关于《Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Surve》
解决新用户 / 物品的公平性:避免依赖历史数据导致的偏见,让新内容获得曝光。提升平台价值:新用户首屏精准推荐可提升留存,新物品快速冷启动可增强平台活力。支撑规模化增长:适配用户 / 物品指数级增长,维持推荐系统动态相关性。通用定义:训练集包含有交互的 “暖用户 / 物品”,测试集包含无 / 少交互的 “冷用户 / 物品”,需预测冷实体的交互行为。
·
文章首次系统整合了内容特征、图关系、领域信息、LLM 世界知识四大知识来源的冷启动推荐方法,明确了 9 类冷启动任务,梳理了技术演进脉络,并指出了多模态、基础模型等未来关键方向。
一、核心背景与问题定义
1. 冷启动推荐的重要性
- 解决新用户 / 物品的公平性:避免依赖历史数据导致的偏见,让新内容获得曝光。
- 提升平台价值:新用户首屏精准推荐可提升留存,新物品快速冷启动可增强平台活力。
- 支撑规模化增长:适配用户 / 物品指数级增长,维持推荐系统动态相关性。
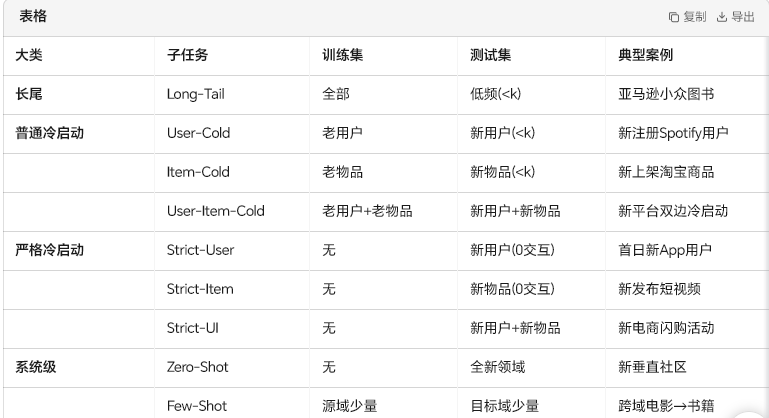
2. 明确的任务定义
- 通用定义:训练集包含有交互的 “暖用户 / 物品”,测试集包含无 / 少交互的 “冷用户 / 物品”,需预测冷实体的交互行为。
- 9 类具体任务(分 4 大类):
二、四大知识来源的技术路径
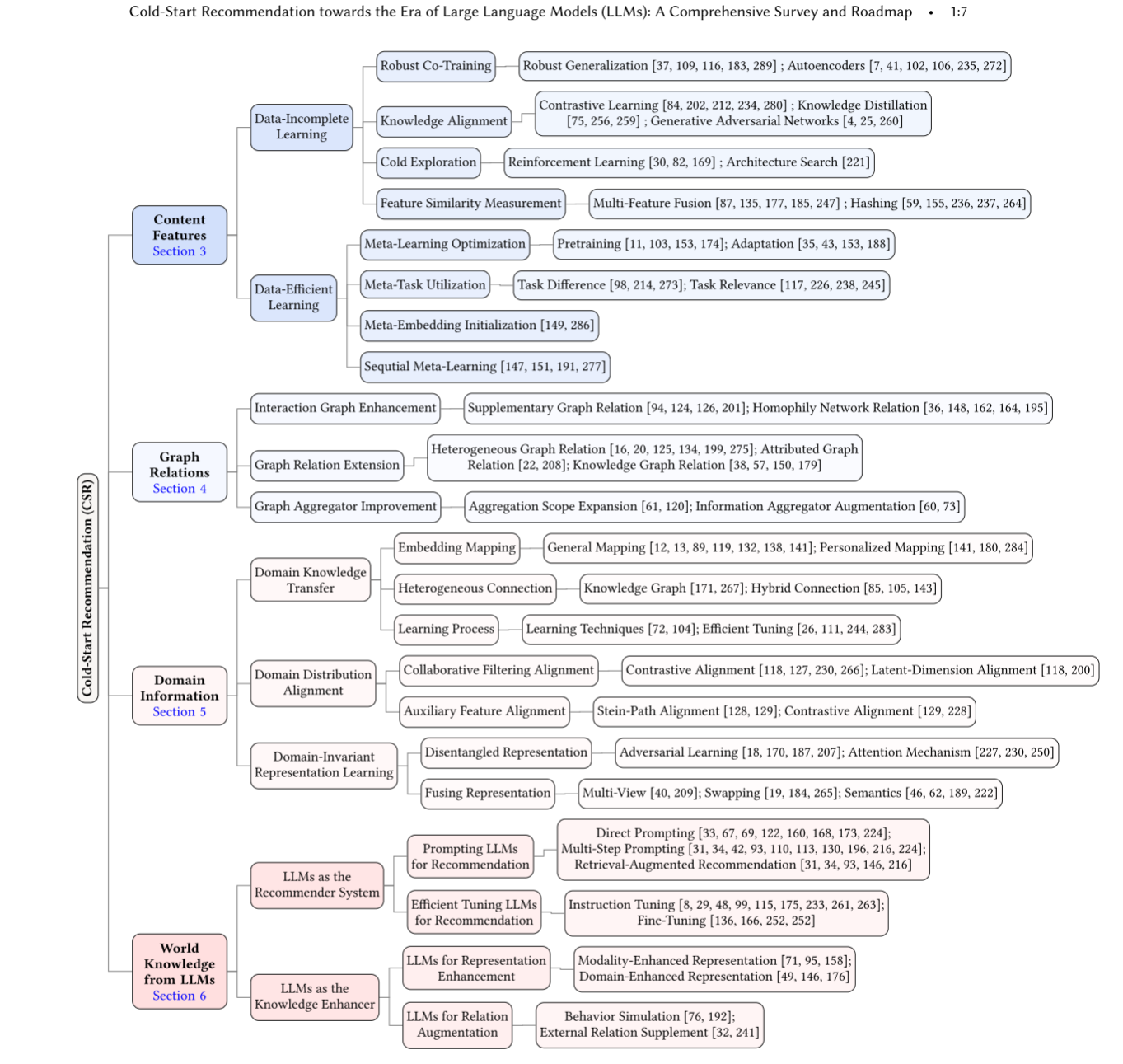




1. 基于内容特征的方法
核心思路:利用用户 / 物品自身的描述信息(如用户画像、物品标题)弥补交互数据缺失,分两类场景:
(1)数据不完整学习(处理严格冷启动)
- 鲁棒协同训练:联合行为特征(暖实体)和内容特征(冷实体)训练,提升模型泛化性
- 例子:DropoutNet(随机将用户 - 物品偏好输入置零,迫使模型依赖内容信息重建相关性得分);Heater(随机输入协同表示或内容中间表示,混合训练暖 / 冷实体)。
- 知识对齐:缩小内容特征(冷)与行为特征(暖)的语义鸿沟
- 例子:ALDI(将预训练暖推荐模型作为 “老师”,从评分分布、排序、识别三个维度蒸馏知识给冷实体);GAR(用 GAN 让冷物品嵌入模仿暖物品嵌入分布)。
- 冷探索:通过 “试错” 挖掘冷实体兴趣
- 例子:MetaCRS(用强化学习开展探索性对话,快速识别冷用户偏好);WSCB(将用户冷启动转化为多臂老虎机问题,平衡探索与利用)。
- 特征相似度度量:直接基于内容特征计算用户 - 物品匹配度
- 例子:NeuHash-CF(将暖 / 冷实体映射到二进制哈希码,用汉明距离快速计算相似度);CIRec(融合协同、视觉、跨模态特征增强冷实体表示)。
(2)数据高效学习(处理普通冷启动)
- 核心技术:元学习(Meta-Learning),模拟少样本场景训练模型快速适应能力
- 例子:MeLU(用 MAML 算法预训练全局参数,冷用户仅需少量交互即可快速微调);Wen et al.(用课程学习给用户分配权重,缓解高难度用户对预测的偏见)。
2. 基于图关系的方法
核心思路:利用图结构的高阶关联信息(如用户 - 物品 - 属性关联),为冷实体补充 “间接交互”,分三类策略:
(1)交互图增强:为冷实体补充图边
- 例子:CGRC(对随机选择的物品执行掩码 - 重建操作,推断冷实体的潜在边);SDCRec(在用户 - 物品 - 属性图中定义 “回文路径”,挖掘用户间隐式好友关系)。
(2)图关系扩展:丰富图的节点 / 边类型
- 异构图关系:引入多类型节点 / 边(如用户、物品、社交关系)
- 例子:GIFT(构建包含物理链接和语义链接的异构图,实现暖视频到冷视频的信息传递)。
- 属性图关系:用实体属性构建图(如物品的细粒度属性)
- 例子:ColdGPT(用 LLM 从物品内容中提取属性,构建物品 - 属性图,学习冷物品表示)。
- 知识图关系:融合外部知识图(如物品类别、实体关联)
- 例子:MetaKG(设计两个元学习器,分别捕捉用户偏好和知识图实体知识,适配冷启动)。
(3)图聚合器改进:优化图信息聚合逻辑
- 例子:MeGNN(区分全局和局部邻域转换,让冷实体感知长距离关联节点);A-GAR(用自适应邻域聚合策略,增强对冷实体稀疏数据的建模能力)。
3. 基于领域信息的方法
核心思路:利用源领域(数据丰富)的知识,迁移到目标领域(冷启动场景),分三类方向:
(1)领域知识迁移:直接传递源领域信息
- 嵌入映射:将源领域嵌入空间映射到目标领域
- 例子:MAFT(用 MLP + 注意力机制,高效映射辅助特征空间);PTUPCDR(用元网络生成个性化映射参数,适配不同用户)。
- 异质连接:通过图结构连接多领域
- 例子:Jiang et al.(将社交网络建模为星型图,中心是社交领域,连接多个物品领域如帖子、视频)。
(2)领域分布对齐:缩小源 - 目标领域的分布差异
- 例子:DAUC(用对比对齐和对抗损失,缓解移动端 APP 使用与文章阅读领域的分布鸿沟);DisAlign(通过 Stein 路径迭代移动嵌入,让目标领域冷实体对齐源领域分布)。
(3)领域不变表示学习:学习跨领域通用特征
- 例子:RecSys-DAN(用对抗网络区分源 / 目标领域表示,迫使生成器产出领域无关特征);CATN(跨领域交换评论中的 Aspect 级偏好,如书籍→电影的 “剧情” 偏好,提取领域不变特征)。
4. 基于 LLM 世界知识的方法(最新技术方向)
核心思路:利用 LLM 的海量预训练知识和语义理解能力,直接建模或增强冷实体表示,分两大角色:
(1)LLM 作为推荐系统(直接完成推荐任务)
- 提示策略(Prompting):将推荐任务转化为自然语言任务
- 例子:Direct Prompting(用 GPT-3.5 直接完成零 - shot 评分预测、序列推荐);Multi-Step Prompting(GPT-3 分 3 步:捕捉用户偏好→选择代表性物品→生成推荐)。
- 模型调优(Tuning):让 LLM 适配推荐场景
- 例子:TALLRec(将推荐数据转化为 “用户历史→是否推荐该物品” 的自然语言指令,LLM 输出 “是 / 否”);NoteLLM(用生成式对比学习微调 LLM,融合协同信号)。
(2)LLM 作为知识增强器(辅助传统推荐模型)
- 表示增强:用 LLM 丰富冷实体的表示
- 例子:Kim et al.(基于 Transformer 的通用物品表示框架,自然融合多模态特征);SAID(用 LLM 学习与物品文本描述语义对齐的嵌入)。
- 关系增强:用 LLM 补充冷实体的关联信息
- 例子:ColdLLM(用 LLM 模拟器生成用户与冷物品的虚拟交互,将冷物品 “暖化”);CSRec(用 LLM 提取常识知识构建知识图,融合现有元数据知识图)。
三、挑战与未来方向
1. 多模态冷启动
- 现有问题:模态融合易引入噪声、部分模态缺失、用户对模态的敏感度差异未被考虑。
- 未来方向:开发鲁棒的模态融合方法、构建多模态丰富的数据集、个性化多模态嵌入技术。
2. 推荐基础模型
- 现有问题:LLM 需重复适配新任务 / 领域,计算开销大。
- 未来方向:设计统一的推荐基础模型,支持多任务、跨领域快速适配(如 P5 的扩展版)。
3. 效率问题
- 现有问题:LLM-based 方法训练 / 推理开销大,难以部署到工业级系统。
- 未来方向:轻量化模型设计、混合策略(LLM 负责高 - level 规划,传统模型负责实时推荐)。
4. 数据隐私
- 现有问题:冷启动依赖用户侧信息和跨领域数据,易引发隐私泄露。
- 未来方向:差分隐私、同态加密、联邦学习(如 FedCDR 的跨领域联邦推荐)。
5. 基准和统一评估
- 现有问题:数据集不统一、冷实体定义模糊、缺乏专用评估框架。
- 未来方向:发布高质量工业级冷启动数据集、制定统一的冷实体划分规则、开发开源评估代码库。
四、文章核心贡献
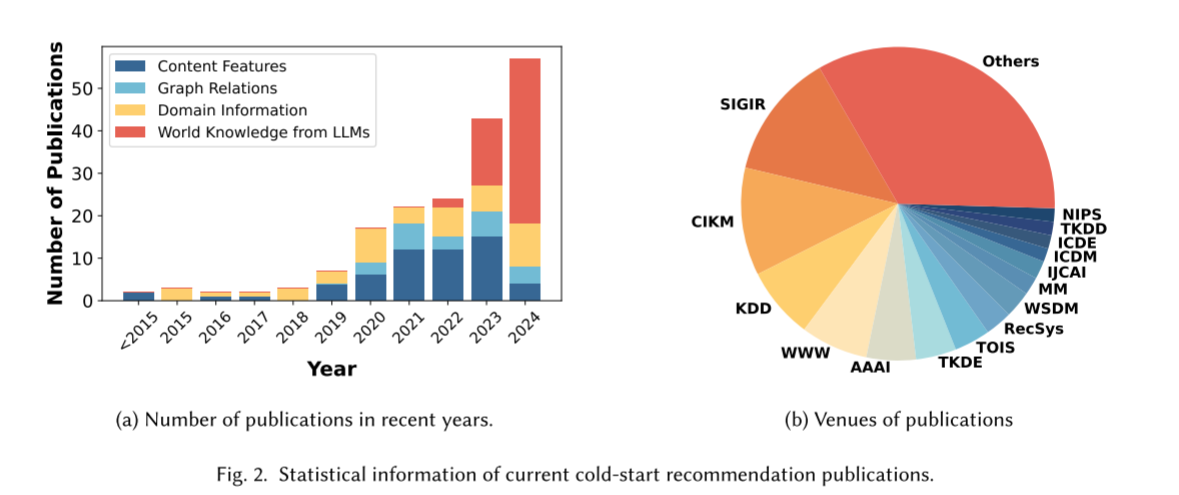
- 首个全面综述:覆盖四大知识来源,收录 220 篇截至 2024 年 12 月的研究,远超现有综述。
- 创新分类法:以 “外部知识来源” 为核心分类维度,清晰呈现技术演进逻辑。
- 明确问题定义:首次定义 9 类冷启动任务,提供统一的研究框架。
- 前瞻性路线图:聚焦 LLM 融合、多模态等前沿方向,为后续研究指明路径。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)