基于AI的实时道路感知系统
本文提出一种基于人工智能的统一框架,用于自动驾驶中的实时道路环境感知。该系统结合SSD模型与OpenCV技术,可同步检测车辆、行人、车道及弯道,在无需GPU支持下实现高效准确检测。实验表明,系统在高质量和低质量视频中准确率分别达96%和84%,具备实际应用潜力。
基于人工智能的自动驾驶实时道路环境感知
摘要
实时道路环境感知是基于物联网的自动驾驶技术为提高道路安全而应用的主要领域之一。道路环境感知包括对各类移动车辆、非车辆(行人、动物等)、弯道和车道的路面检测。尽管已有多种基于人工智能(AI)的检测方法被提出,但大多数方法都是孤立的,由于高检测延迟和低准确率,难以适用于此类实时自动驾驶场景。因此,本文提出一种整体式基于人工智能的道路环境学习系统,可同步实时检测多种路面物体,在降低计算复杂度的同时实现高准确率(超过90%)。
I. 引言
随着物联网(IoT)和人工智能(AI)的广泛普及,自动驾驶已成为实现社会5.0[1],[2]最具吸引力的方向之一。自动驾驶的主要优势包括因减少人为错误而提升驾驶安全、缓解交通拥堵、降低污染等。为了提高自动驾驶汽车的安全性和实现能力,道路环境感知成为一项关键任务,旨在实时识别周围物体,如行人、动物、车辆、交通标志、车道和弯道。随着人工智能技术的进步,对实时驾驶环境的理解变得比以往任何时候都更加可行。
在这方面,已有相当多引人注目的研究致力于利用计算机视觉和人工智能来学习移动车辆周围的动态环境。然而,大多数现有工作未能将可能的路面物体整合到一个单一系统中。例如,文献[3]综述了大量仅与基于视频的车道检测相关的研究。同样,也有其他关于车辆检测[4]和人员识别[5]的研究。有一些文章涉及结合车道与车辆检测[6]。然而,由于这些孤立且依赖的系统具有独立执行时间,若考虑到在道路上对多个物体进行环境感知的整体目标,则此类系统可能无法实现实时运行。因此,这类方法对于自动驾驶等未来物联网应用而言可能并不现实。
为解决这些问题,[7]提出了一种基于RGB‐D图像并使用卷积神经网络(CNN)的集成系统来检测多个物体。在他们的方法中,采用了FasterCNN进行物体检测,并使用LaneNet在执行模型时通过多GPU进行车道检测,以解决FasterCNN速度慢的问题,并声称具有现实可行性。然而,增加多GPU对于低成本车辆(如两轮车或汽车)来说成本效益低且不可行。因此,他们的方法无法在实际环境中部署。此外,没有GPU的支持,FasterCNN由于其运行速度慢,无法满足实时性要求。同样,LanNet检测在缺乏GPU支持的情况下,由于多任务模型复杂的网络结构导致同步检测与分割时也面临检测速度慢和准确率低的问题。因此,本文提出了一种无需使用GPU的实时环境感知实现方案。我们设计了一种单阶段单次多框检测器(SSD),用于检测非车辆(行人和动物)以及车辆,其速度高于FasterCNN[7]。此外,我们嵌入了一种用于车道检测的机器学习模型,该模型比LanNet更快。我们的方法在实时性下实现了高准确率,结果部分将进一步展示其实验效果。下一节将详细描述我们的实现方案,随后章节将进行结果分析。
II. 提出的整体框架
在本节中,我们详细说明了使用机器学习和深度学习实现环境感知的具体方法。我们的框架能够识别非车辆(行人和动物)、车辆(汽车、自行车、摩托车、卡车等)、车道以及弯道。然而,我们采用深度学习来实现车辆和非车辆的识别,而车道和弯道的感知则使用机器学习。这种混合结构是我们的框架相较于其他方法的一个关键优势,能够在无需高硬件要求的情况下实现更快的执行速度,并且即使在低质量视频条件下也能保持较高的准确性。
首先,我们详细介绍用于车辆和非车辆检测的SSD,其在速度方面相较于FasterCNN具有巨大优势。SSD能够单次完成感兴趣区域(ROI)的估计以及区域分类。首先,输入图像通过一系列卷积层,生成不同尺度的特征图,例如10x10、3x3等。我们使用3x3卷积滤波器为每个特征图上的每个位置确定一组较小的边界框。然后,对于每个边界框,SSD预测边界框偏移和类别概率。它进行匹配

通过给定的真实框与预测真实框之间的交并比来确定。最佳的预测框被标记为正样本。此外,SSD使用非极大值抑制模型将重叠的框合并为单个框。然而,我们使用基于TensorFlow的预训练模型(即Inception v2)进行车辆和非车辆检测。
在我们的框架中,我们设计了一个用于检测和绘制汽车当前行驶车道的流水线。车道检测需执行以下步骤:首先,创建用于录制视频设备的校准矩阵和畸变系数。然后,我们运行基于OpenCV的棋盘格查找算法对摄像头进行校准,并逆向工程得到畸变矩阵。接着,我们应用颜色和梯度阈值来识别车道线。之后,使用透视变换生成鸟瞰图,并利用滑动窗口捕捉车道线。为了找到最符合左右车道线的曲线系数,我们采用二次多项式拟合。随后,通过估计与车道线相切的最小圆半径,基于公式(1)计算车道曲率。
$$
R = \frac{[1 + (dy/dx)^2]^{3/2}}{|d^2y/dx^2|}
$$
其中 $x$ 是弯道 $y$ 上车道线的切点。最后,我们在图像上包裹并绘制车道边界,并提供曲率信息。然后,我们对每帧进行检测,并最终将整帧合成为视频。我们框架的结果将在下一节中展示。
III. 实验结果
在本节中,我们介绍了所提出框架的输入文件、数据集、训练设置和评估的详细信息。我们考虑了高质量和低质量的输入视频,以表明所提出的框架可以与低成本摄像头和车辆一起工作,这使其更加贴近实际应用。因此,我们展示了两种类型的结果,将在后面进行讨论。对于目标检测,我们使用包含80类、8万张训练图像和4万张验证图像的上下文中的常见物体(COCO)数据集[?]。在车道检测中,我们使用20张图像进行相机标定,2张图像进行透视变换。图1显示了高质量视频输入下的汽车、车道和弯道检测结果。
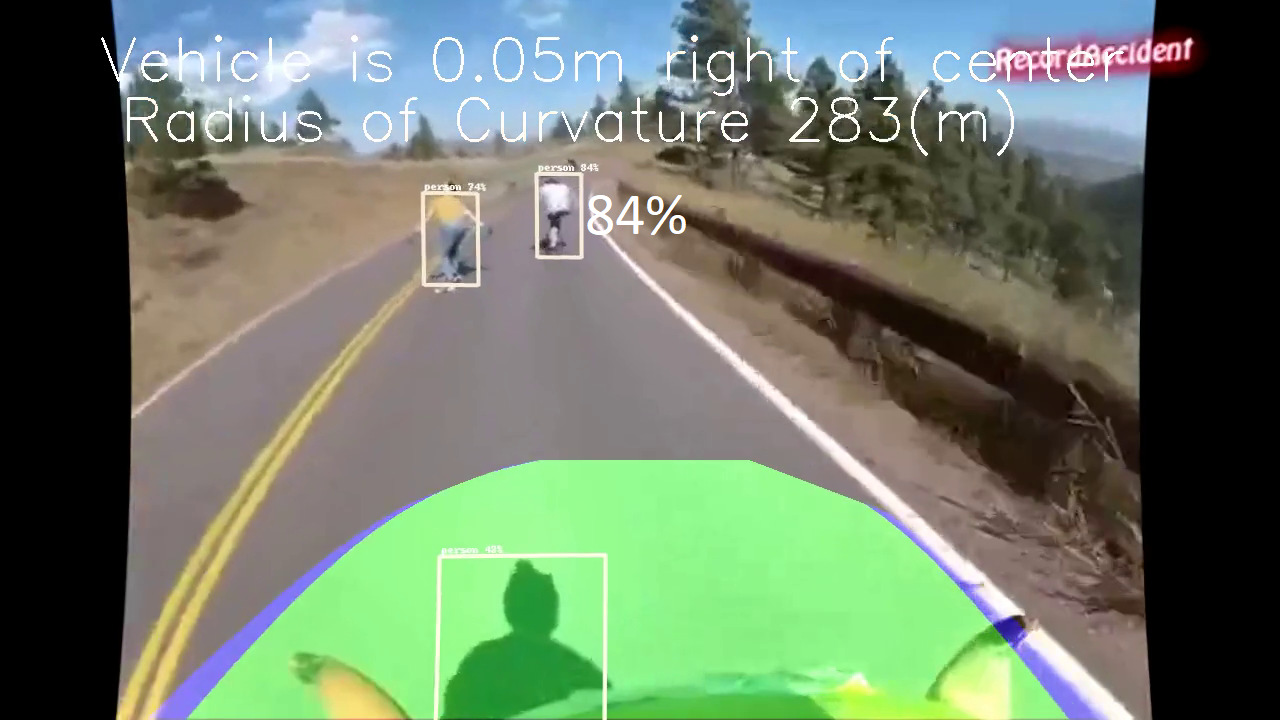
输入。我们可以观察到该图中的准确率为96%。此外,我们可以获得曲率半径以及车辆相对于中心左侧的位置。类似地,图2显示了低质量视频输入下的行人、车道和弯道检测结果。从该图中,即使在如此低质量的视频下,我们的准确率也达到了84%。因此,我们的框架可以应用于任何类型的摄像头和车辆。然而,我们还有关于其他车辆和动物的检测结果,但由于篇幅限制未予展示。从结果可以看出,我们的框架在各种条件下均能实时提供高准确率。
IV. 结论
本文提出了一种基于人工智能的实时道路环境感知新型统一框架。我们采用基于单次拍摄SSD的inception模型来检测车辆和非车辆,并使用OpenCV进行车道检测。此外,我们估算了曲率半径以及车辆距中心左侧的距离。根据实验结果,我们得出结论:该框架在处理高质量和低质量视频时均能以更快的速度实现高准确率。该框架有望应用于多种自动驾驶应用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)