给具身智能装个“大脑模拟器”!世界模型“功能-时序-空间”三维分析:从虚拟练车到机器人抓杯,一篇读懂核心逻辑
摘要:具身AI世界模型是让智能体实现"预想未来"能力的核心技术。本文基于最新综述,系统梳理了世界模型的"功能-时序-空间"三维分类框架:功能维度区分任务专用型与通用型;时序维度对比逐步推演与全局预测;空间维度分析四种场景表示方法。通过自动驾驶和机器人场景的性能对比,指出当前最优模型如DrivePhysica、VidMan等的表现,同时揭示数据碎片化、计算效率
摘要:基于《A Comprehensive Survey on World Models for Embodied AI 2510.16732v1.pdf》,详解具身 AI 世界模型“功能-时序-空间”三维框架,梳理数据集、对比 SOTA 性能、剖析挑战,为具身 AI 研究提供权威参考。
前言:提及人工智能的 “智慧”,很多人会想到它解决复杂问题的能力 —— 但对具身 AI(如服务机器人、自动驾驶汽车)而言,真正的 “智慧” 不仅是 “会做事”,更是 “能预想”:机器人抓握杯子前,能预判 “从哪个角度抓不会摔落”;自动驾驶汽车行驶时,能提前感知 “3 秒后路口是否有碰撞风险”。支撑这种 “预想能力” 的核心技术,正是被称为具身 AI “大脑模拟器” 的世界模型。
近期,南开大学&天津科技大学&中国电子科技大学联合发表的《A Comprehensive Survey on World Models for Embodied AI》(文献编号:2510.16732v1),系统梳理了世界模型的技术体系,从核心概念到分类框架,从数据集到性能对比,为我们揭开了这一技术的神秘面纱。本文将基于该综述,用通俗语言详解世界模型的核心逻辑,带大家轻松读懂 “AI 如何在脑子里模拟世界”。
一、先搞懂:世界模型到底是什么?
简单来说,世界模型是具身 AI 的 “内部环境模拟器”—— 它能将 AI 感知到的多模态信息(如摄像头的图像、传感器的距离数据)转化为 “可计算的场景模型”,再基于这个模型预测 “执行某个动作后,环境会发生什么变化”。
要理解世界模型的核心能力,先看Fig. 1(世界模型分类体系与文章结构示意图)。这张图堪称世界模型的 “理论总纲”:左侧明确了世界模型的三大核心支柱(如同 AI “模拟能力” 的三大基石),右侧则构建了 “功能 - 时序 - 空间” 三维分类框架(给每类世界模型贴上专属 “身份标签”),让复杂的技术体系变得清晰易懂。
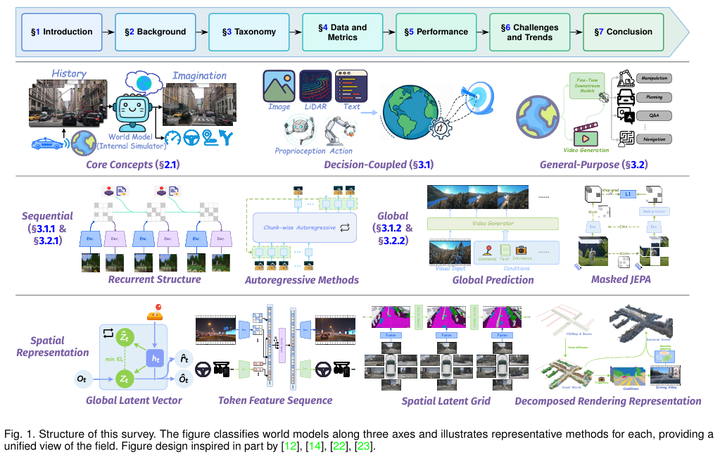
Fig. 1 世界模型分类体系与文章结构
-
图左侧以 “World Model (Internal Simulator)” 为核心,标注出 “仿真规划(Imagination)”“时序演化(History)”“空间表示(Spatial Representation)” 三大核心概念;
-
右侧则用三维坐标轴划分模型类型,X 轴为 “功能维度”(决策耦合型 / 通用型),Y 轴为 “时序维度”(序列仿真 / 全局预测),Z 轴为 “空间维度”(全局向量 / 令牌序列 / 空间网格 / 分解渲染),每个坐标区间对应具体模型案例)
世界模型的 “模拟能力” 全靠三大支柱支撑:
1)仿真与规划:AI 的 “想象力”—— 无需实际执行动作,在 “脑子里” 模拟不同动作的结果,比如机器人模拟 “左手抓杯”“右手抓杯” 两种方案的成功率;
2)时序演化:AI 的 “记忆力”—— 记住前一时刻的场景状态,才能推算出下一时刻的变化,就像我们知道 “杯子现在在茶几左侧”,才能预判 “推动后会移向右侧”;
3)空间表示:AI 的 “空间感”—— 将复杂场景转化为结构化表示(如 “杯子在茶几上,遥控器在杯子右侧”),而非一堆混乱的像素点,这是精准预测的基础。
二、核心框架:世界模型的 “三维身份证”
原著最亮眼的贡献,是提出了 “功能 - 时序 - 空间” 三维分类框架 —— 无论用于机器人、自动驾驶还是其他具身场景的世界模型,都能在这个框架中找到定位。我们结合 Fig. 1 的分类逻辑,逐一拆解:
1. 第一维:功能维度 ——“专才” 还是 “通才”?
世界模型按 “是否绑定特定任务”,分为两类:
-
决策耦合型(专才):聚焦单一任务,仅优化与该任务相关的环境动态。比如专为机器人 “堆叠积木” 设计的模型,只关注 “积木位置、机械臂动作” 的关联预测;自动驾驶中专门用于 “路口转弯” 的模型,仅针对 “转弯时车辆与行人的互动” 进行优化。 原著中提到的 Dreamer 系列(归类于 “决策耦合 / 序列 / 全局向量”)就是典型案例:早期版本专注于 Atari 游戏场景,能精准预测游戏内球的轨迹以优化击球策略,但换为 “机器人抓物” 场景后,性能大幅下降 —— 如同专注某一领域的 “专家”,跨领域能力较弱。
-
通用型(通才):不绑定特定任务,能学习通用环境规律,适配多种场景。比如原著中提及的 V-JEPA 2,可从海量视频中学习 “物体运动、场景变化” 的通用逻辑,既能支持机器人感知桌面物体动态,也能为自动驾驶提供道路场景预测;还有视频生成模型 Sora,既能模拟 “水流进杯子” 的日常场景,也能生成 “车辆在马路行驶” 的自动驾驶场景。
2. 第二维:时序维度 ——“一步一步推” 还是 “一眼看全”?
按 “预测未来的方式”,世界模型分为两种时序策略:
-
序列仿真与推理:像解数学题一样 “逐步推导”—— 先预测 “当前场景→1 秒后场景”,再以 1 秒后的场景为基础,推导 “2 秒后场景”,直至完成长时域预测。这类模型常用 RNN(循环神经网络)或 RSSM(循环状态空间模型)构建核心,比如原著中的 PlaNet、DreamerV2,均通过逐步推演实现 Atari 游戏、机器人控制的长时域预测。 优势是计算效率高(无需一次性处理所有时刻),但缺点是 “误差累积”—— 若第一步预测存在微小偏差,到第 10 步可能完全偏离真实场景(比如机器人抓杯,第一步误判杯子位置,后续推演会导致机械臂 “抓空”)。
-
全局差异预测:“并行计算” 所有时刻的未来场景,无需逐步推导。比如基于扩散模型的世界模型,能直接从 “当前场景” 推算出 “10 秒后场景”,中间时刻的变化也同步生成。原著中提到的 GenAD、DriveDreamer-2 等自动驾驶模型,就采用这种策略预测道路场景,避免了逐步推演的误差累积。 优势是时序连贯性强(不易出现 “物体瞬移”),但缺点是计算成本高 —— 一次性处理多时刻数据,对硬件性能要求较高,难以满足机器人实时控制、自动驾驶低延迟决策的需求。
3. 第三维:空间表示 ——AI 如何 “看懂” 世界?
按 “场景的结构化表示方式”,原著将世界模型的空间策略分为四类,我们用生活场景类比,更易理解:
-
全局 Latent 向量:把整个场景 “压缩成一串数字”。比如将 “茶几 + 杯子 + 遥控器” 的场景,编码为 [0.3, 0.7, 0.5...] 这样的向量。优势是计算速度快,适合嵌入式设备(如小型服务机器人);但缺点是 “丢失细节”——AI 知道场景中有杯子,却无法判断杯子在茶几的左侧还是右侧。
-
令牌特征序列:把场景拆成 “独立小单元(令牌)”,再分析单元间的关联。比如将 “杯子”“茶几”“遥控器” 分别作为独立令牌,模型通过学习 “杯子令牌与茶几令牌的位置关系”“遥控器令牌与杯子令牌的距离”,实现动态预测。原著中用于自动驾驶的 DrivingGPT,就将 “车辆”“行人”“交通灯” 拆分为令牌,通过预测 “下一个令牌的位置” 实现轨迹规划。
-
空间 Latent 网格:像玩《我的世界》一样,用网格划分场景,每个格子标注 “是否有物体”“是什么物体”。比如采用鸟瞰图(BEV)网格,从高空视角将道路划分为多个小格子,“车辆”“行人”“绿化带” 分别对应不同格子 —— 这种方式能清晰呈现物体的空间位置,是自动驾驶世界模型的主流选择。原著中的 DriveWorld、OccLLaMA 等模型,均基于 BEV 网格实现道路场景预测。
-
分解式渲染表示:将 3D 场景拆成 “可渲染的基础单元”,再通过 “拼接渲染” 实现预测。比如用 3D 高斯溅射(3DGS)将杯子拆成数百个 “小高斯点”,用神经辐射场(NeRF)将房间拆成 “可计算光线的场域”—— 这类模型能生成高保真的 3D 场景,甚至支持 “从任意角度观察预测结果”。原著中的 ManiGaussian++、DriveDreamer4D 就采用这种策略,前者实现机器人抓物的 3D 动态预测,后者支持自动驾驶场景的多视角渲染。
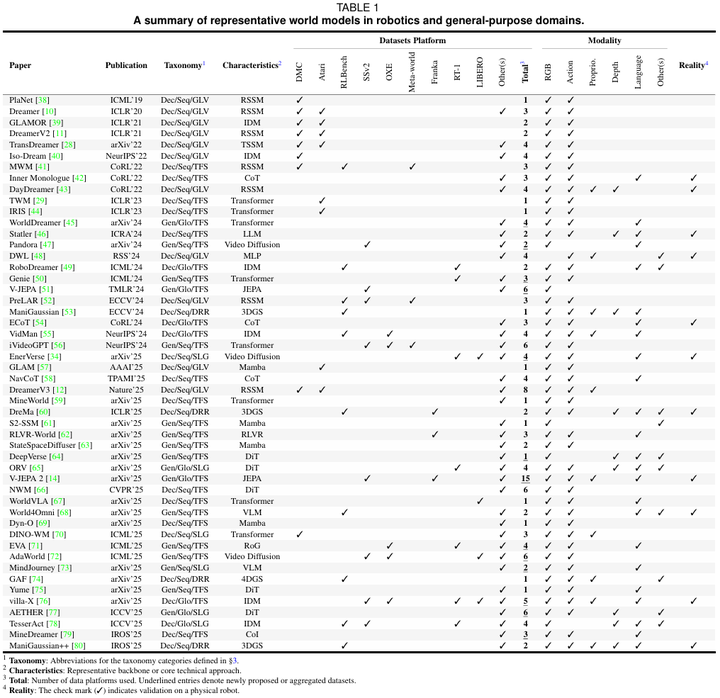
表 1 机器人与通用领域代表性世界模型汇总
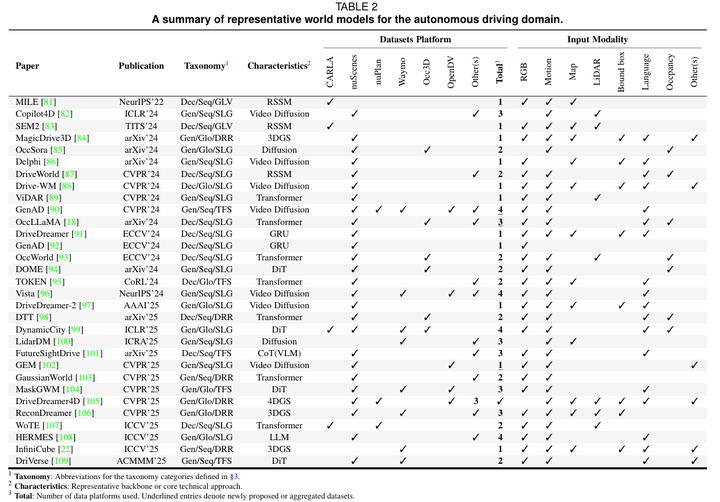
表 2 自动驾驶领域代表性世界模型汇总
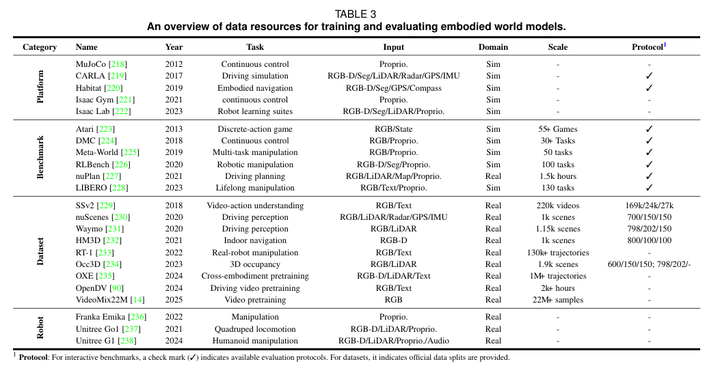
表 3 具身 AI 世界模型数据资源汇总
三、性能对比:哪些世界模型 “更能打”?
原著通过标准化数据集,对当前主流世界模型的性能进行了量化对比。我们选取机器人、自动驾驶两大核心场景,提炼关键结果:
1. 自动驾驶场景:视频生成与规划能力
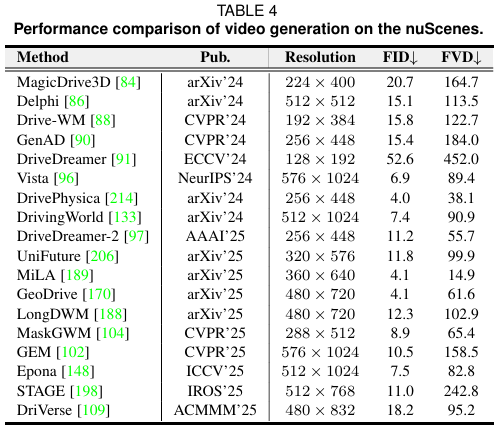
表 4 nuScenes 数据集视频生成性能对比
在 nuScenes 数据集(自动驾驶领域常用的多模态数据集)上,原著从 “视频真实度”(FID 指标,值越低越真实)和 “时序流畅度”(FVD 指标,值越低越流畅)两个维度,测评了模型的场景生成能力:
-
真实度最优:DrivePhysica 模型,FID=4.0—— 生成的道路场景(如车辆行驶、行人过马路)与真实视频几乎无差异,肉眼难以分辨;
-
流畅度最优:MiLA 模型,FVD=14.9—— 避免了 “车辆突然变道”“行人动作卡顿” 等时序伪影,动态表现更贴近真实世界;
-
规划能力突出:SSR 模型,在 “开放环规划” 任务中(给定 2 秒历史轨迹,预测 3 秒后车辆航点),无需额外监督数据,就能实现平均 L2 误差 0.75 米、碰撞率 0.15% 的优异表现,甚至超过部分依赖辅助数据的模型(数据来源:原著表 4、表 8)。
2. 机器人场景:操纵任务成功率
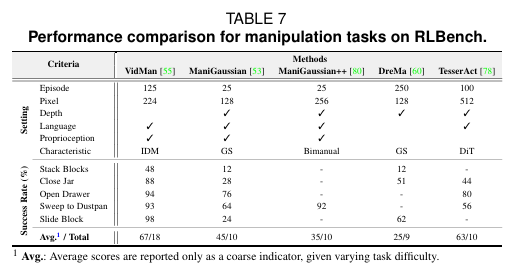
在 RLBench 数据集(机器人操纵领域的标准基准,包含 100 个桌面操纵任务)上,原著以 “任务成功率” 为核心指标,对比了模型的实际应用能力:
-
综合表现最优:VidMan 模型,平均成功率 67%(覆盖 18 个任务)—— 其中 “开抽屉” 任务成功率 94%、“扫垃圾到簸箕” 93%、“滑动方块” 98%,是当前机器人操纵场景的顶尖水平;
-
3D 预测优势:ManiGaussian++ 模型,基于 3D 高斯溅射实现物体动态预测,在 “堆叠积木”“抓握不规则物体” 任务中,成功率分别达 51%、44%,显著优于传统 2D-based 模型(数据来源:原著表 7)。
四、当前挑战:世界模型还需突破哪些难关?
尽管世界模型已在多个场景落地,但原著也指出了三大核心挑战,这是未来研究的重点方向:
1. 数据碎片化与评价片面性
-
数据问题:具身 AI 各领域的数据集相互独立 —— 机器人操纵的数据集(如 RLBench)、自动驾驶的数据集(如 nuScenes)无法共享,导致模型难以学习通用环境规律;
-
评价问题:当前指标(如 FID、PSNR)过度关注 “像素保真度”,忽略 “物理一致性”—— 比如某模型生成的 “杯子悬浮” 视频,像素层面很真实,但违背物理规律,却可能获得高分。原著作者呼吁建立 “物理一致性优先” 的评价体系,如 EWM-Bench 提出的 “场景动态合理性”“物体交互逻辑性” 指标。
2. 计算效率与实时性的矛盾
通用型世界模型(如基于 Transformer、扩散模型的架构)虽性能强,但计算成本高 —— 以自动驾驶模型 DriveDreamer-2 为例,生成 10 秒视频需消耗大量 GPU 资源,难以满足 “毫秒级决策” 的实时需求;而高效的轻量模型(如基于 RNN 的 DreamerV2),又存在长时域预测误差累积的问题。如何在 “性能” 与 “效率” 间找到平衡,是亟待解决的难题。
3. 长时域预测的一致性
当前模型在 “3 秒内短期预测” 表现优异,但 “10 秒以上长时域预测” 易出现 “逻辑跑偏”—— 比如机器人抓杯任务,短期预测能精准判断 “机械臂下一步位置”,但长时域预测可能出现 “杯子突然消失”“机械臂动作混乱” 的问题;自动驾驶场景中,长时域预测也可能出现 “车辆偏离车道”“行人凭空出现” 的矛盾。如何缓解误差累积、保证长时域一致性,是世界模型向 “实用化” 迈进的关键。
五、资源推荐:想深入?这些资料别错过
为方便研究者与爱好者进一步探索,原著作者整理了 “世界模型精选文献库”(链接:https://github.com/Li-Zn-H/AwesomeWorldModels),其中包含:
-
文中所有代表性模型的论文链接(如 Dreamer 系列、V-JEPA 2、DriveDreamer4D 等);
-
标准化数据集的下载地址(如 nuScenes、RLBench、Occ3D 等);
-
部分模型的开源代码与实验复现教程。
无论是想了解理论细节,还是动手复现实验,这个文献库都是优质资源。
结语
世界模型的本质,是让具身 AI 拥有 “理解世界、预想未来” 的能力 —— 它不再是 “盲目执行动作” 的机器,而是能通过 “内部模拟” 优化决策的 “智慧体”。从原著的梳理来看,尽管当前世界模型仍面临数据、效率、长时域预测的挑战,但已在机器人操纵、自动驾驶等场景展现出巨大潜力。
未来,随着 “跨域统一数据集” 的构建、“高效轻量架构” 的突破,我们有理由相信:世界模型将让服务机器人更精准地完成家务,让自动驾驶汽车更安全地穿梭于城市,真正实现 “AI 与世界的智能互动”。
END
您的赞同支持是我努力坚持的动力!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)