TRIVLA: A TRIPLE-SYSTEM-BASED UNIFIED VISION-LANGUAGE-ACTION MODEL FOR GENERAL ROBOT CONTROL
TriVLA 展示了一种新颖的三系统架构,有效地将视觉-语言理解与动力学感知结合起来,增强了机器人捕捉静态信息和未来动态信息的能力。这种整合为机器人操作实现了更流畅和更具泛化性的控制策略。实验结果表明,TriVLA 在标准仿真基准和具有挑战性的现实世界任务上超越了最先进的模仿学习基线,突显了其在通用机器人控制中的广泛应用潜力。那么为什么是三系统架构呢?因为,不仅仅要看得懂,还要有做预判的能力。只有
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | TRIVLA |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | zhenyangliu.github.io/TriVLA/ |
| 4 | 创新点 |
1:从“双系统”进化为“三系统” 双系统(System 1 快反应 + System 2 慢思考)缺点是只关注静态图像,忽略了物体运动的物理规律。TriVLA 引入了 System 3(动力学感知模块)。这个系统充当“世界模型”,专门负责预测“未来会发生什么”。 填补了机器人“懂语义(VLM)”和“懂动作(Policy)”之间“懂物理(Dynamics)”的空白。(世界模型也就是对整个世界运行规律的一个模拟器,而要想准确的预测未来,模型必须理解这个世界的因果关系和物理规律,因此“预测未来”是手段,“构建世界模型”是目的(或结果)。) 2:(System 3):视频生成模型的“单次前向传播” 视频扩散模型(如 SVD)生成完整视频太慢,无法满足机器人实时控制。作者提出了Single Forward Pass(单次前向传播)。给模型输入当前图像+噪声,只让模型跑一步。不等待视频生成,直接“偷取”模型内部上采样层(Up-sampling layers)的特征。既获取了对未来的物理预判(动态特征),又将推理时间压缩到了毫秒级(<86ms)。 3:巧妙利用“中间层” 1)对于 System 2(VLM): 不用最后一层,而是用 第 12 层(中间层) 的特征。兼顾了高层语义(是什么)和底层细节(在哪里),且推理更快。 2)对于 System 3(SVD): 自动聚合所有 上采样层 的特征。通过插值和拼接,把不同尺寸的特征图融合成一个包含丰富时空信息的超级 Feature Map。 4: 策略实现(System 1):流匹配 + 动作分块 采用 Flow Matching(流匹配) 结合 DiT(Diffusion Transformer)。 相比传统扩散模型,生成轨迹更直、效率更高。通过 Cross-Attention 机制,同时吸收 System 2 的语义 Token 和 System 3 的物理 Token。 通过Action Chunking。一次预测未来 10 步动作,结合 36Hz 的高频控制,实现了动作的极致流畅。 |
| 5 | 引用量 | 三系统架构是不是太臃肿了?作者的单词传播机制和采用中间层信息的思路是值得学习的。 |
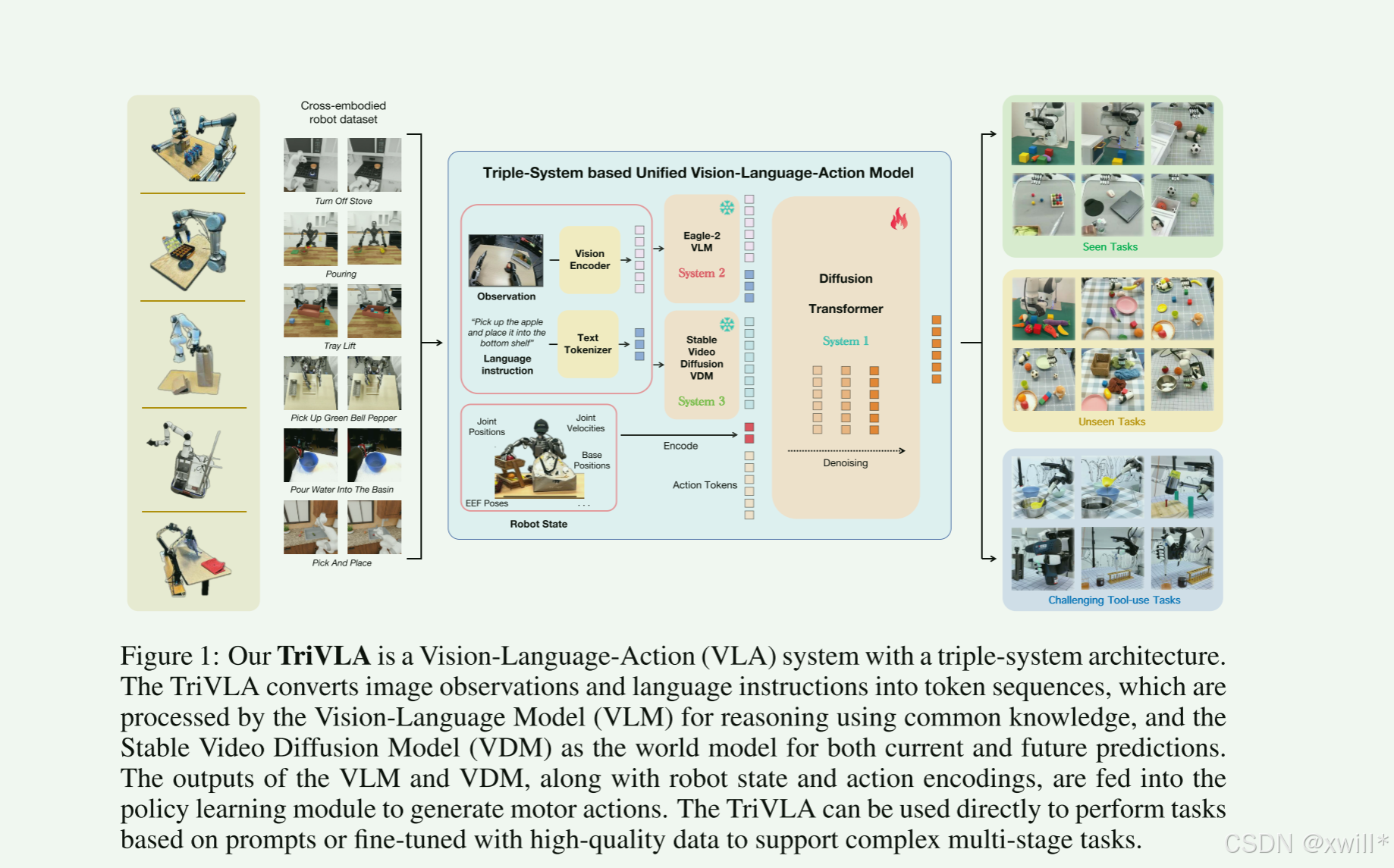
一:提出问题
目前的VLA模型虽然借用了双系统的理念,变得更聪明了,但它们有一个致命弱点:它们擅长看懂静态图片,却忽略了物体运动、碰撞等动态信息,而这对于机器人干活(具身任务)是最重要的。为了解决目前机器人模型缺乏对动态信息处理上的问题,本文提出了 TriVLA,其核心是三系统架构:
-
System 2(大脑): 负责理解任务和环境语义。
-
System 3(核心创新): 这是一个动力学感知模块。它能预测未来动态。它利用微调过的视频基础模型,通过预测视频的下一帧来理解物理规律,给机器人提供物理直觉。
-
System 1(小脑): 结合前两个系统的输入,快速输出动作。
同时,为了更好的训练这个复杂的系统,作者引入互联网人类视频数据是为了让 System 3 更好地学习通用的物理动态规律。
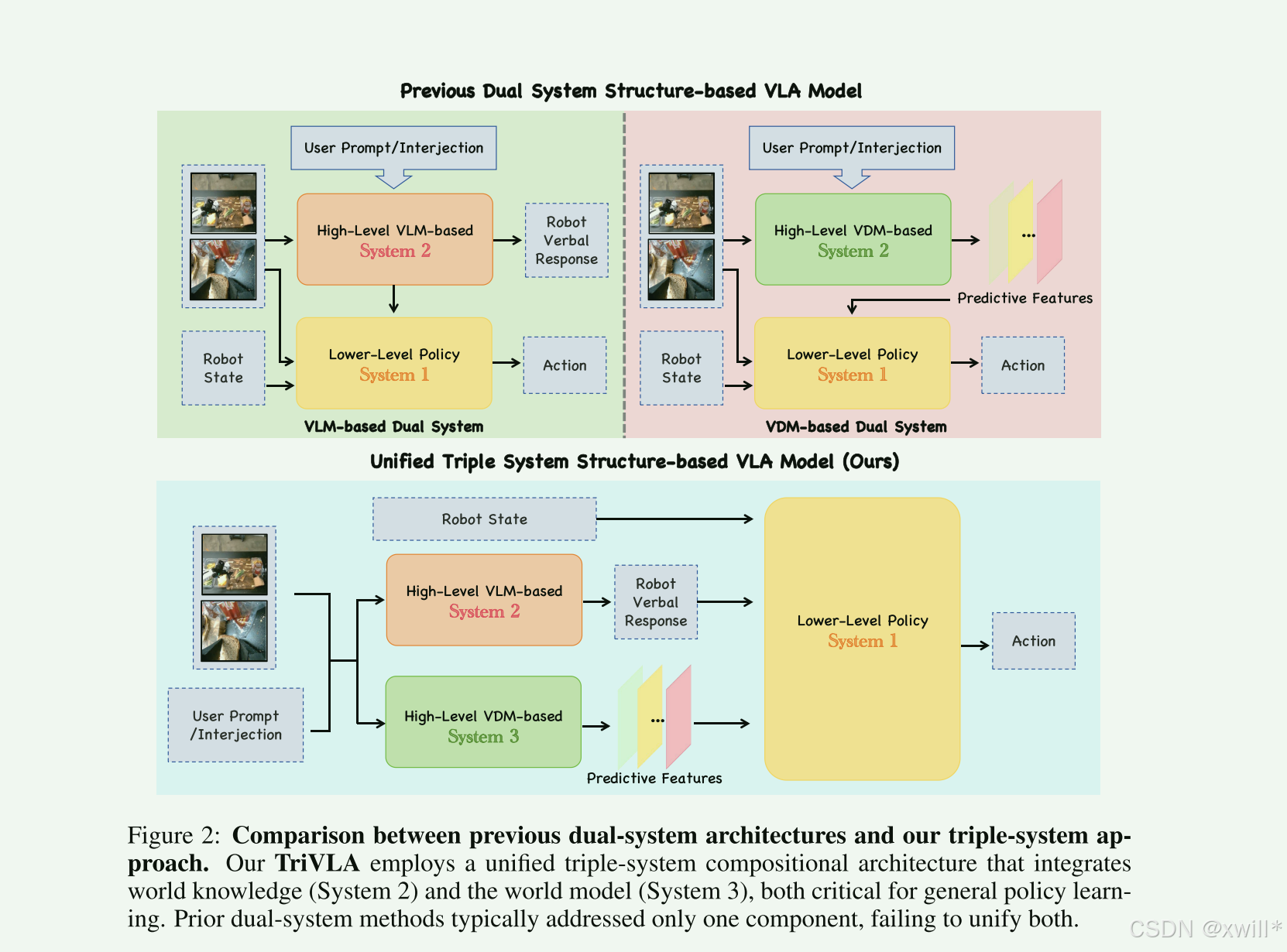
VLMs(视觉语言模型) 是十分强大的,VLA 模型已经利用双系统架构成功将 VLMs 用于机器人控制。这些现有方法有一个重大缺陷:“focus on static information”(关注静态信息)。因为它们通常只看一张或两张图片。丢失了动态信息。对于机器人来说,理解物体是如何移动的至关重要。
而现阶段的VDMs(视频扩散模型,Video Diffusion Models)的是整个视频序列,并且能够预测未来帧,这意味着 VDM 天生就理解物理世界是如何随时间变化的。于是作者提出了 TriVLA。这不仅仅是加一个模块,而是引入了一个 “World Model(世界模型)” 的概念——通过预测未来视频,来模拟物理世界。
System 2(大脑 - 理解):VLM。它负责看懂当前情况和听懂人话。
System 3(核心创新 - 预测):视频扩散模型(VDM)。在海量视频数据上训练过,负责预测视频。
如果模型能准确预测出机器人手臂移动后的视频画面,那么模型隐式地也就学会了“如何控制手臂去达到那个状态”(即逆动力学)。这是 System 3 能够指导动作的关键原理。
System 1(小脑 - 执行):策略学习模块。使用动作流匹配(一种生成模型技术)和 动作分块(一次预测一串动作)。
它同时接收 System 2(语义理解)和 System 3(物理预测)的信号(tokens),最终输出电机指令
二:解决方案
目前主流的双系统VLA模型通常是借鉴心理学中“双系统”的理论:
-
高层系统(System 2,大脑): 负责“慢思考”。它接收图像和人类的语言指令,进行推理,弄清楚“我现在要干什么,计划是什么”。
-
低层系统(System 1,小脑): 负责“快反应”。它拿着高层系统给出的计划,结合当前的具体状态,直接输出机器人的电机动作(比如手往左移 1 厘米)。
而本文是基于此基础上引入了第三个系统。三个系统的学习和工作流程如下:
1:系统 2:视觉-语言模块(负责“理解语义”)
选用了一个名为 Eagle-2 的视觉语言模型。它由一个大型语言模型(LLM,具体是 SmolLM2)和一个图像编码器(SigLIP-2)缝合而成。通过把摄像头看到的图片切成小块,变成数据流。同时也把人类的文本指令也变成数据流。两者在模型内部混合、对齐。
由于大模型中间层的特征既包含了一定的语义理解,又保留了更多的原始细节,而且提取速度更快。这就像是我们在大模型“思考到一半”的时候,把它的脑电波截取下来给后面用。也就是说,在这片论文里边,作者发现取中间层(第 12 层)的特征效果更好。
其次, 不同机器人的身体结构不一样(关节数量不同),作者用了一个专门的小网络(MLP)把不同机器人的状态统一映射到一个共享的空间里,方便模型统一处理。
2:系统 3:动力学感知模块(能够根据一张图预测后续的视频)
TriVLA 最独特的创新点,新加入的“第三系统”。它的作用是给机器人提供物理世界的直觉。使用的是一个基于 Stable Video Diffusion (SVD) 的视频生成模型,参数量很大(15 亿)。系统在海量的互联网视频和机器人操作视频上训练过,任务是“根据第一帧画面,把后续的视频补全”。通过这个过程,模型学会了物理世界是如何运动变化的。

微调使用的数据集包括互联网来源的人类操作数据、互联网机器人操作数据和自收集的数据集。然后,动力学感知模块 Vθ通过扩散目标进行训练,即从加噪样本 xt中重建数据集 D 中的完整视频序列 x0=s0:T。
训练好的模型直接用来控制机器人的话,会有两个问题:
-
计算太重: 生成一个完整视频需要模型反复运算几十次(去噪过程),机器人等不起。
-
信息冗余: 生成的视频里包含了背景颜色、光照等大量细节,而机器人只需要知道“物体怎么动”。
对此,作者提出了一个单次前向传播的方案, 不让模型生成完整视频。只把当前图像加上高斯噪声(随机白噪声),喂给模型,让模型只跑一步。虽然跑一步出来的结果是一团模糊的噪点图,但在模型内部的中间层,神经元已经开始活跃,并形成了对物体未来运动轨迹的“粗略直觉”。这就像你扔出一个球,不需要等球落地,在扔出的瞬间你脑子里已经预判了轨迹。
而模型内部有非常多层,选择那一层效果最好呢?作者引用前人研究(Xiang et al.),上采样层的特征最好用。因为这部分特征既包含了深层的语义(是什么物体),又开始恢复空间分辨率(在哪里运动)。
自动特征聚合: 模型里有多个上采样层,尺寸不一(有的 32x32,有的 64x64)。为了不纠结选哪层,作者直接把它们全部利用:
-
把所有层的特征图强制缩放(插值,Interpolation)成同样的大小(Wp×Hp)。
-
像叠三明治一样,在通道维度把它们拼起来(Concatenate)。这样就得到了一个包含丰富物理动态信息的超级特征块 Fp。


有个疑问,到底生成视频还是没有生成视频呢?
系统3的训练有两个阶段,阶段1是微调、训练阶段。在这个阶段,模型真的在学做视频。它就像一个刚上学的学生,老师给它看大量的机械臂视频,强迫它学会怎么把全是噪点的画面还原成清晰的视频,学习物理规律。阶段2是下游策略学习,也就是推理阶段。等模型学会了(微调好了),要用它控制机器人了。这时候,如果还让它画完整个视频,太慢了所以作者想了个招:“假装”要让它生成视频,把素材喂进去,刚让它跑第一步,就把它的中间层特征偷出来用。这时候,视频还没画出来(不清晰),但那个“脑电波”里已经包含了它对未来的预判。从而学会物理规律。
3:策略学习模块(系统 1:如何指挥动作生成)
系统1是把 System 2 的“指令”和 System 3 的“直觉”结合起来,变成电机信号。
1. 信息压缩:时空注意力机制 System 3 吐出来的那个超级特征块 Fp数据量太大了,直接喂给动作模型会消化不良。因此,先初始化一组可学习的 Token(相当于空的容器)。
-
第一步(空间注意力): 让这些 Token 去“看”每一帧画面的特征,提取重要的空间信息(比如杯子在哪)。
-
第二步(时间注意力): 让这些 Token 在时间轴上进行交流,理解动作的先后顺序。
最终压缩出一组精简的预测 Token (Qp),它浓缩了未来的动态精华。
2. 动作生成大脑:扩散策略 (Diffusion Policy) 与 DiT 这里采用了目前最先进的动作生成架构。DiT (Diffusion Transformer): 这是一个基于 Transformer 的扩散模型。工作方式是“去噪”。
-
输入条件: 它并不是瞎猜动作,而是基于两个条件:
-
Qvl(来自 System 2):视觉语言信息,告诉它“任务是什么”。
-
Qp(来自 System 3):动力学预测信息,告诉它“物理规律允许怎么动”。
-
-
交叉注意力: 是融合信息的关键。在 DiT 的每一层里,都会通过交叉注意力机制,把上面两个条件的 Token “吸入”进来,指导动作生成的去噪过程。
3. 具身特定解码器
DiT 输出的是通用的动作特征。为了控制具体的机器人,最后接了一个 MLP(多层感知机)。它的作用是把通用的特征“翻译”成特定机器人的关节角度或速度。最终训练目标是最小化预测动作和真实专家动作之间的差异。
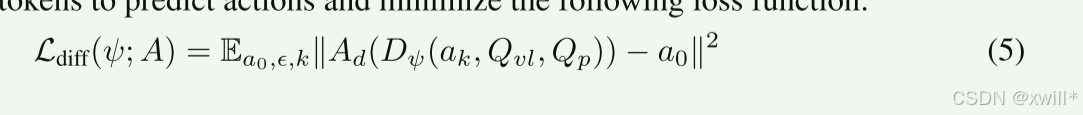
总的来说,TRIVLA它没有笨重地生成视频,而是偷取了视频生成模型“思考过程中”的中间特征(System 3),将其视为物理直觉;然后通过注意力机制压缩这些特征,并结合语言指令,利用最先进的扩散 Transformer(DiT) 生成了精准且符合物理规律的动作(System 1)。
三:实验

-
CALVIN (长视距任务 & 泛化能力):这个环境里的任务通常比较长(比如“打开抽屉,拿出积木,关上抽屉,把积木放在桌子上”)。这是最难的考试模式。机器人在 A、B、C 三个房间里练习(Training),最后却被扔进从来没见过的 D 房间(Testing)去考试。这专门测试机器人举一反三(泛化)的能力。
-
LIBERO (知识广度 & 基础理解):分为四个科目:空间感(Spatial)、物体认知(Object)、目标导向(Goal)、长程任务(Long)。文中特别提到把图像旋转了 180 度。这是一个很具体的实验设置,通常是因为某些数据集采集时的摄像头安装方式和当前测试环境是倒着的,或者为了增加难度。
-
MetaWorld (手部精细活):这里面的任务需要很精细的操作,比如要把一个很小的东西插进孔里,或者拧开一个盖子。它测试的是 TriVLA 的System 1(小脑)手稳不稳。
四:总结
TriVLA 展示了一种新颖的三系统架构,有效地将视觉-语言理解与动力学感知结合起来,增强了机器人捕捉静态信息和未来动态信息的能力。这种整合为机器人操作实现了更流畅和更具泛化性的控制策略。实验结果表明,TriVLA 在标准仿真基准和具有挑战性的现实世界任务上超越了最先进的模仿学习基线,突显了其在通用机器人控制中的广泛应用潜力。
那么为什么是三系统架构呢?因为,不仅仅要看得懂,还要有做预判的能力。只有把这两者结合起来,机器人才能像人一样,既懂任务逻辑,又懂物理直觉。才可以捕捉静态和未来动态信息。从而提升了系统的流畅性和泛化性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)