【AIGC】文档知识库落地中的那些事
在构建本地知识库问答系统的时候,第一步要对本地的知识文档进行处理,因为希望更傻瓜式的去使用它,因此不太希望有人力参与对文档进行处理,比如分段、摘要等等。但如果不做任何处理,直接使用文档喂给大模型肯定是会超出tokeni限制。因此第一步会将文档的知识转成向量存储到向量数据库中,在进行知识问答的时候,先将问题在向量数据库中进行匹配,将匹配到的结果提供给LLM让其针对结果进行整理和回答。
【AIGC】文档知识库落地中的那些事
文档知识库是指一系列紧密关联且始终保持更新的知识集合。这个知识库可以表现为一个结构化的数据库形态(比如:MySQL),也可以表现为一套非结构化的文档体系(比如:文件、图图片、音频、视频等),甚至可能是两者兼具的综合形式。
一.概述
在构建本地知识库问答系统的时候,第一步要对本地的知识文档进行处理,因为希望更傻瓜式的去使用它,因此不太希望有人力参与对文档进行处理,比如分段、摘要等等。但如果不做任何处理,直接使用文档喂给大模型肯定是会超出tokeni限制。因此第一步会将文档的知识转成向量存储到向量数据库中,在进行知识问答的时候,先将问题在向量数据库中进行匹配,将匹配到的结果提供给LLM让其针对结果进行整理和回答。
二.详情
分块处理(Chunking)
在文档知识库中,分块处理是一个关键步骤,它有助于提高信息检索和处理的效率。以下是对文档知识库中分块处理方式的详细探讨:
一、分块处理的目的
(1).减少信息丢失
整个文档的内容过多,数据粒度大,嵌入到向量中丢失的信息多。将文档分块可以减少每个块的信息量,从而降低信息丢失的风险。
(2).提高答案准确性
当召回的单个文档内容较多时,会存在部分干扰信息,使得生成的答案准确性不高。通过分块处理,可以只召回与查询最相关的文档片段,从而提高答案的准确性。
(3).降低成本开销
召回的内容越多,时间和计算成本越高。分块处理可以减少需要处理的数据量,从而降低计算成本。
(4).提高召回质量
仅召回质量高的文档片段,才能有助于模型提供正确的答案。通过分块处理,可以更容易地识别和召回高质量的文档片段。
二、常见的分块策略
(1).基于字符的分块
- 方法:将文档按照字符序列进行切分,通常设定一个固定的长度,如每500或1000个字符作为一个块。
- 优点:简单易行,不需要复杂的算法。
- 缺点:可能无法很好地捕捉到文本的语义结构,导致上下文丢失。
(2).基于句子的分块
- 方法:将文档按照句子进行分块,每个句子作为一个块。可以使用自然语言处理工具(如NLTK或Spacy)来识别句子边界。
- 优点:保持每个句子的完整,有助于保持语义的完整性。
- 缺点:单个句子可能缺乏足够的背景信息来处理复杂的问题,且句子长度不一,导致段落长度不一致。
(3).基于段落的分块
- 方法:将文档按照段落进行分块,每个段落作为一个块。
- 优点:符合文本的自然逻辑结构,更容易保持上下文的连贯性。
- 缺点:段落长度可能会有很大差异,过长的段落可能会超出模型的令牌限制。
(4).基于主题的分块
- 方法:识别文档中的主题,并根据主题内容进行分块。这通常需要更复杂的自然语言理解技术,如主题建模。
- 优点:片段有意义地分组,提升了检索的准确性。
- 缺点:需要高级的自然语言处理模型和足够的计算资源,处理时间可能会比较耗时。
(5).递归嵌入和聚类
- 方法:使用递归神经网络对文本进行嵌入,然后通过聚类算法将相似的文本块聚集在一起。
- 优点:可以自适应地识别文本的层次结构和主题。
- 缺点:实现复杂度较高,需要更多的计算资源。
(6).滑动窗口分块
- 方法:通过在文本上滑动一个窗口来创建重叠的部分,确保这些部分相邻的内容有重叠。
- 优点:重叠有助于保持信息的连贯性,提高检索到的相关信息片段的可能性。
- 缺点:重复内容可能会导致信息重复,增加处理和存储的负担。
(7).富含上下文的分块
- 方法:通过加入周围片段的摘要或元数据来丰富每个片段,从而在整个过程中保持上下文。
- 优点:提供额外信息而不显著增加大小,帮助模型生成更准确且符合上下文的回答。
- 缺点:需要额外处理来生成摘要或元数据,增加了存储开销。
(8).模态特定的分块
- 方法:分别处理不同类型的内容(文本、表格、图片等),根据每种内容的特性进行分块。
- 优点:量身定制的方法,针对每种内容类型进行优化分块,提高准确性。
- 缺点:每个模态都需要自定义的实现逻辑,集成难度较高。
三、分块处理的注意事项
(1).选择合适的分块大小
分块大小应根据文档的性质、用户查询的长度和复杂性以及检索结果的用途来确定。过小的分块可能导致信息不完整,过大的分块则可能超出模型的令牌限制或增加计算成本。
(2).保持上下文的连贯性
在分块处理时,应尽可能保持每个块的上下文连贯性。这可以通过使用重叠窗口、加入周围片段的摘要或元数据等方式来实现。
(3).考虑模型的令牌限制
在将分块后的文本发送到外部模型提供商(如OpenAI)之前,需要确保每个块的大小不超过模型的令牌限制。
(4).优化分块策略
根据实际应用场景和需求,不断优化分块策略,以提高检索效率和准确性。

嵌入模型(Embedding Model)
在文档知识库中,嵌入模型(Embedding Model)扮演着至关重要的角色。以下是对嵌入模型的详细解析:
一、嵌入模型的概念
嵌入模型是指将高维度的数据(例如文字、图片、视频)映射到低维度空间的过程。简单来说,嵌入向量就是一个N维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。在自然语言处理(NLP)中,嵌入模型被广泛用于将文本数据转换为数值向量,这些向量能够捕捉原始数据的潜在关系和结构,为后续的处理和学习任务提供有效的特征表示。
二、嵌入模型的工作原理
嵌入模型的工作原理是利用神经网络中的嵌入层,将高维的离散数据映射到低维度的连续向量空间。在NLP中,这通常意味着将单词、短语或句子转换为数值向量。这些向量能够捕捉单词的语义特征,如意义、上下文关系等,使得计算机能够更有效地处理和理解文本数据。
三、嵌入模型在文档知识库中的应用
(1).信息检索
嵌入模型通过向量化表示和预训练模型,可以显著提升信息检索的效率。在文档知识库中,相似的文本会被映射到距离较近的位置,从而大幅度减少了匹配的计算开销和时间。
(2).数据整合
对于具有多种数据源的企业而言,嵌入模型能够有效地将不同格式、不同来源的数据进行统一处理。通过嵌入模型,企业可以将结构化数据、非结构化数据以及半结构化数据进行有效融合,消除了信息孤岛,使得知识库的信息更加全面和准确。
(3).用户交互体验
嵌入模型还能够提升用户交互体验。通过向量化表示和语义搜索技术,用户可以使用自然语言进行查询,而不仅仅是依赖精确的关键词匹配。这简化了用户的操作流程,并提升了查询结果的准确性和相关性。
四、常见的嵌入模型及其优势
(1).Word2vec
这是一种经典的嵌入模型,通过学习单词之间的长距离依赖关系来生成向量。它的优势在于能够有效地捕捉到词语之间的关系,使得模型能够理解和处理复杂的文本结构。
(2).众安Embedding模型
在中文通用FAQ数据集上表现出色,表明该模型在中文数据集上具有较好的性能。
(3).Nomic Embed
这是首个开源、开放数据、开放权重、开放训练代码、完全可复现和可审核的嵌入模型。它的上下文长度为8192,显示出在特定场景下的高效性。
(4).OpenAI Embedding Models
OpenAI推出了一系列新型嵌入模型,包括更小、高效的text-embedding-3-small模型和更大、更强大的text-embedding-3-large模型。这些模型具有更低的定价,适用于表示自然语言或代码等内容中的概念。
五、嵌入模型的选择与优化
在选择嵌入模型时,需要考虑模型的语义理解能力、容错性、对中文数据的支持程度以及性能差异等因素。此外,还需要考虑如何有效地部署和优化这些模型,以适应特定的业务需求。优化嵌入模型的关键在于深入理解特定领域的需求,合理选择和组合优化方法,以及利用开源资源和先进的技术手段。
向量数据库( Vector Databases)
文档知识库中的向量数据库(Vector Databases)是一种专门用于存储、管理和查询高维向量数据的数据库系统。以下是对向量数据库的详细解析:
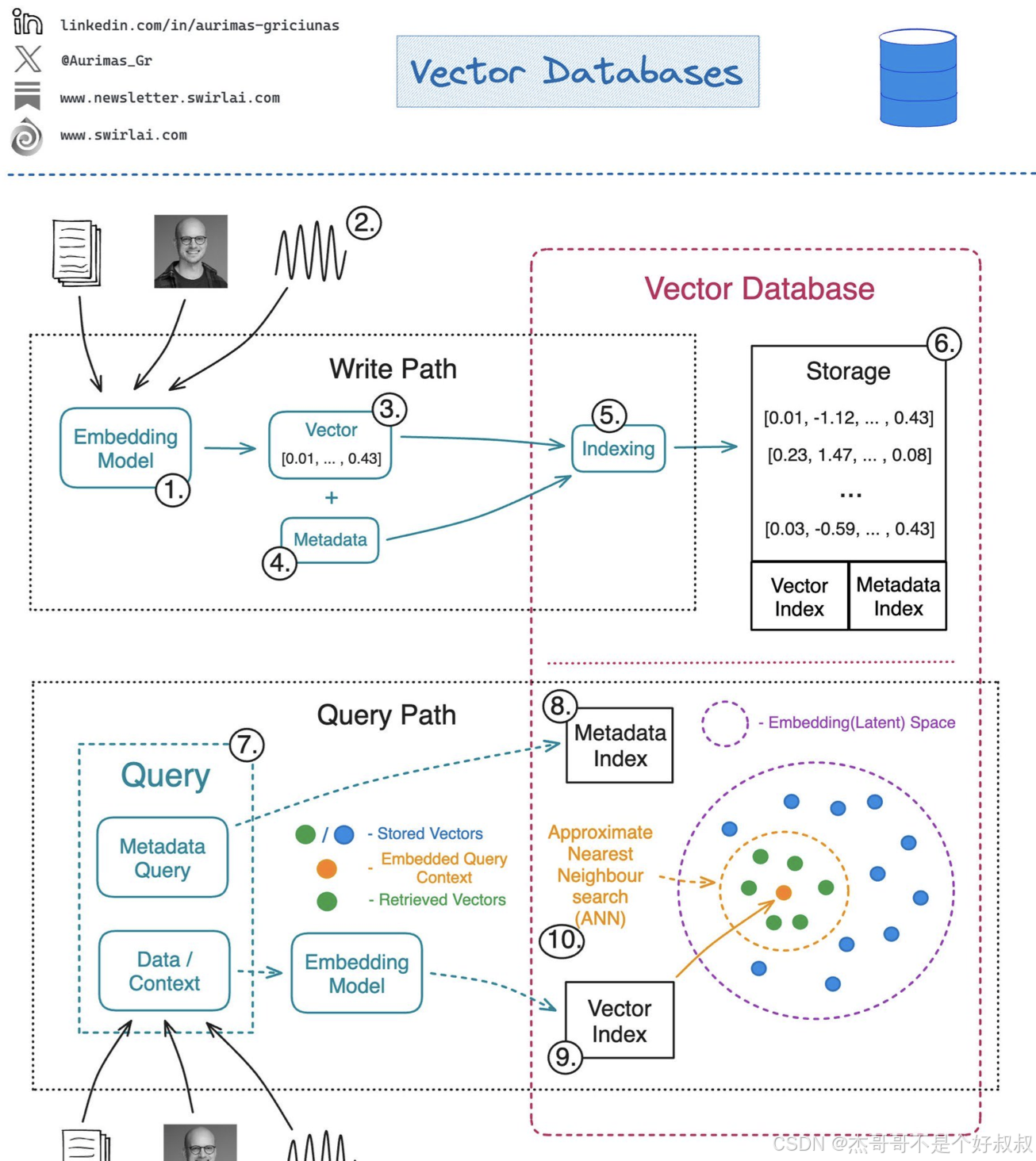
一、向量数据库的基本概念
向量数据库是专门用来存储和查询向量的数据库,其存储的向量来自于对文本、语音、图像、视频等的向量化。这些向量数据是以向量或矢量的形式表示的,其中每个维度表示一个特征。向量数据库通过提供特定的索引(如k-NN索引)和算法,实现了高效的向量相似性搜索。
二、向量数据库的特点
(1).高维度支持
向量数据库能够高效地处理高维度的向量数据,如图像特征、文本特征和声音特征等。传统数据库在处理高维度数据时效率较低,而向量数据库通过采用特定的索引结构和算法,能够有效地存储和查询大规模的向量数据。
(2).相似性搜索
向量数据库能够快速进行相似性搜索,即找到与给定向量相似的向量数据。这在很多应用场景中非常有用,如图像识别、推荐系统和自然语言处理等。通过利用向量之间的距离度量(如欧氏距离和余弦相似度),向量数据库可以快速找到相似的向量。
(3).高性能和扩展性
向量数据库采用了高效的索引结构和算法,并针对向量的特点进行了优化,因此具备了快速的查询和检索能力。此外,向量数据库还具有良好的扩展性,可以处理大规模的向量数据集。
三、向量数据库的应用领域
(1).搜索引擎
搜索引擎需要将大量的文档和查询向量进行相似性匹配,以提供准确的搜索结果。通过使用向量数据库,可以快速找到与查询向量相似的文档或网页,提高搜索的精确度和速度。
(2).推荐系统
推荐系统需要针对用户的兴趣和历史行为进行个性化的推荐。通过将用户和物品表示为向量,并利用向量数据库进行相似性搜索,可以快速找到与用户兴趣相似的物品,提供更准确的推荐结果。
(3).图像识别
图像识别需要将输入图像表示为向量,并在数据库中快速搜索相似的图像。向量数据库可以存储大量的图像特征向量,并通过高效的相似性搜索算法,实现快速的图像检索和识别。
(4).自然语言处理
自然语言处理涉及到将文本表示为向量,并进行语义分析、情感分析和文本相似度比较等任务。向量数据库可以存储和管理大规模的文本向量,支持高效的文本相似性搜索和语义分析。
四、向量数据库的优势
(1).高效的数据处理
向量数据库在处理大量数据时,能够显著提高处理速度,有效提升数据处理效率。这是因为向量数据库采用了向量化查询执行引擎,能够一次处理多个数据,大幅降低了计算的复杂性。
(2).易于维护
向量数据库的架构简洁,易于维护。通过自动化的数据管理,使得数据的备份、恢复、迁移等操作变得简单,大大减轻了运维人员的工作负担。
(3).高度的数据压缩
向量数据库采用高效的数据压缩技术,可以显著减少存储空间的需求。这种高度的数据压缩不仅可以节约存储空间,还可以提升数据处理的速度。
五、向量数据库的发展与挑战
随着人工智能和机器学习技术的不断发展,向量数据库的应用场景也在不断拓展。然而,向量数据库也面临着一些挑战,如如何进一步优化查询性能、如何更好地支持复杂查询操作等。为了解决这些问题,研究者们正在不断探索新的算法和技术,以推动向量数据库的发展和应用。
六、文档转成向量数据两大步骤
(1).tokenizer
Tokenizer负责将文本拆分成词元(token)。它将一个字符序列转换成一个词元序列。常见的tokenizer有基于空格、标点符号的简单tokenizer,还有更复杂的基于字典的tokenizer等。我们最终将词汇或者语句转成向量是通过embedding得到的,但一般来说,我们不太可能将一整篇文档转换成向量。因为文档的长度往往都是比较长,会超过绝大部分模型的token限制;此外我们进行知识搜索的时候也不是要搜到整篇文档,而是文档中相关联的知识。那么tokenizer的第一步就是将文档拆分成合适的片段。
(2).embedding
Embedding则是将词元转换成词向量的表示。它为每个词元映射到一个稠密的向量空间,使得语义相关的词元之间的向量更加相近,进而把数据进行向量化的过程。embedding的目标,就是找到一组合适的向量,来刻画现有的数据集合。这些低维向量称为嵌入(Embedding vectors)。Embedding可以通过事先训练好的词向量表获得,也可以在神经网络中进行学习。

用户聊天界面(User Chat Interface)
文档知识库的用户聊天界面是用户与知识库进行交互的重要窗口,其设计直接关系到用户体验和满意度。
一、界面设计原则
(1).清晰性与易读性
消息应按时间顺序清晰展示,确保阅读流畅。文字大小、颜色对比度需适宜,以适应不同光线环境。
(2).即时反馈
提供发送、接收状态的即时反馈,如发送成功标志、正在输入提示等。操作按钮(如发送、附件上传)应有明确的触控反馈。
(3).简洁性
界面应保持整洁,避免过多装饰干扰核心的聊天功能。功能布局合理,常用功能易于触及,不常用功能可适当隐藏。
(4).一致性
设计元素如按钮、图标和交互模式应保持一致,符合平台设计规范。
跨平台的聊天应用需确保在不同设备上的体验一致性。
(5).适应性与响应式设计
界面应能自适应不同屏幕尺寸和分辨率,保证在手机、平板、桌面端的良好体验。
(6).可访问性
遵循无障碍设计原则,确保视障、听障等残障人士也能正常使用。
二、用户聊天界面功能
(1).登录与注册
用户需要登录后才能使用聊天功能,登录界面应简洁明了,提供用户名、密码输入框和登录按钮。提供注册功能,方便新用户创建账号。
(2).聊天窗口
聊天窗口应显示用户头像、昵称、聊天记录等信息。提供输入框供用户输入文字、表情或上传文件。聊天记录应支持滚动查看,方便用户查看历史消息。
(3).知识库查询
提供搜索框,用户可以通过关键词查询知识库中的信息。搜索结果应以列表形式展示,用户可点击链接查看详细信息。
(4).智能回复
引入嵌入模型和向量数据库,实现智能回复功能。用户提出问题后,系统能够自动从知识库中查找相关信息并给出回复。智能回复应支持图文并茂的形式,提升用户体验。
(5).人工客服
提供人工客服功能,用户可通过聊天窗口与客服人员进行实时交流。人工客服应能够解答用户问题,提供技术支持和解决方案。
(6).个性化设置
提供个性化设置功能,用户可根据自己的喜好调整界面风格、字体大小等参数。支持保存聊天记录、设置消息提醒等功能。
三、用户聊天界面优化建议
(1).提升智能回复准确性
不断优化嵌入模型和向量数据库,提高智能回复的准确性和相关性。引入更多领域的知识和数据,丰富知识库内容。
(2).优化界面布局
根据用户反馈和数据分析,不断调整界面布局和功能位置,提升用户体验。引入创新的布局与交互模式,如卡片式UI布局、SSE在流式对话
(3).实现原理
在ChatGPT等聊天模型中,使用SSE可以让客户端实时接收到生成的对话内容,而不需要等待整个响应完成。服务端在接收到客户端的请求后,开始生成对话内容,并通过SSE将生成的内容逐字逐句地发送给客户端。
1).数据格式:
服务端发送的数据通常包含事件类型(可选)、数据内容(主要数据)、事件ID(可选)和重试时间(可选)。在流式对话中,数据内容通常是生成的对话文本片段。
- [前端实现]:
在前端,使用JavaScript的EventSource对象来创建与服务器端的SSE连接。通过监听EventSource对象的onmessage事件来获取服务器发送的数据,并实时更新到页面上。 - [后端实现]:
在后端,可以使用各种技术和框架来实现SSE流式输出。例如,在Java中,可以使用Spring WebFlux库来创建SSE流,并通过Flux或Mono等响应式类型来发送数据。
2).SSE流式对话的优势与挑战
-
[优势]:
提供流畅的对话体验: 逐字蹦出回复可以实现更快的交互响应,让用户感觉对话更加流畅。
提高用户参与度: 用户可以看到模型正在工作,避免感觉像卡住了或没有响应,从而提高用户参与度。
增强对话透明度: 逐字蹦出的回复有助于用户跟踪模型的思考过程,提高对话的透明度和可解释性。 -
[挑战]:
资源消耗: SSE基于HTTP长轮询机制,每个请求都需要建立和维护一个持久化连接,可能导致较高的资源消耗。
单向通信限制: SSE适用于单向通信,即服务器向客户端发送数据。如果需要在客户端和服务器之间进行双向通信,可能需要考虑其他技术(如WebSockets)。
(4).加强安全防护
加强对用户数据和隐私的保护,确保用户信息安全。提供安全的登录和注册流程,防止恶意攻击和盗号行为。
(5).支持多平台接入
提供Web端、移动端等多种接入方式,满足不同用户的需求。确保各平台之间的数据同步和一致性。
查询引擎(Query Engine)

文档知识库的查询引擎是文档知识库系统的核心组件,它负责处理用户的查询请求,并从知识库中检索相关信息以返回给用户。以下是对文档知识库查询引擎的详细解析:
一、查询引擎的功能与特点
(1).全文检索能力
查询引擎应具备全文检索能力,能够处理用户的自由文本查询,并从知识库中检索出相关的文档或信息。支持复杂的查询语法和过滤条件,以满足用户多样化的查询需求。
(2).高效索引与查询
查询引擎通过构建高效的索引结构,提高查询效率,确保在大量数据中快速找到相关结果。支持实时索引更新,确保新添加的文档能够立即被检索到。
(3).语义理解与匹配
查询引擎能够理解用户的查询意图和内容语义,实现更精准的匹配。
通过自然语言处理(NLP)技术,如词法分析、句法分析、语义分析等,提升查询的准确性和相关性。
(4).多格式支持
查询引擎应支持多种文档格式,如Markdown、PDF、Word等,确保能够处理各种类型的内容。内置文本提取机制,能够从不同类型的文档中提取出可检索的文本信息。
(5).安全访问控制
查询引擎应集成身份验证和授权系统,确保只有被授权的用户才能查看特定的文档或信息。提供细粒度的访问控制策略,以满足不同用户的权限需求。
二、查询引擎的工作流程
(1).用户输入查询
用户通过查询界面输入查询请求,可以是关键词、短语或自由文本。
(2).查询解析
查询引擎对用户的查询请求进行解析,包括分词、去停用词、词干提取等预处理操作。根据查询语法和过滤条件,构建查询表达式。
(3).索引检索
查询引擎利用构建好的索引结构,在知识库中快速检索与查询表达式匹配的文档或信息。根据索引的排序和权重,对检索结果进行排序和筛选。
(4).结果返回
查询引擎将检索到的结果返回给用户,可以是文档列表、摘要或相关片段。提供用户友好的结果展示界面,支持结果排序、分页和过滤等操作。
三、查询引擎的优化策略
(1).索引优化
对索引结构进行优化,提高索引的存储效率和查询速度。
采用分布式索引技术,实现索引的并行处理和存储。
(2).查询优化
对查询语句进行优化,减少不必要的计算和资源消耗。
利用缓存技术,提高重复查询的效率。
(3).语义理解优化
引入更先进的自然语言处理技术,提升语义理解的准确性和相关性。利用用户反馈和机器学习技术,不断优化语义匹配算法。
(4).安全性优化
加强身份验证和授权系统的安全性,防止未经授权的访问。
对敏感数据进行加密存储和传输,确保用户数据的安全。
四、查询引擎的实例与应用
文档知识库的查询引擎是文档知识库系统的关键组件,它具备全文检索能力、高效索引与查询、语义理解与匹配、多格式支持和安全访问控制等特点。通过优化索引、查询、语义理解和安全性等方面,可以进一步提高查询引擎的性能和准确性。同时,实际应用中的查询引擎如Elasticsearch和DocQuery等,为文档知识库提供了高效、可靠的检索服务
(1).Elasticsearch
Elasticsearch是一个基于Lucene的开源搜索引擎,支持全文检索、实时索引和复杂查询。广泛应用于企业知识库、开源项目文档和学习平台等场景,提供高效的文档检索服务。
(2).DocQuery
DocQuery是一个基于Elasticsearch的文档搜索引擎和查询工具,提供简洁的API和多种文件格式支持。
支持自定义查询、实时索引和安全访问控制等功能,适用于各种文档管理和查询场景。
提示词模板(Prompt Template)

文档知识库的提示词模板(Prompt Template)是用于引导查询引擎或AI模型生成符合用户需求的输出的一种文本模板。
提示词模板实际上是与人工智能(AI)工具或系统进行交流时所提供的“指令”或“引导”。这些模板通过巧妙地设计,能够引导AI生成符合预期的内容,而不仅仅是随机生成片段信息。例如,在文档知识库中,通过输入“撰写一篇关于环保的文章”的提示词,AI就能大致生成一篇符合要求的文章。如果进一步细化提示词,加入具体的段落结构、重点内容的要求,甚至是文字风格的指令,AI生成的文章将更加贴近期望。
一、逻辑性与结构性:
一个详细的提示词模板能够确保AI输出的文本具有逻辑性、结构合理。例如,在撰写报告时,可以设定“撰写一份关于XX工作的总结报告,包含数据分析和建议”的提示词,AI将按照这一逻辑结构生成内容。
二、语言风格与语气:
提示词模板还可以用于调整生成内容的语言风格和语气。例如,在撰写旅游攻略时,通过添加“感性”“亲切”等描述词语,AI会生成更加生动的文字。
三、辅助创作者构思:
提示词模板为创作者提供了一个清晰的框架,AI可以自动生成接近最终成品的文字,大大减少了反复修改的时间。对于个人创作者,尤其是小说作者,AI写作提示词模板提供了无限的创作可能。通过提示词,可以引导AI生成不同的故事情节、人物对话,甚至设定不同的写作风格。
四、激发创意灵感:
通过不断优化提示词模板,可以激发更多的创意灵感。例如,调整词语的顺序、添加具体细节等,都能影响生成结果,从而帮助创作者摆脱写作瓶颈。

我是杰叔叔,一名沪漂的码农,下期再会!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)