基于语音功率的说话人定位
本文提出一种在噪声环境下鲁棒的说话人定位方法,通过结合SRP-PHAT与语音活动检测,计算导向响应语音功率(SRVP),有效区分语音与噪声。实验表明,该方法在低信噪比下显著优于传统SRP-PHAT,适用于智能设备的语音交互系统。
基于波束成形语音功率的噪声环境下的说话人定位
摘要
许多设备(包括智能电视和人形机器人)都可以通过语音接口进行操作。由于用户可以在一定距离外与这类设备交互,因此基于语音操作的设备必须能够处理远距离的语音信号。尽管目前已存在多种通过声源定位来实现说话人定位的方法,但在噪声环境中可靠地确定说话人位置仍然非常困难。特别是,传统声源定位方法仅能找出给定区域内最响亮的声源,而该声源未必与人类语音相关。在经常出现强噪声的真实环境中,这一局限性可能导致基于语音的接口性能显著下降。本文提出了一种新的说话人定位方法,该方法从所有候选位置中识别出与最大语音功率相对应的位置。所提出的方法在多种条件下利用仿真数据和实测数据进行了测试,结果表明,针对多种噪声类型,所提出的方法性能优于传统算法。
索引术语
声源定位,说话人定位,人机机器人接口。
一、引言
语音作为通信媒介具有多个优势,主要在于它是人类相互交流的基本接口,且不需要额外的设备。更重要的是,语音可以远距离传播,这使其在多种设备中尤为有用,包括人形机器人和智能电视,因为用户与设备之间通常存在一定的距离。
例如,基于语音的人机机器人接口可以提供一种自然的类人交互接口,无需使用遥控器等外部设备,用户可以在家中任何位置使用熟悉的语音命令来控制智能电视。为了正确实现此类语音接口,应包含处理远场语音信号的方法。与近距离检测到的语音信号不同,经过较长距离传播的语音信号通常会受到严重无关噪声的影响而退化和失真。解决这种远场语音问题的典型方法是使用麦克风阵列,既增强来自目标方向的语音信号,又抑制来自其他方向的噪声信号,从而提高语音信号的质量。
然而,在改善语音信号之前,必须先估计说话者位置。除了使用波束成形的语音增强外,说话者位置的信息还可用于实现高效且自然的交互接口。例如,当用户与人形机器人交互时,机器人可以利用用户的位置来转身面向他或她;智能门铃则可以调整其摄像头以聚焦访客的面部。对于大多数应用而言,说话者的相对位置是未知的,因此需要某种方法来确定说话者的位置。
声源定位(SSL)是一种用于确定说话者位置的方法,该方法不受光照条件影响,即使在黑暗环境中也能估计说话者位置。已有多种方法被提出用于声源定位,其中带相位变换滤波器的导向响应功率(SRP‐PHAT)通常被认为是在房间产生混响时最具鲁棒性的方法之一。然而,直接使用SRP‐PHAT已被证明会对现实生活中基于语音的应用性能产生负面影响。SRP‐PHAT通过控制麦克风阵列来确定最大输出功率的位置,波束形成器的输出功率通常测量为每对麦克风信号之间互相关值的总和。由于SRP‐PHAT仅利用输入信号的互相关值来估计给定位置处语音信号的功率,因此当噪声比说话人语音更响亮时,噪声源可能被判定为最大输出功率位置。也就是说,当无关噪声的导向能量更高时,传统SRP‐PHAT会指向噪声源方向,即使来自说话者位置的导向能量仍然较高。
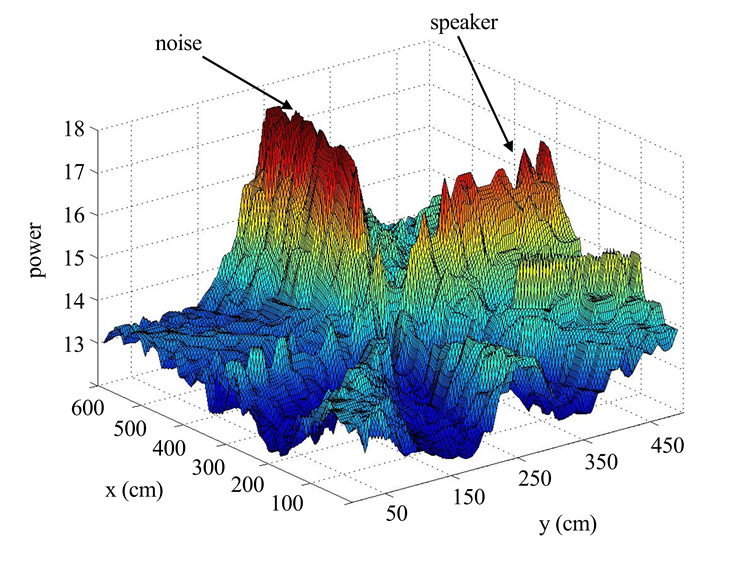
目标说话人,因为SRP‐PHAT会指向能量最高的点,而不考虑声音信号的特征或内容如何。
当使用SRP‐PHAT进行说话人定位时,必须考虑语音特征,以便为实际语音源分配更高的权重,而不是为强噪声源分配更高权重。语音活动检测(VAD)可用于区分人类语音与噪声,从而解决此类问题。本文提出了一种利用VAD的鲁棒说话人定位技术。所提出的方法使用SRP‐PHAT进行声源定位,并采用一种VAD方案,以考虑声音信号的内容而不仅仅是信号的导向响应功率。因此,该方法可计算候选说话人位置的导向响应语音功率(SRVP)。由于所提出的方法能够识别信号中的内容而不仅仅是信号的功率,因此即使在信噪比为0分贝(SNR)的情况下,也能有效定位语音源的位置。结果表明,基于语音的接口可以在存在频繁无关噪声的实际环境中,被有效地应用于各种移动设备。
本文其余部分组织如下。第二节分析了使用 SRP‐PHAT的传统SSL存在的问题,然后描述了一种通过采用SRP‐PHAT和VAD计算SRVP的说话人定位方法。所提出的方法在第三节中进行了评估。最后,第四节对全文进行总结。
II. 导向响应语音功率
A. 噪声环境下的SRP-PHAT
在频域中,聚焦于位置q的滤波求和波束形成器的输出 $Y_q(\omega)$ 定义如下:
$$
Y_q(\omega) = \sum_{m=1}^{M} G_m(\omega) X_m(\omega) e^{-j\omega\tau_{m,q}}
$$
其中M表示麦克风数量,$X_m(\omega)$ 和 $G_m(\omega)$ 分别是第m个麦克风信号及其对应滤波器的傅里叶变换,$\tau_{m,q}$ 是从位置q到第m个麦克风的直接传播时间。通过对麦克风信号应用滤波后,利用导向延迟进行相位对齐并求和得到输出。
基于SRP‐PHAT的声源定位算法计算麦克风阵列在位置q处聚焦时的输出功率 $P(q)$ 如下所示:
$$
P(q) = \int_{-\infty}^{\infty} \left| \sum_{l=1}^{M} \sum_{k=1}^{M} e^{-j\omega(\tau_{k,q}-\tau_{l,q})} X_l(\omega) X_k^*(\omega) \Psi_{lk}(\omega) \right|^2 d\omega
$$
其中 $\Psi_{lk}(\omega) = G_l(\omega)G_k^ (\omega) = 1 / |X_l(\omega)X_k^ (\omega)|$。在计算每个候选位置的导向响应功率 $P(q)$ 后,选择具有最大输出功率的点 $\hat{q}$ 作为声源的位置。
$$
\hat{q} = \arg\max_q P(q)
$$
尽管SRP‐PHAT是声源定位中最常用的技术之一,但在噪声环境中可能并不适用于说话人定位。图1展示了一个在许多现实场景中并不罕见的例子,其中噪声比语音更响亮。在这种情况下,SRP‐PHAT无法区分语音和噪声,仅计算输入信号的输出功率,因此如果噪声功率更大,则会识别出噪声的位置而非语音的位置。应注意的是,在图1中仍可观察到目标说话人位置具有较高的能量,但不希望的噪声具有更高的导向能量。
B. 导向响应语音功率
一种可用于解决此类问题的方法是将VAD值作为 SRP‐PHAT能量图的权重。由于VAD值在语音信号上较高,而在噪声信号上较低,该方法能有效增强语音信号的峰值,同时抑制噪声信号的峰值。然而,SRP‐PHAT算法本身已经需要大量的计算,若对每个候选位置都计算VAD值,将显著增加计算负载。本节提出一种鲁棒说话人定位方法,能够在仅增加少量计算成本的情况下区分语音源和噪声源的位置。
所提出的方法找到与最大语音相似度相关的点,而不是最大SRP‐PHAT的输出功率。它提取n个最佳候选位置,并对这些候选位置应用VAD算法,以确定语音相似度最高的位置。
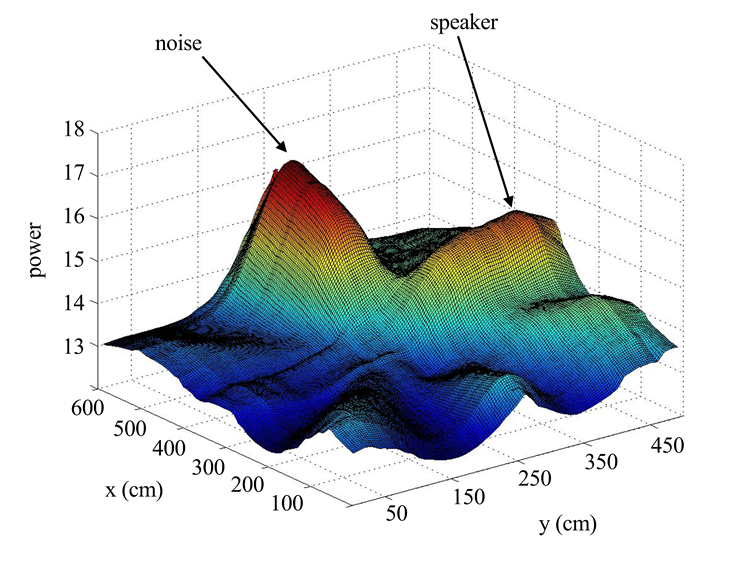
图2展示了所提出的方法的步骤。第一步,应用常规的SRP‐PHAT算法计算每个候选位置的导向响应功率。然后检测出最优的n个候选位置用于后续计算。采用一种带有移动平均的简单平滑方法,以减小围绕主峰值的锯齿状峰值的影响。能量图中每个位置的输出功率值被其邻域内输出功率值的平均值替代。平均输出功率P定义如下:
$$
P’(q_{a,e}) = \frac{1}{(2\theta+1)^2} \sum_{e’=-\theta}^{\theta} \sum_{a’=-\theta}^{\theta} P(q_{a+a’,e+e’})
$$
其中 $q_{a,e}$ 是一个方位角为 $a$、仰角为 $e$ 的点,$\theta$ 是所考虑的邻居数量。图3 显示了使用(4)平滑后的能量图。这种简单的平滑方案通过去除主峰值周围的锯齿状峰值,有效帮助识别多个声源。
 进行了平滑处理。)
进行了平滑处理。)
在第二步中,通过使用自适应波束成形方法,麦克风阵列聚焦于选定的n个最佳候选位置。一个自适应波束形成器,例如广义旁瓣消除器(GSC),会增强来自目标位置的信号,同时减弱来自其他位置的信号。
在第三步中,评估波束形成信号的语音相似度。由于所提出的方法针对语音和背景噪声同时被采集的情况,因此VAD算法的有效性至关重要,在混合信号条件下可靠地工作。如果语音活动检测(VAD)算法利用元音声音,则可在这些条件下良好运行。人类的元音声音具有共振峰,这些是明显的谱峰,即使在噪声造成严重干扰后仍可能保留。然而,由噪声干扰引起的非相关谱峰是在嘈杂环境中利用这些谱峰的主要障碍。直接计算预训练谱峰模板可有效避免非相关谱峰带来的问题。这使得即使存在同时出现的噪声,也能检测到语音信号的存在。因此,利用人类元音特有的谱峰来计算语音相似度,并使用多个说话人的训练数据提取特征谱峰。该算法在识别过程中不提取谱峰,而是直接计算输入频谱与预训练谱峰特征之间的相似性。其主要思想是:如果存在一个谱峰,则该峰所在频带的平均能量将远高于其他频带的平均能量,即峰谷差(PVD)会更高。
谱峰的位置在训练期间获得,并存储为二进制峰特征,其中谱峰频带对应值为‘1’,其余频带对应值为‘0’。在训练过程中,可以对相似的谱峰特征进行聚类以降低计算开销。然后将峰谷差(PVD)用作语音相似度的度量。给定的二进制谱峰特征S与波束成形后的输入频谱 $Y_q$ 之间的相似度可按如下方式计算:
$$
\text{PVD}(Y_q, S) = \frac{\sum_{k=0}^{N-1} S[k] \cdot Y_q[k]}{\sum_{k=0}^{N-1} S[k]} - \frac{\sum_{k=0}^{N-1} (1-S[k]) \cdot Y_q[k]}{\sum_{k=0}^{N-1} (1-S[k])}
$$
其中N是频谱的维度。对每个已注册的谱峰特征进行相似性度量,并将得到的最大值确定为位置q的谱峰能量,如下所示:
$$
\text{PVD}(Y_q) = \max_S \text{PVD}(Y_q, S)
$$
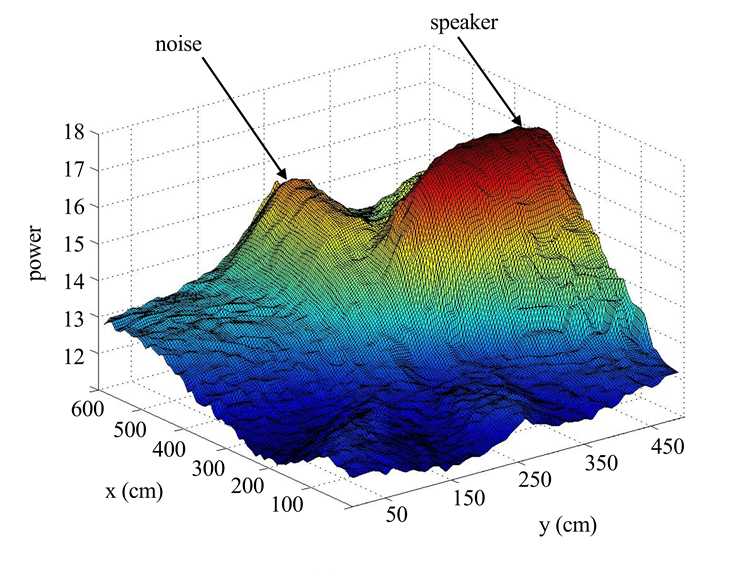
 式与图3所示结果结合得到的导向响应语音功率能量图。在该图中,PVD值被应用于所有点以进行图形化展示。在实际算法中,PVD值仅应用于n个最佳候选位置。)
式与图3所示结果结合得到的导向响应语音功率能量图。在该图中,PVD值被应用于所有点以进行图形化展示。在实际算法中,PVD值仅应用于n个最佳候选位置。)
III. 实验
A. 仿真数据实验
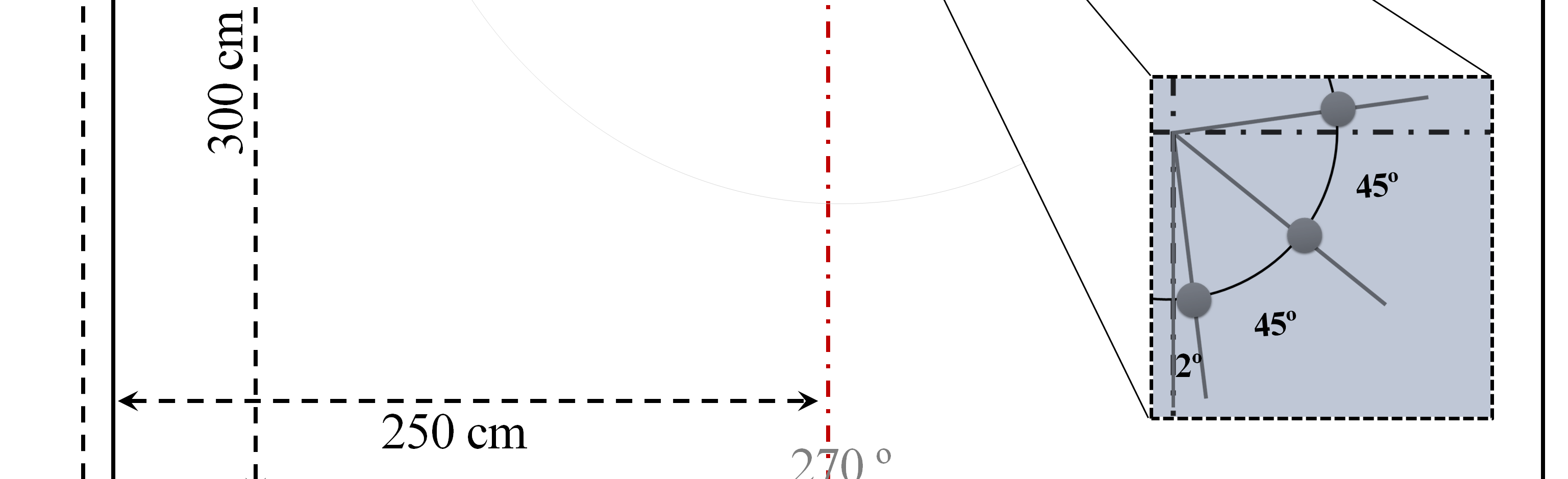
为了分析所提出的方法在不同噪声环境下的性能,使用镜像方法生成了带噪语音数据。本文采用了一个半径为25厘米、包含八个传感器的圆形麦克风阵列。所提出的方法基于SRP‐PHAT,因此该算法也可用于其他多种麦克风阵列配置。麦克风在圆形阵列上等间距布置。
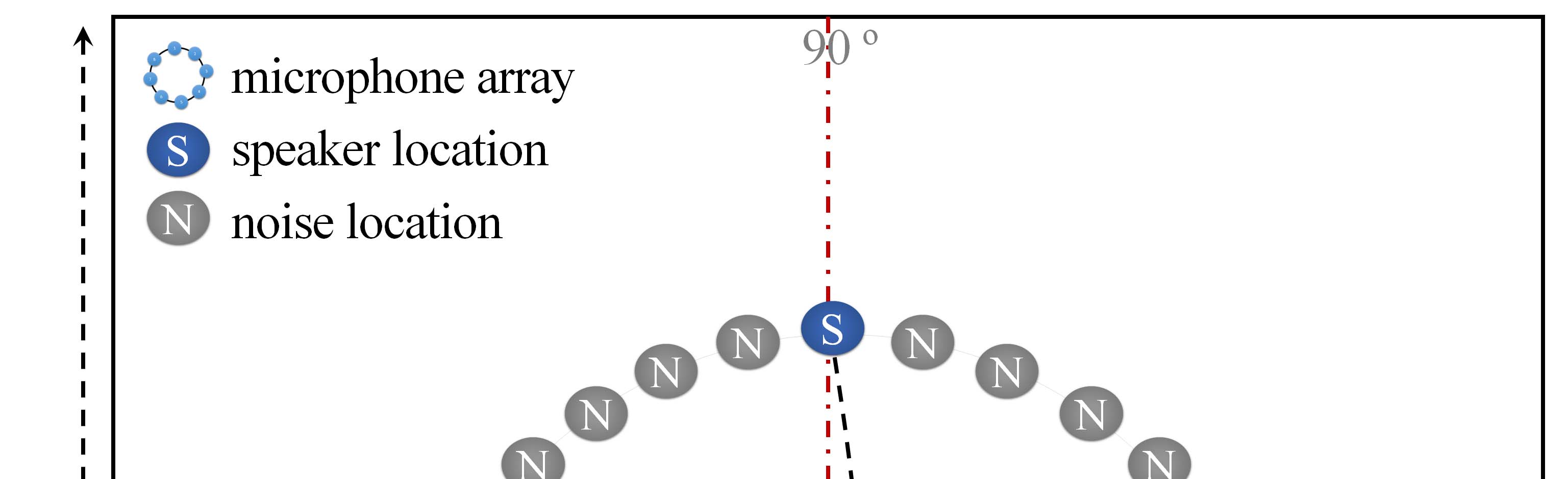
该阵列位于尺寸为600厘米 × 500厘米 × 240厘米的房间内的 (250厘米, 300厘米, 80厘米)处,语音源位于房间内的 (250厘米, 500厘米, 80厘米)处。噪声源以相同距离放置,角度从0到180度以10度间隔变化(除90度外),共形成18个不同位置。图5展示了此配置。
所使用的噪声类型包括汽车、工厂、通道、音乐、地铁、火车、白噪声和粉红噪声。采样率为16千赫,帧长为128毫秒。性能以估计的说话人位置中位于真实语音源位置± 5度范围内的百分比来衡量。
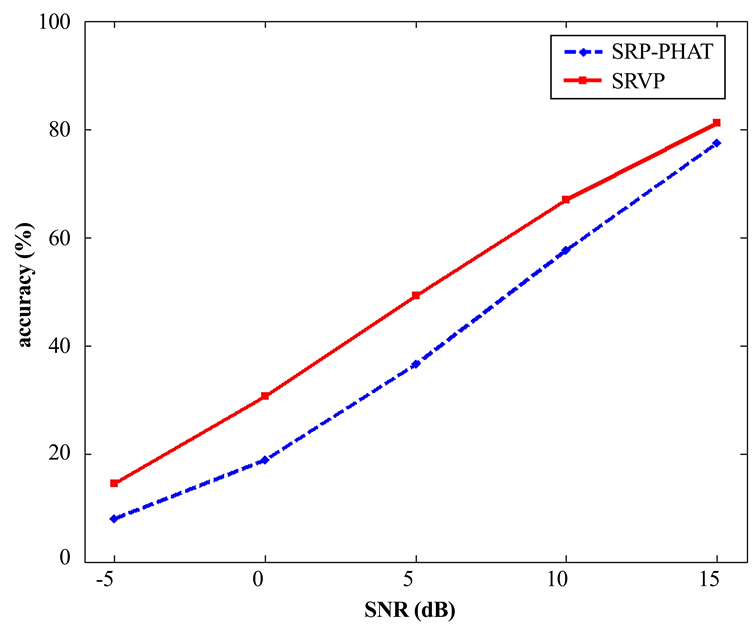
在五种不同的信噪比水平(‐5、0、5、10和15分贝)下分析了说话人定位的性能。图6显示,与SRP‐PHAT相比,所提出的方法在不同信噪比水平下始终表现出更好的性能。在0分贝信噪比条件下,传统SRP‐PHAT在说话人定位上的准确率仅为18.8%,而所提出的方法达到了30.6%的准确率(绝对误差降低11.8%)。当信噪比为5分贝时,所提出的方法实现了49.2%的说话人定位准确率。与传统SRP‐PHAT相比,所提出的方法平均实现了12.6%的绝对误差降低。

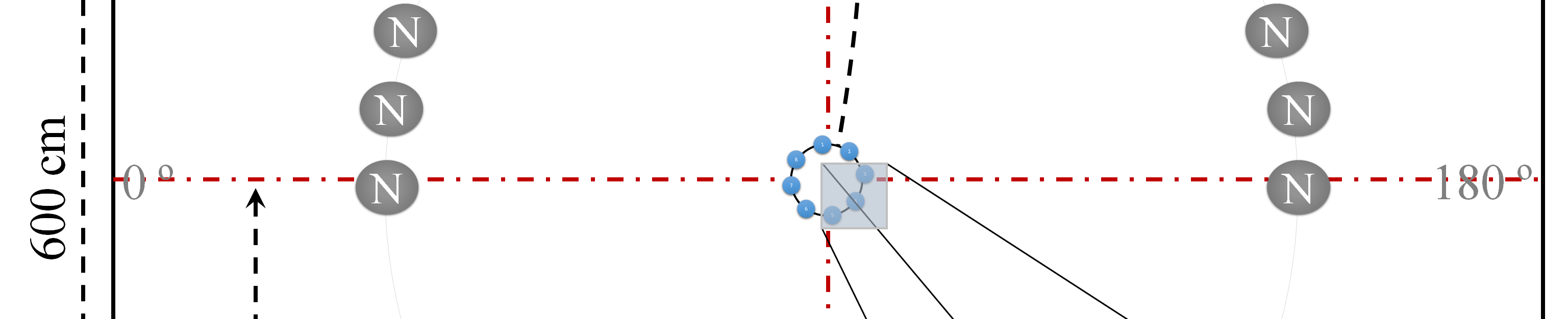
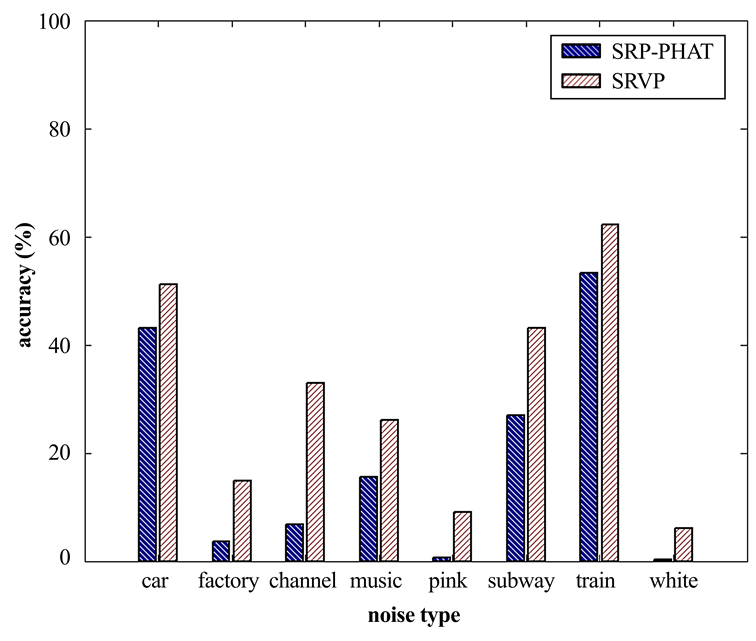
图7展示了在0分贝下,SRP‐PHAT和所提出的方法在多种噪声类型下的定位性能。可以看出,对于所有类型的噪声,所提出的方法均表现出比SRP‐PHAT更好的性能。在存在宽带噪声(如白噪声)的环境中,SRP‐PHAT的准确率严重下降。这可以归因于SRP‐PHAT仅利用所有频带的相位信息来计算输出功率。性能上的大部分提升来自于工厂、通道、音乐、地铁、白噪声和粉红噪声环境。对于汽车和火车噪声环境,相较于上述其他噪声,改进相对较小。这可能是因为汽车和火车噪声的一些峰值特征与某些元音声音的峰值特征非常相似。如果是这样,一些低能量噪声被增强,导致更高的SRVP。
图8展示了在不同噪声位置下的说话人定位性能。由于圆形阵列略有旋转,结果在90度附近并不对称。可以看出,所提出的方法的整体性能相比SRP‐PHAT算法有所提升。随着语音与噪声位置之间角度的增大,性能增益也随之增加。在80至100度之间SRP‐PHAT性能相对较高的原因是,噪声信号与语音信号距离过近,导致来自噪声信号的 SRP‐PHAT旁瓣也影响了语音信号的导向能量。

B. 实测数据实验
通过使用图9所示的机器人原型采集的实际声音数据,验证了所提出的方法在实际使用中的性能。麦克风的配置、房间尺寸以及麦克风阵列的位置与仿真数据实验中的相同。需要强调的是,如仿真数据实验中所述,所提出的方法不限制麦克风阵列必须为圆形配置。噪声源放置在距离200厘米处的0、30和60度位置。实验采用了八种噪声类型和五个信噪比等级,与仿真数据实验一致。
图10总结了SRP‐PHAT和所提出的方法在实测数据上五种不同信噪比水平下的性能。所示结果与图6中的仿真数据结果相似。在0dB 信噪比条件下,SRP‐PHAT的定位精度为23.7%,而所提出的方法的准确率为42.9%,绝对误差率降低了19.2%。在5 dB 信噪比条件下也获得了类似的结果,绝对误差率降低了22.9%。
图11总结了在实测数据上针对多种噪声类型的性能表现。结果与仿真数据类似,在工厂、通道、音乐、地铁、白噪声和粉红噪声情况下性能提升较大,而在火车噪声情况下性能提升较小。

IV. 结论
本文提出了一种鲁棒说话人定位方法,该方法利用输入信号的语音相似度,而非波束形成器简单的输出功率。所提出的方法使用SRP‐PHAT来寻找若干候选位置,然后利用广义旁瓣相消器(GSC)对来自前n个候选位置的信号进行增强。计算增强信号的语音相似度,并将其与导向响应功率相结合。最终输出被解释为导向响应语音功率(SRVP),并将最大SRVP位置选为说话人位置。由于仅对前n个最佳候选位置进行广义旁瓣相消器(GSC)和语音相似性度量,因此计算成本相对较低。实验结果表明,在噪声信号能量等于或高于语音信号的极低信噪比条件下,所提出的方法显著优于传统声源定位方法SRP‐PHAT。与传统SRP‐PHAT方法相比,在包含多种噪声的实测数据环境中,所提出的方法平均实现了19.3%的绝对定位误差降低。
所提出的方法可用于真实环境中同时存在语音和噪声的基于口语的交互接口。声源定位准确率的提高使得用户与各种设备之间能够实现基于位置的交互。例如,智能门铃系统的摄像头可以被引导转向。该方法还可用于提高基于语音的接口的准确性。语音的自然性和远距离特性可为包括智能电视和人形机器人在内的各种设备提供有用的交互接口。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)