CapArena: Benchmarking and Analyzing Detailed Image Captioning in the LLM Era
本文研究了视觉语言模型(VLM)在图像字幕生成中的表现与评估方法。通过构建CapArena平台(含6000+人工标注)评估14种VLM在精确性、信息性和抗幻觉方面的表现,发现现有模型与人类水平仍有差距。同时系统分析了传统与新型评估指标与人类偏好的相关性,并提出自动化基准CapArena-Auto(600样本),采用成对对战评估范式以提高可靠性。研究为提升VLM生成详细字幕能力提供了新的评估框架和基
研究方向:Image Captioning
1.论文介绍
本文首先提出两个问题:
(1)现有VLMs在详细字幕方面的表现如何?顶尖模型是否达到了人类水平的性能,它们之间又如何相互比较?
(2)如何开发能够可靠衡量详细字幕质量并与人类偏好一致的自动化评估方法?
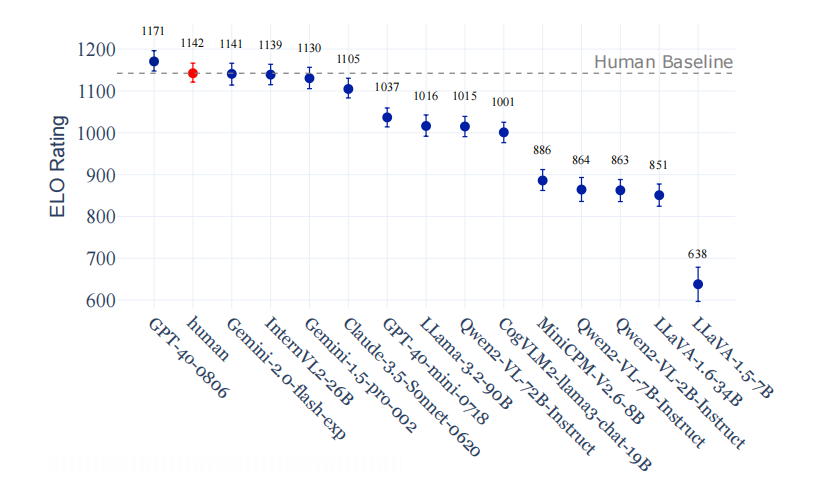
针对第一个问题,本文开发了CapArena,其中包含超过6000条高质量人工注释,用以评估14种先进视觉语言模型(VLM)和人类在详细字幕生成方面的能力。结果如下图:
对第二个问题,对传统和最近字幕评价指标进行了全面分析,以及作为裁判的视觉语言模型(VLM)评估字幕质量的能力,将这些指标与CapArena的人类偏好进行了比较。

最后,鉴于这些发现,发布了CapArena-Auto,一个用于详细标题的自动化基准测试。它包含600个样本,并创新性地采用成对对战范式以提高评估可靠性。
2.方法介绍
2.1 评估方案
指导方针主要从精确性和信息性的角度评估描述的质量。
精确性:精确性衡量描述内容的准确性,即描述是否与图片中的细节一致。例如,在表1的第一个案例中,Qwen2-VL对猫的姿态描述不准确,而人类描述捕捉到了猫扑向狗的关键动作。精确性包括多个方面,如物体、属性、关系和位置。
信息性:信息性评估图像中的关键信息有多少被描述全面覆盖,包括显著的对象和重要细节。例如,在表1的第二个案例中,Llama-3.2对一个女人的描述是精确的;然而,与GPT-4o对一个精神人物的描述相比,其信息性明显较低。
幻觉:幻觉是视觉语言模型(VLMs)中的一个棘手缺陷,模型生成图像中不存在的对象。指导注释者对幻觉进行严格处罚,因为它们损害了标题质量。
2.2 CapArena:成对对战平台
通过匿名成对对战来衡量VLM在详细字幕方面性能的注释平台。该平台涵盖多种多样的图像场景,并通过人类注释者的投票评估一系列成熟的视觉语言模型,提供模型间的可靠排名。
数据来源:DOCCI数据集,其中包括各种现实生活场景的高分辨率图像。数据集中的每张图片都配有一对精心制作的长篇、人工注释的描述,这些描述被用作平台的人类基线。
prompt

设置不同prompt生成的标题

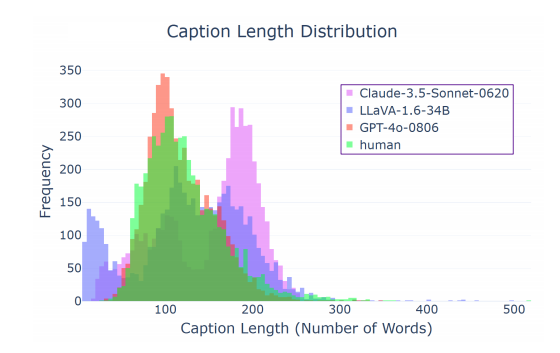
不同模型生成的标题分布长度图
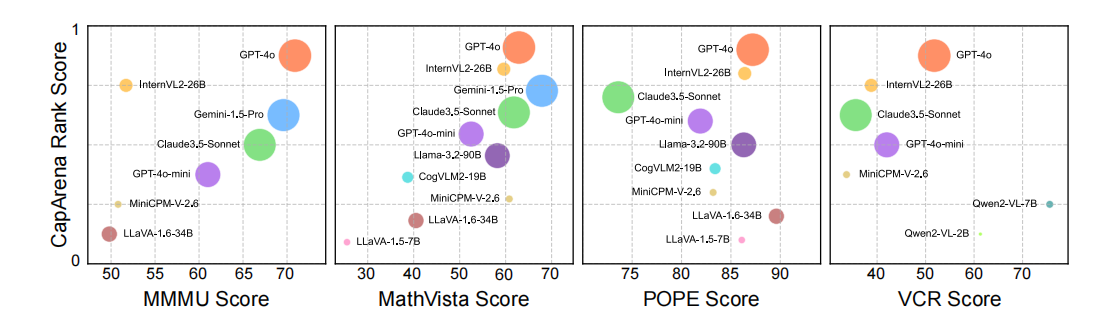
视觉语言基准测试中的模型表现与CapArena排名之间的相关性
2.3 CapArena-Auto:详细字幕的自动化基准测试
采用了DOCCI的图像特征聚类方法,从149个簇中均匀采样了600个样本。此外,还应用了基于CLIP特征的过滤来移除过于相似的样本,以确保最终选择的质量。
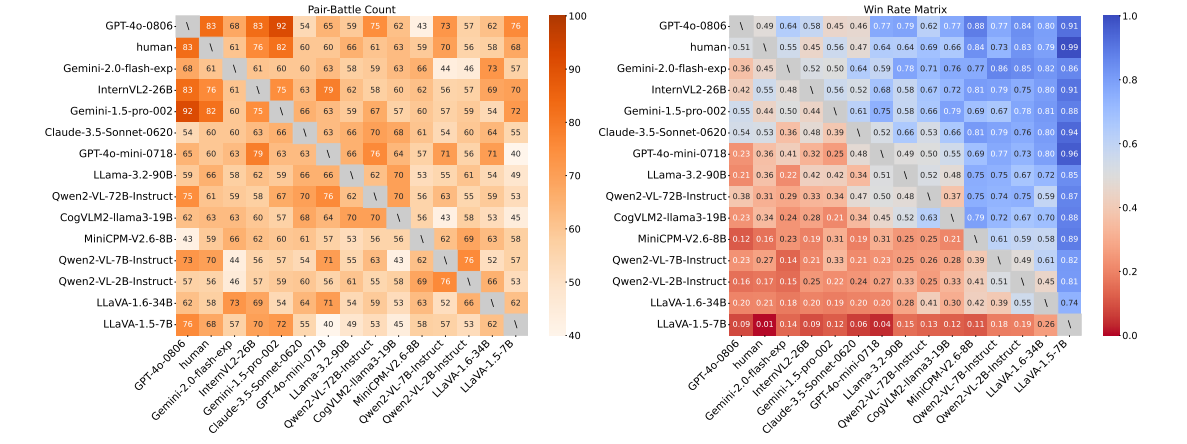
采用成对对抗范式,并使用VLM(GPT-4o)作为裁判进行比较,测试模型和基线模型的标题,以确定哪一个更好。模型在CapArena-Auto中的得分是其600个测试样本得分的总和。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)