深度学习核心揭秘:注意力机制工作原理及变体全解析,Transformer基石大揭秘!
本文详细介绍了深度学习中的注意力机制(Attention),从机器翻译问题入手解释了注意力机制的重要性。文章分析了传统Encoder-Decoder结构在处理长文本时的信息瓶颈问题,并系统讲解了注意力机制的工作原理、权重计算方法及多种变体(Soft Attention、Hard Attention、Global Attention、Local Attention和Self Attention)。最
我们都知道对于人类来说注意力是非常重要的一件事;有了注意的能力我们才能在一个比较复杂的环境中把有限的注意力放到重要的地方。
在这一节中,我们将了解如何使得我们的网络也具有产生注意力的能力和这样的注意力能够给网络表现带来怎样的改变。
一、为什么要有 Attention
让我们从循环神经网络的老大难问题——机器翻译问题入手。
我们知道,普通的用目标语言中的词语来代替原文中的对应词语是行不通的,因为从语言到另一种语言时词语的语序会发生变化。
比如英语的“red”对应法语的“rouge”,英语的“dress”对应法语“robe”,但是英语的“red dress”对应法语的“robe rouge”。
为了解决这个问题,我们创造了 Encoder-Decoder 结构的循环神经网络。
它先通过一个 Encoder 循环神经网络读入所有的待翻译句子中的单词,得到一个包含原文所有信息的中间隐藏层,接着把中间隐藏层状态输入 Decoder 网络,一个词一个词的输出翻译句子。
这样子无论输入中的关键词语有着怎样的先后次序,由于都被打包到中间层一起输入后方网络,我们的 Encoder-Decoder 网络都可以很好地处理这些词的输出位置和形式了。
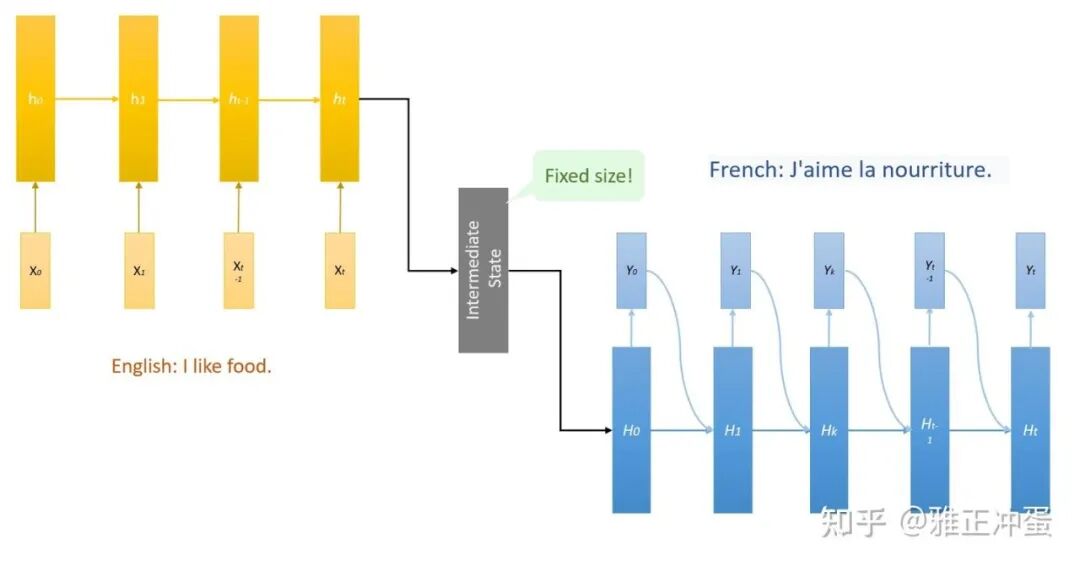
但是问题在于,中间状态由于来自于输入网络最后的隐藏层,一般来说它是一个大小固定的向量。
既然是大小固定的向量,那么它能储存的信息就是有限的,当句子长度不断变长,由于后方的 decoder 网络的所有信息都来自中间状态,中间状态需要表达的信息就越来越多。
如果句子的信息是在太多,我们的网络就有点把握不住了。比如现在你可以尝试把下面这句话一次性记住并且翻译成中文:
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way — in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only.
- A Tale of Two Cities, Charles Dickens.
别说翻译了,对于人类而言,光是记住这个句子就有着不小的难度。如果不能一边翻译一边回头看,我们想要翻译出这个句子是相当不容易的。
Encoder-Decoder 网络就像我们的短时记忆一样,存在着容量的上限,在语句信息量过大时,中间状态就作为一个信息的瓶颈阻碍翻译了。
可惜我们不能感受到 Encoder-Decoder 网络在翻译这个句子时的无奈。但是我们可以从人类这种翻译不同句子时集中注意力在不同的语句段的翻译方式中受到启发,得到循环神经网络中的 Attention 机制。
二、Attention机制

我们要使得网络在翻译不同的句子时可以注意到并利用原文中不同的词语和语句段,那我们就可以把 Decoder 网络式子写作:

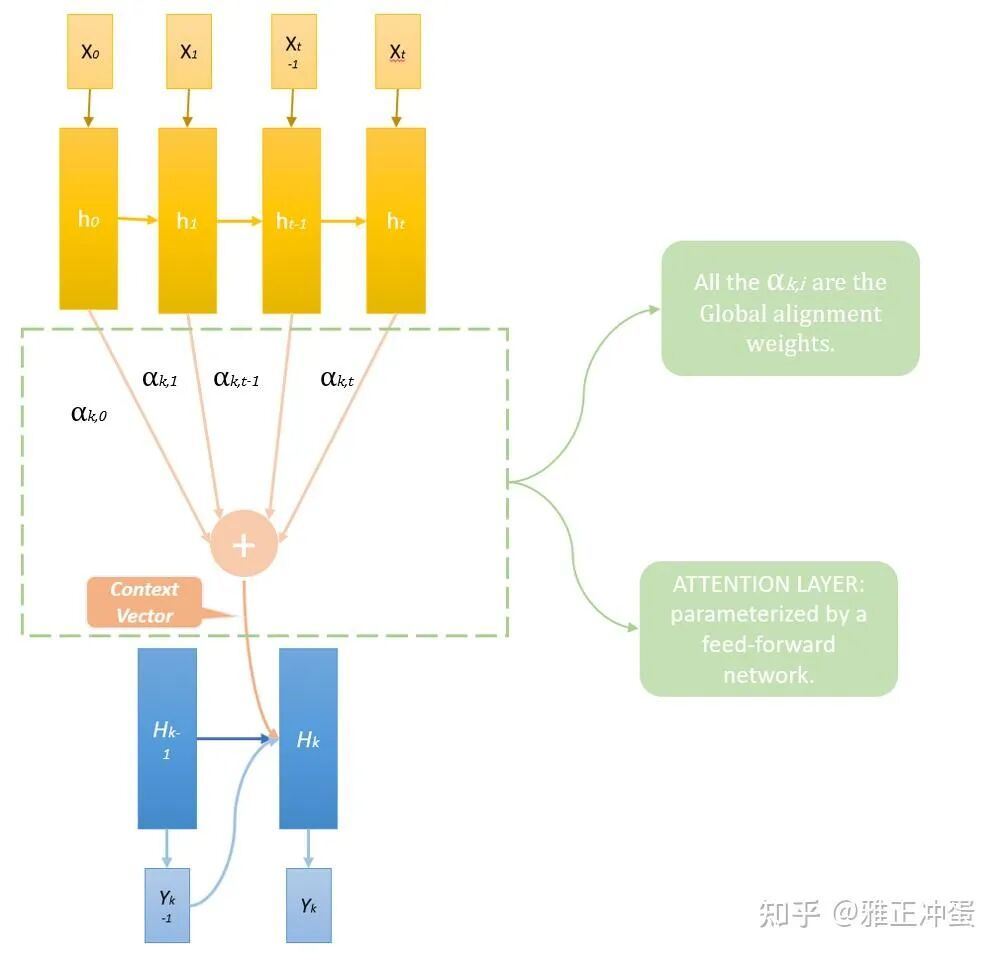

三、全局对齐权重



于是乎我们的带有 Attention 的 Encoder-Decoder 网络的迭代过程就是如下几步:
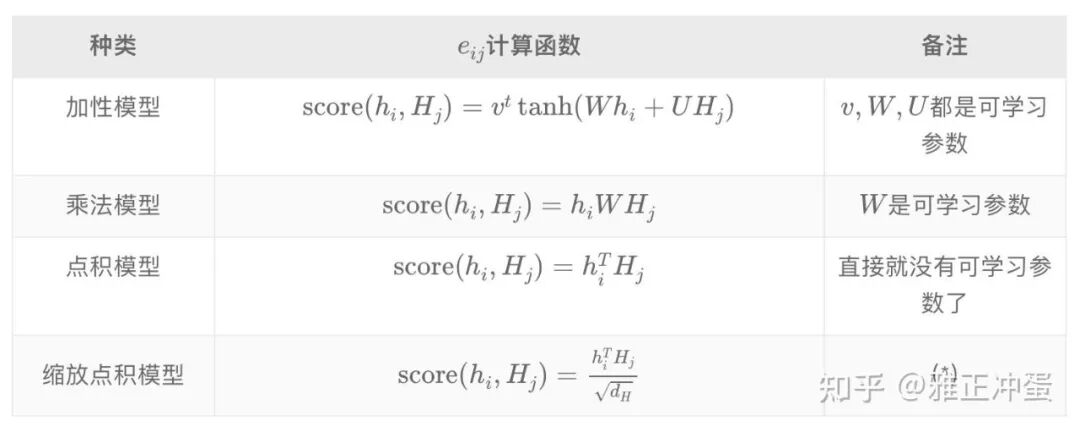
四、如何计算权重计算函数

各种权重计算函数:

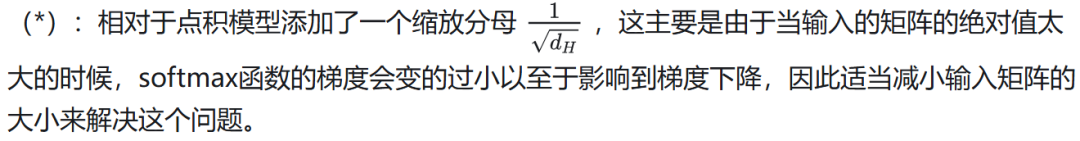
五、Attention 种类
之前我们了解了不同种类的权重计算函数,而从更大的视角来看,我们的 Attention 方法分为几个变体:Soft-Attention,Hard-Attention,Global-Attention,Local-Attention,Self-Attention。接下来让我们一个个介绍。
(1)Soft Attention
我们之前学习的 Attention 机制就是 Soft Attention,它的计算公式我们已经熟悉:
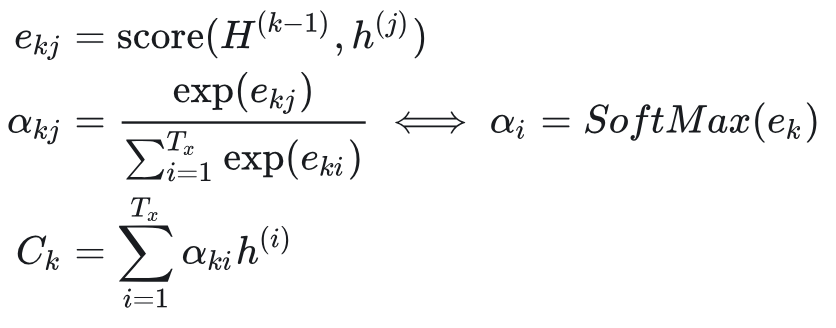
下图是完整的 Soft Attention 工作示意图:
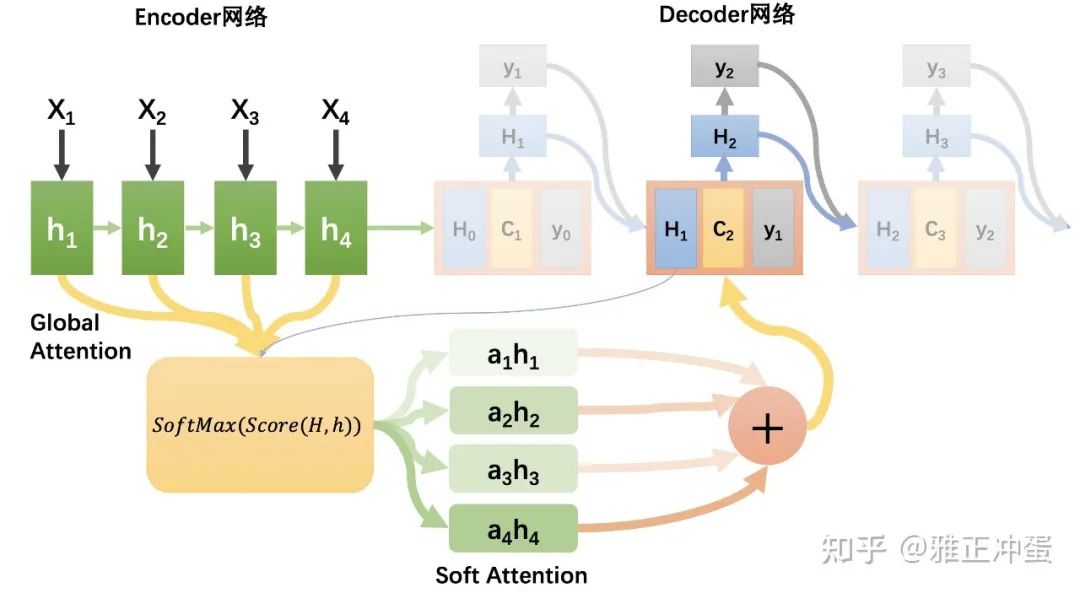
(2)Hard Attention
Hard Attention 不使用加权平均的方法,对于每个待选择的输入隐藏层,它要么完全采纳进入上下文向量,要么彻底抛弃。
具体如何选择需要注意的隐藏层呢,有两种实现方式:

硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息。因此最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练。
为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。
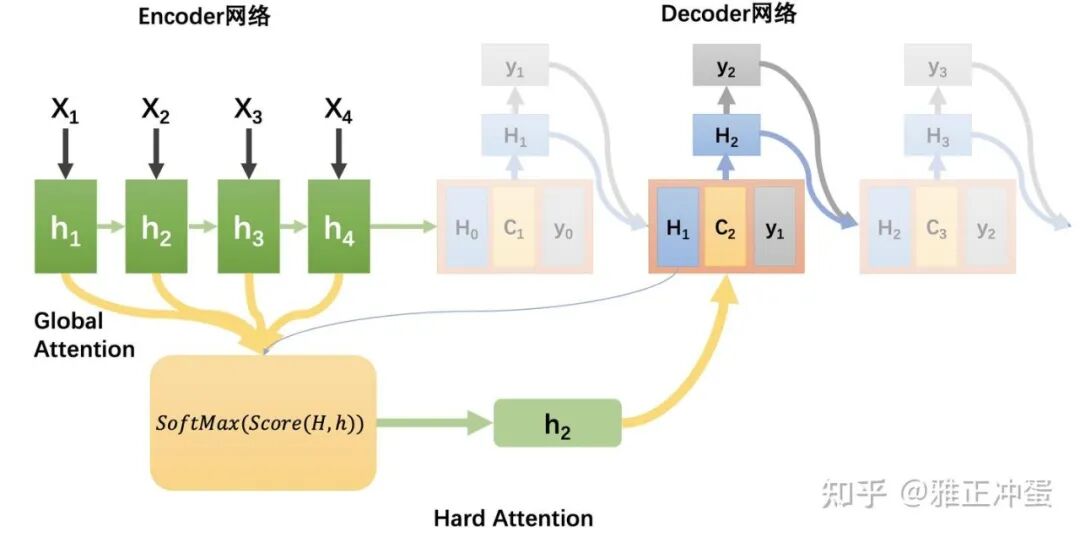
(3)Global Attention\Local Attention
我们之前了解的所有 Attention 机制都是 Global Attention,我们把 Encode r网络中的所有输入都代入计算全局对齐权重,作为候选加入 Ck。
但是如果我们需要翻译的文本是一片很长的论文,那么太多的输入候选隐藏层可能会降低算法的运行速度,如果我们可以首先挑选出可能比较有用的一批隐藏层,只对它们进行 Attention 计算,就可以大大加速算法。
如何预选择出比较有用的隐藏层呢,是这样操作的:

但是如何找到一个合适的 Pt 呢,这里有两种办法:

下图展示的是使用第二种方式确定 Pt 的 Local Attention 方法。
(4)Self Attention
**自监督(Self-Attention)**英文也有叫 Intra- Attention 的,简单来说相比于在输出 Hk 和输入 h 之间寻找对齐关系的其他 Attention 方法。
Self-Attention 可以在一段文本内部寻找不同部分之间的关系来构建这段文本的表征。
因此它多用于非 seq2seq 任务,因为通常 Encoder-Decoder 网络只能构建在 seq2seq 任务中,对于非 seq2seq 问题原先的 Attention 就没有办法排上用场了。
自监督方法非常适合于解决阅读理解,文本摘要和建立文本蕴含关系的任务。

上图显示的就是当算法处理到红色字的表征时,它应该给文中其他文字的表征多大的注意力权重。
接下来我们就会学习怎么实现一个 Self-Attention 过程,不过在此之前,我们需要先切换一下视角。
切换视角——从 Hhc 到 QKV
在我们介绍的几个权重计算函数中,在现在使用比较多的主要是点积模型和缩放点积模型。

如果把这个过程比喻成使用 Query 在数据库中按照 Key 进行筛选,那应该还差一个 Key 对应的值 Value,这里我们还没有定义 Value 是什么。
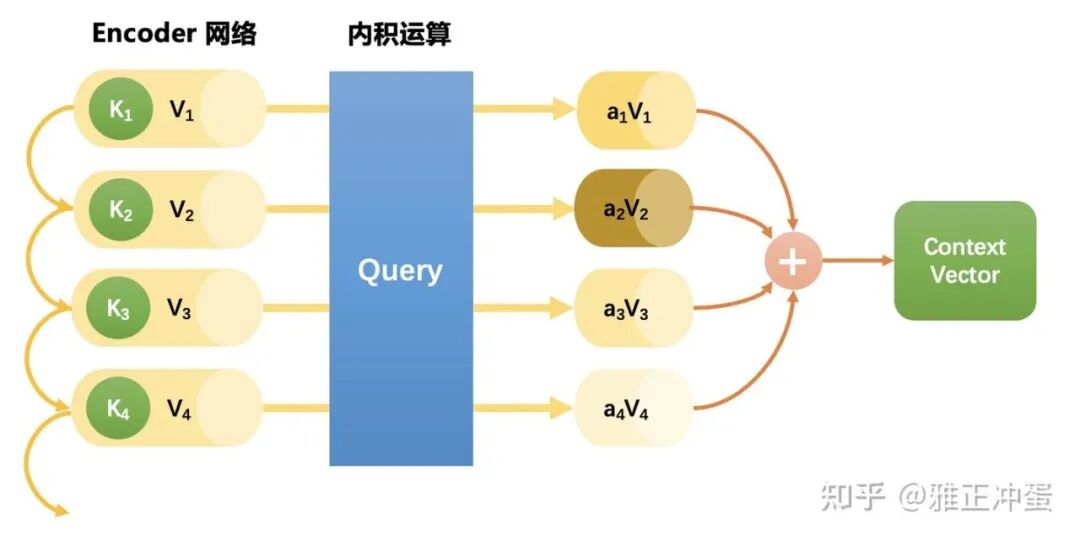

注意在这里我们按照 Key 分配权重但是最终把 Value 进行加权平均。但是一个问题是,什么时候我们的 Key 和 Value 会不同呢?
Self-Attention 中的 Key 和 Value 就是不同的。
Self-Attention 实现
下面这张制作精美的图很简单地演示了如何计算 Self-Attention,图中计算的是处理第一个单词时应该对全文三个单词分别分配多大的注意力:
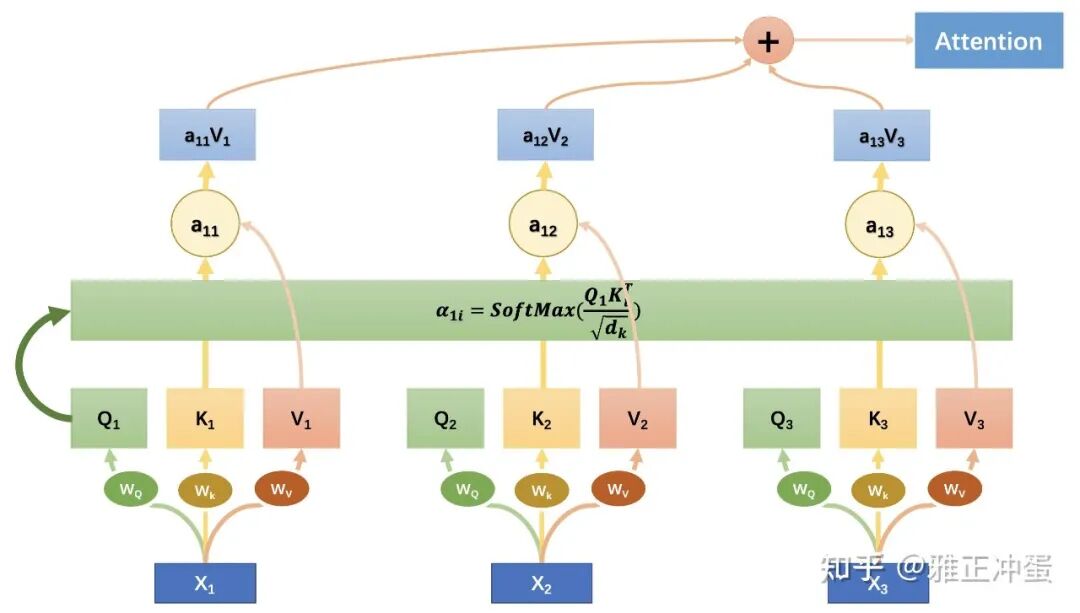

可能讲到这你对具体的计算还是有点懵。懵就对了,我们将在下节教程中在 Transformer 模型中详细演示如何计算自注意力,那时我们才能最好的理解 Self-Attention。
六、Attention 带来的算法改进
Attention 机制为机器翻译任务带来了曙光,具体来说,它能够给机器翻译任务带来以下的好处:
**Attention 显著地提高了翻译算法的表现。**它可以很好地使 Decoder 网络注意原文中的某些重要区域来得到更好的翻译。
**Attention 解决了信息瓶颈问题。**原先的 Encoder-Decoder 网络的中间状态只能存储有限的文本信息,现在它已经从繁重的记忆任务中解放出来了,它只需要完成如何分配注意力的任务即可。
**Attention 减轻了梯度消失问题。**Attention 在网络后方到前方建立了连接的捷径,使得梯度可以更好的传递。
**Attention 提供了一些可解释性。**通过观察网络运行过程中产生的注意力的分布,我们可以知道网络在输出某句话时都把注意力集中在哪里;而且通过训练网络,我们还得到了一个免费的翻译词典(soft alignment)!
还是如下图所示,尽管我们未曾明确地告诉网络两种语言之间的词汇对应关系,但是显然网络依然学习到了一个大体上是正确的词汇对应表。

**Attention 代表了一种更为广泛的运算。**我们之前学习的是 Attention 机制在机器翻译问题上的应用,但是实际上 Attention 还可以使用于更多任务中。我们可以这样描述 Attention 机制的广义定义:
给定一组向量 Value 和一个查询 Query,Attention 是一种分配技术,它可以根据 Query 的需求和内容计算出 Value 的加权和。
Attention,在这种意义下可以被认为是大量信息的选择性总结归纳,或者说是在给定一些表示(query)的情况下,用一个固定大小的表示(Ck)来表示任意许多其他表示集合的方法(Key)。
七、Attention is All You Need
之前的 Self-Attention 我们只介绍了其实现而没有给出具体的应用场景,这是因为留给这篇文章的空间已经不多了。
它的应用——Transformer,另需要一整篇文章来介绍,Transformer 是深度学习历史上的一个里程碑,值得我们细细说道。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
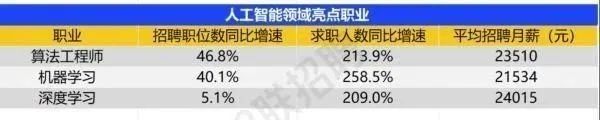
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献361条内容
已为社区贡献361条内容

所有评论(0)