文献阅读(3)——CLIP(动作感知增强(动作三元组+动作状态提示)+LLM外部知识)——看的时候产生的一些想法——(3)
提示融合模块就像一个信息枢纽和翻译官。它接收来自“动作三联提示”的语义剧本和来自“动作状态提示”的视觉分镜图,然后通过上述某种或多种复杂的计算(如拼接、注意力、门控),将它们“编译”成一种CLIP图像编码器能够理解的、统一的多模态提示。这种融合后的提示不仅告诉编码器“要看什么”(厨师切西红柿),还暗示了“怎么看”(关注手和刀的特定运动模式),从而引导CLIP的图像编码
文章目录
二 :额外的拓展(看的时候产生的想法)
1:三种主流的融合策略:
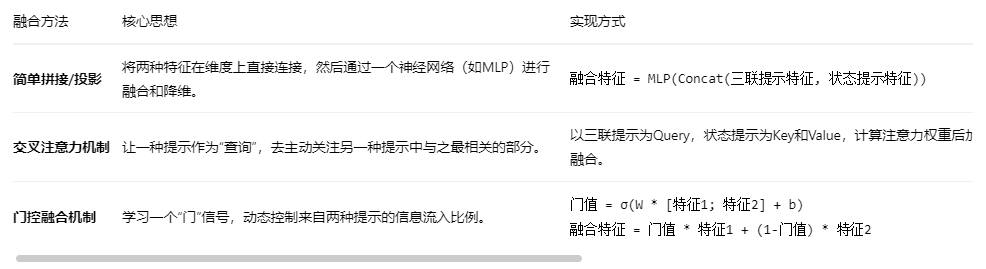

1:融合技术详解
1:特征拼接与联合投影

2:交叉注意力机制

3: 门控融合机制

2:总结
提示融合模块就像一个信息枢纽和翻译官。它接收来自“动作三联提示”的语义剧本和来自“动作状态提示”的视觉分镜图,然后通过上述某种或多种复杂的计算(如拼接、注意力、门控),将它们“编译”成一种CLIP图像编码器能够理解的、统一的多模态提示。
这种融合后的提示不仅告诉编码器“要看什么”(厨师切西红柿),还暗示了“怎么看”(关注手和刀的特定运动模式),从而引导CLIP的图像编码器学习到同时包含物体语义和动作动态的、增强的视觉表示,最终在下游任务(如动作分类/检索)中表现更出色。
2:将提示“视觉化”
核心思想是:无论提示的来源是文本还是其他模态,最终都需要被嵌入到与图像特征相容的向量空间中,并以某种方式“呈现”给图像编码器。 主要有三种技术路径:
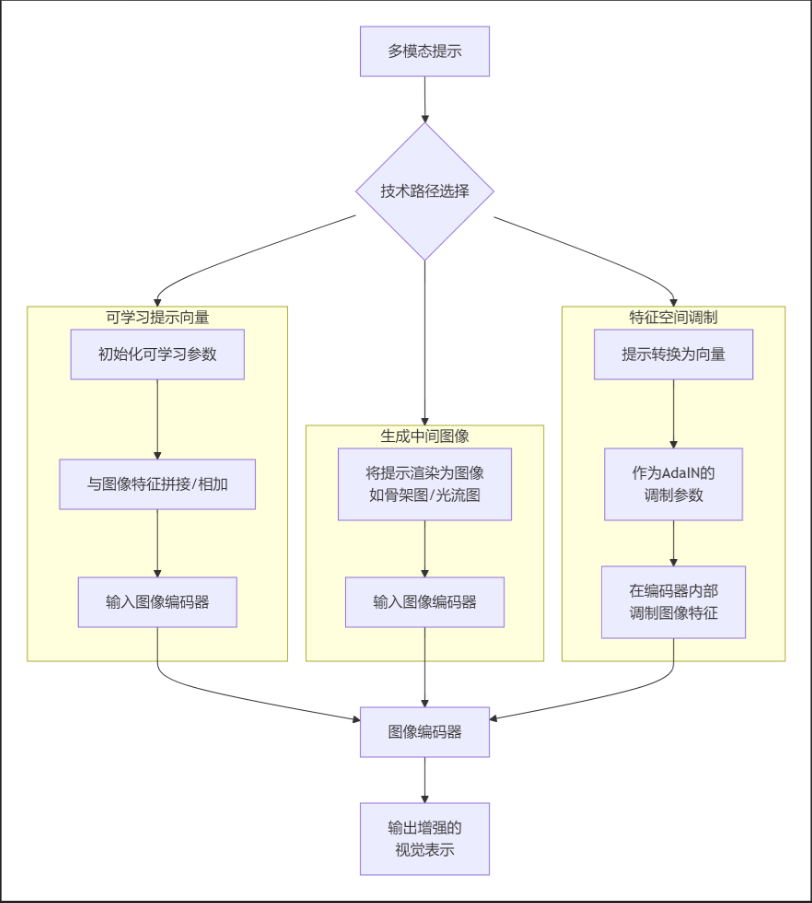
下面,我们来详细解读这三种路径。
1:路径一:可学习提示向量(最主流、最优雅的方法)——提示适配器
这是目前最常用且高效的方法,尤其是在提示调优(Prompt Tuning)领域。

2:路径二:生成中间视觉表征(更直观的方法)

3:路径三:特征空间调制(更底层的影响方式)

2:总结
所以,回到您的核心问题:这个多模态提示是如何输入到CLIP图像编码器的?
答案:它不是以原始文本或符号形式直接输入的。而是通过上述的一种或多种技术,被转换成了图像编码器能够处理的“视觉语言”——要么是可学习的参数向量与图像特征结合,要么被渲染成中间图像,要么作为调制信号从内部影响编码过程。
这种方式打破了“图像编码器只能吃像素”的界限,通过提示工程,将先验知识(动作三联)和动态信息(动作状态)注入模型,从而“教会”CLIP的图像编码器不仅仅看“是什么”,还能理解“在做什么”以及“如何做”,最终获得强大的动作理解能力。
17:这张图展示了一个两阶段训练框架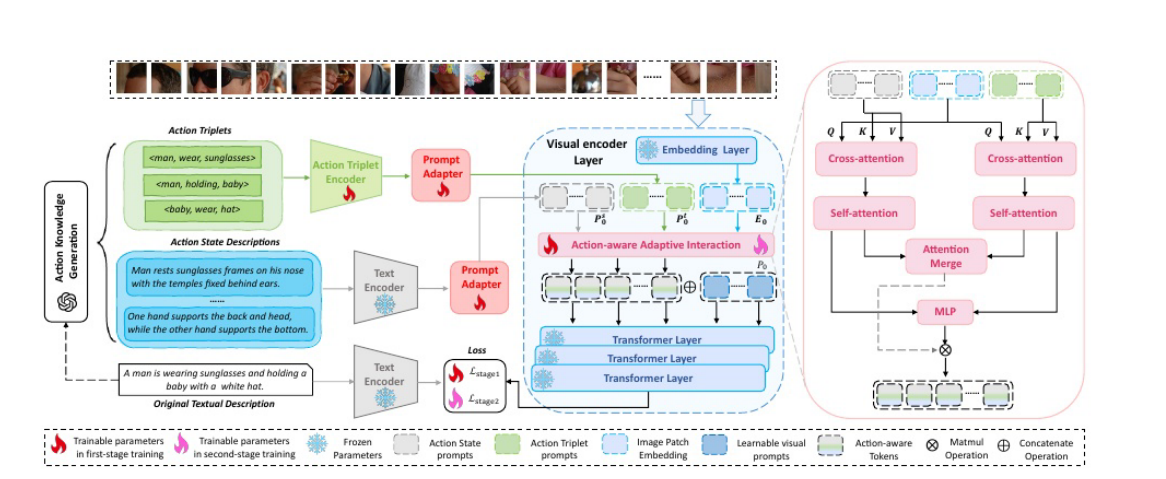
旨在通过引入动作先验知识来增强像CLIP这样的视觉-语言模型的动作理解能力。整个流程的核心是利用动作知识生成提示,并通过“提示适配器”和“动作感知的自适应交互”机制来调制模型的视觉和文本表示。
问题1——在Action - aware Adaptive interaction内加入Learnable visual prompts 和在Action-aware Adaptive interactio之后,输出的 Action-aware Token与Learnable visual prompts做Concatenate operation有什么区别?
在 Action - aware Adaptive interaction(动作感知自适应交互)内加入 Learnable visual prompts(可学习视觉提示),与在 Action - aware Adaptive interaction 之后,让输出的 Action - aware Token(动作感知标记)与 Learnable visual prompts 做 Concatenate operation(拼接操作),这两种方式在信息处理流程、对模型影响等方面存在明显区别:
1:信息融合时机与方式
1:在交互内加入
在交互内加入:Learnable visual prompts 在 Action - aware Adaptive interaction 模块内部,与图像块嵌入、动作状态提示、动作三元组提示等信息一同参与自注意力、交叉注意力等计算。这意味着它从一开始就深度介入动作知识与视觉信息的交互融合过程,与其他信息的融合更加紧密和直接。例如,在计算注意力权重时,Learnable visual prompts 可以直接影响图像块之间以及图像块与动作知识提示之间的关联程度,从而在早期就引导信息融合的方向,使得最终生成的 Action - aware Token 从源头上就带有 Learnable visual prompts 的引导信息。
2:在交互后拼接
在交互后拼接:Learnable visual prompts 不参与 Action - aware Adaptive interaction 模块内的注意力计算等交互过程,而是在该模块完成对图像块嵌入、动作知识提示等信息的交互融合,输出 Action - aware Token 之后,才与 Action - aware Token 进行拼接。这种方式下,Learnable visual prompts 相当于是对已经生成的 Action - aware Token 进行补充和扩展,是在动作知识与视觉信息初步融合完成后,额外添加的信息增强步骤。
2:对特征表示的影响
1:在交互内加入
在交互内加入:生成的 Action - aware Token 会更加紧密地整合 Learnable visual prompts 的信息,其特征表示是在 Learnable visual prompts 参与下,多模态信息深度融合的结果。这可能会使 Action - aware Token 在早期就具备更符合任务需求的特征偏向,比如在捕捉与动作相关的视觉细节上更加精准。但同时,如果 Learnable visual prompts 初始参数设置不合理,也可能对正常的多模态信息融合产生较大干扰,影响最终特征表示的准确性。
2:在交互后拼接
在交互后拼接:Action - aware Token 在交互模块内生成时,不受 Learnable visual prompts 的直接干扰,保持了相对独立的多模态信息融合结果。拼接 Learnable visual prompts 后,特征表示会在原有基础上进行拓展,增加了额外的可学习维度,为后续 Transformer 层等处理提供了更多的信息。这种方式相对更加灵活,即使 Learnable visual prompts 初始状态不佳,也不会对前期多模态信息融合产生根本性影响,而且可以通过后续处理对 Learnable visual prompts 的信息进行调整和优化。
3:对模型训练和优化的影响
1:在交互内加入
在交互内加入:模型在训练时,需要同时优化 Learnable visual prompts 与多模态信息交互融合的过程,训练复杂度相对较高。因为 Learnable visual prompts 的参数调整不仅要考虑自身的优化方向,还要与多模态信息交互过程中的各种参数协同优化,增加了训练的难度和计算量。但如果训练得当,模型可能会更快地收敛到较好的状态,因为 Learnable visual prompts 从一开始就参与塑造特征表示。
2:在交互后拼接
在交互后拼接:训练时可以先专注于 Action - aware Adaptive interaction 模块内多模态信息融合相关参数的优化,之后再单独对 Learnable visual prompts 的参数进行调整。这种分步优化的方式降低了训练的复杂性,使训练过程更加清晰和可控。不过,模型可能需要更多的训练轮次来充分挖掘 Learnable visual prompts 添加后对模型性能提升的潜力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)