论文阅读-CTSAC: Curriculum-Based Transformer Soft Actor-Critic for Goal-Oriented Robot Exploration
本文提出CTSAC算法,将Transformer的时序建模能力融入SAC框架,解决目标导向的机器人探索任务中存在的局部最优和训练不稳定问题。方法创新包括:1) 设计基于前进方向的LiDAR非均匀分段方法,优化环境感知;2) 构建包含7项奖惩的复合奖励函数,引导有效探索;3) 用Transformer网络替换SAC的全连接层,捕获状态序列的时间依赖关系。实验表明,该方法能有效利用历史状态信息,避免局
“CTSAC: Curriculum-Based Transformer Soft Actor-Critic for Goal-Oriented Robot Exploration” (Yang 等, 2025, p. 1) (pdf)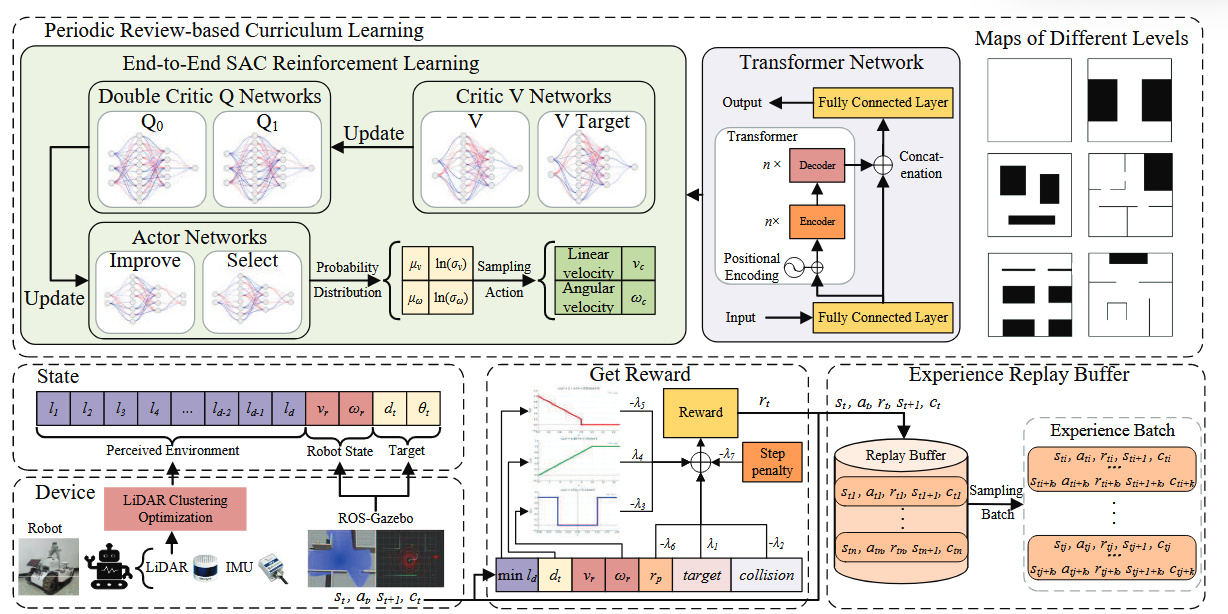
局限
-
它们普遍只依赖当前观测进行决策,而忽略了历史信息的重要性。在实验中发现,机器人容易陷入局部最优或“原地徘徊”状态
-
为了使RL策略具有更好的泛化能力,通常需要在复杂环境中训练,但这会带来训练不稳定、发散风险高的问题,此外,RL算法常依赖大规模CNN来处理LiDAR或图像数据,进一步加剧了收敛难度
内容
本文将Transformer的时序建模能力融入SAC框架,使机器人能够同时利用当前状态与历史状态信息。
AE问题可被建模为一个马尔可夫决策过程:
S:机器人在时间步 ttt 的状态为 sts_tst,
其中包含:
从激光雷达预处理得到的障碍物信息 l1,l2,...,ldl_1, l_2, ..., l_dl1,l2,...,ld
机器人的线速度 vrv_rvr
角速度 ωr\omega_rωr
以及目标点与机器人之间的相对距离 dtd_tdt 和角度 θt\theta_tθt。
根据策略 π\piπ,机器人选择一个动作 at=[vc,ωc]a_t = [v_c, \omega_c]at=[vc,ωc],
其中 vcv_cvc 为控制线速度,ωc\omega_cωc 为控制角速度(受运动学约束)
1️⃣ LiDAR数据预处理与聚类优化
但这种均匀划分忽略了一个关键事实:
机器人在前进方向的感知更重要。
因此作者提出一种基于机器人前进方向的非均匀分段方法。
公式 (1):LiDAR角度划分优化
设激光雷达的总分辨率为 ddd,
第 mmm 个分段的角度跨度为 Δθm\Delta \theta_mΔθm,则:
Δθm={4π3d−4,m<3d44π(3d−8)d(3d−4),m≥3d4\Delta \theta_m = \begin{cases} \dfrac{4\pi}{3d - 4}, & m < \dfrac{3d}{4} \\[10pt] \dfrac{4\pi (3d - 8)}{d(3d - 4)}, & m \geq \dfrac{3d}{4} \end{cases}Δθm=⎩ ⎨ ⎧3d−44π,d(3d−4)4π(3d−8),m<43dm≥43d
2️⃣ 奖励函数设计(Reward Function)
奖励函数由七个部分组成:
R={λ1,到达目标−λ2,发生碰撞−λ3⋅r1(ωr)+λ4⋅r2(dt)−λ5⋅r3(minld)−λ6⋅rp−λ7,其他情况R = \begin{cases} \lambda_1, & \text{到达目标} \\ -\lambda_2, & \text{发生碰撞} \\[6pt] -\lambda_3 \cdot r_1(\omega_r) + \lambda_4 \cdot r_2(d_t) - \lambda_5 \cdot r_3(\min l_d) - \lambda_6 \cdot r_p - \lambda_7, & \text{其他情况} \end{cases}R=⎩ ⎨ ⎧λ1,−λ2,−λ3⋅r1(ωr)+λ4⋅r2(dt)−λ5⋅r3(minld)−λ6⋅rp−λ7,到达目标发生碰撞其他情况
转向惩罚(Turning penalty)
r1(ωr)={1,∣ωr∣>0.50,否则r_1(\omega_r) = \begin{cases} 1, & |\omega_r| > 0.5 \\ 0, & \text{否则} \end{cases}r1(ωr)={1,0,∣ωr∣>0.5否则
→ 当机器人转向过于频繁或急促时施加惩罚。
目标接近奖励(Goal proximity reward)
r2(dt)={dt10,dt<101,否则r_2(d_t) = \begin{cases} \dfrac{d_t}{10}, & d_t < 10 \\ 1, & \text{否则} \end{cases}r2(dt)=⎩ ⎨ ⎧10dt,1,dt<10否则
→ 当距离目标小于10米时给予奖励,λ₄较小,防止奖励过大导致学习偏移。
障碍接近惩罚(Obstacle proximity penalty)
r3(minld)={1−minld,minld<10,否则r_3(\min l_d) = \begin{cases} 1 - \min l_d, & \min l_d < 1 \\ 0, & \text{否则} \end{cases}r3(minld)={1−minld,0,minld<1否则
→ 当障碍物距离小于1m时线性惩罚。
徘徊惩罚(Wandering penalty)
通过计算当前坐标与历史坐标的曼哈顿距离 dmd_mdm:
dm(x,y,xi,yi)=∣x−xi∣+∣y−yi∣d_m(x, y, x_i, y_i) = |x - x_i| + |y - y_i|dm(x,y,xi,yi)=∣x−xi∣+∣y−yi∣
若该距离小于阈值 δ\deltaδ,则记一次惩罚:
rp=∑i=1n1(dm(x,y,xi,yi)<δ)r_p = \sum_{i=1}^{n} 1(d_m(x, y, x_i, y_i) < \delta)rp=i=1∑n1(dm(x,y,xi,yi)<δ)
其中 1(⋅)1(\cdot)1(⋅) 是指示函数。
→ 当机器人重复出现在相近位置时,说明它“原地打转”,将被惩罚。
步长惩罚(Step penalty)
每个时间步都会固定扣除 λ7\lambda_7λ7,促使机器人更快到达目标。
目标是在最大化期望奖励的同时最大化策略熵,从而在保证任务完成的同时促进探索多样性。
SAC算法中引入了“温度系数” α\alphaα,用于平衡探索与利用。
其动态更新规则如下:在新环境初期,算法倾向于探索;随着训练进行,逐渐转向利用。
α=α01.0+τ⋅ne(8)\alpha = \frac{\alpha_0}{1.0 + \tau \cdot n_e} \tag{8}α=1.0+τ⋅neα0(8)
其中:
| 参数 | 含义 |
|---|---|
| α0\alpha_0α0 | 初始温度系数,默认为 1 |
| τ\tauτ | 温度衰减率,设为 1×10−61\times10^{-6}1×10−6 |
| nen_ene | 当前课程阶段完成的episode数 |
本文在SAC的三类网络(Actor、V、Q)中全面用Transformer替换传统的全连接层(FC),以捕获时间序列状态之间的依赖关系。
Transformer网络包含:
嵌入维度(embedding dim):1024
编码器与解码器层数:2层
每层注意力头(attention heads):8个
内部采用 Dropout + Weight Decay 防止过拟合。
网络结构
-
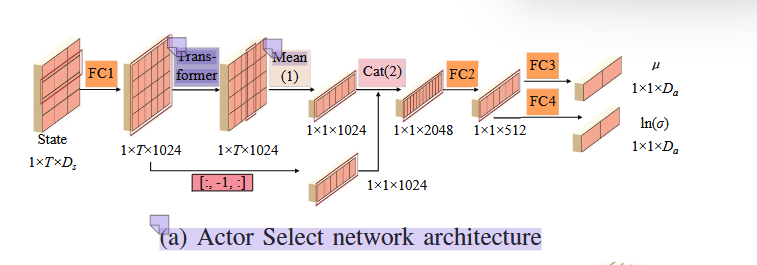
Actor(策略网络):
-
Actor Select:用于策略采样决策(inference)。
-
输入为最近 TTT 个状态序列:S=[st−T+1,st−T+2,...,st]S = [s_{t−T+1}, s_{t−T+2}, ..., s_t]S=[st−T+1,st−T+2,...,st]
-
通过全连接层(FC)升维: 1×T×Ds→1×T×10241 \times T \times D_s \to 1 \times T \times 10241×T×Ds→1×T×1024
-
输入到 Transformer 编码器,计算时间步之间的相关性(自注意力):
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dkQKT)V
-
输出序列进行平均(Mean pooling)以汇聚历史信息。
-
与当前时刻状态拼接(Concat),得到融合历史与当前的特征向量。
-
经过两层全连接网络输出:
-
动作均值 μ\muμ
-
动作标准差的对数 ln(σ)\ln(\sigma)ln(σ)
-
最终动作通过采样得到:
at=μ+σ⋅ϵ,ϵ∼N(0,1)a_t = \mu + \sigma \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, 1)at=μ+σ⋅ϵ,ϵ∼N(0,1)
-
-
-
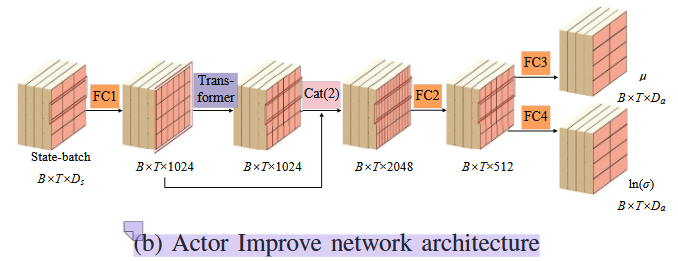
Actor Improve:用于策略更新阶段(从经验池中采样进行优化)
-
输入为从经验回放池(Replay Buffer)采样的状态序列批次 B×T×DsB \times T \times D_sB×T×Ds
-
经过Transformer后拼接原始状态,以保持原状态特征,再输入到Critic网络学习
-
-
两者参数共享
-
-
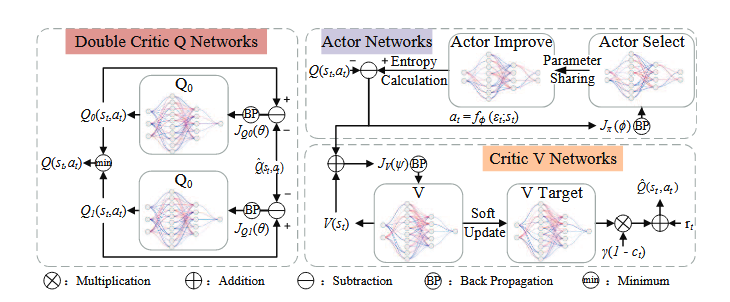
Critic-V(状态值函数):用于估计当前状态价值 V(st)V(s_t)V(st) 与目标状态价值 V(st+1)V(s_{t+1})V(st+1)。
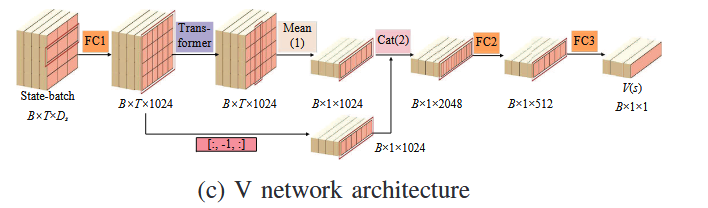
-
输入状态序列 → 输出 V(s)V(s)V(s)
-
目标网络参数通过软更新获得:
ψ′←τψ+(1−τ)ψ′\psi' \leftarrow \tau \psi + (1-\tau) \psi'ψ′←τψ+(1−τ)ψ′
-
-
Critic-Q(动作值函数):包含两套独立的Q网络 Q1(s,a)Q_1(s,a)Q1(s,a) 与 Q2(s,a)Q_2(s,a)Q2(s,a)。
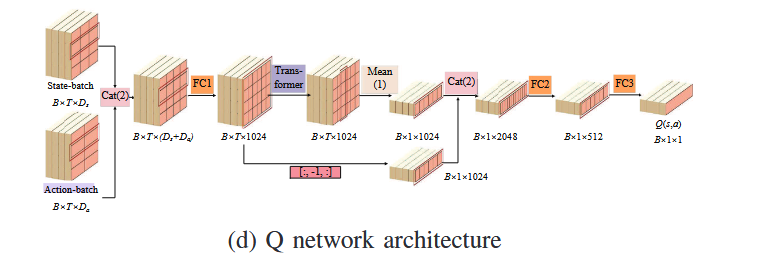
-
输入状态-动作序列 → 输出 Q(s,a)Q(s,a)Q(s,a)
-
使用双Q网络结构:Q1Q_1Q1 与 Q2Q_2Q2,取较小者以减少过估计。
-
更新目标为二者的最小值:
Q(s,a)=min(Q1(s,a),Q2(s,a))Q(s,a) = \min(Q_1(s,a), Q_2(s,a))Q(s,a)=min(Q1(s,a),Q2(s,a))
以减少Q值过估计问题(Overestimation bias)
-
-
SAC整体优化目标函数
目标是最大化以下带熵的期望回报:
J(π)=∑tE(st,at)∼π[r(st,at)+αH(π(⋅∣st))]J(\pi) = \sum_t \mathbb{E}_{(s_t,a_t)\sim \pi} \left[ r(s_t,a_t) + \alpha H(\pi(\cdot|s_t)) \right]J(π)=t∑E(st,at)∼π[r(st,at)+αH(π(⋅∣st))]
其中 H(π)=−logπ(at∣st)H(\pi) = -\log \pi(a_t|s_t)H(π)=−logπ(at∣st) 为策略熵。
此项促使智能体探索多样化动作。
🔄 课程学习机制(Curriculum Learning)
CTSAC 使用周期复习型课程学习策略:死胡同、随机动态障碍、被阻塞的路径等。
过程
-
从简到难,依次构造 nnn 个训练环境 e(1),e(2),...,e(n)e(1), e(2), ..., e(n)e(1),e(2),...,e(n)。
-
在每个阶段 jjj,回顾之前所有阶段 i≤ji\leq ji≤j 的环境。
-
采样概率为:
p(i,j)=i2∑k=1jk2p(i,j) = \frac{i^2}{\sum_{k=1}^j k^2}p(i,j)=∑k=1jk2i2
-
只有在当前阶段的成功率 > 阈值 β\betaβ 时,才进入下一阶段。
这种机制有效保留早期经验,缓解灾难性遗忘,避免因太快推进导致策略不稳定。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)