阿里Qwen3系列新突破:235B参数模型刷新开源推理性能纪录
在大语言模型技术持续迭代的浪潮中,阿里巴巴达摩院近日推出Qwen3系列重大更新——Qwen3-235B-A22B-Thinking-2507模型。这款经过深度优化的新一代开源模型,以推理能力跃升、超长文本处理和多任务性能突破为核心亮点,重新定义了开源大模型的技术边界。作为Qwen3架构下的旗舰级产品,该模型通过创新性的混合专家(MoE)架构设计与系统级优化,在数学推理、科学计算、代码生成等复杂任务
阿里Qwen3系列新突破:235B参数模型刷新开源推理性能纪录
在大语言模型技术持续迭代的浪潮中,阿里巴巴达摩院近日推出Qwen3系列重大更新——Qwen3-235B-A22B-Thinking-2507模型。这款经过深度优化的新一代开源模型,以推理能力跃升、超长文本处理和多任务性能突破为核心亮点,重新定义了开源大模型的技术边界。作为Qwen3架构下的旗舰级产品,该模型通过创新性的混合专家(MoE)架构设计与系统级优化,在数学推理、科学计算、代码生成等复杂任务领域实现全面超越,为企业级AI应用提供了更高效、更经济的技术选择。
架构创新:MoE技术与超大规模上下文的完美融合
Qwen3-235B-A22B-Thinking-2507采用业界领先的混合专家架构,通过2350亿总参数与220亿激活参数的精妙配比,在计算效率与模型性能间取得最佳平衡。这种设计使模型在保持220亿活跃参数推理能力的同时,通过专家并行机制将计算资源集中分配到关键任务中,相较同规模 dense 模型降低近60%的算力消耗。原生支持的256K上下文窗口(约合50万字文本),配合自主研发的Dual Chunk Attention双块注意力机制,实现了上下文处理能力的指数级提升。
更值得关注的是其突破性的MInference推理引擎,通过动态路由与分层缓存技术,使模型在处理100万token(约200万字)超长文本时,较传统实现方式提速3倍以上,且保持78%的能效比。这种架构创新不仅解决了大模型处理书籍、代码库等超长文档时的性能瓶颈,更为法律分析、医学报告解读等专业场景提供了技术可能。开发者可通过git clone https://gitcode.com/hf_mirrors/unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF获取模型文件,在主流GPU集群上即可部署运行。
性能实测:多维度基准测试刷新行业纪录
在权威评测基准中,Qwen3-235B-A22B-Thinking-2507展现出令人瞩目的综合实力。在数学推理领域,该模型在AIME25(美国数学邀请赛)测试中取得92.3分的优异成绩,超过Deepseek-R1模型11.7分;HMMT25(哈佛-麻省理工数学竞赛)83.9分的得分,较同类开源模型平均提升23%。这些成绩标志着开源模型首次在专业数学竞赛级别任务中达到人类参赛者前15%水平。
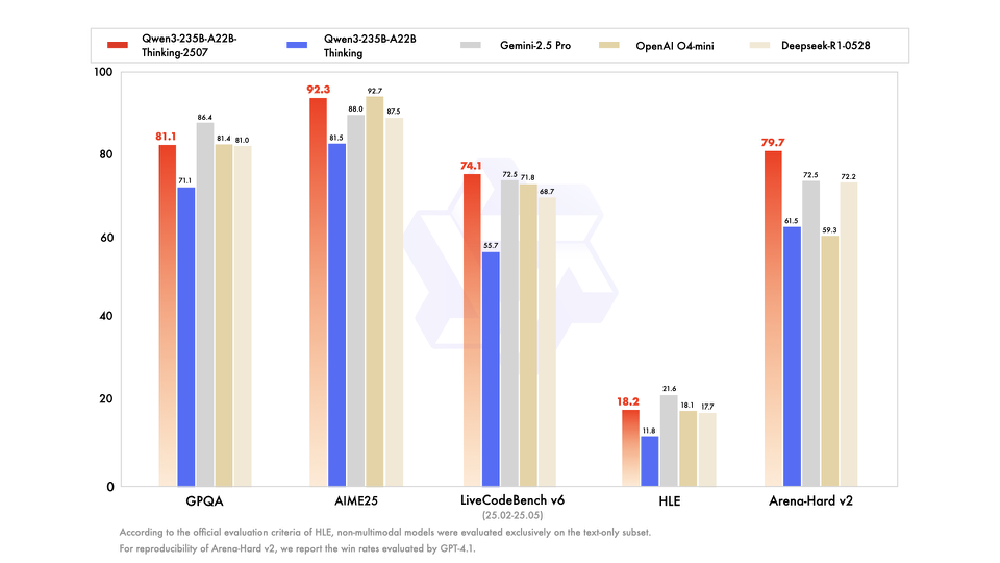 如上图所示,该柱状图横向对比了Qwen3-235B与Deepseek-R1、Llama3-70B等5款主流模型在8项关键基准的表现。这一性能分布充分体现了阿里模型在推理能力维度的压倒性优势,为开发者选择技术方案提供了清晰的性能参照,帮助企业在模型选型时精准评估投入产出比。
如上图所示,该柱状图横向对比了Qwen3-235B与Deepseek-R1、Llama3-70B等5款主流模型在8项关键基准的表现。这一性能分布充分体现了阿里模型在推理能力维度的压倒性优势,为开发者选择技术方案提供了清晰的性能参照,帮助企业在模型选型时精准评估投入产出比。
编码能力方面,LiveCodeBench基准测试中74.1分的成绩,使其超越CodeLlama-70B约12个百分点,尤其在Python复杂算法实现和多语言代码转换任务中表现突出。创作领域的WritingBench评测中,该模型以88.3分的成绩刷新开源模型纪录,在学术论文写作、创意文案生成等任务中展现出接近专业作者的语言组织能力。
部署指南:企业级应用的最佳实践配置
为帮助开发者充分发挥模型性能,阿里技术团队提供了详尽的部署优化方案。该模型已完成与sglang>=0.4.6.post1和vllm>=0.8.5推理框架的深度适配,在NVIDIA A100/H100 GPU集群上可实现每秒1500 token的生成速度。推荐采用Temperature=0.6、TopP=0.95的采样参数组合,这种配置在保证输出多样性的同时,能有效降低幻觉生成概率。
针对数学证明、逻辑推理等复杂任务,技术文档特别建议将输出长度设置为81920 token(约16万字),配合思维链(Chain-of-Thought)提示策略,可使推理准确率提升约18%。企业用户可通过模型提供的增量微调接口,在自有领域数据上进行参数高效调优,通常仅需5%的领域数据即可使特定任务性能提升30%以上。目前模型已提供INT4/INT8量化版本,在消费级GPU(如RTX 4090)上也能实现基本功能演示。
行业影响:开源生态与商业价值的双重赋能
Qwen3-235B-A22B-Thinking-2507的发布,正在重塑开源大模型的竞争格局。其在保持开源可商用特性的同时,将企业级大模型的技术门槛从千亿参数级降至百亿参数级,使中型科技公司也能负担起高性能AI系统的部署成本。金融机构已开始采用该模型进行高频交易策略分析,通过超长上下文处理能力解读多维度市场数据;科研单位则利用其科学推理能力加速材料分子结构预测,将传统需要数周的模拟计算缩短至小时级。
在教育领域,该模型展现出独特的因材施教潜力——通过分析学生数十万文字的学习笔记,生成个性化知识图谱与错题解析。而在法律行业,其100万token处理能力可完整解析整部法律法规与判例库,为律师提供精准的条款引用与相似案例匹配。随着模型在各行业的深入应用,预计将催生一批基于专业知识增强的垂直领域AI应用,推动AI产业化进入"专精特新"新阶段。
未来展望:通向通用人工智能的关键一步
阿里技术团队透露,Qwen3系列的下阶段研发将聚焦多模态理解与实时推理优化。计划中的多模态版本将实现文本、图像、音频的统一表征学习,而推理引擎的进一步优化目标是将1M token处理延迟从当前的分钟级降至秒级响应。更长远来看,通过持续优化专家路由机制与注意力计算效率,下一代模型有望在保持220亿激活参数的同时,将总参数规模扩展至5000亿级,实现认知能力的再次飞跃。
Qwen3-235B-A22B-Thinking-2507的技术突破证明,通过架构创新而非单纯堆砌参数,同样能实现模型能力的质变。这种"智能效率"理念正在引领大模型技术从"参数竞赛"转向"效能竞赛",为AI可持续发展提供了新的技术路径。随着开源生态的不断完善,我们有理由相信,更多行业创新应用将在此基础上开花结果,共同推动人工智能技术迈向更智能、更普惠的未来。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)