豆瓣读书scrapy爬虫项目创建运行详细教程
进行修改,运行,发现还是没有,接下来打开豆瓣找到要爬取的地方,鼠标右键点击检查,找到你需要的代码复制下来给豆包,并表达你的要求。通过豆包给出的内容对相应的部分进行修改,随后运行,然后会发现会运行错误,接下来将错误的部分复制下来给豆包,再次进行询问。进行修改,运行,而后发现出现了csv文件但文件中没有图书的名字,继续询问豆包。1、打开豆瓣,找到你想爬取的内容,例如要爬取豆瓣中读书中前五个图书的名字。
一、创建项目
1、下载anaconda、python、vscode
2、检查是否存在conda。通过Windows+R打开搜索栏输入cmd
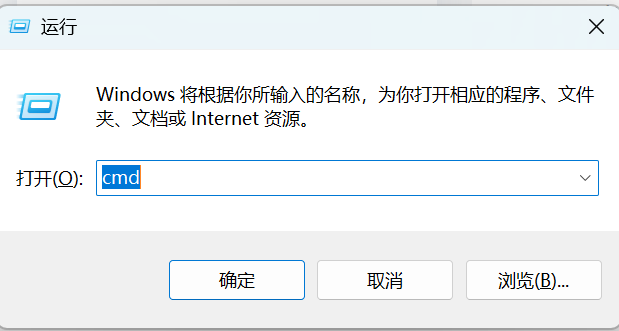
命令页面打开后,输入conda回车
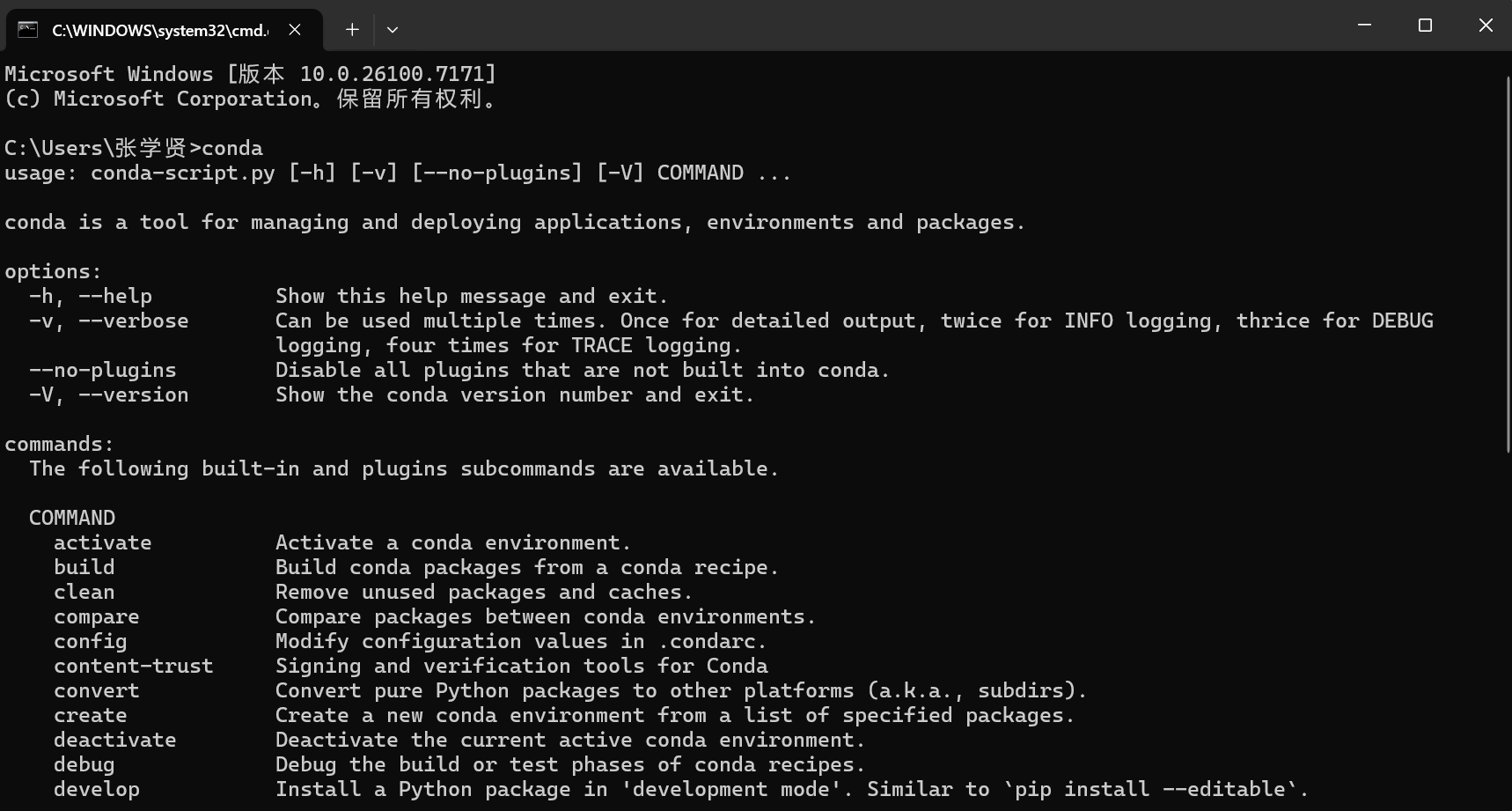
若没有,按照以下流程进行配置:
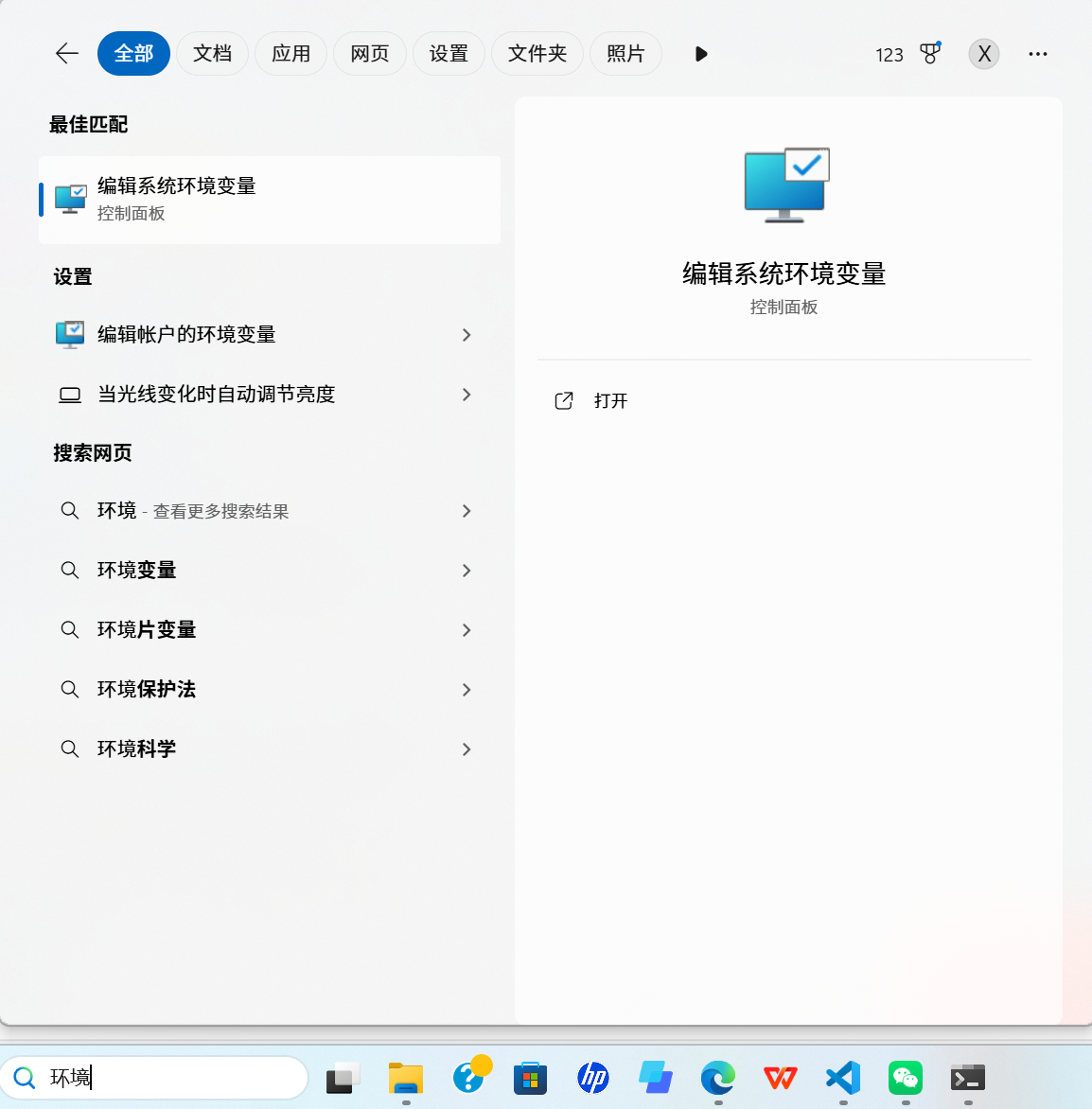
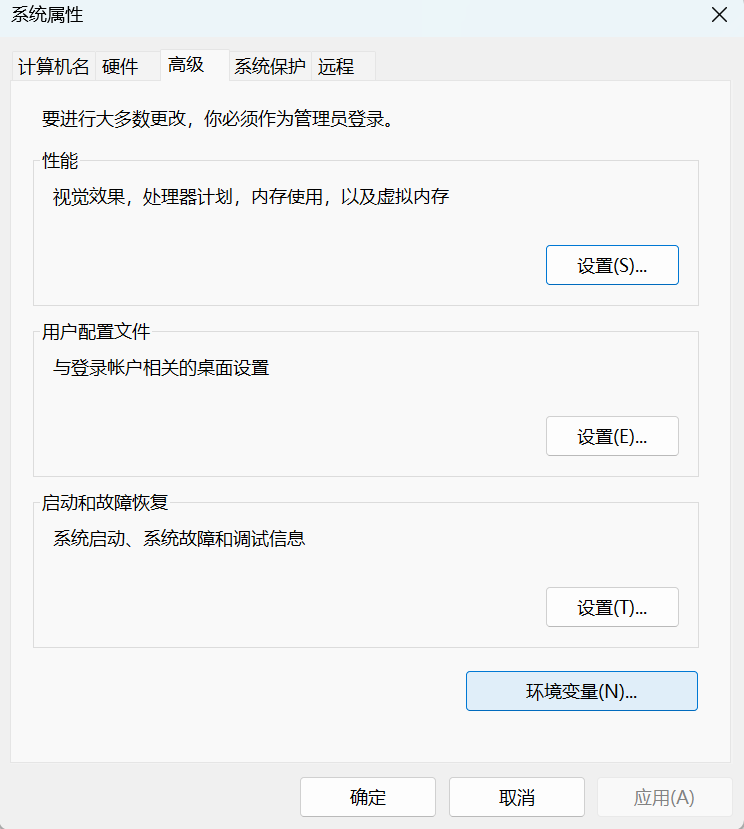
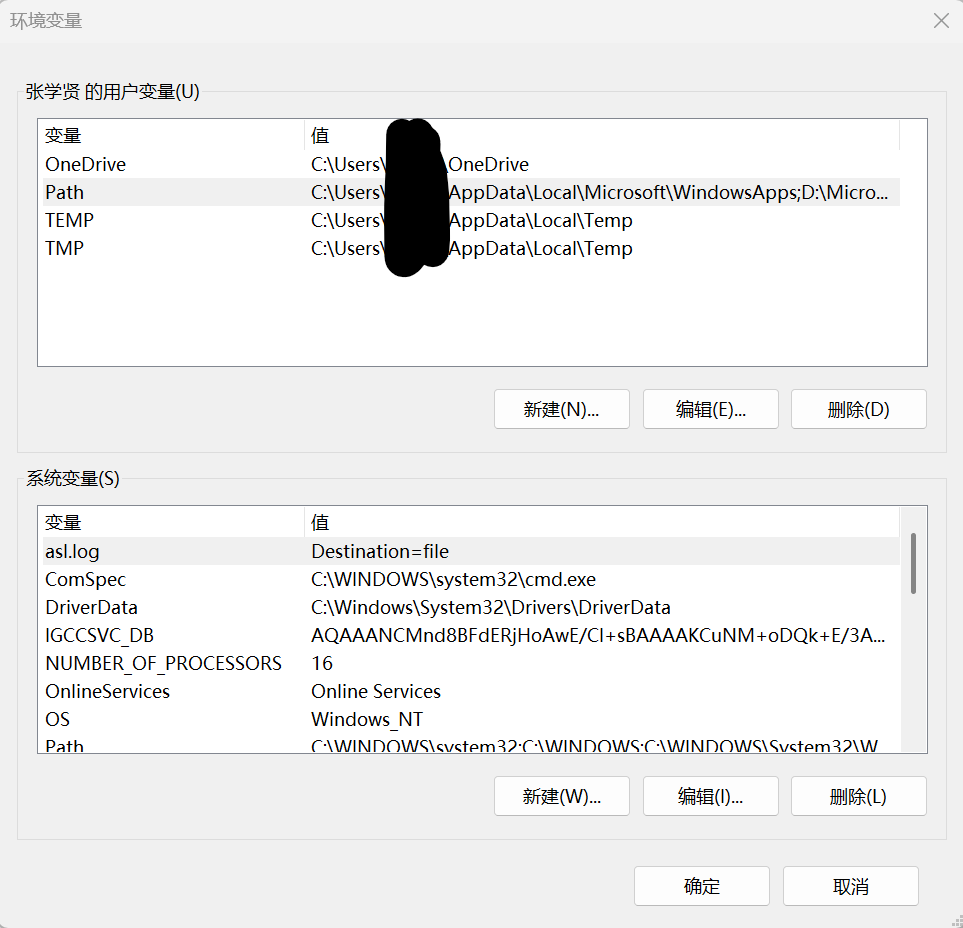
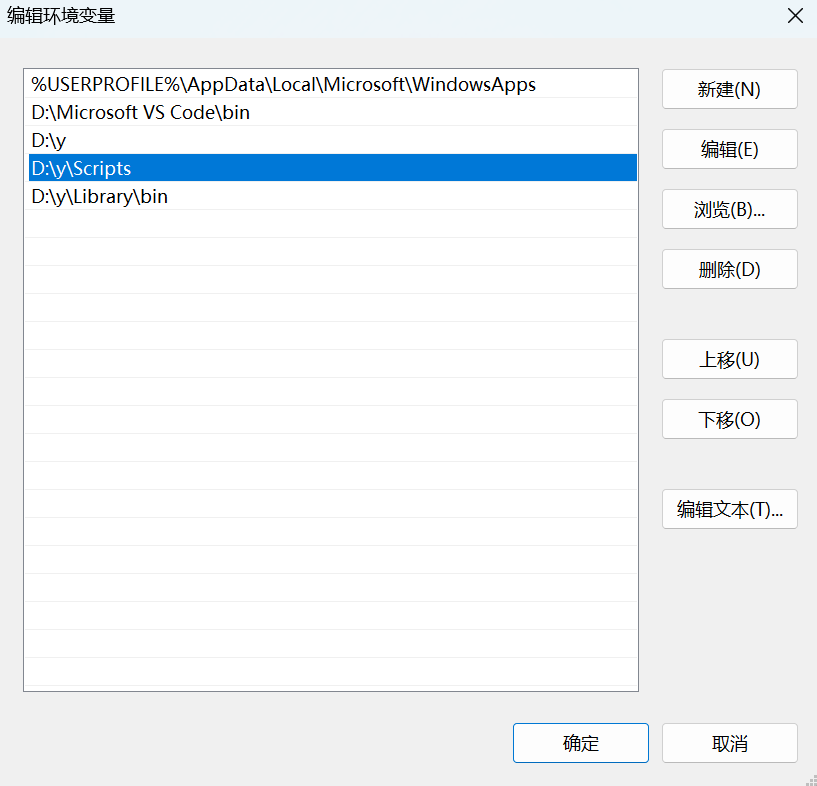
加入两个网址,点击确定,在重新打开cmd输入conda就会存在conda。
3、按照这个网址https://blog.csdn.net/m0_37192554/article/details/153347936?spm=1011.2415.3001.5331对vscode进行python环境的配置
4、输入pip install scrapy 下载scrapy,下载好后重新打开终端输入conda activate ai–py38进入Python环境
5、开始创建项目(首先要新建一个文件夹,在文件夹中创建项目)
(1) 创建项目
scrapy startproject douban_book
(2) 进入项目目录
cd douban_book
(3)创建爬虫文件(爬虫名:book_literature,允许爬取的域名:book.douban.com)
scrapy genspider book_literature book.douban.com
二、进行爬虫
1、打开豆瓣,找到你想爬取的内容,例如要爬取豆瓣中读书中前五个图书的名字。
2、打开豆包,将网址复制下来传给豆包并进行询问,就会得到以下
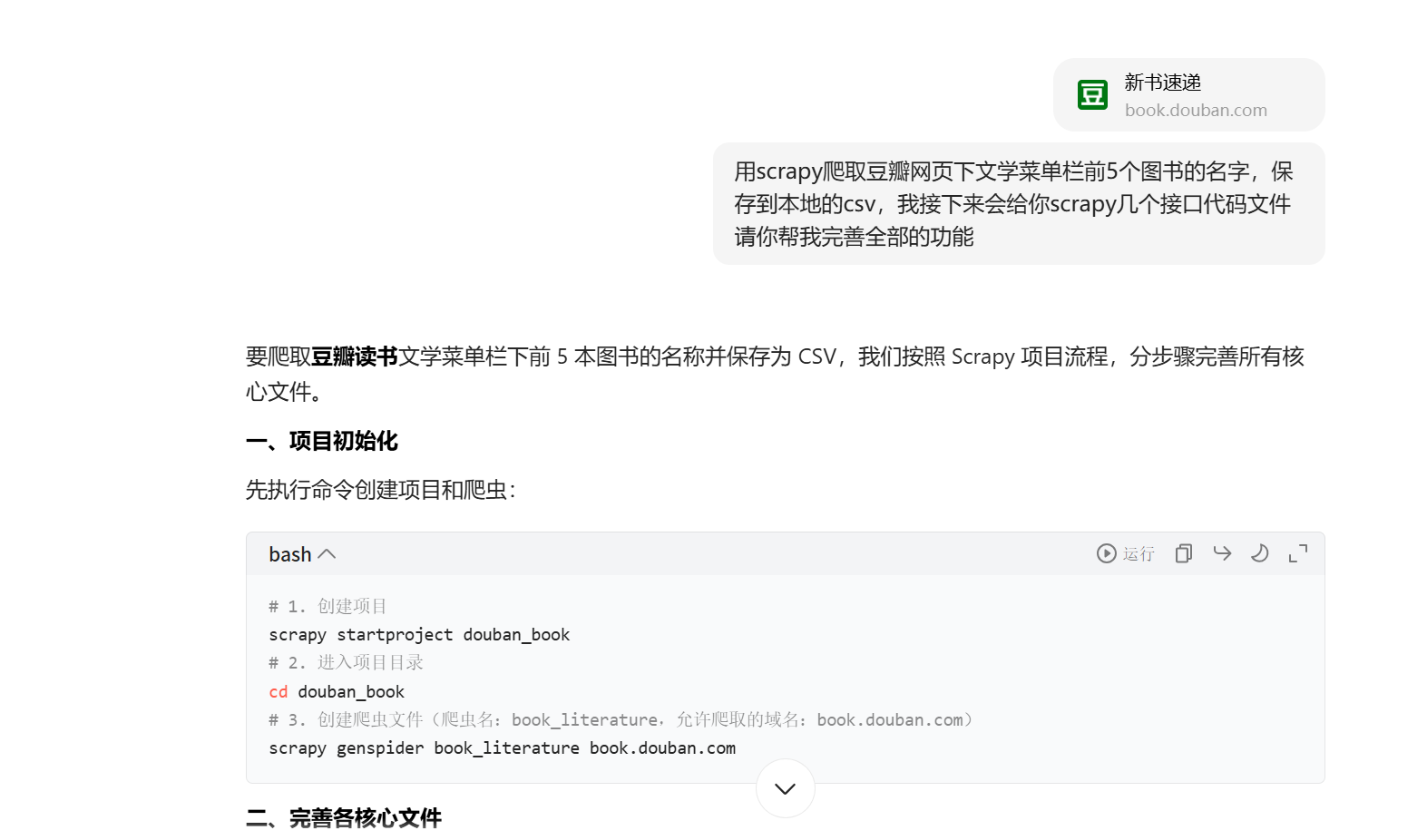
通过豆包给出的内容对相应的部分进行修改,随后运行,然后会发现会运行错误,接下来将错误的部分复制下来给豆包,再次进行询问
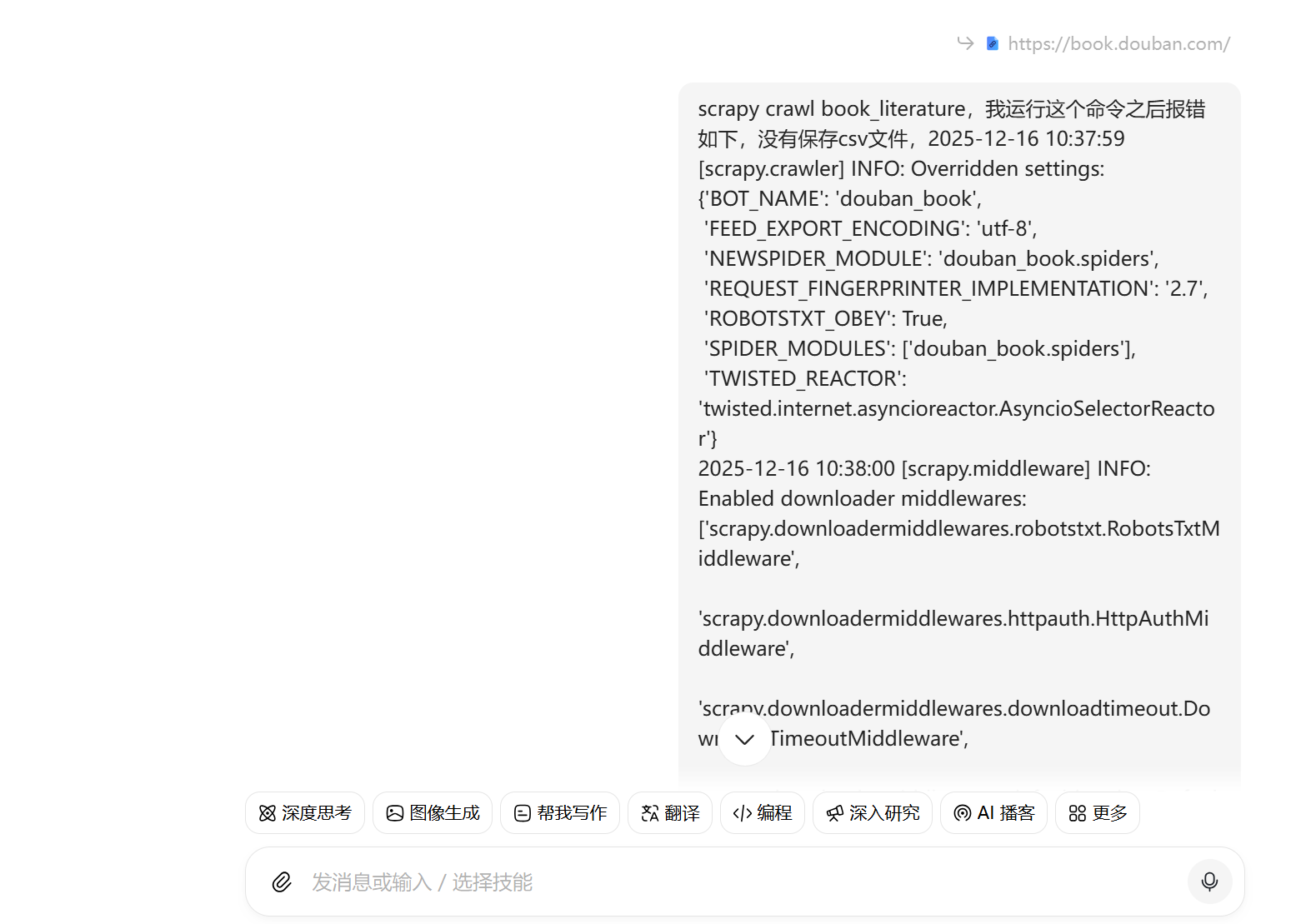
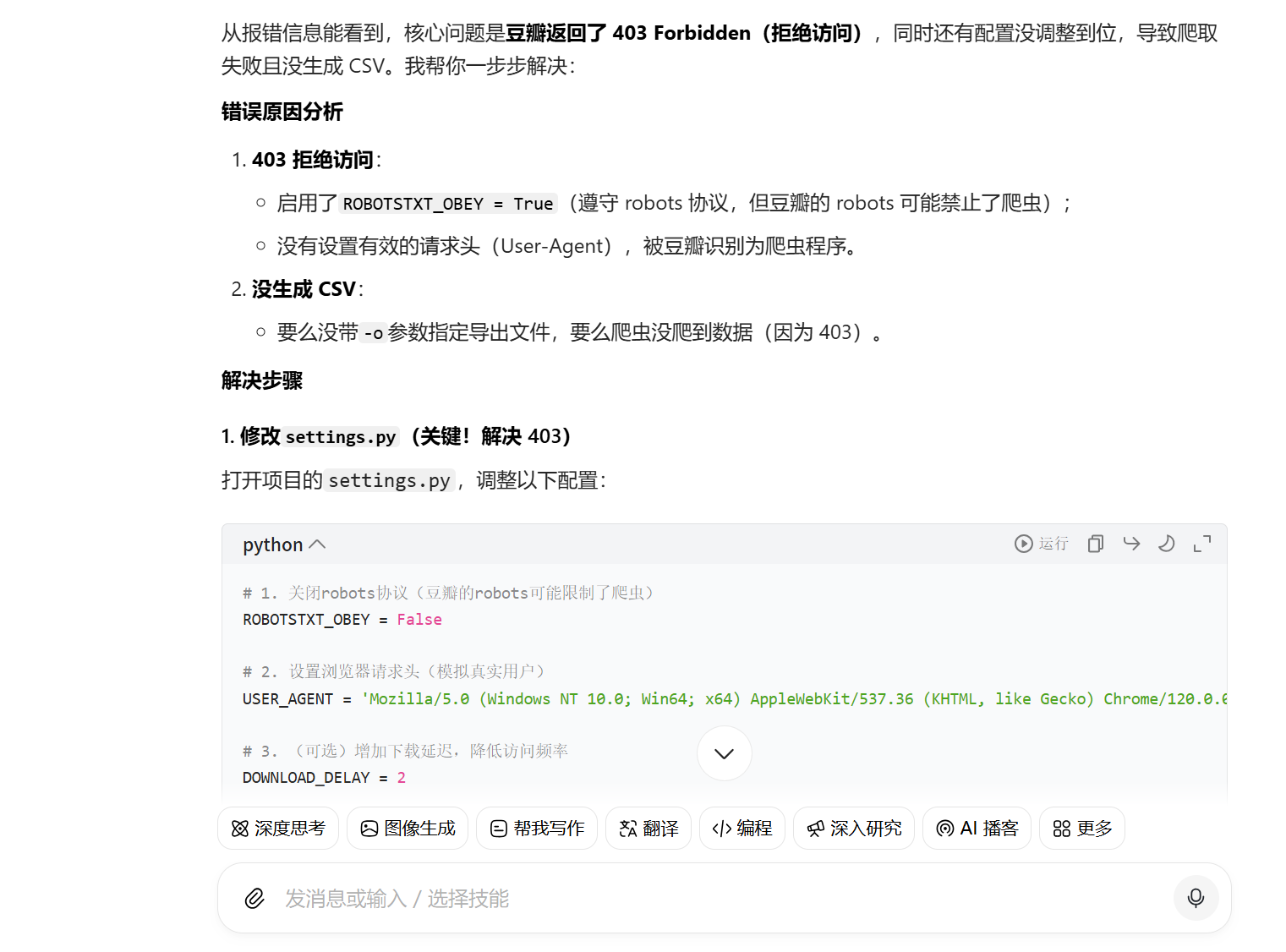
通过豆包给出的答案再次进行修改,随后运行,再次错误,继续询问
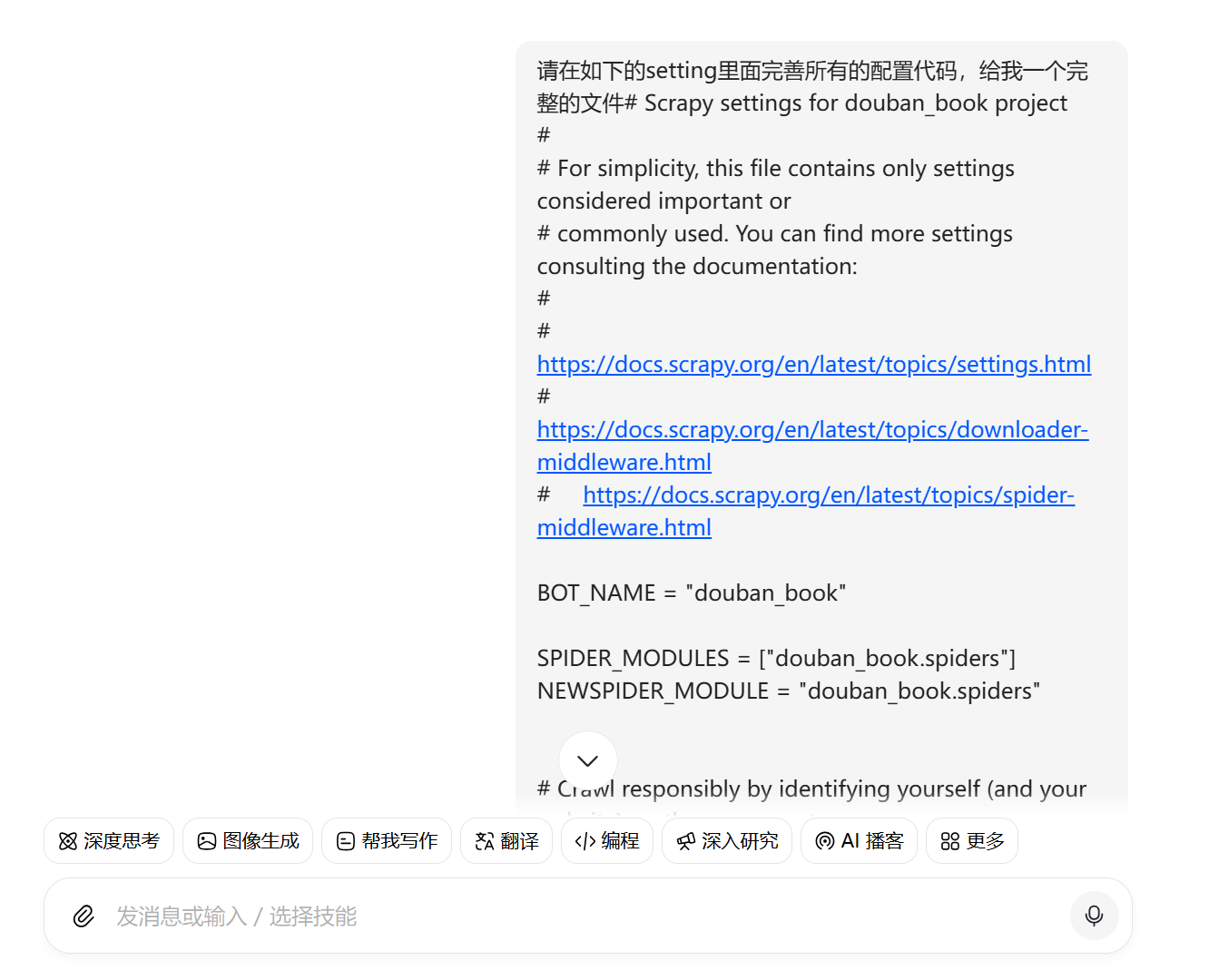
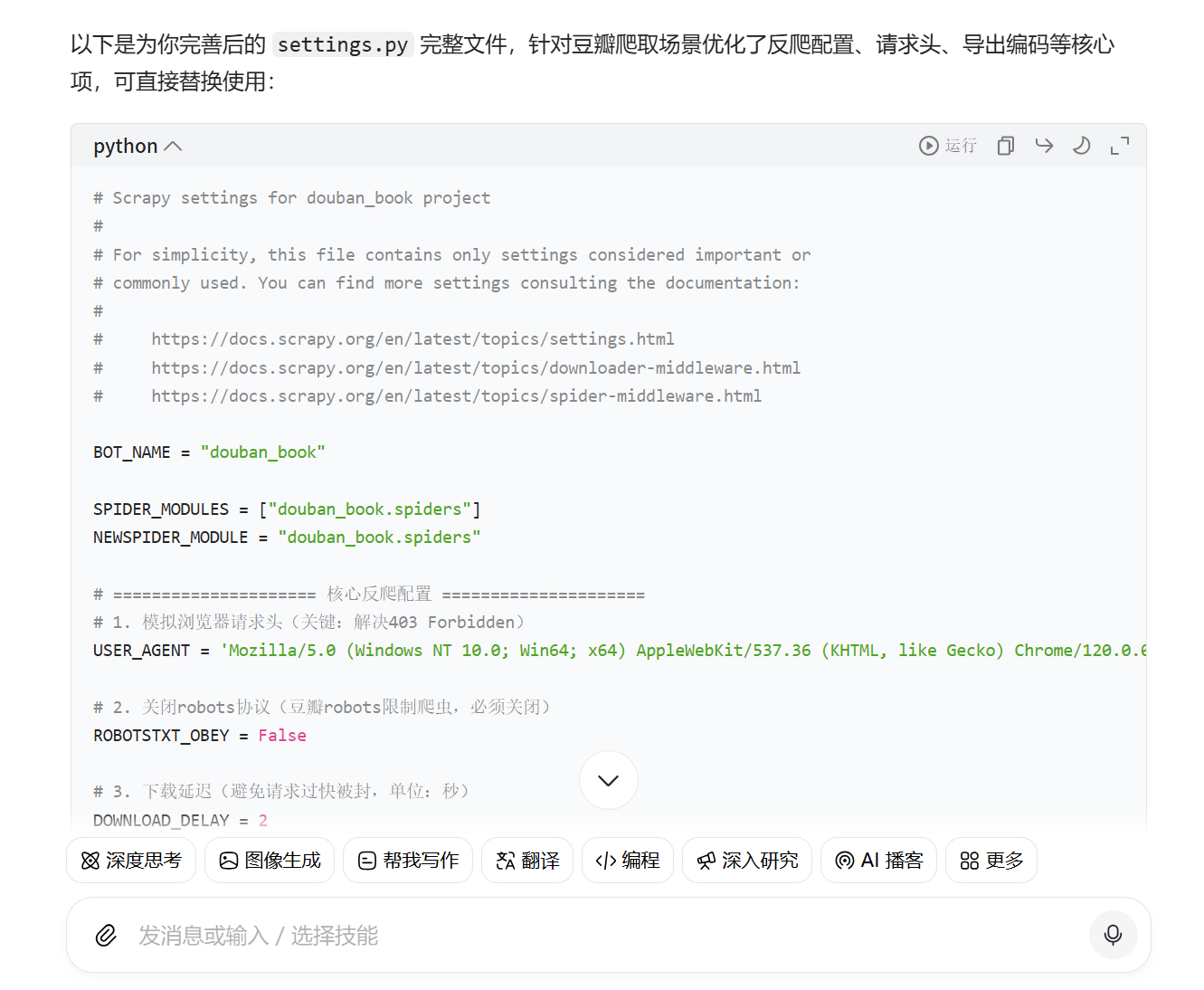
进行修改,运行,而后发现出现了csv文件但文件中没有图书的名字,继续询问豆包
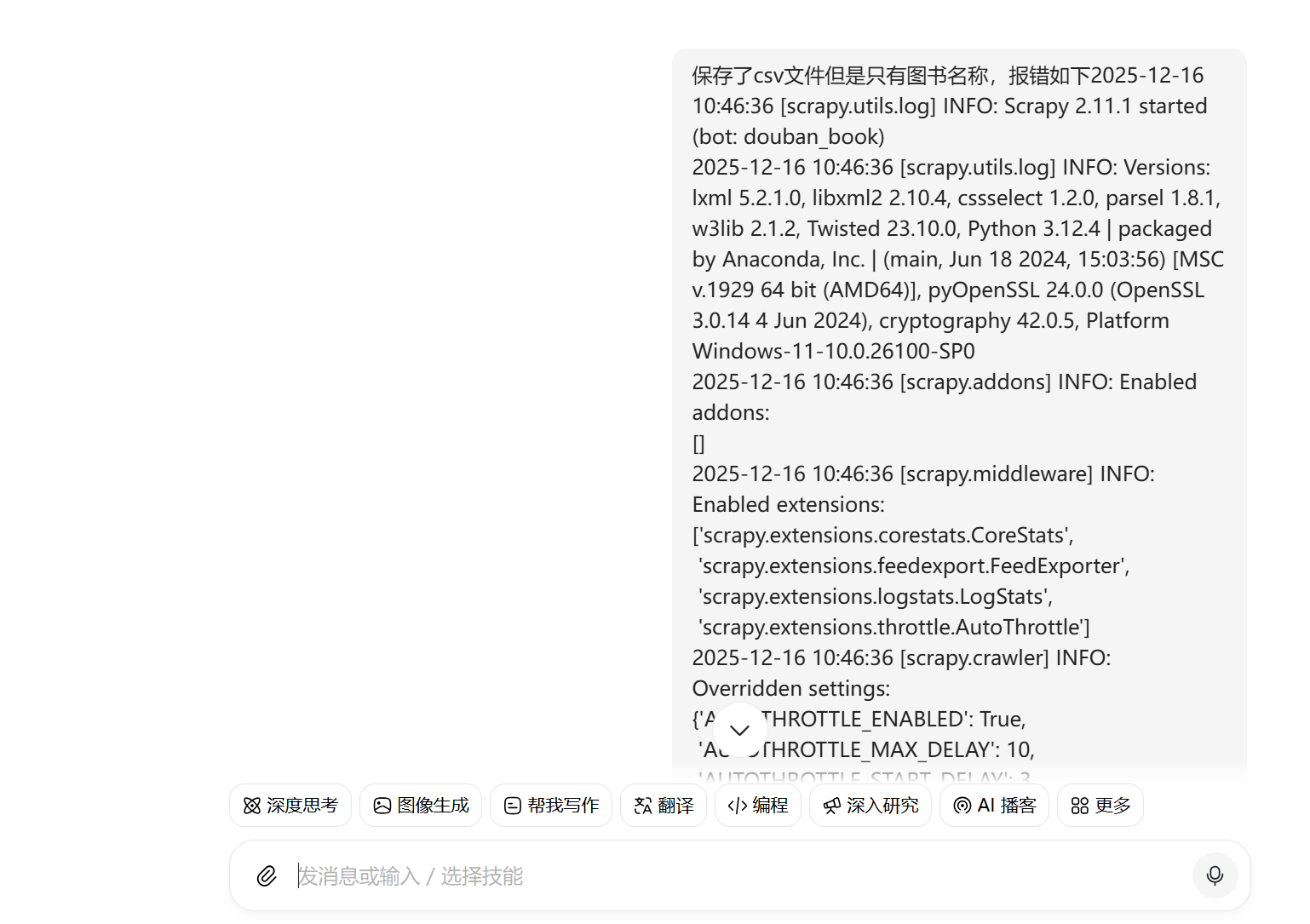
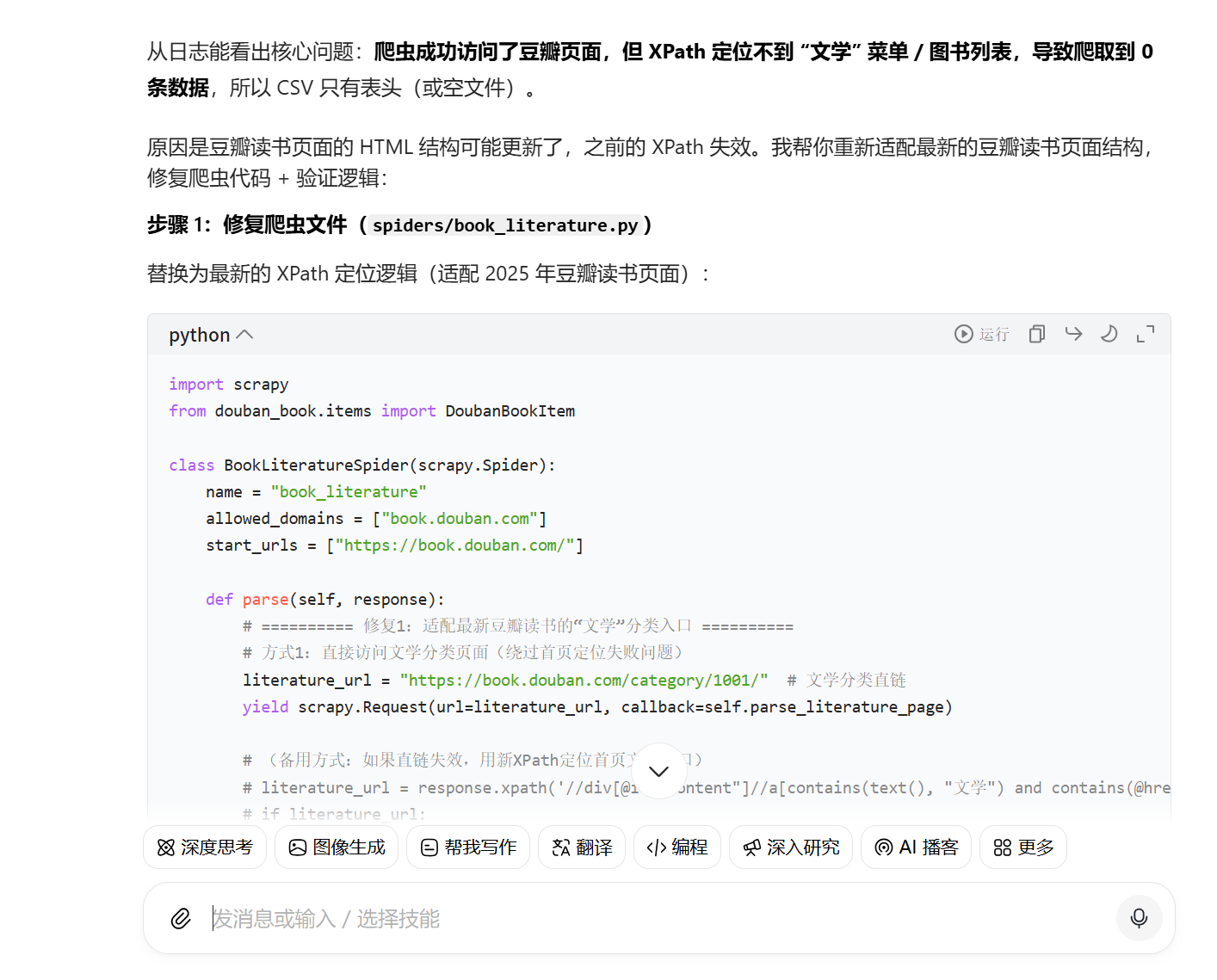
进行修改,运行,发现还是没有,接下来打开豆瓣找到要爬取的地方,鼠标右键点击检查,找到你需要的代码复制下来给豆包,并表达你的要求

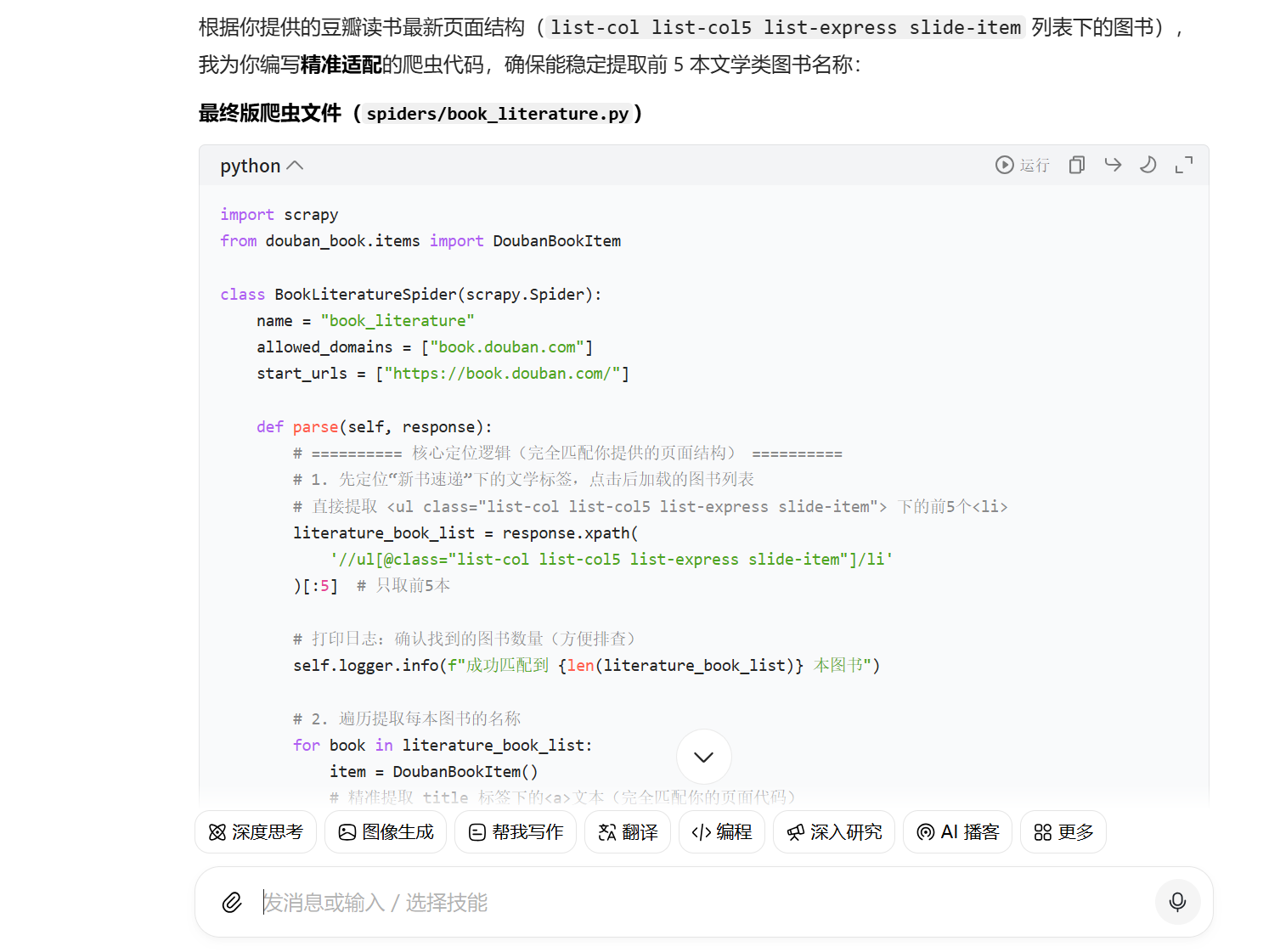
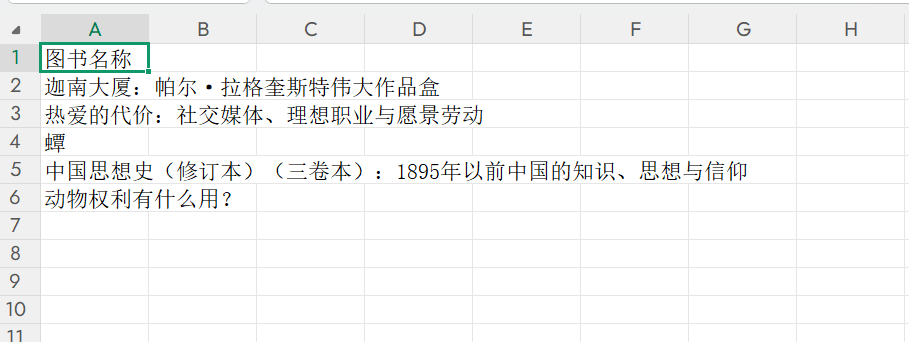
根据豆包给出的内容进行适当的修改,随后运行(运行时在终端输入scrapy crawl book_literature或者scrapy crawl book_literature -o literature_books.csv都可以),发现在csv文件中出现了我们想要爬取的内容。
最终结果:
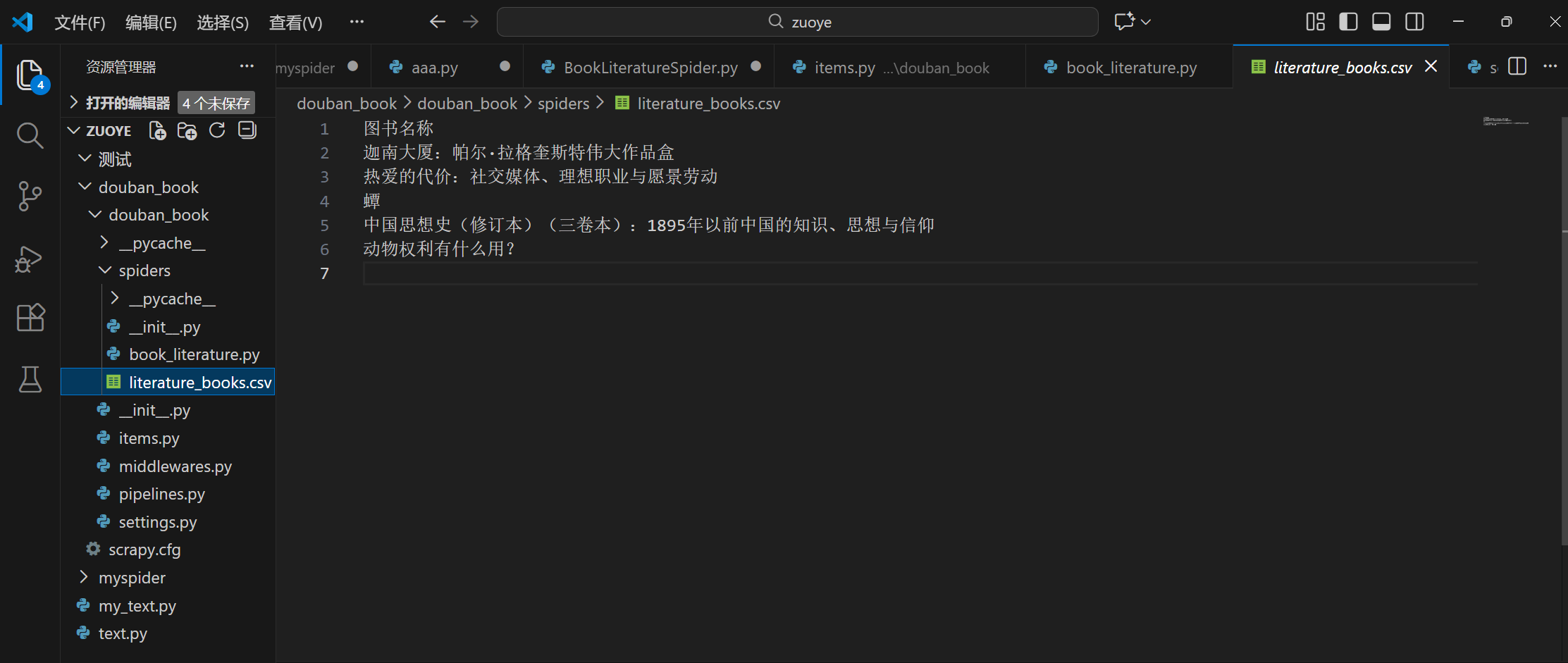
附录:
豆瓣读书页面及页面结构的代码
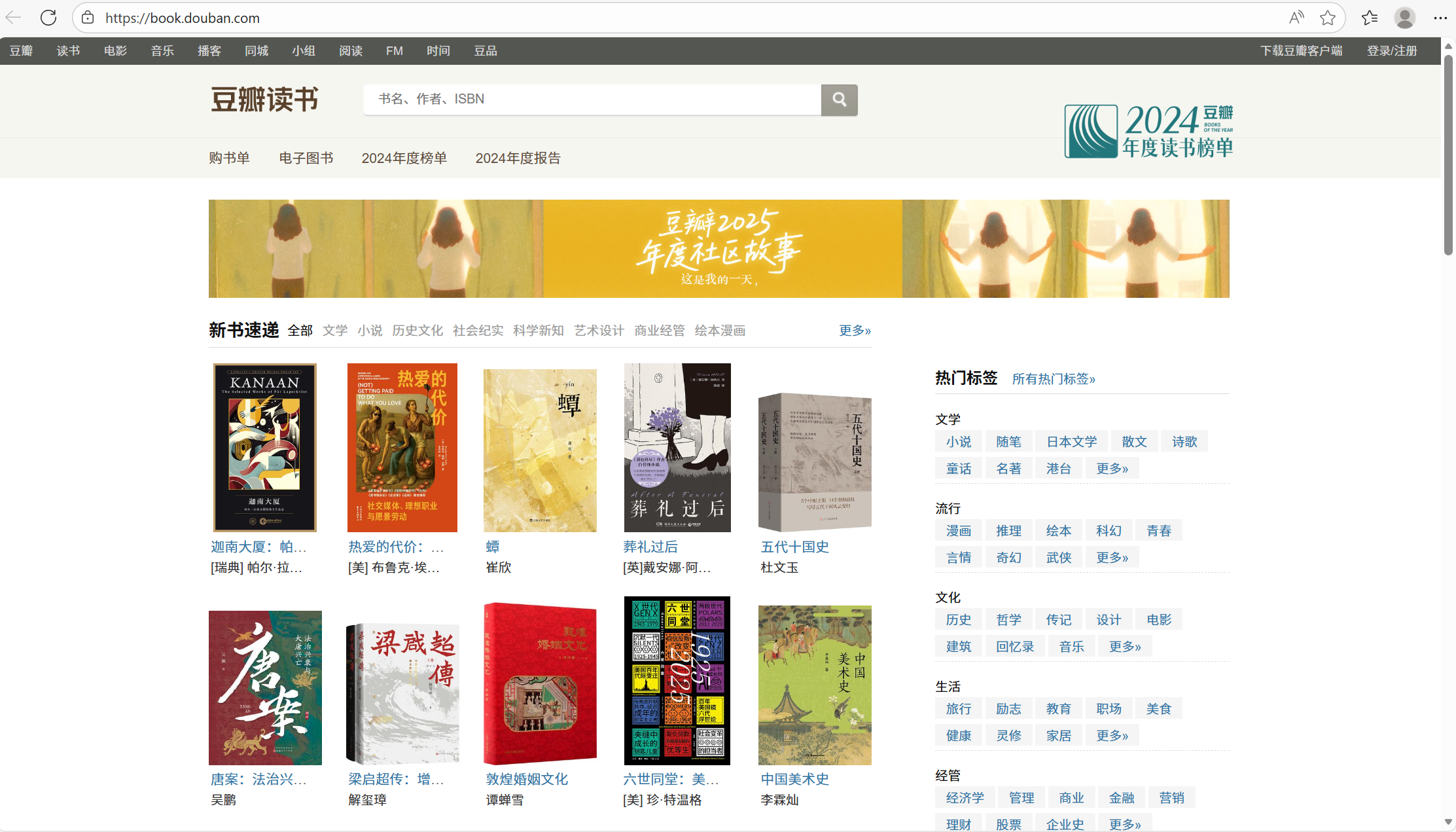
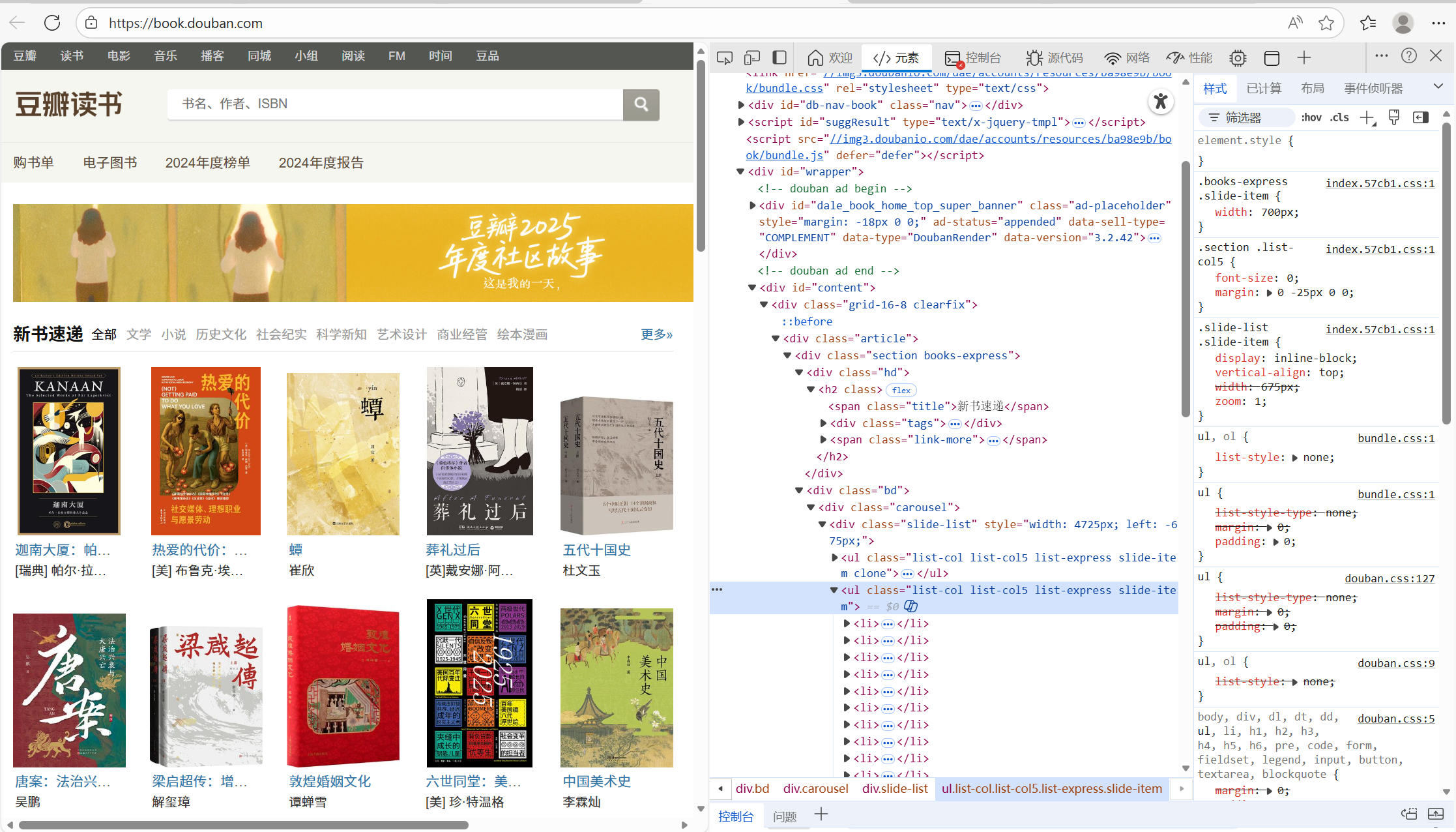
最终爬取结果显示

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)