Can AI-Generated Text be Reliably Detected? —— 当攻击者认真起来,AI 文本检测还有多大胜算?
在现实世界里,AI 生成文本究竟能不能被“可靠地”检测出来?不是在干净的 benchmark 上,不是在“老实人”场景里,而是在有攻击者、有动机、有时间专门绕过检测器的情况下。作者做了两件事:一方面,他们系统性地“压力测试”了当下主流的 AI 文本检测方案,包括水印、训练好的分类器、DetectGPT 这类 zero-shot 检测器以及基于检索的检测器;就算你有“最强可能的检测器”,当 AI 文
1. 论文基本信息
标题:Can AI-Generated Text be Reliably Detected?
作者:Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, Soheil Feizi 等
机构:University of Maryland、Harvard University 等
年份:2025(arXiv v4,2025-01-17)
论文链接:
- arXiv 链接
- 代码仓库
领域关键词:AI-generated text detection,watermarking,paraphrasing attacks,spoofing attacks,total variation distance,AUROC,LLM 安全性
2. 前言:这篇论文到底想回答什么?
这篇论文盯着一个简单但很刺耳的问题:在现实世界里,AI 生成文本究竟能不能被“可靠地”检测出来?不是在干净的 benchmark 上,不是在“老实人”场景里,而是在有攻击者、有动机、有时间专门绕过检测器的情况下。
作者做了两件事:一方面,他们系统性地“压力测试”了当下主流的 AI 文本检测方案,包括水印、训练好的分类器、DetectGPT 这类 zero-shot 检测器以及基于检索的检测器;另一方面,他们从理论上推了一个上界:就算你有“最强可能的检测器”,当 AI 文本分布逐渐逼近人类文本时,检测这件事本身会变得越来越不可能。
实验上的结果非常直观:通过一个看起来颇为“朴素”的递归释义(recursive paraphrasing)攻击,作者把一些原本 TPR@1%FPR 接近 99% 的检测器,打到了个位数;与此同时,文本质量(人类评分、perplexity、下游 QA 精度)只略有下降。理论上的结果则更悲观:随着模型变强、AI 文本越来越像人写的,哪怕是“上帝视角”的最佳检测器,AUROC 也会逐步逼近随机猜测。
3. 历史背景与前置技术:AI 文本检测是怎么走到今天的?
要理解这篇论文在做什么,得先把 AI 文本检测这条线的技术脉络梳理一下,作者在引言里其实已经给了一个很清晰的地图。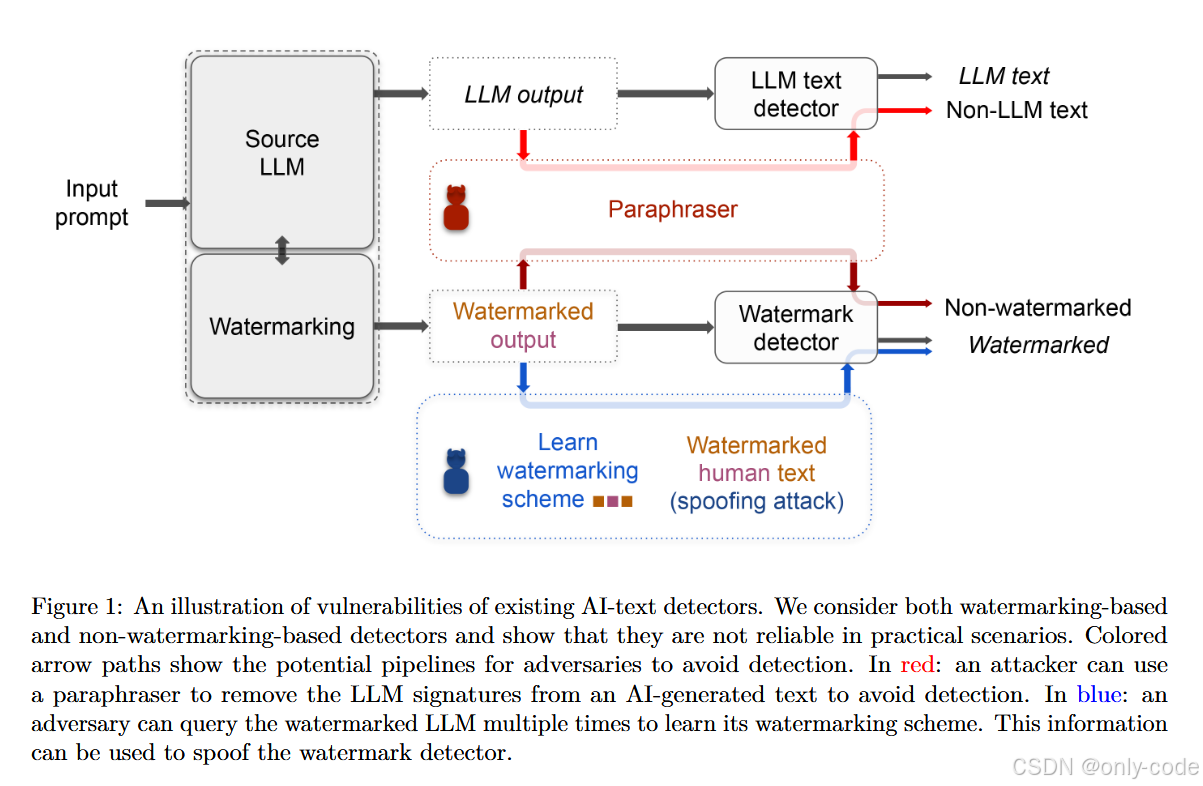
【插图:图1 AI 文本检测系统与攻击路径整体示意图(论文 Figure 1)】
第一条路线,是监督式的“判别器”思路。典型代表是 OpenAI 基于 RoBERTa 微调的 GPT-2 detector、MAGE 这类模型:把检测问题当成“AI 文本 vs 人类文本”的二分类,喂大量标注数据训练。优势是效果好、AUROC 高;缺点也显而易见:每出一个新 LLM,就要重新收集数据、重新微调,而且这类模型本身也容易受到对抗样本、数据投毒等攻击。
第二条路线,是 zero-shot 统计检测。这条线不再训练新的模型,而是直接拿生成模型本身当“判官”,看一段文本在模型下的统计特征异常不异常。早期工作多用per-token log prob 或 perplexity 做阈值,比如 Solaiman 等、Gehrmann 等、Ippolito 等的工作;更进一步的就是 Mitchell 等提出的 DetectGPT:他们发现 LLM 生成的文本,在 log 概率曲面的曲率上呈现出系统性差异,进而利用“在扰动邻域中的概率曲率”为特征来做检测。这类方法的优点是不需要再训练检测器,缺点是:最好得能访问到“那个真正生成文本的模型”本身,而且依然可以被对抗性操作破坏。
第三条路线,是文本水印(watermarking)。从信息隐藏的角度出发,在生成时往输出中“打暗号”。近期比较有代表性的是 Kirchenbauer 等提出的 soft watermark:把词表按伪随机方式分成“绿色列表”和“红色列表”,生成时强烈偏向绿色 token;检测时统计一段文本中绿色 token 的占比,显著高于自然语言时就判为 AI 文本。优点是检测非常简单、无需再训练检测器,缺点是用户必须真的用带水印的模型,否则攻击者直接换一个没水印的 LLM 就绕过去了。
第四条路线,是基于检索(retrieval-based)的检测。Krishna 等的想法是:把 LLM 的输出都存到一个向量数据库里,检测时只要看候选文本在库里有没有“高度相似”的邻居——有就判为 AI 文本。这样就算攻击者做一些简单的释义,仍然很可能被相似度抓回来。问题在于:这意味着要存大量用户对话,隐私风险非常高,而且真正遇到聪明的释义攻击,效果也未必可靠。
这篇论文就是在这样的背景下出现的:水印看起来很有希望、DetectGPT 也有不错的 AUROC、检索式检测似乎能挡住“普通”的 paraphrase,但当攻击者愿意多走几步路、反复利用 paraphraser 和检测器的反馈时,这一切还能撑住吗?
4. 论文核心贡献:从“造检测器”转向“解构检测器”
读完论文,我的感受是:这篇工作并不是再造一个“更强检测器”,而是站在一个略微悲观但很诚实的立场上,系统性地拆解现有检测技术的脆弱点。他们的主线大概可以浓缩成三句话:
首先,作者设计了一个自动化、可递归的释义攻击框架,把它同时用在四大类检测器上:soft watermark、训练好的 RoBERTa 检测器、多种 zero-shot 检测器(含 DetectGPT)、以及检索式检测。结论是:递归释义可以在保持文本质量基本不崩的前提下,把检测性能从“几乎完美”打到“接近随机”。
其次,他们又反向思考:既然可以让 AI 文本被“误判成人类文本”(evasion),能不能让人类文本被“误判成 AI 文本”?这就是他们提出的 spoofing 攻击。他们在水印检测、检索式检测以及常见的检测器上,都给出了现实可行的 spoofing 方案,说明如果盲目依赖检测器,很容易造成“误伤无辜”的严重后果。
最后,作者从分布距离的角度给出了一个理论上界:对于任意检测器 D D D,在 AI 文本分布 M M M 与人类文本分布 H H H 的 total variation distance T V ( M , H ) TV(M,H) TV(M,H) 给定的情况下,AUROC 至多为
A U R O C ( D ) ≤ 1 2 + T V ( M , H ) − T V ( M , H ) 2 2 AUROC(D) \le \frac12 + TV(M,H) - \frac{TV(M,H)^2}{2} AUROC(D)≤21+TV(M,H)−2TV(M,H)2。
换句话说,当 LLM 的输出越来越像人写的、两者的 T V TV TV 变小时,就算你有“完美的信息”和“无限算力”,检测这件事本身也会变得越来越接近随机猜测。
5. 方法详解:递归释义、伪造攻击与理论上界
5.1 整体设定与记号
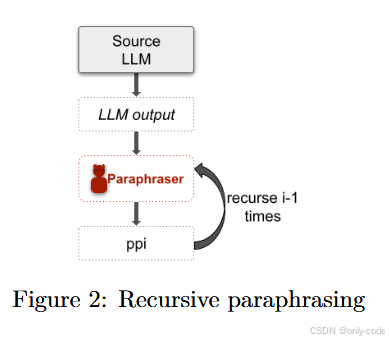
【插图:图2 递归释义攻击整体流程图(论文 Figure 2)】
作者先设定了一个非常贴近现实的攻击场景:攻击者可以访问一个“强大但可能带水印”的目标 LLM L L L,也可以访问一个“专门用来改写文本”的释义模型 P P P。
具体来说,一段 AI 文本的产生过程是这样的:
- 给定数据集中的一篇新闻/文章,取前约 300 个 token 作为上下文 C C C;
- 用目标 LLM L L L 生成一段长度约 300 token 的输出 S = L ( C ) S = L(C) S=L(C);
- 这段 S S S 可以是带水印的(比如 soft watermark 的 watermarked OPT-13B),也可以是普通 LLM 输出。
接下来,攻击者用释义模型 P P P 对 S S S 做改写。作者考虑了三类 paraphraser:
- DIPPER:11B 参数的高质量 paraphraser,可以整体 paraphrase 一整段 S S S;
- LLaMA-2-7B-Chat:通过一段 system prompt 把 chat 模型“改装”成 paraphraser,用法类似 DIPPER;
- T5-based paraphraser:较轻量的句级 paraphraser,对每个句子独立改写。
形式化地,如果一篇文章是句子序列 S = ( s 1 , s 2 , … , s n ) S = (s_1, s_2, \dots, s_n) S=(s1,s2,…,sn),DIPPER / LLaMA-2-7B-Chat 以整体形式输出
S ′ = f strong ( S , C ) S' = f_{\text{strong}}(S, C) S′=fstrong(S,C),而 T5 则是句级
S ′ = ( f weak ( s 1 ) , … , f weak ( s n ) ) S' = (f_{\text{weak}}(s_1), \dots, f_{\text{weak}}(s_n)) S′=(fweak(s1),…,fweak(sn))。
**递归释义(recursive paraphrasing)**则是在此基础上进一步迭代:
- 第一次释义: p p 1 ( S ) = f strong ( S , C ) pp_1(S) = f_{\text{strong}}(S, C) pp1(S)=fstrong(S,C)
- 第二次释义: p p 2 ( S ) = f strong ( p p 1 ( S ) , C ) pp_2(S) = f_{\text{strong}}(pp_1(S), C) pp2(S)=fstrong(pp1(S),C)
- ……
- 第 k k k 次释义: p p k ( S ) = f strong ( p p k − 1 ( S ) , C ) pp_k(S) = f_{\text{strong}}(pp_{k-1}(S), C) ppk(S)=fstrong(ppk−1(S),C)
作者一般做到 五轮释义,记作 p p 1 pp_1 pp1 到 p p 5 pp_5 pp5,并且在一些设置里还引入了 Best-of-ppi:对同一段文本生成多种释义,利用检测器本身的分数挑出“最难被检测那个”。这相当于攻击者具有黑盒查询检测器的能力。
【插图:递归释义攻击伪代码或流程示意(可对应论文 Figure 2)】
数据集方面,核心实验用的是:
- XSum:新闻摘要数据集,用其长文档部分,每段约 300 token;
- PubMedQA:医疗问答数据集,文本风格与新闻明显不同;
- Kafkai:包含真实与 AI 生成文章的混合数据集,涵盖营销、网络安全等多个领域。
目标 LLM 则包括 OPT-1.3B、OPT-13B、GPT-2-Medium、LLaMA-2-13B 等,基本覆盖了从老一代 GPT-2 到较新的开源大模型。
5.2 文本质量评估:攻击不能“自毁文采”
【插图:表1 与 表2 使用 MTurk 的人工评估结果(递归释义的内容保真与语法质量)】
有了攻击框架之后,一个关键问题是:**我们是不是为了绕过检测而把文本质量牺牲得一塌糊涂?**作者从人工和自动两个角度做了相当细致的评估。
在人类评估方面,他们从水印 OPT-13B 生成的文本中选出 20 段,分别对其 p p 1 … p p 5 pp_1 \dots pp_5 pp1…pp5 做评估,每个样本由 3 个 MTurk 工人打分,关注两个维度:
- 内容保真度:释义后是否还保持原意?
- 语法与文本质量:流畅度、语法错误、可读性。
评分采用 1–5 的 Likert scale。对 DIPPER 的结果大致是:
- 内容保真:约 70% 的释义被评为 4 或 5 分(基本保留主要信息);
- 语法质量:约 89% 的释义被评为 4 或 5 分,平均分约为 4.14±0.58。
LLaMA-2-7B-Chat 的结果甚至略好一些:内容维度 83% 为高分,语法维度 88% 为高分。总体上看,大部分递归释义在语义和语法上都被认为是“高质量改写”,而不是“糊弄机器”的垃圾文本。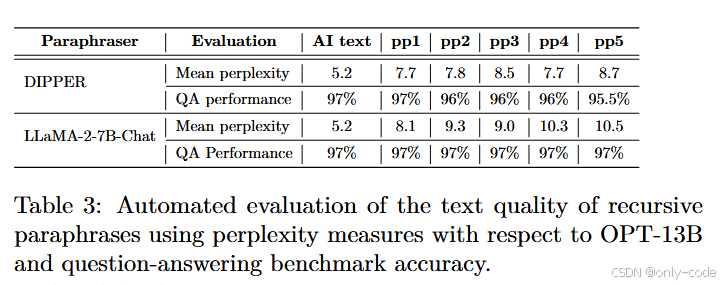
【插图:表3 递归释义轮次与 perplexity / QA 准确率关系】
在自动度量方面,作者看了两件事:
- 用 OPT-13B 计算 perplexity:不释义时约为 5.5,经过五轮 DIPPER 释义后提升到约 8.7,LLaMA-2-7B-Chat 下约为 10.5——有明显提升,意味着风格有所变化,但不是灾难性飙升。
- 在 SQuAD-v2 问答任务上评估:他们选取上下文长度≥300 token 的样本,递归释义上下文,再让 LLaMA-2-13B 以精心设计的 system prompt 回答问题。结果是:原文上下文下 QA 准确率约为 97%,递归释义后依然维持在 95–97% 左右,说明信息内容基本没有丢失。
这两个角度共同支持了一个结论:递归释义确实在有效改变“检测器眼里的统计特征”,但在人类读者看来,文本依然像是“正常高质量写作”。
5.3 对水印检测器的递归释义攻击
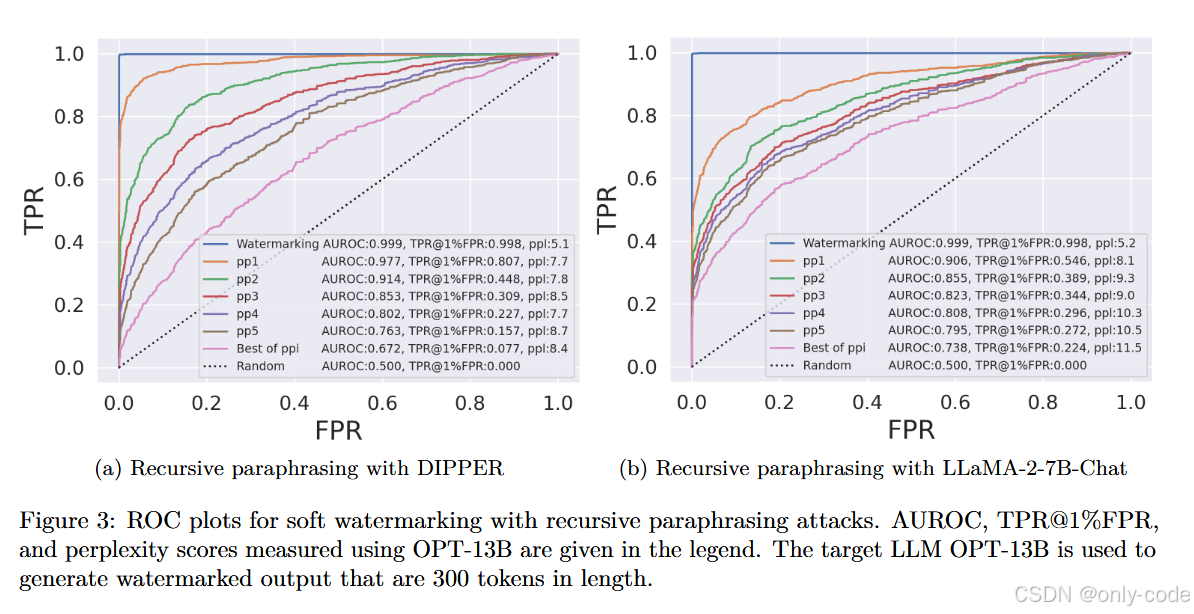
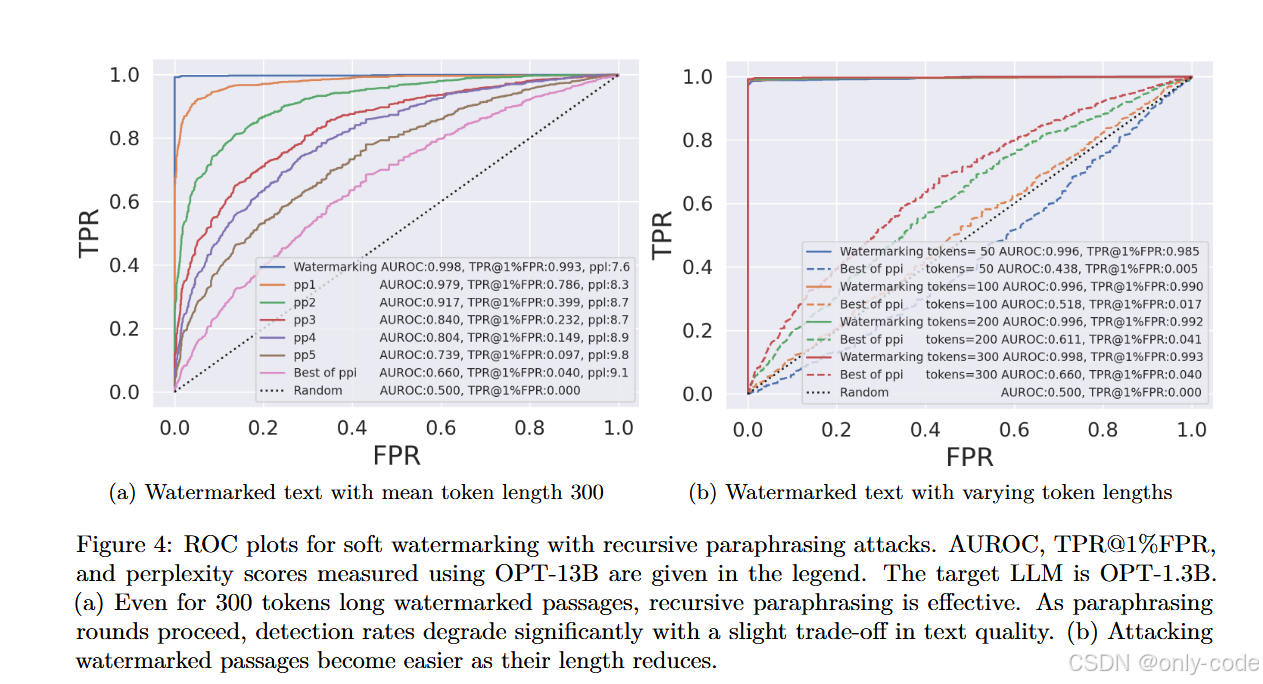
【插图:图3 与 图4 不同模型与不同长度下 soft watermark ROC 曲线变化】
接下来是论文中最“刺眼”的部分之一:soft watermark 在递归释义面前有多脆弱。
soft watermark 的机制是:对每个时间步 t t t,根据前一 token s t − 1 s_{t-1} st−1 通过一个伪随机函数生成“绿色列表”和“红色列表”,然后在采样时强烈偏向绿色 token。检测器只要数一段文本中绿色 token 的比例是否“异常高”,就能判断是否水印文本。
作者在 XSum 上构造了 2000 段样本:1000 段 AI 文本来自 watermarked OPT-13B(或 OPT-1.3B),每段约 300 token;另一半是人类写的新闻片段。基线情况下,Kirchenbauer 等的 soft watermark 在这一设置下可以做到:
- TPR@1%FPR ≈ 99.8%,几乎完美检测。
然后他们施加递归释义攻击:
- 只做 一轮释义 p p 1 pp_1 pp1 时,TPR@1%FPR 从 99.8% 掉到大约 80.7%(DIPPER)或 54.6%(LLaMA-2-7B-Chat);
- 继续做 五轮释义 p p 5 pp_5 pp5,检测性能进一步跌到十几甚至个位数;
- 在允许黑盒查询检测器的 Best-of-ppi 设置下,OPT-1.3B 的 TPR@1%FPR 可以从 99.8% 直接打到接近 4%,perplexity 只上升约 1.5。
另外一个有意思的 ablation,是看文本长度的影响。总体趋势是:
- 对 300 token 的长文本,水印相对更稳一些,但依然挡不住多轮释义;
- 当文本长度降到 50 或 100 token 时,在递归释义后,水印检测的 ROC 曲线几乎和随机分类器重合。
这给了一个很现实的提醒:哪怕我们能在长文档场景下把水印做得还可以,在推特式短文本、评论、标题这些场景里,水印的检测力会迅速崩塌。
5.4 对非水印检测器的攻击:zero-shot、训练模型与检索式检测
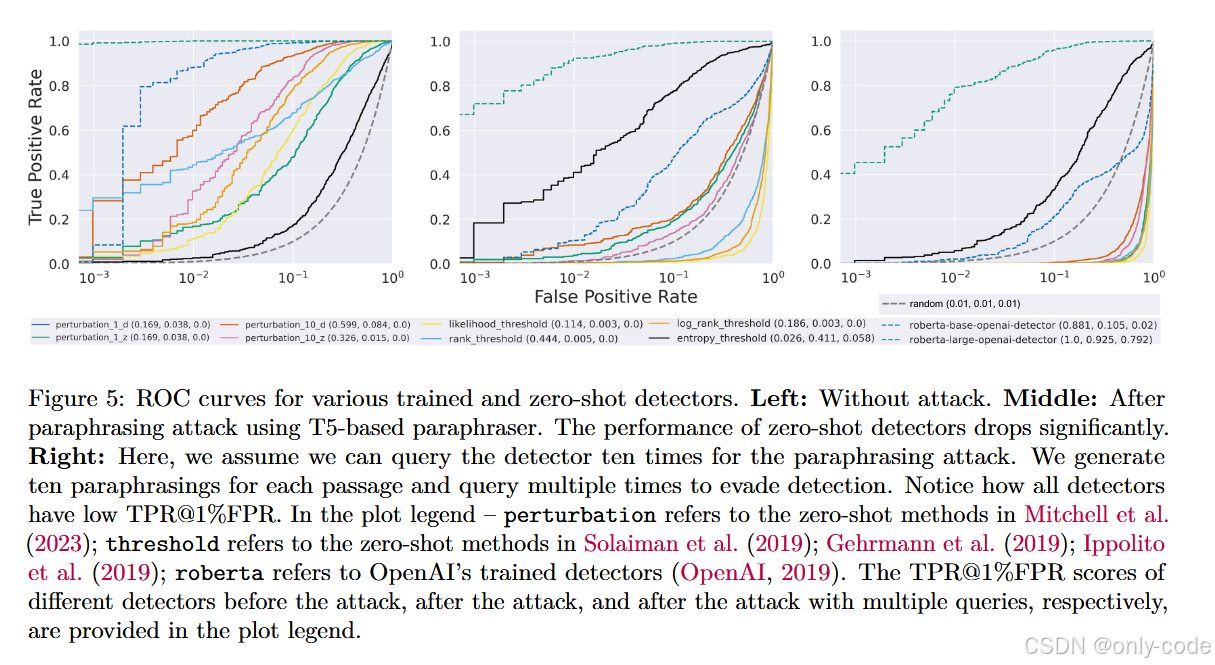
【插图:图5 各类 zero-shot 与训练检测器在释义前后及多次查询下的 ROC 曲线】
接下来,作者把战场转向非水印检测器。这里主要有三类:
- Zero-shot 检测器:包括 DetectGPT 的不同变体(用不同扰动策略与 score)、以及基于 likelihood/rank/log-rank/entropy 阈值的经典方法;
- 训练好的检测器:OpenAI 的 RoBERTa-base / RoBERTa-large,Longformer、MAGE 等;
- 基于检索的检测器:Krishna 等提出的“存库 + 相似度”策略。
在针对 GPT-2-Medium + XSum 的实验中,作者用句级 T5 paraphraser 做单轮释义,得到的结果大致是:
- DetectGPT 的 AUROC 从约 96.5% 掉到 59.8% 左右,几乎接近随机;
- 其他 threshold-based zero-shot 检测器也集体暴跌;
- OpenAI 的 RoBERTa-Large 虽然更“抗打”一些,但 TPR@1%FPR 也从 100% 掉到约 92% 左右。
在允许攻击者对每个样本生成十个 paraphrase,并多次查询检测器,挑最“像人写”的那个时,情况进一步恶化:
- RoBERTa-Large 的 TPR@1%FPR 可以持续被拉低到 80% 左右;
- DetectGPT 及其他 zero-shot 检测器则基本彻底崩溃。
有一个有趣的现象是:熵阈值检测器在某些设置下“反而变好了”。作者的解释是:LLM 训练数据中已经包含了很多 XSum 里的新闻,人类写的 XSum 段落对模型来说熵可能反而较低;经过 paraphraser 改写之后,这些人类文本“不再被 LLM 记住”,熵上去了,于是检测器的识别效果“假装提高”。这进一步说明:很多检测器对训练分布高度敏感,一旦换数据集或体裁,很容易失效。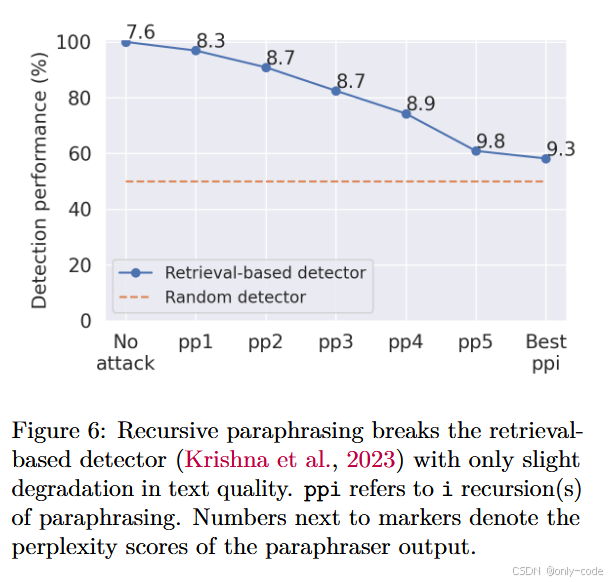
【插图:图6 检索式检测器在多轮释义攻击下的准确率变化】
对 检索式检测器,作者的策略是用 DIPPER 做递归释义,并让检测器始终把原始 AI 输出存入数据库。结果是:
- 在不攻击或只单轮释义 p p 1 pp_1 pp1 时,检索式检测几乎能做到接近 100% 的准确率;
- 但随着轮数增加到 p p 5 pp_5 pp5,检测准确率逐步滑落到 50–60% 左右,本质上也接近随机水平;
- 对应的 perplexity 只上升了约 1.7 左右。
同时,作者也指出了一个现实问题:要做到这类检测,就意味着要长时间保存用户与 LLM 的会话内容,这在隐私和合规层面会引出完全不同的一套风险。
5.5 Spoofing 攻击:让人类文本“看上去更像 AI”
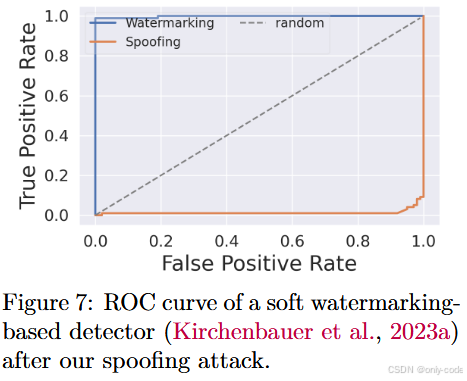
【插图:图7 soft watermark 在 spoofing 攻击下的 ROC 曲线】
到目前为止,我们讨论的都是“让 AI 文本像人类文本一样难以检测”。但现实世界里还有另一种非常危险的攻击:让人类文本被检测器误判为 AI 文本。这就是论文中所谓的 spoofing attack。
对 soft watermark,作者的思路是:虽然用于生成绿色列表的伪随机函数是私有的,但攻击者可以通过反复调用带水印的 LLM,从统计上“反推”哪些 token 在特定前缀后更可能被选中。具体做法包括:
- 限定一个常用词表(比如 181 个高频英语单词),反复采样一百万次,统计在每个前缀下后续 token 的分布;
- 基于这些统计构造一个“代理版绿色列表”,再按照这个列表手工写出句子。
结果是:只要写作时刻意从“代理绿色列表”里选词,水印检测器会牢牢相信这些文本是 AI 生成的。作者给出的数字非常激进:AUROC 可以从 99.8% 反向打到约 1.3%——也就是“几乎反着判”。
对 检索式检测器,spoofing 甚至更容易:比如一个老师拿到学生的论文 S S S,可以把 S S S 丢给 LLM 让它改写出 S ′ S' S′,而检索式检测器会把 S ′ S' S′ 入库。此后只要拿着原文 S S S 去检测,它就会因为和库里的 S ′ S' S′ 高度相似而被判定为 AI 文本。作者在实验中表明:这种操作可以 100% 地“栽赃”成功。
对 zero-shot / 训练检测器,作者采用了一个非常朴素的策略:先找出一个被检测器强烈判为 AI 的短文本,然后把它前置到其他人类文本前面。结果表明,许多检测器在这种“恶意拼接”后 TPR@1%FPR 明显下降,意味着一个恶意合作者可以通过插入几句“高风险文本”,让整个合作文档都被判为 AI 生成。
这一部分的核心信息其实很直白:如果你要用 AI 文本检测结果去作“道德判断”或“纪律处分”,一定要意识到攻击者可以轻易制造“误报”来伤害无辜者。
5.6 理论分析:AUROC 与 total variation distance 的关系
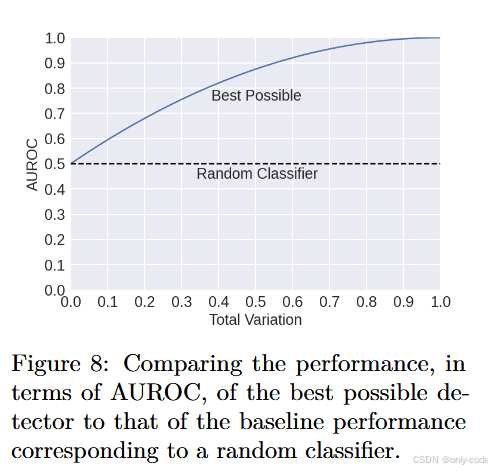
【插图:图8 不同 TV 下最佳可能检测器 AUROC 上界曲线】
最后,作者从更抽象的层面,给出了一个关于“检测难度”的理论上界。设:
- H H H:人类文本的分布;
- M M M:AI 文本的分布(可以是任意模型,甚至是攻击者特意训练的);
- T V ( M , H ) TV(M,H) TV(M,H):两者之间的 total variation distance。
他们把任意检测器 D D D 看作一个打分函数 D : Ω → R D:\Omega \to \mathbb{R} D:Ω→R(对每个文本输出一个分数),再通过阈值 γ \gamma γ 得到不同的 TPR 与 FPR。主定理是:
- 对任意检测器 D D D,都有
A U R O C ( D ) ≤ 1 2 + T V ( M , H ) − T V ( M , H ) 2 2 AUROC(D) \le \frac12 + TV(M,H) - \frac{TV(M,H)^2}{2} AUROC(D)≤21+TV(M,H)−2TV(M,H)2。
这条不等式有几个直观含义:
- 当 T V ( M , H ) = 0 TV(M,H)=0 TV(M,H)=0 时,AUROC 的上界就是 0.5 0.5 0.5,也就是再聪明的检测器也只能做到“抛硬币水平”;
- 要想 AUROC 超过 0.9, T V ( M , H ) TV(M,H) TV(M,H) 至少要大于约 0.5——也就是说 AI 文本与人类文本在分布上要有非常明显的差异;
- 而在很多实际应用(比如查重)中,我们还希望在 FPR 很低(比如 1%)时 TPR 很高(比如 90%),这要求 T V ( M , H ) TV(M,H) TV(M,H) 极大,接近 0.9。
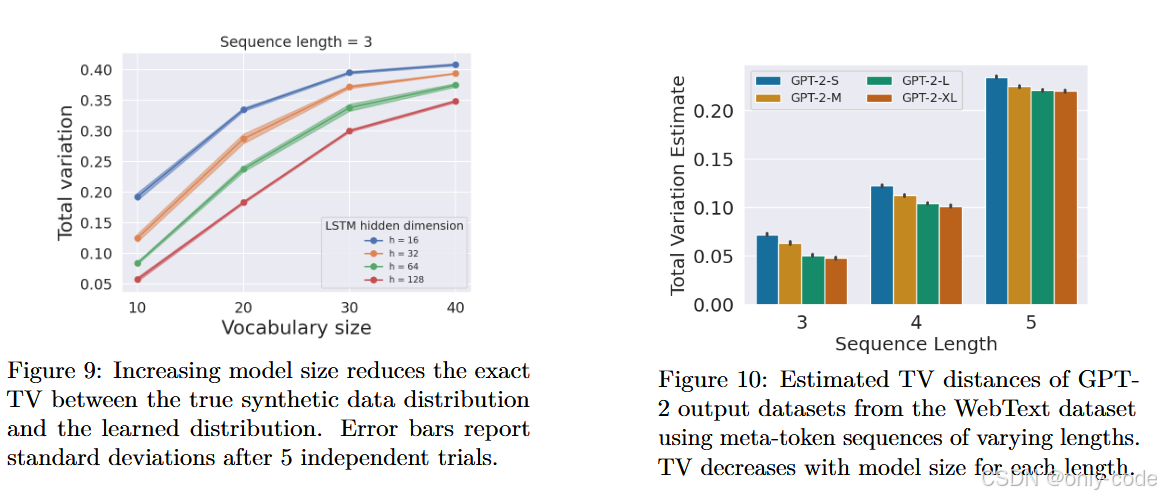
【插图:图9 合成数据上 LSTM 模型大小与 TV 距离的关系】
【插图:图10 不同尺寸 GPT-2 输出分布与 WebText 之间 TV 估计的关系】
为了支撑“随着模型变强,TV 会变小”这个直觉,作者做了两组实验:
- 合成马尔可夫文本 + LSTM:用随机生成的转移矩阵构造“真”分布,再用不同隐藏维度的单层 LSTM 去拟合;由于状态空间简单,可以精确算出 TV。结果是:LSTM 越大,学到的分布越接近真实分布,TV 单调下降。
- GPT-2 + WebText 的投影 TV 估计:真实文本空间巨大会让 TV 难以估计,他们把词表划分成 5 个大块,并用“元 token 序列”来近似。用 WebText 与不同规模 GPT-2(small、medium、large、XL)的输出估计 TV,发现在不同序列长度下,TV 都随模型规模增大而下降。
结合主定理,这两组实验其实在诉说同一件事:随着模型变得更强、文本分布更贴近人类,检测这件事从“工程问题”逐步走向“信息论极限问题”,最终不可避免地变得越来越难。
作者还在附录中讨论了伪随机数带来的细节:严格来说,使用伪随机采样会让 AI 文本分布在数学上与人类文本分布“非常不同”,TV 接近 1。但只要伪随机发生器足够安全,对任何多项式时间的检测器来说,这点差异几乎不可利用,因此他们引入了一个“计算版 TV” 的概念,证明在这个意义上,前面的上界仍然成立。
6. 实验结果:从 ROC 曲线读出“无力感”
如果只看一两张 ROC 曲线,你可能还觉得“检测器还能挺一挺”。但把论文里的表和图连着看下来,会很容易感受到作者想传达的那个基调:在攻击者真正动手之后,现有检测方法的性能塌得非常快。
在 水印检测 部分,soft watermark 在 XSum + watermarked OPT-13B 上的表现起点很高:TPR@1%FPR 约 99.8%。然而在 DIPPER 的递归释义下,只要两轮 p p 2 pp_2 pp2,检测率就能打到 50% 以下,五轮或 Best-of-ppi 几乎接近随机。对文本长度的消融实验则说明,当 passage 较短时,水印信息本身就不稳定,更容易被改写冲淡。
在 zero-shot 与训练检测器 部分,DetectGPT 系列在不攻击时 AUROC 可达 0.96 以上,属于相当不错的检测器;一轮释义后掉到 0.6 左右,多轮释义 + 多次查询后进一步趋向 0.5。RoBERTa-Large 这类训练检测器虽然更稳,但:
- 在自己“见过”的分布(如 XSum)上还能勉强有效;
- 一换到 Kafkai 这种风格不同的数据集,AUROC 和 TPR@1%FPR 都出现明显下滑;
- 再叠加释义攻击,整体性能就很难被称为“可靠”。
在 检索式检测 部分,初始准确率可以高到 90–100%,这也印证了“只要 paraphrase 稍微弱一点,检索就能抓回来”这个直觉。但递归释义之后,准确率一路降到 50–60%,对于一个需要做严肃决策(比如判定作弊)的系统来说,这样的性能显然难以承担责任。
论文还给出了递归轮次与 perplexity 的统计:基本趋势是**攻击越强、轮次越多,perplexity 越高;**但在人类评估中,大部分 paraphrase 依然被评为“高质量改写”。这形成了一个非常清晰的 trade-off:攻击者可以在可接受的文本质量损失范围内,把检测器性能压到危险水平。
7. 创新点与不足:这篇论文最值得记住的是什么?
对我来说,这篇论文最重要的创新不在于某个“新模型”,而在于它整体的视角转向:从“如何提高检测器 AUROC”转向“在攻击者存在时,检测这件事本身有多脆弱、多有限”。其中几个点尤其值得记住:
- 他们给出了一个非常具体、可操作的 递归释义攻击框架,并在多种 paraphraser、多个数据集、多个目标模型上展示了它的威力。这个框架兼顾了“攻击成功率”和“文本质量”,而不是简单做无意义的扰动。
- 他们第一次系统地把 watermark、zero-shot 检测、训练检测器、检索式检测 放到同一个实验框架下进行压力测试,让我们能直接比较不同思路在攻击下的脆弱性。
- 在 spoofing 攻击 上,他们展示了攻击者如何让人类文本被检测器误判为 AI 文本——尤其是对 soft watermark 和检索式检测的“栽赃”攻击,非常直观地揭示了盲目依赖检测器可能造成的社会后果。
- 从理论上,他们把检测问题和 total variation distance 联系在一起,通过一个简单但有力的不等式,提醒我们:当模型越来越像人类时,检测问题不是调参数或换网络结构就能解决的,而是在逼近一个信息论意义上的极限。
当然,这篇论文也有它的局限性,部分是作者主动承认、部分是我自己阅读时的感受:
- 实验主要集中在 英文长文本、新闻/问答/文章这样的体裁上。对于短文本、多语言场景,虽然有长度方向上的分析,但仍缺乏系统实验。
- 攻击者的能力设定相对“强”:能访问高质量 paraphraser、甚至在一些设置里可以多次查询检测器。现实中并不是所有攻击者都具备这样的资源,不过,从防御角度看,我们更应该担心那些“有资源、有时间”的人。
- 理论部分使用的 TV 距离在真实文本空间里很难精确估计,作者的实证只是一些合理但仍然粗略的 proxy。这不影响结论的方向,但把“定量”变得比较保守。
- 在防御建议上,论文并没有给出太多建设性的方案,更多是扮演了“提醒你,这条路非常难走”的角色。这既是诚实的,也意味着后续工作还需要在“检测之外的治理手段”上继续探索。
8. 总结:当检测走到极限,我们该怎样看待“AI 文本检测”这件事?
如果只用几句话来压缩这篇论文的核心,我会这样概括:**作者用递归释义和 spoofing 两把“锤子”,把当前主流 AI 文本检测方案逐个敲了一遍,发现几乎没有谁能在攻击者认真出手时保持真正的“可靠”。**无论是看起来很有希望的 soft watermark,还是 DetectGPT 这样的 zero-shot 检测器,或者是隐私风险很高但理论上强力的检索式检测,都在实验中显露出了明显的脆弱性。
在此之上,他们又从 total variation distance 的角度,给出了一个与具体模型无关的上界:**当 AI 文本和人类文本的分布差异缩小时,任何检测器的 AUROC 都会不可避免地退化。**随着大模型能力不断提升,这个趋势几乎是注定的。
这并不意味着检测完全“没用”,而是提醒我们:**它更适合作为风险信号和辅助手段,而不是裁决工具。**在面对学术诚信、舆论操控、垃圾信息治理这些严肃问题时,把所有希望寄托在“检测器能精准告诉我们谁用了 AI”上,既不现实,也不安全。
读完这篇论文,我会更倾向于把精力分散到其他维度上:比如在生产端加入水印和平台治理、在流程端设计更合理的评价机制、在教育端调整对写作的要求。检测器依然可以存在,但它不再是那个被寄予“万能审判”期望的主角,而是一个需要被小心使用、理解其局限的工具。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)