Kimi K2:国产模型终于走上思维路线,你怎么看?
K2 最重要的特性是整体训练路线:专家分工、长上下文驱动一致性、工具调用通过真实执行训练、浏览器任务与长步骤任务强化、INT4 进入训练闭环。但 K2 是第一个明确走上深度推理、工具交织、认知分工、长期任务链、原生性能优化的路线。本文拆解其技术路线、核心理念、MoE 专家分工、工具链交织推理路径,并分析其与国际前沿 Claude/Gemini 的路线关系。国产大模型的叙事正在从“Chat 型模型”
欢迎关注「几米宋」微信公众号,这里专注分享 AI 前沿、云原生技术、开源生态、行业洞察与个人思考。更多精彩内容,欢迎访问我的个人网站 jimmysong.io。
📄 文章摘要
Kimi K2 Thinking 的开源标志着国产模型进入思维型大模型时代。本文拆解其技术路线、核心理念、MoE 专家分工、工具链交织推理路径,并分析其与国际前沿 Claude/Gemini 的路线关系。
国产大模型终于从“写得像人”迈向“想得像人”,Kimi K2 的开源是中国 AI 路线的分水岭。
国产大模型的叙事正在从“Chat 型模型”,转向“思维型模型(Thinking Model, Thinking Model)”。
Moonshot AI 开源的 Kimi K2 Thinking 标志着这场转折第一次真正落地。K2 并不是又一个 ChatGLM/Qwen 式的迭代,而是中国团队首次完成了“深度推理 + 长上下文 + 工具调用连续性”三者的统一训练。这也是思维模型路线的核心,正是过去 Claude、Gemini 领先的原因。
K2 开源的意义:国产模型进入思维型时代
K2 的开源为何成为拐点?因为它首次让国产模型具备了以下能力:
• 稳定执行 200–300 次工具调用(工具链推理稳定性)
• 深度、多阶段推理链连续执行(CoT Consistency, Chain-of-Thought Consistency)
• 256k 上下文作为“思维缓冲区”(Working Memory, Working Memory)
• 原生 INT4 加速 + MoE 激活稀疏度调度
这是一条完全不同于“堆参数 → 堆 benchmark”的路线,强调推理能力而非参数规模。
一句话总结:
K2 是国产模型第一次进入思维型模型(Thinking Model, Thinking Model)序列。
K2 的技术路线拆解
K2 的技术路线可以拆解为五个关键点,每一点都直接影响模型的推理能力和生态适配性。
MoE 专家分工:认知分工而非参数扩展
K2 的 MoE(Mixture of Experts, Mixture of Experts)设计理念与以往不同。其核心不是激活更少的参数或更便宜地跑更大模型,而是将不同认知子技能分配给不同专家。例如:
• 数学推理专家
• 规划专家
• 工具调用专家
• 浏览器任务专家
• 代码生成专家
• 长链路保持专家
这种分工方式直接对齐了 Claude 3.5 的认知分层(Cognitive Layering, Cognitive Layering)路线。K2 的 MoE 是“让模型分工思考”,而不是“让模型便宜计算”。
256K 上下文:打造模型的工作记忆
K2 的超长上下文不仅仅是参数炫技,更是用于构建模型的“思维缓冲区”。它允许全过程保留推理链、工具调用状态、多阶段反思,以及长任务(如科研、代码 refactor)不中断,稳定执行多阶段 Agent 流程。长期思考需要长期记忆支持,K2 的长上下文就是为持续推理链打造的“内存”。
工具调用与推理链交织训练
K2 在工具调用与推理链交织训练方面表现突出。传统开源模型通常是:
1. 生成推理
2. 输出 JSON 函数调用
3. 工具返回结果
4. 再继续推理
这种方式下,推理链与调用链是分离的。而 K2 的训练方式则允许推理链随时调用工具,并将工具结果塞回推理链,进入下一阶段思考。支持 200–300 步连续工具调用不中断,与 Claude 3.5 的 Interleaved CoT + Tool Use 完全一致。
INT4 原生量化:保障推理链稳定性
K2 的 INT4(INT4, 4-bit Integer Quantization)路线不是普通的后量化。其目的不仅是降低显存、提高吞吐,更重要的是确保深度推理链不会因算力不足而中断。深度思维链的最大杀手是超时、冻结、Worker 不稳定。INT4 让国产 GPU(非 H100)也能跑完整推理链,这对国产生态意义重大。
MoE + 长上下文 + 工具链:统一训练而非模块拼接
K2 最重要的特性是整体训练路线:专家分工、长上下文驱动一致性、工具调用通过真实执行训练、浏览器任务与长步骤任务强化、INT4 进入训练闭环。它不是“ChatLLM + Memory + RAG + Tools”的拼贴式路线,而是一体化推理系统。
K2 与国际主流路线的对齐与差异
K2 与国际主流模型(如 Claude、Gemini、OpenAI)在认知推理、超长上下文、工具调用机制等方面高度对齐,但也有国产模型的独特优势:
• 原生 INT4 + 国产算力适配路线全球少见
• 工具链连续性比大多数开源模型更稳定
• 开源程度更高,生态可复用性更强
国产 AI Infra 的协同价值:K2 × RLinf × Mem-alpha
K2 生态中还出现了一系列重要开源基础设施。下表总结了这些项目类型及其对 K2 的价值:
这是各基础设施与 K2 协同价值的对比表:
|
项目 |
类型 |
对 K2 的价值 |
|---|---|---|
|
RLinf |
强化学习训练系统 |
用于训练更强的规划/浏览器任务能力 |
|
Mem-alpha |
记忆增强框架 |
可与 K2 结合形成长期记忆 Agent |
|
AgentDebug |
Agent 错误调试系统 |
用于分析 K2 的 toolchain 错误 |
|
UI-Genie |
GUI Agent 训练系统 |
可作为 K2 的 Agent 能力扩展实验场 |
这套组合已经隐约构成了一个国产 AI Agent Infra Stack。
个人观点:K2 的路线意义
我认为 K2 的意义不在模型本身,而在于其技术路线:
K2 标志着国产模型第一次从“语言生成竞争”,进入“思维能力竞争”。
过去三年,中国开源模型的主线是评测得分、参数规模、指令跟随、对齐数据。但 K2 是第一个明确走上深度推理、工具交织、认知分工、长期任务链、原生性能优化的路线。这代表中国模型路线开始与美国同步,而不是追赶旧路线。
未来一年值得关注的 K2 生态发展方向
K2 未来生态影响力将取决于以下几个关键点:
• 是否开放工具注册表(Tool Registry, Tool Registry)
• 是否支持动态记忆(Mem-alpha 融合)
• 是否开放 MoE 专家结构
• 是否能与 vLLM / llm-d / KServe 形成国产推理链优化路线
• 是否有针对多节点的连续推理链容错
这些能力将决定 K2 的生态影响力和技术扩展性。
K2 思维路线架构图
下方流程图展示了 K2 思维模型的核心架构及其与外部 Agent/应用的协同关系:
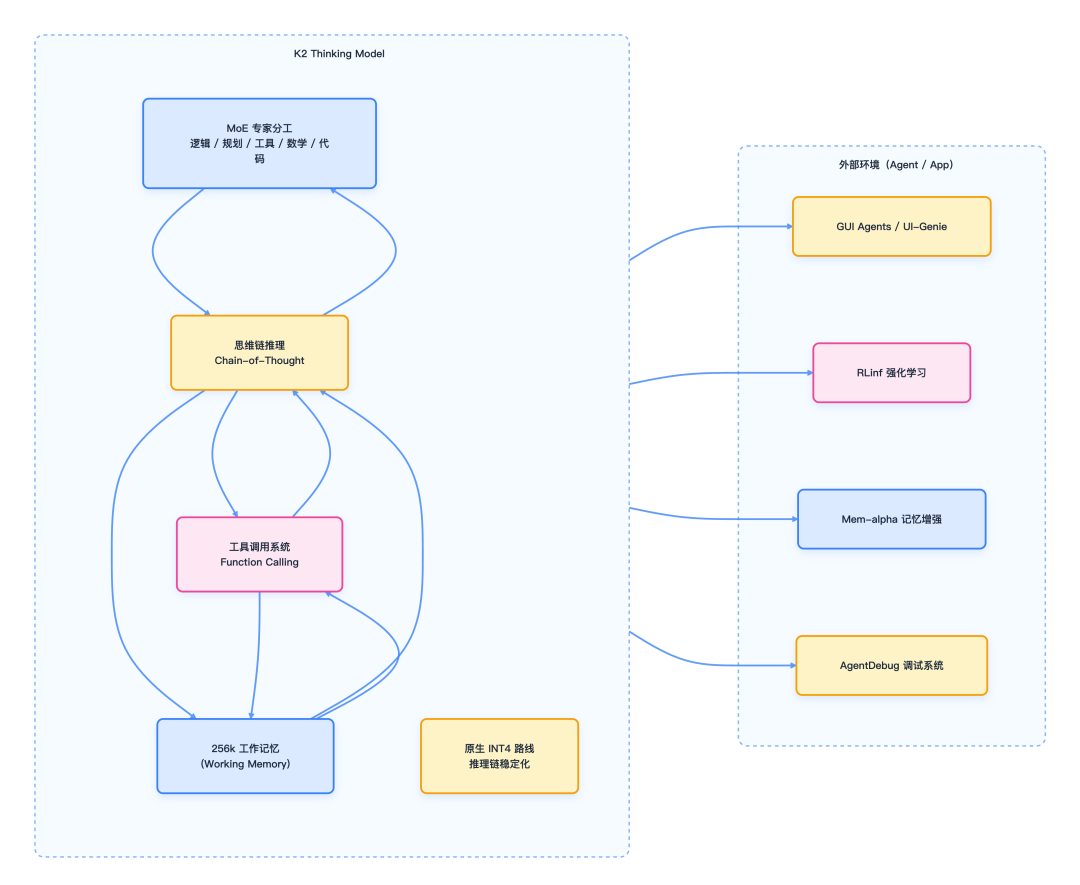
K2 思维路线架构图
结语
K2 是国产模型路线第一次走在正确方向:
从“写得像人”到“想得像人”。
思维型模型时代正在到来,国产模型首次站在了国际前沿的同一条路线图上。
参考文献
如有外部链接或引用的研究论文、技术文档等,请在此处列出。
更多精彩内容
🌐 个人网站:jimmysong.io
🎥 Bilibili:space.bilibili.com/31004924
如果这篇文章对你有帮助,欢迎点赞、分享给更多朋友!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)