示例以 Docker 单机部署为例,实际还可选用 Podman、docker-compose 或 Helm。
-
拉取镜像
docker pull ghcr.io/open-webui/open-webui:main通过 GitHub Container Registry 获取最新版镜像。(docs.openwebui.com)
-
启动服务
docker run -d \ --name openwebui \ -e OLLAMA_BASE_URL=http://host.docker.internal:11434 \ -p 3000:8080 \ ghcr.io/open-webui/open-webui:mainOLLAMA_BASE_URL指向本地 Ollama 实例;-p参数把容器 8080 端口映射到宿主 3000;- 初次访问
http://localhost:3000即进入注册页面。
-
配置模型
- 先在宿主机执行
ollama pull llama3下载权重; - WebUI → Settings → LLM Runners,选择 Ollama 并勾选 llama3;
- 点击 New Chat,下拉框即可看到新模型。
- 先在宿主机执行
-
启用 RAG
- 侧栏 Knowledge → Create KB,上传 PDF;
- 选择该知识库后再对话,模型将引用文档段落并附带标注。
主流模型选择
只说结论:目前可选的系列只有Qwen3和Llama3,下面说一下结合硬件条件怎么选模型
注意:这里只是说部署即推理的显卡,不能做微调相关操作,微调对显卡的要求高很多
1 ⸺ 轻量级本地推理(≤ 8 GB VRAM)
| 典型设备 | 推荐模型 | 加载形态 | 说明 |
|---|---|---|---|
| RTX 3050 / GTX 1650 / Apple M2 集显 | Qwen 3-4B / 1.7B / 0.6B | GGUF Q4_0 ≈ 2–4 GB | 4 bit 压缩后 2 GB 就能跑,适合离线问答、嵌入式边缘部署 (llm.extractum.io, qwenlm.github.io) |
| 同级显卡但想体验 Llama 语料 | Llama 3-8B | GPTQ 4-bit ≈ 6 GB | <6 GB 即可加载,Uns-loth 预量化包省显存 80% (huggingface.co, reddit.com) |
要求:日常问答/文案生成,吞吐低于 10 tokens/s 也能接受。
建议:系统内存≥ 16 GB,否则上下文一长就必须强制交换 (apxml.com)。
2 ⸺ 入门级单卡(12–16 GB VRAM)
-
最舒服的组合:RTX 3060 12 GB + Qwen 3-7B Q4 或 Llama 3-8B 8-bit。
- Qwen 3-7B 在 4 bit 模式下只占约 8 GB,仍能保持不错的中文/代码表现 (dev.to)。
- Llama 3-8B 若加载 8-bit(bits-and-bytes)需要 13-14 GB,可勉强塞进 16 GB 卡 (reddit.com)。
适合桌面开发者做低并发原型,或笔记本外挂显卡盒。
3 ⸺ 高端消费级单卡(24 GB VRAM:RTX 3090/4090)
-
最佳选择:
-
“极限尝鲜”:社区已成功把 Llama 3-70B 做到 2.55 bpw(≈ 24.5 GB)在 3090 上推理,不过速度只有 ~1 token/s,长上下文明显卡顿 ([reddit.com][8])。
如果你主要做 RAG / 文档问答,这一级别显卡足以支撑 8 K-32 K 上下文的日常业务。
4 ⸺ 工作站/服务器单卡(48–80 GB VRAM:RTX 6000 Ada、A100 80G 等)
- Llama 3-70B FP16 全量载入需 ≈ 161 GB,但 80 GB 卡配合 vLLM/TensorRT-LLM 可 pipeline 并行“拆半”装下,性能比 llama.cpp 快 70% 左右 (apxml.com, [jan.ai][9])。
- Qwen 3-32B FP16 或 Qwen 3-30B MoE(仅 3 B 活跃参数)都能满显存吃下,同时中文写作与代码能力更强 (qwenlm.github.io, dev.to)。
5 ⸺ 多卡 / 云端集群
| 集群规模 | 推荐模型 | 推理策略 |
|---|---|---|
| 2 × RTX 4090(48 GB 总) | Llama 3-70B Q4_0 ≈ 40 GB | 张量并行 + FlashAttention,可达 15 tokens/s (apxml.com) |
| 4 × A100 40G | Qwen 3-72B FP16 | DeepSpeed ZeRO-3 或 vLLM 分片推理 (dev.to) |
| 8 × H100 80G | Qwen 3-235B MoE | 每卡只需 ≈ 40 GB FP16;活跃子网 22 B 参数,延迟与 70B 相当 (qwenlm.github.io) |
企业如果已有分布式 GPU,可优先选 Qwen 3 的 MoE 系列:推理成本几乎与 30 B 相当,却能在复杂任务上逼近 100 B 水平。
速查表:显存预算 ↔️ 推荐型号
| 显存预算 | Llama 3 | Qwen 3 | 加载形态 |
|---|---|---|---|
| ≤ 8 GB | 8B GPTQ 4-bit (~6 GB) (huggingface.co) | 4B GGUF Q4 (~2–4 GB) (llm.extractum.io) | 量化 |
| 12–16 GB | 8B 8-bit (~14 GB) (reddit.com) | 7B 4-bit (~8 GB) (dev.to) | 量化 |
| 24 GB | 8B FP16 (18.4 GB) (apxml.com) | 14B 8-bit (~22 GB) (dev.to) | 原生 / 量化 |
| 48 GB | 70B Q4_0 (40 GB) (apxml.com) | 32B 8-bit (~40 GB) (dev.to) | 量化 |
| 80 GB+ | 70B FP16 (161 GB,总拆分) (apxml.com) | 30B MoE (≈ 22 GB 活跃) (qwenlm.github.io) | 分布式 / MoE |
AutoGen
面向产品经理的多智能体与RAG方案概览:
AutoGen Studio 是微软开源的 AutoGen 框架之上的低代码界面,旨在让开发者快速构建、测试和分享多智能体 AI 解决方案。它支持通过图形界面配置“智能体”(Agent)及其团队(工作流),让多个大模型驱动的智能体协作完成复杂任务。对于产品经理而言,这意味着无需深厚的编程功底,也能原型化复杂 AI 应用场景,例如自动化的旅游规划师、市场分析助手等智能代理团队。
AutoGen Studio的搭建流程
**环境准备:**要使用 AutoGen Studio UI 2.0,官方建议使用 Python 3.11 环境。确保本机已安装 Python 3.11 以避免兼容性问题;建议通过 Conda 或 venv 创建隔离的虚拟环境,这样不同项目的依赖不会相互冲突。准备好环境后,只需通过 pip install autogenstudio 一键安装所需的软件包。AutoGen Studio 会自动拉取所有依赖并完成安装。安装完成后,在终端运行启动命令,例如:
autogenstudio ui
即可启动 AutoGen Studio 的本地服务(默认使用 Uvicorn 网络服务器)。控制台将显示服务运行的 URL(例如 http://127.0.0.1:8081/build),用浏览器打开该地址,就能看到 AutoGen Studio 的 Web 界面。
从产品构建角度,AutoGen Studio 提供了“所见即所得”的体验:Build 页面用于拖拽/配置智能体和工作流;Playground 页面则允许我们运行工作流,与智能体团队交互并观察结果。接下来我们将详细介绍这些核心概念和配置方式。
核心概念一:代理(Agent)与大模型配置
智能体(Agent):在 AutoGen Studio 中,智能体相当于具备特定角色和能力的 AI 代理。可以将其类比为团队中的一个“员工”,能自主执行任务并与其他智能体对话协作。每个代理可以配置自己的“大脑”,即所使用的大语言模型(LLM)。实际上,代理的大脑就是某个后端 LLM 模型(如 OpenAI GPT-4、Anthropic Claude,或本地开源模型等)。AutoGen Studio 允许为代理配置多个模型,并按顺序优先使用;例如同时配置 GPT-4 和 Gemini,当首选模型失败时会回退到下一个模型。模型管理界面提供了“New Model”按钮来登记新的模型信息,包括模型名称、API Key、接口地址等。产品经理无需深入代码,通过 UI 填写并测试连接,即可完成模型接入的配置。
在具体实践中,配置代理大脑一般分两步:1)登记模型:如同新员工入职登记,先在 “Models” 菜单添加模型名称(比如 GPT-4 或 deepseek-coder 等)、接口凭证等。成功登记后,模型会出现在可用列表中。2)赋予代理大脑:切换到 “Agents” 菜单,选中某个代理,在其配置对话框中选择一个已登记的模型附加给它。例如,AutoGen Studio 自带一个名为 default_assistant 的代理,我们可以给它绑定 deepseek-coder 模型作为大脑。同样的方法可以给团队中的其他代理分配各自的大模型。需要注意,有些特殊代理不需要大脑,例如系统默认存在的 user_proxy 代理充当用户入口和任务转发角色,它仅执行指令本身不需要思考,因此无须配置模型。
AutoGen Studio 中代理的配置界面。用户可以通过图形界面为每个 Agent 选择关联的模型(作为“大脑”)或技能函数,以及设定其在工作流中的角色和参数
技能(Skill):技能是 AutoGen Studio 中定义的一段可执行的 Python 代码,用于让代理具备除纯语言模型对话以外的额外能力(例如调用API、查询数据库、执行工具操作等)。技能就像代理的特长或工具箱,产品经理可以预先定义好特定的功能函数,然后在界面上将这些技能赋予某些代理,使其在需要时调用这些函数来辅助完成任务。例如,AutoGen Studio 默认内置了 generate_images(图像生成)和 fetch_profile(获取资料)两个示例技能。点开 generate_images 可以看到,其代码在调用 DALL·E-3 模型以根据提示生成图像。我们也可以自定义技能,如编写一个爬取网页数据的函数,添加到技能库并赋予某代理,让它在任务中具备联网抓取信息的能力。通过这种设计,非技术背景的产品经理也能借助开发人员提前编写的技能模块,自由组合出功能丰富的智能体。AutoGen Studio 的界面使这一切变得直观:新增技能后,会出现在 Skills 列表,然后在 Agent 配置中可将该技能勾选附加给代理。
大模型与技能的配置意义:综合来看,AutoGen Studio 将复杂的智能体配置拆解为可视化的模块配置:产品经理可以选择某代理用哪个LLM思考,用哪些技能工具,从而低代码地定制代理行为。这降低了开发难度,也方便在迭代中快速替换模型或调整技能组合,极大提高了 AI 产品原型开发的敏捷性。
核心概念二:智能体工作流(Workflow)管理
单个智能体往往只能解决有限范围的问题,而 AutoGen Studio 的强大之处在于可以编排多个智能体协作解决复杂任务。这样的智能体团队协作通过 Workflow(工作流) 来定义。工作流类似于一个剧本,指定了有哪些代理参与、它们扮演何种角色、如何交替互动完成任务。
工作流角色与流程:以 AutoGen Studio 自带的 “AI旅游规划师” 工作流为例:它其实是由多个代理合作完成用户的旅游规划请求。其中,第一个代理 user_proxy 充当发起者 (Initiator)。当用户在界面提交一个旅游计划需求时,user_proxy接收该任务并将其交给下一环节处理。user_proxy可以理解为前台接待,不负责具体决策,只负责把用户的请求转交给负责分析的代理。接下来,travel_groupchat 代理扮演接收者 (Receiver)。它的功能是对来自 Initiator 的任务进行理解和初步拆解。在工作流配置界面查看 “Travel Planning Workflow” 时,可以看到只有 user_proxy 和 travel_groupchat 两个代理直接列在其中——这对应了工作流的第一层流程。然而,之前提到任务需要多个代理协作完成,那么其它代理去哪了呢?
答案是在 代理的层级组织 中。AutoGen Studio 支持代理调用/管理其他代理,形成层次化的团队结构。继续上述例子:点击 travel_groupchat 代理的配置,可以发现它关联了多个下属 Agent。也就是说,travel_groupchat 实际上是一个组长/主管代理,负责将任务进一步分派给其“员工”代理们,并汇总他们的结果。在 AI 旅游规划师中,这些下属代理可能包括:擅长行程生成的代理、擅长地图路径规划的代理、擅长图像生成的代理等。travel_groupchat 会将用户的旅游计划需求拆分成子任务,让不同专长的代理各司其职完成,比如一个代理负责生成5天的行程文本,另一个调用地图API绘制路线图,还有一个生成景点图片,最后再将这些结果汇总成完整的答复。通过这种工作流和层次结构设计,AutoGen Studio 实现了多智能体像团队一样协作:每个代理承担部分工作,互相通信协同,完成单个代理难以独立胜任的复杂任务。
Playground 运行与交互:配置好工作流后,就可以在 Playground(演练场)中让智能体团队上场“表演”了。产品经理或用户在 Playground 选择对应的工作流(如 “Travel Planning Workflow”),点击 Create 创建一个会话,然后即可输入任务请求。例如,我们给 AI 旅游规划师下达任务:“制定去成都旅游的5天计划,并画出路线图,并生成图片”。在 Playground 中发送这个指令后,前端会首先显示智能体最终给用户的响应(比如详细的5日游行程描述,附带路线图和生成的风景图片)。更有价值的是,AutoGen Studio 允许查看这些智能体内部对话的记录。在对话界面下方可以展开 Agent Messages 面板,看到为完成任务,在幕后发生的多轮代理对话。就像一个真实公司的团队为完成任务而开会交流一样,多个代理之间可能进行了复杂的讨论与信息传递,但这些细节对于终端用户是不可见的——用户只需提出需求,静待答案即可。这一设计体现出良好的产品体验:对用户而言,得到的是简洁直接的结果;对开发者/产品经理而言,可以在后台调试观察智能体团队的工作流程,定位问题或优化协作逻辑。
总的来说,AutoGen Studio 的工作流管理使我们能够像配置业务流程一样配置 AI 代理协作流程,清晰定义每个代理的角色和交互顺序。这种显式的流程编排对于复杂任务尤为重要,保证了多智能体协作的可控性和可解释性。
AutoGen Studio 应用案例:AI旅游规划师的任务执行流程
让我们基于上述 AI 旅游规划师示例,简要总结其面向最终用户的交互方式和任务执行流程,以加深对 AutoGen Studio 工作机制的理解:
-
用户提出需求:终端用户通过 AutoGen Studio 的界面(Playground 聊天窗口)提出任务请求,例如“请帮我计划一次成都5日游,并提供路线图和配图”。用户的语言是自然的,无需了解幕后细节。
-
初始代理接收:
user_proxy作为 Initiator 收到用户请求。它不做复杂处理,直接将问题转交给指定工作流中的下一代理。 -
任务拆解与分发:
travel_groupchat作为 Receiver/调度者分析需求,将其拆解成子任务。比如拆解出:“生成成都5日游行程文本”、“绘制成都景点路线图”、“为行程相关景点生成图像” 等子任务。然后travel_groupchat将这些子任务分别指派给其关联的下级代理去完成。 -
多代理并行工作:各专能代理各显其能:
- 文本行程规划代理调用大模型撰写详细的每日行程建议;
- 地图代理调用地图API绘制线路图;
- 图像代理调用图像生成模型(如 DALL·E)生成景点图片;
这些代理在幕后可能还会彼此通信,或者由travel_groupchat控制协调顺序,例如先生成行程文本再传给图像代理作为提示,等等。所有这些交互通过 AutoGen 框架的消息机制完成,对用户透明。
-
结果汇总与响应用户:当所有子任务结果完成,
travel_groupchat这个主管代理汇总文本、地图、图片等内容,形成完整的答复内容。例如一个包含每日行程说明、嵌入的地图和图片的富文本回答。然后由travel_groupchat将最终答案发回给最初的user_proxy。 -
用户收到结果:
user_proxy将结果展示给用户,用户在界面上看到完整的5日游规划方案和相关图片/地图。整个过程对用户而言就像和一个聪明的AI助手对话一次,立即得到了一个经过深思熟虑且丰富的答复。 -
幕后对话日志(可选):开发人员可以查看 Agent Messages 日志。在那里可以看到例如:
user_proxy->travel_groupchat: 提交了用户请求。travel_groupchat-> 文本规划代理: 要求生成行程。- 文本代理 ->
travel_groupchat: 返回行程草案。 travel_groupchat-> 地图代理: 要求根据行程生成线路图。- …(省略若干内部消息)…
- 最终
travel_groupchat->user_proxy: 发送了完整答案。
这些内部沟通对最终用户不可见,但对于改进智能体协作、调试任务流程非常有帮助。
通过这个实际应用可以看出,AutoGen Studio 让复杂的 AI 代理协作流程变得清晰可控,并提供了直接的用户交互接口。这对产品经理意味着可以更容易地将多个 AI 能力组合在一起,打造出功能复合的智能产品。例如类似的多智能体架构可以用于AI 导购(客服代理+推荐代理+库存查询代理等协作)、智能报告生成(查询数据库代理+分析总结代理+可视化生成代理)等场景,极大拓展了单一大模型助手的能力边界。
AutoGen 与向量数据库的集成方式
AutoGen 检索增强代理:AutoGen 框架在 0.2 版本中已原生支持了 RAG 模式,提供了 RetrieveAssistantAgent 和 RetrieveUserProxyAgent 这类特别的代理。当使用 RetrieveUserProxyAgent 时,我们可以为其配置一个 retrieve_config,其中指定任务类型(如 "task": "qa" 表示问答)、知识文档路径(如一个文件夹或URL)等。AutoGen 会自动读取文档、切分文本(可定制分句策略)、调用嵌入模型计算向量并存储到默认的向量数据库中。AutoGen 默认使用 Chroma 作为向量存储后端。开发者也可以通过 retrieve_config 中的 vector_db 参数,将其切换为 "mongodb", "pgvector", "qdrant" 或 "couchbase" 等其他受支持的向量库。如果要接入 Faiss,目前可以通过扩展 AutoGen 的 VectorDB 基类或自定义 Memory 模块的方式实现——社区有人分享了利用 Faiss 做内存向量检索的示例代码,证明 AutoGen 具备这方面的可扩展性。
检索增强工作流程:当 RetrieveUserProxyAgent 与普通 AssistantAgent 组合在一个聊天中时,交互过程如下:用户的问题先发给检索代理;检索代理在后台查询向量数据库,找到相关文档片段,然后将这些片段作为上下文插入对话,再把问题转交给 AssistantAgent。AssistantAgent(由LLM驱动)因为拿到了额外的知识提示,就能给出正确且详实的回答。AutoGen 的博客演示了这一点:当用户问“AutoGen 是什么?”时,普通 UserProxyAgent 直接由 ChatGPT 作答,结果因为训练数据不足而给出了无关的回答;而使用 RetrieveUserProxyAgent 加载了 AutoGen 文档后,AssistantAgent 返回了关于 AutoGen 框架的准确描述。这充分体现了 RAG 的价值——使智能体能够利用外部知识完成本来无法胜任的任务。
从产品化角度,AutoGen Studio + 向量数据库为我们提供了一个模块化的知识增强方案。产品经理可以:
- 准备好领域知识库(例如产品手册、旅游景点资料库等),通过 AutoGen 的 RAG 代理配置,将其嵌入到智能体的工作流中。
- 无需关心具体的嵌入计算和检索算法实现细节——AutoGen 帮助调用向量数据库(默认为 Chroma)处理这些过程。
- 在界面上,就能获得一个“更聪明”的智能体:既有大模型的语言能力,又有专门知识库的支撑。
值得一提的是,向量数据库还可用来实现长短期记忆功能,例如将对话历史要点嵌入存储,使智能体在长对话中依然保持对上下文的把握。这些高级应用都可以建立在 AutoGen 与向量数据库集成的能力之上。
应用价值与展望
从产品经理的角度,AutoGen Studio 与向量数据库技术的结合为打造新一代智能产品带来了巨大的价值和可行性:
-
降低开发门槛,提升开发效率:AutoGen Studio 提供的可视化界面和预集成功能,让跨学科团队能够更紧密协作。产品经理可以直接在 UI 上设计智能体流程,快速试错各种业务场景;开发者则专注于实现定制技能或优化模型效果。向量数据库的引入也无需从零开始,实现 RAG 所需的大量底层工作已经由 Faiss、Chroma 等组件完成。这样一来,新功能从创意到原型的周期大大缩短,有助于抢占市场先机。
-
提升用户体验与功能深度:多智能体协作意味着产品可以同时具备多个“智囊”的能力。例如旅游规划产品不仅会聊天,还能出行程、画地图、给图片;企业知识库助手不仅能问答,还能串联分析、调用工具。一站式满足用户复杂需求将成为可能。而通过 RAG 加持,产品的回答可靠性和实用性也明显增强——用户提问得到的信息将更准确、有依据、不容易误导。这种体验升级有望带来更高的用户满意度和粘性。
-
技术可行性与扩展:AutoGen Studio 虽然目前定位为原型和研究工具(尚非成熟的生产环境方案),但其背后的理念和架构对产品化非常有参考意义。团队可以基于 AutoGen 的框架进行定制开发,或在摸索清楚需求后将核心逻辑迁移到自有系统中。向量数据库方面,Faiss 和 Chroma 一个经过大规模检验、一个快速演进易用,均是开源可控的方案,可根据业务增长逐步扩展规模或更换方案。因此,从技术风险上看,这套组合是开放且灵活的,利于长期演进。很多公司已经在尝试类似的多Agent+知识库架构,用于客服、办公助手等领域,这印证了其可行性。
-
产品化注意事项:需要强调的是,AutoGen 及 AutoGen Studio 目前主要用于快速构建和研究用途。在真正的生产环境中,还需考虑模型API费用、响应延迟、并发能力以及安全控制(防止错误操作)等因素。向量数据库需要定期更新内容、监控检索效果,以确保知识不过时且检索准确。另外,多智能体系统的调优也比单一模型更复杂,需要测试各种任务下代理间交互的稳定性。产品经理应与工程团队紧密合作,在小规模试点成功后,再逐步扩展用户群体,以确保产品质量。
总结:AutoGen Studio 提供了一个直观的平台,将多代理编排和大模型配置变得前所未有的简单,而向量数据库的融入使这些智能代理真正具备了“博闻强识”的本领。对于产品经理而言,这意味着可以用较低成本探索出许多创新的 AI 应用场景,把过去需要多个独立AI功能才能完成的任务整合到一个协作系统中。随着技术的不断成熟,我们有理由相信,多智能体协作+检索增强的模式将在更多产品中落地,从智能客服、教育助手到专业决策支持系统,打造出更智能、更可靠的用户体验。现在,借助 AutoGen Studio 的低代码工具和 Faiss/Chroma 等向量数据库的赋能,我们正站在一个让科幻般 AI 团队走进现实产品的起点。抓住这个机遇,优秀的产品将能以全新的方式为用户创造价值。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)