技术科普 | “你是谁训练的?”,让模型暴露“出身”的技术来了
当模型输出一句话时,它的“身份”也悄悄写在了边上,在大模型商业化加速、API 封装流行的当下,我们越来越难掌握模型的“真实来源”。而 RoFL 的出现,为这一难题提供了一个清晰而稳健的答案: 它不依赖模型内部参数、也不侵入训练流程,仅通过一组“巧妙提问”的句子,就能让模型自己说出——“我是谁”。这不只是一次技术手段的进步,更是一种理念的颠覆: 它让我们意识到,每一个模型的表达,其实都带着不可抹除的
模型不再只是冰冷的工具,它们更像是承载知识产权的“表达体”——背后是数百万美元的训练投入,是独有的数据选取、微调策略、架构调整,共同塑造出它对世界的理解方式。而这些,最终都融进了它回你的每一个答案里。
你发布的模型,也许正以另一个名字,在某个不知名的 API 中运行。要证明“那是我训练的”,谈何容易——尤其当你面前只有一个不透明的接口,看不见代码、摸不到参数,更别提接触模型权重。
这一次,我们介绍一项由哥伦比亚大学与 Meta 研究者提出的技术突破,它不需要访问模型内部,不涉及任何权重提取或架构探测,只靠“对一组特殊问题的回答”,就能验证模型的归属。

当黑匣子变成产品,谁还能追得上它的「影子」?
在大型语言模型席卷产业格局的今天,我们面对的不只是智能工具,更是附带许可的知识产权资产。你发布的模型,也许已经悄然现身在某个同行的产品中,以另一个名字运行。而你,却无法证明:那是你训练的成果。
传统的软件领域,可以通过代码比对、哈希签名追踪抄袭者;但面对由数十亿参数构成的大模型世界,过去这些办法统统失效。
你看不见它的参数,也摸不到它的训练过程。对面只留给你一个冷冰冰的 API 接口。一问,它会答,但答什么、怎么答,似乎都泛泛而平——还能从中找到蛛丝马迹吗?
也许可以。语言模型虽是「黑箱」,但并非不留痕迹。每一句回答,都是它数亿次训练中形成的决策轨迹。那些轨迹虽然不能明面刻印,但会在面对某些特别构造的问题时,以一种专属于它的方式「露出破绽」。
是的,不是随便聊两句就能识别它是谁。破案的钥匙,藏在一组特制的问题与回答中。
也许是一串别人从不这么写的提示词,也许是一个极不自然的组合句,也许是一个只有它,才会那样解读的模糊表达。这些精心设计的“提示”——就像给模型下的一道“谶语”。别的模型看不懂,它却本能地回应了你想要的那句话。这,便是指纹。
RoFL 的核心思想在于:通过启发式的提示优化策略,生成一组精巧设计的指纹触发器,使得模型在接收到这些特定输入时,会稳定地产生带有其“独有指纹”的回应,从而实现对模型身份的识别。我们可以在完全黑箱的接入方式下,仅凭互动,验证一个模型是否与原始版本属于同一“血统”。而这个过程,无需篡改网络结构,也无需任何内嵌水印——它是非侵入的、保真度极高的身份识别方式。

启发式提示优化策略:通过该策略优化蓝色部分提示,使得模型在该模板和蓝色提示的基础上能够输出“预设回答”(红色部分)
模型的回答并不是随机游走在语言迷雾中的回声。相反,那些看似随性的选择,反而是在练习成自然之后,屏不住地显露「出身」。
哪怕只是几次对话,只要你问对了问题,它就会露出熟悉的模样。
从语言中“取证”:模型指纹是怎么做出来的?
在前文我们提到,RoFL 的关键在于:生成一组可以被模型“认出”的提示词——我们称它们为“指纹触发器”。
而这组特殊提示,不是随便几个离谱的问题,更不是简单的手工设定,而是通过一套系统性的搜索与优化流程,从海量组合中“挖”出来的——这一部分,就是 RoFL 方法的核心。 我们不妨先看一眼它的整体框架:
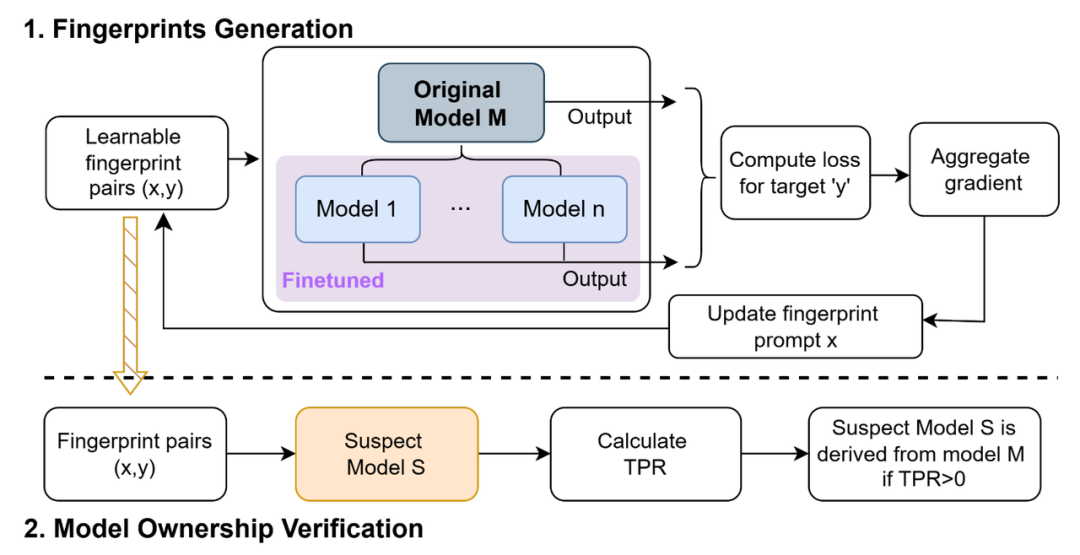
过程分为生成与验证两个阶段,通过优化“形如乱码的输入提示”来生成稳定而唯一的模型指纹,在黑盒访问下即可验证模型身份。
-
1.指纹生成阶段(Generation)
-
输入:原始模型 M
-
输出:多组指纹对(prompt, response)
-
算法组件:初始化 + GCG 优化 + 多模型协同学习
-
-
2.指纹验证阶段(Verification)
-
输入:怀疑模型 S + 指纹(x, y)
-
输出:TPR 指标(是否命中)
-
Step 1:如何打造一枚“只属于你的指纹”?——Fingerprint Generation
RoFL 设计的指纹,是一对 prompt–response 对:也就是一串特殊输入 x,能被特定模型唯一解读为某个输出 y。 而要确保这对(x, y)具备唯一性与鲁棒性,研究者提出如下优化方法:
1.指纹的 Prompt 要够“稀有”(Unlikely)换句话说,这些提示词 x 不应该在传统训练语料中频繁出现。它最好是些明明读起来有“乱码感”,但模型依然能正常处理的混合信息。这样生成的回答,才更可能反映模型自身隐含的“偏好路径”。
2.Response 要稳定(Consistent)面对这个稀有提示词,目标模型应始终产生同一个输出 y,而其他模型则无法还原。 那么这样的(x, y)组合,从哪里来?
📍研究者的方法:离散优化 + 梯度引导的搜索策略
我们从随机初始 prompt 出发,优化它使得模型在面对该 prompt 时产生指定输出。 这个优化采用了 GCG(Greedy Coordinate Gradient)算法,具体过程如下: 目标优化函数为:
其中:
-
是我们要优化的 prompt
-
是系统提示(system prompt)
-
是目标响应
-
为模型的下游输出概率分布
我们希望找到一个输入 x,它在预设系统 prompt 下,生成 y 的概率最大。
Multi-task Prompt Optimization:让指纹更鲁棒的秘诀
为了确保这些 prompt 能在多种环境中的“衍生模型”上依然有效,RoFL 提出了一个非常重要的策略:多任务优化(Multi-task Prompt Optimization)
现实中,模型很可能被做过各种微调:
-
增加了中文回答能力(如 Llama2-Chinese)
-
精调了医学对话(如 Meditron-7B)
-
或者通过 LoRA 等参数高效调器进行了上线部署
那么,我们如何确保一次优化得到的 prompt,在这些“变体身上”也依旧生效?答案是:让模型家族一起参与优化!也就是说,研究者将多个派生版本的同一模型(M₁′、M₂′…)一并加入指纹生成阶段,寻找一个能够在这些模型中都产生「相同输出 y」的 prompt:
即:我们找一个 prompt,能让多个下游版本 M′ 在多个系统提示 h 下,都稳定输出 y。 这种集体共识式的优化方式,使得生成的 prompt 在面对不同微调、不同行为模版下,依然具有显著辨识度,极大提高了 RoFL 验证的鲁棒性。

图如论文中图 2 所示,展示指纹 prompt 在无系统提示(无 system prompt)与 Vicuna-style 系统提示(“A chat between a helpful assistant…”)两种设置下,均输出相同 answer,验证鲁棒性强。
Practical Considerations:让 Fingerprint 真正落地的细节工程
生成思路已成,RoFL 的工程策略也为模型实用部署考虑得细致入微。
-
Multi-Trial Strategy:为确保找到真正鲁棒的 prompt,不轻易中止优化。在原始 GCG 算法中,只要第一次在 base 模型上生成成功(匹配 y 即可),优化就可以结束。但 RoFL 发现,这样产生的 prompt 不够健壮。于是他们引入了 Multi-Trial 策略,要求“prompt 在多轮试验中都要成功”,以避免局部最优。
-
Uniqueness Validation:避免“泛指纹”误判。有没有可能,我们优化出来的某个(x, y)组合,其实别的模型也能答出来?别慌,RoFL 在验证阶段加入了“交叉验证”机制: 对每组(x, y)指纹,不光在目标模型上测试,还会对多个无关模型进行验证;只要有一个非血缘模型“蒙对了”,这组指纹就会被剔除。
与其他水印&指纹方法(如指令微调来植入)不同,RoFL 仅使用输入输出数据层的信息,不对任何底层变换做干预,模型性能完整保留,安全性与实用性并重。
方法小结 — 一组能“唯一还原”,还能“稳定输出”的 fingerprint 它需要满足:
-
模型本体和其全部变体都能还原相同 y
-
黑箱条件下也能触发
-
其他非同源模型极难猜中
-
可大规模批量获取,且无侵入性
它不是一段话,而是一种「表达方式」的习惯。正如每个人都有自己写字的布局特征,每个大模型对 rare prompt 的回答方式,也终究藏着独一无二的痕迹。
在 RoFL 的世界里:你说什么,怎么说,什么时候说,都有迹可循。下一部分,我们将走入实验章节,看看 RoFL 如何在多种模型、数十种微调配置中,牢牢定位出模型的“出身记号”。
有效性分析
方法再巧妙,生成再精致,最终还是要落到一个简单的问题:“它能不能准确认出自己家那一位?”
换句话说,当我们用 RoFL 提取出的指纹去测试原始大模型时——它是否能牢牢开口说出那句“属于我”的回答?验证是否命中本家模型,这就是「指纹有效性」的核心考量。为此,作者在四个主流开源模型上展开了实验检验,并分别在每个模型上生成10组指纹对(prompt, response),然后再回喂这些 prompt 看模型是否能给出预设 answer。 结果如下 ——

Table 2 展示了四个模型在四种不同指纹方案下的 True Positive Rate(TPR),也就是“模型能不能认出自己指纹”的成功率。
对比可见:
-
GCG(最基础版本)表现较差,TPR在个别模型仅为25%~80%不等。
-
IF-Emb(只在embedding层做微调)表现中等,受限于参数冻结,TPR浮动幅度大。
-
IF-SFT(全参数微调)虽性能高,但会对模型表现带来性能下降风险。
-
而 RoFL 在全部模型上都拿下了 100% 的 TPR,且无需修改任何模型参数。
也就是说:RoFL 能精准在“本体模型”上识别指纹,给定触发 prompt,生成的输出准确还原 response,不仅稳定,而且对模型没有任何干扰。
接下来让我们看看:面对那些经过微调、压缩、强化对话能力之后的“衍生模型”,RoFL 又能表现如何?模型经历岁月洗礼后,指纹还在不在?
鲁棒性分析
在现实场景下,一款语言模型的旅程往往不止于“发布”。 它可能被改头换面,例如增量训练~ 那么问题来了:「如果你训练的模型被人拿去“加工”了一遍,还能认出来吗?」
这就是 RoFL 所强调的第二项核心能力——鲁棒性(Robustness)。也就是说,一组指纹如果只在“出厂模型”上有效用,一旦换了包装就失灵,那它的价值也就大打折扣。于是,作者用 RoFL 的指纹跨模型验证,以衡量:这些指纹在模型被微调或改造之后,还能维持多少匹配率?
他们挑选了与前文相同的四款主流大模型,并为每款模型各自训练五个不同“变体模型”版本,即通过增量训练来完成这个步骤~再将原始模型生成的指纹(即未改动时生成的 prompt–response 对)输入这些“变体”,看看匹配率还能维持多少。你也许会惊讶于结果。 结果如下 ——

我们发现,在几乎所有情况下,RoFL 都展现出极强的鲁棒性:
-
对 LLaMA 2 7B,TPR 高达 100%
-
对 LLaMA 13B、LLaMA 3 8B、Mistral 7B,TPR 稳居 93~100% 区间
-
显著优于 IF-SFT、IF-Emb、GCG 等方法,其它方法在微调后的 TPR 普遍会下滑 30%以上
换言之,RoFL 是能“追着模型血脉认人”的:即使它在形式上换了壳,它的表达边界不会说谎。只要是“我训练的”,我就找得出来。
接下来的章节,我们将看到 RoFL 面对真正“野外部署”的模型,包括多个 Hugging Face 现有模型,如何用指纹实现一次次“黑箱追踪”成功命中。
「认亲」易,「错认」难:验证 RoFL 的唯一性
好的指纹不仅要能“认出自己家的人”,更重要的是 “不会错认陌生人”。这,就是指纹方案中至关重要的「唯一性」(Uniqueness)。Table 4 正是为了验证这一点。
作者将 RoFL 生成的指纹用来测试:
-
✅ 一组与原始模型确有血缘关系的衍生模型(如 LLaMA 2 7B 的多语种版本、医学微调版本等)
-
❌ 以及五个完全无关的模型(如 Falcon、MPT、Guanaco 等)
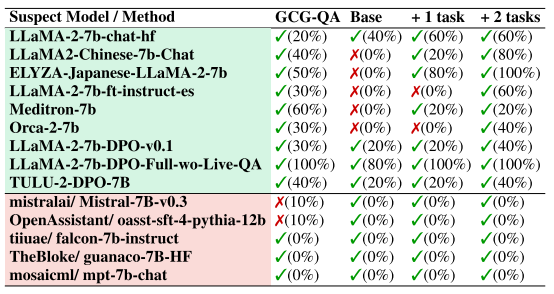
结果非常可靠:
-
对“相关模型”,RoFL 准确识别率达到了 100%,覆盖所有变体;
-
对“无关模型”,完全没有误判,FPR 为 0%;
-
相比之下,其他方法(如 GCG-QA)误判率明显偏高,唯一性较弱;而只用 base 模型学指纹的方案,更容易被无关模型“误打误撞”触发。
RoFL 不仅能牢牢记住“亲生模型”的表达特征,还有效避免了“模糊相似”的大量模型被误认,具备强辨识力。
「多任务」不是锦上添花,而是指纹稳如磐石的关键
前文我们提到,RoFL 的指纹生成采用了一种「多任务优化策略」(multi-task prompt optimization):不只在一个模型身上学指纹,而是让多个衍生模型一同参与“标签对教育”,从而学到更加通用的“语感偏好”。
那这个设计,真的有必要吗?还是说,它只是一次工程上“谨慎一些”的富余设置?
为此,作者专门做了一轮消融实验。对照的核心逻辑就是:把 Prompt 优化分别限制在以下三种条件下:
-
仅使用 base 模型(不引入任何微调后模型)进行指纹学习
-
使用 base + 一个 fine-tune 变体(+1 task)
-
使用 base + 两个 fine-tune 变体(+2 tasks)
然后,再用这些生成的指纹,分别去验证更多不同下游变体——看看鲁棒性是否随“多任务学习”增加而提高? 结果如下 ——
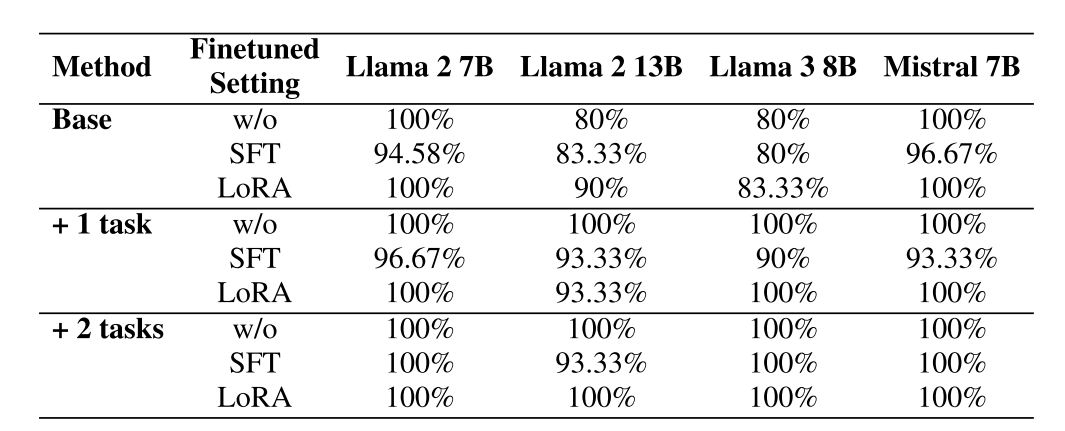
实验结果很明确:
-
在 Base-only 设置下,部分模型 TPR 会降到 80% 左右,且在 SFT / LoRA 情况下容易“打滑”。
-
当使用 base +1 task 时,TPR 大幅提升,基本都维持在 90%~100% 区间。
-
而 +2 tasks 理论上是“合力优化”,几乎在所有模型与设定中拿下 100% TPR,完全覆盖所有微调方式!
这说明:Multi-task Prompt Optimization 不只是“管得严”那么简单,而是真实提升了指纹的「横向稳定性」——即便面对未知的微调模型,只要“血脉未断”,指纹依旧能锁定目标。 为何会这样?
原因其实不难理解:在多任务中优化,就是“逼模型在更复杂的干扰项下保持回答一致性”。这本质是一次“打磨泛化能力”的过程,让 prompt 忽略掉表层模板与微调语气,只捕捉源于原始模型的“表达肌理”。
下一节,我们将深入实际部署情景,看 RoFL 是否也能在公开平台、已上线模型中实现准确追踪?那些你以为随机运行的 API 响应,或许也藏着谁训练了它的答案👇
温度升高,指纹还清晰吗?
Figure 3 探讨的是另一个现实中的关键变量:模型“说话时”的生成温度(temperature)。作者测试了从 0 到 0.9 的不同温度设置,观察 RoFL 指纹在高随机性的生成环境下,是否依然能稳定命中。
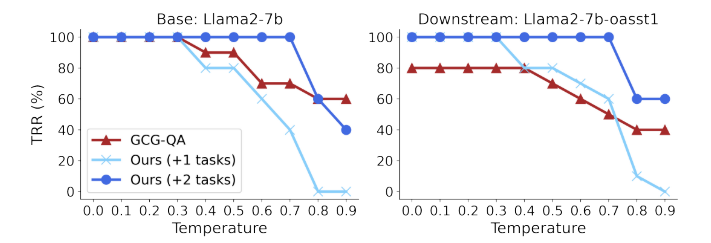
结果显示:
-
✅ RoFL(+2 tasks)在 0.7 以下均保持 100% 的命中率(TPR)
-
⚠️ 到了 0.8 以上才出现轻微下滑,但整体仍然稳定可用
也就是说,即便模型生成变得更“不确定”,RoFL 的指纹也几乎不会被扰乱。
你换话术,我识本体:RoFL 抵得住提示词“变脸”
Table 6 的目标是检验: 如果你换了 prompt 模板模型 —— 从 LLaMA 默认风格,变成 Alpaca 式指令,或 ChatGPT 风格的对话框架 —— 指纹还管用吗?
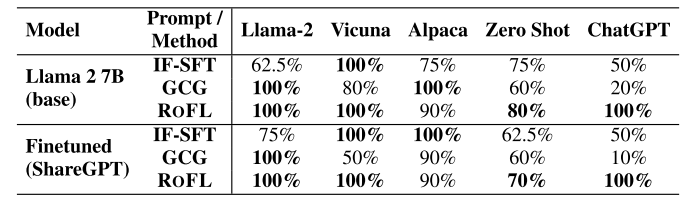
实验设置包括五类常见模板:LLaMA 原始、Vicuna、Alpaca、Zero-shot、ChatGPT 口吻 在 base 模型与微调模型(如 ShareGPT)上分别测试 RoFL 与几种 baseline 的 TPR 结果一目了然:
-
RoFL 在所有 prompt 模板下 TPR 均保持在 70%~100% 区间,变化最小
-
尤其在 ChatGPT 等诱导性模板中,RoFL 表现依旧稳健
-
对比来看,IF-SFT 与 GCG 在 prompt 模板变化后性能下滑明显,鲁棒性较弱
总结一句:不论你用哪种提示框架包装,只要底层模型还是那一个,RoFL 都有办法“读出”它的原声。
总结
当模型输出一句话时,它的“身份”也悄悄写在了边上,在大模型商业化加速、API 封装流行的当下,我们越来越难掌握模型的“真实来源”。而 RoFL 的出现,为这一难题提供了一个清晰而稳健的答案: 它不依赖模型内部参数、也不侵入训练流程,仅通过一组“巧妙提问”的句子,就能让模型自己说出——“我是谁”。
这不只是一次技术手段的进步,更是一种理念的颠覆: 它让我们意识到,每一个模型的表达,其实都带着不可抹除的“训练记忆”——那是属于数据、属于算法、属于训练者的痕迹。
RoFL 提供了一种前所未有的“数字签名”方式,把模型本体变成自己的证明本身。 而这,意味着未来的大模型可能不只是要问“能不能做”,还得先回答一句——“你是谁?”
来源:RoFL: Robust Fingerprinting of Language Models (arXiv 2025.05)
链接:https://arxiv.org/abs/2505.12682
内容来源:IF 实验室

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)