ALOHA Unleashed: A Simple Recipe for Robot Dexterity
提出了,1.在ALOHA 2 平台上收集了超过 26,000 个示范、2.使用这些数据训练了基于 Transformer 的、3.在真实和模拟环境中,充分展示了机器人灵巧行为。ALOHA Unleashed 证明,一个简单的方法就可以提升双臂灵巧操作的能力。局限性,策略每次只训练单一任务(其他方法可能使用单一模型权重,通过语言或目标图像条件化,实现多任务操作)、2.策略每 1 秒重新规划一次(对于
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | ALOHA Unleashed |
| 2 | 发表时间/位置 | 2024 / Google DeepMind |
| 3 | Code | ALOHA Unleashed: A Simple Recipe for Robot Dexterity |
| 4 | 创新点 |
1.提供了大规模的双臂灵巧操作示范数据集 2.Diffusion Policy 在机器人控制中的应用 使用 Denoising Diffusion Implicit Models (DDIM) 来训练动作生成策略,模型可以多模态输入,并输出14维自由度动作空间(双臂12+grippers2) 3.Transformer + Diffusion 的结构设计 Observation encoder:ResNet50 + Transformer 编码多视角图像和机器人状态 得到 latent embedding Diffusion denoiser:Transformer 结构,对动作 chunk 进行去噪生成最终动作 Action chunking:一次预测 50 步动作 得到 1 秒操作序列,提高长序列学习能力 Cross-attention 机制结合 observation embedding 和 diffusion timestep 使得 模型可以在复杂状态下生成合理动作 展示端到端自主完成复杂双手任务,通过 大规模多操作员数据 + Transformer + Diffusion Policy,ALOHA Unleashed 成功实现了复杂双臂灵巧任务的端到端学习,同时引入动作 chunking、cross-attention、多模态输入和恢复策略,实现了比传统方法更稳定、更高精度的动作生成。 |
| 5 | 引用量 | 端到端的灵巧任务实现,灵巧任务很有特点。但是是否普通vla就能够完成呢? |

一:提出问题
用模仿学习来训练端到端机器人策略取得了令人鼓舞的成果。那么在处理具有挑战性的灵巧操作任务时,我们能够将模仿学习推进到什么程度?
本文展示了一个简单但有效的方案,在 ALOHA 2 平台上进行大规模数据采集,并结合具有强表达能力的模型(如 扩散策略 Diffusion Policies),即可有效学习困难的双臂操作任务,包括可变形物体(如系鞋带这个任务)以及复杂接触动力学。
采集足够覆盖状态变化并满足精度要求的模仿学习数据的成本实在是太高了,目前也不确定 仅靠扩大模仿学习的数据规模,是否足以实现真正的灵巧操作?,在本文中,作者展示了只要选择合适的学习架构,并配合合理的数据采集策略,就能够推动基于模仿学习的灵巧操作更进一步。
1.设计了一个流程,使能够在双臂操作平台(基于他们搭建的ALOHA 2 平台)上采集史无前例规模的数据,总计:
-
真实机器人岗位:5 个任务,共超过 26,000 条示范
-
仿真环境:3 个任务,超过 2,000 条示范
2.基于 Transformer 的学习架构,并使用扩散损失(diffusion loss)进行训练。
该架构在多视角输入条件下,对一个动作轨迹进行去噪(denoising),并在滚动时域(receding horizon)中开环执行。结果显示就算把普通 Transformer 或 BC 模型在 ALOHA 平台上调得再好(调超参数、调结构、调输入输出),它们依然无法解决论文中的某些灵巧任务。主要是因为模型表达能力不够,但是扩散策略在灵巧操作任务上具有质的优势,而不仅仅是“调得好”那么简单,可以完成其他模型完不成的灵巧任务。(只用普通 transformer + BC(Behavioral Cloning(行为克隆)) 无法完成任务,但 diffusion 可以完成。)
二:解决方案
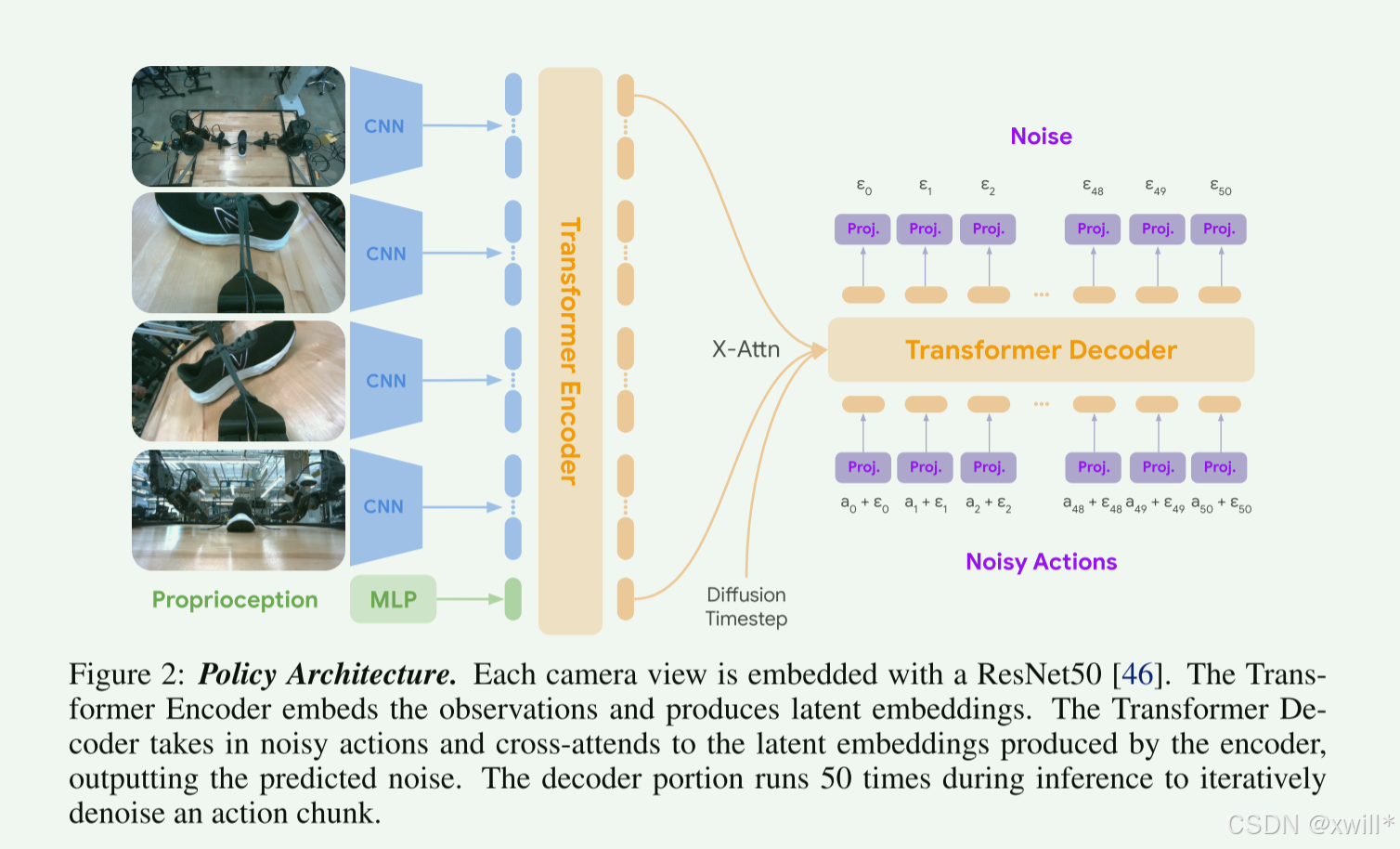
ALOHA Unleashed 是一个用于训练机器人灵巧操作策略的通用模仿学习系统。在 ALOHA 2 平台上展示实验结果,该平台由一个双臂(bimanual)平行夹爪工作单元组成,拥有两个 6 自由度机械臂。ALOHA Unleashed 包含:
-
一个可扩展的远程操作(teleoperation)框架,允许用户采集示范数据来教机器人;
-
一个基于 Transformer 的神经网络,并使用 Diffusion Policy 进行训练(参考文献 [18] 和 [20]),为模仿学习提供了具有强表达能力的策略结构。
2.1 Policy
Diffusion Policy:作者认为他们的训练数据具有天然的多样性,因为来自多个操作者、多种远程策略、再多掏机器人工作单元上、长时间持续采集。作者为每一个任务分别训练一个Diffusion Policy,而Diffusion Policy 能处理多视角图像 + 机器人关节状态这类复杂输入,并且能从大量风格不同、策略不同的操作数据中学习出“多个可能动作方式”,而不是简单的平均动作,因此训练更稳定、效果更好。此外,使用DDIM(Denoising Diffusion Implicit Models)的公式,使得在推理时可以灵活使用不同数量的推理步数。进行了action chunking,使得策略可以一次性预测50个动作,构成1秒长的动作轨迹,输出12个绝对关节角和两个夹爪的连续gripper值(所以tensor shape是(50,14))。在训练过程中,使用了平方余弦噪声调度。
普通扩散模型(DDPM)在推理(采样)时具有以下问题:
需要很多 denoising steps(如 1000 步)
每一步都比较慢。由于推理速度慢,因此不适合实时控制机器人
DDIM 是 DDPM 的改进版本,全称Denoising Diffusion Implicit Models。具有以下特点:
推理步数可以任意减少
可以从 1000 步减少到 100、50、10 步,效果不会“过度下降”
DDIM 可以把漫长的扩散过程压缩成更少的 steps。DDIM 让扩散策略网络可以非常灵活,推理速度可以按需变快或变慢,而不会像普通扩散模型那样必须走满所有 steps。
Transformer 架构:主题模型是Transformer Encoder-Decoder 架构,但其中视觉 backbone为ResNet50。
每张图像调整为480 × 640 × 3,并分别输入 4 个独立的 ResNet50(每个 ResNet50 使用 ImageNet 预训练的权重初始化)。之后取 ResNet stage 4 (也就是第四个阶段)的输出,对应一个 15×20×512 的 feature map。之后展开,得到1200 个 512 维 embedding。展开后,再追加一个来自机器人本体状态(joint position + gripper 值)的投影embedding,因此共有 1201 个 embedding token。再加上positional embedding,之后送入一个 8500 万参数的 Transformer encoder,该 encoder 使用双向注意力,输出观察的 latent embedding(也就是编码后的“隐藏特征向量”)。这些 latent 会送入扩散 denoiser(Diffusion Policy 中负责从噪声生成动作轨迹的 Transformer 网络,它利用观察 latent embedding 和 cross-attention,将随机噪声逐步去噪成合理动作序列。),它是一个 5500 万参数的 transformer 结构。
Decoder 接收到的是一段“有噪声的动作序列”,每个动作知道自己在时间序列中的位置。Decoder 并不是单独预测动作,它还要参考观察信息:
-
observation encoder 的 latent embedding:来自 ResNet+Transformer encoder 的视觉+本体状态抽象表示
-
Decoder 可以 “问” encoder:我现在的动作应该怎么调整才能抓到鞋带/毛巾?
-
-
diffusion timestep(one-hot):告诉模型这是第几步 denoising
-
例如:第 10/50 步去噪,模型知道噪声还很大或接近干净
-
其输出是(50, 512) 也就是每个动作步的 latent embedding,然后通过 线性层映射 回 (50, 14)。整个Decoder也就是把带噪声的动作 → 参考观察信息 → 去噪成合理动作。
在推理时,首先从高斯分布采样一个带噪声的动作 chunk。我们获取 4 张相机图像和本体状态,通过 observation encoder 编码。然后运行 50 次扩散去噪循环,生成一个去噪后的动作 chunk。
我们发现不需要 [20] 的 temporal ensembling,直接将整个 chunk 的 50 个动作 open-loop(开环控制,控制器执行动作 不依赖实时反馈,直接按照预定动作序列输出。) 执行即可。
整个前向过程(包括去噪循环)在 RTX 4090 上耗时 0.043 秒。因为我们使用 open-loop 的 50 个动作 chunk,所以可以超过目标控制频率 50 Hz。
Data Collection:ALOHA 平台允许双臂远程操作(bimanual teleoperation),通过一个 puppeteering 界面实现操作机较小的leader 机械臂,同时较小的leader 机械臂关键会同步到较大的fllow机械臂。

收集了五个任务:Shirt hanging(挂衬衫)、Shoelace tying(系鞋带)、Robot finger replacement(更换机器人手指)、Gear insertion(齿轮插入)、Random kitchen stack(随机厨房物品堆叠)。
由于存在机器人硬件差异、环境差异、操作员差异。因此数据是十分多样的。
三:实验
每个任务使用分别训练在 5 个数据集(Shirt, Lace, FingerReplace, GearInsert, RandomKitchen)的模型各做 20 次试验
每一回合(episode)结束条件,1 成功完成任务,2 超时(ShirtMessy = 120 秒,其余任务 = 80 秒)
经过实验可以知道:
-
模型能够学习复杂的双手操作、物体重新定向、恢复与重试行为
-
数据量和质量直接影响模型性能
-
Diffusion Policy 在长序列、复杂任务上明显优于传统 L1 回归
-
模型有一定泛化能力:
-
对未见过的物体、初始状态和环境
-
对不同硬件机器人
-
模型对训练集覆盖范围内的状态有良好的泛化能力,但对于训练中未见过的极端初始状态(如倒置衬衫、翻倒鞋子)仍然会失败;同时模型能在不同机器人和环境中保持一定的任务执行能力。
四:总结
提出了 ALOHA Unleashed,1.在 ALOHA 2 平台上收集了 超过 26,000 个示范、2.使用这些数据训练了基于 Transformer 的 Diffusion Policy、3.在真实和模拟环境中,充分展示了机器人灵巧行为。ALOHA Unleashed 证明,一个简单的方法就可以提升 双臂灵巧操作的能力。
局限性,策略每次只训练单一任务(其他方法可能使用 单一模型权重,通过语言或目标图像条件化,实现多任务操作)、2.策略每 1 秒重新规划一次(对于高度需要快速反应的任务,这可能不够快)、3.每个任务都需要大量人工示范(数据收集耗时)
未来工作,1.扩展 ALOHA Unleashed,使单个模型能够执行 多任务、2. 改进建模以支持更 快速反应的任务、3.继续提升数据多样性与复杂性,减少学习灵巧行为所需的数据量。
虽然ALOHA Unleashed 展示了大规模示范 + Diffusion Policy 可以让机器人学会双臂灵巧操作,但还需要多任务能力、高速反应和更高数据效率来进一步扩展应用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)