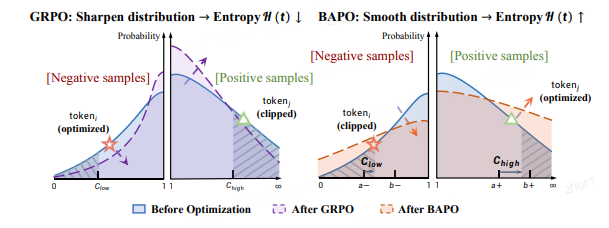
BAPO:自适应裁剪如何实现LLM策略优化的动态平衡
BAPO (Balanced Policy Optimization with Adaptive Clipping),从根本上改变了游戏规则。BAPO 摒弃了 PPO 僵化的固定裁剪区间,转而采用一种以目标为导向的自适应机制:它为每一次更新动态地调整裁剪边界,其核心目标是确保正向信号在总梯度贡献中维持一个健康的比例。
BAPO (Balanced Policy Optimization with Adaptive Clipping),从根本上改变了游戏规则。BAPO 摒弃了 PPO 僵化的固定裁剪区间,转而采用一种以目标为导向的自适应机制:它为每一次更新动态地调整裁剪边界,其核心目标是确保正向信号在总梯度贡献中维持一个健康的比例。
| 现象 | 根源 | 后果 |
|---|---|---|
| 优化失衡 | 负优势样本在数量与梯度贡献上均占压倒性主导: ① 难题产生更长序列 → 负令牌更多; ② 初期模型能力弱 → 负样本比例高。 |
① 有用正信号被淹没; ② 低概率负令牌累积 → 梯度爆炸; ③ 训练失稳、性能停滞。 |
| 熵裁剪法则 | 固定对称裁剪 [1−ε, 1+ε] 系统性地阻断低概率正令牌更新,排除熵增方向。 | ① 分布持续锐化 → 熵崩溃; ② 探索能力丧失; ③ 陷入局部最优。 |
三、动机:不平衡优化与熵裁剪法则
尽管离策略(Off-policy)RL 在理论上具备提升样本效率的巨大潜力,但在实践中,尤其是在训练 LLM 这类复杂模型时,常常观察到一种令人困惑的现象:训练过程不仅不稳定,而且模型会迅速丧失探索新可能性的能力。
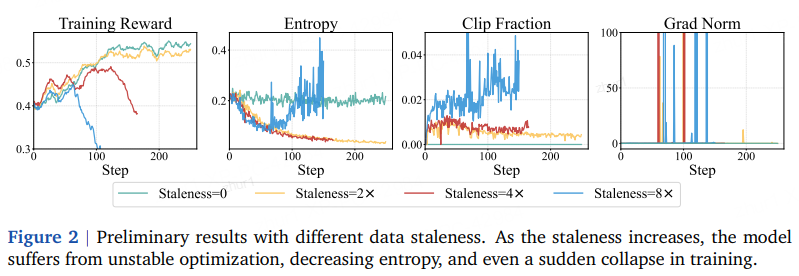
数据陈旧度实验(图 2)
随陈旧度增加 → 熵降更快、裁剪比例↑、梯度震荡甚至崩溃。
同策略训练全程保持稳定。
1. 洞察一:负向信号主导下的优化不平衡
第一个发现来自于对 PPO 目标函数中梯度构成的直接观察。训练过程并非在正向激励和负向惩罚之间取得了健康的平衡,而是严重失衡。
1.1 负样本的压倒性优势
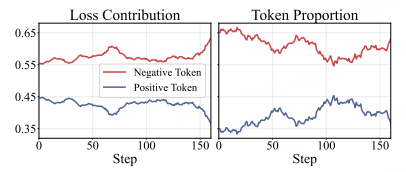
图 4:负令牌在数量与梯度贡献上都占 ~80%,正令牌成了“少数派”。
正令牌仅占约 20%,却对 loss 贡献不足 30%。
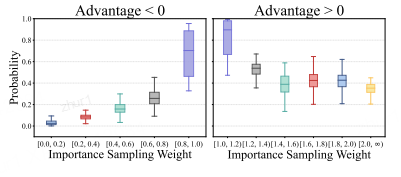
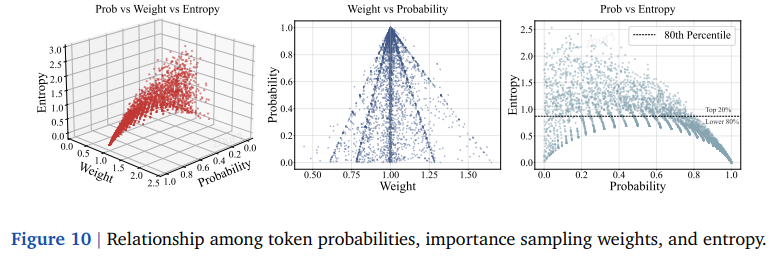
图 5:低概率令牌(IS 权重远离 1)里既有“潜力正样本”,也有“噪声负样本”;固定裁剪把低概率正样本全部挡在门外 → 熵增通道被切断。
平均响应长度:负样本显著更长 → 负梯度绝对值更大。
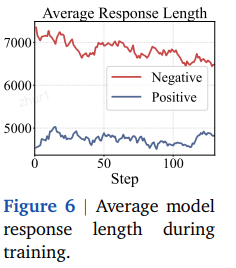
1.2 为何负样本如此之多?
这种不平衡主要源于两个因素:
- 探索性惩罚:在训练初期,模型能力有限,其探索性生成的大部分响应质量不高,自然会收到大量负面反馈。
- 长尾难题:在面对困难问题时,模型倾向于生成更长的、充满试错的轨迹,这同样会累积大量的负优势 token。
1.3 不平衡优化的致命后果
这种由负向信号主导的优化过程极其危险。首先,它会过度惩罚模型的探索行为,甚至抑制一些中性或有潜力的行为,导致学习效率低下。更严重的是,它带来了梯度爆炸的风险。当模型试图强烈抑制一个低概率的负优势 token 时(即 趋近与0),其对数项 会趋向于 无穷大 ,这足以引发梯度爆炸,彻底摧毁训练进程。
2. 洞察二:PPO 裁剪机制下的“熵裁剪法则”
优化不平衡解释了训练的“不稳定性”,但未能完全解释为何模型的“探索性”(即策略熵)会系统性地崩塌。为此,必须深入审视 PPO 的核心——裁剪机制,并揭示其一个未被充分认识的副作用。
Token 特征 类别 对熵的影响 说明 高概率,正优势 利用 (Exploitation) ↓ 熵减少 强化已知好动作,分布更尖锐。 低概率,负优势 强惩罚 ↓ 熵减少 抑制罕见坏动作,分布更尖锐。 低概率,正优势 探索 (Exploration) ↑ 熵增加 鼓励潜在新好动作,分布更平滑。 高概率,负优势 软化 (Softening) ↑ 熵增加 轻微削弱常见动作,分布更平滑。
标准 PPO(例如,裁剪区间为 [0.8, 1.2])的致命缺陷:
对于一个低概率、正优势的 token(探索的关键),其 rt 值很可能远大于 1.2,因此其更新被裁剪,无法对熵产生积极影响。
对于一个高概率、正优势的 token(利用的体现),其 rt 值接近 1,因此其更新未被裁剪,持续地降低熵。
PPO 的对称裁剪机制,在设计之初是为了保证稳定性,却无意中扮演了一个有偏见的“守门员”:它系统性地拒绝了能够增加熵的“探索性”更新,却放行了大量导致熵减少的“利用性”更新。这使得策略熵的下降成为一种必然,最终导致模型陷入局部最优,丧失了进一步提升的可能。
4 方法:BAPO——自适应裁剪的平衡策略优化
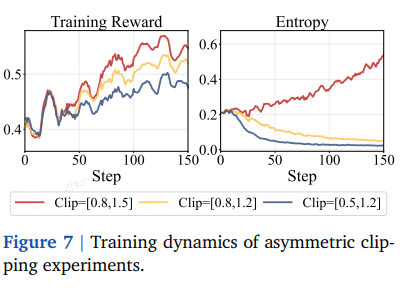
4.1 验证实验:非对称裁剪的有效性
- 固定下界 c_low、仅抬高上界 c_high → 熵降减缓、性能提升;
- 固定上界、放松下界 → 熵更快崩溃、性能下降。
⇒ 通过非对称信任区可人为控制熵,但需手动调参,缺乏灵活性。
4.2 BAPO 核心算法
目标:在每个更新步动态找到一对 (c_low, c_high),使正令牌对策略梯度损失的贡献占比 ≥ 预设阈值 ρ₀(式 8)。
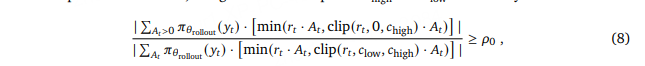
输入:
初始化的 LLM 策略 πθ,训练数据集 D,奖励函数 R,陈旧度 E,
裁剪界可移动范围 [a⁻, b⁻] 与 [a⁺, b⁺],上界步长 δ₁,下界步长 δ₂,
正令牌贡献阈值 ρ₀。
1 for 步数 s = 1…S do
2 过程:采样并过滤响应
3 更新旧策略 πθ_rollout ← πθ;
4 从 D 中采样第 s 批数据 Ds;
5 对每条 x ∈ Ds 采样 G 条响应 {yᵢ} ~ πθ_rollout(·|x);
6 基于奖励函数 R 计算每条 yᵢ 的奖励与优势 A;
7 for 陈旧度 = 0…E do
8 过程:动态调整裁剪界 chigh 与 clow
9 初始化 clow = a⁻,chigh = a⁺;
10 while 正令牌贡献 ρ < ρ₀ 且 clow + δ₂ ≤ b⁻ do
11 if chigh + δ₁ ≤ b⁺ then
12 chigh ← chigh + δ₁;
13 else
14 clow ← clow + δ₂;
15 end
16 end
17 过程:更新 LLM 策略 πθ
18 通过最大化以下目标更新 πθ:
19 JBAPO(θ) = E[∑ min(rt·At, clip(rt, clow, chigh)·At)];
20 end
21 end

收益
实时再平衡正负信号,避免负样本主导;
主动纳入低概率正令牌 → 维持熵水平;
通过 ρ₀ 防止正信号过度膨胀,缓解尾部退化(只学好学样本,难题放弃)。
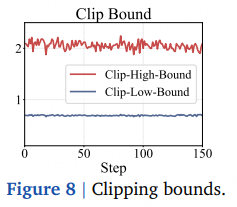
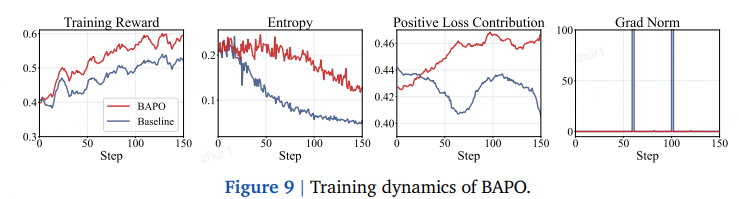
指标 BAPO 表现 训练曲线(图 9) 相比基线,BAPO 奖励上升更快;正令牌贡献更高、熵平稳、梯度范数可控 ,正贡献占比稳定。 裁剪界变化(图 8) c_high、c_low随训练动态波动,验证自适应调节。不同陈旧度(图 11) 在 2×/4× 陈旧度下,BAPO 一致优于基线与固定“clip-higher”策略,彰显鲁棒性。 token-概率-熵关系(图 10) IS 权重越远离 1,概率越低,熵越高;BAPO 正好利用这部分低概率高熵正令牌,与 Clip-Higher、Top-20%-Entropy 等前作目标一致,但无需手工调参。
一句话总结
BAPO 通过“每步自动寻找最合适的裁剪窗” (c_low, c_high),在不引入额外超参搜索的前提下,使得正令牌对策略梯度损失的贡献占比 ≥ 预设目标 ρ₀;
从而放大正信号、抑制负主导、持续引入低概率正例,在不掉熵的前提下实现稳定且快速的离策略训练

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)